BERT (Pre-training of Deep Bidirectional Transformers for Language Understanding)
Natural Language Processing
목록 보기
1/2
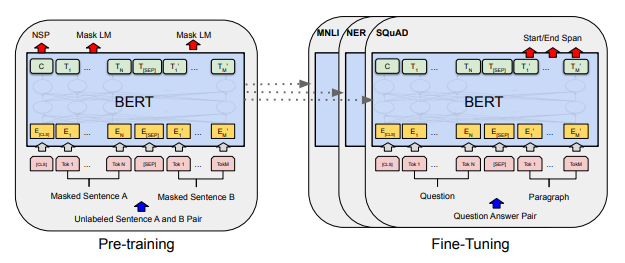
BERT
- BERT는 Transformer의 Encoder를 쌓아올린 구조
- BERT는 위키피디아(25억개의 단어)와 BooksCorpus(8억개의 단어)와 같은 레이블이 없는 텍스트 데이터로 사전 훈련된 언어 모델
- BERT가 높은 성능을 얻을 수 있었던 것은, 레이블이 없는 방대한 데이터로 사전 훈련된 모델으로, 레이블이 있는 다른 작업에서 Fine-tuning과 Hyperparameter tuning을 하면 모델의 성능이 높게 나오는 기존의 사례들을 참고하였기 때문이라고 함
Input embeddings
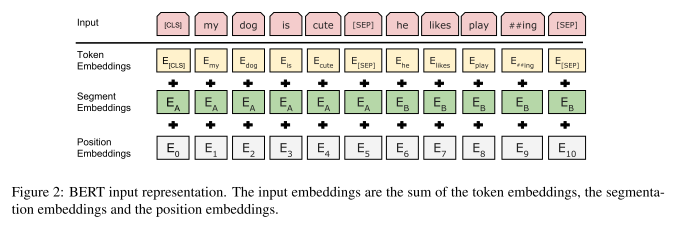
Token embeddings
- Vocab을 만드는 과정으로 WordPiece 알고리즘을 사용함.
- 아래 동영상을 보는 것이 복습하기에 좋을 것으로 생각됨
Segment Embeddings
- 단어가 첫번째 문장에 속하는지 두번째 문장에 속하는지 알려주는 역할
- 더해지는 임베딩 값
- 첫번째 문장(
[CLS] ~ [SEP]): 0 - 두번째 문장(
[SEP] 이후 ~): 1
- 첫번째 문장(
Position Embeddings
-
어순을 제공하여 언어를 잘 이해할 수 있도록하는 역할
- 어순은 모델이 언어를 이해하는데 중요한 요소
- recurrence도 없고 convolution도 없으므로, 어순에 대한 정보를 직접 넣어줘야 함
Attention Is All You Need (Transformer)
Since our model contains no recurrence and no convolution, in order for the model to make use of the order of the sequence, we must inject some information about the relative or absolute position of the tokens in the sequence.
-
아래와 같은 조건을 사인과 코사인함수가 위치 정보를 표현하는데 있어 충족함
- 각 토큰의 위치값은 유일한 값을 가져야함
- 서로 다른 두 토큰이 떨어져 있는 거리가 일정해야 함
- 주로 짧은 길이의 문장을 학습했더라도, 긴 길이의 문장들도 잘 표현할 수 있어야함
- 함수에 따른 토큰 위치의 값을 예측할 수 있어야 함
-
Transformer 에서는 sin, cos을 사용하여 아래와 같이 PE를 함
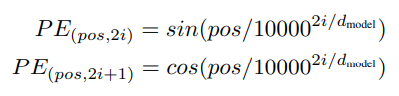
- pos는 정수로 각 토큰의 위치값
- 차원(d)이 짝수일 때는 sin, 홀수일 때는 cos으로 계산한 값을 사용함
-
sin, cos 중 하나를 사용하지 않는 이유: 어떤 특정 두 토큰의 위치값이 동일해질 수 있는 것을 방지하기 위함
Pre-training BERT
- 제목 그대로 BERT를 Pre-training 할 때 사용하는 방법
- 이후에는 Pre-training된 버트를 특정 task에 맞게 Fine-tuning
Masked Language Model (MLM)
- Deep bidirectional representation 학습을 위해 Input token을 랜덤하게 마스킹하고 예측
- denoising auto-encoders와 반대로 전체 입력을 복원 X, 마스킹된 단어만 예측 O
- 데이터 전처리에서 각 문장의 15%(
[CLS], [SEP] 제외)를 random하게 선택하여 마스킹 - 하지만 Fine-tuning에서는
[MASK]가 없으므로 Pre-training과 Fine-tuning 사이 mismatch 발생- 그래서 15%로 뽑은 것을 아래와 같은 방법을 적용하여 해결함
- 80%는
[MASK]로 교체
- 80%는
- 10%는 random하게 교체
- 마지막 10%는 교체하지 않음
Next Sentence Prediction (NSP)
- 2개의 문장을 넣었을 때 그 관계를 이해시키기 위한 방법
- Question Answering이나 Natural Language Inference과 같은 Downstream task
- 단순히 문장 A, B를 Input으로 사용한다고 할 때
- 50%는 B가 실제로 A 바로 다음에 나오는 문장인 경우 (IsNext)
- 50%는 B가 실제로 A 바로 다음에 나오는 문장이 아닌 경우 (NotNext)
Hyperparameters
- Maximum token length: 512
- Batch size: 256
- Adam with learning rate of 1e-4, beta1=0.9, beta2=0.999
- L2 weight decay of 0.01
- Learning rate warmup over the first 10,000 steps, linear decay of the learning rate
- 아마 Gradual warmup으로 생각됨.
- Dropout probability of 0.1 on all layers
- GELU activation
- BERT_BASE took 4 days with 16 TPUs and BERT_LARGE took 4 days with 64 TPUs
- Pre-train the model with sequence length of 128 for 90% of the steps
- The rest 10% of the steps are trained with sequence length of 512
Reference
- ✔ 논문: https://arxiv.org/abs/1810.04805
- ✔ 유튜브: https://www.youtube.com/watch?v=IwtexRHoWG0
- ✔ Tacademy 강의
- ✔ 블로그
- kaggle tutorial: https://www.kaggle.com/abhinand05/bert-for-humans-tutorial-baseline#Code-Implementation-in-Tensorflow-2.0

개인 학습 및 복습을 위한 머신러닝 엔지니어의 블로그입니다 :)