Intro.
RAG는 검색(Retrieval)과 생성(Generation)을 결합한 구조로써 LLM이 외부 지식(문서, DB 등)을 참고하여 답변을 만드는 구조이다. LLM은 학습 데이터 기준으로 답변을 생성하므로 최신 정보나 도메인에 특화된 정보에 약한 모습을 보이고, 이를 보완하기 위해 외부 지식 정보를 통해 답변을 생성하는 원리이다.
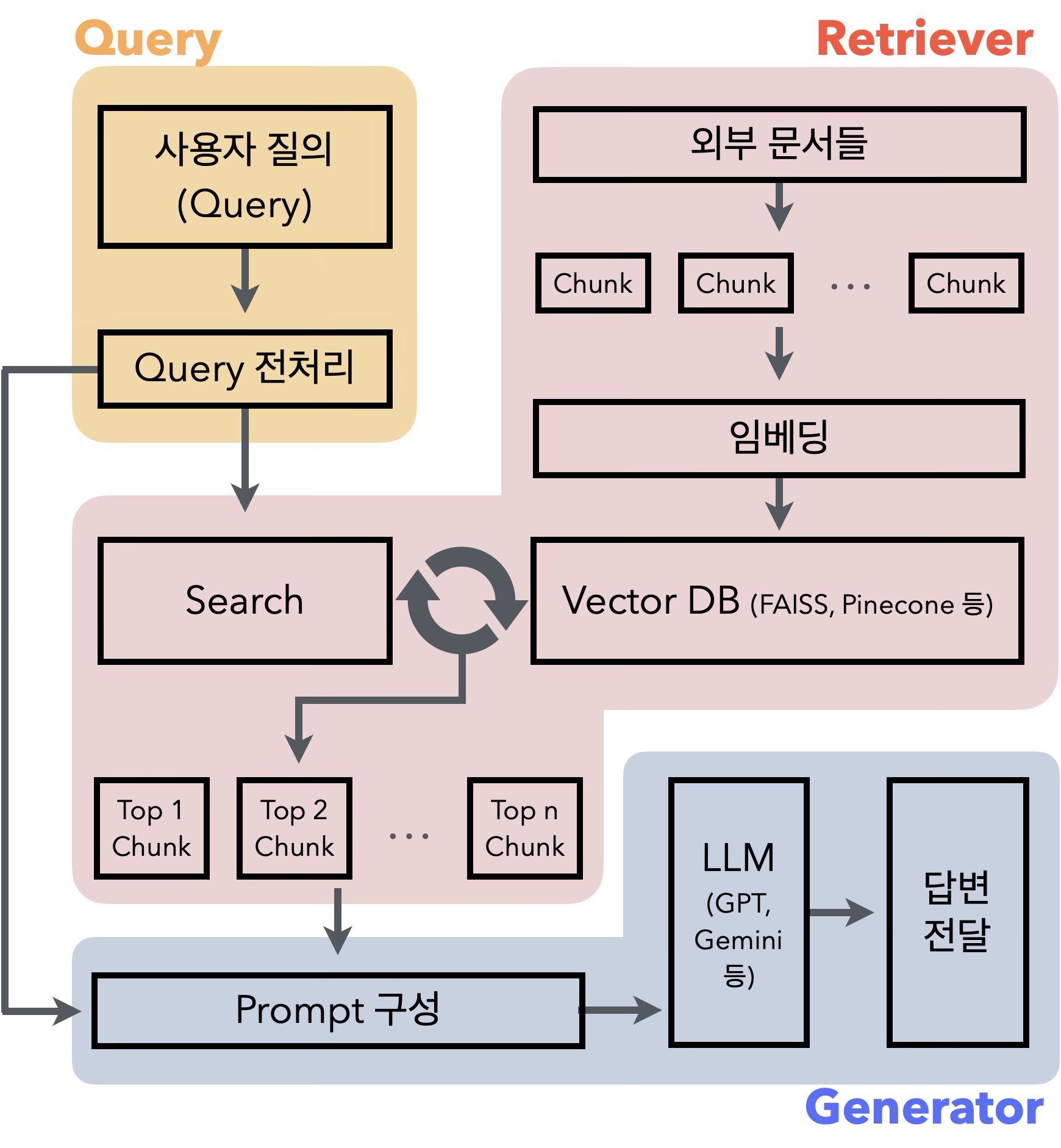
1. Query
사용자가 자연어를 통해 질문을 입력하는 단계이다. 해당 입력은 전처리(ex. lowercasing, stopwords 제거, typo correction 등) 될 수 있다. 또는 필요시에 이전 대화 context를 붙여서 사용할 수도 있다.
2. Retriever
RAG의 핵심 단계로써, 해당 부분이 대부분에 성능을 결정하게 된다.
2.1 Indexing 파이프라인
-
Chunking
LLM은 보통 긴 문서를 한 번에 처리하지 못하므로, 의미 단위의 짧은 Chunk로 분할할 필요가 있다. 보통 “문단 단위” 또는 “Fixed-length + Overlap”방식을 사용한다.
- 문단 단위
- 논리적 구조(ex. 문단, 제목, 리스트 등)를 기준으로 나누는 방식으로 내용 흐름을 잘 보존할 수 있다.
- 보통
\n\n(줄바꿈 두번) 이나 markdown heading###(제목) 등을 기준으로 삼는다.
- Fixed-length + Overlap
- 일정한 길이 (ex. 500자 or 512 token) 단위로 자르되, 이전 chunk의 끝 일부를 다음 chunk에 overlap하여 문맥의 연속성을 확보한다.
- 예를 들어, chunk1: [0~500자], chunk2: [400~900자]로 두어 100자를 겹치게 하는 방식이다.
# 예시코드 (with.LangChain) from langchain.text_splitter import RecursiveCharacterTextSplitter # 긴 문서 doc_text = """ GA4는 구글의 차세대 웹 분석 플랫폼입니다. 이벤트 기반 구조를 사용하며... """ # 텍스트 분할기 설정 splitter = RecursiveCharacterTextSplitter( chunk_size=500, # 각 청크의 최대 길이 chunk_overlap=100, # 청크 간 중복 영역 (문맥 유지를 위해) ) chunks = splitter.split_text(doc_text) print(chunks[:2]) # 첫 두 개 chunk 확인 - 문단 단위
-
Embedding
자연어인 텍스트를 고차원 공간의 수치 벡터로 변환하는 과정이다. Open AI, Cohere, Gemini, HuggingFace 등 여러 곳에서 임베딩 모델을 지원하고 있으므로 상황에 맞는 모델을 사용하면 된다.
# 예시코드 01 (with.OpenAI) import openai openai.api_key = "YOUR_OPENAI_API_KEY" def get_openai_embedding(text): response = openai.Embedding.create( input=[text], model="text-embedding-ada-002" ) return response['data'][0]['embedding'] text = "GA4에서 session_start 이벤트는 언제 발생하나요?" embedding = get_openai_embedding(text) print(len(embedding)) # 1536차원 벡터# 예시코드 02 (with.HuggingFace 내 sentence-transformers) from sentence_transformers import SentenceTransformer model = SentenceTransformer("all-MiniLM-L6-v2") # 384차원, 속도 빠름 # 다른 예: "multi-qa-MiniLM-L6-cos-v1", "paraphrase-mpnet-base-v2", "bge-base-en-v1.5" text = "GA4에서 session_start 이벤트는 언제 발생하나요?" embedding = model.encode(text) print(embedding.shape) -
Vector Store
사용자의 질문을 벡터화 하여 유사도 기반 검색을 수행 하기 위해 벡터로 변환된 문서의 내용을 검색 가능한 형태로 저장하는 과정이다.
다음 표는 주요 벡터 DB 프로덕트들이다. (25.04 기준)
FAISS Pinecone Weaviate 개발 주체 Meta Pinecone Inc. Semi Technologies 배포 방식 로컬 라이브러리 클라우드 SaaS 로컬(Docker/K8s) + 클라우드 사용 대상 학습, PoC, 프로토타입 실무 운영, 대규모 RAG 실무 운영, 고급 검색 필요 시 메타 데이터 필터링 없음 매우 강력 매우 강력 하이브리드 검색 불가능 불가능 가능 (BM25 + Dense) 검색 정확도 Top-k Dense Top-k Dense + Reranker 지원 Dense + BM25 Hybrid 관리 편의성 매우 쉬움 매우 쉬움 중간 (Docker 필요) 유사도 방식 L2, Inner Product Cosine, Dot, L2 Cosine, Hybrid, Customizable 확장성 없음 무제한 (클라우드) 있음 (K8s 또는 클라우드 배포) API 제공 없음 REST API REST + GraphQL API 라이선스 Apache 2.0 Closed SaaS Apache 2.0 활용 사례 개인 프로젝트, 연구용 실시간 RAG API, 챗봇 SaaS AI 기반 검색엔진, 추천 시스템 등 # 예시코드 (with.FAISS) # pip install sentence-transformers faiss-cpu from sentence_transformers import SentenceTransformer import numpy as np import faiss # 2. 문서 준비 (예: 문서 chunk 3개) documents = [ {"id": 0, "text": "GA4는 구글의 이벤트 기반 웹 분석 도구입니다."}, {"id": 1, "text": "session_start 이벤트는 사용자가 새 세션을 시작할 때 발생합니다."}, {"id": 2, "text": "Universal Analytics는 페이지뷰 중심의 모델입니다."} ] # 3. 임베딩 모델 로딩 (HuggingFace) model = SentenceTransformer("all-MiniLM-L6-v2") # 384차원 # 4. 텍스트 → 임베딩 벡터 texts = [doc["text"] for doc in documents] embeddings = model.encode(texts) embeddings = np.array(embeddings).astype("float32") # 5. FAISS 인덱스 생성 및 벡터 추가 dimension = embeddings.shape[1] index = faiss.IndexFlatL2(dimension) # L2 거리 기반 검색 index.add(embeddings) # 6. 원문 문서 저장 (메타데이터 매핑용) doc_store = {i: documents[i] for i in range(len(documents))} # ─────────────────────────────────────── # 검색 테스트 (사용자 쿼리 → 임베딩 → 유사 문서 검색) query = "GA4에서 세션은 언제 시작되나요?" query_vec = model.encode([query]).astype("float32") top_k = 2 D, I = index.search(query_vec, k=top_k) print(f"\n Query: {query}") print(f"\n Top {top_k} 유사 문서:") for i in I[0]: print(f"- ID: {doc_store[i]['id']} | 내용: {doc_store[i]['text']}")
2.2 Retrieval 전략
파이프라인에 따라 문서는 벡터 DB에까지 저장된다. 이 후, 사용자에 질의(Query)와 가장 연관 있는 문서들을 선별하여 답변을 생성하기에 전략적인 방법들을 통해 보다 높은 수준에 문서 만을 가져와야 한다.
-
Embedding 전략: 어떤 임베딩 모델을 사용하느냐에 따라 차이를 가질 수 있다.
-
Search 방식: 유사도 기반에 Dense 방식, 키워드 기반에 Sparse 방식, 또는 두 방식을 연결한 Hybrid 방식 등이 있다.
💡Hybrid Search
하이브리드 검색 기능은 벡터 검색과 키워드 검색 두가지를 결합하여 정밀한 검색 기능을 제공하는 방식이다.
- Dense(임베딩 기반): 벡터화 된 문서와 벡터화 된 질문에 유사도를 통해 검색
- Sparse(BM25 등 키워드 기반): 단어 빈도 기반에 키워드 매칭
예를들어, 같은 방식으로 키워드에 매칭되는 문서는 추가 가중치를 부여하여 더 정밀하고 유연하게 관련 문서를 찾는 방식이다.
-
Scoring & Reranking: 1차 검색 결과 이후, LLM이나 특수 모델을 통해 재정렬 할 수 있다.
-
Filtering: 검색 시 문서의 메타정보(출처, 날짜 등)로 범위를 제한할 수 있다.
-
Query Rewriting: 사용자의 질문을 검색에 최적화된 형태로 변환하여 검색 정확도를 향상 시킬수도 있다.
3. Generator
Retrieval에 결과를 바탕으로 LLM을 통해 최종 응답을 생성하는 단계이다. Retrieval을 통해 선별된 Top N개의 Chunk와 유저의 질의를 가지고 Prompt를 구성한다. 구성된 Prompt를 원하는 LLM에 입력하여 최종적인 답변을 생성한다.
# 예시코드 (with.GPT)
import openai
# 1. OpenAI API Key 설정
openai.api_key = "your-api-key"
# 2. 사용자 질문
query = "GA4에서 session_start 이벤트는 언제 발생하나요?"
# 3. 검색된 문서 chunk 리스트 (Top-k 검색 결과)
retrieved_chunks = [
"GA4에서 session_start 이벤트는 사용자가 앱이나 웹사이트를 처음 방문할 때 발생합니다.",
"session_start는 기본적으로 세션을 정의하는 핵심 이벤트로, 최초 페이지뷰 이후 자동으로 발생합니다.",
]
# 4. 프롬프트 구성
context = "\n\n".join(retrieved_chunks)
prompt = f"""
당신은 GA4 문서를 바탕으로 질문에 답하는 전문가입니다. 다음 문서를 참고하여 질문에 답해주세요.
문서:
\"\"\"
{context}
\"\"\"
질문:
{query}
답변:
"""
# 5. GPT 호출 (Chat API 사용)
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo", # 또는 "gpt-4"
messages=[
{"role": "system", "content": "너는 GA4 전문가야. 주어진 문서 외의 정보를 포함하지 마."},
{"role": "user", "content": prompt}
],
temperature=0.2,
max_tokens=500,
)
# 6. 출력
answer = response["choices"][0]["message"]["content"]
print("생성된 답변:\n", answer)