지난 장까지는 웹 브라우저에서 어떻게 HTTP 메시지를 만드는지 살펴보았다. 이번 장에서는 만든 HTTP 메시지가 어떻게 컴퓨터를 빠져 나가는지를 살펴보자.
도입
브라우저(어플리케이션)가 부탁한 HTTP 메시지 요청은 운영체제와 하드웨어를 거쳐 컴퓨터를 빠져나간다. 이 후 요청은 여러가지 통신 장치들을 거쳐 서버에 도착하게 된다. 이번 장에서는 컴퓨터를 빠져나가며 거치는 컴퓨터 내부의 요소들을 알아볼 것이다. 소켓을 거쳐 만나게되는 요소들로는 소프트웨어인 프로토콜 스택(TCP, UPD, IP등을 포함하는 네트워크 제어용 소프트웨어)이 있고 하드웨어인 LAN 어댑터가 있다.
우선 이러한 요소들을 간단하게 살펴보자.
TCP 프로토콜은 연결지향형 프로토콜이다. 신뢰성이 높으므로, 일반적인 웹 어플리케이션에서 데이터를 송수신하는데 사용한다. UDP 프로토콜은 비연결지향형 프로토콜이다. 신뢰성이 낮지만 속도가 빨라 DNS 조회 등 단순한 데이터를 송수신하는 데 사용한다.
전송 계층의 두 프로토콜(TCP, UDP) 아래에 있는 IP 프로토콜은 패킷 단위로 데이터를 운반하며 ICMP와 ARP라는 프로토콜들을 다룬다.
IP의 아래에는 LAN 드라이버가 있다. LAN 드라이버는 LAN 어댑터를 제어하며, LAN 어댑터는 물리적인 송수신 동작을 수행한다.
그림으로 살펴보면 아래와 같다.
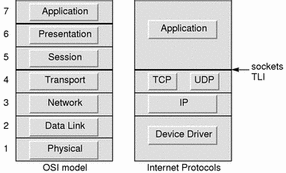
Application(브라우저)이 전송한 데이터(HTTP 요청 메시지)가 TCP(or UDP) - IP - Device Driver(+ Lan Adapter)을 거쳐 컴퓨터 외부로 나가게 된다.
소켓
소켓부터 살펴보자. 소켓은 운영체제의 핵심 기능인 커널 중에, 어플리케이션이 사용할 수 있는 네트워크 인터페이스들을 모아놓은 것이다. 프로토콜 스택은 메모리에 있는 소켓에 제어 정보를 유지한다. 송신측(클라이언트)과 수신측(서버)의 정보(IP, Port번호)나 재전송을 위한 동작 후 경과시간 등이 포함된다.
소켓 생성
int socketfd = socket(domain, type, protocol)
어플리케이션이 위와 같은 코드를 통해 프로토콜 스택에 소켓 생성을 의뢰한다. 프로토콜 스택은 소켓을 저장할 메모리 영역을 확보한 후 연결이 되지 않은 초기상태임을 나타내는 데이터들을 기록하면 소켓이 생성되었다고 할 수 있다. 이 때, 코드의 반환값으로 획득하는 파일 디스크립터는 여러 소켓들을 식별하는 역할을 한다.
소켓 접속
접속은 클라이언트와 서버간에 제어 정보를 교환하는 과정을 의미한다. 이를 통해 프로토콜 스택이 상대방의 정보를 알게된다. 물리적으로는 케이블을 통해 이미 연결이 되어있기 때문에, SW관점에서만 연결이 되면 된다.
connect(sockfd, (struct sockaddr*)&server_addr, sizeof(server_addr))
위와 같은 코드를 어플리케이션(클라이언트)이 호출하면, 프로토콜 스택이 송신측(클라이언트) 소켓을 수신측(서버) 소켓에 접속한다. 접속 과정에서 상대방과 제어 정보를 교환하여 상대방을 식별할 수 있다.
서버는 bind()를 통해 IP, Port번호를 결정하고, listen()을 통해 대기한다. 클라이언트에서 접속 요청이 들어오면 accept()를 통해 승인한다. 이 과정을 거치면 서버 역시도 클라이언트의 IP와 Port번호를 얻게된다.
이 때, 양 측 모두 데이터 송수신을 위한 버퍼 공간을 확보하는 작업도 진행되며 이 역시 접속 동작의 일부이다.
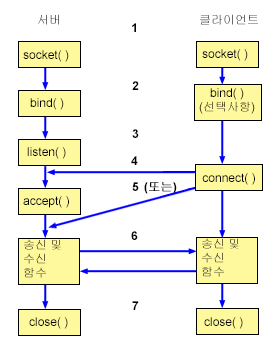
(소켓 동작 과정)
제어 정보
제어 정보는 다양한 정보를 포함한다. 이는 TCP 프로토콜의 헤더로 나타나있으며, 연결을 위한 정보와 송수신, 연결 끊기와 같은 동작을 위한 정보로 나뉜다. 자세한 설명은 링크를 참고하자. TCP 헤더 이외에도 IP 헤더, 이더넷 헤더에도 제어 정보가 담겨있다.
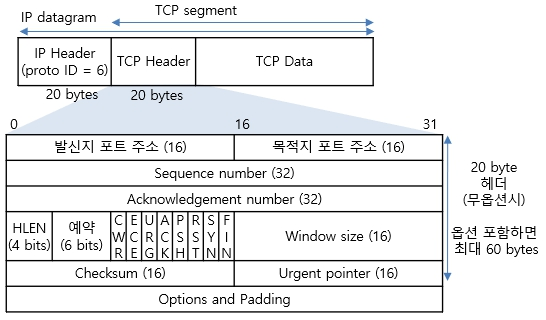
(TCP 헤더의 모습)
제어 정보가 어떻게 활용되는지를 살피기 위해 아까 확인하였던 접속 동작을 헤더 관점에서 확인해보자.
- 클라이언트에서
SYN을 활성화한 헤더를 서버에게 보낸다.
- 이는 클라이언트에서
connect()를 호출하였기에 일어난다. - 발신지(송신측, 클라이언트)와 목적지(수신측, 서버)의 Port번호도 헤더에 기입되어있다.
- 서버에서
SYN과ACK를 활성화하여 클라이언트에게 보낸다.
- 이는 서버에서
accept()호출하였기에 일어난다. - 발신지(송신측, 서버)와 목적지(수신측, 클라이언트)의 Port번호도 기입되어있다.
- 클라이트에서
ACK를 활성화하여 서버에게 보낸다.
- 이를 수신한 서버는
ACK비트가 1인 것을 식별하여 연결이 되었음을 확인한다.
이렇게 접속 동작이 진행되며 이를 3-way-handshake라고 한다.
소켓 읽기와 쓰기
송신
소켓에 접속이 된 후 전송하고자 했던 HTTP 요청 메시지를 보낼 수 있다. 이는 소켓의 write() 를 호출하여 일어난다.
프로토콜 스택은 전달 받은 데이터를 곧바로 송신하지 않고, 송신용 버퍼에 저장한 후 버퍼가 충분히 찬다면 그 이후 넘겨주는데, 이러한 버퍼가 존재하는 이유는 여러 어플리케이션마다 데이터를 넘겨주는 단위가 다르기 때문에 이들을 일괄처리하고 데이터가 작은 송신을 최소화시켜 효율적으로 데이터를 송수신하기 위함이다.
- 버퍼를 채우지 않고도 송신을 진행하는
flush()라는 명령도 존재한다.
수신
길고 긴 과정을 거쳐 HTTP 메시지를 요청하였고, 응답을 수신한다고 하자. 이는 read()에 의해 이루어진다. 송신 이후 잠시 대기한 후 수신 버퍼에서 어플리케이션으로 데이터를 건네주었기 때문에 일어난다. 정리해보면, 수신한 데이터가 이상이 없다고 판단된다면 ACK 번호를 응답한다. 그리고 수신 버퍼에 데이터들을 보관한 후 시퀀스 번호를 이용하여 원래 데이터를 복원하여 어플리케이션에 넘겨준다. 이 때 윈도우 사이즈가 줄게되고 윈도우 필드를 헤더로 하는 데이터를 송신측에 응답해준다.
소켓 연결끊기
데이터 송수신까지 완료하였다. 이후에는 연결을 끊는 작업이 필요하다. 연결은 클라이언트와 서버 모두 끊을 수 있다. 클라이언트에서 연결을 먼저 끊는다고 가정하면 아래와 같다.
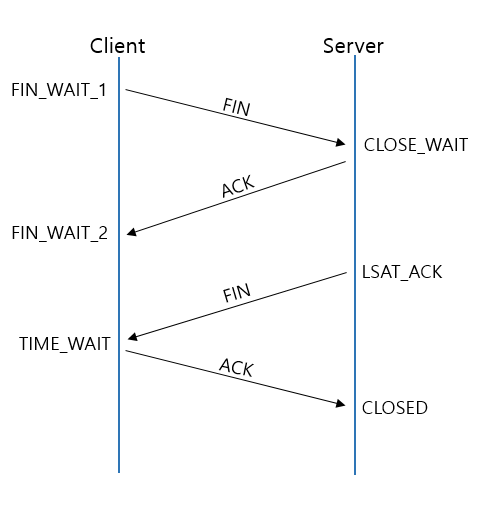
(4-way handshake의 모습)
클라이언트가 close()를 호출하면 프로토콜 스택이 아래와 같은 동작을 수행한다.
- 클라이언트에서 컨트롤 비트의
FIN을 1로 설정한 데이터를 송신한다. - 서버측에서 수신완료되었음을
ACK를 통해 알린다. - (서버측에서
close()를 호출) 서버측에서 컨트롤 비트의FIN을 1로 설정한 데이터를 송신한다. - 클라이언트측에서
ACK응답을 해준다.
서버는 ACK을 응답해준 후 소켓을 종료하며, 일반적으로 요청자인 클라이언트는 연결을 끊기 전 소켓에서 사용했던 모든 통신들이 사라질 때까지 대기한 후 (최대 세그먼트 수명의 2배) 연결을 끊는데, 이는 수신하지 못한 FIN 송신이 추후 연결될 소켓을 의도치않게 종료할 우려가 있기 때문이다.
TCP 프로토콜 키워드
송신용 버퍼의 임계치
송신을 시작하는 버퍼는 MSS라는 임계치까지 데이터를 저장한 후 전송한다. MSS(Maximum Segment Size)는 MTU(Maximum Transmission Unit)이라는 패킷이 운반할 수 있는 최대 길이에서 IP, TCP 헤더를 제외한 데이터의 최대 길이이다.
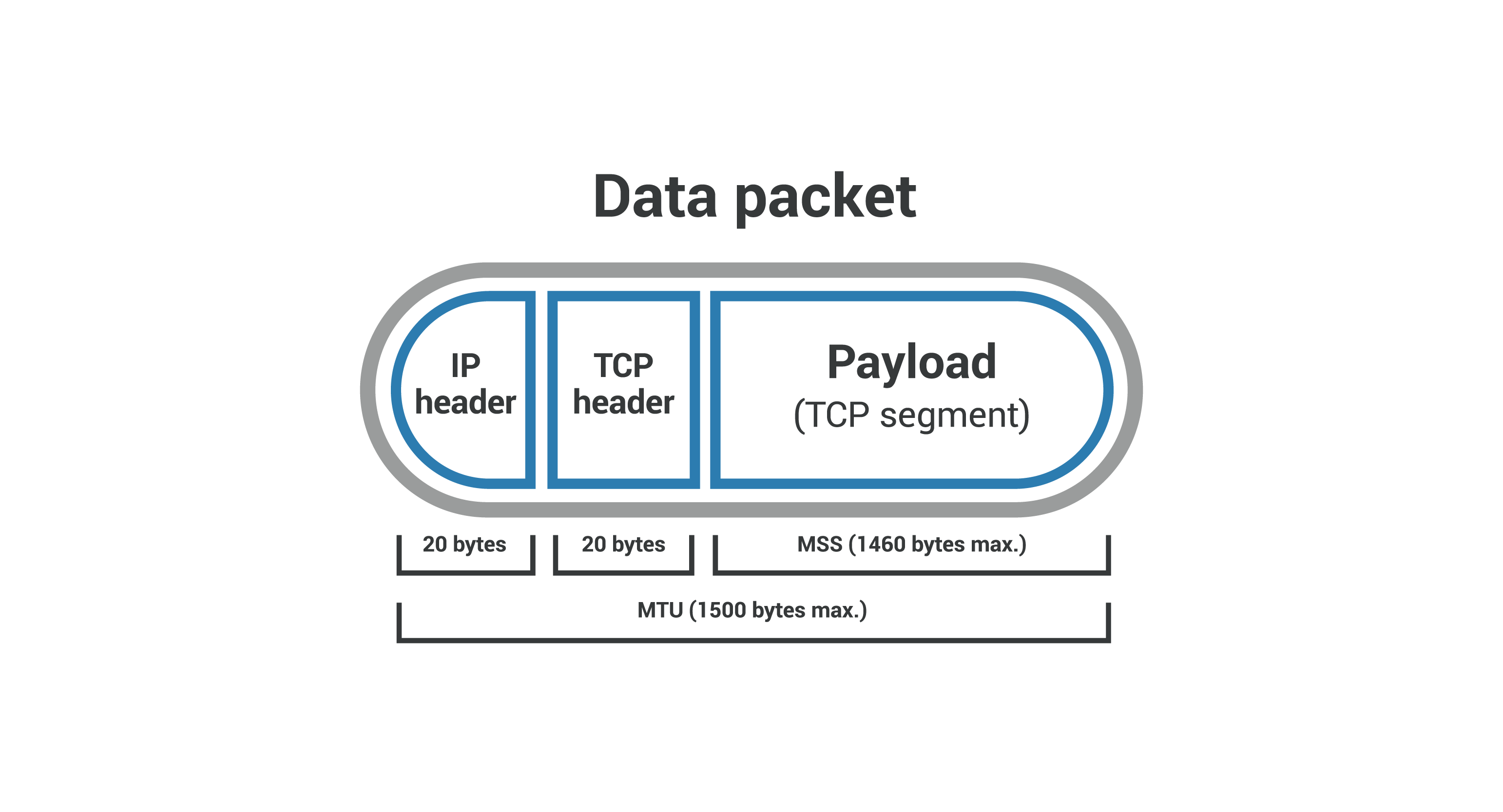
대용량 데이터의 분할
폼 데이터 혹은 멀티미디어같은 큰 용량의 데이터는 MSS의 길이를 초과하는 경우가 잦다. 이러한 경우 데이터는 분할되어 송신된다. 분할하여 송신할 경우, 순서가 뒤바뀔수도 있는데 이는 시퀀스 번호에 의해 원래 순서대로 재조립된다.
시퀀스 번호와 ACK 번호
데이터를 분할할 때, 몇 번째 바이트인지 기억한다. 이렇게 기억한 바이트는 이후 분할한 데이터를 전송할 때 TCP 헤더의 시퀀스 번호에 기록한다.
예를 들어 3000바이트를 1000바이트씩 나누어 보낸다면
- 시퀀스 번호: 1
- 시퀀스 번호: 1001
- 시퀀스 번호: 2001
이 된다.
실제로는 악의적인 공격을 방지하고자, 시퀀스 번호는 임의의 난수부터 시작하며, 양방향 데이터 송수신을 위해 서버와 클라이언트 모두 각자가 사용할 시퀀스 번호의 초기값을 교환한다.
송신한 데이터는 시퀀스 번호를 통해 누락 여부, 순서 변경 여부를 파악할 수 있다. 수신이 잘 이루어졌다면 몇 번째 바이트까지 읽었는지를 TCP 헤더의 ACK 번호를 통해 응답해주며, 이를 수신 확인 응답이라고 한다.
추가로, 메모리에 송신 버퍼를 저장하여 누락, 순서 변경을 감지한다면 이를 이용하여 회복 처리를 취하며, 회복 처리에도 일정 시간 이상 복구가 되지 않는다면 회복을 중지한다.
타임아웃
송신을 한 후 ACK 응답을 기다리는 시간을 타임아웃 값이라고 한다. 이를 너무 길게 설정한다면 재전송 속도에 저하가 발생하며, 너무 짧게 설정한다면 재전송의 빈도가 너무 높아진다. 따라서 적당한 시간을 설정해야 한다. 데이터 송수신 시간은 보통 서버와의 거리 & 혼잡 등에 따라 변한다. 따라서 실제로 ACK 응답이 돌아오는데 걸리는 시간을 토대로 타임아웃 값을 유동적으로 설정한다.
흐름 제어
슬라이딩 윈도우
우리가 알고있던 데이터 전송 방식은 stop-and-wait (ping pong) 방식이다. 이는 ACK 응답이 들어올 때 까지 대기를 하기 때문이 이러한 이름이 붙여졌다. 이러한 대기 시간을 최소화하기 위해 ACK 응답을 기다리지 않고 요청을 추가로 보내는 방식을 sliding window 방식이라고 한다.
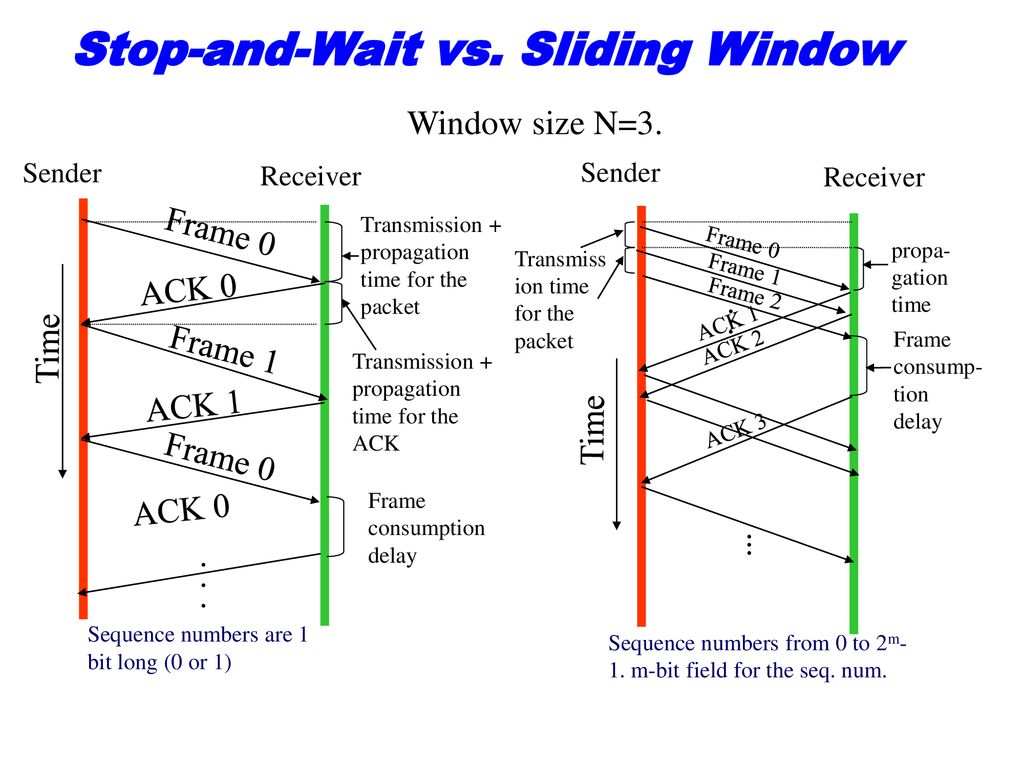
(stop-and-wait 방식 vs sliding window 방식)
위 이미지를 확인해보면 sliding window 방식이 확연하게 빠르게 끝나는 것을 확인할 수 있다. 하지만, stop-and-wait 방식과는 달리 수신측에서 여러 데이터를 한꺼번에 받다보면, 수신 버퍼를 초과하는 경우가 생길 수 있다. (수신 버퍼의 데이터를 어플리케이션이 처리하는 속도보다 송신 데이터를 저장하는 속도가 빠른 경우) 이러한 문제를 방지하고자 수신 측에서 수신 버퍼의 남은 영역을 TCP 헤더의 윈도우 필드에 심어 전달한다. 송신 측은 이러한 필드를 바탕으로 송신 버퍼를 창문을 움직이는 것처럼 이동시켜 윈도우 필드 이하의 데이터를 보내게 된다. (수신 가능한 최대 양을 윈도우 사이즈라고 한다.)
송신 타이밍
그렇다면 윈도우 필드는 언제 보내야 할까? 송신 측에서는 기존 수신 측의 윈도우 사이즈와 송신 측이 보낸 데이터 사이즈를 알기에 송신이 완료되었을 때의 윈도우 사이즈는 응답이 없어도 계산할 수 있다. 단 어플리케이션에 의해 수신 버퍼가 줄어들었을 경우는 수신 측에서 정보를 통지해주어야 한다. 어플리케이션이 수신 버퍼를 줄였을 때마다 송신을 한다면 비효율적이므로 ACK 응답과 합승을 하여 보내는 경우가 잦다.
합승은 ACK 응답끼리 일어나기도 하는데, 이 때 마지막에 보낼 ACK 번호만 통지하면 된다. 또한 윈도우 필드 끼리 합승한 경우에도 마지막에 보낼 윈도우 필드만 통지하면 된다.
오류 제어
수신 측은 송신 측이
NACK을 송신.ACK을 송신하지 않음.- 중복된
ACK송신
을 통해 오류 발생을 감지할 수 있다. 오류를 방식에 대해 살펴보자.
Stop and Wait
흐름 제어에서 살펴본 이 방식은 오류 제어에도 사용될 수 있다. 송신이 올 때 까지 대기한다.
Go Back N
특정 번호에서 에러 발생을 감지하면 해당 지점부터 재송신을 요청한다.
Selective Repeat
에러 발생한 데이터만 재전송하는 방식이다.
혼잡 제어
혼잡이란? 갑작스럽게 많은 데이터가 전송되어 이를 처리하지 못하는 경우를 말한다. 이는 빈번한 재전송을 유발하여 악순환이 반복된다. (부정적인 피드백이 일어난다.) 이 때 수신 측의 윈도우 필드를 조절하여 상황을 개선할 수 있다. 윈도우 필드는 수신 버퍼의 남은 양인 윈도우 사이즈와 혼잡한 상황을 고려하여 상정한 혼잡 윈도우 중에 작은 값을 사용한다. 이처럼 혼잡 윈도우를 통하여 혼잡 상황을 개선하는 행위를 혼잡 제어 중 혼잡 회피라고 한다. 기본적으로 AIMD(Additive Increase/Multiplicative Decrease)와 Slow Start가 있다.
AIMD
AIMD는 영어 뜻 그대로 일반적인 상황에서 윈도우가 1씩 증가하며, 혼잡한 상황(데이터 유실, 응답이 오지 않는 상황)에서는 절반으로 감소시키는 방법이다.
Slow Start
AIMD와 달리 지수배로 윈도우 크가기 증가하며, 혼잡 상황에서는 크기를 1로 급감하는 방법이다.
AIMD와 달리 지수배로 증가하기에 빠르게 키울 수 있다는 장점이 있다.
Tahoe
Slow Start 방식을 사용하다, 임계점 이후에는 AIMD를 사용하는 방식이다. 혼잡에 가까워질 수록 AIMD를 사용하여 천천히 혼잡에 다다르도록 하며, 혼잡 이후 Slow Start를 사용하여 작아진 사이즈를 빠르게 키운다.
Reno
Tahoe와 유사하다. 단 혼잡의 종류인 timeout과 3 duplicate ACKs를 구분하여 각각 윈도우 사이즈를 1로 설정, 윈도우 사이즈를 절반 설정 + 임계점을 해당 값으로 설정하며 다른 조치사항을 가진다.
TCP 소켓 연결 종료 방식
TCP 소켓이 연결을 종료할 때 사용하는 방식은 일반 연결 해제(Graceful connection release), 긴급 연결 해제(Abrupt connection release)가 있다. 일반 연결 해제 방식은 앞에서 살펴보았던 대기 시간이 있는 종료 방식이며, 긴급 연결 해제 방식은 의도치 않은 상황(SYN 비트가 활성화 되지않은 요청을 받은 경우, 유효하지 않은 헤더를 받은 경우, 자원이 부족한 경우)에 발생하며 컨트롤 비트 FIN이 아닌 RST을 전송하며 일어난다.
출처
- 핸드쉐이크 상세
- 흐름 제어, 오류 제어, 혼합 제어
- 종료 방식
