자료구조&알고리즘
1.[자료구조] 큐(Queue) -C++ 구현
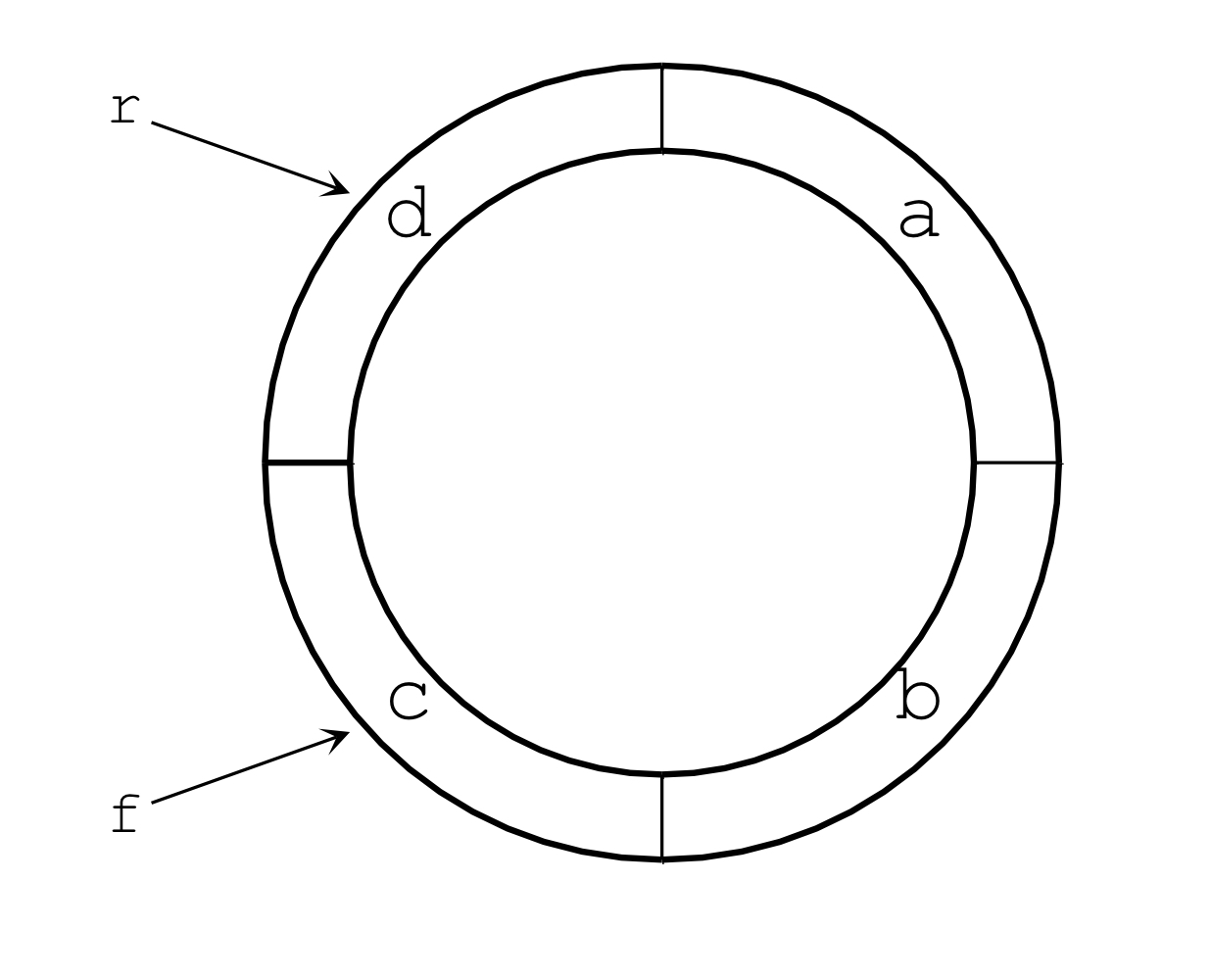
Queue > 큐(queue)란? > > 선입선출 (First In First Out)의 구조를 가지는 자료구조 -> 시간 순서상 먼저 들어간 데이터가 먼저 나오는 자료구조이다. 구현
2.[자료구조] 스택(stack), 큐-c++

stack은 데이터를 저장하는 자료구조 중 하나로 후입선출(Last In First Out) 의 구조를 따른다. 즉, 나중에 추가된 데이터가 먼저 제거되는 구조이다. 활용 예시: 함수 호출이나 재귀 알고리즘, 데이터를 저장하고 추출하는 데에 있어서 효율적이다.call
3.[자료구조] 우선순위 큐(priority queue) -C++
우선순위 큐(Priority Queue)는 각 요소에 우선순위가 할당된 큐 자료구조로 일반적으로 높은 우선순위를 가진 요소가 낮은 우선순위를 가진 요소보다 먼저 처리되는 큐이다. 우선순위 큐는 일반적인 큐와 달리 요소를 삽입할 때마다 요소의 우선순위를 기준으로 정렬되거
4.[자료구조] 힙(heap) - c++
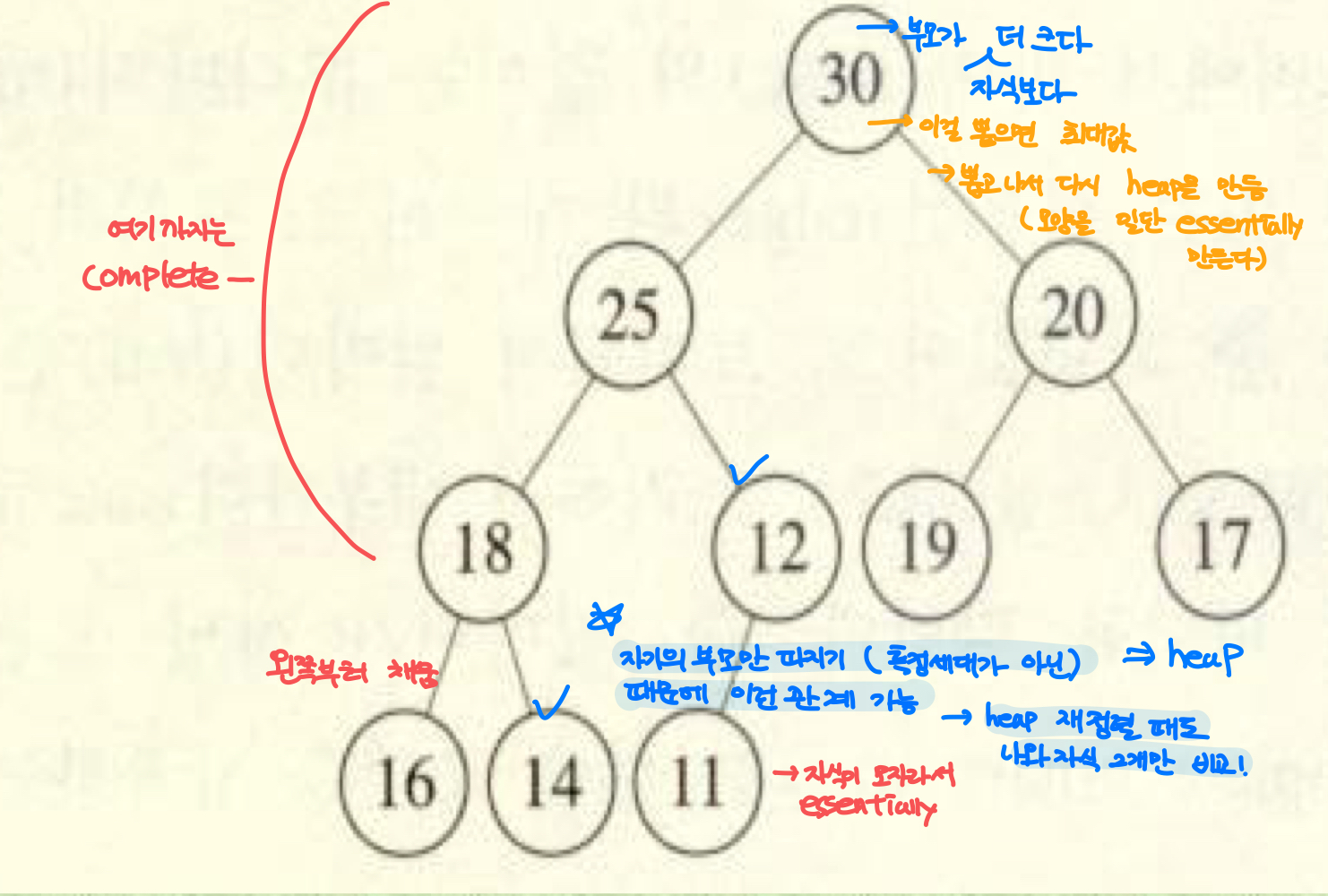
heap은 그 자체로 우선 순위 큐의 구현과 일치하다.heap은 완전이진트리(complete binary tree) 구조로 heap이 되기 위한 조건은 다음과 같다.essentially complete binary tree 구조이다.min heap의 경우 각 노드에 저
5.[알고리즘] 정렬(insertion, bubble, selection, quick, merge, heap) - C++
정렬 > 정렬: sorting > - 지정한 기준에 맞게 정렬해서 출력하는 알고리즘 ⭐️ inplace sort : 정렬하는 데이터에 추가적 메모리 공간이 필요하지 않은 정렬 시간 복잡도: O(1) > O(nlogn) > O(N) > O(Nlogn) > O(n^2)
6.[자료구조] 해시 테이블(Hash Table) -C++
테이블 (table) :데이터를 구조화해 저장하는 자료구조로 key-value 쌍으로 데이터를 입력 받아 키를 입력해 해당 쌍의 데이터를 찾아온다.해시 테이블:큰 테이블 하나를 키로 생각해서 key-value 쌍으로 데이터를 입력받는다.해시 함수를 이용해 데이터를 고유
7.[자료구조] BST(Binary Search Tree) 이진 탐색 트리- C++

이진 탐색 트리특정 노드를 기준으로 왼쪽 서브트리에는 해당 노드보다 작은 값으로 이루어져 있고 오른쪽 서브트리는 해당 노드보다 큰 값으로 이루어져 있는 이진 트리(Binary Tree) 이다.조건: 특정 노드 기준 왼쪽은 해당 노드보다 작은 값으로 이루어진다.특정 노드
8.[알고리즘] 너비 우선 탐색 BFS(Breath-First-Search)-C++
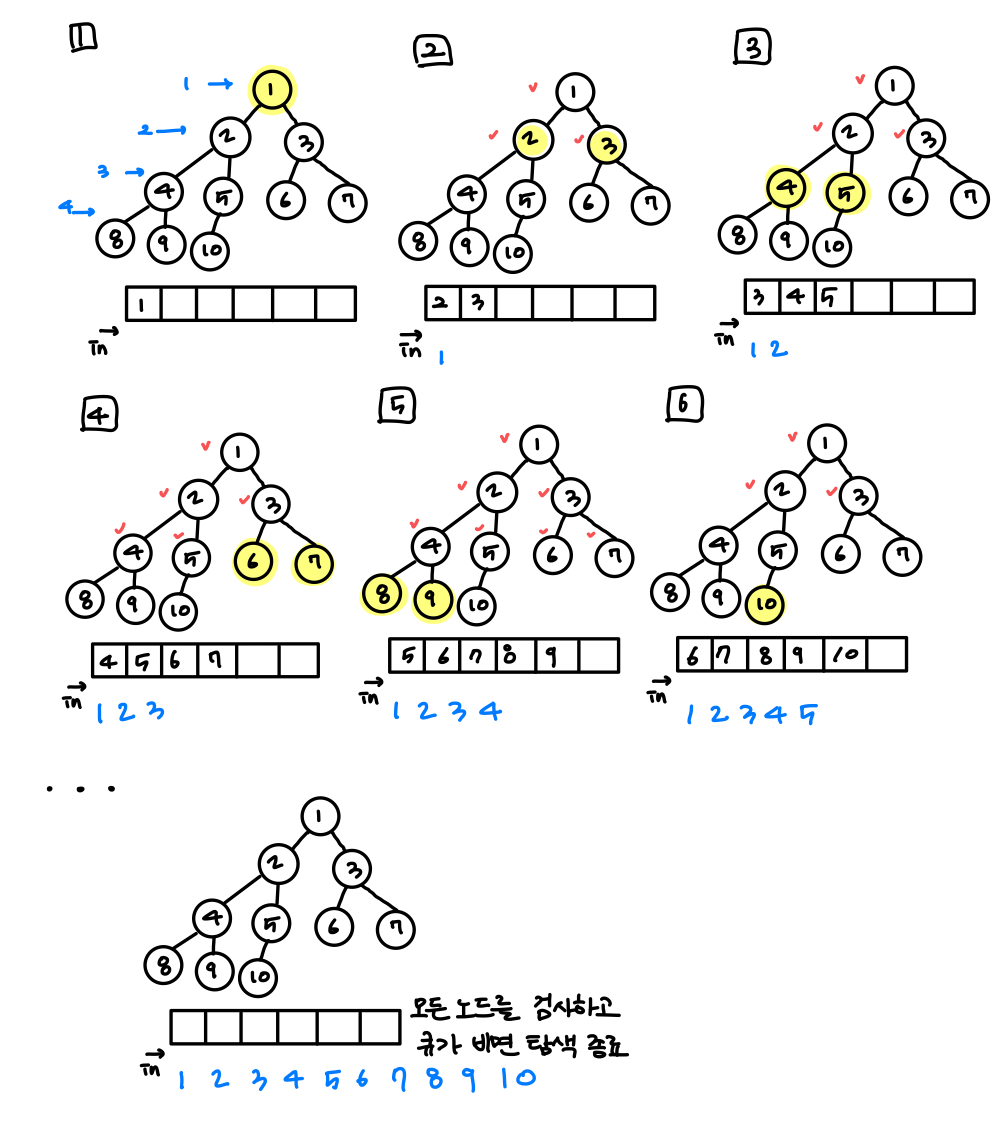
BFS(Breath-First-Search) : 너비 우선 탐색같은 자식 레벨은 다 탐색하고 다음 레벨의 자식으로 넘어간다.root 노드부터 먼저 검색level 1의 모든 노드 검색(왼쪽 노드부터 오른쪽 노드로)level 2…leaf마디 까지 모든 노드 검색사용 : 그
9.[알고리즘] 깊이 우선 탐색 DFS(Depth - First- Search)-C++
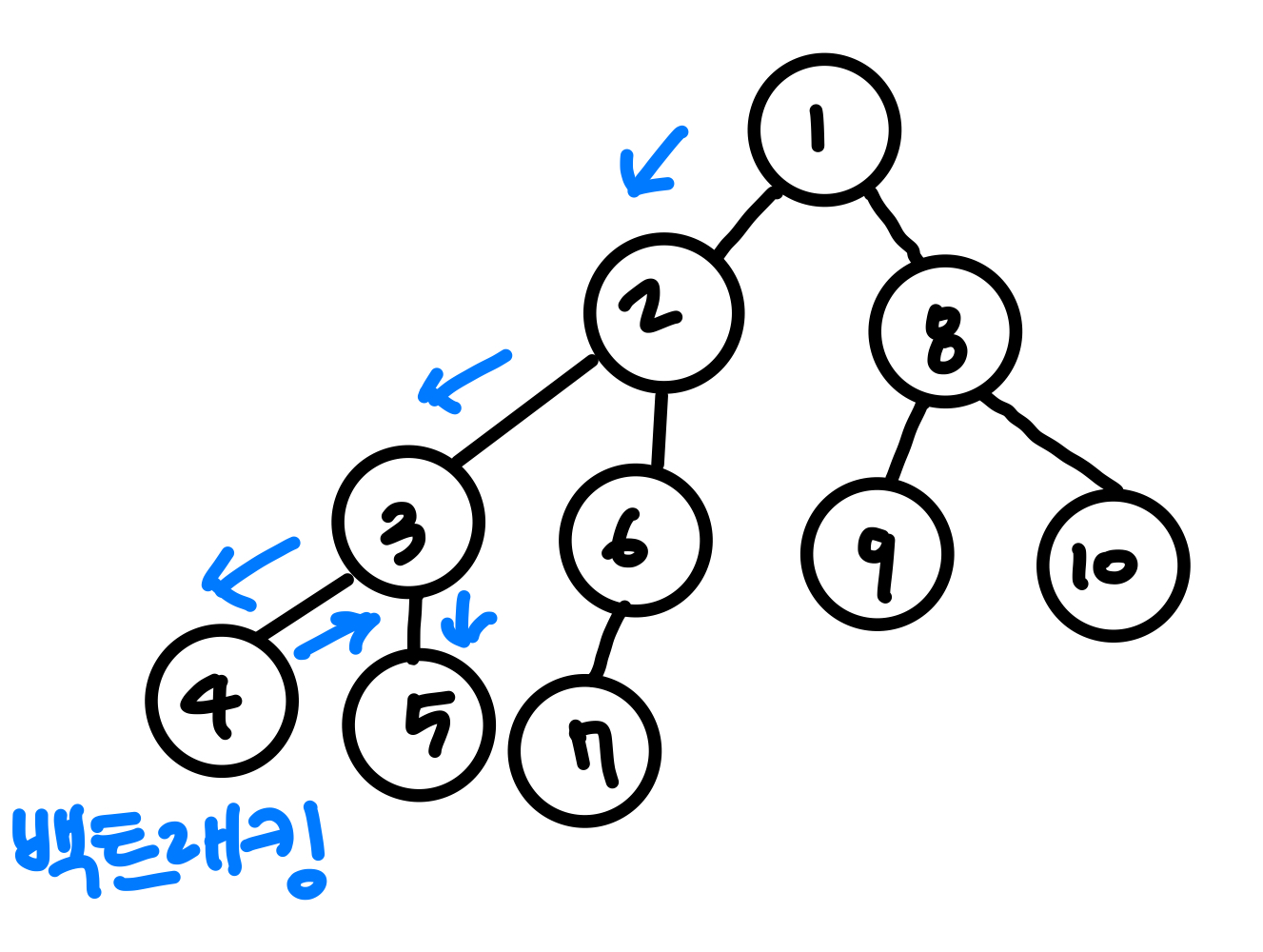
DFS(Depth-First-Search) : 깊이 우선 탐색현재 탐색중인 경로를 끝까지 탐색하고 다음 경로로 넘어간다.root 노드부터 먼저 검색root노드의 자식 중 가장 왼쪽 노드 부터 탐색왼쪽 노드의 자식 중 왼쪽….을 탐색하고 다시 부모 노드로 돌아가서 오른쪽
10.[알고리즘] 백트래킹 (Back Tracking), 되추적 알고리즘-C++
되추적 알고리즘되추적 알고리즘은 상태공간트리에서 깊이 우선 탐색 (DFS)를 실시유망하지 않은 노드들은 가지( pruning )쳐서 검색하지 않는다.유망한 노드에 대해서만 그 노드의 자식 노드들을 검색한다.전혀 해답이 나올 가능성이 없는 노드는 유망하지 않다. (non