[논문 리뷰] GraphNet: Learning Image Pseudo Annotations for Weakly-Supervised Semantic Segmentation
semi-supervised learning
Vision Task에서 가장 객체를 정밀하게 탐지할 수 있는 방법은 Segmentation이다. 그러나 Segmentation은 라벨링에 너무 많은 공수가 소요된다는 문제점이 있다. 객체의 외곽선을 따라 한땀한땀 점을 찍거나, 브러시를 이용해 정밀하게 객체를 색칠하는 과정을 거쳐야 segmentation 학습을 진행 할 수 있다.
그렇기에 높은 정밀도를 가진 Task임에도 불구하고 대부분의 산업 현장에서는 Object detection으로 대체하여 객체를 탐지하곤 한다. Weakly Supervised Semantic Segmentation(이하 WSSS)은 그러한 맥락에서 등장한 기법으로 classification label이나 bbox를 이용해 Segmentation을 수행하는 방법을 연구한 학문이다.
GraphNet은 2018년에 출판된 논문으로 WSSS를 그래프의 label propagation로 접근한 연구이다.
1. 연구 배경
1-1. Weakly Supervised Semantic Segmentation
WSSS는 유사도를 기반으로 정답을 알고 있는 픽셀의 이웃 픽셀의 라벨을 예측하는 문제이다. 아래의 그림을 예로 보면, 우리는 선홍색 박스 내부가 'Apple'임을 알고 있다. 선홍색 패치의 내부는 빨갛고 끝이 살짝 라운딩 되어 있다. 그리고 선홍색 패치의 오른쪽에 위치한 파란색 패치도 비슷하게 빨간색 객체와 라운딩된 외곽을 가지고 있다. 이 정보를 통해 우리는 우측의 파란색 패치도 동일하게 'Apple' 클래스임을 유추할 수 있다.

1-2. Graph based Label Propagation
Label Propagation은 특정 데이터의 클래스 정보를 기반으로 인접한 노드의 클래스 정보를 예측하는 문제이다. 아래의 그림을 예로 보면, 그래프에 10개의 노드가 있고 그 중 두개 노드의 클래스 정보가 결정되어 있다.
예를 들어 각 노드를는 사람, 엣지는 인맥, 파란색 노드는 '고등학생', 노란색 노드는 '대학생'을 의미한다고 가정하겠다. 파란색 노드와 그 주변 노드들은 동일한 학원을 다녀 인맥이 생성됐다고 본다면은 높은 확률로 주변 노드들도 '고등학생' 클래스일 것이다. 반대로 노란색 노드와 그 주변 노드들이 같은 동아리 활동을 하여 인맥이 생성됐다고 하면 높은 확률로 주변의 노드들도 '대학생'일 것이다.
이렇게 Label propagation을 통해 그래프에서 특정 클래스의 정보와 주변 관계(유사도)를 기반으로 새로운 노드의 클래스를 유추할 수 있다.
1-3. 다시 처음으로 돌아가서
위의 WSSS와 Label propagation이 뭔가 유사하지 않은가? 아래와 같이 써보면 더 명확할지도 모르겠다.
이미지에서 특정 패치의 클래스 정보를 이용하여 인접한 다른 패치의 클래스 정보를 예측한다.
그래프에서 특정 노드의 클래스 정보를 이용하여 인접한 다른 노드의 클래스 정보를 예측한다.
이미지와 그래프, 패치와 노드라는 단어만 제외하면 둘은 거의 유사한 Task라고 볼 수 있다. 그렇기에 본 논문의 저자는 이 두 Task를 유사하다고 보았고, Graph의 Label Propataion 방법론을 이용하여 이미지의 WSSS를 수행할 수 있다고 판단하였다.
아주 합리적인 생각이다. 다만 이를 위해 넘어야할 벽이 몇가지가 있다.
- 문제 1. Label Propagation을 진행하기 위해서는 그래프 구조를 만들어야하는데, 어떻게 이미지를 그래프 구조로 바꿀거야?
- 문제 2. 각 노드 간의 유사도를 계산해야할텐데 이미지 픽셀 간의 유사도는 어떻게 계산할거야?
- 문제 3. 위 단계를 통해 어떻게 마스크를 생성할거야?
이제 논문에서 각 벽을 어떻게 뚫었는지 하나하나 설명해보도록 하겠다.
2. 라벨 포맷
- Weak labels
- Scribble Annotations
- Bounding Box Annotations
논문에서는 두 가지 라벨에 대해서 테스트 하였으나, 결과를 먼저 말하면은 BBOX 라벨일때의 결과가 매우 좋지 못하다. 그렇기에 본 포스팅에서는 설명의 용이를 위해 scribble 라벨 위주로 설명을 진행하도록 하겠다.
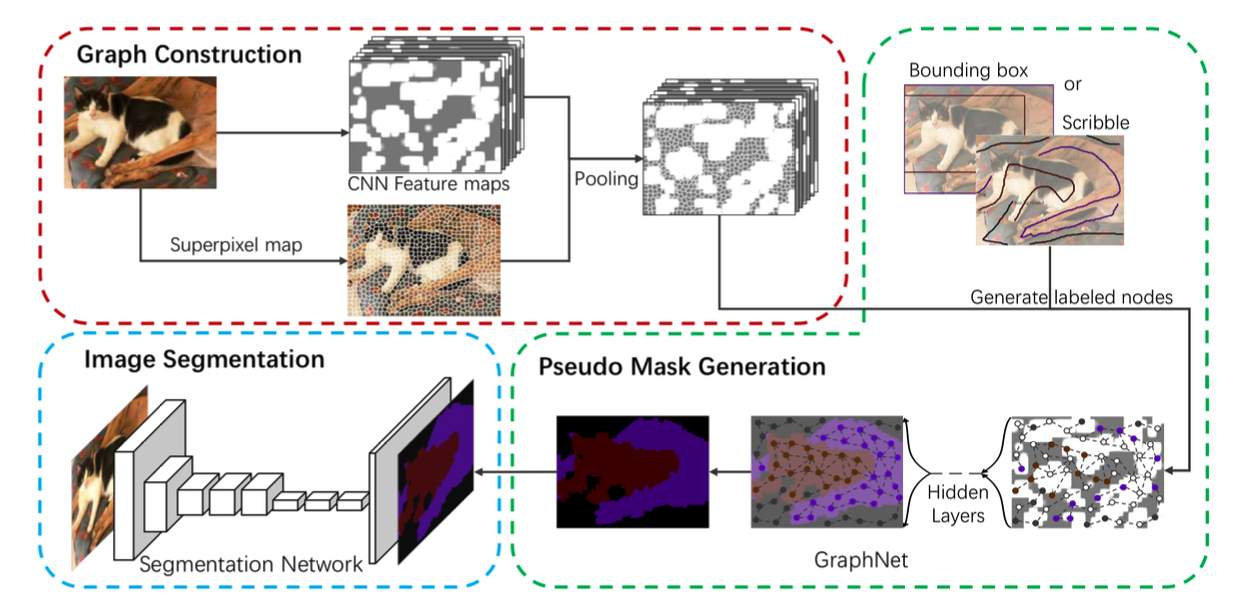
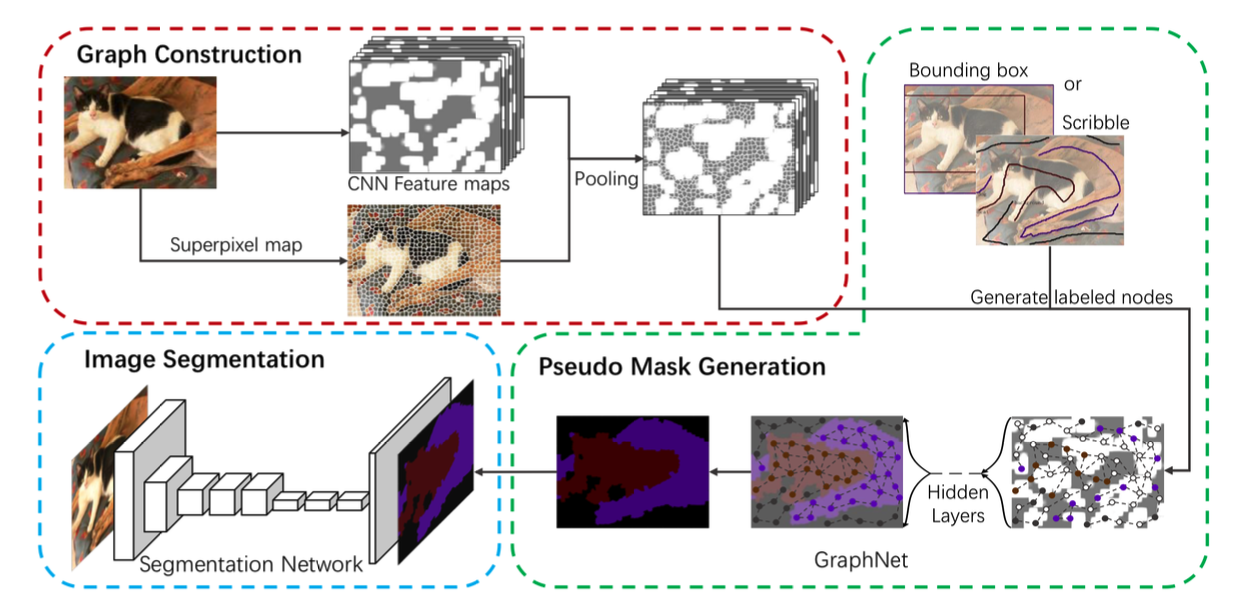
3. GraphNet Architecture
GraphNet은 크게 3단계로 구성된다. 각 단계의 하위 단계까지 고려하면 4단계라고 보는것이 맞기도 하겠다.
- 그래프 구축
- 노드 구축
- 엣지 구축
- 그래프 신경망을 이용하여 Pseudo Mask 생성
- Segmentation 모델을 이용하여 정밀 마스크 생성
Segmentation 모델에 학습 시키는 3단계를 제외하면 본 논문의 핵심은 1, 2단계를 어떻게 수행하느냐이다.
3-1. Graph 구축
본 논문에서는 superpixel을 이용하여 그래프를 구축하였다. 좀 더 상세히 말하자면 본 논문에서 제안하는 그래프의 노드는 이미지의 superpixel이고 엣지는 각 superpixel의 spatial 및 feature 유사도이다. 전체적인 그래프 생성 flow는 아래와 같다.
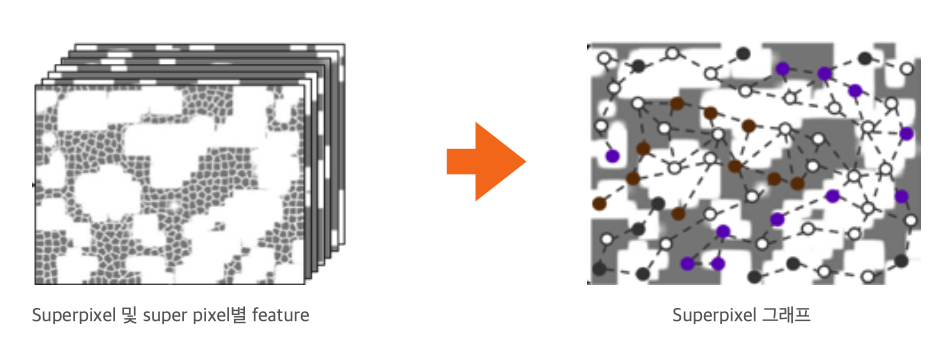
- 이미지의 superpixel 생성
- Backbone 네트워크를 이용하여 이미지의 feature 추출
- 1과 2의 결과를 elementwise product하여 superpixel의 feature 생성
- superpixel의 spatial 정보와 feature 정보를 함께 고려하여(dual constraints) 그래프 생성
말들이 참 어려운데 최대한 하나하나 차근차근히 설명해보겠다.
3-1-1. Node 생성
위의 그래프 생성 flow 중 1번부터 3번 과정까지가 Node와 그 feature를 생성하는 과정이다. 앞서 언급했듯, 본 연구에서는 이미지의 superpixel을 노드로 본다.
superpixel이란 의미론적으로 비슷한 영역을 하나의 거대한 픽셀로 보는 것을 말한다. 아래 그림과 같이 색상 정보가 유사한 주변의 픽셀들을 하나로 묶어 슈퍼픽셀을 생성한다. 슈퍼픽셀은 대게 SLIC알고리즘을 통해서 생성되며 몇개의 슈퍼픽셀을 생성할지 갯수에 대한 파라미터를 제공해야한다. 이때, 슈퍼픽셀의 갯수를 많이 할수록 좌상단과 같이 촘촘한 슈퍼픽셀이 생성되고 갯수를 적게 할수록 우하단과 같이 덩어리가 큼직한 슈퍼픽셀이 생성된다.

노드를 생성했다! - superpixel map
만약 scribble을 이용해 라벨링을 해줬다면은 scribble이 통과하는 슈퍼픽셀 노드는 해당 클래스로 라벨링한다.
이렇게 노드가 생성되고 나면 다음 단계는 노드 간의 유사도를 계산할 feature 정보를 구할 차례이다. 본 논문에서는 VGG-16 network를 사용하여 feature를 추출하였다. Deep Learning Network에서는 layer가 deep 해질수록 더 semantic한 정보를 추출하기 때문에 본 연구에서도 마지막 layer에서 추출된 feature를 사용하였다.
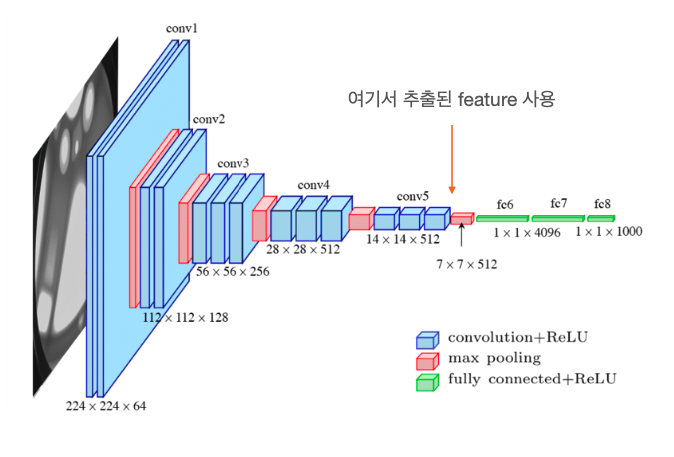
노파심에 하는 말인데 여기까지 설명을 들은 내 동료 중에서 "슈퍼픽셀로 분할된 이미지를 어떻게 신경망에 학습해?"라는 질문을 한 분이 있다. 아주 큰 오해가 있었던듯한데, feature를 추출할 때는 원본 이미지를 그대로 넣고 feature를 추출하는거다.
이미지의 feature를 생성했다! - VGG 16 feature
노드 생성의 마지막 과정은 이렇게 만들어진 슈퍼픽셀 노드와 VGG feature를 이용하여 슈퍼픽셀의 feature값을 획득하는 것이다. 아래의 그림처럼 생성된 Superpixel map과 VGG 16의 feature map(아래 그림의 CNN feature maps)를 elementwise product하여 각 슈퍼픽셀의 feature를 생성한다.
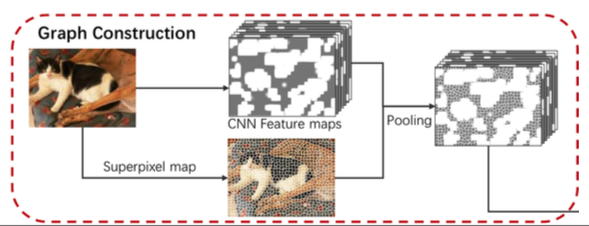
슈퍼픽셀의 feature를 생성했다!
3-1-2. Edge 생성
본 논문에서는 2가지 프로세스를 거쳐 엣지를 생성한다.
이미지 내에서 위치 상 가까운 슈퍼픽셀은 서로 연결되어 있다고 가정한다.
이미지 내에서 feature 정보가 유사한 슈퍼픽셀은 서로 연결되어 있다고 가정한다.
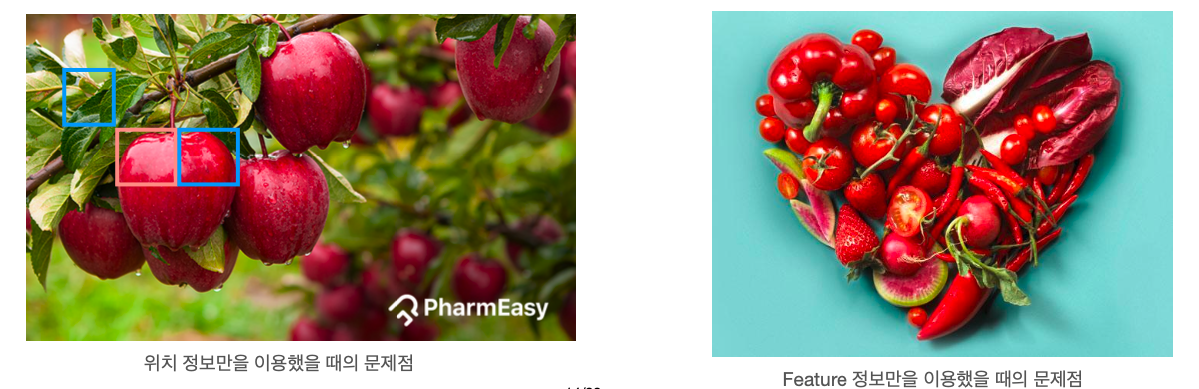
만약 위치 정보만을 가지고 엣지를 만든다면은 위의 그림에서 왼쪽과 같은 케이스에서 낭패를 볼 수 있다. 선홍색 패치 좌상단에 위치한 파란 패치는 분명 'apple' 클래스의 패치와 인접해있음에도 불구하고 다른 클래스를 가진다. 즉 경계면의 segment를 부적절하게 추출할 가능성이 있다.
반대로 feature 정보만을 가지고 엣지를 만든다면 위의 그림에서 오른쪽과 같은 케이스에서 낭패를 볼 수 있다. 이미지의 모든 객체들이 붉은 색의 과일 또는 채소이다. 만약 feature 정보만을 이용한다면 좌측 상단은 파프리카와 하단의 작은 방울토마토를 동일한 객체로 분류하는 불상사가 발생할 수 있다.
엣지 구축 시 두 가지 정보를 사용해야하는 필요성에 대해서는 여기까지만 이야기하고 실제로 엣지를 어떻게 구축하는지에 대해 이야기 해보자. 엣지 구축 시에는 먼저 spatial한 정보를 이용한다. 즉, 물리적으로 가까운 슈퍼픽셀간에 연결관계가 있다고 먼저 가정한다.
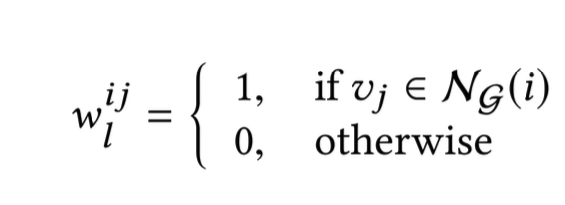
위의 식과 같이 특정 슈퍼 픽셀에서 인접해있는 픽셀 간에 연결 관계가 있다(w를 1로 설정)고 설정하였으며, 인접하지 않은 경우에는 연결 관계가 없다(w를 0으로 설정)고 설정하였다.
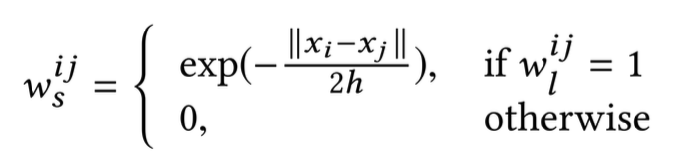
이후 슈퍼픽셀간의 feature 정보를 고려하여 엣지의 가중치를 업데이트 해준다. 식은 위와 같으며 두 픽셀이 유사하면 가중치가 커지고 유사하지 않으면 가중치가 작아지는 형태이다. 이러한 방식으로 이미지를 기반으로 WSSS용 그래프를 생성할 수 있다.
그래프의 엣지를 생성했다!
3-2. Graph Convolutional Network
3-1의 과정을 거쳐 그래프를 생성하고 나면 GCN(Graph Convolutional Network)을 이용하여 Semi supervised classificaiton을 진행한다. 앞서 말했듯이 scribble이 통과하는 노드는 해당 클래스로 이미 라벨링 되어 있는 상태이므로 Label Propagation 과정을 거치며 물리적으로나 특징적으로 유사한 주변 노드를 해당 클래스로 할당한다.

이에 대한 자세한 설명은 위의 그림을 참고하면 된다. a는 scribble을 이용하여 라벨링을 한 결과이고, b는 이미지를 슈퍼픽셀로 분할한 결과이다. 그리고 c는 scribble이 통과하는 슈퍼픽셀을 해당 클래스로 할당한 결과이다. 마지막으로 d는 구축된 그래프에 GCN을 거쳐 최종적으로 생성된 Pseudo Mask이다.
4. 실험 결과
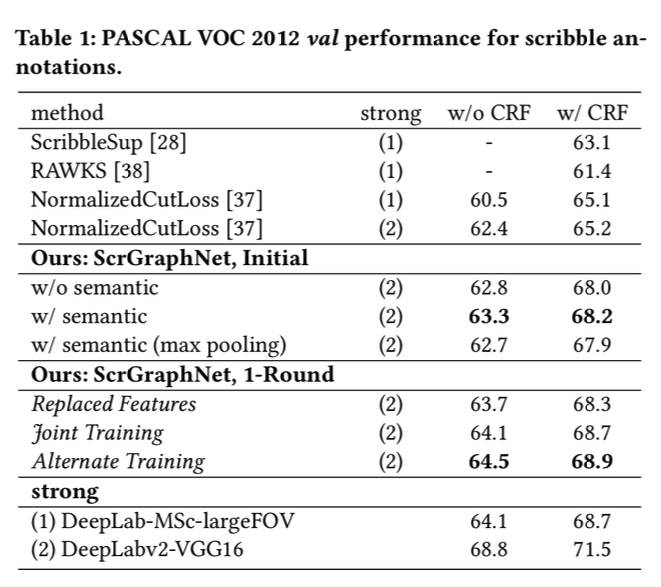
위의 표는 본 논문에서 제안하는 GraphNet과 다른 WSSS 모델들, 그리고 Fully Segmentation모델인 DeepLab v2(논문에서는 strong model로 표현)의 분할 성능을 비교한 표이다. GraphNet initail은 본 아키텍처만을 이용해서 만든 Psuedo 마스크로 측정한 성능이고, GraphNet 1-Round는 Psuedo 라벨을 이용하여 DeepLab 모델에 한 번 학습 시킨 후 생성된 마스크로 측정한 성능이다.
표에서 알수 있듯이 GraphNet이 다른 WSSS모델들(ScribbleSup, RAWKS등)에 비해 더 좋은 성능을 보임을 알 수 있다. 또한 1-Round 모델의 경우, Strong 모델인 DeepLab보다 성능이 좋음을 알 수 있다. 다만 더 상위 모델인 DeepLab v2에 비해서는 좋은 성능을 보이지는 못했다.
그럼에도 불구하고 마스크 라벨 없이 strong 모델과 비슷한 성능을 보인다는 것 자체가 매우 고무적인 결과라고 볼 수 있다.
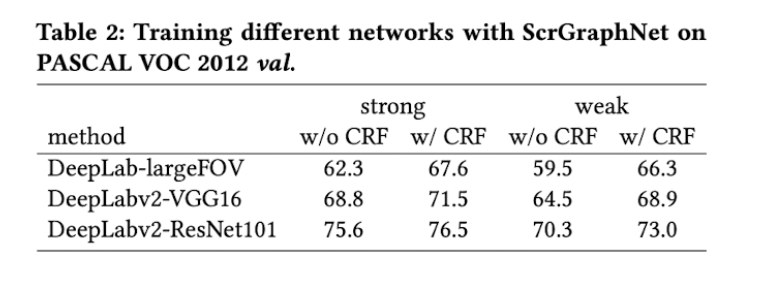
위의 표는 VGG 16 대신 다른 백본을 이용하여 이미지의 feature를 추출하였을 때 성능 변화이다. VGG 16에 비해 Resnet101을 사용하였을 때 더 좋은 성능을 보임을 확인할 수 있다. 이 결과를 보면서 '이미지 피처 추출용 백본을 timm에서 제공하는 최신의 classification모델로 변경한다면 성능이 더 개선될 수 있지 않을까?' 라는 생각이 들었는데, 언젠가 기회가 된다면 구현을 해봐야겠다.
추가로 1-Round용 학습 모델로 DeepLab 아키텍처에 비해 DeepLab v2 아키텍처를 사용하였을 때, segmentation 성능이 좋음을 확인하였다.(어찌보면 당연한 결과이다.) 이 또한 2023년 기준 DeepLab 계열 중 최신 모델인 DeepLab v3 +를 사용한다면 성능이 더 개선될 것이라고 기대해본다.

위의 그림은 strong 모델과 graphnet의 결과를 비교한 이미지이다. 객체 가장 자리 부분의 디테일에서 다소 차이가 있지만 strong 모델과 매우 유사한 수준의 마스크를 생성함을 알 수 있다. 나의 개인적인 사견으로는 이를 바로 프로덕트에 탑재하기는 무리겠지만 라벨링 툴로써 이런 기능이 있다면 기꺼이 사용할만한 수준이라고는 판단된다.

추가로 성능이 좋지않아 설명에서 누락했던 bbox graphnet의 결과 이미지이다. 말, 사람, 오토바이 등 strong 모델과 scribble graphnet이 잘 탐지한 객체에 대해서 상대적으로 낮은 정확도를 보여줌을 확인할 수 있다.
바운딩 박스 기반 모델이 성능이 낮은 이유는 박스 내부에 다른 객체의 정보가 섞여 들어가기 때문이다. 예를 들어, 세번째 줄의 말을 타고 있는 사람을 바운딩 박스로 라벨링 한다면, 박스 내부에는 약간의 배경과 말 등 부분이 포함되게 된다. 이러한 정보의 중첩이 graphnet의 성능을 저하시킨다.
5. 마치며
대학원때 열심히 공부했던 그래프가 비전 task에서도 쓰이는 사례가 궁금했었는데 좋은 케이스를 발굴했다. 2018년에 쓰인 논문이다 보니 현재(2023년 9월)를 기준으로 성능이 만족스럽지 못하지만 실험에 사용된 아키텍처나 모델만 보완한다면 충분히 좋은 성능을 보일 것이라 생각된다.
최근 SAM이 나오면서 WSSS 연구가 그쪽으로 완전히 넘어가버렸다. 하지만 공정 데이터, 의료 데이터 등에서 확인하였듯이 SAM도 완벽한 zero-shot 성능을 보이지는 않는다. 이럴 때, 기존의 WSSS 방법론과 SAM이 만난다면 더 높은 수준의 WSSS 모델을 만들 수 있을 것이라 생각한다.
추가로 그래프의 엣지를 정의하는 방식이 꽤나 납득이 가지 않긴하다. 저런 식으로 인접한 노드끼리만 엣지를 정의하게 되면 엣지 정보가 부족해지기 때문에 propagation의 성능을 충분히 보장하지 못한다. 때문에 Graph Construction 방법만 보완한다면 더 좋은 성능을 보일 것이다.
