Multiple Indexes

Most selective access path

Option1 : "retrieved"라고 강조한 이유는 이미 I/O로 읽은 상태에서 걸러내는 것이기 때문에 I/O가 줄어들지는 않는다.
시험이나 과제에서는 (RF)ReductionFactor가 주어진다
여기서는 하나의 쿼리만 이용했다.
Second Approach: Intersectio Of Rids

Intersection Of Rids

Compare I/O cost

<pageId, slot number>
Intersected and sorted에서 보면 <p1, 1> <p1, 2>지만 둘다 p1이니 1 I/O로 계산한다.
rid를 retrieve하는데는 I/O가 필요하지만, intersect하는데는 필요없다.
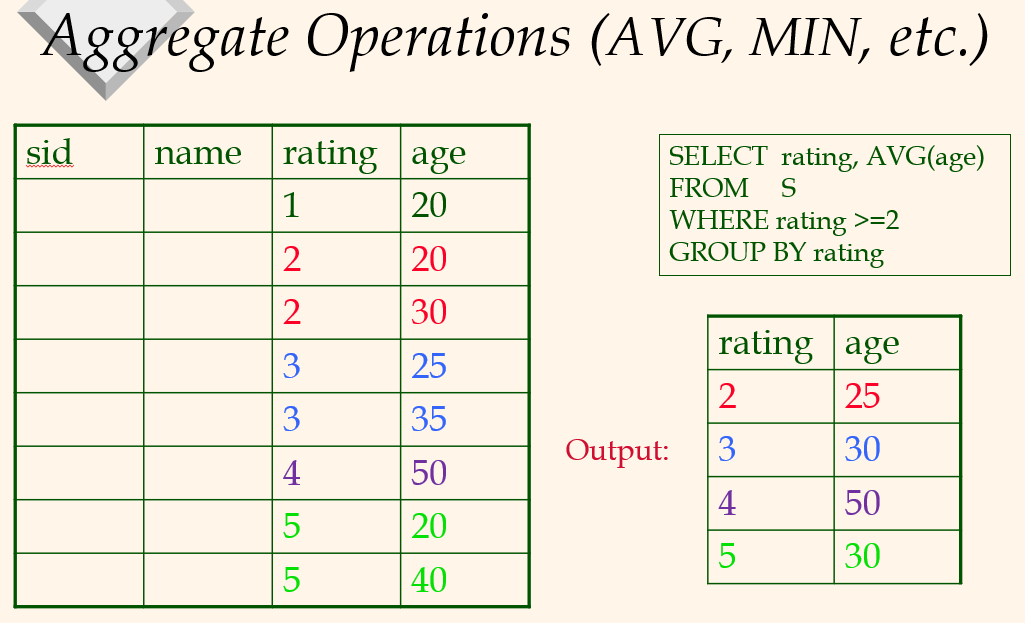
Relational Operaions

The Projection Operations

Example (sort-based)

In Pass 0: have to read everything : 1000 IO
Pass 0 이후 wirte는 50%만 하면 된다 : 500 IO
Merge 들어가기 전에 run 읽어야하니 : 500 IO
중복된 것들 제거해서 write하니 : 500 * 0.8 = 400
Discussion of Projection

An Example

data entries이므로 data records 보다 크기가 훨씬 작다. 오른쪽 위 쿼리에서, B, C를 기준으로 sorting이 되어있지 않아 sorting 해야하자만 index만 sorting 하면 되므로, data record를 sorting하는 것 보다 낫다.
오른쪽 밑에 쿼리를 기준으로, A, B는 sorting이 이미 되어있다.
과제 할 때도, index-only 테크닉을 사용할 수 있다는 것을 염두에 둬라.
Projection Based on Hashing


partition phase에서 필요없는 field는 버렸다.
duplicate elimination phase에서 hash를 한번 더 이용해서 중복을 없앤다.
R1내에서만 또는 R0 내에서만 중복이 있을 수 있다. R1과 R0에 같은 것이 있을 수 없다.
Set Operations

union에서 중복을 없애려한다.


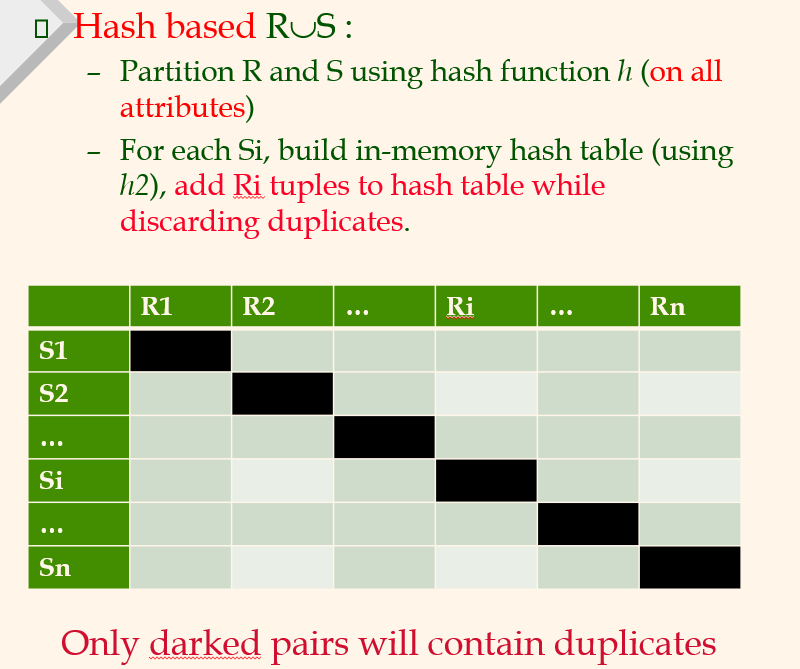
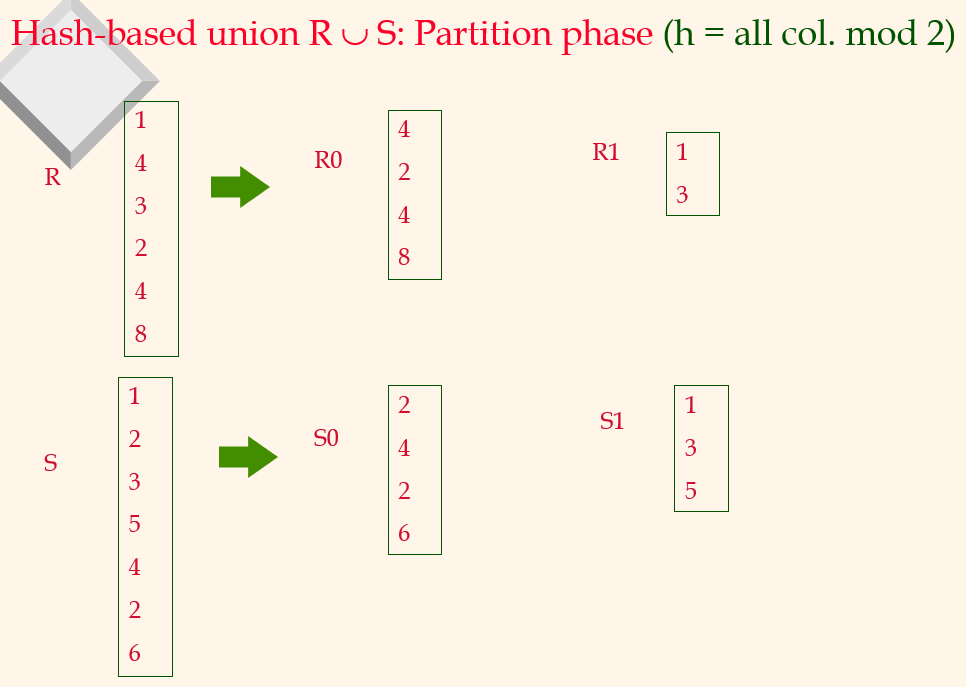

R을 먼저 bucket들에 있고, S에서 하나씩 체크해서 겹치면 bucket에서 제거함녀된다.