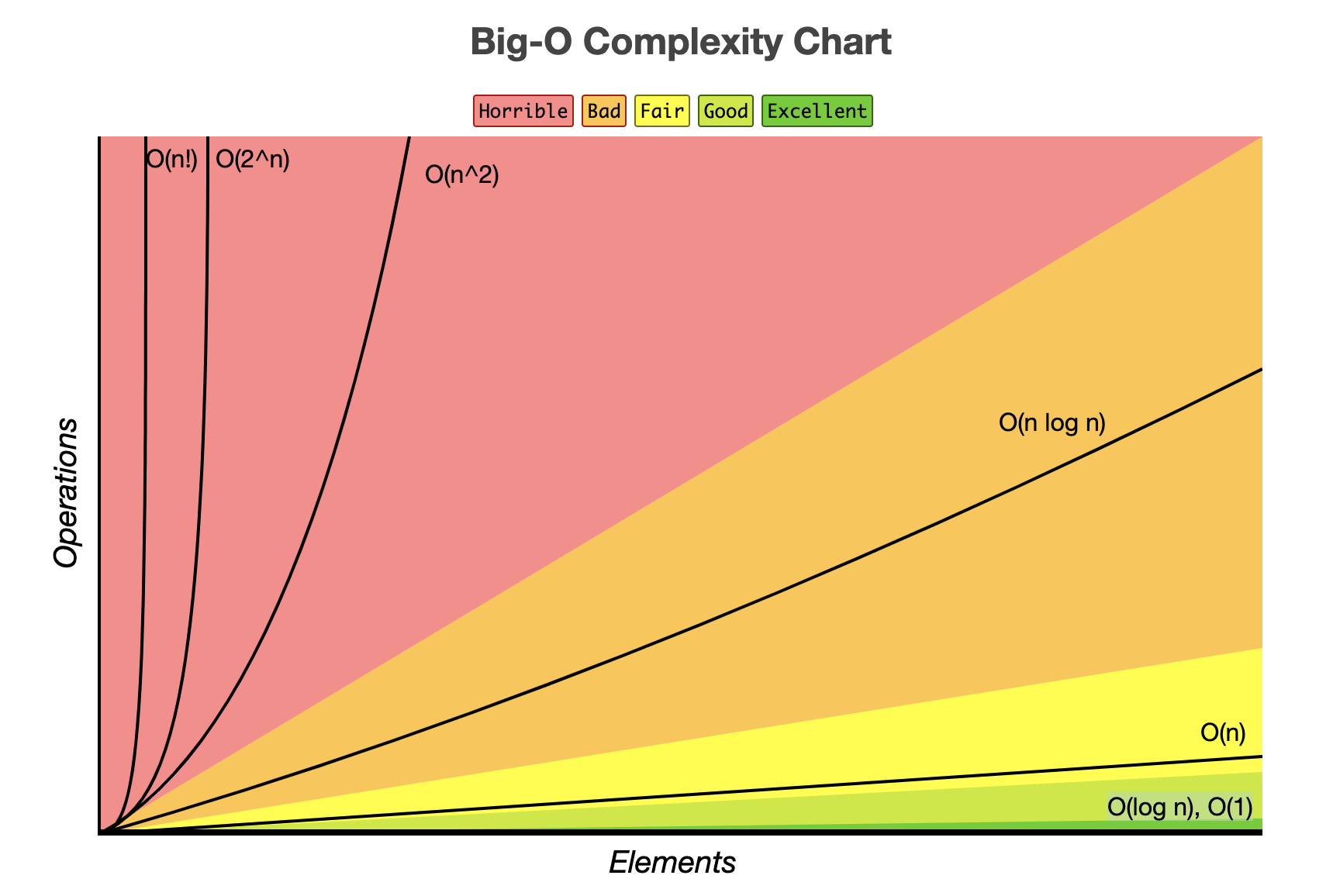
Big-O 표기법 => Big-Ω, Big-θ
Big-O는 입력값의 증가/감소함에 따라 시간이 얼마만큼 비례하여 증가/감소하는가를 표기하는 방법
O(1)
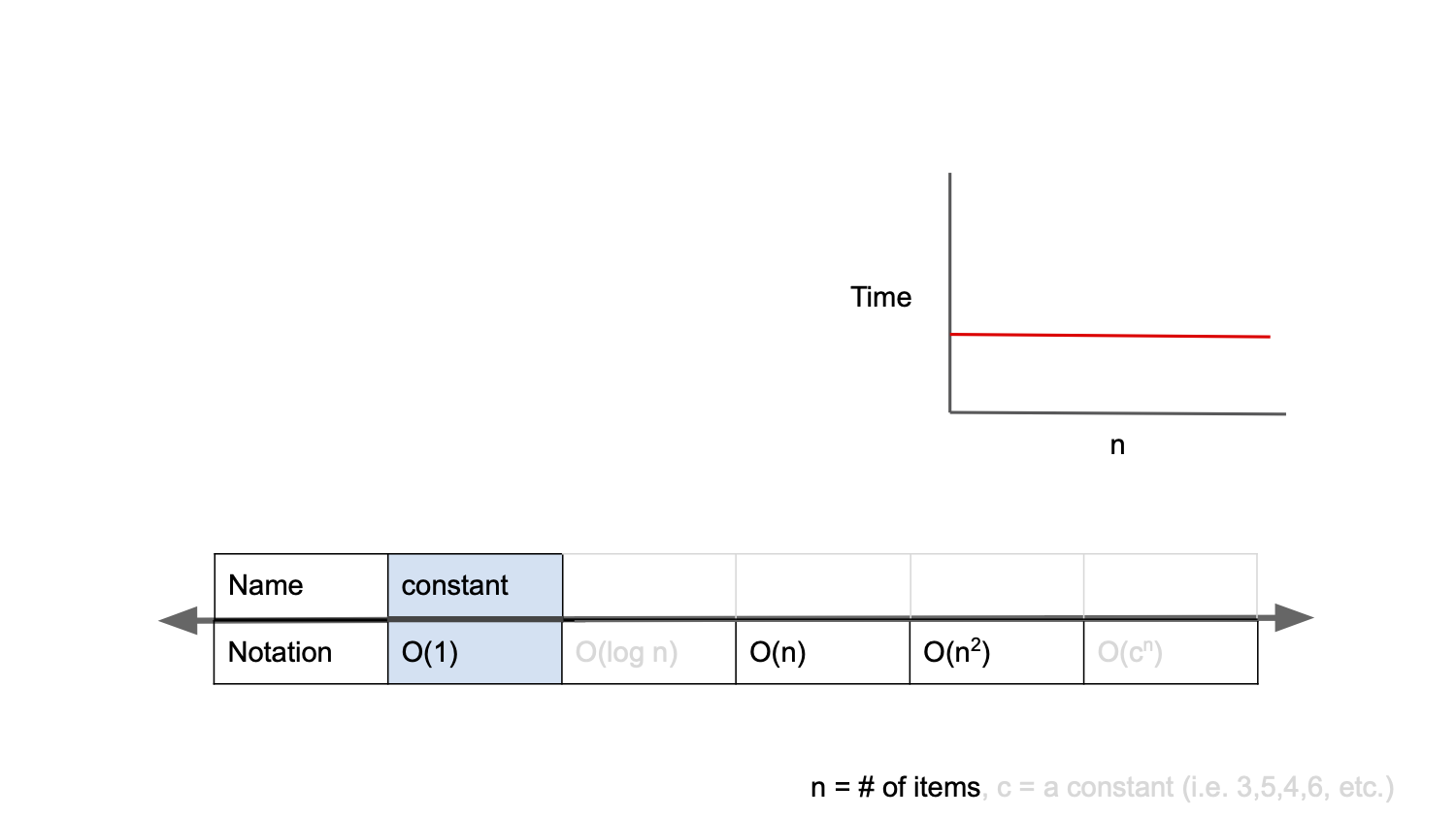
O(1)는 constant complexity라고 부르며, 입력값이 증가해도 시간은 늘어나지 않음을 의미
(입력값이 얼마나 커지는지와 관계없이, 즉시 출력값을 얻어낼 수 있다는 의미)
문이 3개가 있고 각 문에 방 번호 1 2 3이 있다고 가정해보자.
이때, 3번방 열쇠가 하나 주어졌는데 이 열쇠를 가지고 문을 여는 방법은
한가지 방법이다.
n(문 갯수)가 아무리 늘어난고 한들. 열쇠는 한 가지이기 때문에 바로 해당 방문을 꽂는 경우의 수 밖에 없기 때문에 위와 같은 그림이 나온다.
function O_1_algorithm(arr, index) {
return arr[index];
}
let arr = [1, 2, 3, 4, 5];
let index = 1;
let result = O_1_algorithm(arr, index);
console.log(result); // 2O(n)
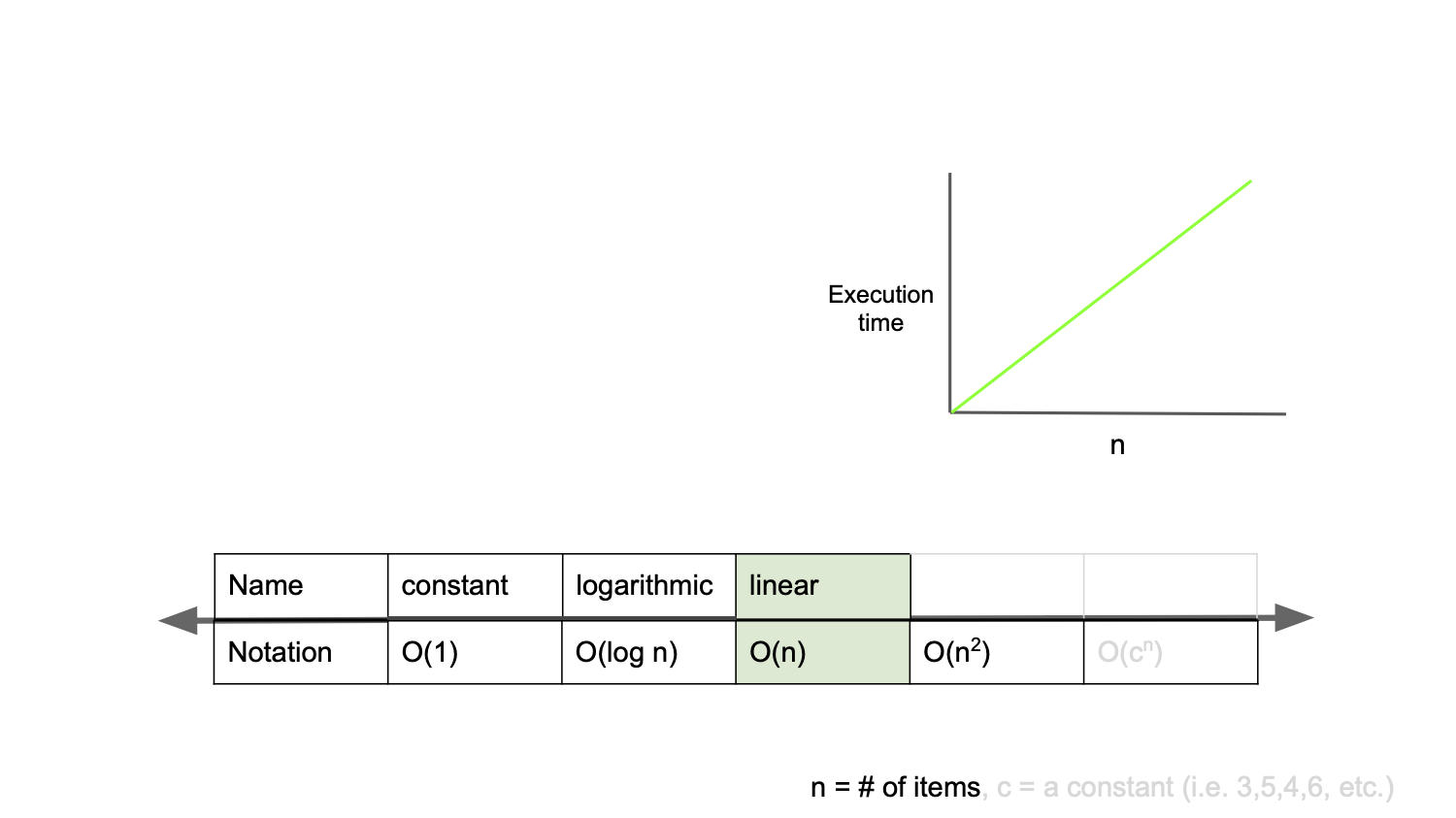
function O_n_algorithm(n) {
for (let i = 0; i < n; i++) {
// do something for 1 second
}
}O(n)은 linear complexity 라고 부르며, 입력값이 증가함에 따라 시간 또한 같은 비율로 증가하는 것을 의미한다.
예를 들어, for문 처럼 입력값이 1일 때 1초의 시간이 걸리고, 입력값을 100배로 했을 때 100배인 100초가 걸리기 때문에 그 알고리즘은 O(n)의 시간 복잡도를 가진다고 할 수 있다.
2n 3n 4n 모두 O(n)으로 표기
O(log n)
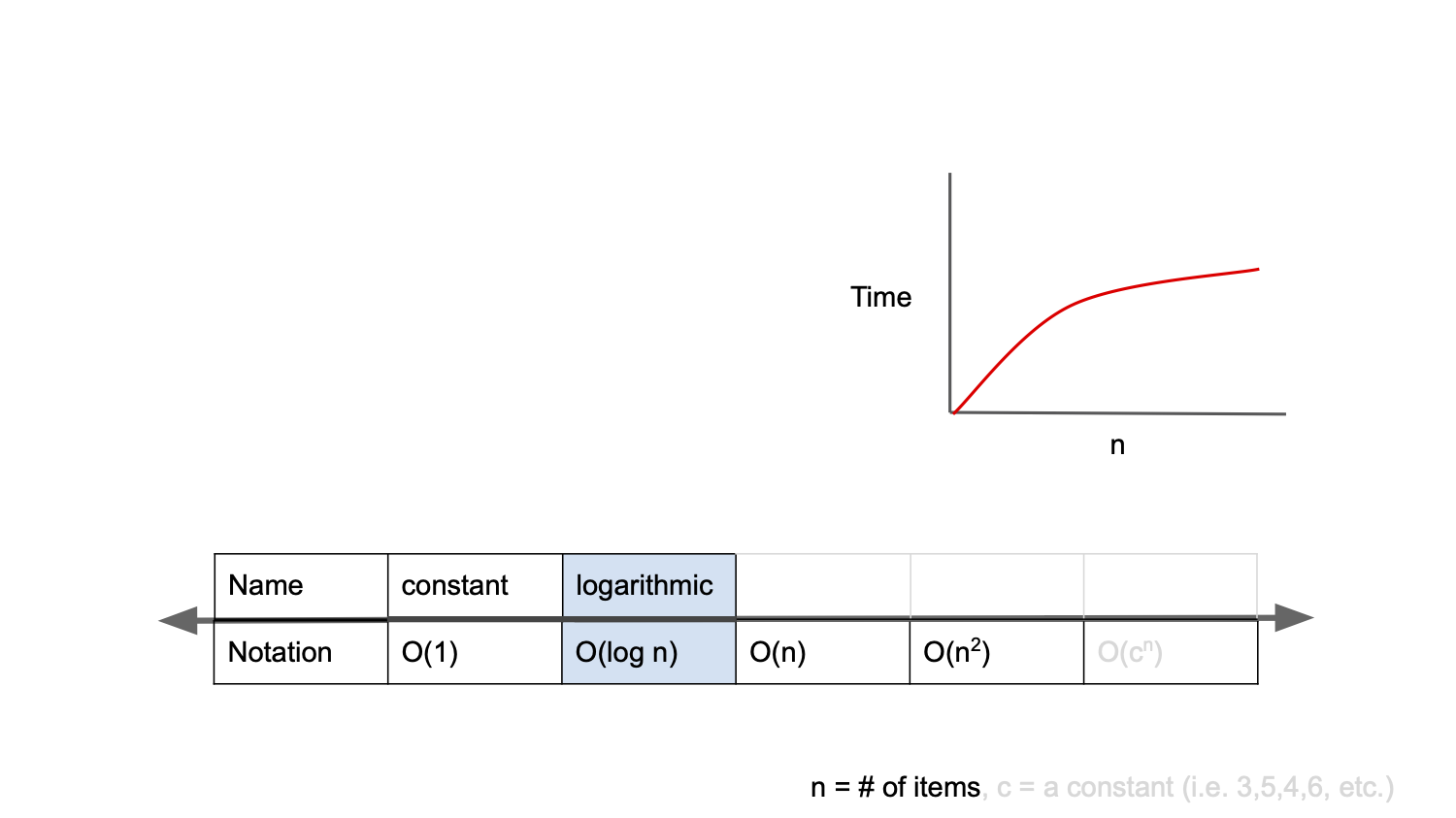
O(log n)은 logarithmic complexity라고 부르며 Big-O표기법중 O(1) 다음으로 빠른 시간 복잡도를 가진다.
up & down을 생각해서 계속 반으로 경우의 수를 줄여나가는 방법.
log 자체가 예를들어 log8이라면 3이나오는데, 2^3 = 2x2x2
즉, 로그는 2가 몇번 곱해지냐 8이되냐?라는 질문이다.
O(n^2)
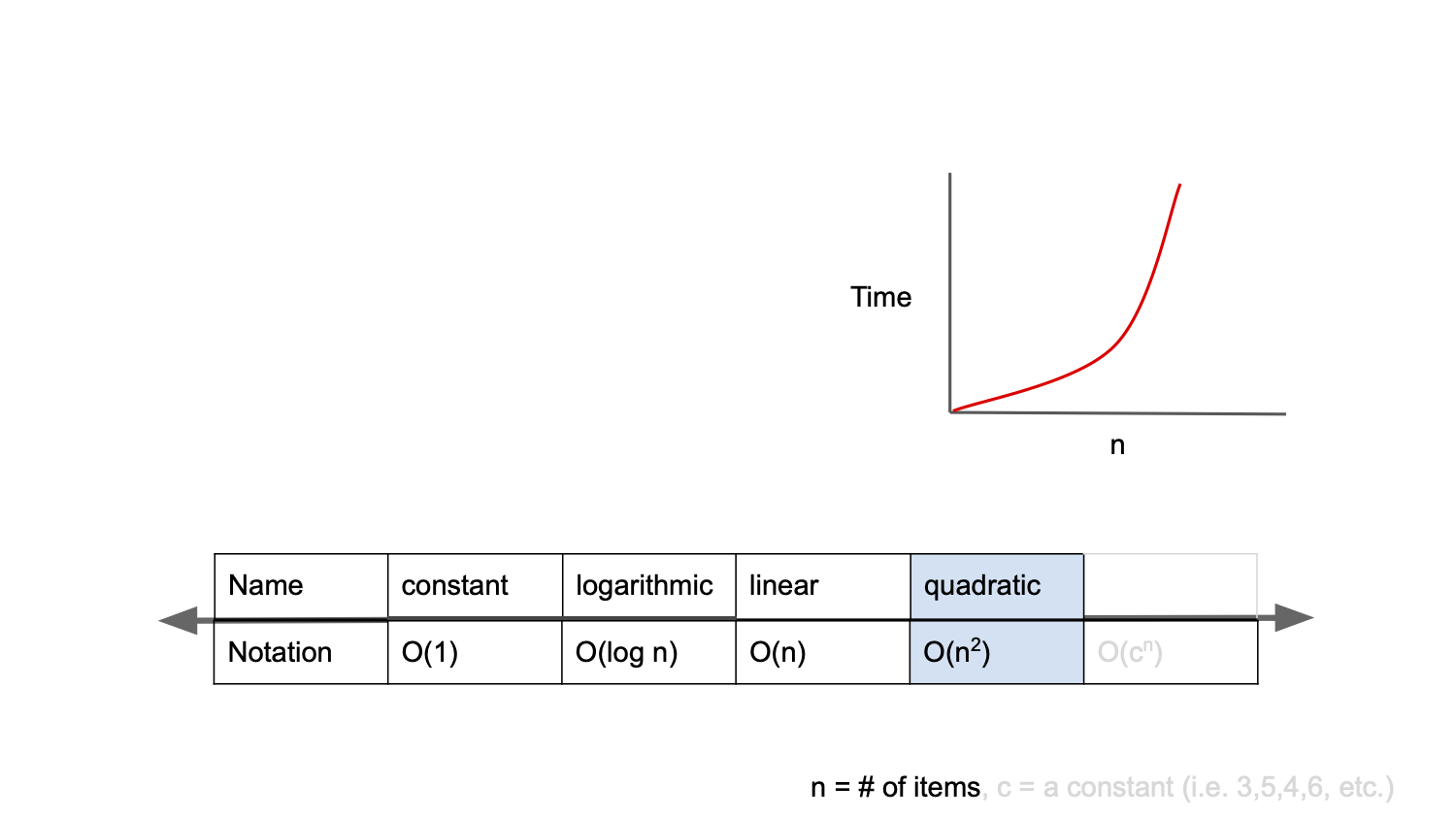
O(n^2)은 quadratic complexity 라고 부르며, 입력값이 증가함에 따라 시간이 그의 제곱수의 비율로 증가하는 것을 의미
예를 들어 입력값이 1일경우 1초가 걸리던 알고리즘에 5라는 값을 주었더니 25초가 걸리게 된다면, 이 알고리즘의 시간 복잡도는 O(n^2)라고 표현
function O_quadratic_algorithm(n) {
for (let i = 0; i < n; i++) {
for (let j = 0; j < n; j++) {
// do something for 1 second
}
}
}
function another_O_quadratic_algorithm(n) {
for (let i = 0; i < n; i++) {
for (let j = 0; j < n; j++) {
for (let k = 0; k < n; k++) {
// do something for 1 second
}
}
}
}n^3, n^5 도 모두 Big-O 표기법으로는 O(n^2)라 표기
O(2^n)
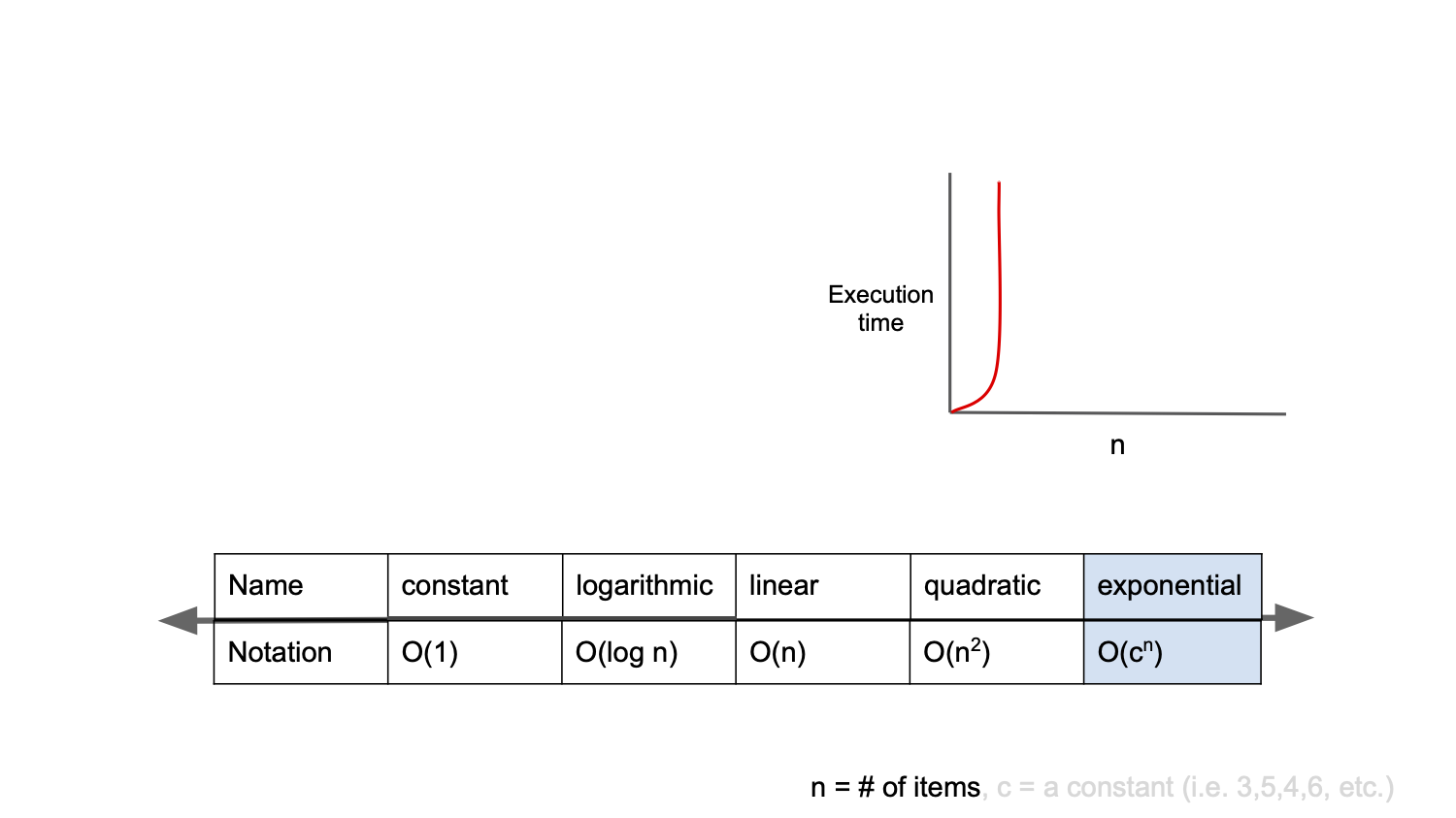
O(2^n)은 exponential complexity라고 부르며 Big-O표기법 중 가장 느린 시간 복잡도를 가진다.
function fibonacci(n) {
if (n <= 1) {
return 1;
}
return fibonacci(n - 1) + fibonacci(n - 2);
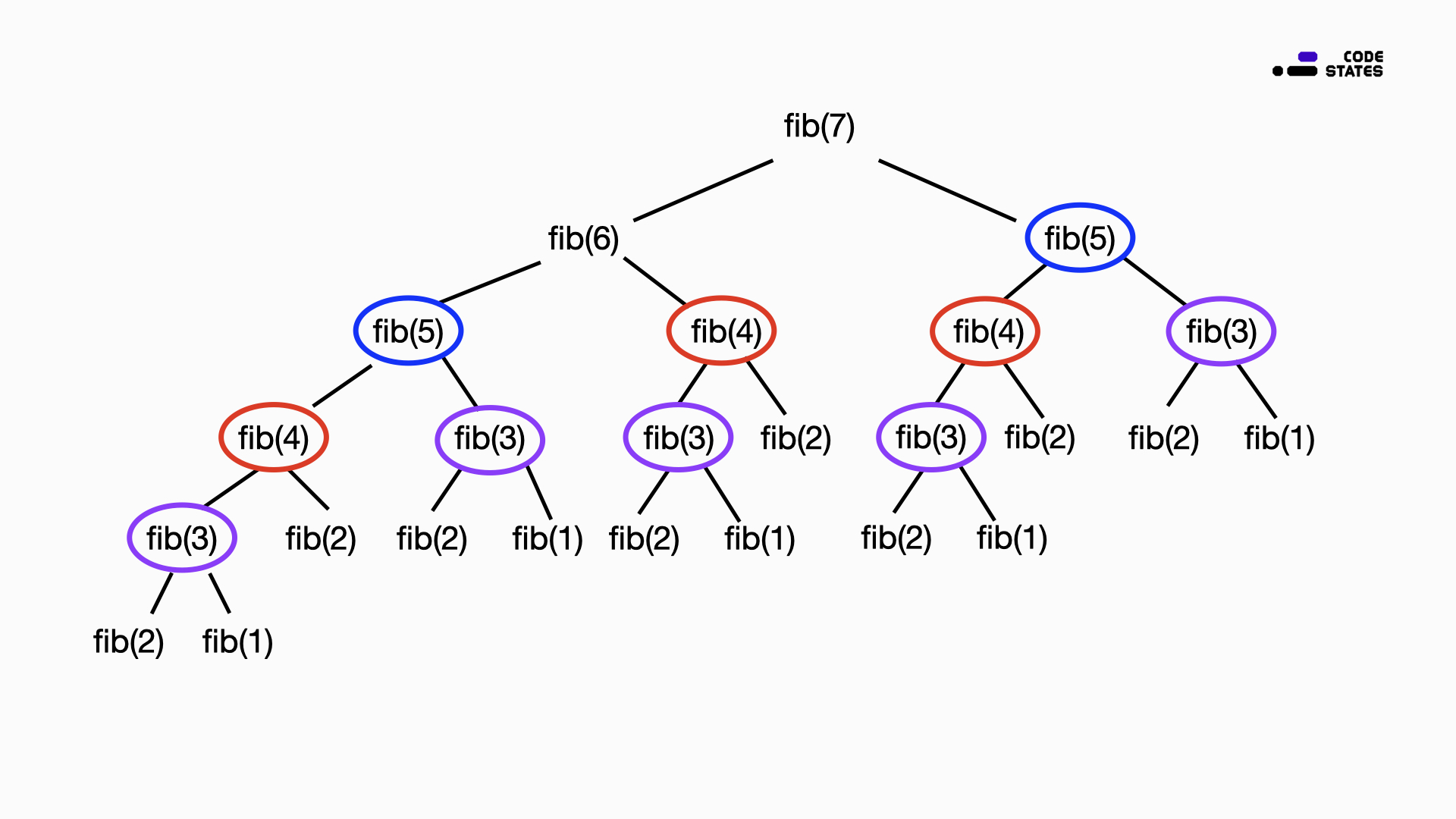
}대표적으로 피보나치가 해당 fibo가 재귀적으로 돌아가면서 다시 2개로 쪼개지면서 2^n의 시간 복잡도를 가지게 된다.
codestates from
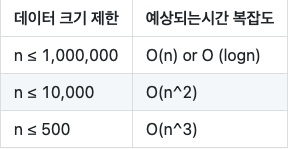
일반적으로 코딩테스트에서는 정확한 값을 제한된 시간 내에 반환하는 프로그램을 작성해야 합니다.
컴파일러 혹은 컴퓨터의 사양에 따라 차이는 있겠지만, 시간제한과 주어진 데이터 크기 제한에 따른 시간복잡도를 어림으로라도 예측해 보는 것은 중요합니다.
예를 들어, n만큼의 크기를 가지는 데이터가 있고, n의 제한을 1,000,000보다 작은 수라고 했을 때, 예상되는 시간 복잡도는 O(n) 혹은 O(nlogn)을 예측하여 프로그램을 작성 할 수 있습니다.
왜 n2의 시간복잡도는 예측할 수 없냐고 했을 때, 실제 수를 대입해 보면 어느 정도의 답이 나오는데요, 1,000,000의 2 정도만 되어도 즉시 처리하기에는 무리가 있는 숫자가 나오게 됩니다. (1,000,000 * 1,000,000=1,000,000,000,000) 반대의 경우로 n≤500 정도로 제한이 되었을 때는 n3 정도까지는 예측 할 수 있습니다. n3으로 문제를 풀게 된다면 금방 풀 수 있을 텐데, 시간복잡도를 log n까지 낮추느라 끙끙댈 필요가 없다는 말로도 바꿀 수 있겠습니다.
이를 기준으로 데이터가 클 때는 O(n) 혹은 O(log n) 정도로 예측해서 문제를 풀어보시고, 주어진 데이터가 작을 때는 우선 시간복잡도가 크더라도 문제 풀이에 집중하는 것도 좋습니다.
대략적인 데이터 크기에 따른 시간복잡도는 다음과 같습니다.