Index Nested Loops Join (INL)

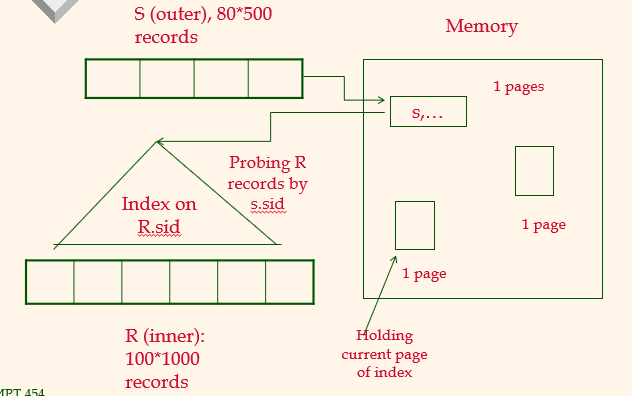
INL (sid is key in S)
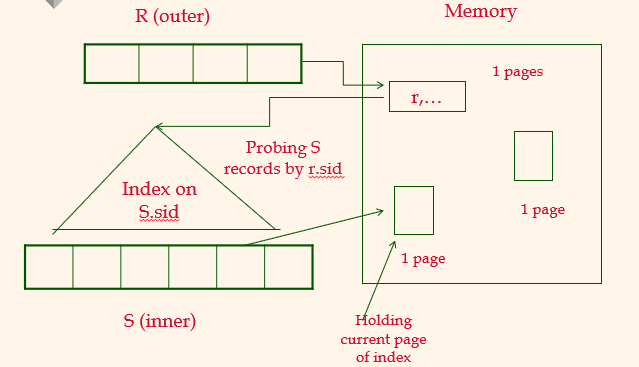
R에 있는 record 마다 probing을 하게된다. \
Hash-index (Alt. 2) on sid of R


100,000 = total number of R record
40,000 = total number of S record
2.5는 평균적으로 matching되는 record 개수이다.
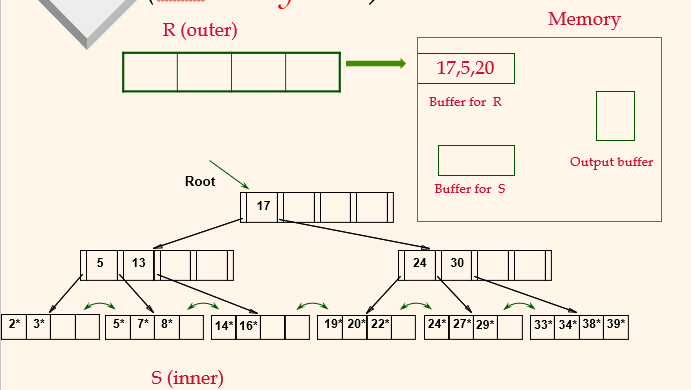
INL (sid is not a key in R)
index 있는 것을 inner로 index 없는 것을 outer로 하면된다.
Sort-Merge Join (SM)

Example of Sort-Merge Join (on sid)

sid를 기준으로 s 테이블과 R 테이블 모두 external sorting 된 상태이다.
R is scanned 2 times (bad)

처음 s에서 두 페이지를 가져오고 R에서 두 페이지를 가져오면 ((2,2), (2,2)) 그리고 ((2,2),(2,2))일 것이다. 그렇게 R을 쭉 읽고, 다음에 (2,2)가 s에 남은게 있으니 그걸 가져와서 R을 또 쭉 읽는다.
R is scanned three times (worse)
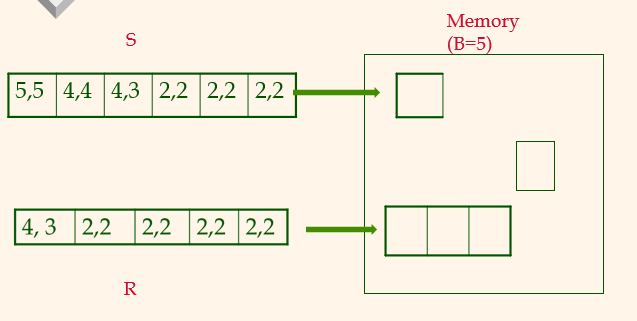
R is scanned once (good)
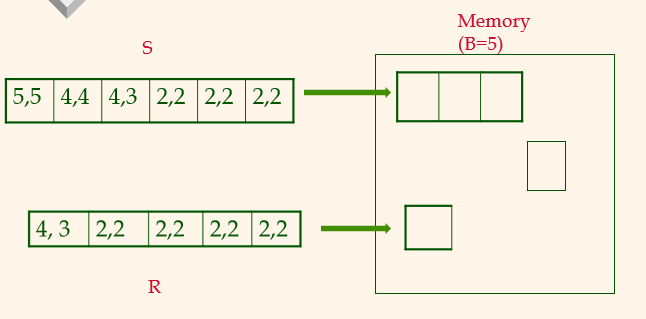
여기서 보면 (2,2) 개수가 s가 더 적고 r이 더 많다. 더 작은 것을 outer에 놓고 outer에 buffer page 개수를 많이 놓는 것이 유리하다.
Cost of SM

assume no repeated scan의 뜻은 memory가 충분히 크다고 가정해서, 각각 테이블이 한번씩만 scan되는 것이다.
메모리가 35page, 100, 300page인 각각 시나리오다. 이 각각 의 메모리 사이즈 일지라도 2 pass에 가능하다. Then this two table both can be sorted in 2 passes. pass 0 is generating run and pass 1 is merge.
Refinement of Sort-Merge Join



정확히 말하면 B=4가 아니라 B=5다. output buffer에서 1이 필요하다.
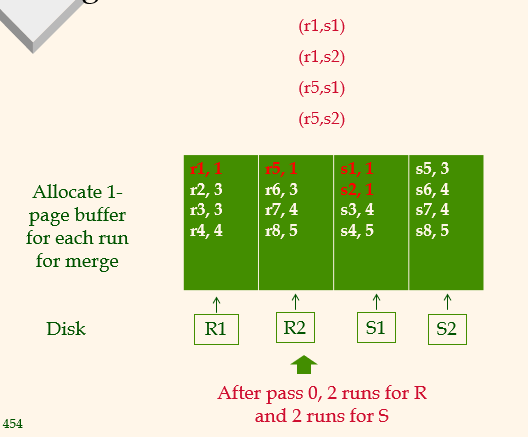
Merge 4 runs in One Pass
Hash-Join


