CMPT 454
1.[CMPT 454] Week 1_1
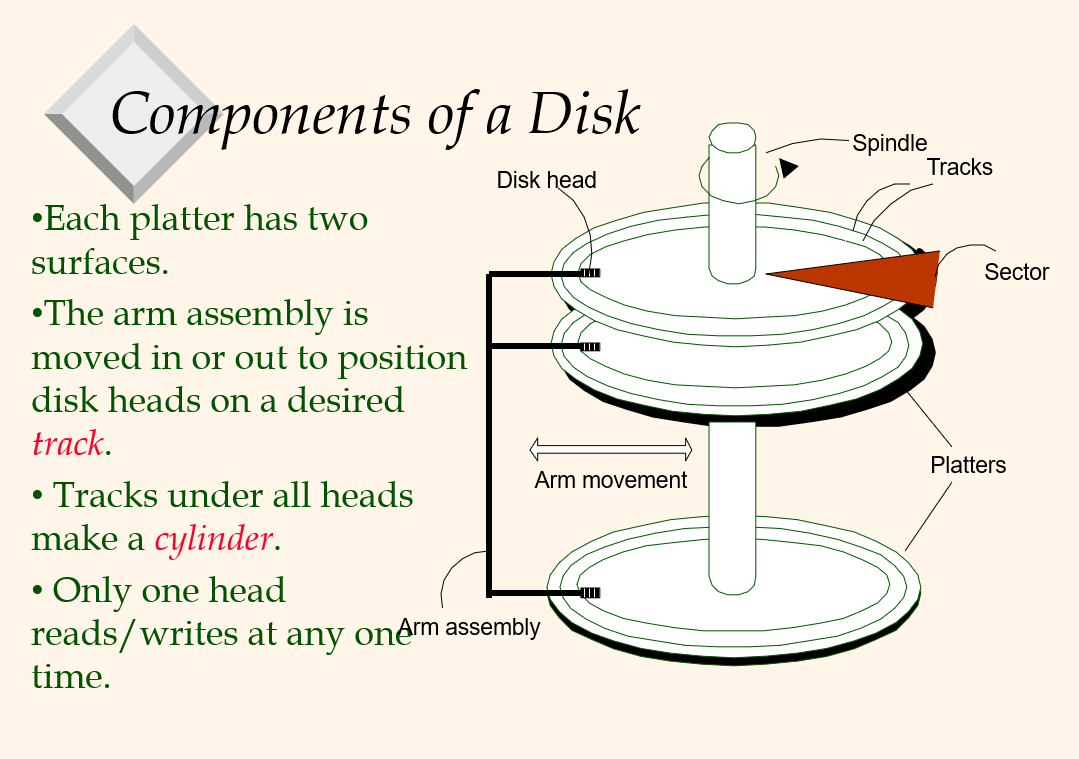
Why not store everything id main memoery? \- Costs too muchMain memory is volatile to power off. Typical storage hierarchy:Main memory for currently
2.[CMPT 454] Week 1_2
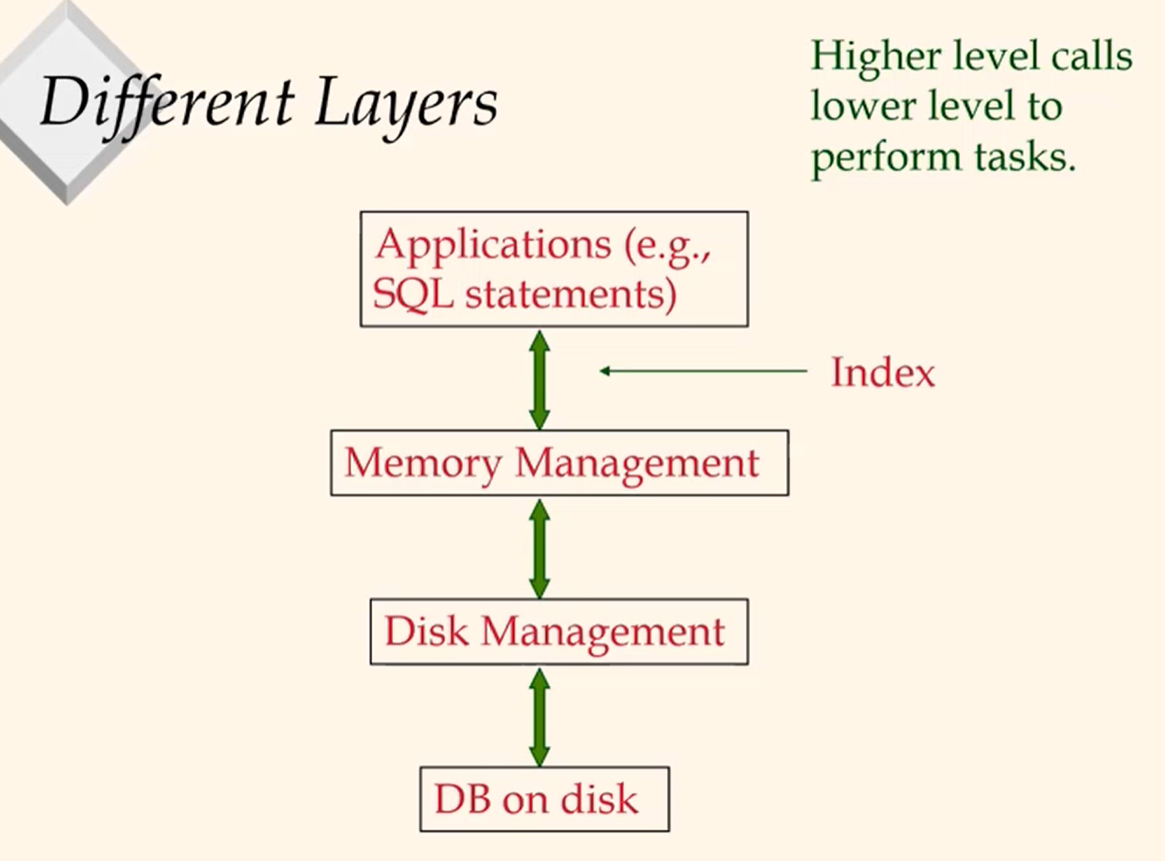
'Next' page concept: Pages on same track, foloowed by pages on same cylinder, followed by pages on adjacent cylinder.Pages in a file should be arrang
3.[CMPT 454] Week 1_3
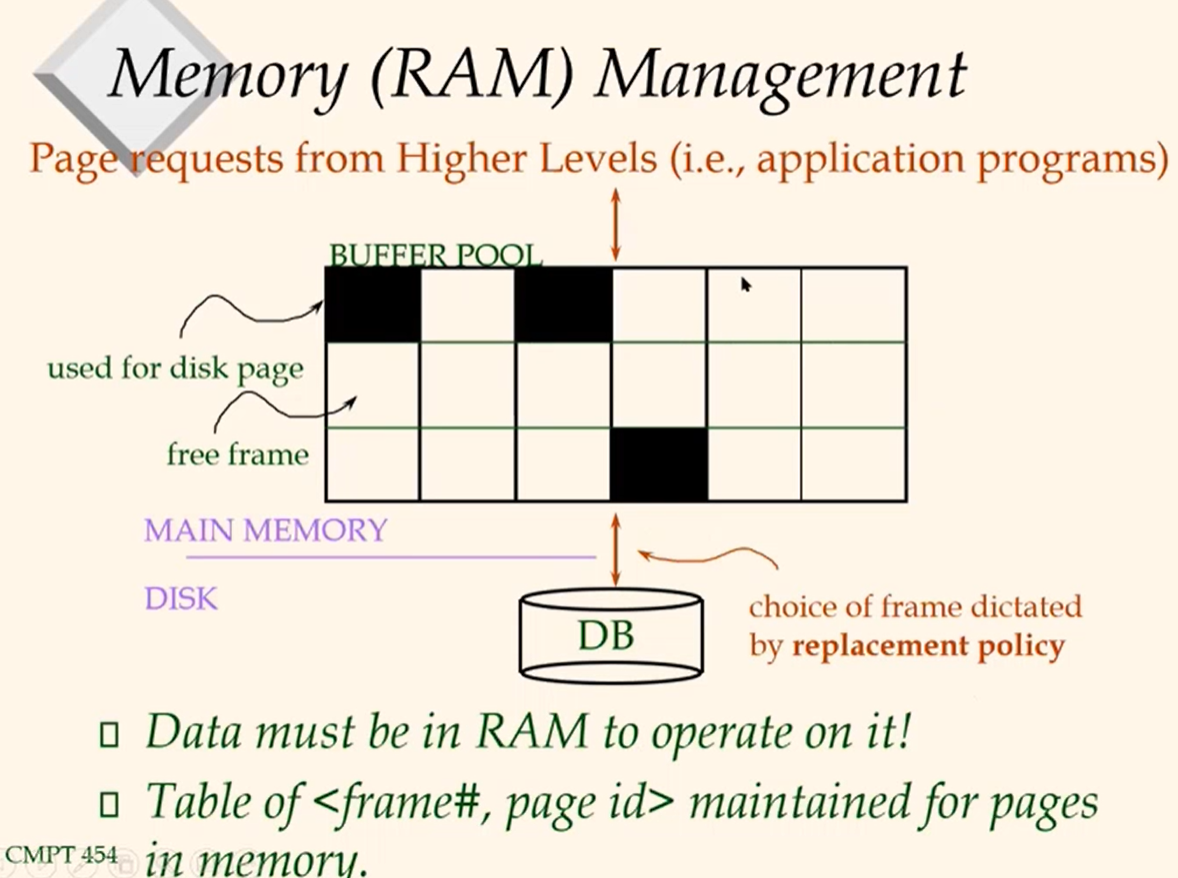
Frame is chosen for replacement by a replacement policyIdeas: choose frame that least likely will be used in future, e.g., FIFO, least-recently-used(L
4.[CMPT 454] Week 2_1 - Concept of Indexing
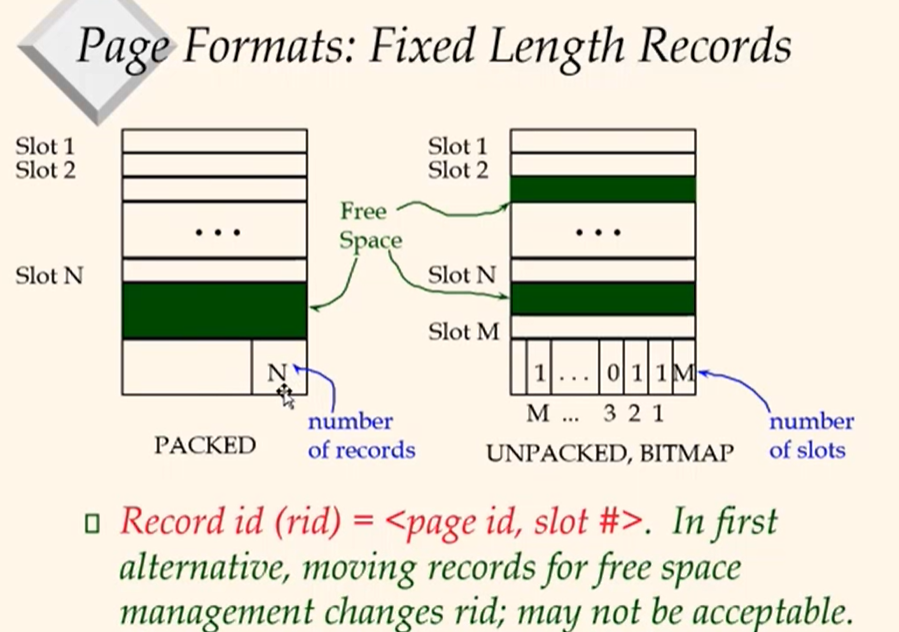
When delete the record, all the offset at bottom would be changed. By deleting it, the grey area would get bigger. Rid would not be changed.Files as a
5.[CMPT 454] Week 2_2
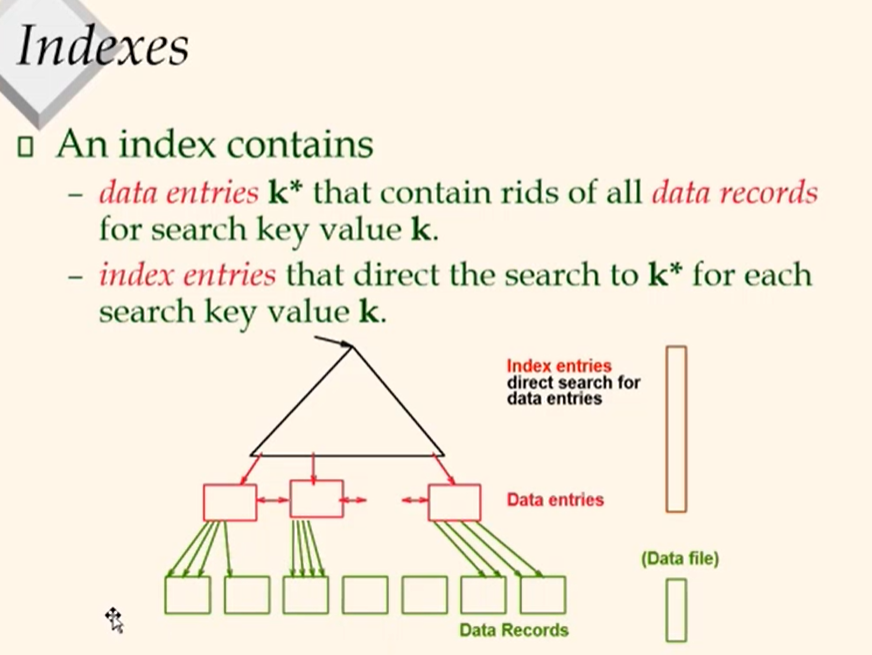
Indexing Alternatives for Data Entry k*
6.[CMPT 454] Week 2_3
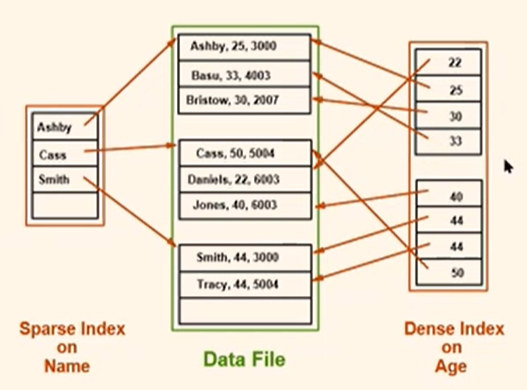
Dense vs. Sparse: If there is at least one data entry k\* per search key value k, then dense. \- Alternative 1 leads to dense index \- Every sp
7.[CMPT 454] Week 3_1 - B+ Tree
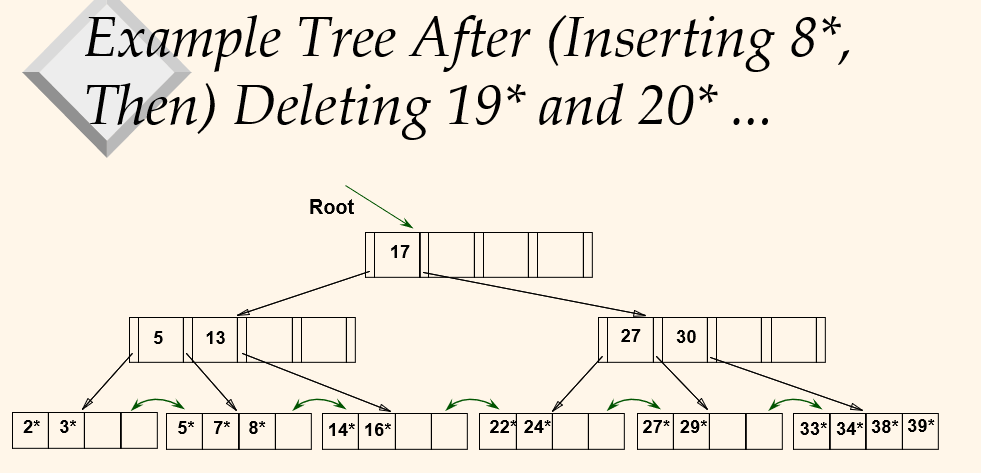
Keep tree height-balanced. Search/insert/delete at log_f N cost(F = fanout (F is branch factor), N = - Minimum 50% occupancy(except for root). Each no
8.[CMPT 454] Week 3_2
Start at root, find leat L where entry belongsRemove the entryIf L is at least half-full, done!Otherwise, L has only d-1 entries,Try to re-distribute,
9.[CMPT 454] Week 3_3

여기서 h(r) = 5 = binary 101이면 global depth가 2이니 마지막 뒤 두자리만 봐서 01이 가리키는 bucket B로 간다.이 상태에서 20을 넣으려면 20은 (10100)이니 끝자리 두개를 보면 00인데 bucket A가 꽉 찼다. globa
10.[CMPT 454] Week 4_1
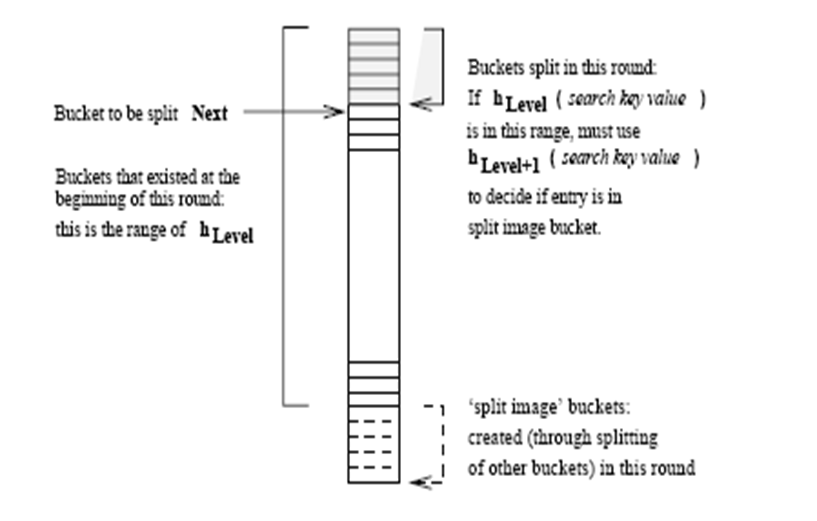
Linear Hashing
11.[CMPT 454] Week 4_2

Hash-based indexes: best for equality searchs, cannot support range searches.Static Hashing can lead to overflow chains.Extendible Hashing avoids over
12.[CMPT 454] Week 4_3 - External Sorting
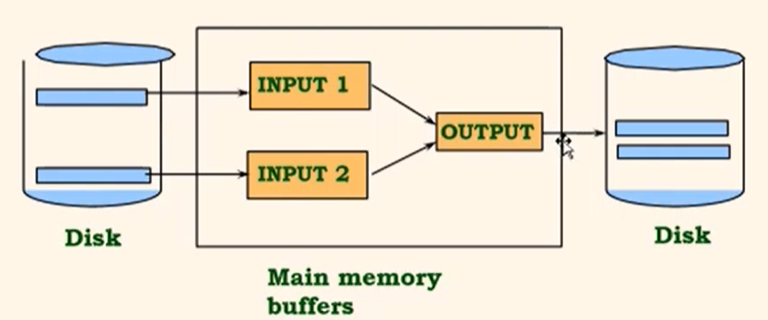
The Problem: sort 100Gb of data with 100Mb of RAMThe file is stored on disk and too large for any in-memory sorting methods.Cost model: I/O pages.A cl
13.[CMPT 454] Week 5_1
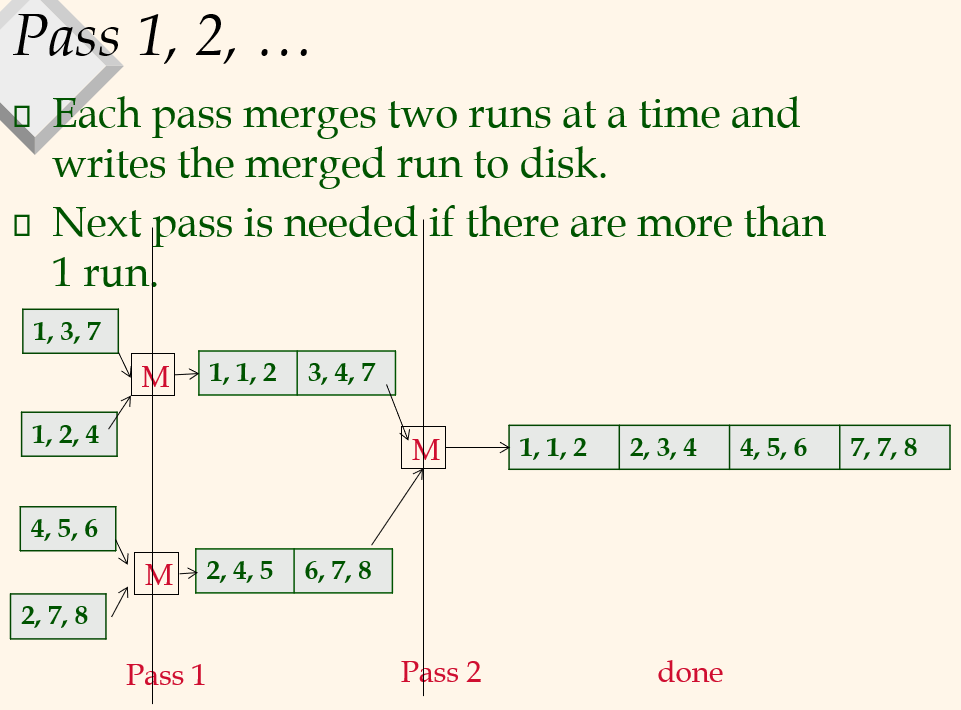
If pages are sequentially stored on disk, I/O time per page can be reduced by having larger (b>1) input buffer.read b pages with 1 seek time and 1 rot
14.[CMPT 454] Week 5_2 - Join (Simple Nested Loop Join)
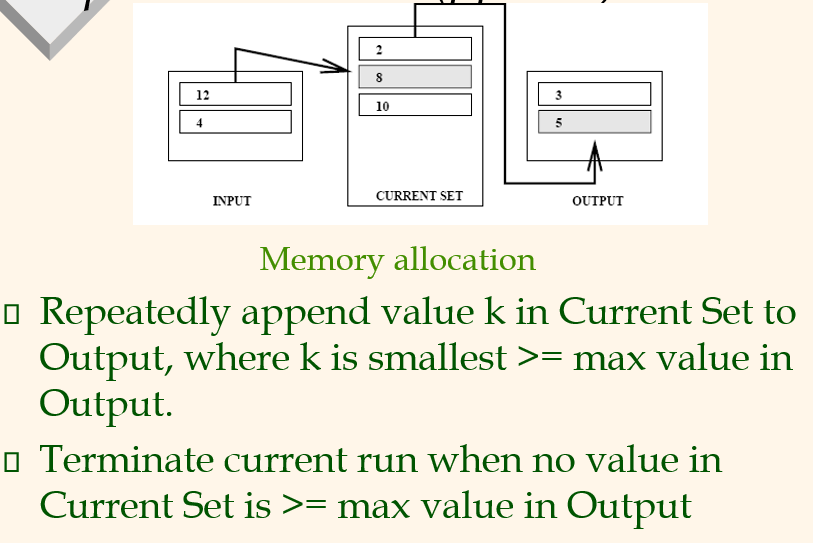
current set에서 ouput의 max value인 5보다 크면서 가장 작은 값은 8이다. 그래서 8을 붙이고 그다음은 input에서 12가 오지만, 8보다 크면서 가장 작은 값은 10이니 10이 온다. 처음에는 current set에서 1을 output으로 옮긴
15.[CMPT 454] Week 5_3
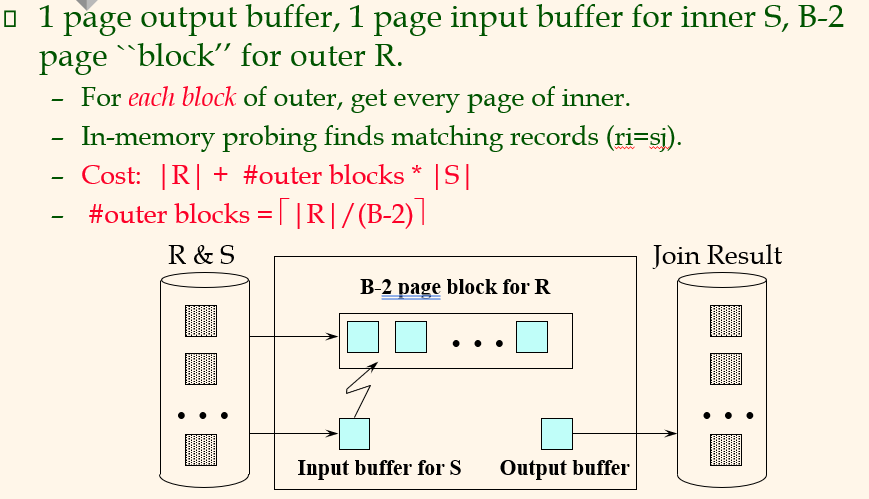
메모리에 2-page block for outer이므로 1 block, 즉 여기서는 2 page씩 읽어 들인다. outer 페이지를 읽는데 I/O가 바뀌지는 않지만, inner가 outer마다 반복을 해야하는 것에서 I/O가 많이 줄어든다. 예전에는 610 이었지만 2
16.[CMPT 454] Week 7_1

R에 있는 record 마다 probing을 하게된다. \\100,000 = total number of R record40,000 = total number of S record2.5는 평균적으로 matching되는 record 개수이다. sid를 기준으로 s 테이블
17.[CMPT 454] Week 7_2

join- phase에서 Ri는 크기가 메모리보다 작지만 si는 메모리보다 크다고 가정한 것이다. 둘다 메모리보다 한참 작으면 둘다 메모리에 올릴 수 있다. Nested loop join때와 비슷한 상황이다.만약 둘다 메모리보다 크다면 partition을 또 해야한다.
18.[CMPT 454] Week 7_3

clustered에서1000 \* 0.1인 이유는 10%가 matching term이기 때문이다. unclustered에서는한 rid를 follow해도 1개의 record만 얻을 수 있다. 10\*0.1인 이유는 전체 data entries의 개수가 10개이기 때문이다
19.[CMPT 454] Week 8_1

Option1 : "retrieved"라고 강조한 이유는 이미 I/O로 읽은 상태에서 걸러내는 것이기 때문에 I/O가 줄어들지는 않는다. 시험이나 과제에서는 (RF)ReductionFactor가 주어진다 여기서는 하나의 쿼리만 이용했다.<pageId, slot n
20.[CMPT 454] Week 8_2
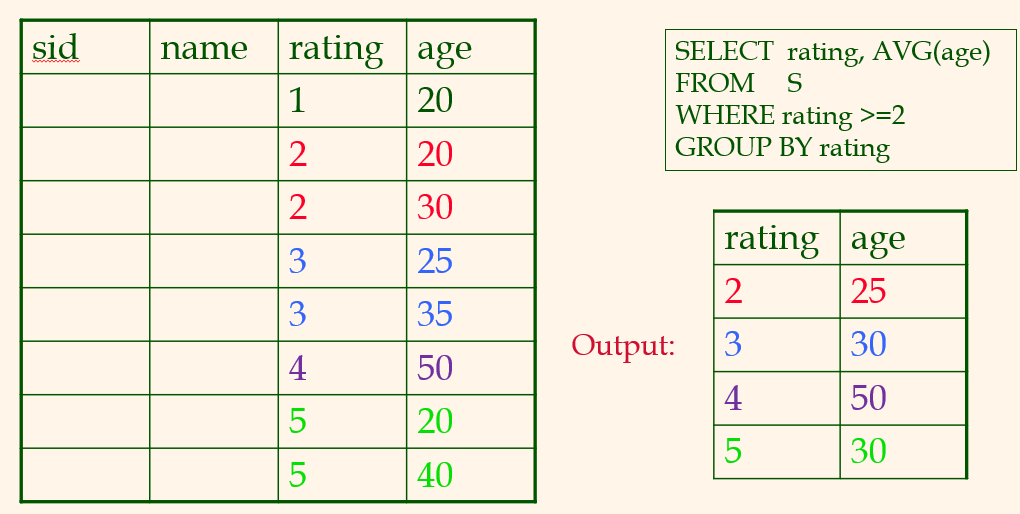
without grouping:group by가 없다면 avg를 한번만 구하면된다. rating과 age만 있으면 되므로, index-only를 써야한다.with group:index only, but sorting is neededrating을 기준으로 sorting
21.[CMPT 454] Week 8_3

To enusre correctness for concurrent execution of queries and updates from multiple users.T1T2는 concurrency가 없었을 때 상황을 나타내는 표시이다.결과는 다르지만 acceptable하다
22.[CMPT 454] Week9_1 - ACID

commit이 디스크에 write하는 것이 아니다. 커밋할 때마다 disk에 write하면 performance가 떨어진다. 다만 commit하면 그것을 기억할 방법이 있어야한다.T1T2 와 T2T1은 serial schedule이다.T1T2에서 W2(B)는 R2(B)
23.[CMPT 454] Week9_2

Transaction 1이랑 Transaction2는 완전히 별개다? R1(B)와 R2(B)에 전혀 영향을 미치지 않는다. R1(B)이후 B-100 해도 W 하지 않으면 R2(B)에 영향 미치지 않는다. 메모리에 separated된 공간에 있다. W1(B)이후 R2(B
24.[CMPT 454] Week9_3
제일 처음 예를 보면, R2(A)는 W1(A)를 읽어서 depends on 하지만, after T1 commit이다. 따라서 recoverable이다.마찬가지로 T2는 T1에 depends on 하고 T2의 commit은 T1의 commit 다음이다. 세 번째에서는 아
25.[CMPT 454] Week10_1

W1(A)다음 W2(A)이므로 T1 -> T2 이고 W2(B) 다음 W2(B)여서 T2 -> T1이다. Cycle이 있으므로 not serializable. 첫번째 막대기 이후는 T1이 shrinking 한다. 첫 막대 이전에 T1은 필요한 lock을 다 얻었다. 두번
26.[CMPT 454] Week10_2

C.C = Concurrency Control38\*을 찾는다고하면 처음 A (20)을 lock하고 그다음 B만 필요하다는 것을 안다. 그다음 B를 lock하고 A를 release한다. 그다음 C가 필요하다는 것을 알고 C를 lock 하고 B를 release한다. 그
27.[CMPT 454] Week10_3
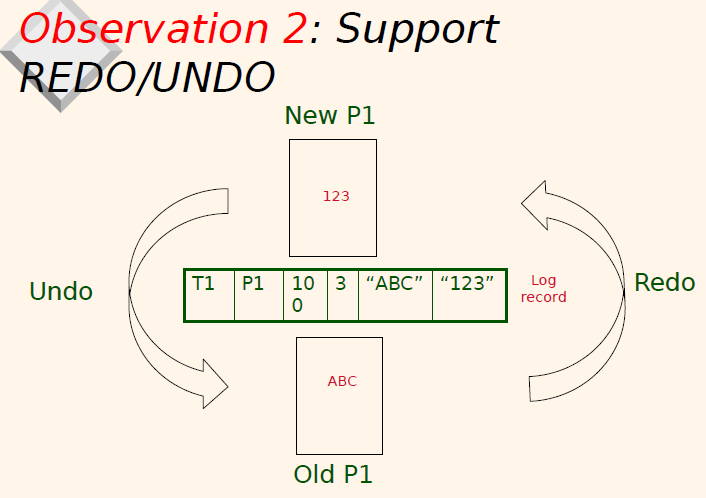
T1 update A는 메모리에만 일어나고, disk에는 바뀌지 않으므로 dirty page다.T2 update C도 마찬가지다.T1 update A (steal)은 write to the disk이다. steal은 steal from memory page A and
28.[CMPT 454] Week11_1

맨 마지막 TT에 (T2, U, 160)이 들어갈 것이다. 만약 (150, T1, End)가 없다면 (140, T1, Commit)이 있을 것이다. 뒤뒤 transaction commits 참조.Write LSN을 하는 이유는 crash 됐을 때 checkpoint 기
29.[CMPT 454] Week11_2

system crash는 memory는 날라가고 disk는 괜찮은 상황을 말한다.120까지 봤을 때 100만 disk에 쓰지 않았으므로 dirty table에 남아있다.그다음 140이 disk에 write하므로 dirty table은 비워져야한다.steal은 log에
30.[CMPT 454] Week11_3
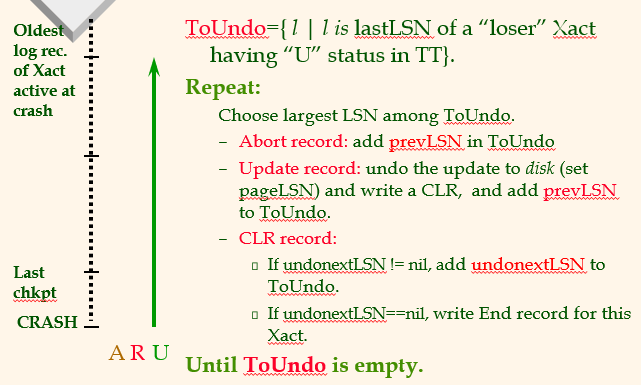
Transaction table은 after analysis와 redo 이후 만들어진 것이다. 여기서 Status에서 C가 아닌 것들만 ToUndo에 있다.190은 180에서 abort이기 때문에 T1의 가장 최근 것을 undo 중이었다.Undo Phase 알고리즘에
31.[CMPT 454] Week12_1

Effect of CLR > CLR represents UNDO. The Effects of CLRs > 140: T1 CLR LSN 130은 130을 UNDO 했다는 것이다. 150은 120을 UNDO 했다는 것이고 160은 110을 UNDO한 것이다.
32.[CMPT 454] Week12_2
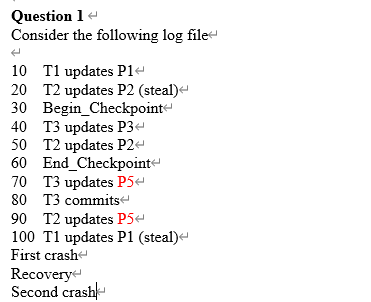
for all the actions you must update the transaction table.for dirty page table, you update for "update" record.Beign Checkpoint까지만 테이블을 만들면된다.DPT에서 p5
33.[CMPT 454] Week13_2

T1:R(X), T2:R(X), T1:W(X), T2:W(X)Serializable:T1T2또는 T2T1에 해당하는지 봐야한다.T1T2가 될 수 없다. 왜냐하면 R2(X)는 initial value를 읽기 때문이다. T1T2에서는 W1(X)를 R2(X)가 읽는다. T2