Natural Language Processing
1.BERT (Pre-training of Deep Bidirectional Transformers for Language Understanding)
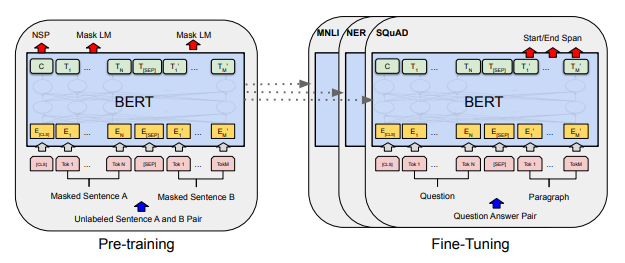
BERT는 Tranformer의 Encoder를 쌓아올린 구조로 위키피디아(25억개의 단어)와 BooksCorpus(8억개의 단어)와 같은 레이블이 없는 텍스트 데이터로 사전 훈련된 언어 모델로 Task에 맞게 Fine-tuning을 하는 Language 모델입니다.
2021년 8월 10일
2.Transformer (Attention Is All You Need)
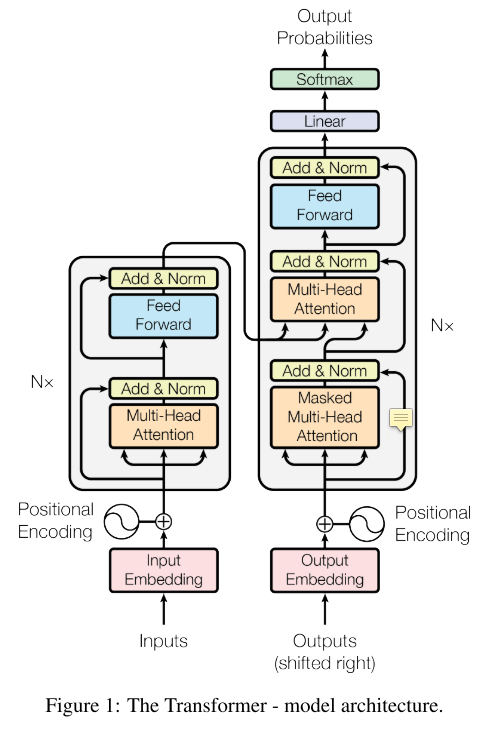
기존에 사용되었던 recurrent와 CNN을 없애고 attention을 기반으로한 simple network인 Transformer입니다.
2021년 8월 31일