Aggregate Operations (AVG, MIN, etc.)
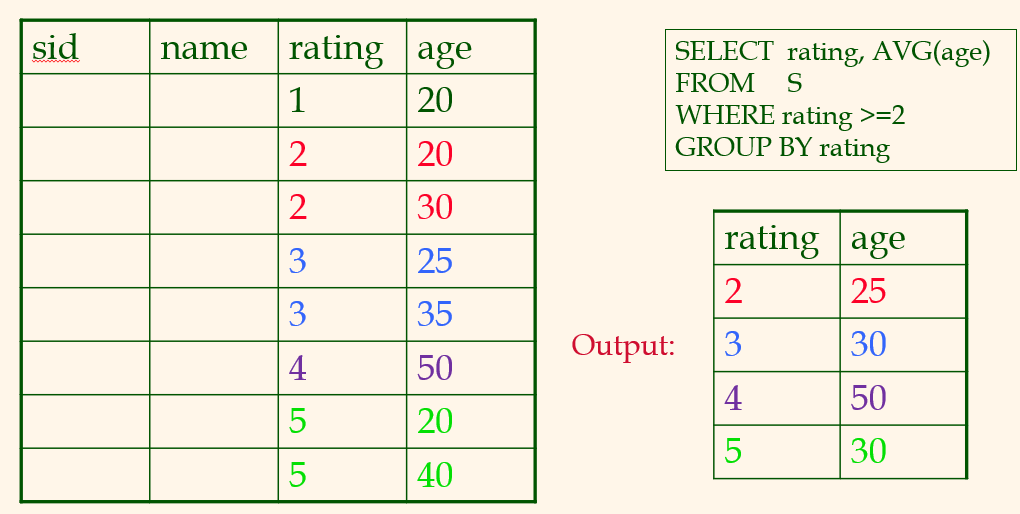

- without grouping:
group by가 없다면 avg를 한번만 구하면된다. rating과 age만 있으면 되므로, index-only를 써야한다.- with group:
Using Index for Sorting
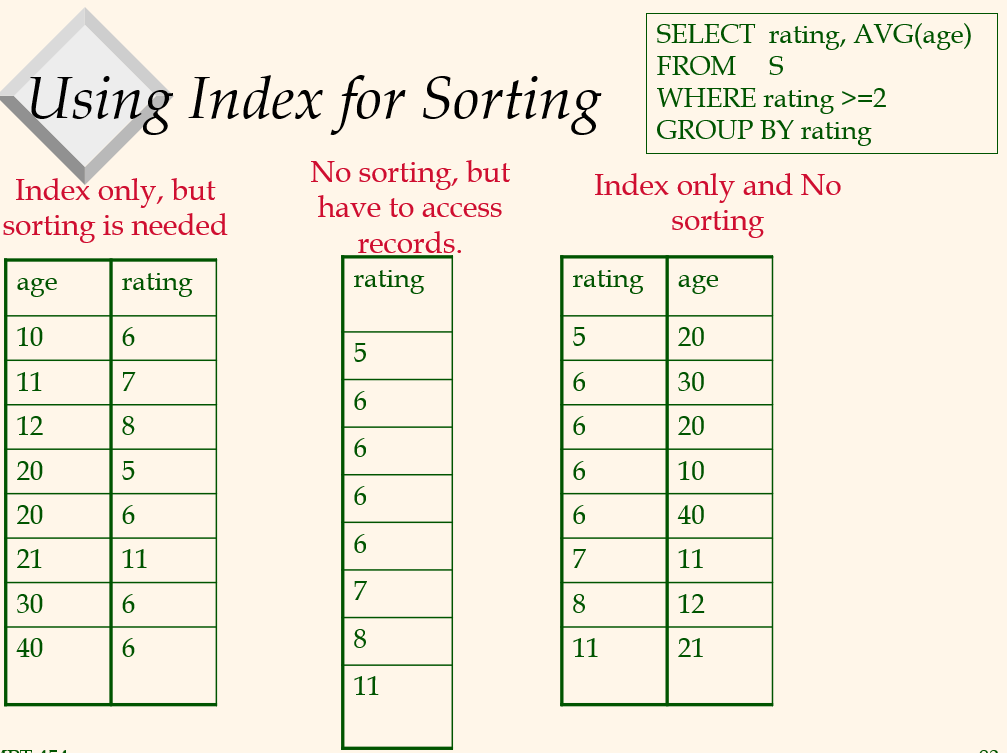
index only, but sorting is needed
rating을 기준으로 sorting 해야한다.No sorting, but have to access records
age가 없으므로 record에 access해야한다.Index only and No Sorting
rating 기준으로 정렬되어있다.
Summary

Things to consider for efficient query evaluation strategies

unclusterd를 쓰면 entire scan보다도 cost가 커질 수도 있다. 항상 index를 쓰는 것이 아니다.
Example : Join then Aggregate
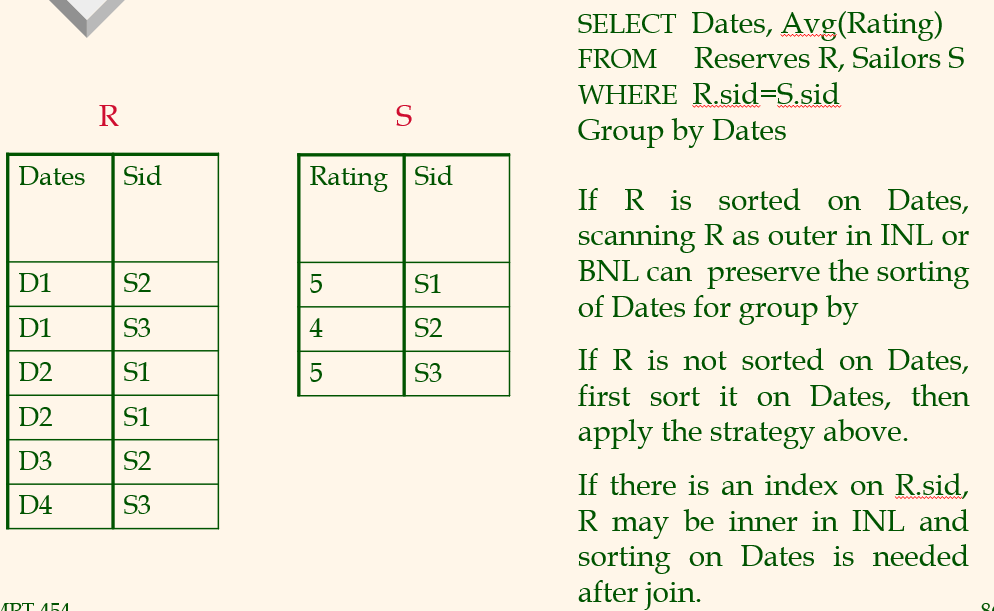
R이 이미 sorting되어 있으므로,R을 outer로 하면 output에서 따로 sorting을 할 필요가 없다. input에서 이미 sorting되어 있으므로.
R.sid에 인덱스가 있다면 R을 inner로 쓰고 S를 outer로 쓰고, 결과에 대해 sorting하면된다.
Practice Questions
Q1

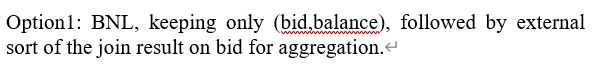
구체적으로 계산하라는 말이 없으면 이렇게만 적으면 된다. BNL과 Sort-merge join은 인덱스가 없을 때 활용할 수 있는 방법이다.
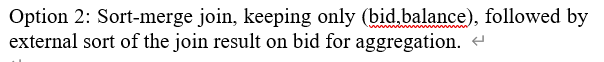
sort-merge지만 accNo를 기준으로 일어난다. 하지만 Group by bid이므로 external sort가 또 필요하다
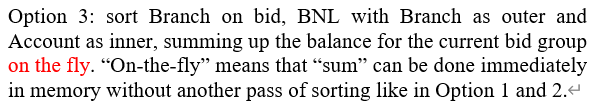
bid를 기준으로 sort를 먼저하는 것이다.

BNL를 Outer로 두고, Account를 inner로 둔다. "on-the-fly"의 의미는 메모리에서 바로 계산이 가능하다는 것이다. 예를 들어 B에서 (1, 500)은 A의 (500, 10K)와 대응되므로 10K를 바로 누적할 수 있는 것이다. 따라서 disk에 썼다가 다사 읽는 비용을 아낀다.
Which is likely the best?
-> 만약 join 결과가 크다면 option3가 best다. option1과 option2에서 큰 테이블을 sorting 해야하기 때문이다.
-> 만약 join 결과가 작다면 option1이나 option2가 나을 수도 있다.

이미 bid를 기준으로 sort되어있으므로, join만 하면된다. sort되어 있기 때문에 grouping 하가 쉽고 "on-the-fly" 가능하다.

Q2



why writing cost is larger than reading cost?
-> There is a fragmentation (한 페이지가 다 차지 않아도 한 페이지가 필요한 경우)

smaller한 것을 hash table을 만드는 이유는 much easier for memory to hold hash table.
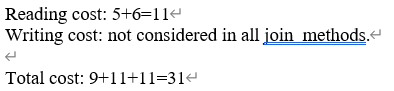
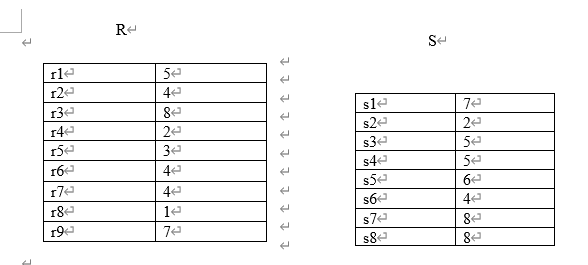
마지막 11은 R1, S1에서 (3+1), R2, S2에서 (2+3), R0, S0에서 (1,1)이다.

Q3


