서울시 범죄 현황 데이터 분석

해당 글은 제로베이스데이터스쿨 학습자료를 참고하여 작성되었습니다
📌서울시 범죄 현황 데이터 분석
📌프로젝트 목표
서울시 범죄율 분석
- 과거에 서울 강남3구의 체감안전도가 높다는 기사가 있었는데 당시에 정말로 안전했는지 지도시각화를 통해 분석해보자
데이터출처 : 공공데이터포털
제로베이스에서 수정한 2016년도 데이터 활용
📌프로젝트 절차
- 서울시 범죄 현황 데이터 확보
- 서울시 범죄 현황 데이터 정리
- google maps를 이용한 데이터 정리
- 구별데이터로 변경하기
- 범죄데이터 정렬을 위한 데이터 정리
- 범죄 현황 데이터 시각화
- 서울시 범죄 현황 지도 시각화
- 서울시 범죄 현황 발생 장소 분석
📌1. 서울시 범죄 현황 데이터 확보

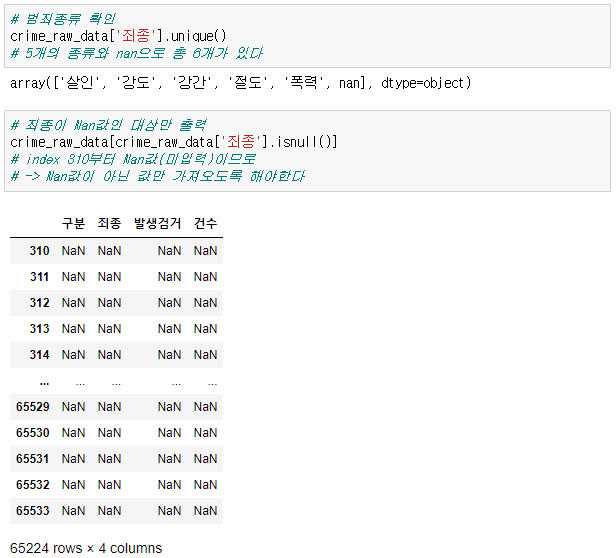
📝입력
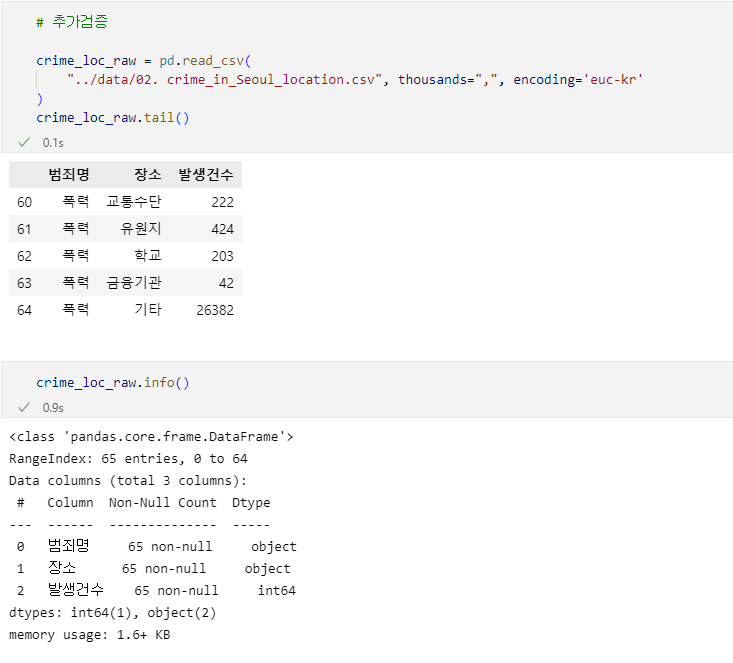
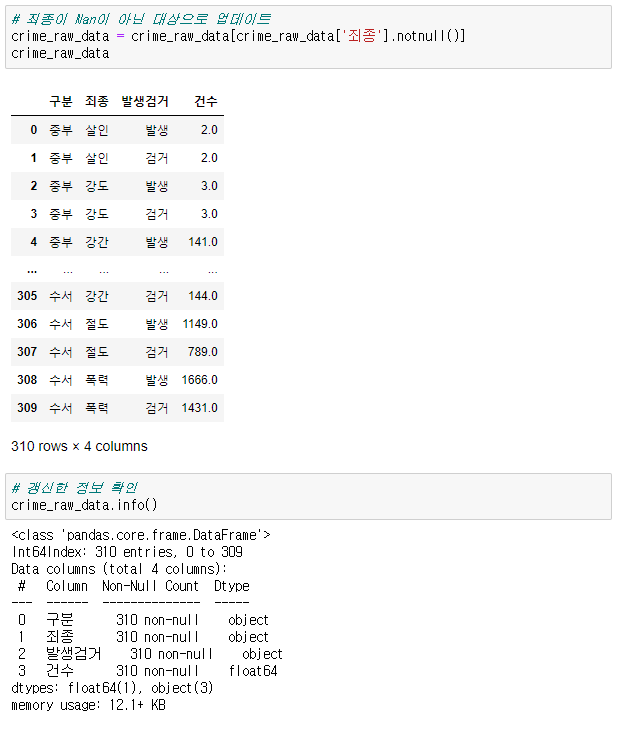
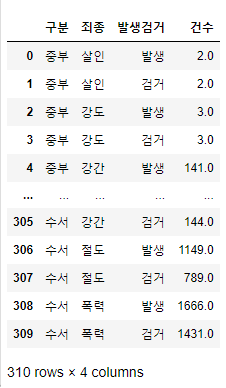
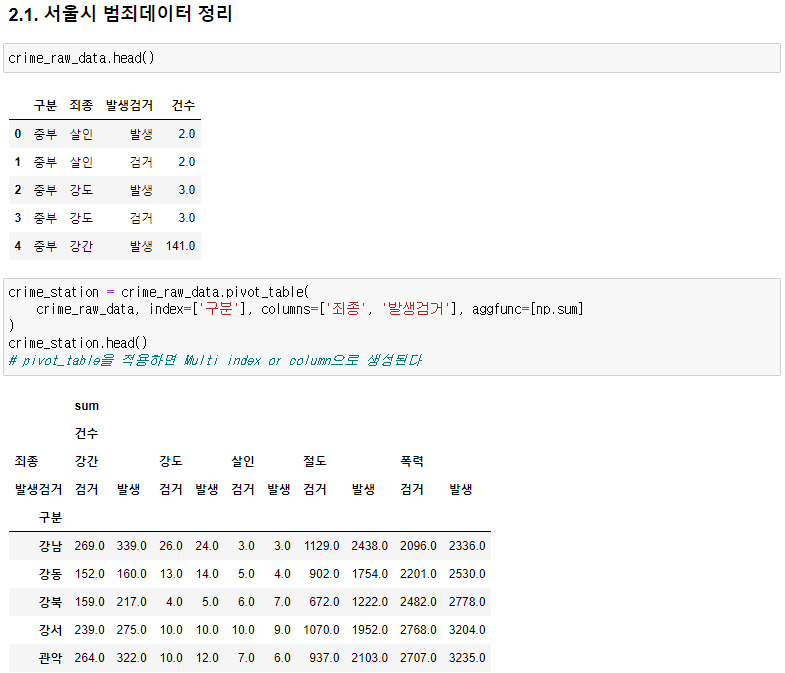
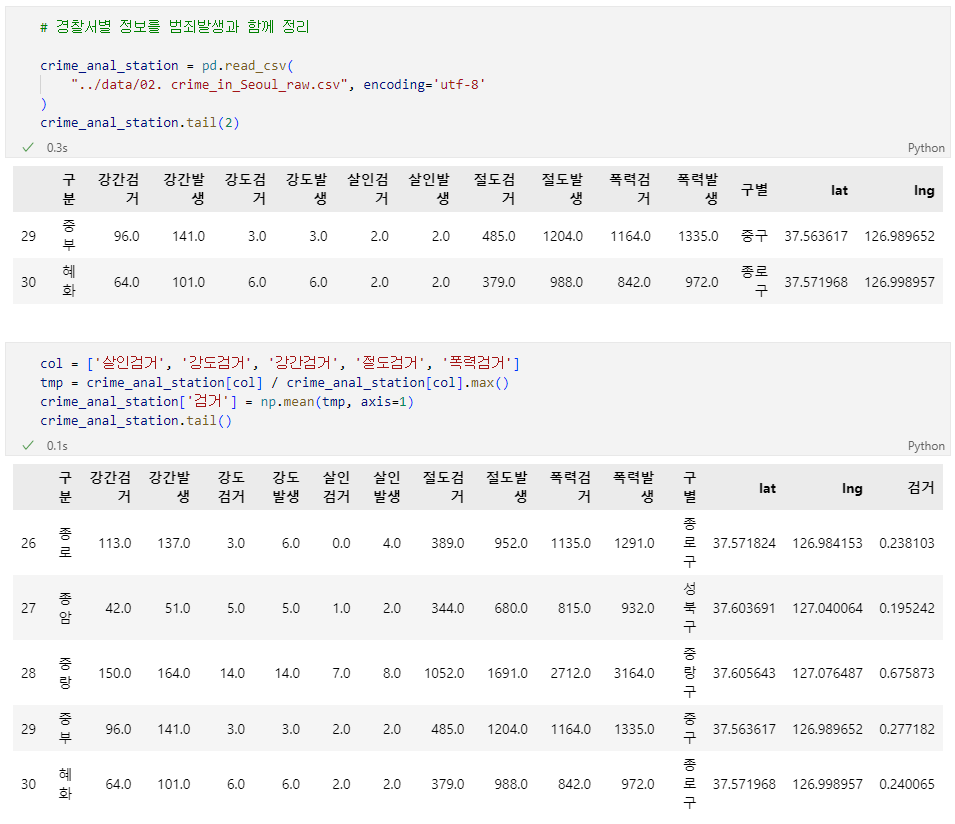
import numpy as np import pandas as pd crime_raw_data = pd.read_csv( '../data/02. crime_in_Seoul.csv', encoding='euc-kr', thousands=",") # 데이터 확인 crime_raw_data.info() # 데이터에 Nan값이 많음을 확인 -> 의미있는 값만 사용하기로 판단 crime_raw_data = crime_raw_data[crime_raw_data['죄종'].notnull()] crime_raw_data🧾출력
🧾crime_raw_data.info()

🧾crime_raw_data
📌2. 서울시 범죄 현황 데이터 정리
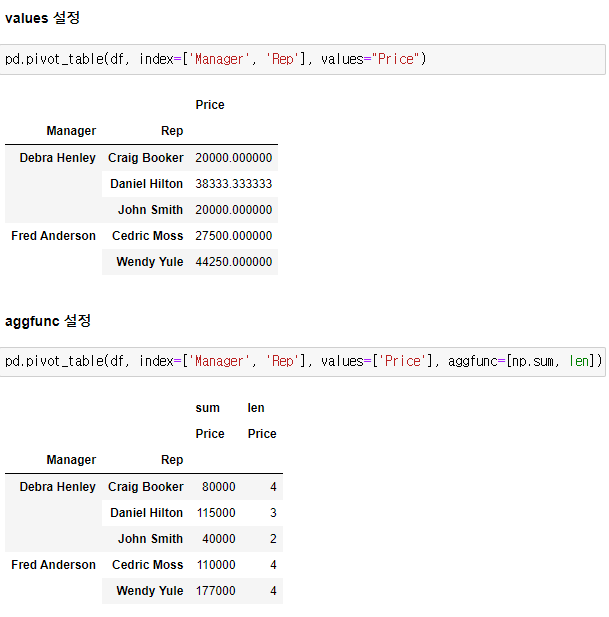
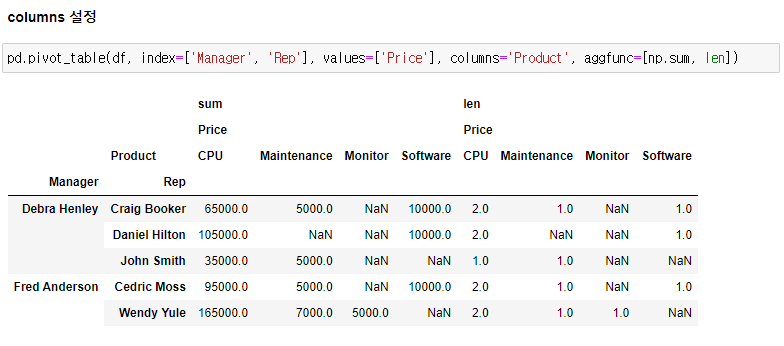
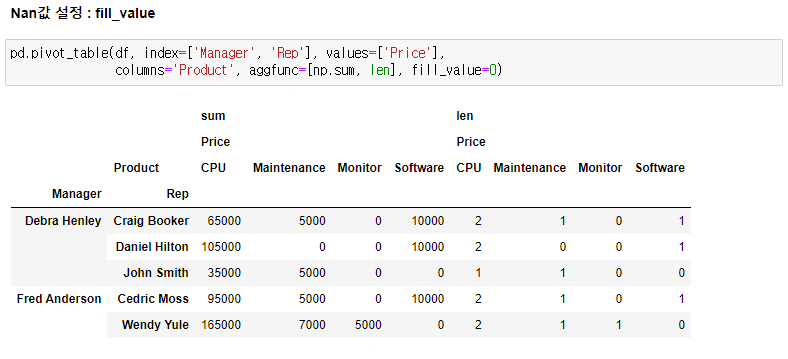
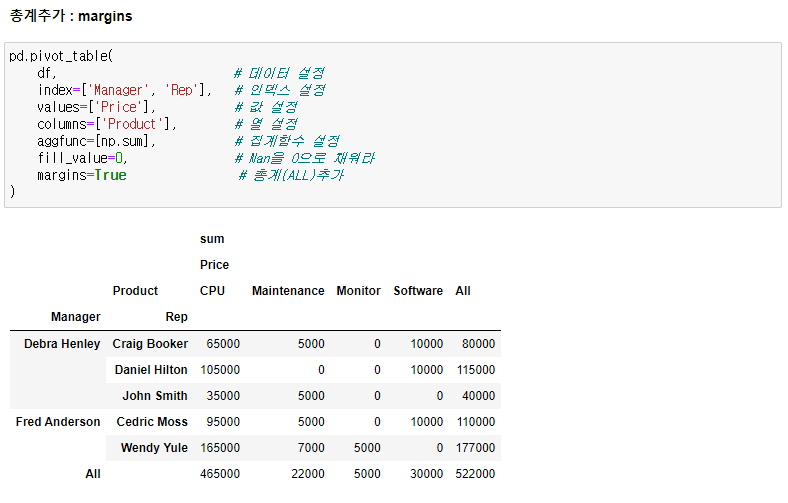
2.0. Pandas Pivot Table
- 속성 : index, columns, values, aggfunc, margins, fill_value
- 속성에 복수의 내용 지정시 ['A', 'B'] 사용
- pd.pivot_table(df, ...) = df.pivot_table(...)
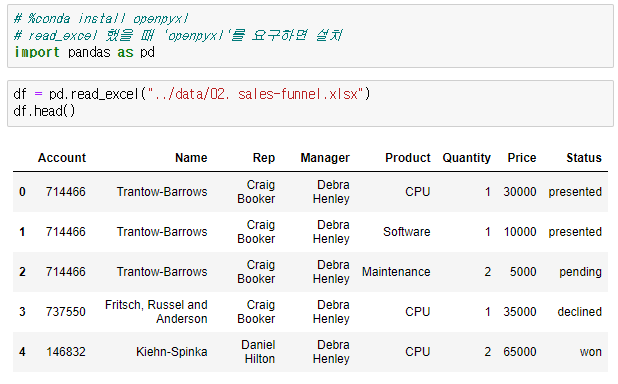

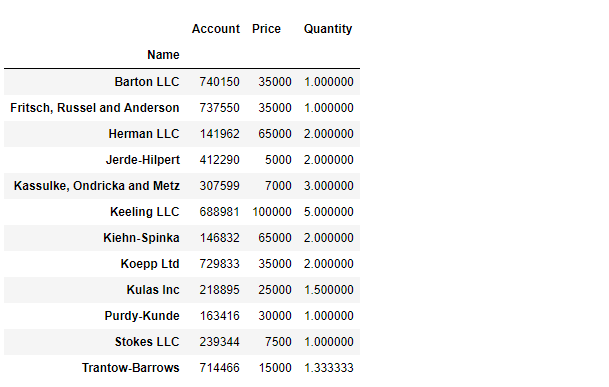

2.1. 서울시 범죄 현황 데이터 정리

📝입력
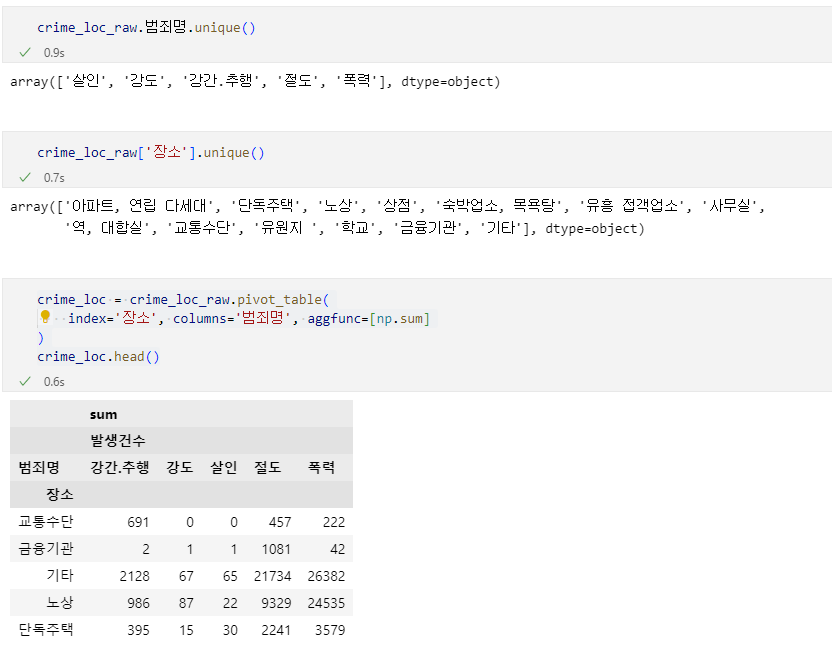
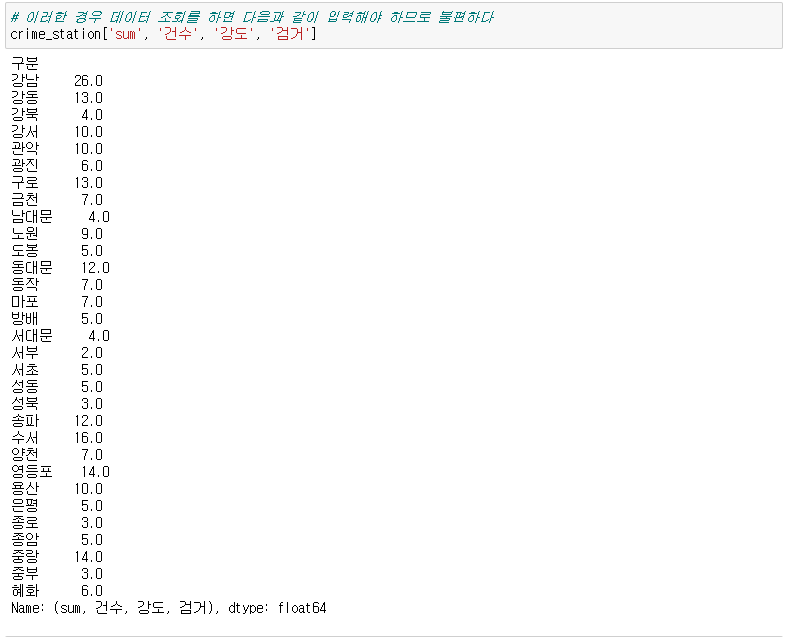
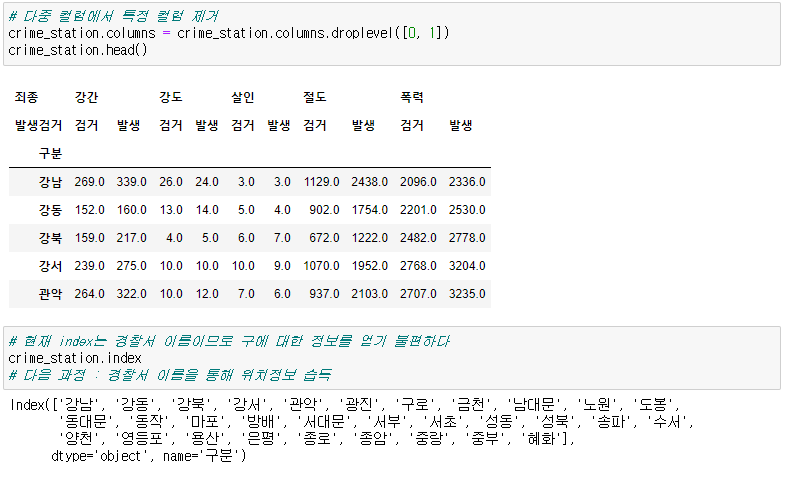
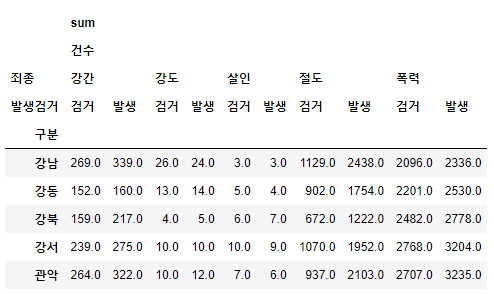
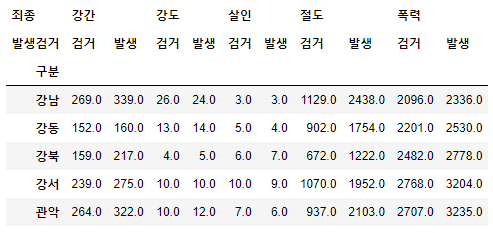
crime_station = crime_raw_data.pivot_table( crime_raw_data, index=['구분'], columns=['죄종', '발생검거'], aggfunc=[np.sum] # 데이터확인 crime_station.head() # pivot_table의 구조를 수정하기로 결정 crime_station.columns = crime_station.columns.droplevel([0, 1]) crime_station.head() )🧾출력
🧾수정 전 crime_station.head()
🧾수정 후 crime_station.head()
📌3. google maps를 이용한 데이터 정리
3.0. Google Maps API 사용준비
구글 클라우드 플랫폼으로 접속 결제로 이동
결제로 이동 계정만들기 클릭
계정만들기 클릭
이후 절차에 따라서 계정을 생성한다
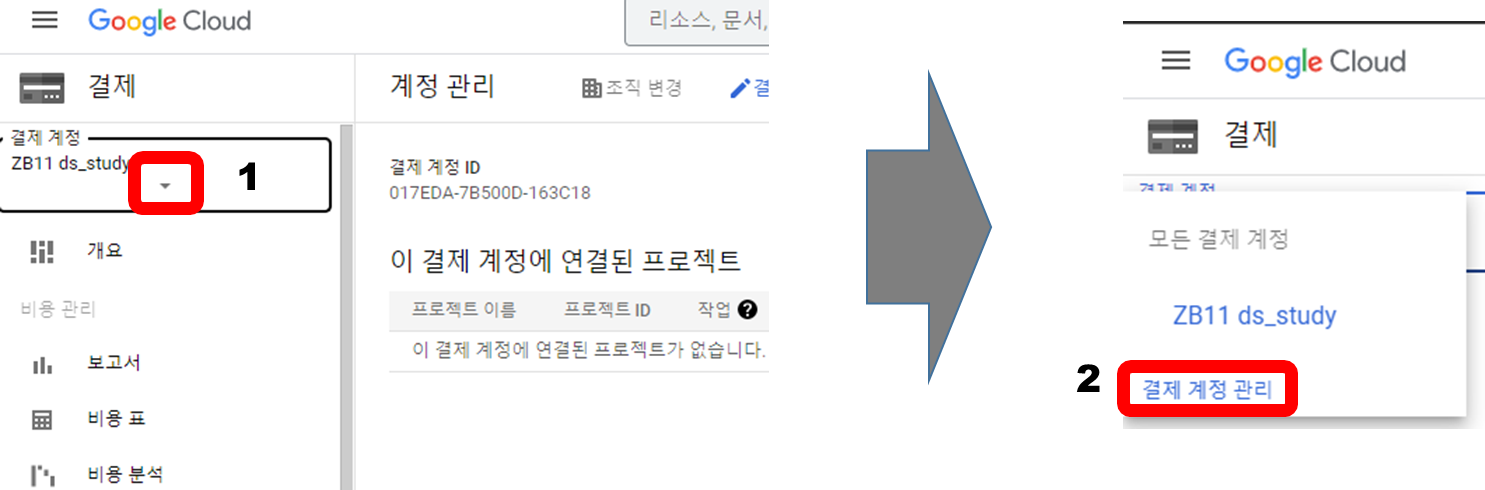
계정 생성 후 계정관리로 이동
아래의 그림을 따라 이동한다
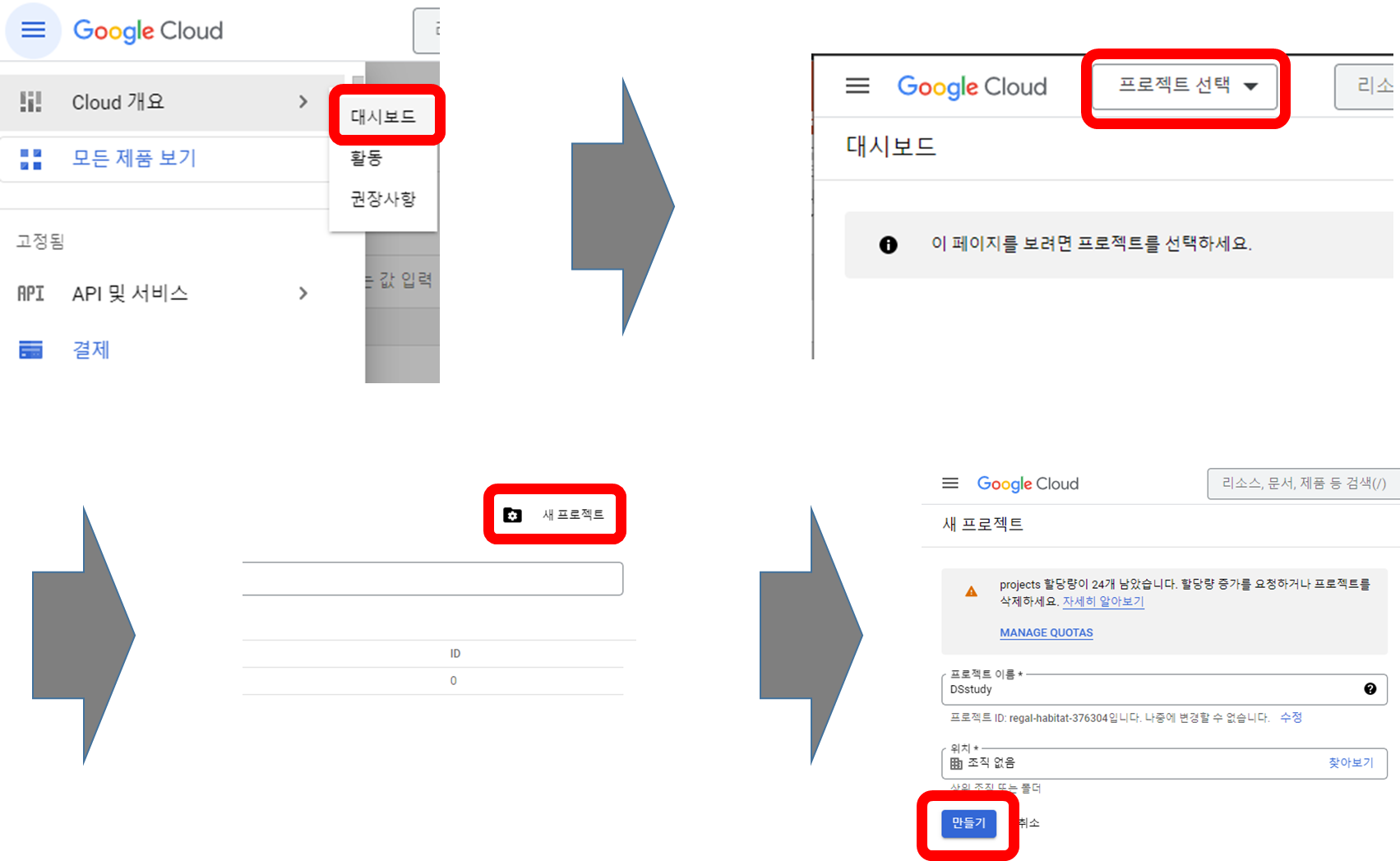
프로젝트를 생성한다
검색창에서 geocoding을 검색해서 들어간 후 사용으로 설정
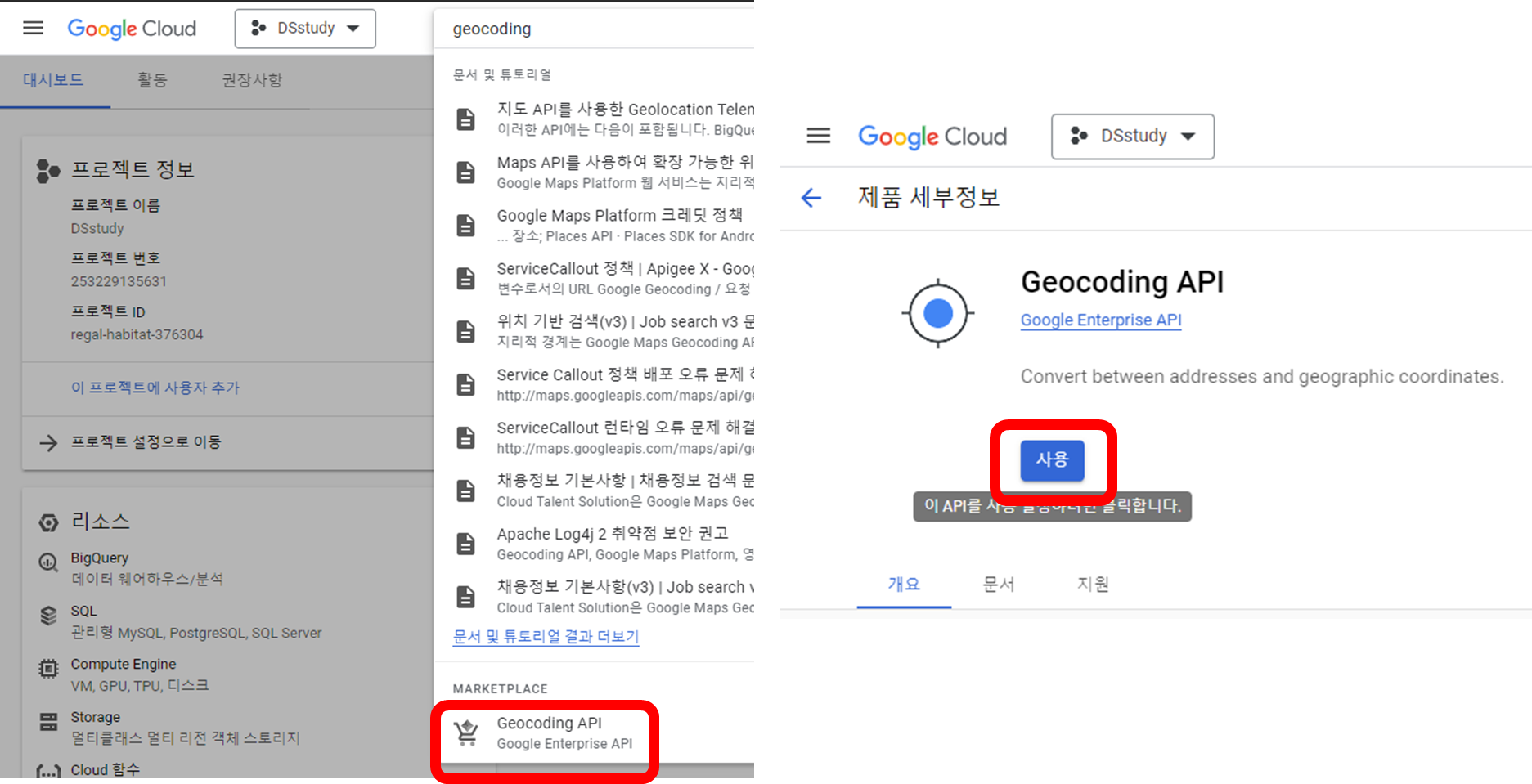
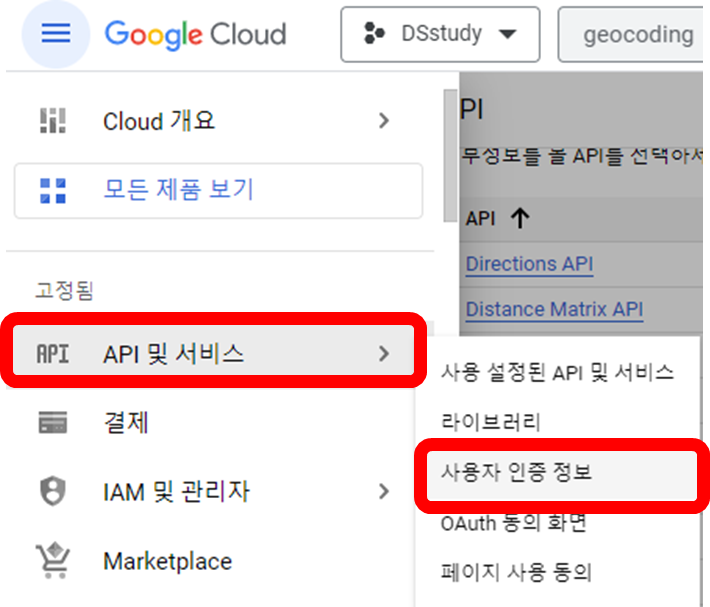
구글 맵스 플랫폼으로 이동 후 API 제한사항, geocoding API를 선택하고 키 제한 클릭
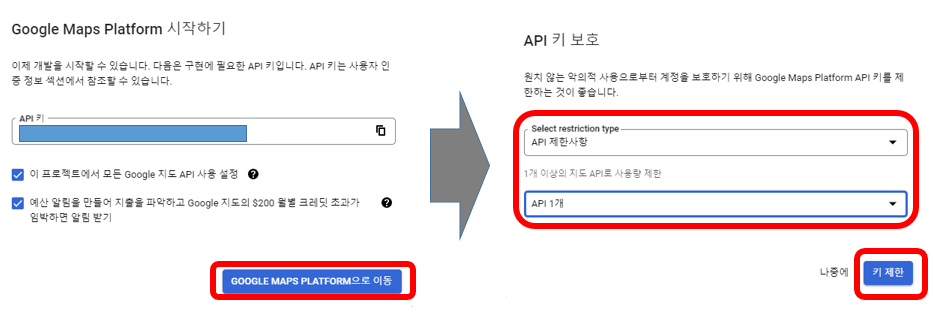
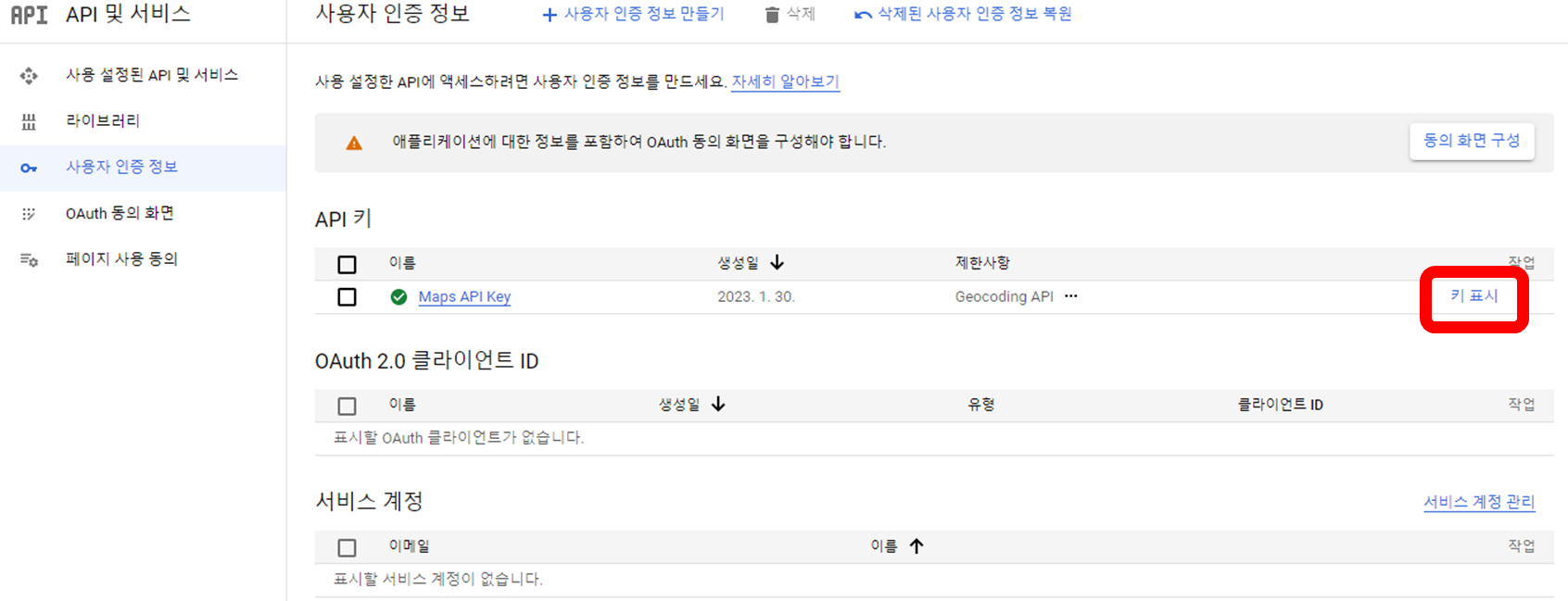
사용자인증정보로 들어가서 키를 복사해서 Python에 활용한다
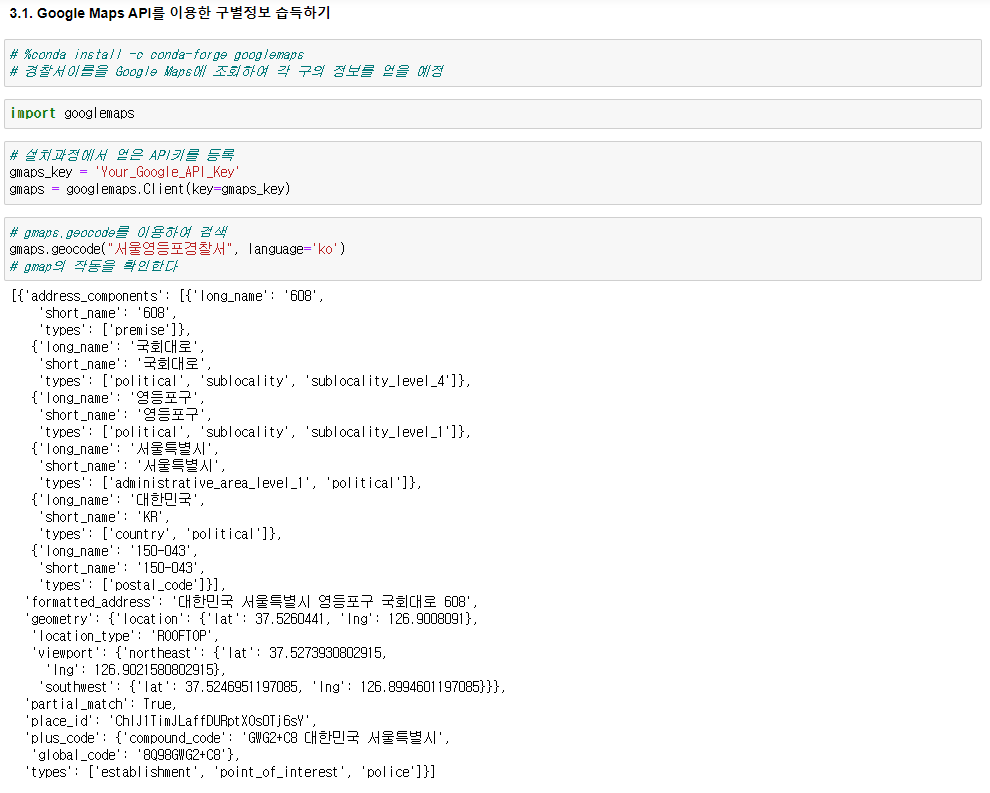
3.1. google maps를 이용하여 구별 정보 습득하기
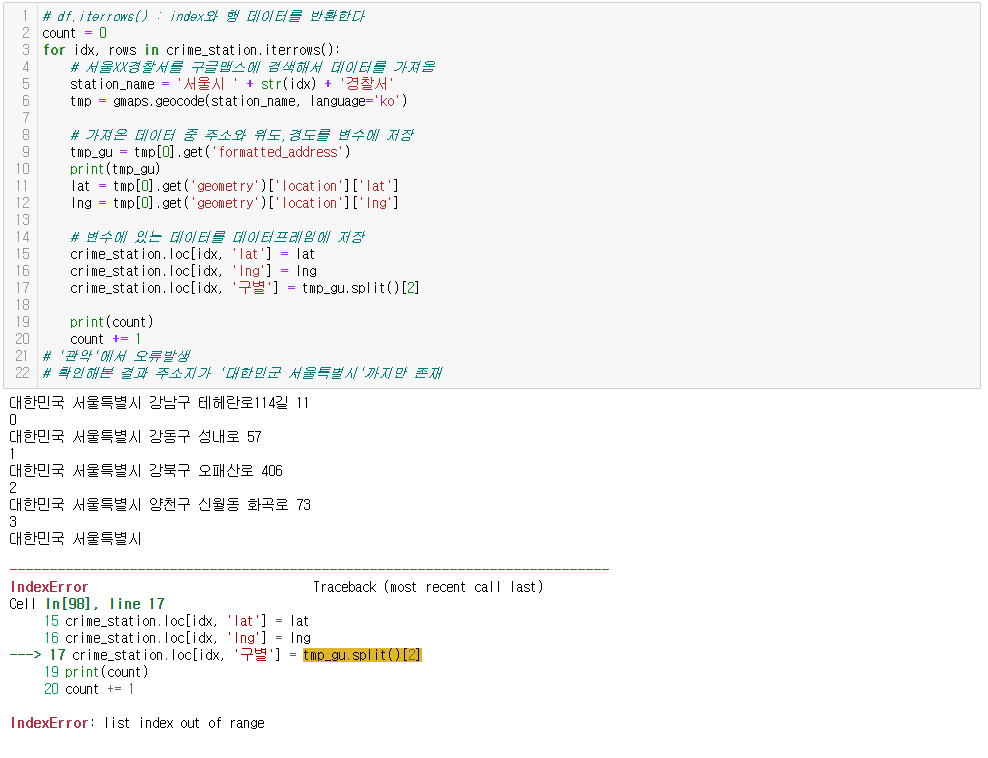
오류발생
- '관악'에서 주소지가 정상적으로 출력되지 않음
해결
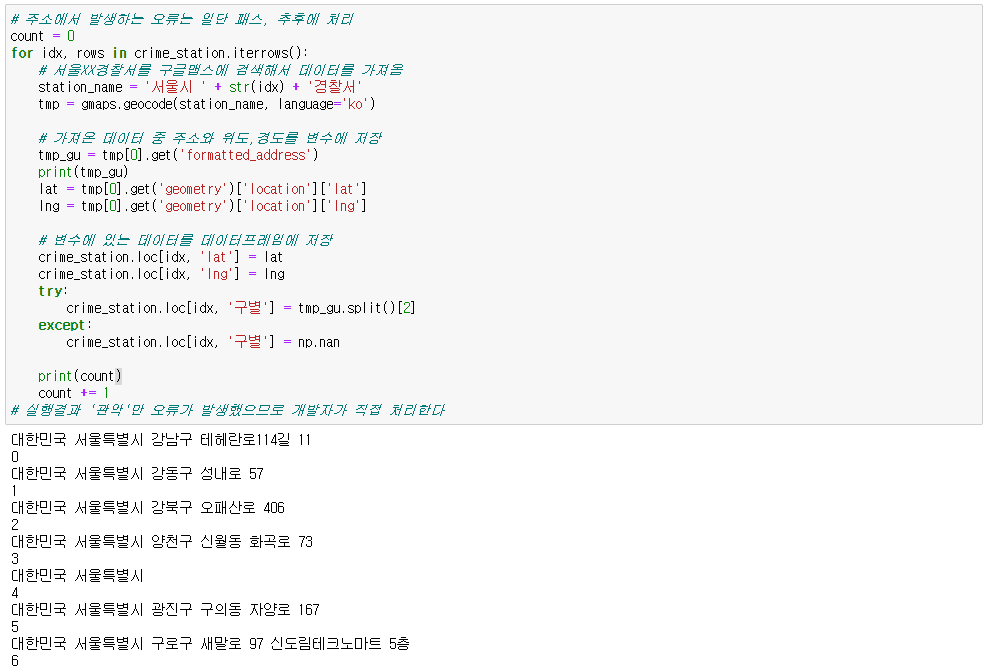
- 확인 결과, '관악'에서만 오류가 발생하였으므로 사용자가 직접처리
📝입력
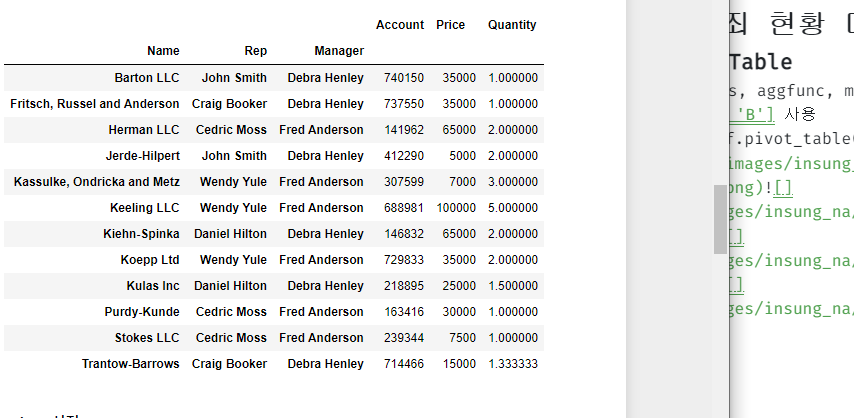
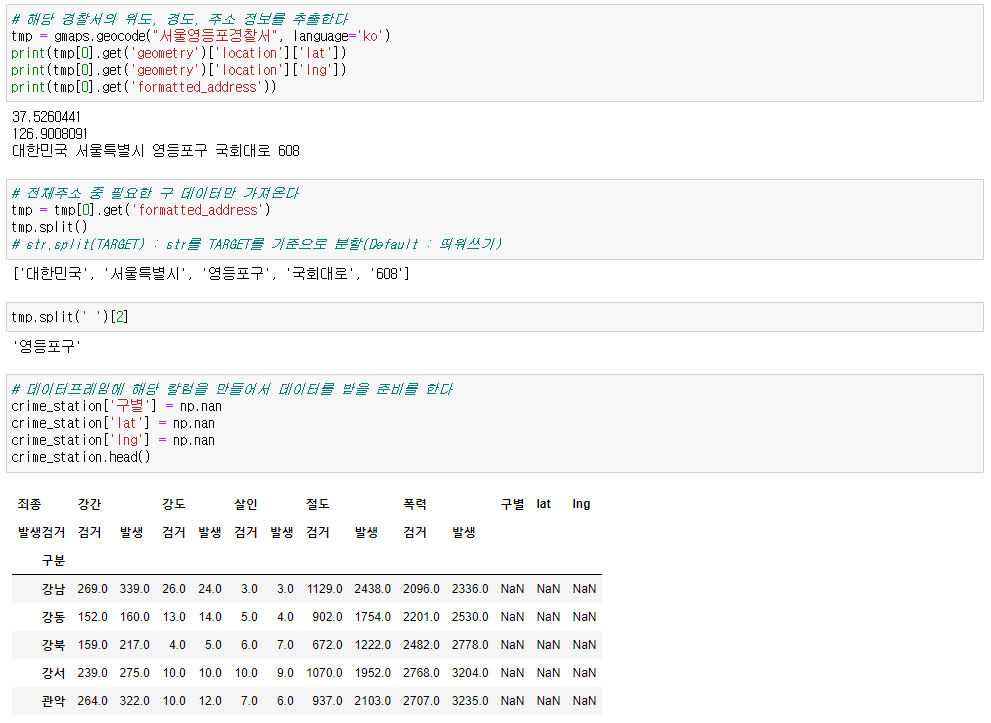
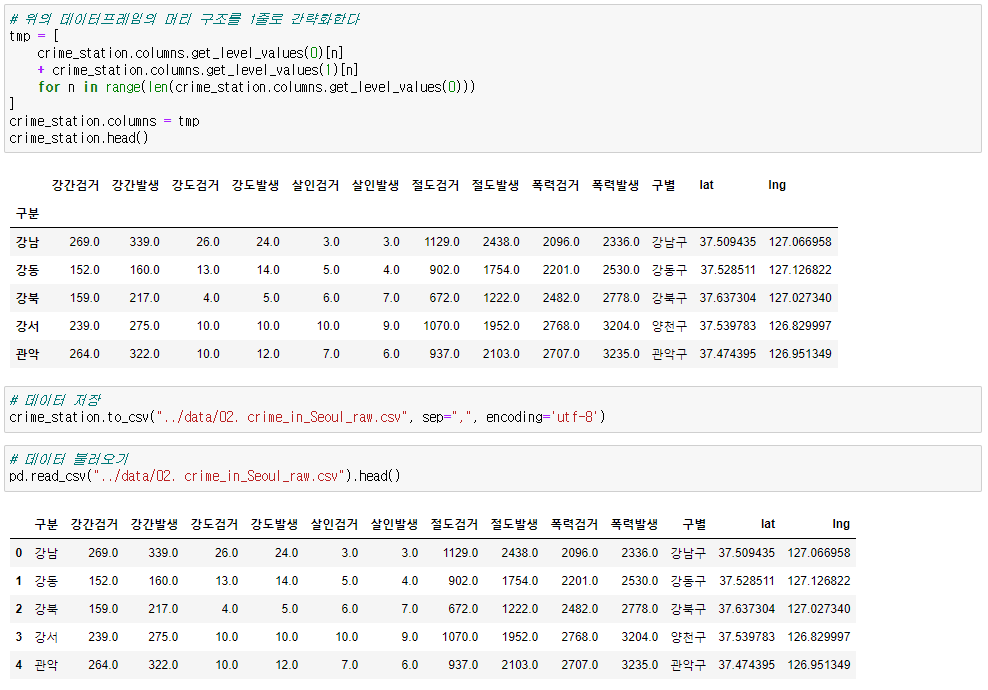
import googlemaps gmaps_key = 'Your_Google_API_Key' gmaps = googlemaps.Client(key=gmaps_key) # 데이터 구조 확인, 데이터추출방법 결정 gmaps.geocode("서울영등포경찰서", language='ko') # # 데이터프레임에 구조만들기 crime_station['구별'] = np.nan crime_station['lat'] = np.nan crime_station['lng'] = np.nan # # 주소, 위도, 경도 정보 가져오기 count = 0 for idx, rows in crime_station.iterrows(): # 서울XX경찰서를 구글맵스에 검색해서 데이터를 가져옴 station_name = '서울시 ' + str(idx) + '경찰서' tmp = gmaps.geocode(station_name, language='ko') # # 가져온 데이터 중 주소와 위도,경도를 변수에 저장 tmp_gu = tmp[0].get('formatted_address') lat = tmp[0].get('geometry')['location']['lat'] lng = tmp[0].get('geometry')['location']['lng'] # # 변수에 있는 데이터를 데이터프레임에 저장 crime_station.loc[idx, 'lat'] = lat crime_station.loc[idx, 'lng'] = lng # # '관악' 오류 해결 try: crime_station.loc[idx, '구별'] = tmp_gu.split()[2] except: if idx == '관악': crime_station.loc['관악', '구별'] = '관악구' else: crime_station.loc[idx, '구별'] = np.nan # count += 1 # 데이터프레임의 머리 구조를 1줄로 간략화 tmp = [ crime_station.columns.get_level_values(0)[n] + crime_station.columns.get_level_values(1)[n] for n in range(len(crime_station.columns.get_level_values(0))) ] crime_station.columns = tmp crime_station.head() # 데이터 저장 crime_station.to_csv("../data/02. crime_in_Seoul_raw.csv", sep=",", encoding='utf-8')
🧾출력
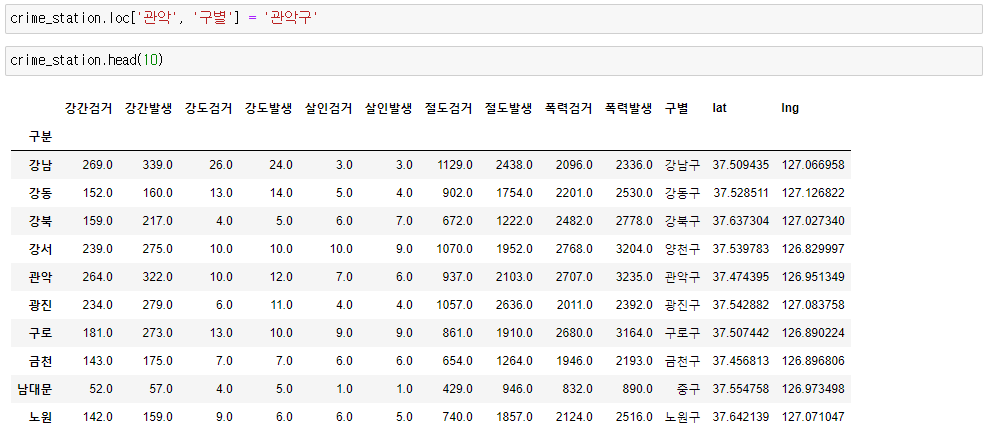
🧾crime_station.head()
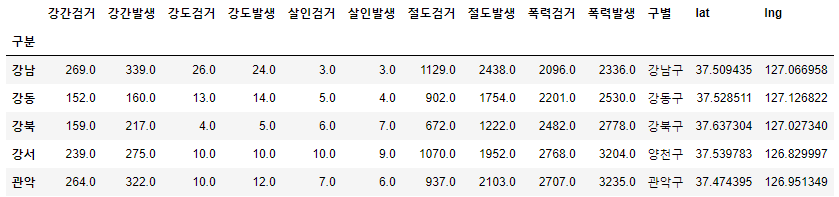
📌4. 구별데이터로 변경하기
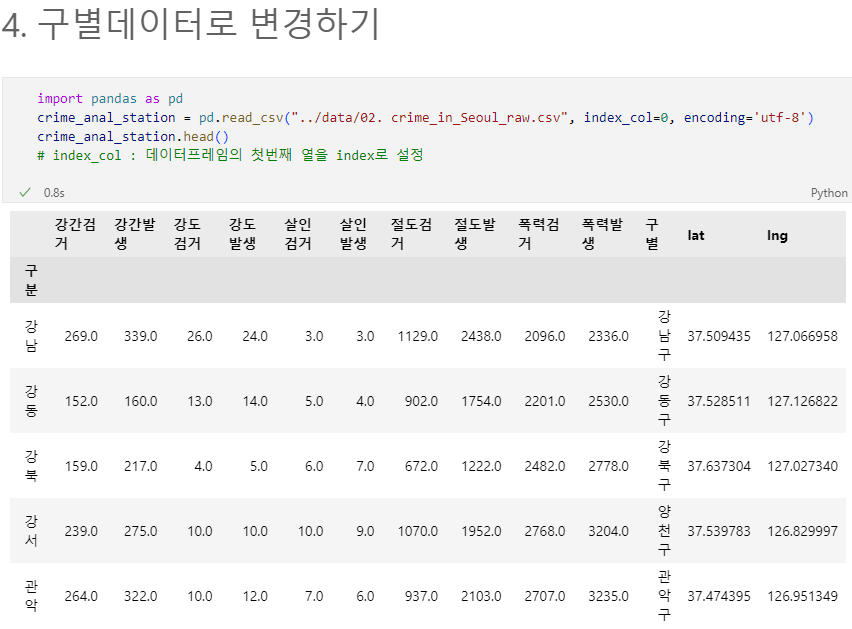
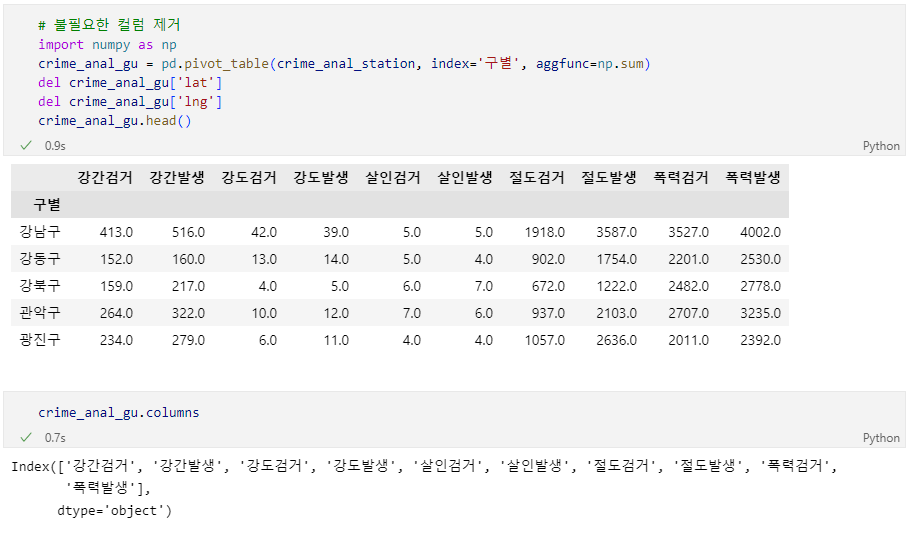
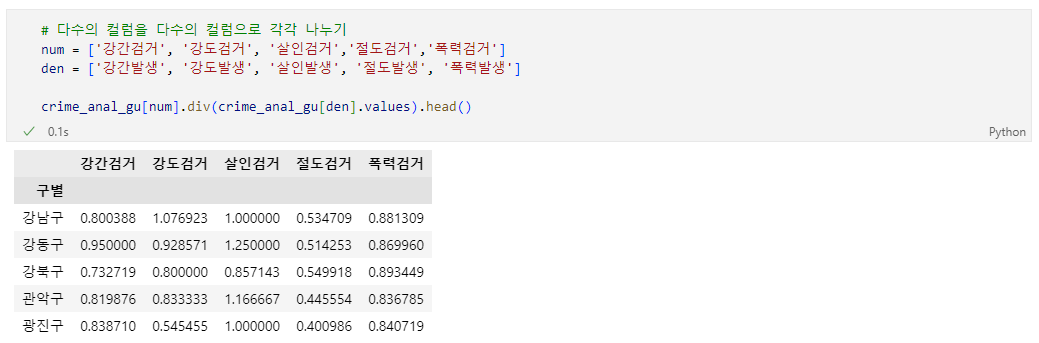
📝입력
import pandas as pd
import numpy as np
crime_anal_station = pd.read_csv("../data/02. crime_in_Seoul_raw.csv", index_col=0, encoding='utf-8')
# 구별로 데이터 정리
crime_anal_gu = pd.pivot_table(crime_anal_station, index='구별', aggfunc=np.sum)
del crime_anal_gu['lat']
del crime_anal_gu['lng']
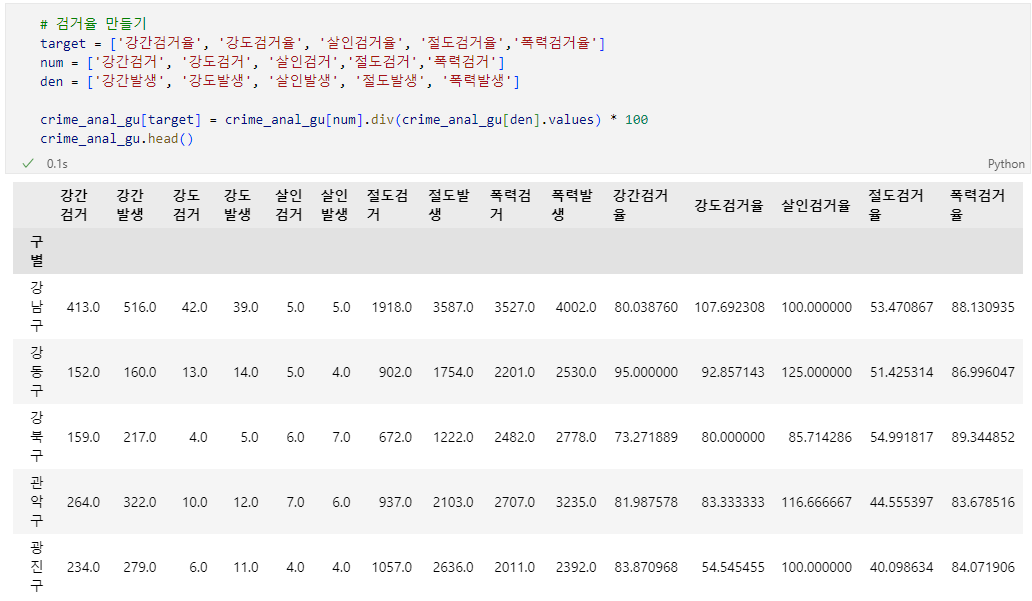
# 각 범죄의 검거율 생성
target = ['강간검거율', '강도검거율', '살인검거율', '절도검거율','폭력검거율']
num = ['강간검거', '강도검거', '살인검거','절도검거','폭력검거']
den = ['강간발생', '강도발생', '살인발생', '절도발생', '폭력발생']
crime_anal_gu[target] = crime_anal_gu[num].div(crime_anal_gu[den].values) * 100
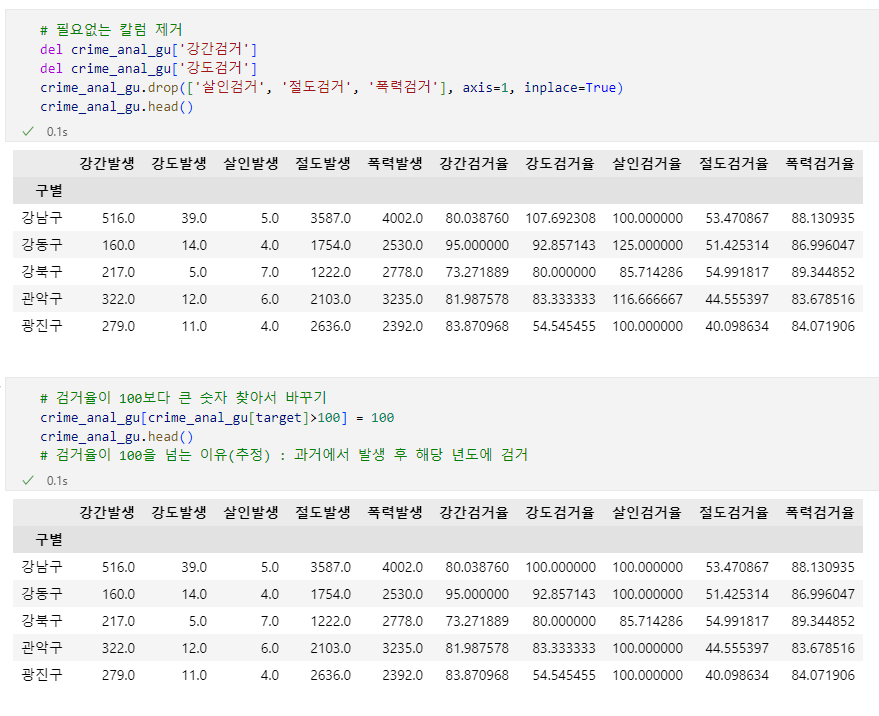
# 불필요한 5대 범죄 검거 컬럼 제거
del crime_anal_gu['강간검거']
del crime_anal_gu['강도검거']
crime_anal_gu.drop(['살인검거', '절도검거', '폭력검거'], axis=1, inplace=True)
# 검거율 100으로 제한, 컬럼명 변경
crime_anal_gu[crime_anal_gu[target]>100] = 100
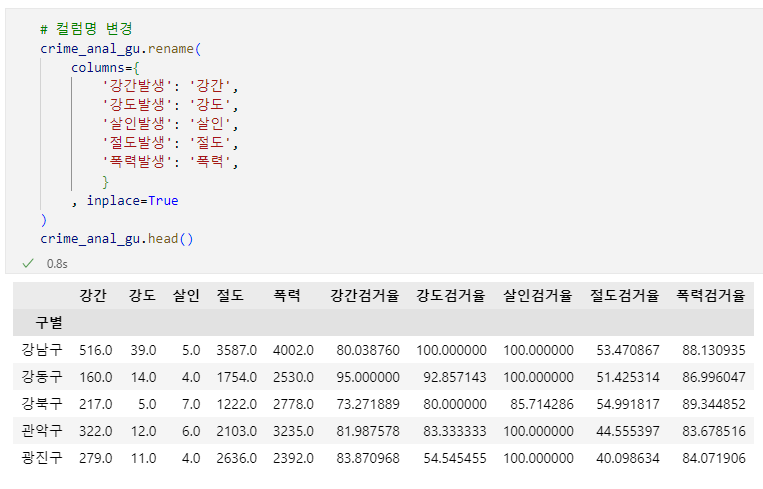
crime_anal_gu.rename(
columns={
'강간발생': '강간',
'강도발생': '강도',
'살인발생': '살인',
'절도발생': '절도',
'폭력발생': '폭력',
}, inplace=True
)
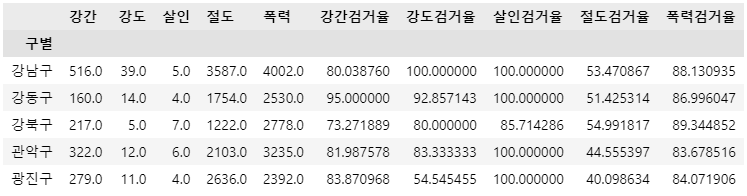
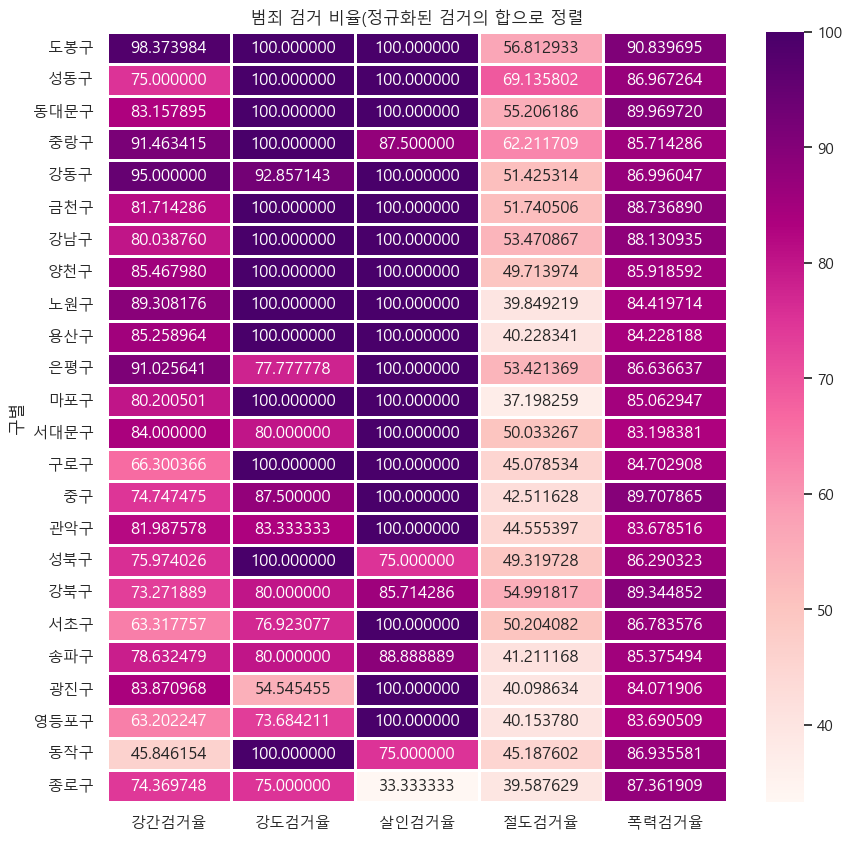
crime_anal_gu.head()🧾출력 : crime_anal_gu.head()
📌5. 범죄데이터 정렬을 위한 데이터 정리


📝입력
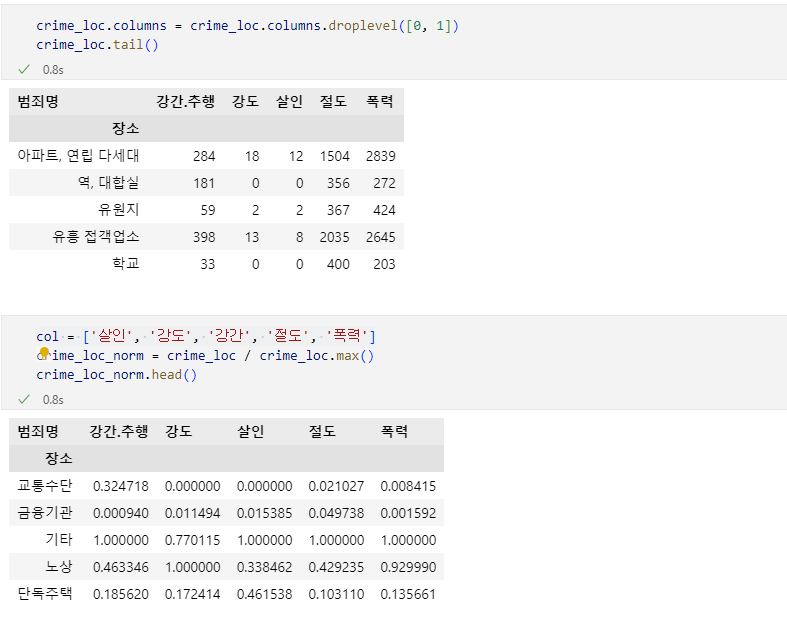
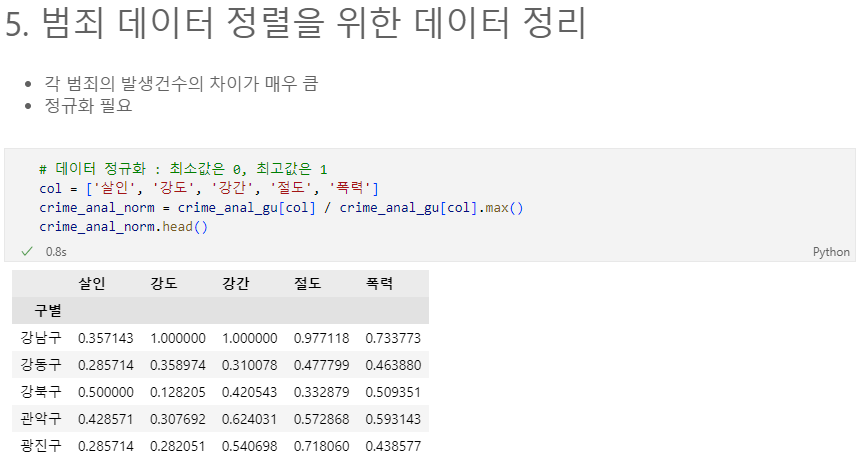
# 데이터 정규화 : 최소값은 0, 최고값은 1
col = ['살인', '강도', '강간', '절도', '폭력']
crime_anal_norm = crime_anal_gu[col] / crime_anal_gu[col].max()
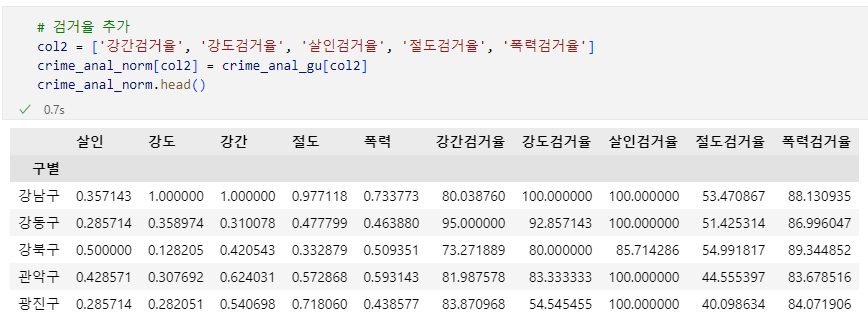
# 검거율 추가
col2 = ['강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율']
crime_anal_norm[col2] = crime_anal_gu[col2]
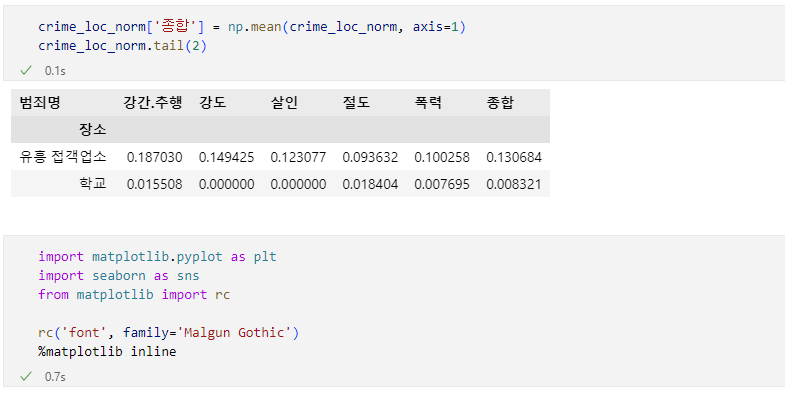
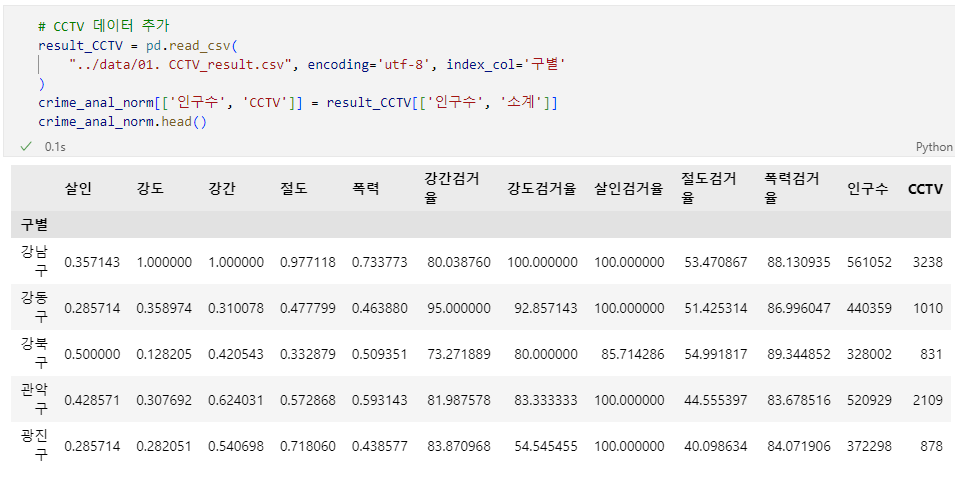
# CCTV 데이터 추가
result_CCTV = pd.read_csv(
"../data/01. CCTV_result.csv", encoding='utf-8', index_col='구별'
)
crime_anal_norm[['인구수', 'CCTV']] = result_CCTV[['인구수', '소계']]
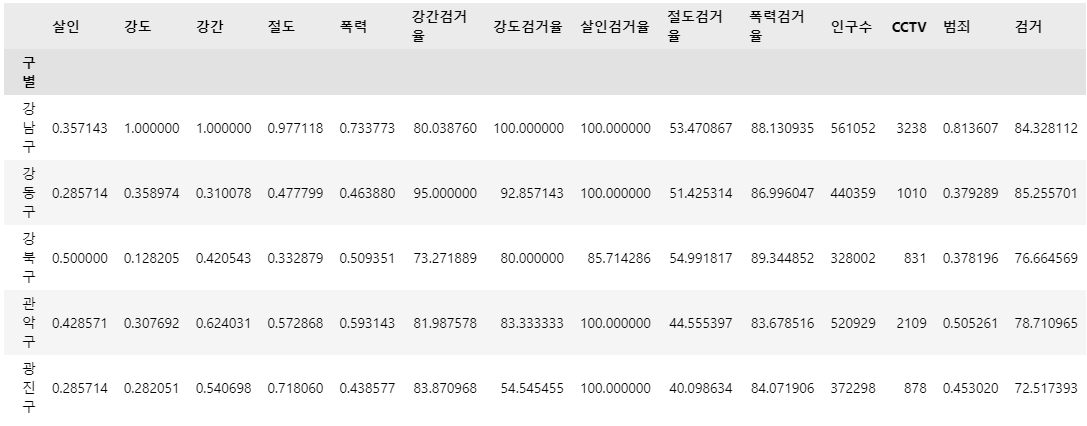
# 범죄와 검거 컬럼 추가
col = ['살인', '강도', '강간', '절도', '폭력']
col2 = ['강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율']
crime_anal_norm['범죄'] = np.mean(crime_anal_norm[col], axis=1)
crime_anal_norm['검거'] = np.mean(crime_anal_norm[col2], axis=1)
crime_anal_norm.head()🧾출력 : crime_anal_norm.head()
📌6. 범죄 현황 데이터 시각화
6.0. seaborn
- matplotlib을 기반으로 다양한 색상 테마와 통계용 차트 등의 기능을 추가한 시각화패키지
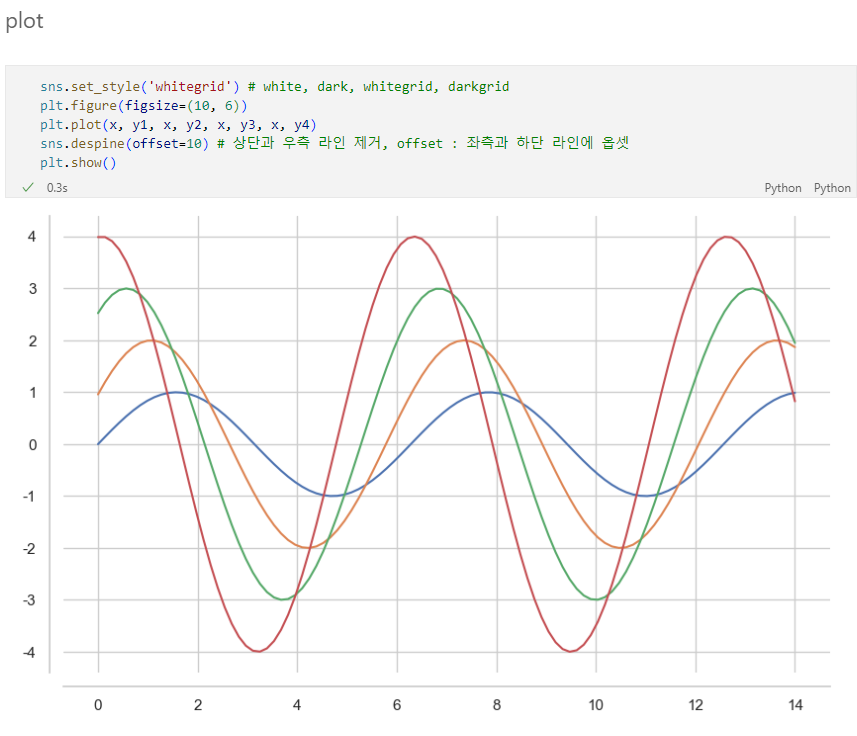
예제데이터셋 : tips
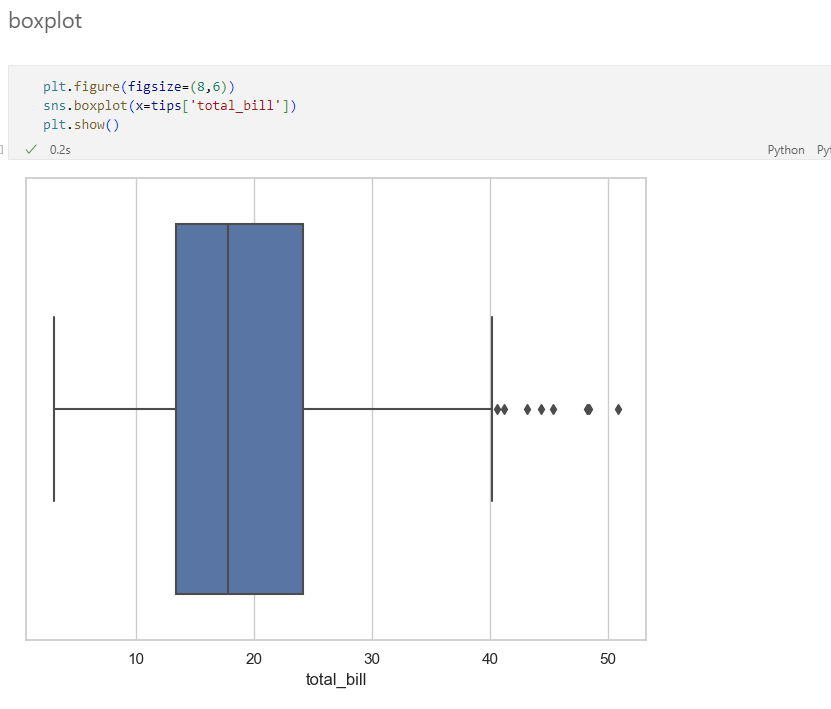
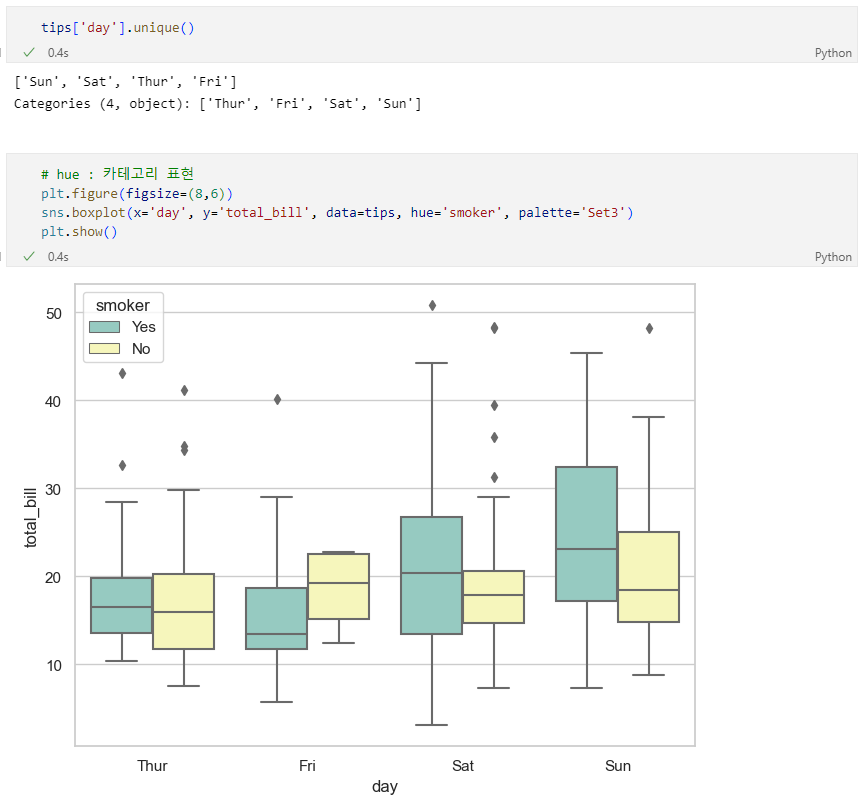
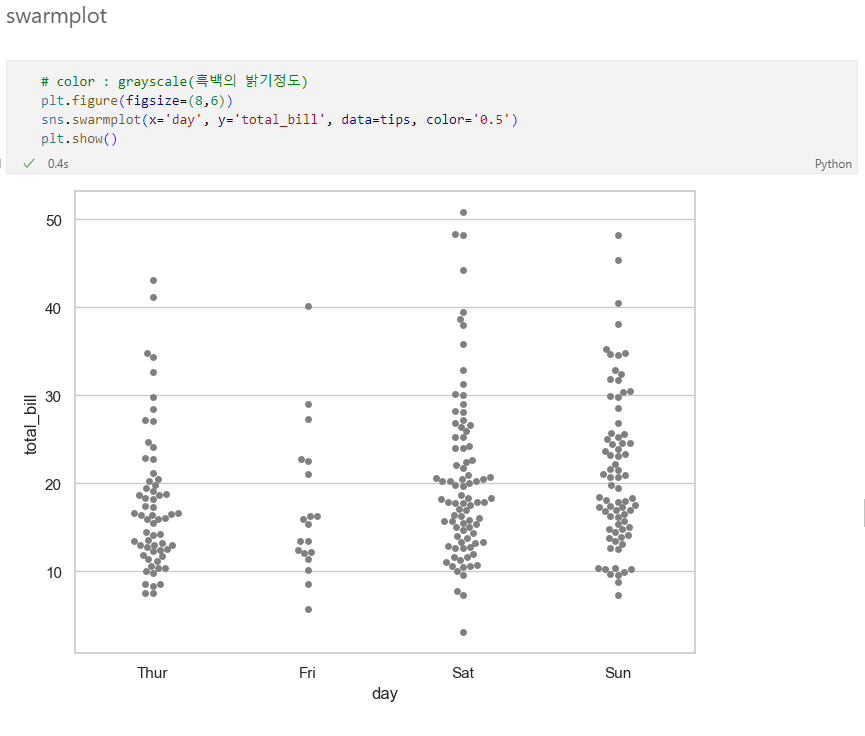
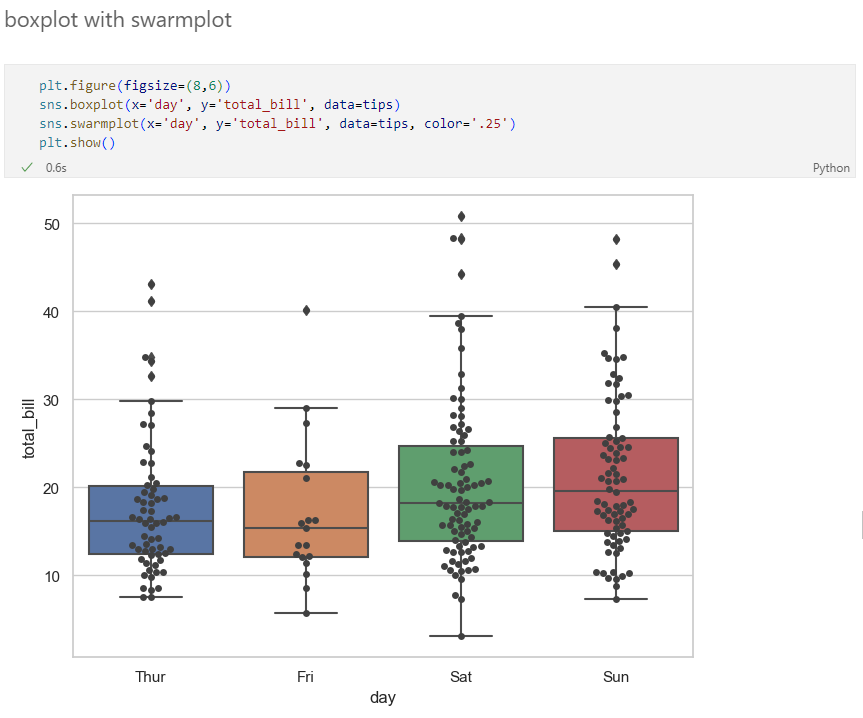
boxplot & swarmplot
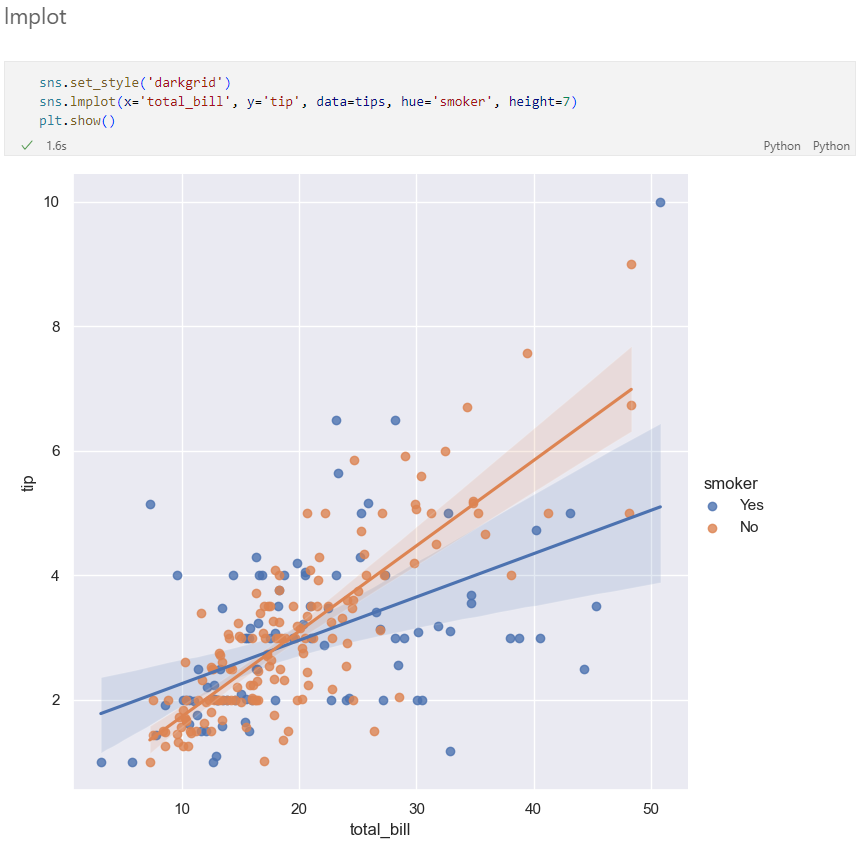
lmplot
예제데이터셋 : flights
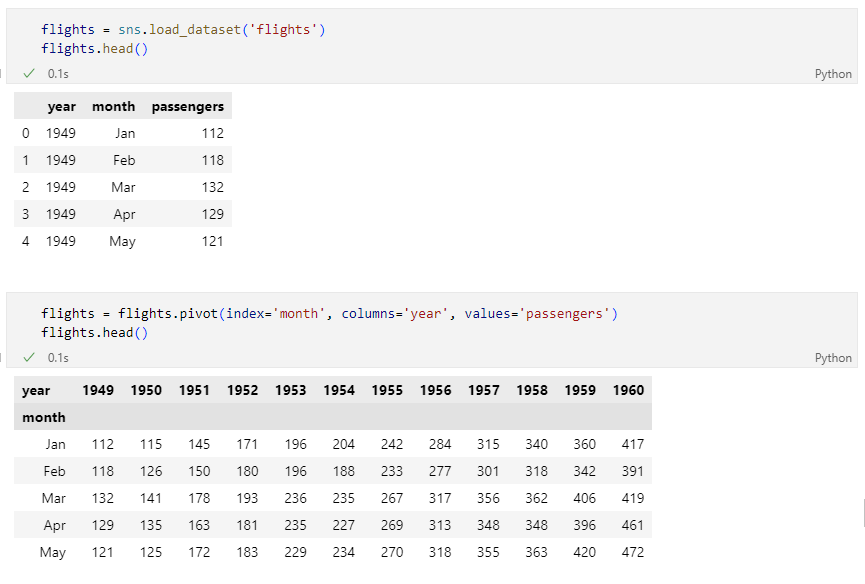
heatmap
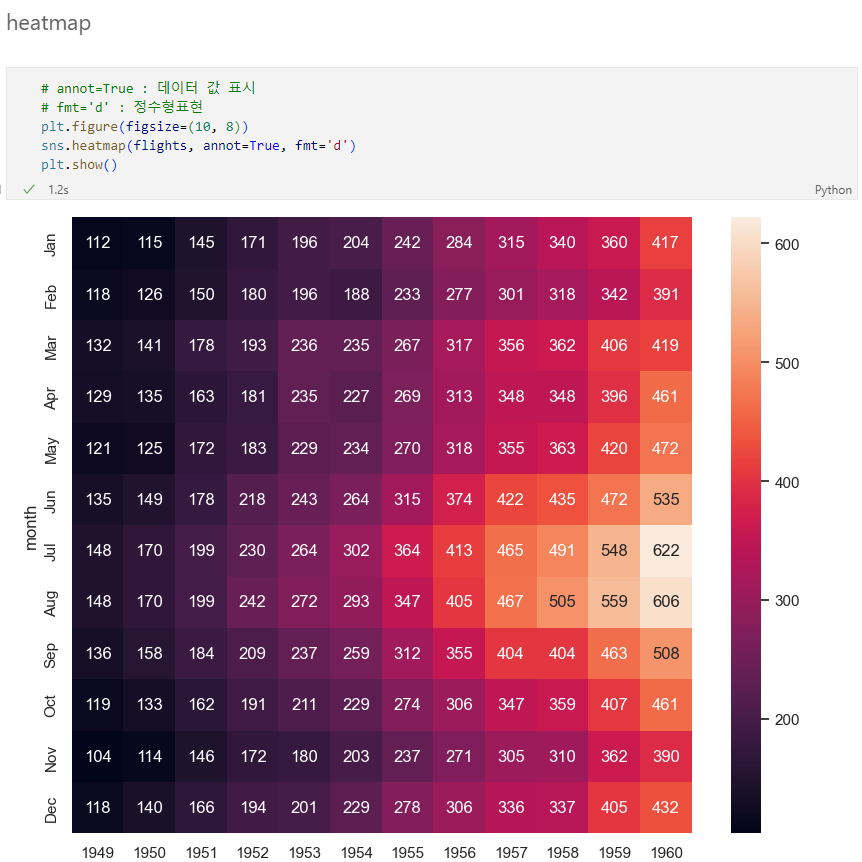
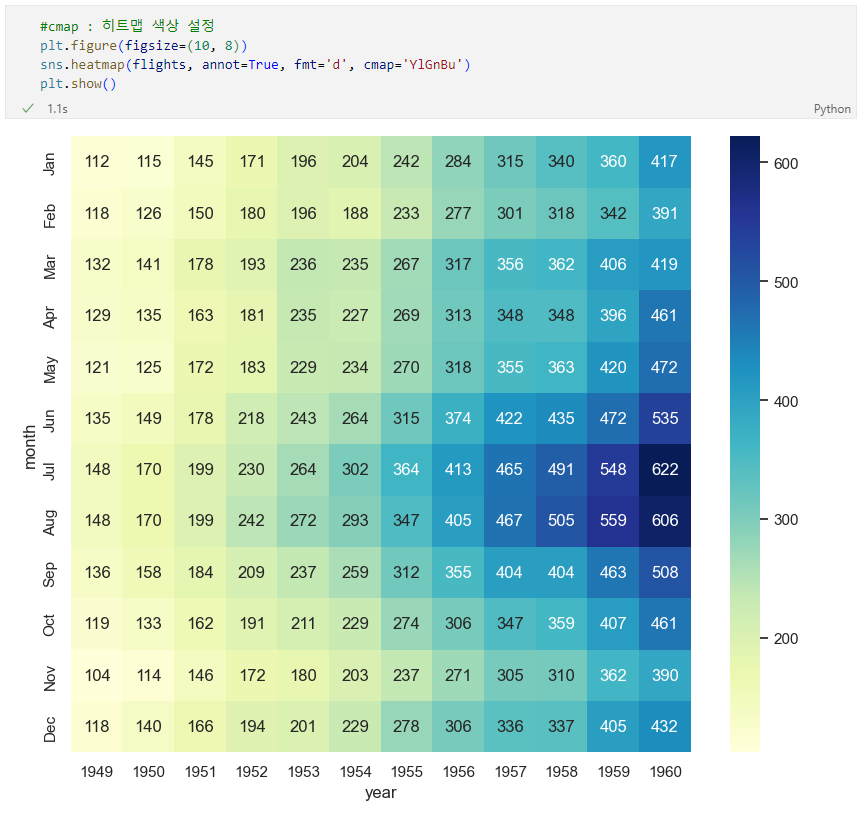
예제데이터셋 : iris
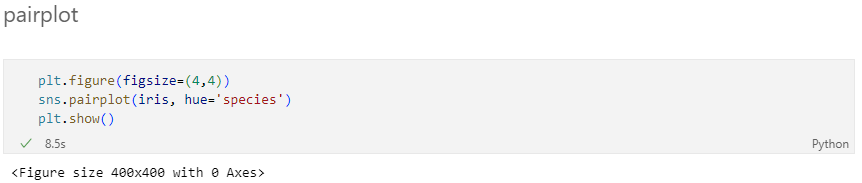
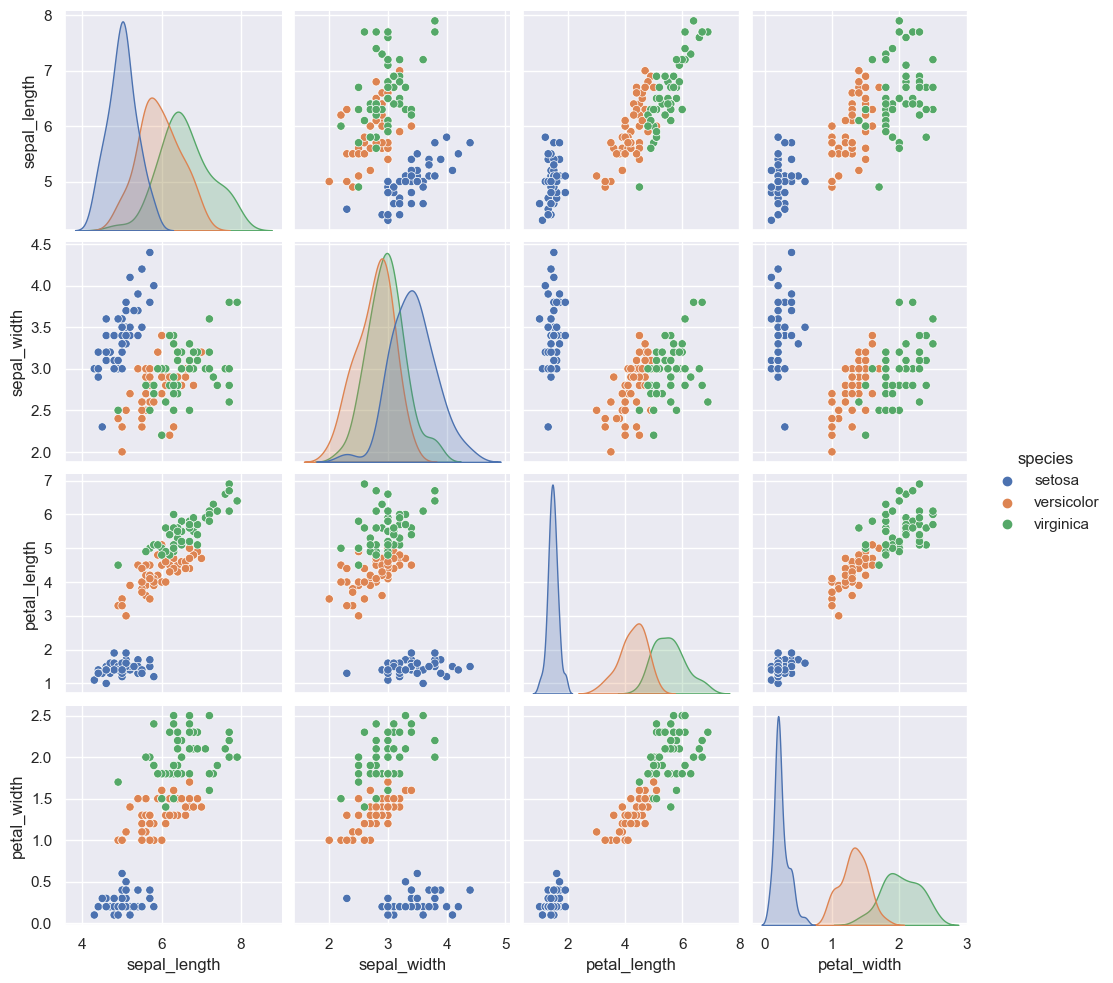
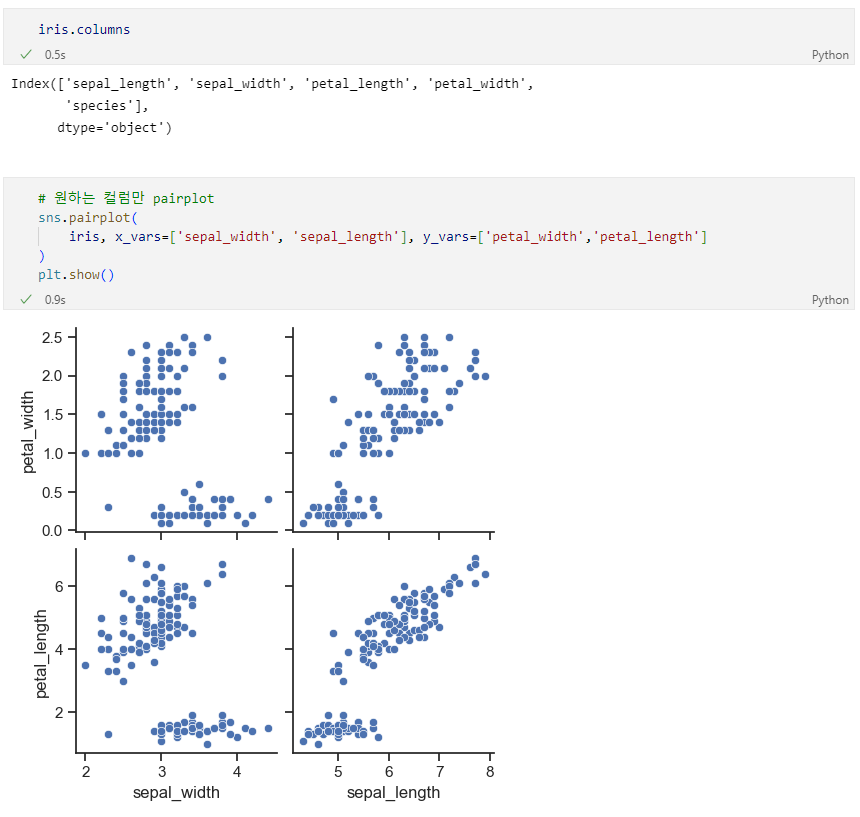
pairplot
예제데이터셋 : anscombe
lmplot 속성 : order, robust
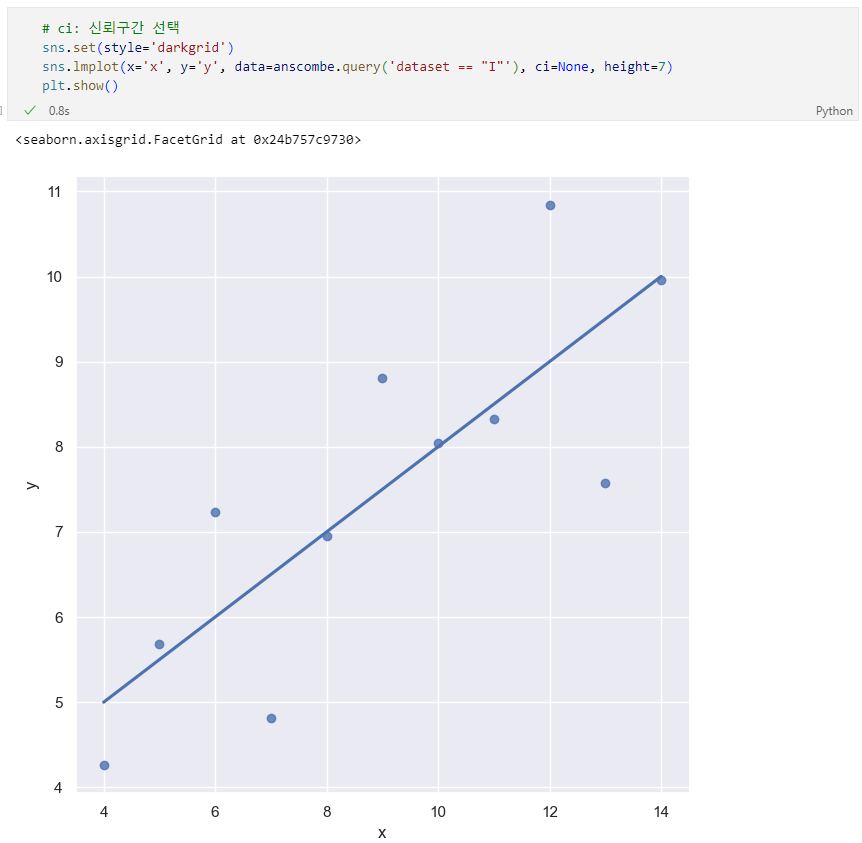
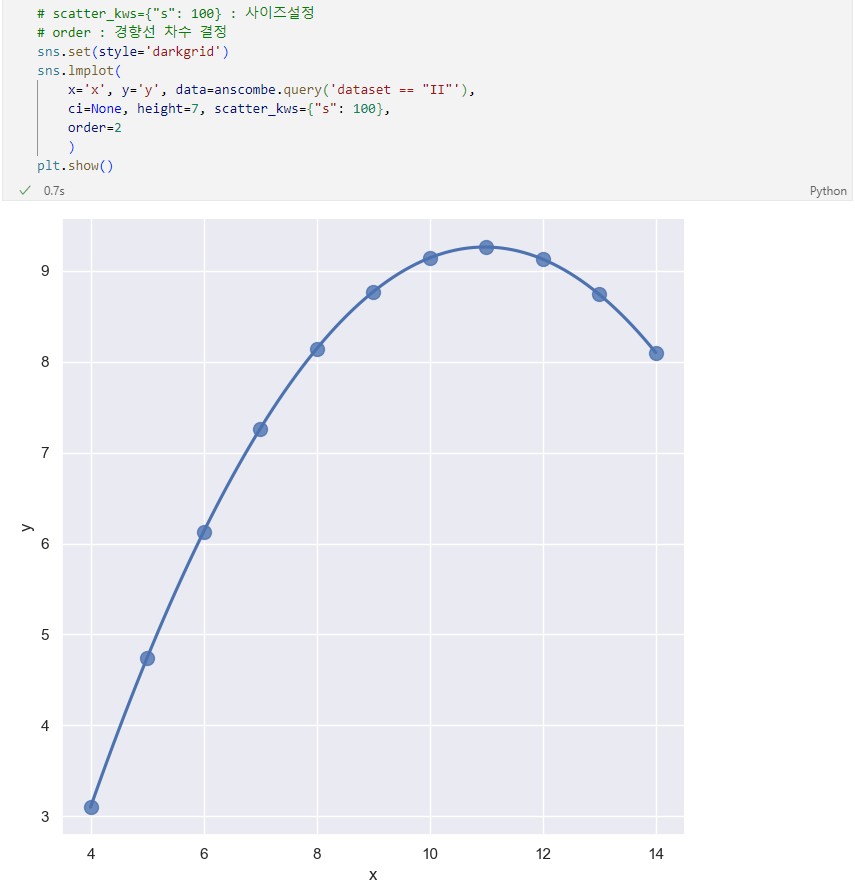
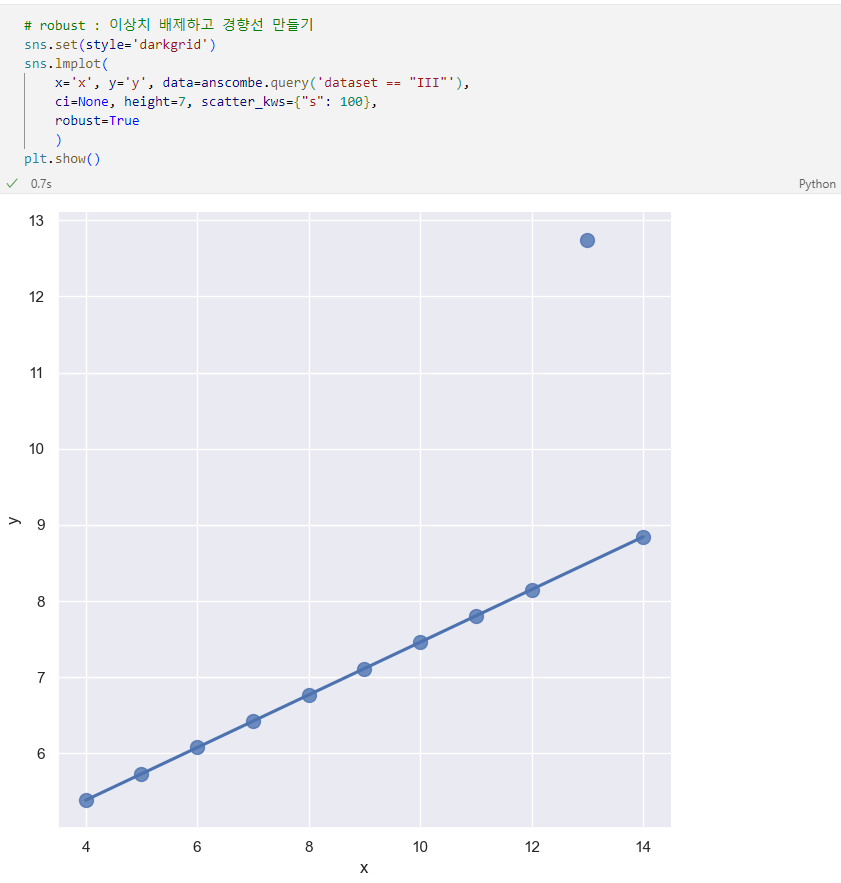
6.1. 서울시 범죄 현황 데이터 시각화

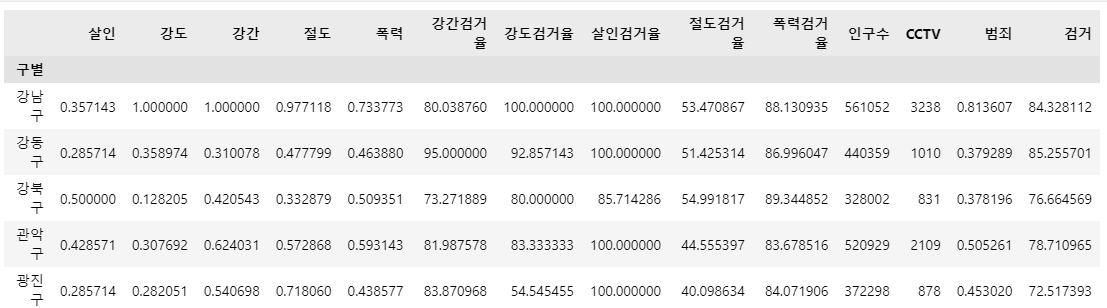

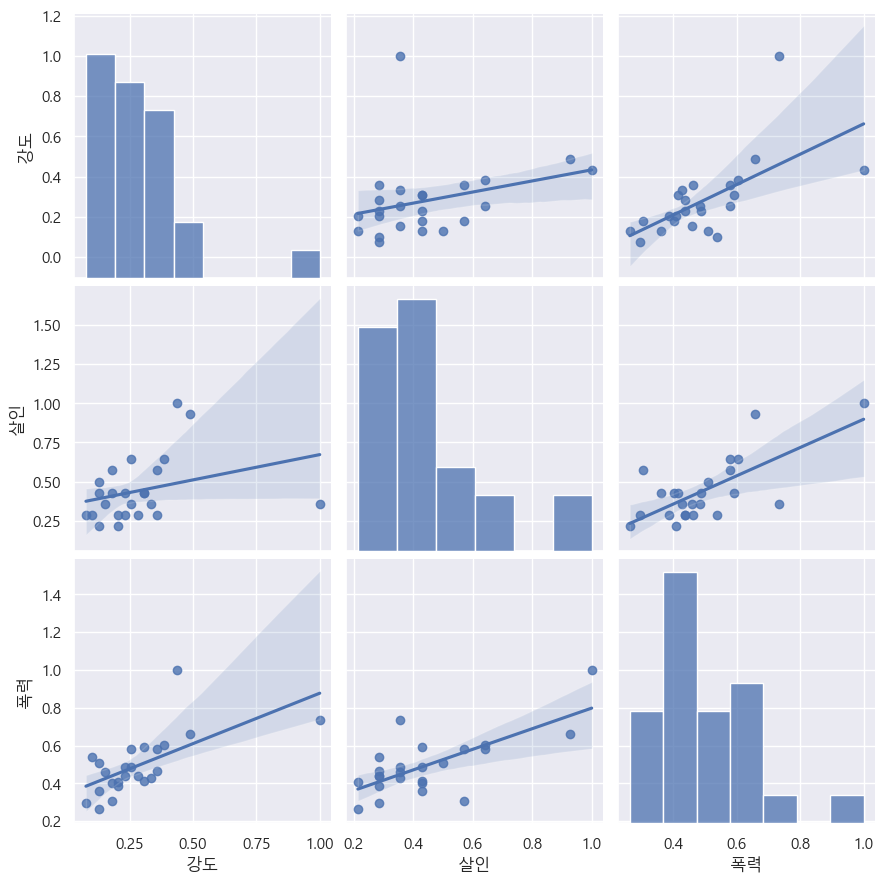

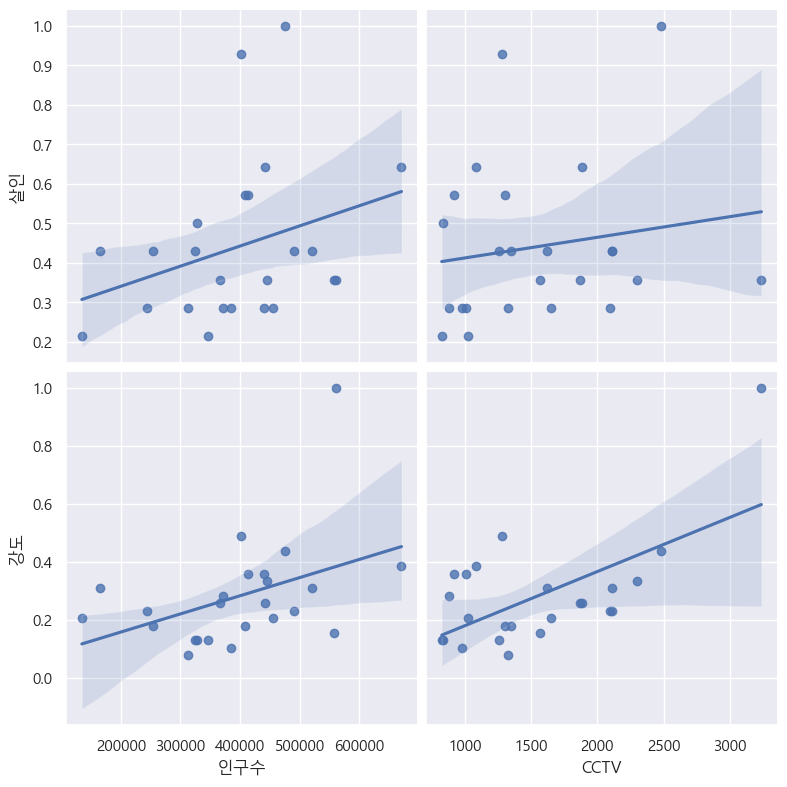

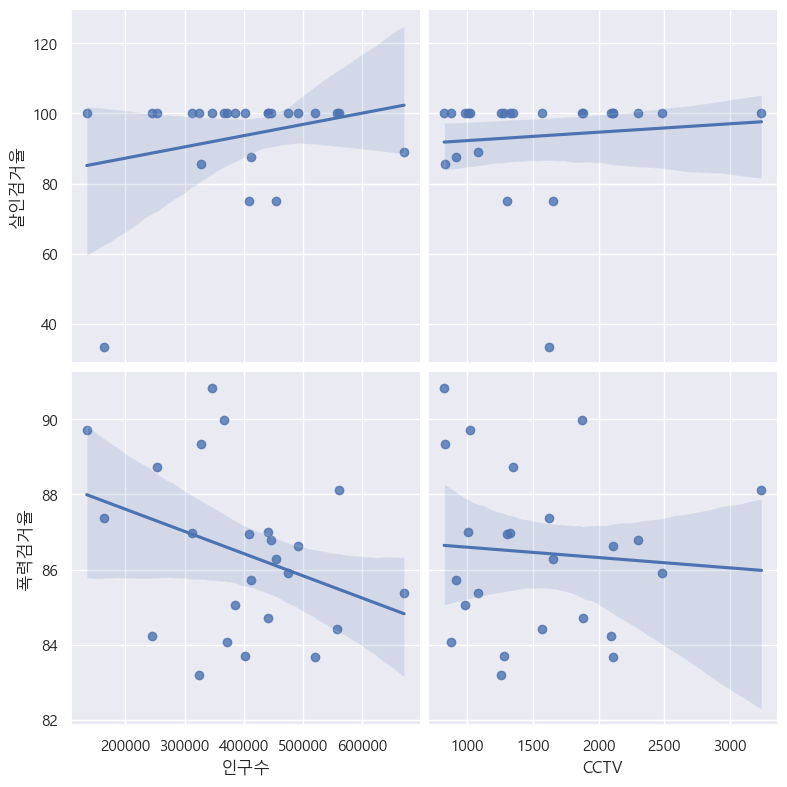

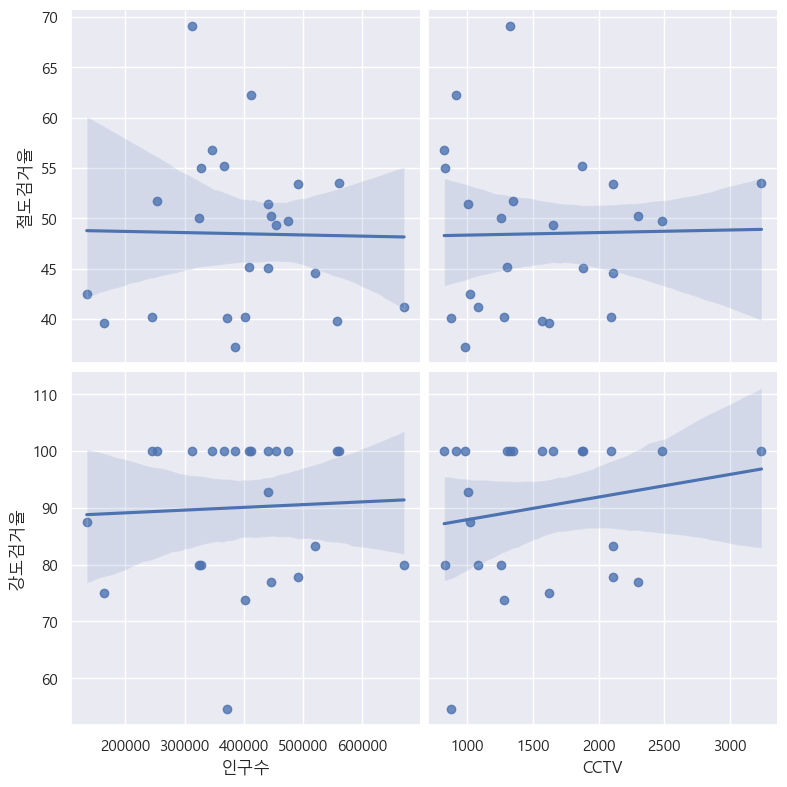




오류발견
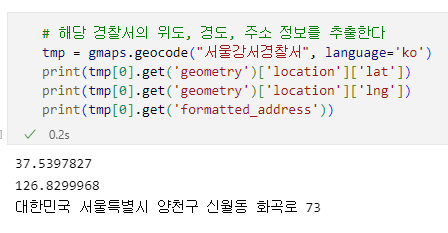
데이터수집 코드 수정
# 주소, 위도, 경도 정보 가져오기
count = 0
for idx, rows in crime_station.iterrows():
# 서울XX경찰서를 구글맵스에 검색해서 데이터를 가져옴
station_name = '서울시 ' + str(idx) + '경찰서'
tmp = gmaps.geocode(station_name, language='ko')
# 가져온 데이터 중 주소와 위도,경도를 변수에 저장
tmp_gu = tmp[0].get('formatted_address')
lat = tmp[0].get('geometry')['location']['lat']
lng = tmp[0].get('geometry')['location']['lng']
print(tmp_gu)
# 변수에 있는 데이터를 데이터프레임에 저장
crime_station.loc[idx, 'lat'] = lat
crime_station.loc[idx, 'lng'] = lng
# '강서', '관악' 오류 해결
if idx in ['관악', '강서']:
if idx == '관악':
crime_station.loc['관악', '구별'] = '관악구'
elif idx == '강서':
crime_station.loc['강서', '구별'] = '강서구'
else:
crime_station.loc[idx, '구별'] = tmp_gu.split()[2]
print(count)
count += 1
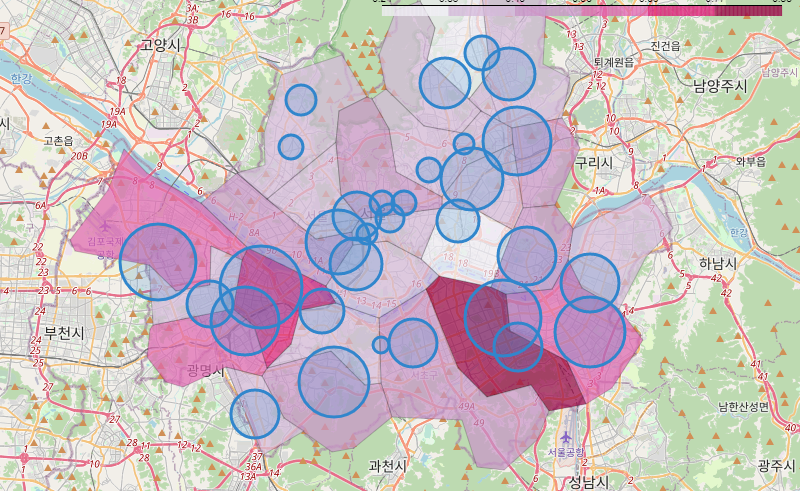
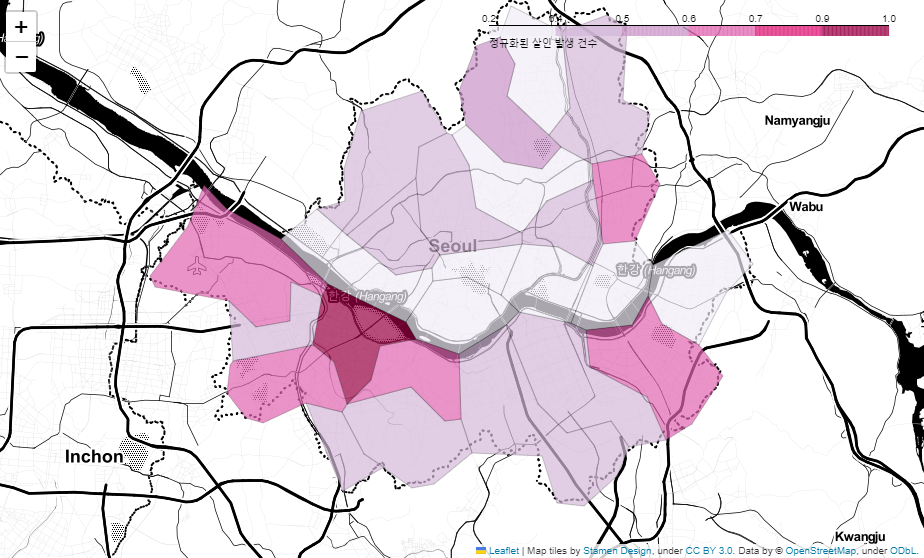
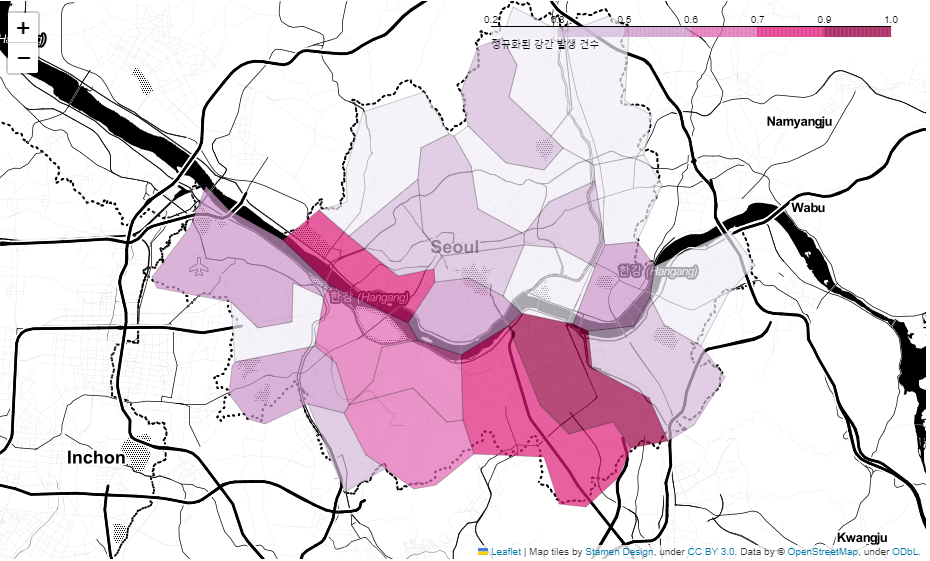
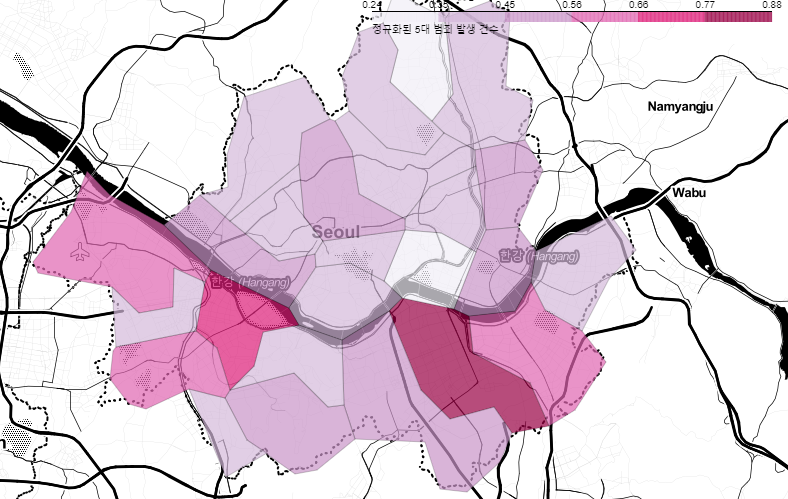
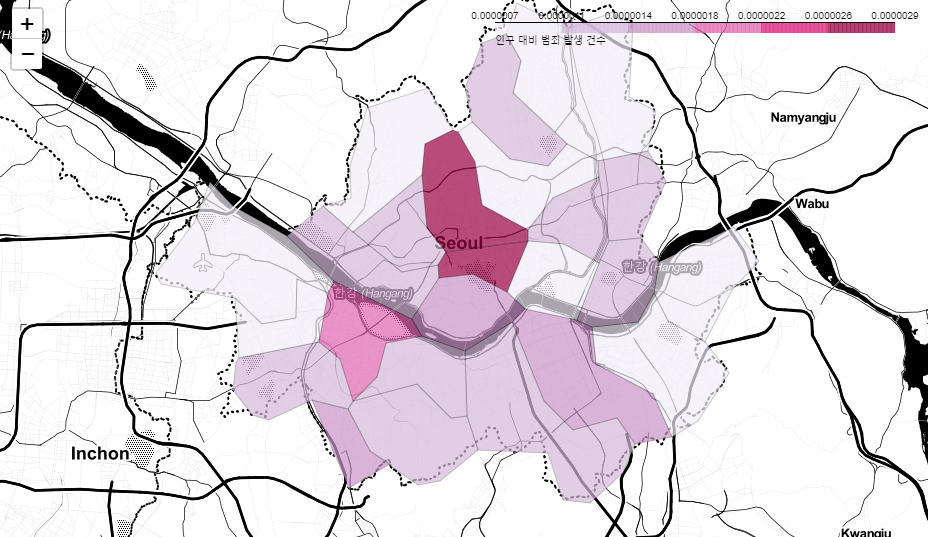
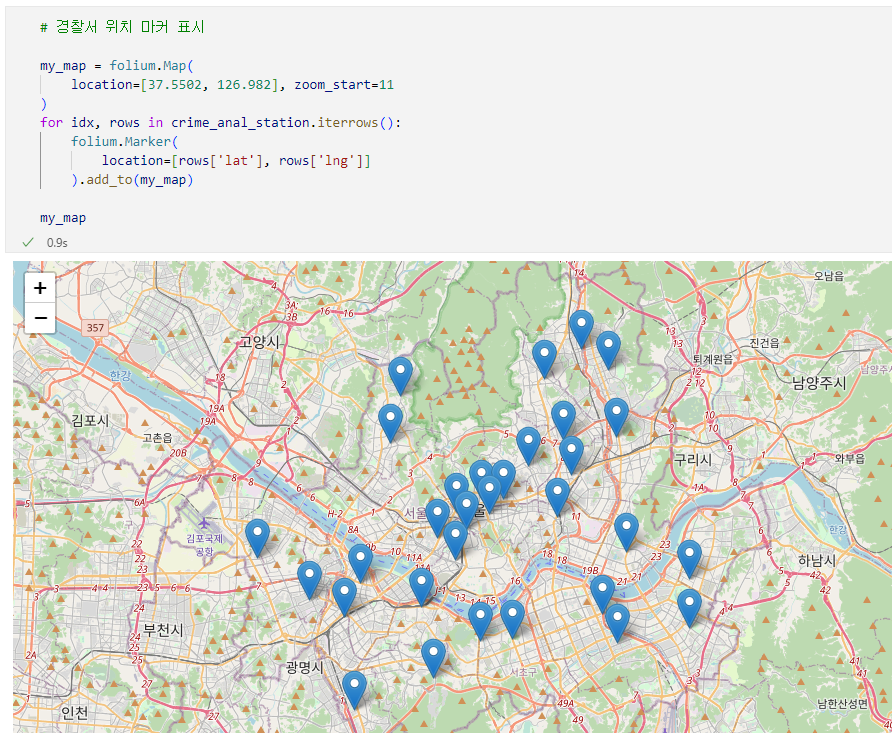
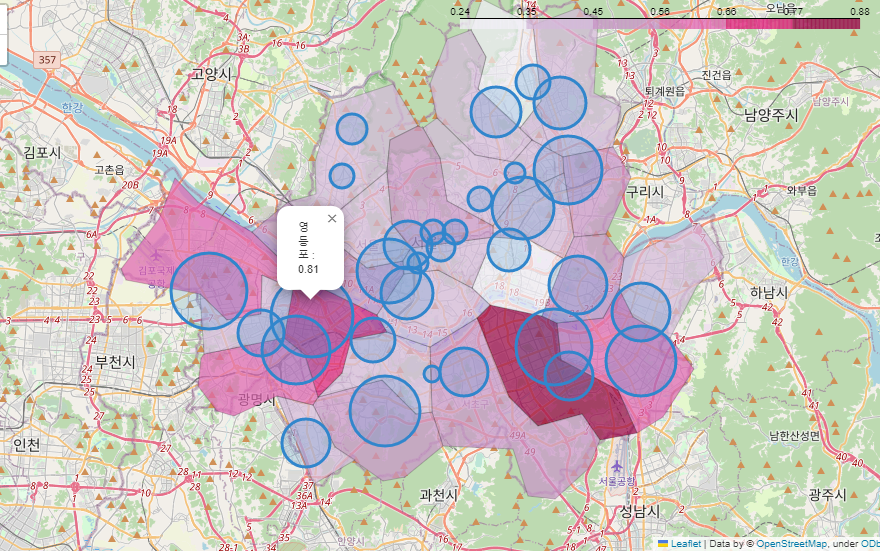
📌7. 서울시 범죄 현황 지도 시각화
7.0. Folium
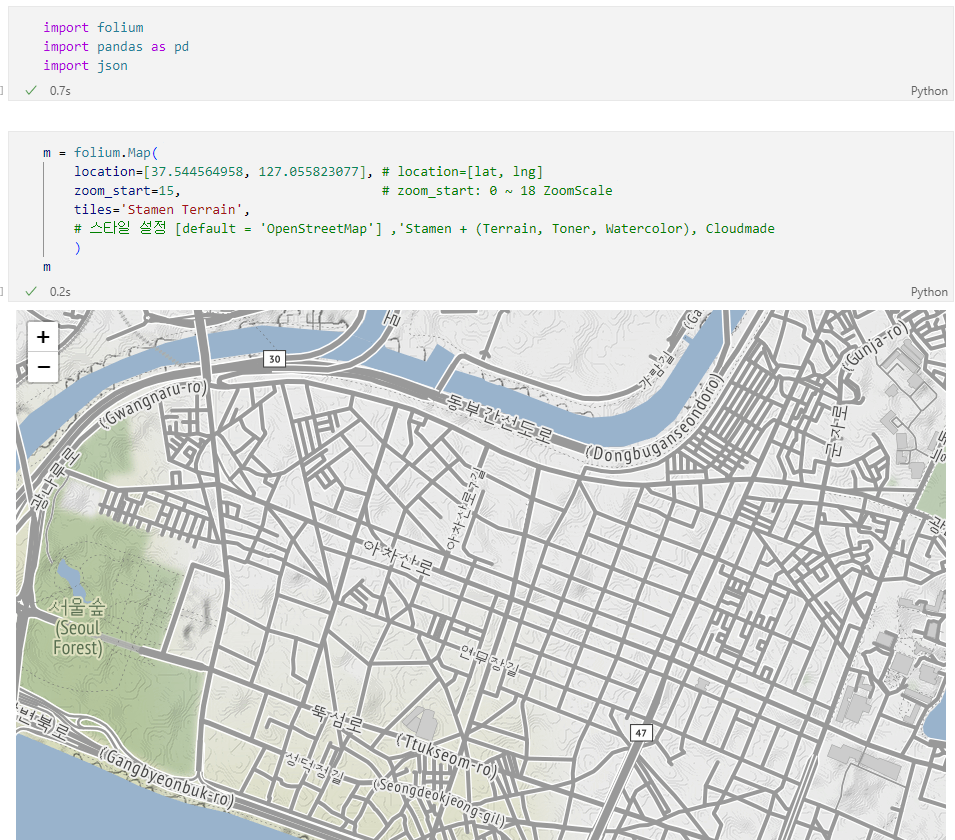



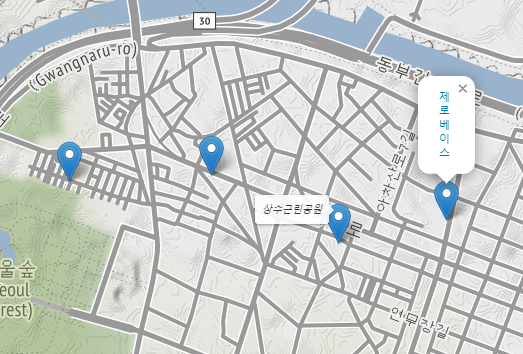
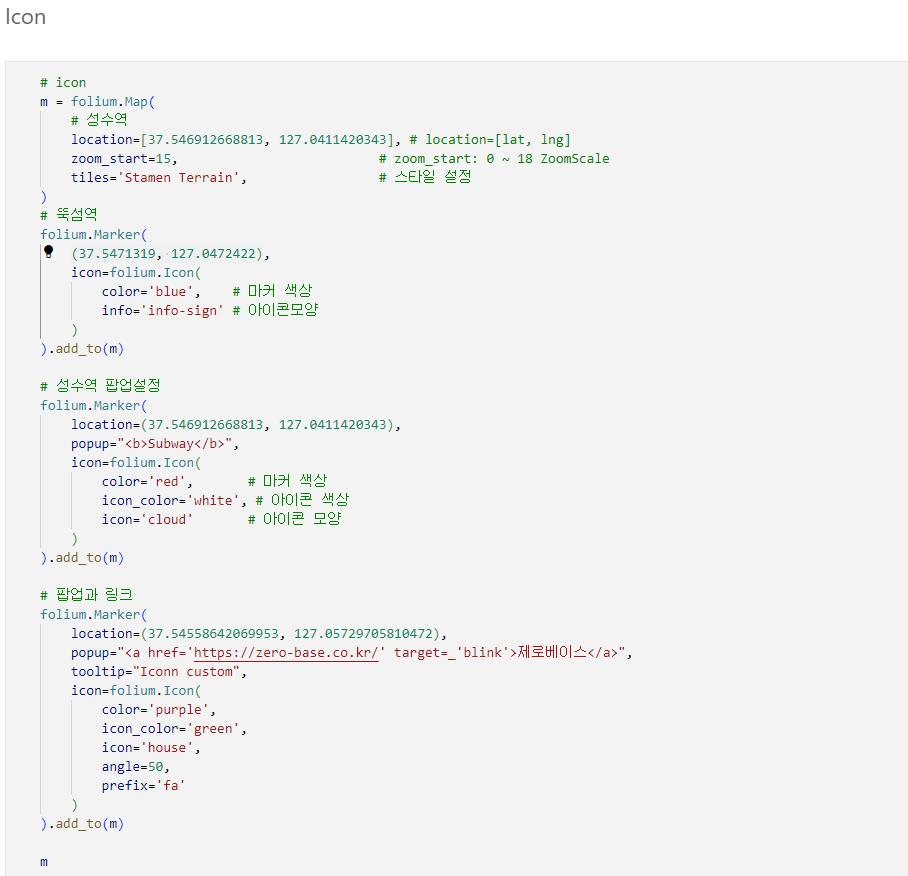
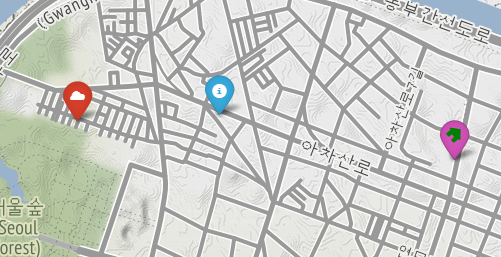
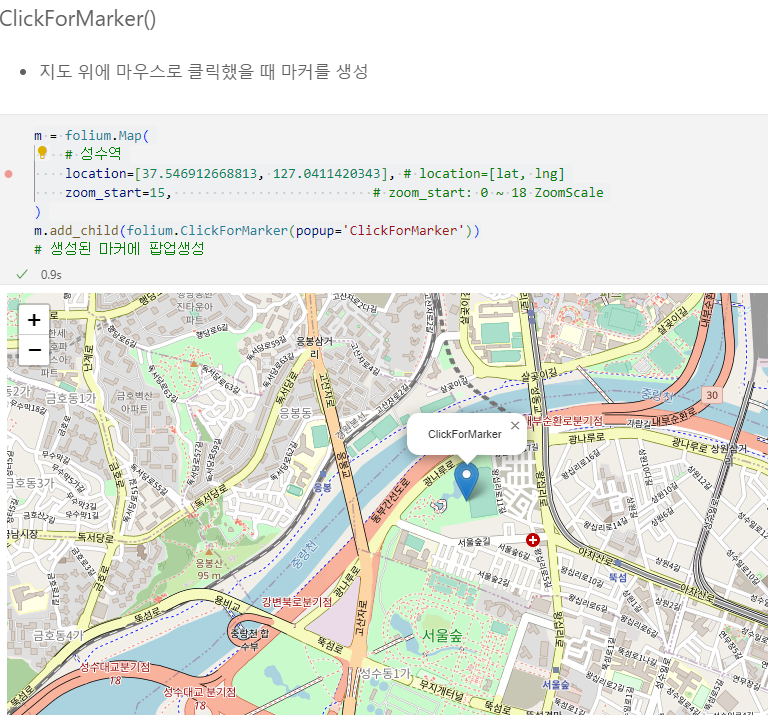
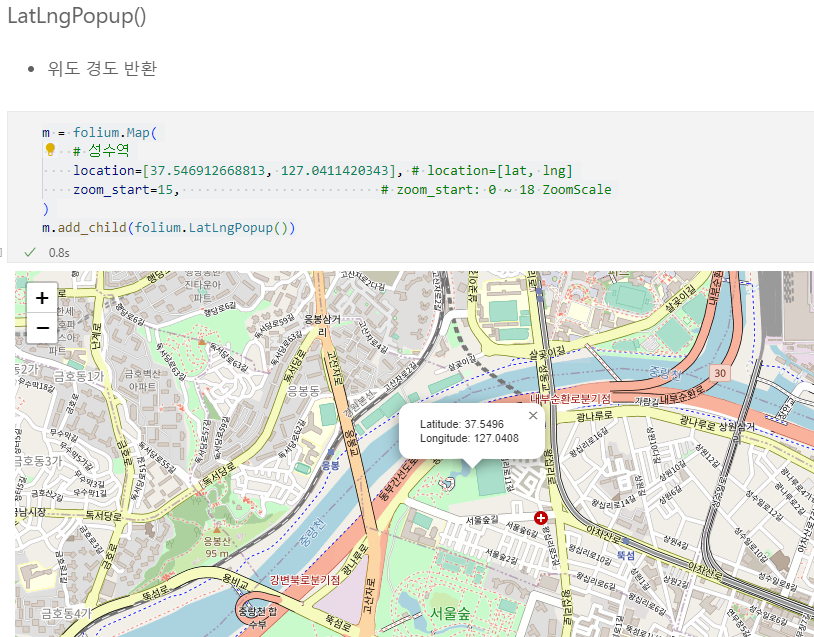
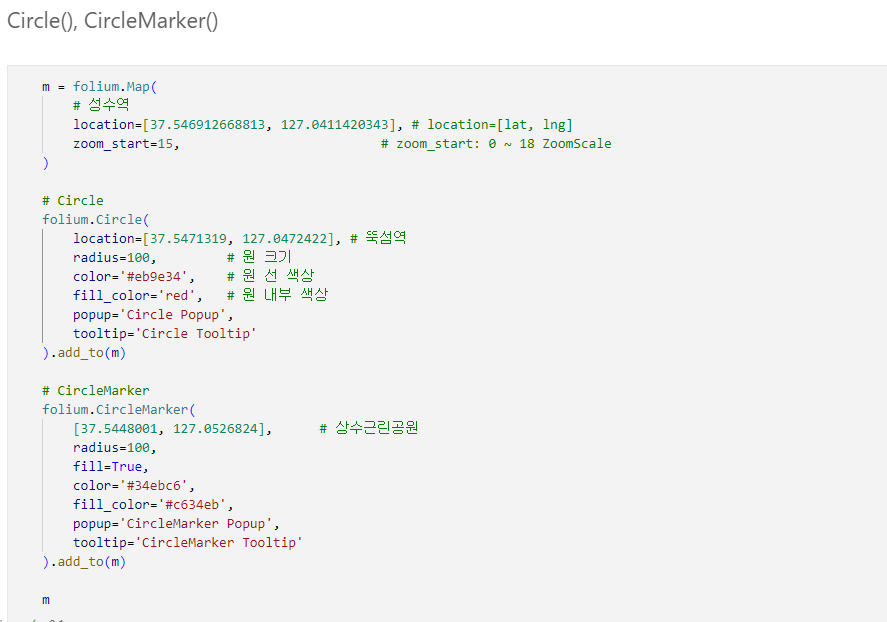
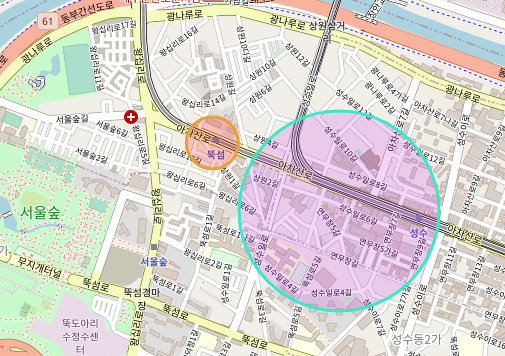
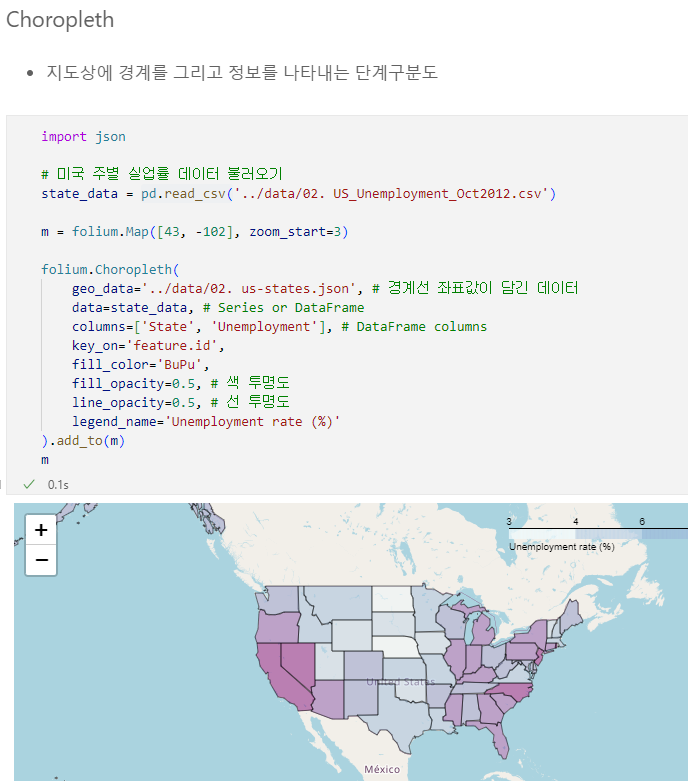
7.1. 구별 범죄 현황 지도 시각화
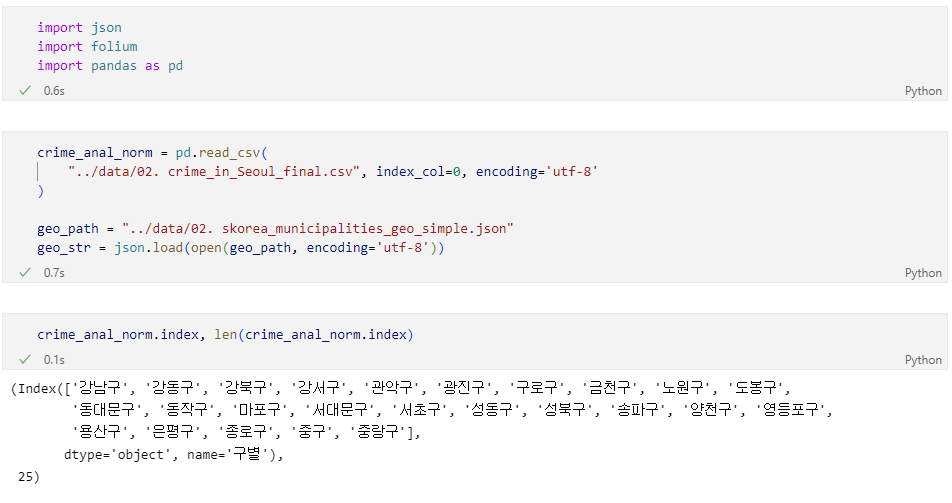





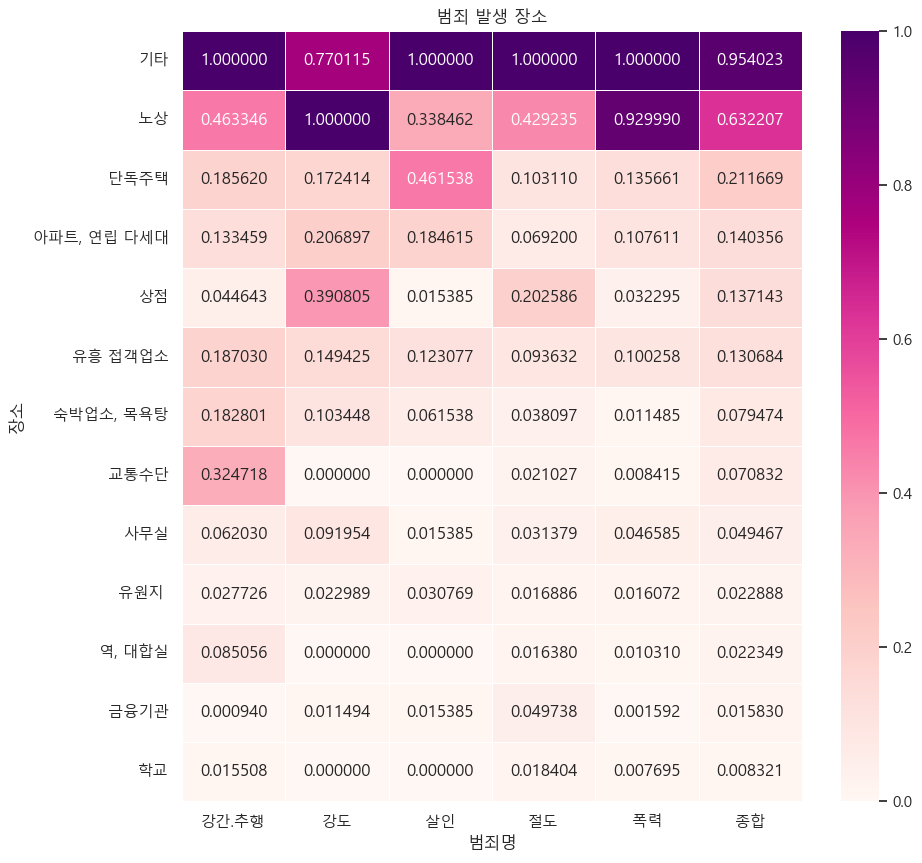
📌8. 서울시 범죄 현황 발생 장소 분석