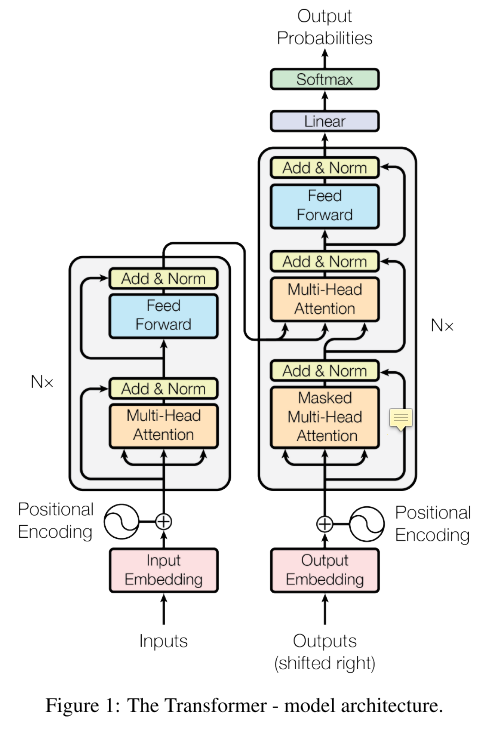
Transformer (Attention Is All You Need)
- 기존의 sequence transduction 모델들은
- encoder와 decoder를 포함하는 complex한 recurrent or CNN을 기반으로 하며
- attention 메커니즘을 통해 encoder와 decoder를 연결하였음
- Transformer는 오직 attention 메커니즘에만 기반한 simple network
- 기존 모델에 비해 성능이 좋고, 더욱 parallelizable하며, train에 더 적은 시간이 걸림
- sequence transduction 이란?
Transformers were developed to solve the problem of sequence transduction, or neural machine translation. That means any task that transforms an input sequence to an output sequence. This includes speech recognition, text-to-speech transformation, etc.. Sequence transduction.
Model Architecture
- 당시 Most competitive한 neural squence transduction 모델들은
- encoder-decoder 구조
- output sequence를 생성할 때 한 번에 1개의 element씩 생성함
- 다음 element를 생성할 때 이전에 생성된 symbols를 additional input으로 사용
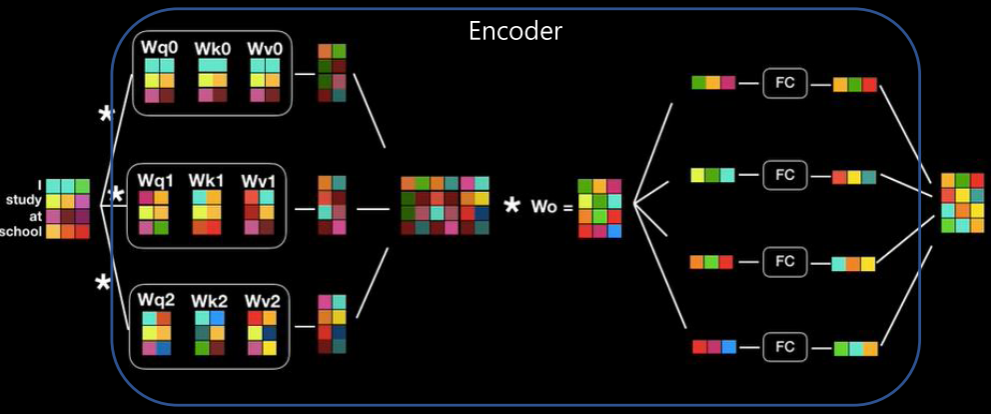
Encoder, Decoder
-
Encoder
- stack of N=6 identical layers
- 각각은 아래의 sub-layers를 가짐
- multi-head self-attention mechanism
- position- wise fully connected feed-forward network
- 각 2개의 sub-layers에는 gradeint vanishing 방지를 위한 residual connection이 있음
- ex) LayerNorm(x + Sublayer(x)),
-
Decoder
- also stack of N=6 identical layers
- encoder에서의 sub-layers 2개와 더불어 3번째 sub-layer가 추가됨
- encoder stack의 output을 사용하여 multi-head attention을 하는 부분
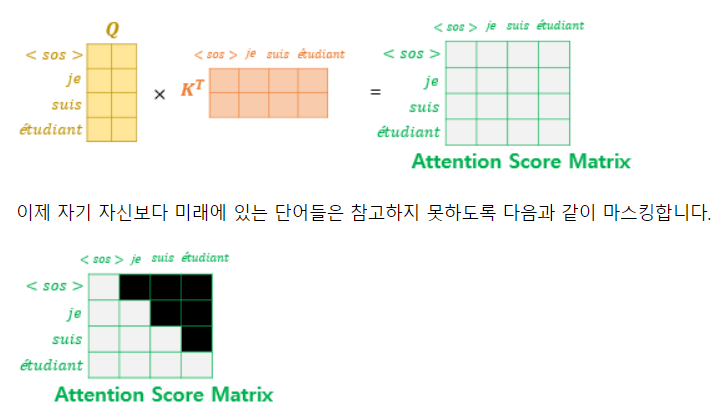
- 디코더의 Masked Multi-Head Attention에서 아래와 같이 Masking이 수행됨
- 현재 시점의 예측에서 현재 시점보다 미래에 있는 단어들을 참고하지 못하도록 룩-어헤드 마스크(look-ahead mask)를 사용 (출처: https://wikidocs.net/31379)
Attention
- attention은 query와 key-value 쌍을 output에 맵핑하는 방식으로 진행됨
- 이러한 일련의 과정은 T Academy 강의에서 좋은 그림들로 자세히 다루어져 있음
- Self-Attention
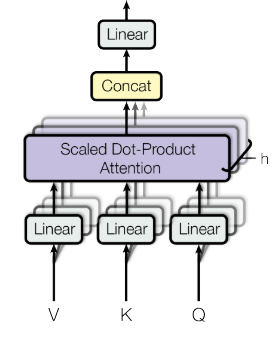
- Multi-Head Attention
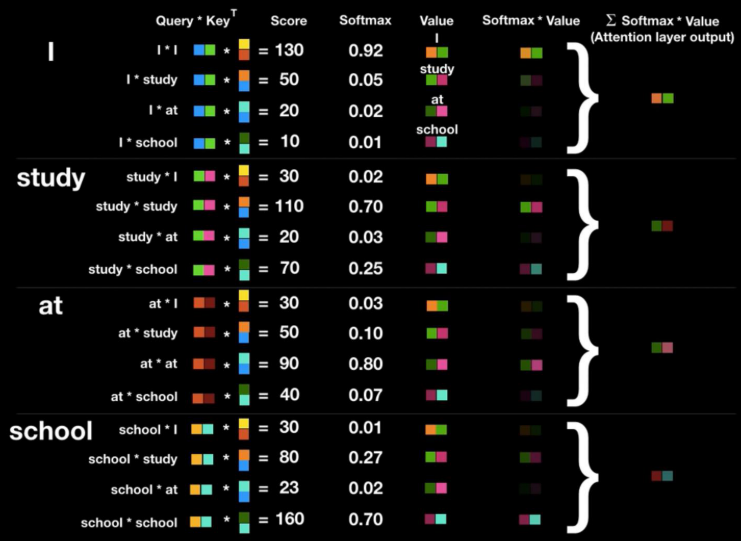
Scaled Dot-Product Attention
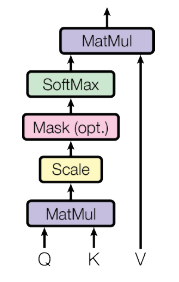
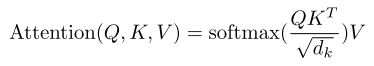
- Scaled Dot-Product Attention에서 Scaled = root(d_k)로 나누는 이유
- Q, K의 dimension은 d_k, V의 dimension은 d_v
- d_k가 큰 경우 dot products의 크기가 커지고, softmax를 통과했을 때 gradients가 작아짐
Multi-Head Attention

Position-wise Feed-Forward Networks
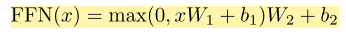
Positional Encoding
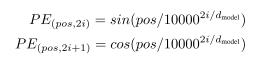
Training
- Optimizer: Adam optimizer (+warmup)
- Regularization: Residual Dropout, Label Smoothing
Reference
- ✔ 논문: https://arxiv.org/abs/1706.03762
- ✔ 유튜브: https://www.youtube.com/watch?v=IwtexRHoWG0
- ✔ Tacademy 강의
- ✔ 블로그
- kaggle tutorial: https://www.kaggle.com/abhinand05/bert-for-humans-tutorial-baseline#Code-Implementation-in-Tensorflow-2.0

개인 학습 및 복습을 위한 머신러닝 엔지니어의 블로그입니다 :)