위 글 마지막 부분에서 나왔듯 offset 방식은 데이터가 커지면 그만큼 느려진다. 그래서 찾아보면서 알게된 해결책들을 정리한다.
1. No Offset
문자 그대로 offset을 쓰지 않는 방식이다. 즉, 페이지 번호를 이용해서 한번에 자유롭게 특정 페이지로 이동하는 것이 아니라 '다음 목록'을 불러오는 방식으로 구현하는 것이다. 현재 속닥속닥처럼 무한스크롤 방식에서도 적합하다.
처음에는 무한스크롤 방식이면 no offset일 것이라고 생각을 했다.
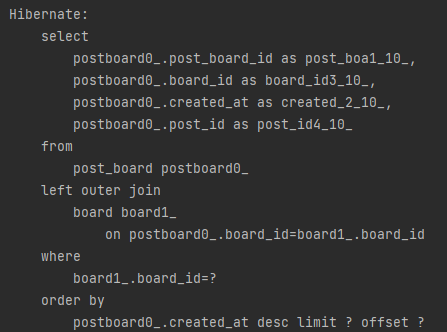
하지만 현재 게시판에서 글을 가져올 때 나가는 쿼리를 보면 limit과 offset이 걸려있다.
위 쿼리를 개선해보면
SELECT *
FROM post_board LEFT OUTER JOIN board on post_board.board_id = board.board_id
WHERE board.board_id < {마지막 조회 id}
ORDER BY id DESC
LIMIT 20이렇게 개선할 수 있다. 물론 이 경우는 id가 AutoIncrement 되어서 시간순으로 증가했다는 전제하이다.
offset을 이용하면 필요한 데이터 페이지가 나올때까지 하나하나 읽어야 하는데, 위의 쿼리로 하면 어디서부터 읽어야할지를 찾고 필요양만 읽는 것이다. 그리고 어디서부터 읽어야할지는 인덱스로 빠르게 검색이 가능하다 (id는 pk이고 pk는 MySQL 8.0에서 클러스터 인덱스가 생성된다)
성능비교
select * from myTable limit 10 offset 800000;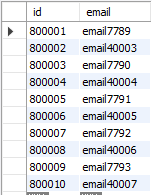

80만개 정도의 데이터가 있을 때 0.156초가 걸렸다.
SELECT * FROM myTable WHERE id > 800000 ORDER BY id ASC LIMIT 10;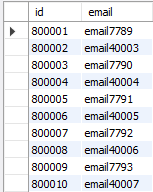

80만건의 데이터에서는 아예 0.0으로 잡혀버린다.
2. 커버링 인덱스
이왕쓸거면 성능이라도 좋게 해서 쓰자. 데이터 파일을 실질적으로 읽지 않고 인덱스만 읽어서 쿼리를 처리할 수 있으면 성능이 더 좋아질 수 있다. 왜냐하면 인덱스 파일은 데이터파일보다 크기가 훨씬작다.
인덱스만으로 쿼리를 수행할 수 있을 때 실행 계획의 Extra 컬럼에 "Using Index"라고 표시되는데, 이렇게 인덱스만으로 처리하는걸 커버링 인덱스라고 한다.
쓰던 예제에서 email에만 인덱스를 만들어도 그 인덱스에 id 칼럼이 같이 저장되는 효과가 난다. email은 세컨더리 인덱스인데, 세컨더리 인덱스의 끝에는 프라이머리 키 값을 가지고, 그 키 값으로 클러스터링 인덱스를 또 타기 때문이다.
CREATE INDEX emailIndex on myTable (email);
select * from myTable limit 10 offset 800000;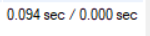
0.094초가 나왔다. 커버링 인덱스를 쓰기 전에는 0.125~0.15초정도가 나왔다.

실제로 실행 계획을 보면 Extra에 Using index가 잡혔다.
하지만 테이블간의 조인이 있다면 문제를 어떻게 풀지는 또 생각을 더 해봐야할 것 같다
속닥속닥의 경우 board와 조인을 하고 있는데 board_id가 4개 밖에 없다. 이정도라면 정규화를 포기하고 post에 board_id를 저장할 수도 있을 것 같다.
3. 운영으로 풀기
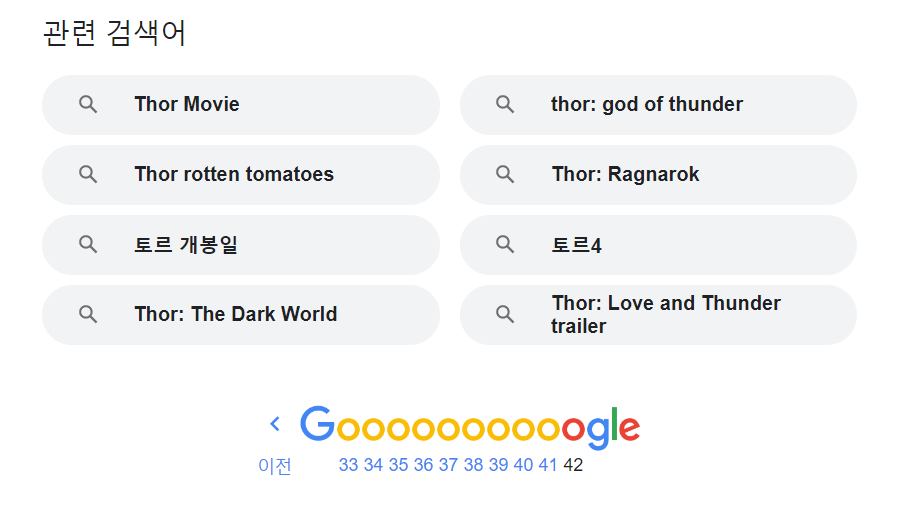
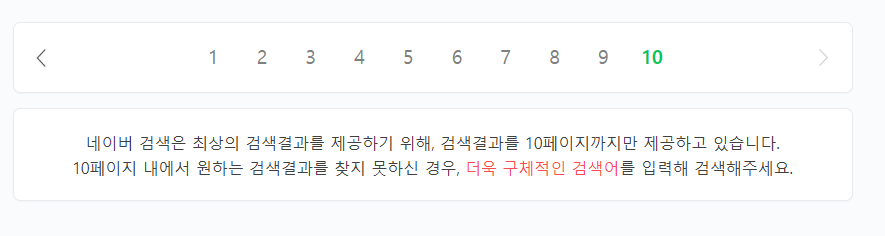
구글과 네이버에서 검색했을 때 결과다. 두 사이트 다 페이지를 무한정 넘어갈 수 없게 해놨다. 구글의 경우 키워드가 문제인가 싶어 다른 키워드로 해봤는데 마찬가지였다.
사실 대부분의 사람들이 몇 페이지가 넘어가서 원하는게 나오지 않으면 키워드를 수정한다. 따라서 아예 서비스 차원에서 막는 것도 방법이다.
하지만 현재 속닥속닥처럼 무한스크롤 방식이면 데이터가 끝이 나지 않는 이상 계속 보여주기는 해야하지 않을까 싶기도하다. 반대로 제한을 둬도 크게 이상하지 않을 것 같아서 이 부분은 서비스 정책으로 정하면 될 것 같다.
결론
사실 이 모든건 데이터가 너무 많아질 경우를 생각해보고 궁금해져서 학습한 것이다. 지금의 규모에서는 문제가 크게 없고, 오히려 지금 방식이 더 편하기까지하다. 문제가 생긴다면 커버링 인덱스를 이용하고, 그 이후에 no offset을 이용해도 될 것 같다.
