앙상블 (Ensemble Learning)
앙상블 기법이란, 여러 개 분류기를 생성하고, 그 예측을 결합함으로써 보다 정확한 예측을 도출하는 기법으로, Strong Classifier를 사용하는 대신 Weak Classifier를 조합하여 더 정확한 예측을 수행한다.
이는 단일 모델의 예측을 평가하는 것보다 더 많은 계산이 필요하므로 더 많은 연산 능력을 활용해 더 좋은 예측력을 가지게 된다.
앙상블 기법의 유형
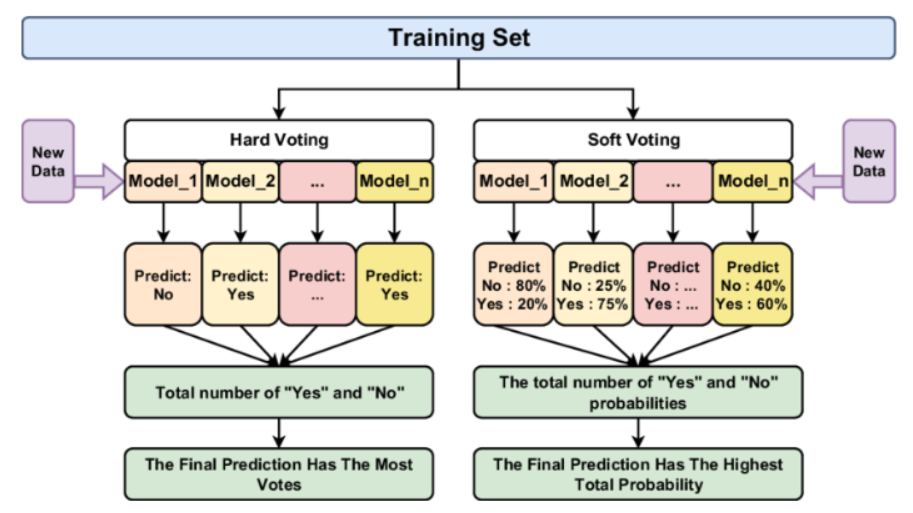
- 보팅 (Voting) : 여러 개 분류기가 투표를 통해 최종 예측 결과를 결정하는 방식
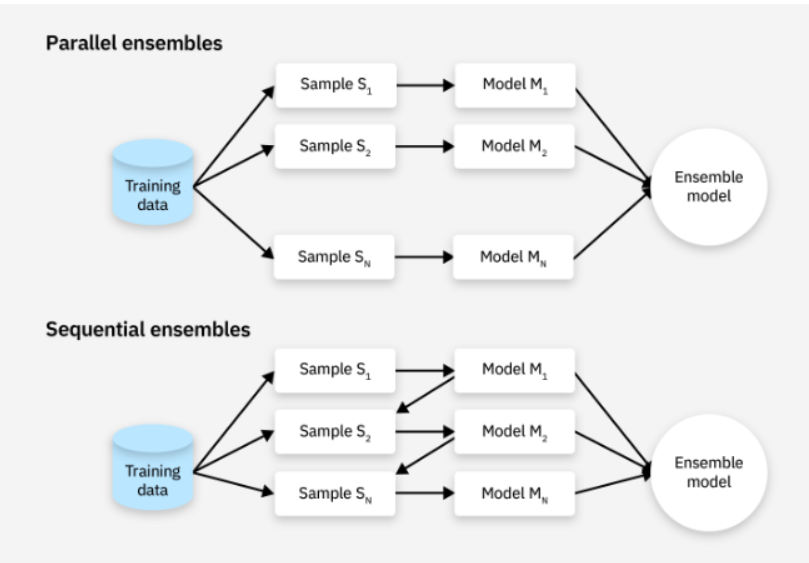
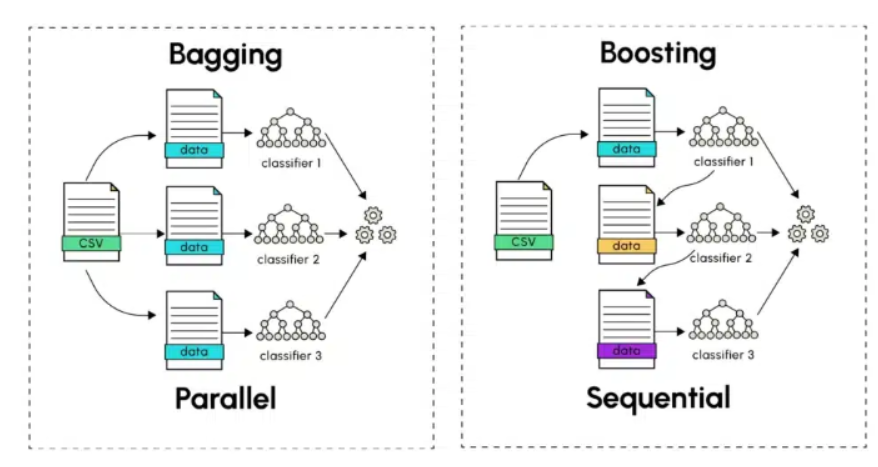
- 배깅 (Bagging : Bootstrap Aggregating) : 데이터 샘플링을 통해 모델을 학습시키고 결과를 집계하는 방식
- 부스팅 (Boosting) : 여러 개 분류기가 순차적으로 학습을 수행하는 방식 (다음 분류기에게 가중치 부스팅)
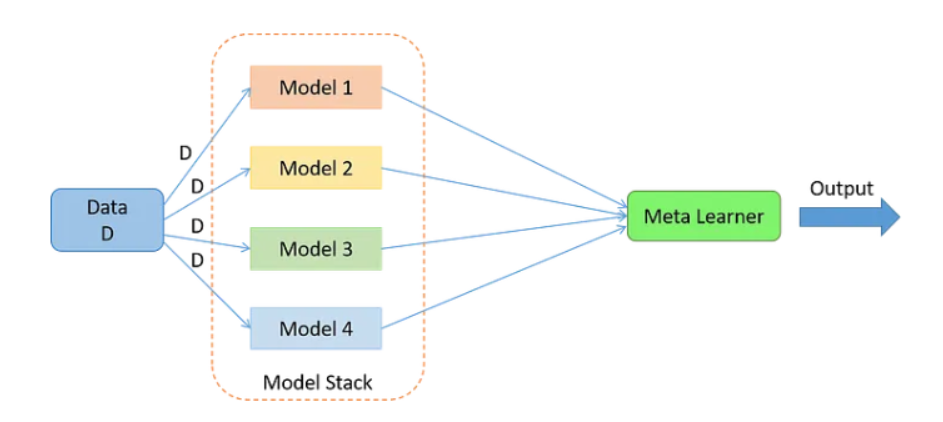
- 스태킹 (Stacking : Stacked Generalization) : 여러 개 분류기 결과를 취합하는 마지막 예측기(블렌더 또는 메타 학습기)를 학습하는 방법
앙상블 기법의 특징
- 앙상블 모델은 Heterogeneous하고 Independent한 특성을 지니고, 낮은 상관관계를 지녀야 성능이 좋아짐. (즉, 모델의 종류나 학습 방식이 서로 다르고, 독립적이어야 함.)
- 이러한 특성을 지녀야 서로 다른 종류의 오차를 생성할 가능성이 높고, 높은 정확도를 얻을 수 있으며, 성능을 분산시키므로 과적합 감소 효과를 얻을 수 있음.
- 앙상블이 잘 작동하려면 모델들이 같은 실수를 반복하지 않는 것이 중요한데, 모든 모델이 같은 방향으로 틀리면 앙상블 효과가 떨어짐. (하지만, 모델들이 서로 다른 관점에서 판단하면 투표나 평균을 취했을 때 앙상블 효과가 높아지므로 정확도가 높아질 가능성이 높음.)
- 즉, 오차가 서로 상관되지 않는 것이 중요함.
보팅 (Voting)
Voting은 서로 다른 알고리즘을 가진 분류기 중 투표를 통해 최종 예측 결과를 결정하는 방식으로, 최종 결과 선정 방식에 따라 Hard Voting과 Soft Voting으로 분류된다.
하드 보팅 (Hard Voting)
- 분류기 각각의 예측 결과를 활용하는 방법으로, 다수의 분류기가 예측한 결과 값을 최종 결과로 선정하므로 직접 투표에 해당함.
- 다시 말해, 각각의 분류기 결과값 중 가장 많은 것을 따르는 방식임.
- 확률의 신뢰도가 낮거나 모델들이 확률 출력을 제공하지 않는 경우 사용됨.
소프트 보팅 (Soft Voting)
- 예측 결과의 확률값을 활용하는 방법으로, 모든 분류기가 예측한 레이블 값의 결정 확률 평균을 계산해 가장 확률이 높은 레이블 값을 최종 결과로 선정하므로 간접 투표에 해당함.
- 분류기의 확률을 더하고 각각 평균을 내서 확률이 제일 높은 값을 선정하는 방식임.
- 확률 예측이 가능한 모델들(즉, 확률의 신뢰도가 높음)이고 모델의 성능 차이가 큰 경우 사용됨.
- 하드 보팅에 비해 성능이 좋은 편에 속함.
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.ensemble import VotingClassifier
from sklearn.metrics import accuracy_score
X_train, X_test, y_train, y_test = train_test_split(X, y) # 데이터 분할
dt_clf = DecisionTreeClassifier(max_depth=4) # Decision Tree 객체 생성 (트리 최대 깊이 = 4)
knn_clf = KNeighborsClassifier(n_neighbors=7) # KNN 분류기 생성 (예측 시 참고할 주변 데이터 포인트 개수 = 7)
svm_clf = SVC(gamma=0.1, probability=True) # SVC 객체 생성 (probability=True이므로 클래스 확률 출력 제공)
models = [('dt', dt_clf), ('knn', knn_clf), ('svc', svm_clf)] # 모델 정의
voting_clf = VotingClassifier(estimators=models, voting='soft', weights=[2, 1, 2]) # 소프트 보팅 객체 생성 (weight는 각 모델에 대한 가중치 비율/중요도를 지정함.)
voting_clf.fit(X_train, y_train)
# 여러 분류기를 한 번에 학습시키고 성능 비교
for clf in (dt_clf, knn_clf, svm_clf, voting_clf):
clf.fit(X_train, y_train) # 학습
y_pred = clf.predict(X_test) # 예측
print(clf.__class__.__name__, accuracy_score(y_test, y_pred)) # 성능 측정 (정확도)배깅 (Bagging, Boostrap Aggregating)
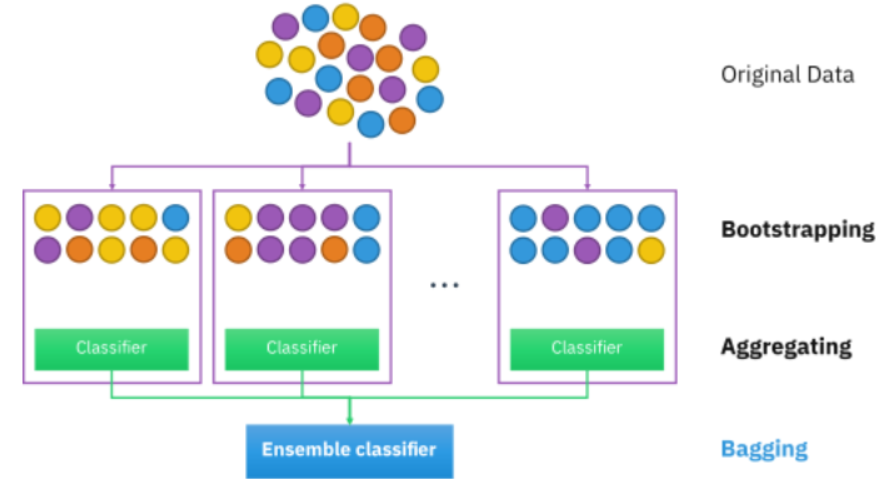
배깅이란, 부트스트랩으로 생성된 여러 데이터셋을 통해 Weak Learner를 훈련시키고, 그 결과를 Voting하여 최종 예측을 만드는 것을 의미한다.
다시 말해, 데이터 샘플링(Bootstrap)을 통해 모델을 학습시키고, 결과를 집계(Aggregating)하는 방법으로, 모두 같은 유형의 알고리즘 기반 분류기를 활용한다. 즉, 원본 데이터를 여러 번 랜덤 샘플링 해서 각기 다른 학습 데이터를 만들고, 동일한 알고리즘의 여러 모델을 학습시킨 뒤 예측을 평균 또는 투표로 결합하는 방법을 배깅이라고 한다.
- 부트스트랩(bootstrap) : 통계학에서 사용하는 용어로, 무작위 샘플링을 통해 새로운 데이터셋을 생성하는 것을 의미함.
(ex) 한 식자재 마트에 들어오는 상추의 신선도를 알기 위해 마트에 입고되는 모든 상추 중 임의로 100개를 뽑아 상추의 신선도 평균을 구하는 것 - 부트스트랩은 raw data의 분포를 추정할 때 사용할 수 있음.
예를 들어, 측정된 데이터 중에서 중복을 허용한 복원 추출로 n개를 뽑고, 뽑은 n개의 평균을 구하는 것을 m번 반복하여 모으게 되면 평균에 대한 분포를 구할 수 있게 되고, 이로부터 샘플 평균에 대한 신뢰 구간을 추정할 수 있게 됨. 이를 통해 데이터가 부족해도 여러 데이터셋을 가진 것처럼 모델을 반복 학습하는 효과를 낼 수 있음. - 즉, 배깅(Bagging)은 부트스트랩(bootstrap)을 집계(Aggregating)하여 학습 데이터가 충분하지 않더라도 충분한 학습효과를 주어 높은 bias의 underfitting 문제나, 높은 variance로 인한 overfitting 문제를 해결하는데 도움을 줌.
- 일반적으로 배깅에선 데이터 분할 시 중복을 허용하는 방식을 활용하며, 만약 중복을 허용하지 않는다면 그 방식을 페이스팅(Pasting)이라고 한다.
- 집계 방법에는 다수결 투표 방식으로 결과를 집계하는 Categorical Data 방법과 평균값을 집계하는 Continuous Data가 있음.
- 대표적인 Bagging 알고리즘에는 랜덤 포레스트(Random Forest)가 있음.
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
dt_clf = DecisionTreeClassifier() # 결정 트리 객체 생성
# 배깅 객체 생성, 결정 트리 모델을 기본으로 사용하며, 내부적으로는 이를 500번 복제하여 사용
# 다시 말해, Decision Tree 500개를 랜덤하게 학습시키고, 그 결과를 투표해서 최종 예측하는 배깅 앙상블 모델임.
# 각 트리는 서로 다른 부트스트랩 샘플로 학습되며, 원본 데이터에서 중복 허용하여 랜덤하게 뽑은 데이터로 각 트리를 학습함.
# 트리마다 조금씩 다른 데이터 -> 서로 다른 결정 경계 -> 오차 상관 감소 -> 앙상블 효과 증가
bag_clf = BaggingClassifier(dt_clf, n_estimators=500)
bag_clf.fit(X_train, y_train) # 학습
# 단일 Decision Tree 모델과 배깅 분류기 성능 차이 비교
# 배깅은 여러 트리의 결과를 활용하므로 분산을 줄이고 일반화 성능을 향상시킴.
for clf in (dt_clf, bag_clf):
clf.fit(X_train, y_train) # 학습
y_pred = clf.predict(X_test) # 예측
print(clf.__class__.__name__, accuracy_score(y_test, y_pred)) # 성능 측정 (정확도)from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
X, y = make_moons(n_samples=500, noise=0.30, random_state=42) # 랜덤 데이터 500개 생성
X_train, X_test, y_train, y_test = train_test_split(X, y) # 데이터 분할
# 대표적인 Bagging 알고리즘 - 랜덤 포레스트(Random Forest)
clf = RandomForestClassifier(n_estimators=500) # 랜덤 포레스트 객체 생성
clf.fit(X_train, y_train) # 학습
y_pred = clf.predict(X_test) # 예측
print(f"{clf.__class__.__name__} : {accuracy_score(y_test, y_pred):.4f}") # 성능 측정 (정확도)부스팅 (Boosting)
순차적으로 모델을 학습시키고, 이전 모델이 잘못 예측한 부분을 다음 모델이 개선할 수 있도록 하는 방법으로, 각 모델의 예측 결과를 가중 평균하여 최종 예측을 만들어 낸다.
다시 말해, 이전 분류기가 틀린 예측을 한 데이터에 대해 올바른 예측이 가능하도록 다음 분류기에게 가중치를 부여하면서 학습과 예측을 진행해 계속해서 가중치를 부스팅하며 학습을 진행한다.
이는 배깅과 유사한 매커니즘을 지니나, 배깅과는 다르게 순차적으로 진행된다는 차이가 있다. 앞선 Bagging의 경우 각각의 분류기들이 학습시 상호영향을 주지 않은 상황에서(독립적) 학습이 끝난 다음 결과를 종합하는 기법이라면, Boosting은 이전 분류기의 학습 결과를 토대로 다음 분류기의 학습 데이터의 샘플 가중치를 조정해 학습을 진행하는 방법이므로 먼저 생성된 모델을 꾸준히 개선해 나가는 방식으로 학습이 진행된다.
따라서 오차에 대해 높은 가중치를 부여하므로 높은 정확도를 나타내고, 배깅에 비해 성능이 좋으나, 속도가 느리고 과적합 가능성이 있으며, 이상치에 취약할 수 있다. 이러한 Boosting 기법을 활용한 대표적인 알고리즘은 XGBoost, AdaBoost, GBM, LightBoost 등이 있다.
AdaBoost
- 가장 초기의 부스팅 알고리즘 중 하나로, 약한 학습기(weak learners)를 순차적으로 추가하여 학습시키고, 이전 학습기에서 잘못 분류된 샘플에 더 많은 가중치를 부여하여 이후 학습기가 이를 더 잘 맞추도록 함. (오차 보정을 위해 데이터들에 가중치를 부여하며 동작함)
- 단순한 모델을 결합해 높은 예측 성능을 내는 방법
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
from sklearn.ensemble import AdaBoostClassifier
from sklearn.metrics import accuracy_score
X, y = make_moons(n_samples=500, noise=0.30, random_state=42) # 랜덤 데이터 500개 생성
X_train, X_test, y_train, y_test = train_test_split(X, y) # 데이터 분할
# AdaBoost = Adaptive Boosting
# 앞에서 틀린 것을 뒤에서 계속 보완해 나가면서 강한 분류기를 만들어 가는 부스팅 알고리즘으로,
# 약한 분류기 여러 개를 순차적으로 학습시키면서 못 맞춘 샘플에 점점 더 가중치를 많이 줘서
# 어려운 샘플에 집중할 수 있도록 하는 방식임.
# 즉, 데이터에 대한 가중치를 적응적으로 바꾸면서 학습해 나가는 방식임.
clf = AdaBoostClassifier(n_estimators=500, learning_rate=0.1) # AdaBoost 객체 생성
clf.fit(X_train, y_train) # 학습
y_pred = clf.predict(X_test) # 예측
print(f"{clf.__class__.__name__} : {accuracy_score(y_test, y_pred):.4f}") # 성능 측정 (정확도)Gradient Boosting Machine (GBM)
- Gradient Descent를 사용하여 loss function이 줄어드는 방향으로 weak learner들을 반복적으로 결합함으로써 성능을 향상시키는 boosting 알고리즘
- 이전 예측기가 만든 잔여 오차(Residual Error)를 예측하는 새로운 예측기를 만들고 학습시키며, 이전 모델의 잔차를 통해 약한 학습기를 강화함.
- 즉, 순차적으로 모델을 학습시키면서 각 단계에서 이전 모델의 오차를 줄이는 방향으로 새로운 모델을 추가하는 방식임.
- 계산 시간이 오래 걸릴 수 있고, 과적합 문제가 발생할 수 있음.
- 가중치 업데이트
- AdaBoost : 가중치를 단순히 증가 또는 감소
- GBM : 경사하강법
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import accuracy_score
X, y = make_moons(n_samples=500, noise=0.30, random_state=42) # 랜덤 데이터 500개 생성
X_train, X_test, y_train, y_test = train_test_split(X, y) # 데이터 분할
# GBM은 오차(잔차/Residual)를 줄이기 위해 이전 모델이 틀린 부분을 점점 보완하면서 모델을 쌓아가는 부스팅 알고리즘
# 잔차 기반 학습을 진행하는 알고리즘임.
clf = GradientBoostingClassifier(n_estimators=500, learning_rate=0.1) # GBM 객체 생성
clf.fit(X_train, y_train) # 학습
y_pred = clf.predict(X_test) # 예측
print(f"{clf.__class__.__name__} : {accuracy_score(y_test, y_pred):.4f}") # 성능 측정 (정확도)스태킹 (Stacking)
스태킹은 여러 개의 서로 다른 모델(베이스 모델)을 학습시키고, 그 예측 결과를 조합해 최종 예측을 만드는 방식이며, 이 방법의 핵심 요소는 Meta Learner이다.
Stacking은 여러 모델의 예측값을 새로운 입력으로 사용해서 또 다른 모델(Meta Learner)을 학습시키는 앙상블 방법이다. 개별 모델이 예측한 데이터를 다시 Meta dataset으로 사용해 학습한다는 컨셉의 접근법으로, Stacking을 위해선 개별 모델들(Base Learner)과 최종 모델(Meta Learner)이 필요하다.
이때, 스태킹에선 여러 예측기에서 각각 다른 값을 예측하면, 마지막 예측기에서 이 예측을 입력으로 받아 최종 예측을 수행한다.
스태킹의 장점은 다양한 모델의 강점을 활용하여 전체적인 성능을 향상시킬 수 있다는 것이며, 스테이지 0에서 k-폴드 교차 검증을 사용함으로써 과적합을 방지하고 견고한 성능을 보장할 수 있다.
스테이지 0 (Base Model)
- 여러 개의 서로 다른 모델(베이스 모델)을 k-fold Cross Validation을 통해 학습시킴.
- 각 폴드에서 베이스 모델은 검증 세트에 대한 예측을 수행함.
- 이러한 예측 결과를 모아 새로운 데이터셋을 만들고, 이러한 데이터셋은 메타 모델이 베이스 모델이 학습한 데이터를 직접 보지 않도록 하여 과적합 방지에 도움을 줌.
스테이지 1 (Meta Learner)
- 베이스 모델의 예측 결과로 구성된 새로운 데이터셋을 통해 메타 모델을 학습시킴.
- 메타 모델은 이 예측 결과를 조합해 최종 출력을 만듦.
Blending
- Stacking에서 k-fold 교차 검증을 생략하고, hold out 방식을 사용하는 방식
- Stacking에서 사용하는 k-fold 교차 검증을 생략하고, 데이터를 훈련-검증-테스트 세트로 나누어 각 ML 모델을 한 번씩 훈련시킨 후, 예측된 값을 사용해 메타 모델을 학습하는 방식 (즉 데이터를 Train / Hold-out / Test로 나누고 훈련된 모델을 Hold-out set에 대해 예측하여 Meta Feature를 생성함. 이후 이 Meta Feature를 입력으로 하는 메타 모델을 학습해 최종적으로 Test set에 대해 예측하여 결과를 생성함.)