해당 글은 제로베이스데이터스쿨 학습자료를 참고하여 작성되었습니다
1. 앙상블(Ensemble)
-
여러 개의 분류기를 생성하고 그 예측을 결합하여 정확한 최종 예측을 기대하는 기법
-
다양한 분류기의 예측 결과를 결합함으로써 단일 분류기보다 신뢰성이 높은 예측 값을 얻는 것
보팅과 배깅
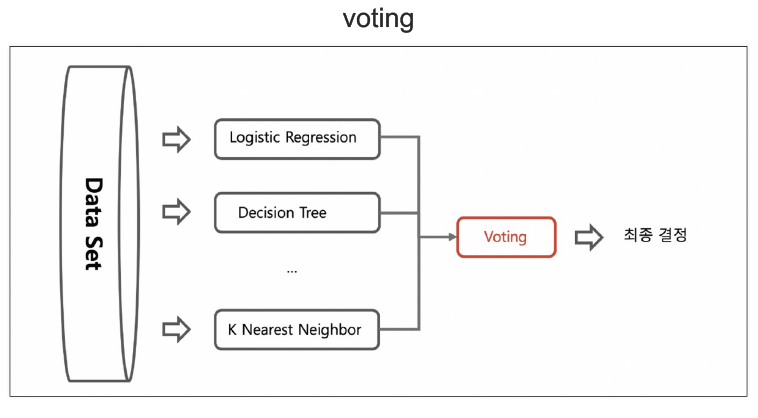
보팅(Voting)
-
각기 다른 방식으로 얻은 결과를 통합하여 최종 결정을 함
-
성능이 좋지 않아서 사용하지 않음
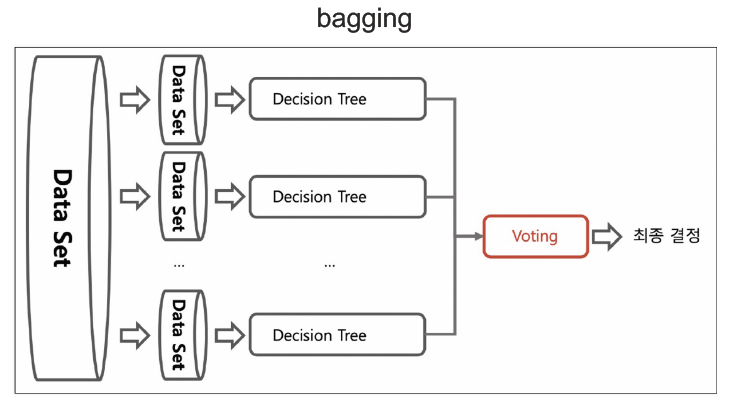
배깅(Bagging=Bootstrap AGGregatING)
-
부트스트랩 집계라는 뜻으로, 하나의 방식으로 얻은 결과를 통합하여 최종 결정을 함
-
각각의 분류기에 데이터를 각각 샘플링해서 추출하는 부트스트래핑 방식을 사용함(중복 허용)
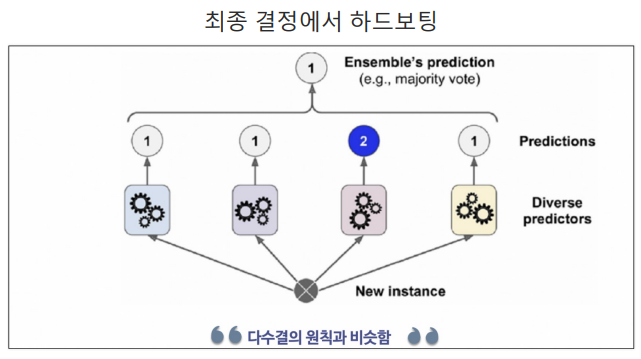
최종 결정 방식
하드보팅(=다수결의 원칙)
- 결과의 갯수가 많은쪽으로 최종결정을 하는 방식
- ex) '1'이 3개, '2'가 1개이므로 최종값은 '1'이다.
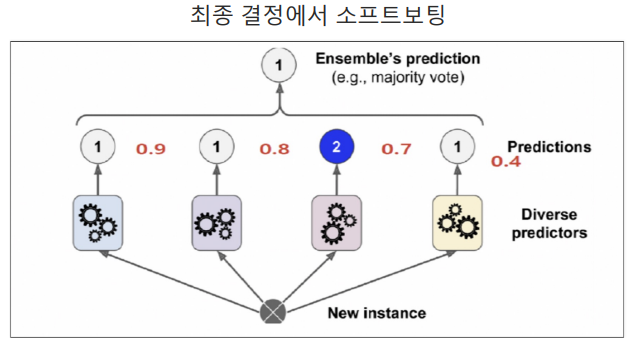
소프트보팅(=확률평균화)
-
각 카테고리의 확률을 산술평균하여 최종결정을 하는 방식
-
단, 동률인 경우 다수결을 따른다.
-
ex) '1'의 확률은 (0.9+0.8+0.4)/3=0.7이고 '2'의 확률은 0.7이므로 동률이므로 다수결에 의해 최종값은 '1'이다.
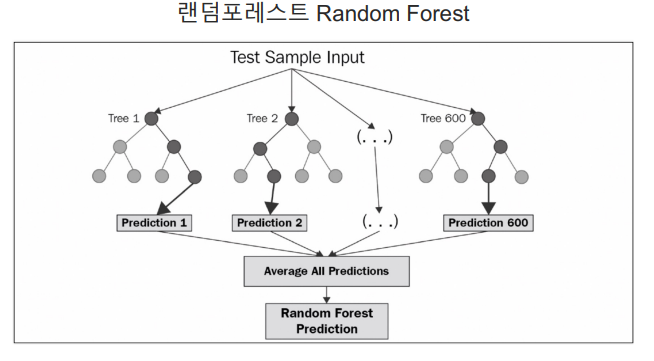
랜덤포레스트(RandomForest)
-
의사결정나무(DecisionTree)의 집합
-
배깅의 대표적인 방법
-
앙상블 방법 중에서 비교적 속도가 빠르며 다양한 영역에서 높은 성능을 보여주고 있다.
-
최종 결정은 소프트보팅

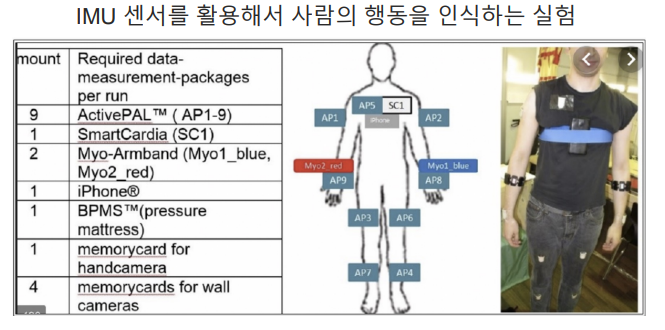
2. HAR
- Human Activity Recognition
개요

목표
- 가속도와 각속도 데이터를 통해서 행동예측하기
절차
- 1) 데이터 이해
- 2) 데이터 전처리
- 3) DecisionTree
- 4) RandomForest
1,2) 데이터 이해와 전처리


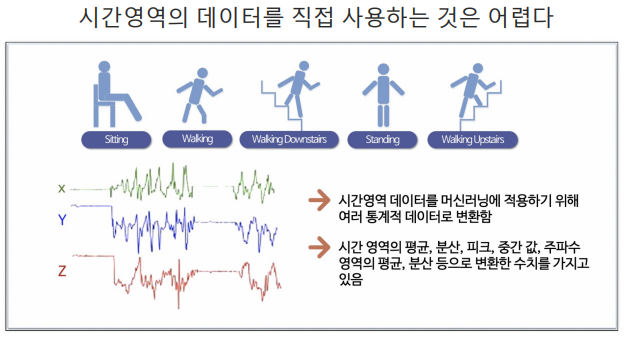
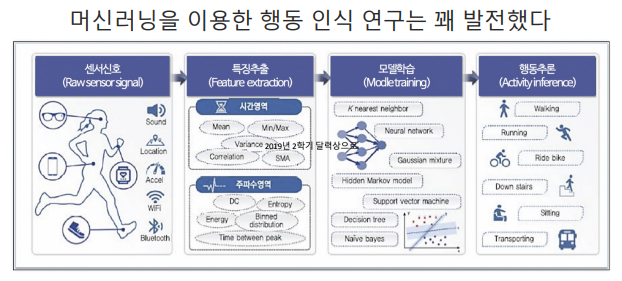
데이터 가져오기
- feature 데이터 가져오기(데이터 명칭 모아놓은 파일 읽기)
- txt파일이고, '공백'으로 분류되어 있음
import pandas as pd
import matplotlib.pyplot as plt
url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/features.txt'
feature_name_df = pd.read_csv(url, sep='\s+', header=None, names=['column_index', 'column_name'])
feature_name_df
---------------------------------------------------------
column_index column_name
0 1 tBodyAcc-mean()-X
1 2 tBodyAcc-mean()-Y
2 3 tBodyAcc-mean()-Z
3 4 tBodyAcc-std()-X
4 5 tBodyAcc-std()-Y
.. ... ...
556 557 angle(tBodyGyroMean,gravityMean)
557 558 angle(tBodyGyroJerkMean,gravityMean)
558 559 angle(X,gravityMean)
559 560 angle(Y,gravityMean)
560 561 angle(Z,gravityMean)
[561 rows x 2 columns]결측치 확인
feature_name_df.info()
------------------------------------------
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 561 entries, 0 to 560
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 column_index 561 non-null int64
1 column_name 561 non-null object
dtypes: int64(1), object(1)
memory usage: 8.9+ KBfeature_name_df[feature_name_df['column_name']==0]
-------------------------------------
Empty DataFrame
Columns: [column_index, column_name]
Index: []특성명 리스트화
feature_name = list(feature_name_df['column_name'])
feature_name[:10]
----------------------------
['tBodyAcc-mean()-X',
'tBodyAcc-mean()-Y',
'tBodyAcc-mean()-Z',
'tBodyAcc-std()-X',
'tBodyAcc-std()-Y',
'tBodyAcc-std()-Z',
'tBodyAcc-mad()-X',
'tBodyAcc-mad()-Y',
'tBodyAcc-mad()-Z',
'tBodyAcc-max()-X']특성 데이터 가져오기
# X_train, X_test (특성) 데이터 가져오기
X_train_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/train/X_train.txt'
X_test_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/test/X_test.txt'
X_train = pd.read_csv(X_train_url, sep='\s+', header=None)
X_test = pd.read_csv(X_test_url, sep='\s+', header=None)
# 칼럼명 설정
X_train.columns = feature_name
X_test.columns = feature_name
X_train.head()
라벨 데이터 가져오기
# y_train, y_test (라벨) 데이터 가져오기
y_train_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/train/y_train.txt'
y_test_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/test/y_test.txt'
y_train = pd.read_csv(y_train_url, sep='\s+', header=None, names=['action'])
y_test = pd.read_csv(y_test_url, sep='\s+', header=None, names=['action'])
y_train.head()
--------------------
action
0 5
1 5
2 5
3 5
4 5데이터 형태 확인
X_train.shape, X_test.shape, y_train.shape, y_test.shape
------------------------------------------------
((7352, 561), (2947, 561), (7352, 1), (2947, 1))라벨데이터 확인
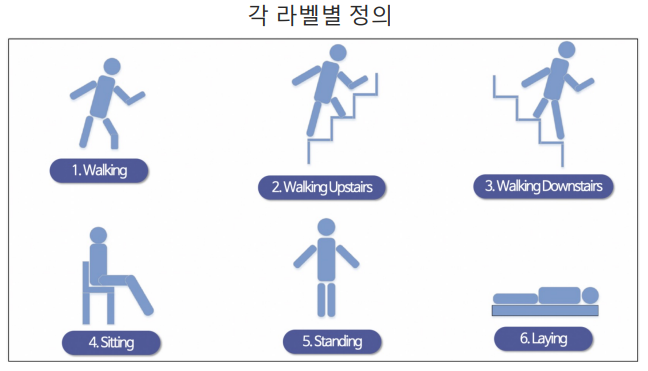
y_train['action'].value_counts()
--------------------------
6 1407 # 6. Laying
5 1374 # 5. Standing
4 1286 # 4. Sitting
1 1226 # 1. Walking
2 1073 # 2. Walking Upstairs
3 986 # 3. waliking Downstairs
Name: action, dtype: int643) DecisionTree
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
dt_clf = DecisionTreeClassifier(max_depth=4, random_state=13)
dt_clf.fit(X_train, y_train)
pred = dt_clf.predict(X_test)
accuracy_score(y_test, pred)
------------------------------
0.8096369189005769GridSearchCV
- 최적의 파라미터 찾기
from sklearn.model_selection import GridSearchCV
params = {
'max_depth': [6, 8, 10, 12, 16, 20, 24]
}
grid_cv = GridSearchCV(dt_clf, param_grid=params, scoring='accuracy', cv=5, return_train_score=True)
grid_cv.fit(X_train, y_train)
grid_cv.best_score_, grid_cv.best_params_
------------------------------------------
(0.8543335321892183, {'max_depth': 8})수행내용확인
- 수행내용이 많으므로 생략함
grid_cv.cv_results_DT 데이터 정리
max_depth별 score 정리
- grid_cv.cv_results_에서 필요내용만 정리
- max_depth '8'의 test와 train score 차이 = 0.13
cv_results_df = pd.DataFrame(grid_cv.cv_results_)
cv_results_df[['param_max_depth','mean_test_score','mean_train_score']]
------------------------------------------------------
param_max_depth mean_test_score mean_train_score
0 6 0.843444 0.944879
1 8 0.854334 0.982692
2 10 0.847125 0.993369
3 12 0.841958 0.997212
4 16 0.841958 0.999660
5 20 0.842365 0.999966
6 24 0.841821 1.000000max_depth별 accuracy_score 정리
- max_depth {8}일 때, 정확도 또한 가장 높음
# for문으로 하나씩 알아보기
max_depth = [6,8,10,12,16,20,24]
for depth in max_depth:
dt_clf = DecisionTreeClassifier(max_depth=depth, random_state=13)
dt_clf.fit(X_train, y_train)
pred = dt_clf.predict(X_test)
accuracy = accuracy_score(y_test, pred)
print('Max_Depth :', depth, ', Accuracy =', accuracy)
----------------------------------------------------------
Max_Depth : 6 , Accuracy = 0.8554462164913471
Max_Depth : 8 , Accuracy = 0.8734306073973532
Max_Depth : 10 , Accuracy = 0.8615541228367831
Max_Depth : 12 , Accuracy = 0.8595181540549711
Max_Depth : 16 , Accuracy = 0.8669833729216152최적의 파라미터(max_depth 8) 모델에 적용
best_dt_clf = grid_cv.best_estimator_
pred1 = best_dt_clf.predict(X_test)
accuracy_score(y_test, pred1)
------------------------------
0.87343060739735324) RandomForest
- 나무가 많다고 무조건 좋은 것은 아니다
- rank 1위인 데이터는 나무가 100개이고,
- 그 다음부터의 데이터들은 나무가 200개 이다.
# RandomForest
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
params = {
'max_depth' : [6,8,10], # DT 깊이
'n_estimators' : [50, 100, 200], # DT 사용갯수
'min_samples_leaf' : [8,12], # 마지막 노드(잎)에 위치한 최소 데이터 갯수
'min_samples_split' : [8,12] # 데이터 분할 최소 갯수
}
# n_jobs=-1은 모든 코어를 사용하라는 의미
rf_clf = RandomForestClassifier(n_jobs=7, random_state=13)
grid_cv = GridSearchCV(rf_clf, param_grid=params, cv=2, n_jobs=7)
grid_cv.fit(X_train, y_train.values.reshape(-1,))
# 결과 정리를 위해 칼럼명 확인
cv_results_df = pd.DataFrame(grid_cv.cv_results_)
target_col = ['rank_test_score', 'mean_test_score', 'param_n_estimators', 'param_max_depth']
cv_results_df[target_col].sort_values('rank_test_score').head(7)
------------------------------------------
rank_test_score mean_test_score param_n_estimators param_max_depth
28 1 0.915125 100 10
25 1 0.915125 100 10
23 3 0.912813 200 8
20 3 0.912813 200 8
35 5 0.912541 200 10
32 5 0.912541 200 10
29 7 0.912405 200 10RF 데이터 정리
최적의 파라미터와 점수 확인
grid_cv.best_params_, grid_cv.best_score_
-----------------------------------------
({'max_depth': 10,
'min_samples_leaf': 8,
'min_samples_split': 8,
'n_estimators': 100},
0.9151251360174102)최적의 파라미터를 활용한 FR 학습 및 평가
- DecisionTree보다 정확도가 0.05 높음
rf_clf_best = grid_cv.best_estimator_
rf_clf_best.fit(X_train, y_train.values.reshape(-1, ))
pred1 = rf_clf_best.predict(X_test)
accuracy_score(y_test, pred1)
------------------------------
0.9205972175093315중요특성
중요특성 확인
best_cols_values = rf_clf_best.feature_importances_
best_cols = pd.Series(best_cols_values, index=X_train.columns)
top20_cols = best_cols.sort_values(ascending=False)[:20]
top20_cols중요특성 시각화
- HAR에는 561개나 되는 특성들이 있는데 그 중 유의미한 것은 몇개 되지 않는다
import seaborn as sns
plt.figure(figsize=(10,8))
sns.barplot(x=top20_cols, y=top20_cols.index)
plt.show()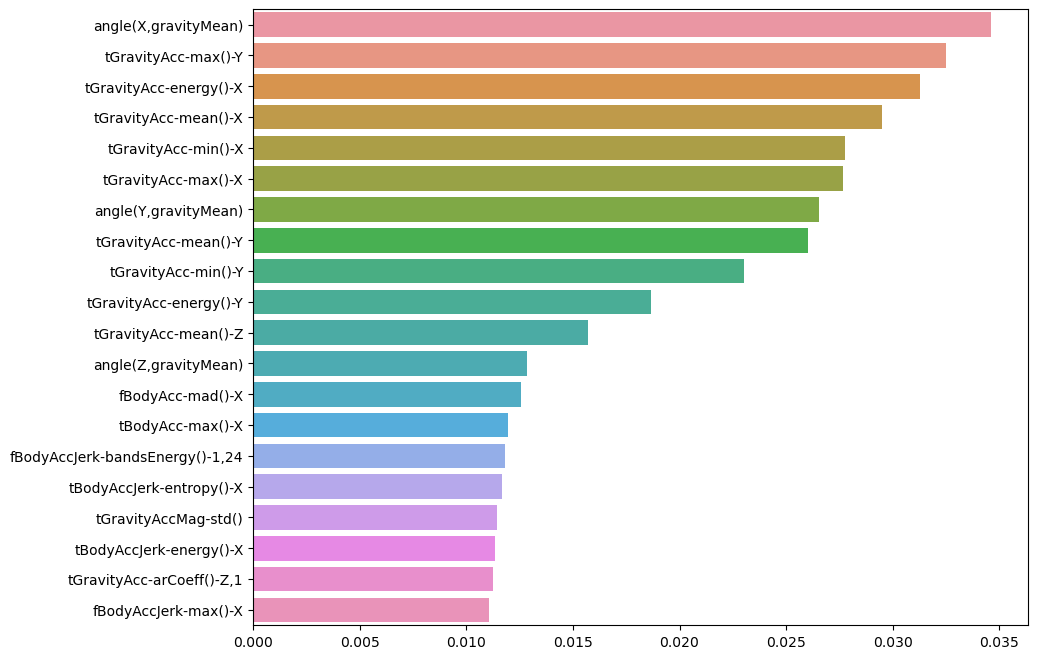
중요특성 20개만 사용하여 학습
- 데이터가 줄어든만큼 속도가 매우 빨라진다.
- 정확도는 이전에 비하면 0.10 차이가 있지만, 둘다 0.80이상의 성능을 가지고 있다.
- 엔지니어는 이 부분을 잘 판단하여야 할 것이다.
X_train_re = X_train[top20_cols.index]
X_test_re = X_test[top20_cols.index]
rf_clf_best_re = grid_cv.best_estimator_
rf_clf_best_re.fit(X_train_re, y_train.values.reshape(-1, ))
pred1_re = rf_clf_best_re.predict(X_test_re)
accuracy_score(y_test, pred1_re)
-------------------------------------
0.8177807940278249