해당 글은 제로베이스데이터스쿨 학습자료를 참고하여 작성되었습니다
앙상블 기법
-
Voting, Bagging, Boosting, Stacking 등 으로 나뉨
-
보팅과 배깅은 여러 개의 분류기가 튜표를 통해 최종 예측 결과를 결정하는 방식
-
보팅은 각기 다른 분류기, 배깅은 같은 분류기를 사용
1. 부스팅(Boosting)
-
여러 개의 (약한)분류기를 순차적으로 학습을 하면서, 앞에서 틀린 데이터에 대해 학습하고 해당 가중치를 이어 받아서 다음 분류기에 영향을 주는 방식
-
"약한"은 성능은 떨어지지만, 속도가 매우 빠른 것을 의미함
-
에이다부스트(Adaboost), 그래디언트부스트, XGBoost(eXtra Gradient Boost), LightGBM(Light Gradient Boost)등이 있음
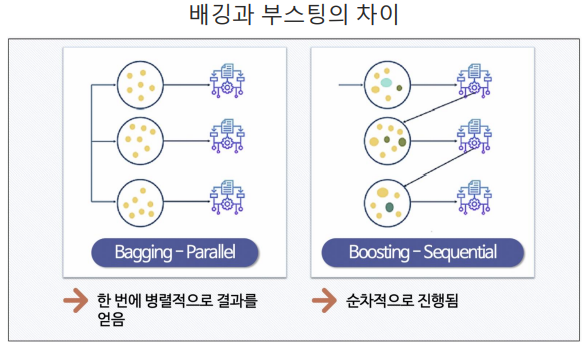
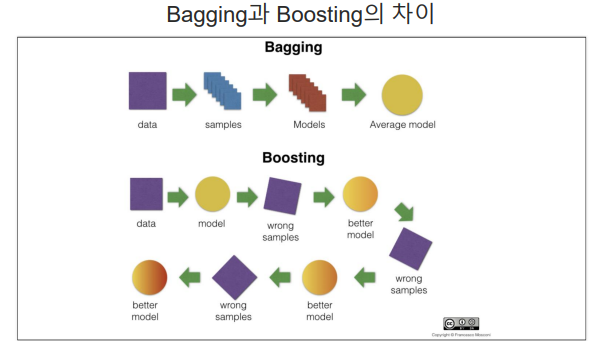
1) Adaboost(Adaptive Boosting)
- 순차적으로 다른 가중치를 부여하여 결과를 도출

데이터 가져오기
# 와인 데이터 가져오기
import pandas as pd
wine_url = 'https://raw.githubusercontent.com/Pinkwink/ML_tutorial/master/dataset/wine.csv'
wine = pd.read_csv(wine_url, index_col=0)
# quality 칼럼에 기반하여 0과1로 구분되는 taste 칼럼을 생성
wine['taste'] = [1. if grade>5 else 0. for grade in wine['quality']]
X = wine.drop(['taste','quality'], axis=1)
y = wine['taste']
# 표준스케일러 적용
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_sc = sc.fit_transform(X)
# 데이터 분리
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
# 모든 칼럼의 히스토그램 조사
import matplotlib.pyplot as plt
wine.hist(bins=10, figsize=(15,16))
plt.show()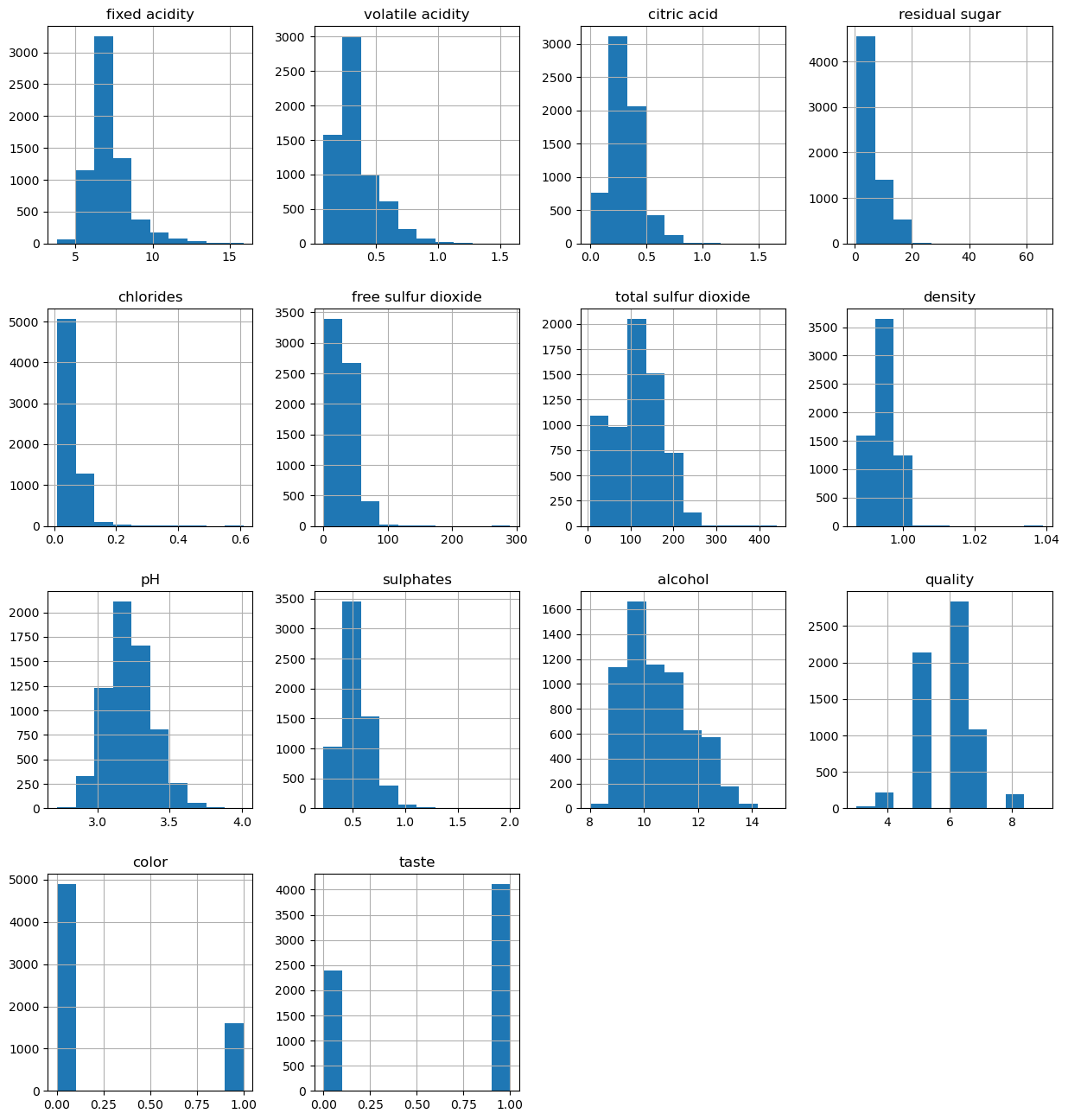
quality별 데이터 특성
- 일반적으로 alcohol, total sulfur dioxide는 비례
- chlorides, volatile acidity는 반비례
# quality별 다른 특성이 있는지 확인해보자
column_names = wine.drop(['quality', 'color', 'taste'], axis=1).columns
df_pivot_table = wine.pivot_table(column_names, ['quality'], aggfunc='median')
df_pivot_table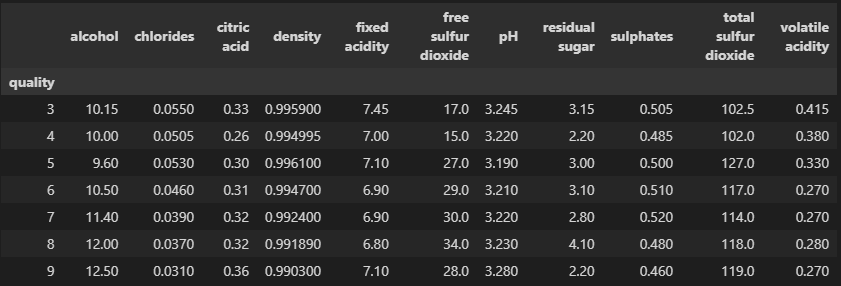
특성데이터의 상관관계
- 맛과 알코올이 가장 중요
corr_matrix = wine.corr()
corr_matrix['quality'].sort_values(ascending=False)
------------------------------------
quality 1.000000
taste 0.814484
alcohol 0.444319
citric acid 0.085532
free sulfur dioxide 0.055463
sulphates 0.038485
pH 0.019506
residual sugar -0.036980
total sulfur dioxide -0.041385
fixed acidity -0.076743
color -0.119323
chlorides -0.200666
volatile acidity -0.265699
density -0.305858
Name: quality, dtype: float64모델학습
# 다양한 모델을 한 번에 테스트해보자
from sklearn.ensemble import AdaBoostClassifier, GradientBoostingClassifier, RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
models = []
models.append(('AdaBoostClassifier', AdaBoostClassifier()))
models.append(('GradientBoostingClassifier', GradientBoostingClassifier()))
models.append(('RandomForestClassifier', RandomForestClassifier()))
models.append(('DecisionTreeClassifier', DecisionTreeClassifier()))
models.append(('LogisticRegression', LogisticRegression(solver='liblinear')))
# 결과물 저장
from sklearn.model_selection import KFold, cross_val_score
results = []
names = []
for name, model in models:
kfold = KFold(n_splits=5, random_state=13, shuffle=True)
cv_results = cross_val_score(model, X_train, y_train, cv=kfold, scoring='accuracy')
results.append(cv_results)
names.append(name)
print(name, cv_results.mean(), cv_results.std())
--------------------------------------------------------------------
AdaBoostClassifier 0.7533103205745169 0.02644765901536818
GradientBoostingClassifier 0.7663959428444511 0.021596556352125432
RandomForestClassifier 0.8198895017398385 0.018691486407511598
DecisionTreeClassifier 0.7556241208262382 0.013083004677429408
LogisticRegression 0.741963426371511 0.013906384147929532cross-validation 시각화
- 와인데이터의 모델 순위
- 1등 : 랜덤포레스트
- 2등 : 그래디언트 부스팅
# cross-validation 결과 시각화
fig = plt.figure(figsize=(14,8))
fig.suptitle('Algorithm Camparion')
ax = fig.add_subplot(111)
plt.boxplot(results)
ax.set_xticklabels(names)
plt.show()
모델 정확도 평가
from sklearn.metrics import accuracy_score
Name = []
Accuracy_Score = []
for name, model in models:
model.fit(X_train, y_train)
pred = model.predict(X_test)
Name.append(name)
Accuracy_Score.append(accuracy_score(pred, y_test))
pd.DataFrame({'name' : Name, 'accuracy_score' : Accuracy_Score})
------------------------------------------------------------------
name accuracy_score
0 AdaBoostClassifier 0.755385
1 GradientBoostingClassifier 0.788462
2 RandomForestClassifier 0.841538
3 DecisionTreeClassifier 0.778462
4 LogisticRegression 0.7438462) GBM(Gradient Boosting Machine)
- AdaBoost 기법과 비슷하지만, 가중치를 업데이트할 때 경사하강법(Gradient Descent)을 사용
HAR 데이터 가져오기
import pandas as pd
# HAR 데이터 가져오기
url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/features.txt'
feature_name_df = pd.read_csv(url, sep='\s+', header=None, names=['column_index', 'column_name'])
feature_name = feature_name_df.iloc[:, 1].values.tolist()
# X_train, X_test (특성) 데이터 가져오기
X_train_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/train/X_train.txt'
X_test_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/test/X_test.txt'
X_train = pd.read_csv(X_train_url, sep='\s+', header=None)
X_test = pd.read_csv(X_test_url, sep='\s+', header=None)
# 칼럼명 설정
X_train.columns = feature_name
X_test.columns = feature_name
# y_train, y_test (라벨) 데이터 가져오기
y_train_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/train/y_train.txt'
y_test_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/test/y_test.txt'
y_train = pd.read_csv(y_train_url, sep='\s+', header=None, names=['action'])
y_test = pd.read_csv(y_test_url, sep='\s+', header=None, names=['action'])Gradient Boosting
- 정확도가 높은대신, 계산시간도 상당히 오래 걸림
- GBM 성능자체는 랜덤포레스트보다 좋다고 알려져있다
- scikit-learn의 GBM은 속도가 아주 느린 것으로 알려져있다
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import accuracy_score
import time
import warnings
warnings.filterwarnings('ignore')
# 그래디언트 부스팅 사용
start_time = time.time()
gb_clf = GradientBoostingClassifier(random_state=13)
gb_clf.fit(X_train, y_train)
gb_pred = gb_clf.predict(X_test)
print('ACC : ', accuracy_score(y_test, gb_pred))
print('Fit time : ', time.time() - start_time)
-----------------------------------------------
ACC : 0.9385816084153377
Fit time : 1336.3437371253967GridSearchCV
# 그리드서치 사용
from sklearn.model_selection import GridSearchCV
parmas = {
'n_estimators' : [100, 500],
'learning_rate' : [0.05, 0.1]
}
start_time = time.time()
grid = GridSearchCV(gb_clf, params_grid=parmas, cv=2, verbose=1, n_jobs=7)
grid.fit(X_train, y_train)
print('Fit time : ', time.time() - start_time)
------------------------------------------------
Fit time : 7064.0076719985학습결과
# 최적의 파라미터와 스코어 확인
grid.best_params_, grid.best_score_
------------------------------------
(0.90111534, {'learning_rate': 0.05, 'n_estimators': 500})# 정확도 확인
accuracy_score(y_test, grid.best_estimator_.predict(X_test))
------------------------------------------------------------
0.939260263) XGBoost(eXtra Gradient Boost)
-
GBM에서 PC의 파워를 효율적으로 사용하기 위한 다양한 기법에 채택되어 빠른 속도와 효율을 가짐(GPU사용)
-
트리 기반의 앙상블 학습에서 가장 각광받는 알고리즘 중 하나
-
GBM 기반의 알고리즘인데, GBM의 느린 속도를 다양한 규제를 통해 해결
-
병렬학습이 가능하도록 설계됨
-
반복수행할 때 마다 내부적으로 학습데이터와 검증데이터를 교차검증함
-
교차검증을 통해 최적화되면 반복을 중단하는 조기 중단 기능이 있음
주요 파라미터
-
nthread : CPU의 실행 스레드 개수를 조정. default는 CPU 전체 스레드를 사용함
-
eta : GBM 학습률
-
num_boost_rounds : n_estimators와 같은 파라미터
-
max_depth : 깊이 설정
# 조기종료조건과 검증데이터를 지정할 수 있다
from xgboost import XGBClassifier
evals = [(X_test.values, y_test)]
start_time = time.time()
xgb = XGBClassifier(n_estimators=400, learning_rate=0.1, max_depth=3)
xgb.fit(X_train.values, y_train, early_stopping_rounds=10, eval_set=evals)
print('Fit time : ', time.time() - start_time)
------------------------------------------------
Fit time : 289.58694934학습결과
# 성능 확인
accuracy_score(y_test, xgb.predict(X_test.values))
------------------------------------------------------
0.93926026464) LightGBM
-
XGBoost보다 빠른 속도를 가짐
-
XGBoost와 함께 부스팅 계열에서 각광받는 알고리즘
-
단, 적은 수의 데이터에는 적합하지 않음(일반적으로 10000건 이상의 데이터가 필요함)
-
GPU버전도 존재함
# !pip install lightgbm
from lightgbm import LGBMClassifier
start_time = time.time()
evals = [(X_test.values, y_test)]
lgbm = LGBMClassifier(n_estimators=400)
lgbm.fit(X_train.values, y_train, early_stopping_rounds=100, eval_set=evals)
print('Fit time : ', time.time() - start_time)
--------------------------------------------------
[1] valid_0's multi_logloss: 1.4404
[2] valid_0's multi_logloss: 1.21574
[3] valid_0's multi_logloss: 1.04795
[4] valid_0's multi_logloss: 0.913299
[5] valid_0's multi_logloss: 0.812686
[6] valid_0's multi_logloss: 0.725964
[7] valid_0's multi_logloss: 0.652995
...
[136] valid_0's multi_logloss: 0.260353
[137] valid_0's multi_logloss: 0.260621
[138] valid_0's multi_logloss: 0.25998
Fit time : 16.5495400428학습결과
# 성능 확인
accuracy_score(y_test, lgbm.predict(X_test.values))
----------------------------------------------------
0.9260264675941635