LLM의 Agent를 보다 잘 이해하기 위해 CAMEL: Communicative Agents for “Mind” Exploration of Large Language Model Society (2023. Guohao Li, Hasan Abed, Al Kader Hammoud, Hani Itani, Dmitrii Khizbullin) 논문을 리뷰 해본다.
Intro.
대규모 언어 모델(LLM)은 다양한 자연어 처리 태스크에서 인간에 필적하는 능력을 보여 주었지만, 이는 주로 명확한 단일 명령에 대한 응답에 국한되었다. 복잡하고 다단계에 걸친 작업을 자율적으로 수행하는 데에는 여전히 어려움이 있으며, 이는 다음과 같은 근본적인 문제 때문이다.
- 지속적인 인간의 안내 필요성: 사용자는 전체 작업 과정을 세부 단계로 나누어 순차적으로 명령해야 하므로, 완전한 자동화를 구현하기 어렵다.
- 의도의 불일치 (Intent Alignment): 사용자의 추상적인 목표와 LLM이 이해하고 실행하는 구체적인 행동 사이에 간극이 발생하여, 예상치 못한 결과를 초래할 수 있다.
논문은 이러한 문제 해결을 위해 사회적 협력(Social Cooperation)의 개념을 도입한다. 인간 사회에서 개인이 서로 협력하여 복잡한 문제를 해결하듯, AI 에이전트들도 서로 소통하고 협력함으로써 자율성을 높일 수 있다는 가설을 세웠다. 이를 위해, 작업을 지시하는 역할과 수행하는 역할을 분리하여 두 에이전트가 대화를 통해 목표를 구체화하고 달성해 나가는 CAMEL 프레임워크를 제안하였다.
Related Work.
CAMEL은 여러 기존 연구 분야의 아이디어를 기반으로 하며, 동시에 이들과 차별점을 가진다.
- 단일 에이전트 시스템 (Single-Agent Systems): Auto-GPT, BabyAGI 등은 단일 LLM 에이전트가 스스로 작업을 계획하고 실행하는 프레임워크이다. 이들은 외부 도구(메모리, 웹 검색 등)를 활용하여 능력을 확장했지만, 에이전트가 잘못된 계획에 빠졌을 때 스스로 교정하기 어려운 한계가 있다.
- 다중 에이전트 시스템 (Multi-Agent Systems): 여러 에이전트가 상호작용하는 연구는 이전부터 존재해왔지만 대부분의 시스템은 에이전트의 행동 규칙을 인간이 직접 설계해야 했다. LLM의 등장은 에이전트들이 보다 유연하고 자연스러운 소통을 통해 협력할 수 있는 새로운 가능성을 열었다.
- 프롬프트 엔지니어링 (Prompt Engineering): Chain-of-Thought(CoT), In-context Learning 등은 LLM의 성능을 극대화하기 위한 프롬프팅 기법이다. CAMEL의 “인셉션 프롬프팅”은 이러한 프롬프트 엔지니어링의 연장선상에 있으며, 특히 “역할 부여”를 통해 LLM의 행동을 일관성 있게 제어하는 데 초점을 맞춘다는 점에서 차별화 전략을 가진다.
Camel Framework.
1. 개요 (Overall)
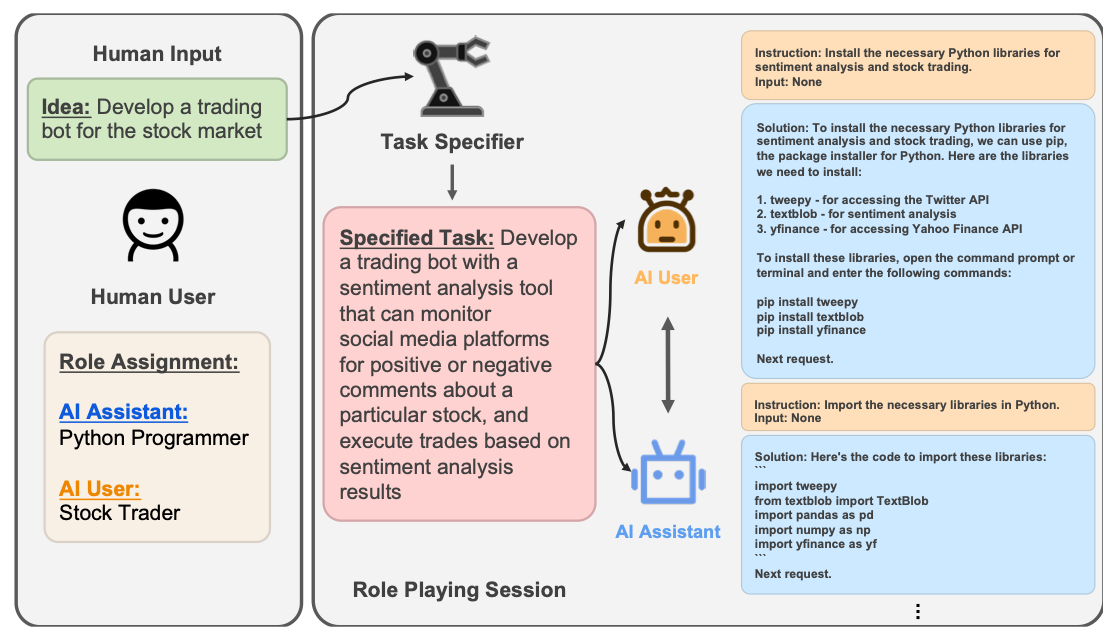
프레임워크의 목표는 추상적인 아이디어(ex. "주식 거래 봇 만들기")를 구체적인 실행 계획으로 발전시키고 완료하는 것으로써 이 과정은 AI 사용자 에이전트와 AI 비서 에이전트 간의 턴 기반 대화(Turn-based conversation)를 통해 이루어진다.
2. 역할극 에이전트 (Role-Playing Agents)
두 에이전트는 명확히 구분된 역할을 수행하며 상호 보완적인 관계를 형성한다.
- AI 사용자 (AI User): 인간 사용자의 의도를 대변하는 역할을 한다. 태스크를 작은 단위로 쪼개어 AI 비서에게 지시하고, 결과물을 검토하며, 다음 단계를 안내하는 '지휘자' 역할을 담당한다.
- AI 비서 (AI Assistant): AI 사용자의 지시를 받아 실제 코드를 작성하거나 글을 쓰는 등 구체적인 작업을 수행하는 “실행자” 역할을 하게된다. 지시가 불분명할 경우, 역으로 질문하여 요구사항을 명확히 하는 역할도 수행한다.
이러한 역할 분담은 AI 비서가 길을 잃는 것을 방지하고, AI 사용자가 전체 작업의 맥락을 유지하도록 도울수 있다.
3. 인셉션 프롬프팅 (Inception Prompting)

성공적인 역할극을 위해서는 각 에이전트에게 정체성과 임무를 명확히 주입하는 초기 프롬프트가 필수적이며, 인셉션 프롬프트는 다음과 같은 구조로 설계된다.
- 역할 지정: "당신은 {직업}입니다." (e.g., "당신은 노련한 파이썬 개발자입니다.")
- 임무 부여: "당신의 임무는 {상대방 직업}과 협력하여 {공동의 목표}를 달성하는 것입니다."
- 행동 규칙 및 제약 조건 설정: "지시는 한 번에 하나씩 명확하게 내려야 합니다." 또는 "모르는 것은 반드시 질문해야 하며, 임의로 작업을 추측해서는 안 됩니다."
- 종료 조건 명시: "최종 목표가 달성되었다고 판단되면
<CAMEL_TASK_DONE>이라고 출력하세요."
이 정교한 초기 설정은 에이전트들이 대화 내내 일관된 페르소나를 유지하고 목표 지향적인 상호작용을 하도록 강제한다.
4. 대화 기반 솔루션 생성 (Conversation-driven Solution Generation)
인셉션 프롬프팅이 완료되면, 두 에이전트는 다음과 같은 대화 사이클을 반복하며 작업을 수행하게 된다.
AI 사용자 지시 → AI 비서 수행 및 결과 보고 → AI 사용자 피드백 및 다음 지시 → …
이 과정 전체가 로그로 기록되어서 문제 해결의 전 과정을 투명하게 추적하고 분석할 수 있다.
Experiments.
논문에서는 CAMEL 프레임워크의 유효성을 검증하기 위해 다음과 같은 실험을 설계하고 실행하였다.
- 데이터셋 구축: 다양한 역할과 작업 시나리오를 생성하기 위해 두 개의 대규모 데이터셋을 구축
- CAMEL AI-Society: 사회의 다양한 직업(e.g., 프로그래머, 작가, 의사)과 그들이 수행할 만한 작업을 페어링한 데이터셋
- CAMEL Code: 프로그래밍 및 코드 생성과 관련된 특정 작업을 모은 데이터셋
- 평가 태스크: 데이터셋을 기반으로 생성된 다양한 태스크(e.g., 웹 스크래퍼 개발, 이메일 초안 작성, 수학 문제 풀이)를 에이전트에게 부여
- 비교 모델 (Baselines): 별도의 지시 에이전트 없이, LLM에게 전체 작업을 한 번에 지시하는 '단일 프롬프트(Single-Prompt)' 방식과 성능을 비교
- 평가 지표:
- 태스크 성공률: 에이전트가 주어진 목표를 성공적으로 완수했는지 여부
- 대화 길이: 작업을 완료하는 데 필요한 대화 턴(Turn)의 수
- 비용 효율성: 소모된 토큰(Token)의 수
- 인간 평가: 생성된 결과물의 품질을 인간이 직접 평가
Results and Analysis.
논문에 실험 결과에서는 CAMEL 프레임워크에 놀라운 성능을 보여주고 있다.

실패한 사례들은 주로 인셉션 프롬프트가 충분히 구체적이지 않거나, 태스크 자체가 지나치게 복잡하여 에이전트들이 대화의 맥락을 잃어버리는 경우였으며, 이는 프롬프트 설계의 중요성을 다시금 강조하는 부분이다.
Reference.
