주성분분석 (PCA)
차원의 저주
차원의 저주(Curse of dimensionality)란, 학습 데이터에 비해 입력 차원의 수가 큰 경우 일정 차원을 기점으로 학습 능력이 급격히 감소하는 현상을 의미한다. 다시 말해, 특징 공간의 차원이 증가하면서 학습 데이터의 수가 특징 공간의 차원의 수보다 적어져 성능이 저하되는 것이다.
차원이 증가할 수록 특징 공간의 부피가 커지고, 개별 차원 내에서의 데이터의 밀도가 희소해지며, 이에 따라 거리 함수가 제대로 작동하지 않고, 계산 비용이 증가하는 등의 문제가 발생하는데, 이러한 문제를 차원의 저주라고 한다.
그러나, 입력 차원 수가 증가한다고 반드시 차원의 저주가 발생하는 것은 아니며, 학습 데이터보다 입력 차원의 수가 많아지는 경우에 차원의 저주 문제가 발생한다. 공간이 희소해짐에 따라, 저차원 데이터에서 패턴을 파악하는 것보다 고차원 데이터에서 패턴을 파악하는데 더 많은 데이터가 필요해지기 때문이다.
이러한 차원의 저주는 차원이 증가함에 따라 동일한 데이터 개수로는 공간을 충분히 채울 수 없게 되어 데이터의 분포가 희소해지기에 발생한다. 입력 데이터의 차원이 증가하면, 특징 공간의 부피가 차원에 따라 기하급수적로 증가하여 데이터 간 거리가 멀어지고, 학습 데이터의 밀도가 낮아진다.
이러한 차원의 저주 문제를 해결하기 위한 이론적인 해결책은 훈련 샘플의 밀도가 충분히 높아질 때까지 데이터를 모아서 훈련 세트의 크기를 키우는 것이다. 그러나, 일정 밀도에 도달하기 위해 필요한 훈련 샘플 수는 차원의 수가 커짐에 따라 기하급수적으로 늘어난다는 문제가 존재한다. 따라서 PCA, SVD 등과 같은 차원 축소 기법들을 통해 학습 결과에 영향을 미치지 않는 불필요한 축을 줄임으로써 차원의 저주를 완화하기도 한다.
“The curse of dimensionality refers to various phenomena that arise when analyzing and organizing data in high-dimensional spaces (often with hundreds or thousands of dimensions) that do not occur in low-dimensional settings such as the three-dimensional physical space of everyday experience.
차원 축소 방법
특징 선택 (Feature Selection)
- 변수들 중 중요한 변수만 몇 개 고르고 나머지는 버리는 방법으로, 변수 간 중첩이 있는지, 어떤 변수가 중요한 변수인지, 어떤 변수가 종속 변수에 영향을 크게 주는 변수인지를 분석할 필요가 있음.
- 변수 간의 중첩을 확인하는 방법으로 상관관계를 주로 사용함.
특징 추출 (Feature Extraction)
- 변수들을 조합해 데이터를 잘 표현하는 주성분을 가진 새로운 변수를 추출하는 방법
- (ex) 주성분분석 (PCA, Principal Component Analysis)
선형 판별 분석 (LDA : Linear Discrimination Analysis)
- 학습 과정 중 클래스를 가장 잘 구분하는 축(axis)을 학습하는 방법
PCA (Principal Component Analysis)
PCA는 데이터의 분산을 최대한 보존하면서 서로 직교하는 주성분을 찾아 고차원 공간의 표본들을 저차원 공간으로 변환하는 기법을 의미한다. 이를 위해 데이터를 잘 표현하는 초평면을 정의한 뒤, 데이터를 이 초평면에 projection하여 분산이 최대로 보존되는 축을 선택한다.
다시 말해, PCA는 다변량 데이터의 차원을 축소하면서 정보 손실을 최소화하는 방법으로, 데이터의 분산을 최대한 보존하는 새로운 축(주성분)을 찾아 원래 데이터를 이 주성분에 투영함으로써 차원을 축소하는 방법이다. 이를 통해 데이터의 중요한 정보를 유지하면서 차원을 줄이고, 시각화 및 기계 학습 알고리즘의 성능을 향상시킬 수 있다.
이러한 PCA의 과정은 다음과 같다.
- 데이터 전처리 : 데이터를 표준화(평균 0, 표준편차 1)하거나 정규화(최소값 0, 최댓값 1)하여 스케일 조정
- 공분산 행렬 계산 : 데이터의 공분산 행렬을 계산합니다. 공분산 행렬은 변수 간의 선형 관계를 나타내며, 이를 통해 데이터의 분포와 구조를 파악할 수 있습니다.
- 고윳값 및 고유벡터 계산 : 공분산 행렬의 고윳값과 고유벡터를 계산합니다. 고윳값은 데이터의 분산을 나타내고, 고유벡터는 주성분의 방향을 나타냅니다. (입력 데이터들의 공분산 행렬에 대한 고유값 분해)
- 고유벡터 : 주성분 벡터. 데이터 분포에서 분산이 큰 방향.
- 고유값 : 분산의 크기
- 주성분 선택 : 고유값이 큰 순서대로 주성분을 선택합니다. 주성분 개수를 선택하는 방법으로, 누적 설명 분산 비율(cumulative explained variance ratio)을 활용할 수 있습니다. 누적 설명 분산 비율이 일정 수준(예: 95% 또는 99%) 이상인 주성분까지 선택하여 차원 축소를 수행합니다.
- 주성분으로 원본 데이터 변환 : 선택된 주성분(고유 벡터)을 이용하여 원본 데이터를 변환합니다. 이 과정에서 원본 데이터의 차원이 축소되며, 새로운 주성분 축에 투영된 데이터를 얻게 됩니다.
주성분을 찾는 방법
주성분을 찾기 위해선 특이값 분해(Singular Value Decomposition, SVD)를 사용한다. 이는 정방행렬이 아닌 경우(비정방행렬)에 대해서도 행렬 분해를 수행하기 위해 활용하는 방법이다. 이를 위해 임의의 행렬을 의 형태 행렬로 분해한다.
- : 𝑚 × 𝑛 matrix (주어진 𝑚 × 𝑛 행렬)
- : 𝑚 × 𝑚 orthogonal matrix (직교행렬)
- : 𝑚 × 𝑛 diagonal matrix (대각행렬)
- : 𝑛 × 𝑛 orthogonal matrix (직교행렬)
이때, 고유값은 행렬 A가 직사각행렬이면 입출력 차원이 달라 고유값을 직접 정의할 수 없다. 따라서 길이(스케일 크기)만 추출하기 위해 , 의 결과가 항상 정방 행렬이고 대칭행렬인 점을 활용한다.
- (왼쪽 특이행렬) : 의 고유 벡터를 열에 배치한 n × n 행렬
- (특이값 리스트) : 의 고유값의 제곱근을 대각선에 배치한 대각 행렬 (n × m 행렬)
- (특이행렬) : 의 고유 벡터를 열에 배치한 m × m 행렬
고유값 분해 (Eigen-Decomposition)
고유값 분해 (Eigen-Decomposition)란 행렬을 고유값과 고유 벡터를 통해 분해하는 기법으로, 어떤 정방행렬 A를 의 형태로 쪼개는 것을 의미한다. 이때, Q는 A의 고유벡터를 열에 배치한 행렬, Λ는 고유값을 대각선에 배치한 대각행렬을 의미한다.
이렇게 고유값 분해를 수행하면 행렬을 그 행렬만의 좌표계(고유 벡터)로 바꾸어 단순 대각 형태로 만들어 준다. 이때, 고유값이 크다는 것은 그 방향에 데이터의 정보량이 많다는 의미이기에 정보량이 큰 데이터만 남기고 차원을 축소할 수 있기 때문에 PCA에서 주로 활용된다.
- 대각화 가능하다 = 행렬 A를 고유 벡터와 고유값으로 분해할 수 있다
- 다시 말해, 고유값 분해가 가능하고, 의 형태로 표현이 가능하다는 것
고유값 분해를 해주면, 대각행렬 가 단순 스케일 행렬임을 볼 수 있다. (이는 표준 기저에서 봤을 땐 복잡한 변환이었는데, 좌표계를 고유벡터 기준으로 바꿨더니 A가 단순히 각 좌표 성분을 배 해주는 행렬로 보이더라! 라는 느낌으로 이해하면 된다.)
의 열벡터들을 고유벡터로 구성한 이유는 결국엔 이 벡터들이 만드는 좌표계가 고유기저이기 때문이고, 결국 고유값 분해는 이 고유 기저를 기준으로 행렬을 분해하는 것을 의미한다고 볼 수 있다.
고유값 분해 예시
- 고유값 :
- 고유벡터 :
- 고유값들의 합 : 대각 요소들의 합
- 고유값들의 곱 : 행렬식
- 정규직교벡터 : 서로 수직이고, 각각 길이가 1인 벡터들
군집화 (Clustering)
군집화는 유사한 속성들을 갖는 관측치들을 묶어 전체 데이터를 몇 개의 군집(cluster)로 나누는 것을 의미한다. 다시 말해, 어떠한 레이블 없이 데이터 내에서 거리가 가까운 것들끼리 각 군집들로 분류하여 데이터 내에 숨어있는 패턴 혹은 그룹을 파악해 서로 묶는 것이다. 이때, 군집(cluster)은 비슷한 특성을 가진 데이터의 집합을 의미한다. 군집화는 군집 내 응집도와 군집 간 분리도를 최대화하는 것을 목적으로 하며, 이러한 군집화 알고리즘에는 K-Means Clustering, Mean Shift, Gaussian Mixture Model, DBSCAN, Agglomerative Clustering 등이 있다.
거리 척도
유클리드 거리
- 각 차원의 차를 제곱해서 사용하는 것으로, n차원에서 두 점 사이의 거리를 구할 경우 다음과 같이 나타냄.
맨하탄 거리
- 각 차원의 차를 제곱해서 사용하는 것이 아닌, 절댓값을 바로 합산하는 것을 의미하며, 맨해튼 거리는 항상 유클리드 거리보다 크거나 같다.
마할라노비스 거리
- 변수들의 공분산(상관관계)을 고려해 거리를 측정하는 방식
- : covariance matrix
공분산 행렬 (Covariance Matrix)
- 각 확률 변수 사이의 공분산을 모두 구해 행렬화한 것
- 대각선에는 각 변수의 분산, 그 외 위치에는 변수 쌍들의 공분산이 표현됨.
K-means 알고리즘
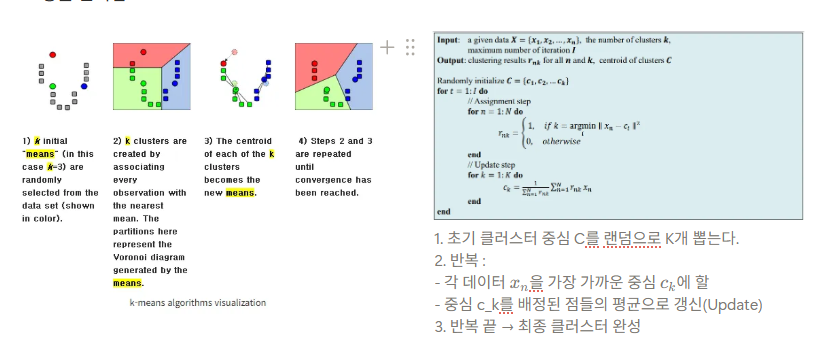
K-Means 클러스터링은 클러스터링에서 가장 일반적으로 사용되는 알고리즘으로, 군집 중심점(centroid)이라는 특정한 임의의 지점을 선택해 해당 중심에 가장 가까운 포인트들을 선택하는 군집화 기법이다. K-Means이므로 K개의 centroid를 지정할 수 있고, 이때 가장 가까운 포인트를 선택한다는 점에서 K-Means는 거리 기반 군집화 방법임을 알 수 있다.
이처럼 K-means 클러스터링은 군집 중심점(centroid)라는 특정한 k개의 임의 지점을 선택해 해당 중심에 가장 가까운 포인트들을 선택하는 군집화 기법으로, 다음과 같은 과정에 의해 수행된다.
- 초기 중심점 설정
- 중심점을 선택된 포인트들의 평균 지점으로 이동함.
- 이동된 중심점에서 다시 가까운 포인트를 선택함.
- 다시 중심점을 평균 지점으로 이동하는 프로세스를 반복적으로 수행함.
- 즉, 초기 중심 설정 → 할당 단계 (closest centroid) → 업데이트 단계 (평균 재계산) → 수렴 시 종료의 과정을 반복함.
inertia (=SSE)
- Centroid와 Sample들 사이의 거리 제곱 합
- K-Means 알고리즘은 k개의 중심(centroid)를 추정하여 각 샘플을 가장 가까운 중심에 할당하고, 중심을 재계산하는 과정을 반복하여 군집 내 제곱합(SSE)를 최소화함.
참고 - Rule of Thumb
- 일상적인 상황에서 간단하게 적용할 수 있는 규칙이나 원리
- k : cluster의 개수이고, N : sample 개수일 때,
Silhouette Score
- 최적의 cluster 개수를 찾는 방법
- 클러스터링의 품질을 정량적으로 계산해 주는 방법으로, 데이터의 응집도를 나타내는 값인 , 클러스터 간 분리도를 나타내는 값인 를 통해 실루엣 계수 를 계산함.
- : i번째 샘플이 속한 클러스터 내부의 평균 거리
- : i번째 샘플과 가장 가까운 클러스터 샘플들과의 평균 거리
- 실루엣 계수는 클러스터 내 데이터 포인트 간의 거리는 가깝고, 클러스터 간 거리는 멀면 높은 값을 지니며, -1~+1 사이의 값을 지님.
- 클러스터 개수가 최적화되어 있다면 분리도의 값은 커지고, 응집도의 값은 작아지기에 실루엣 계수는 1에 가까워짐. 결국 실루엣 계수가 1에 가까울 수록 클러스터 개수가 최적화된 것임.
Mean-Shift 알고리즘
평균 이동(Mean Shift)은 K-means와 유사하게 중심을 군집의 중심으로 지속적으로 움직이면서 군집화를 수행한다. 그러나 K-means 방법이 중심에 소속된 데이터의 평균 거리 중심으로 이동을 한다면, Mean Shift는 중심을 데이터가 모여 있는 밀도가 가장 높은 곳으로 이동시킨다는 점에서 그 차이가 있다.
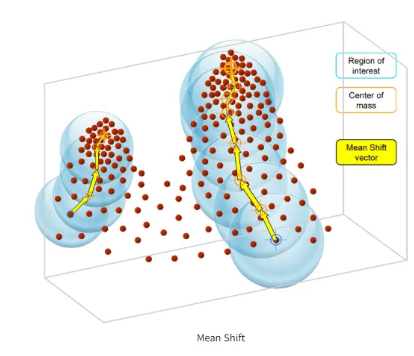
Mean Shift는 특정 대역폭(bandwidth;region of interest)을 가지고 최초의 확률 밀도 중심 내에서 데이터의 확률 밀도가 더 높은 곳으로 중심을 이동한다. (centroid-based algorithm라고 한다)
Mean Shift는 데이터 간의 거리가 아닌 데이터의 분포도를 이용해 군집 중심점을 잡는다. 군집 중심점은 데이터 포인트가 모여 있는 곳이라는 아이디어에 착안한 것이며, 이를 위해 확률 밀도 함수를 이용한다. 일반적으로 확률 밀도 함수를 찾기 위해 KDE(Kernel Density Estimation)를 이용한다. Mean Shift 알고리즘은 임의의 포인트에서 시작해 데이터 내의 확률 밀도 peak 포인트를 찾을 때까지 KDE를 반복적으로 적용하며 군집화를 수행한다.
Mean Shift 알고리즘은 K-Means와 다르게 군집의 개수를 지정할 필요가 없다. 다만 Bandwidth의 크기에 따라 알고리즘 자체에서 군집의 개수를 최적화하므로, Bandwidth의 최적화가 필요하다
또한, Mean Shift 알고리즘은 K-평균과 달리 초기 중심점을 무작위로 선택하는 방식이 아니므로 초기값 설정에 따른 결과의 변화가 거의 없고, 초기화 과정에서 모든 데이터 포인트를 잠재적인 클러스터 중심으로 설정한다. 따라서 K-Means와 달리 랜덤 초기화에 의존하지 않으며, 이로 인해 실행할 때마다 결과가 항상 동일하다는 장점이 존재한다. (모든 데이터 포인트에서 각각이 밀도 높은 방향으로 올라가다 보면 자연스럽게 같은 peak로 수렴하는 시작점들이 생김 → 그때 같은 peak에 도착한 시작점들을 하나의 cluster로 묶음. 따라서 Mean Shift의 클러스터 개수 = 데이터 밀도 분포의 피크(Mode)의 개수)
정리
- Mean Shift 알고리즘 : 주어진 Bandwidth 내에서 KDE(Kernel Density Estimation)를 이용해 데이터의 밀도 분포를 추정하고, 밀도가 높은 방향으로 중심점을 반복적으로 이동시키면서 군집화를 수행하는 모델
- 각 샘플은 주변 데이터의 밀도가 가장 높은 방향으로 이동하게 되며, 이러한 이동 과정이 수렴하게 되면 그 점은 하나의 클러스터 중심이 된다. 즉, Mean Shift는 데이터 밀도 기반으로 군집 중심을 자동 탐색하는 알고리즘이다.
- 중심을 군집의 중심으로 지속적으로 움직이면서 군집화를 수행한다는 점이 K-Means 알고리즘과 유사하나, K-Means 알고리즘은 중심에 소속된 데이터의 평균 거리 중심으로 이동하는 데 반해, Mean-Shift 알고리즘은 중심을 데이터가 많이 모여 있는, 밀도가 가장 높은 곳으로 이동한다.
- 즉, Mean-Shift 알고리즘은 데이터의 분포도를 통해 군집 중심점을 찾는 알고리즘으로, 가장 집중적으로 데이터가 모여있어 확률 밀도 함수가 피크인 점을 군집 중심점으로 선정하며, 일반적으로 주어진 모델의 확률 밀도 함수를 찾기 위해 KDE(Kernel Density Estimation)를 이용한다.
- Mean Shift 알고리즘에서의 Bandwidth는 각 데이터 포인트 주변에서 밀도를 계산할 때 고려할 이웃 데이터의 반경을 정의하며. Bandwidth 크기에 따라 군집 수가 결정된다. 이때, 탐색 반경이 너무 크면 정확한 중심 위치를 찾을 수 없고, 너무 작으면 local minimum에 빠지기 쉽다.
KDE (Kernel Density Estimation)
- 커널(kernel) 함수를 통해 어떤 변수의 확률 밀도 함수를 추정하는 대표적인 방법
- KDE는 확률 변수의 확률 밀도 함수를 사용하여 각 반복에서 데이터 밀도가 높은 영역을 식별한다.
- 개별 데이터 포인트에 커널 함수(Gaussian 등)를 적용한 값들을 모두 합한 후 평균을 구하여 확률 밀도 함수를 추정하는 방식
- 다시 말해, KDE는 각 데이터 포인트에 Gaussian 같은 커널을 올리고, 모든 커널을 합쳐 확률 밀도 함수를 만든 뒤 Mean Shift가 이 density에서 가장 높은 지점을 찾도록 돕는 방법
코드
- PCA 수행 :
class PCA(n_components=None, svd_solver='auto')- 유지할 주성분의 수 (또는 비율) :
n_components- 수 지정 :
PCA(n_components=2) - 비율 지정 :
PCA(n_components=0.95)
- 수 지정 :
- 특이값 분해 수행 방식 결정 :
svd_solver:{‘auto’, ‘full’, ‘arpack’, ‘randomized’}- PCA에서 계산 시 어떤 방식으로 특이값 분해를 수행할지 결정하는 옵션
- 전체 데이터를 사용할 건지, 일부 성분을 근사적으로 뽑아 빠르게 계산할 건지 결정
full: full SVD(특이 분해) 실행arpack: n_components로 잘린 SVD 실행randomized: Halko 등의 방법으로 무작위 SVD 실행
- 유지할 주성분의 수 (또는 비율) :
- KMeans 수행 :
class KMeans(n_clusters=8, init='k-means++’, n_init=10, max_iter=300, random_state=None, algorithm='auto')n_clusters: cluster의 개수init: {'k-means++', 'random’}- k-means++ : 수렴 속도를 높이기 위한 스마트한 방식으로, 첫 번째 중심은 아무거나 선택하고, 나머지 중심들은 이미 선택된 중심들과 최대한 멀리 있도록 선택함.
n_init: 다른 centroid로 시도할 횟수algorithm: {“auto”, “full”, “elkan”}full: classical EM-style algorithm- EM(Expectation Maximization) 알고리즘
elkan: ****삼각부등식으로 거리 계산을 줄이는 최적화auto: dense면 elkan, sparse면 full
- 실루엣 점수 계산 :
silhouette_score(X, labels, metric= 'euclidean') - Mean-Shift 수행 :
class MeanShift(bandwidth=None, seeds=None, n_jobs=None, max_iter=300)bandwidth: float value used in the RBF kernelseeds: used to initialize kernels
