
해당 글은 제로베이스데이터스쿨 학습자료를 참고하여 작성되었습니다
Natural Language Processing
- 사람이 사용하는 자연어를 컴퓨터가 이해하고 처리할 수 있도록 하는 기술
- 기계번역, 텍스트 분류, 감성 분석, 정보 추출, 질문 응답 등에 다양한 분야에서 사용됨
- 텍스트 분석, 언어 모델링, 형태소 분석, 구문 분석, 의미 분석, 담화 분석등의 기술을 포함하고 있음
%conda update conda
%pip install --upgrade pip
%pip install konlpy
%pip install tweepy==3.10.0
%conda install -y -c conda-forge jpypel==1.0.2
%conda install -y -c conda-forge wordcloud
%conda install -y nltk
설치 완료 후 아래 내용 수행
import nltk
nltk.download()
생성된 창에서 'All Packages' -> 'punkt'와 'stopwords' 다운로드 후 종료KoNLPy
- Korean Natural Language processing in Python
- 쉽고 간결한 한국어 정보처리 파이썬 패키지
한글 문장구조 분석
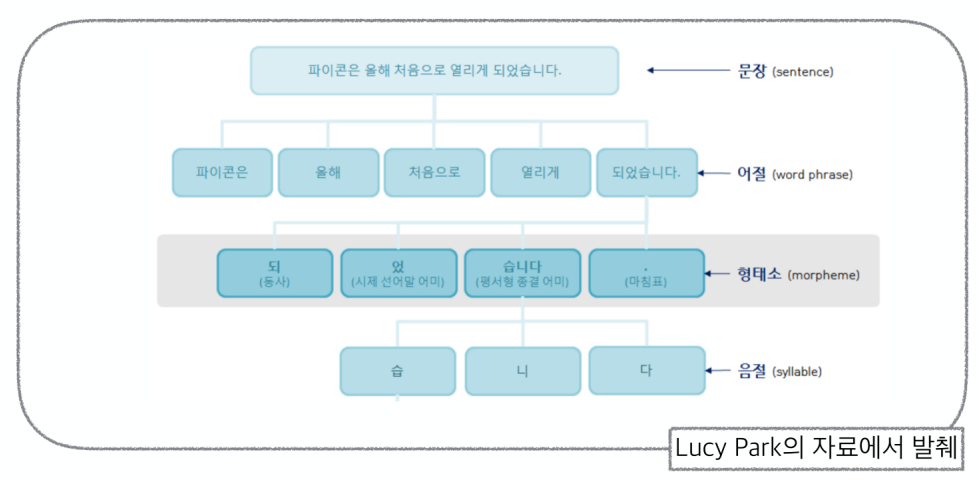
형태소 분석
- 단어의 구조와 형성을 분석하는 데 사용되는 언어학적 방법
- 단어를 형태소라고 하는 의미 있는 가장 작은 단위로 분해하고 이들이 결합하여 다양한 형태의 단어를 만드는 방법을 분석하는 것
from konlpy.tag import Okt
t = Okt()
t.pos('한국어 분석을 시작합니다 재미있어요~~')
------------------------------------------
[('한국어', 'Noun'),
('분석', 'Noun'),
('을', 'Josa'),
('시작', 'Noun'),
('합니다', 'Verb'),
('재미있어요', 'Adjective'),
('~~', 'Punctuation')]1) 이상한 나라의 엘리스
stopword
- 자연어 처리에 영향을 주지 않도록 하는 설정
- ex) a, about, above 등의 단어
from wordcloud import WordCloud, STOPWORDS
import numpy as np
from PIL import Image
text = open('./data/06_alice.txt').read() # 이상한 나라 엘리스 소설(영문)
alice_mask = np.array(Image.open('./data/06_alice_mask.png')) # 엘리스 그림
stopwords = set(STOPWORDS)
stopwords.add('said') # 많이 등장하는 'said' 단어는 stopword 처리엘리스 그림 확인
import matplotlib.pyplot as plt
import platform
from matplotlib import rc
rc('font', family='Malgun Gothic')
plt.figure(figsize=(8,8))
plt.imshow(alice_mask, cmap=plt.cm.gray, interpolation='bilinear')
plt.title('엘리스 그림')
plt.axis('off')
plt.show()
워드클라우드 만들기
- WordCloud 모듈은 자체적으로 단어를 추출해서
- 빈도수를 조사하고 정규화하는 기능을 가지고 있음
단어 빈도수 조사
wc = WordCloud(
background_color='white', max_words=2000, mask=alice_mask, stopwords=stopwords
)
wc = wc.generate(text)
wc.words_
-------------------------------------------------
{'Alice': 1.0,
'little': 0.29508196721311475,
'one': 0.27595628415300544,
'know': 0.2459016393442623,
'went': 0.226775956284153,
'thing': 0.2185792349726776,
'time': 0.2103825136612022,
'Queen': 0.20765027322404372,
'see': 0.1830601092896175,
'King': 0.17486338797814208,
'well': 0.1721311475409836,
'now': 0.16393442622950818,
'head': 0.16393442622950818,
'began': 0.15846994535519127,
'way': 0.1557377049180328,
'Hatter': 0.1557377049180328,
'Mock Turtle': 0.15300546448087432,
'say': 0.15027322404371585,
'Gryphon': 0.15027322404371585,
'think': 0.1448087431693989,
'quite': 0.14207650273224043,
'much': 0.13934426229508196,
'first': 0.13934426229508196,
'thought': 0.1366120218579235,
'go': 0.1366120218579235,
...
'older': 0.00546448087431694,
'knowing': 0.00546448087431694,
'authority': 0.00546448087431694,
'ring': 0.00546448087431694,
...}워드클라우드 그리기
plt.figure(figsize=(12,12))
plt.imshow(wc, interpolation='bilinear')
plt.axis('off')
plt.show()
2) 스타워즈
스타워즈 워드클라우드 설정
text = open('./data/06_a_new_hope.txt').read()
text = text.replace('HAN', 'Han')
text = text.replace("LUKE'S", "LUKE")
mask = np.array(Image.open('./data/06_stormtrooper_mask.png'))
stopwords = set(STOPWORDS)
stopwords.add('int')
stopwords.add('ext')
wc = WordCloud(max_words=1000, mask=mask, stopwords=stopwords, margin=10, random_state=13).generate(text)
default_colors = wc.to_array()그레이톤으로 색상 함수 정의
import random
def gray_color_func(word, font_size, position, orientation, random_state=None, **kwards):
return 'hsl(0, 0%%, %d%%)' % random.randint(60, 100)
plt.figure(figsize=(12,12))
plt.imshow(wc.recolor(color_func=gray_color_func, random_state=13))
plt.axis('off')
plt.show()
감성분석
- 텍스트에서 의견, 감정, 태도와 같은 주관적인 정보를 식별하고 추출
- 기계 학습 알고리즘을 사용하여 긍정적, 부정적 또는 중립적일 수 있는 감정을 기반으로 텍스트 데이터를 분석하고 분류
나이브 베이즈 분류
- 특성들 사이의 독립을 가정하는 베이즈 정리를 적용한 확률 분류기
영어
말 뭉치 만들기
from nltk.tokenize import word_tokenize
import nltk
train = [
('i like you', 'pos'),
('i hate you', 'neg'),
('you like me', 'neg'),
('i like her', 'pos')
]
all_words = set(
word.lower() for sentence in train for word in word_tokenize(sentence[0])
)
all_words
-------------------------------------------
{'hate', 'her', 'i', 'like', 'me', 'you'}각 단어들로 P/N 분석
t = [({word: (word in word_tokenize(x[0])) for word in all_words}, x[1]) for x in train]
t
-------------------------
[({'like': True,
'you': True,
'her': False,
'hate': False,
'i': True,
'me': False},
'pos'),
({'like': False,
'you': True,
'her': False,
'hate': True,
'i': True,
'me': False},
'neg'),
({'like': True,
'you': True,
'her': False,
'hate': False,
'i': False,
'me': True},
'neg'),
({'like': True,
'you': False,
'her': True,
'hate': False,
'i': True,
'me': False},
'pos')]분류기 학습
- 각 단어의 여부에 따른 P/N 예측 결과
classifier = nltk.NaiveBayesClassifier.train(t)
classifier.show_most_informative_features()
---------------------------------------------------------------------------
Most Informative Features
hate = False pos : neg = 1.7 : 1.0
her = False neg : pos = 1.7 : 1.0
i = True pos : neg = 1.7 : 1.0
like = True pos : neg = 1.7 : 1.0
me = False pos : neg = 1.7 : 1.0
you = True neg : pos = 1.7 : 1.0분류기 학습 결과
- 위에서 i와 like가 있을 때 pos일 비율이 1.7이고, MeRui는 없는 데이터이다
- hate, me가 없을 때 pos일 비율이 1.7, her이 없을 때 부정일 비율 1.7
- 즉, 긍정 8.5, 부정 6.7이므로 긍정이다
test_sentence = 'i like MeRui'
test_sent_features = {
word.lower(): (word in word_tokenize(test_sentence.lower())) for word in all_words
}
test_sent_features, classifier.classify(test_sent_features)
----------------------------------------
({'like': True,
'you': False,
'her': False,
'hate': False,
'i': True,
'me': False},
'pos')한글
말뭉치 만들기
- 조사가 다르면 다른 단어로 인식
- 올바른 데이터 분석이 불가능하므로 형태소 분석이 필수적
형태소 분석 안한 말뭉치 만들기
from konlpy.tag import Okt
pos_tagger = Okt()
train = [
("메리가 좋아", 'pos'),
("고양이도 좋아", 'pos'),
("난 수업이 지루해", 'neg'),
("메리는 이쁜 고양이야", 'pos'),
("난 마치고 메리랑 놀거야", 'pos'),
]
all_words = set(
word.lower() for sentence in train for word in word_tokenize(sentence[0])
)
all_words
------------------------------------------
{'고양이도',
'고양이야',
'난',
'놀거야',
'마치고',
'메리가',
'메리는',
'메리랑',
'수업이',
'이쁜',
'좋아',
'지루해'}형태소 분석 후 단어별 P/N 분석
def tokenize(doc):
return ["/".join(t) for t in pos_tagger.pos(doc, norm=True, stem=True)]
train_docs = [(tokenize(row[0]), row[1]) for row in train]
tokens = [t for d in train_docs for t in d[0]]
def term_exists(doc):
return {word: (word in set(doc)) for word in tokens}
train_xy = [(term_exists(d), c) for d, c in train_docs]
train_xy
----------------------------------------
[({'메리/Noun': True,
'가/Josa': True,
'좋다/Adjective': True,
'고양이/Noun': False,
'도/Josa': False,
'난/Noun': False,
'수업/Noun': False,
'이/Josa': False,
'지루하다/Adjective': False,
'는/Josa': False,
'이쁘다/Adjective': False,
'야/Josa': False,
'마치/Noun': False,
'고/Josa': False,
'랑/Josa': False,
'놀다/Verb': False},
'pos'),
({'메리/Noun': False,
'가/Josa': False,
'좋다/Adjective': True,
'고양이/Noun': True,
'도/Josa': True,
'난/Noun': False,
'수업/Noun': False,
'이/Josa': False,
...
'마치/Noun': True,
'고/Josa': True,
'랑/Josa': True,
'놀다/Verb': True},
'pos')]분류기 학습
classifier = nltk.NaiveBayesClassifier.train(train_xy)
classifier.show_most_informative_features()
------------------------------------------------------------------------------
Most Informative Features
난/Noun = True neg : pos = 2.5 : 1.0
메리/Noun = False neg : pos = 2.5 : 1.0
고양이/Noun = False neg : pos = 1.5 : 1.0
좋다/Adjective = False neg : pos = 1.5 : 1.0
가/Josa = False neg : pos = 1.1 : 1.0
고/Josa = False neg : pos = 1.1 : 1.0
놀다/Verb = False neg : pos = 1.1 : 1.0
는/Josa = False neg : pos = 1.1 : 1.0
도/Josa = False neg : pos = 1.1 : 1.0
랑/Josa = False neg : pos = 1.1 : 1.0분류기 테스트
test_sentence = [('난 수업이 마치면 메리랑 놀거야')]
test_docs = pos_tagger.pos(test_sentence[0])
test_sent_features = {word: (word in tokens) for word in test_docs}
test_sent_features, classifier.classify(test_sent_features)
-------------------------------
({('난', 'Noun'): False,
('수업', 'Noun'): False,
('이', 'Josa'): False,
('마치', 'Noun'): False,
('면', 'Josa'): False,
('메리', 'Noun'): False,
('랑', 'Josa'): False,
('놀거야', 'Verb'): False},
'pos')문장의 유사도
CountVecotrize
- 문장을 수치 벡터로 변환
- 각 벡터의 거리를 측정하여 유사도 검사
데이터 준비
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(min_df=1)
contents = ['상처받은 아이들은 너무 일찍 커버려',
'내가 상처받은 거 아는 사람 불편해',
'잘 사는 사람들은 좋은 사람 되기 쉬워',
'아무 일도 아니야 괜찮아']형태소 분석
from konlpy.tag import Okt
t = Okt()
contents_tokens = [t.morphs(row) for row in contents]
contents_tokens
------------------------------------------------------
[['상처', '받은', '아이', '들', '은', '너무', '일찍', '커버', '려'],
['내', '가', '상처', '받은', '거', '아는', '사람', '불편해'],
['잘', '사는', '사람', '들', '은', '좋은', '사람', '되기', '쉬워'],
['아무', '일도', '아니야', '괜찮아']]contents_for_vectorize = []
for content in contents_tokens:
sentence = ''
for word in content:
sentence = sentence + ' ' + word
contents_for_vectorize.append(sentence)
contents_for_vectorize
----------------------------------------------------------------
[' 상처 받은 아이 들 은 너무 일찍 커버 려',
' 내 가 상처 받은 거 아는 사람 불편해',
' 잘 사는 사람 들 은 좋은 사람 되기 쉬워',
' 아무 일도 아니야 괜찮아']학습용 데이터 벡터화
- 4개 문장에 전체 말뭉치의 단어가 17개
X = vectorizer.fit_transform(contents_for_vectorize)
num_samples, num_features = X.shape
num_samples, num_features
--------------------------
(4, 17)벡터내용 확인
- 각 문장은 열, 말뭉치들은 행
- ex1) 1행 : 4번 문장에 '괜찮아' 있음
- ex2) 2행 : 1번 문장에 '너무' 있음
vectorizer.get_feature_names_out().reshape(-1, 1)
----------------------------------------------------
array([['괜찮아'],
['너무'],
['되기'],
['받은'],
['불편해'],
['사는'],
['사람'],
['상처'],
['쉬워'],
['아는'],
['아니야'],
['아무'],
['아이'],
['일도'],
['일찍'],
['좋은'],
['커버']], dtype=object)X.toarray().transpose()
-----------------------------------------------------
array([[0, 0, 0, 1],
[1, 0, 0, 0],
[0, 0, 1, 0],
[1, 1, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 1, 2, 0],
[1, 1, 0, 0],
[0, 0, 1, 0],
[0, 1, 0, 0],
[0, 0, 0, 1],
[0, 0, 0, 1],
[1, 0, 0, 0],
[0, 0, 0, 1],
[1, 0, 0, 0],
[0, 0, 1, 0],
[1, 0, 0, 0]], dtype=int64)
테스트용 문장 만들기
new_post = ['상처받기 싫어 괜찮아']
new_post_tokens = [t.morphs(row) for row in new_post]
new_post_for_vectorize = []
for content in new_post_tokens:
sentence = ''
for word in content:
sentence = sentence + ' ' + word
new_post_for_vectorize.append(sentence)
new_post_for_vectorize
-------------------------
[' 상처 받기 싫어 괜찮아']테스트 문장 벡터화
new_post_vec = vectorizer.transform(new_post_for_vectorize)
new_post_vec.toarray()
--------------------------------------------------------------------------
array([[1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]], dtype=int64)거리계산
import scipy as sp
def dist_raw(v1, v2):
delta = v1 - v2
return sp.linalg.norm(delta.toarray())
dist = [dist_raw(each, new_post_vec) for each in X]
dist
-----------------------------------------------------------------
[2.449489742783178, 2.23606797749979, 2.8284271247461903, 2.0]유사도가 가장 높은 문장과 비교
print('Best post is ', dist.index(min(dist)), ', dist = ', min(dist))
print('Test post is --> ', new_post)
print('Best dist post is --> ', contents[dist.index(min(dist))])
-------------------------------------------------------------------
Best post is 3 , dist = 2.0
Test post is --> ['상처받기 싫어 괜찮아']
Best dist post is --> 아무 일도 아니야 괜찮아벡터 표기
for i in range(len(contents)):
print(X.getrow(i).toarray())
print('-' * 40)
print(new_post_vec.toarray())
--------------------------------------------------------
[[0 1 0 1 0 0 0 1 0 0 0 0 1 0 1 0 1]]
[[0 0 0 1 1 0 1 1 0 1 0 0 0 0 0 0 0]]
[[0 0 1 0 0 1 2 0 1 0 0 0 0 0 0 1 0]]
[[1 0 0 0 0 0 0 0 0 0 1 1 0 1 0 0 0]]
----------------------------------------
[[1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0]]
TF-IDF
- Term Frequency-Inverse Document Frequency
- 여러 문서에서 어떤 단어가 문서 내에서 얼마나 중요한 것인지를 나타내는 통계적 수치
- 중요성에 따른 가중치 부여
- 한 문서에서 자주 등장하는 단어는 중요성 상승
- 모든 문서에서 자주 등장하는 단어는 중요성 하락
TF-IDF로 학습
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(min_df=1, decode_error='ignore')
X = vectorizer.fit_transform(contents_for_vectorize)
num_samples, num_features = X.shape
num_samples, num_features
-------------------------
(4, 17)학습데이터 벡터
X.toarray().transpose()
-----------------------------------------------------------
array([[0. , 0. , 0. , 0.5 ],
[0.43671931, 0. , 0. , 0. ],
[0. , 0. , 0.39264414, 0. ],
[0.34431452, 0.40104275, 0. , 0. ],
[0. , 0.50867187, 0. , 0. ],
[0. , 0. , 0.39264414, 0. ],
[0. , 0.40104275, 0.6191303 , 0. ],
[0.34431452, 0.40104275, 0. , 0. ],
[0. , 0. , 0.39264414, 0. ],
[0. , 0.50867187, 0. , 0. ],
[0. , 0. , 0. , 0.5 ],
[0. , 0. , 0. , 0.5 ],
[0.43671931, 0. , 0. , 0. ],
[0. , 0. , 0. , 0.5 ],
[0.43671931, 0. , 0. , 0. ],
[0. , 0. , 0.39264414, 0. ],
[0.43671931, 0. , 0. , 0. ]])테스트데이터 벡터
new_post_vec = vectorizer.transform(new_post_for_vectorize)
new_post_vec.toarray()
--------------------------------------------------------------------
array([[0.78528828, 0. , 0. , 0. , 0. ,
0. , 0. , 0.6191303 , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. ]])거리계산
def dist_norm(v1, v2):
v1_normalize = v1 / sp.linalg.norm(v1.toarray())
v2_normalize = v2 / sp.linalg.norm(v2.toarray())
delta = v1_normalize - v2_normalize
return sp.linalg.norm(delta.toarray())
dist = [dist_norm(each, new_post_vec) for each in X]
dist
-------------------------------------------------------------------------------
[1.254451632446019, 1.2261339938790283, 1.4142135623730951, 1.1021396119773588]유사도가 가장 높은 문장과 비교
print('Best post is ', dist.index(min(dist)), ', dist = ', min(dist))
print('Test post is --> ', new_post)
print('Best dist post is --> ', contents[dist.index(min(dist))])
------------------------------------------------------------------
Best post is 3 , dist = 1.1021396119773588
Test post is --> ['상처받기 싫어 괜찮아']
Best dist post is --> 아무 일도 아니야 괜찮아