Bayesian Personalized Ranking from Implicit Feedback
- Maximum posterior estimator(최대 사후 확률)에서 파생되었으며, Optimal personalized ranking에 대한 Generic optimization criterion인 BPR-OPT를 제안함
- 그리고 BPR-OPT를 최대화하기 위해 LEARN-BPR(learning algorithm)을 제안함
- 구체적인 학습 방법으로는 Bootstrap sampling과 SGD를 이용함
- 마지막으로 Matrix factorization과 Adaptive kNN에 적용하여 실험을 하였음
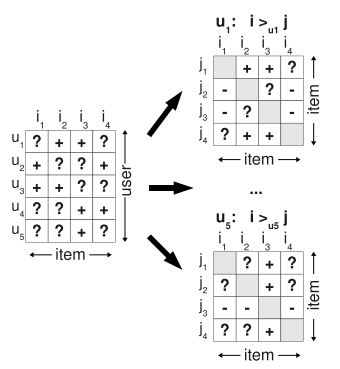
Personalized Ranking
- Personalized Ranking: 개인화된 ranked item의 목록을 사용자에게 제공
- 기존 Implicit feedback systems은 positive observations에만 집중함
- 유저가 소비하지 않은 아이템(non-observed user-item pairs)은 아래의 혼합임
- real negative feedback 이며(실제로 아이템에 흥미를 가지지 않거나)
- missing values 이다(미래에 아이템 구매를 원할 수도 있음)
Formalization
-
U를 모든 유저의 집합, I를 모든 아이템의 집합이라 하고, Implicit feedback S ⊆ U×I 이라 하자.
-
추천 시스템의 목표는 모든 아이템의 Personalized total ranking인
>_u를 제공하는 것이며, 이는 아래 total order의 3가지 특성을 만족해야한다.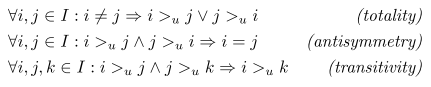
- totality: i!=j이면, i>j or j>i이다.
- antisymmetry: i>j and j>i이면 i=j이다.
- 일반적으로 알려진 전순서(total order)를 보면, "같음"이 포함되어야 하는데 .. 생략된걸까?
- https://namu.wiki/w/%EC%88%9C%EC%84%9C%20%EA%B4%80%EA%B3%84
- transitivity: i>j and j>k이면, i>k이다.
-
편의상 유저가 소비한 아이템에 대한 Implicit Feedback의 유저와 아이템은 아래처럼 표현함
Analysis of the problem setting
-
이전에 언급했듯 유저가 소비하지 않은 아이템(non-observed user-item pairs)은 아래의 혼합임
- real negative feedback 이며(실제로 아이템에 흥미를 가지지 않거나)
- missing values 이다(미래에 아이템 구매를 원할 수도 있음)
-
일반적으로 트레이닝 데이터는 아래와 같이 구성함
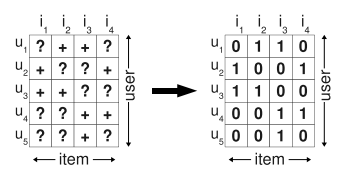
- positive class label (u, i) ∈ S
- all other combinations in (U × I) \ S a negative one
- \ = 역슬래쉬
-
이제 모델이 데이터에 피팅되면.. S에 대해서는 1로 예측하고, 나머지에 대해 0으로 예측함
- 여기서 저자가 지적하는 문제는 미래에 순위를 매겨야 하는 모든 요소 중 ((U × I) \ S)가 negative feedback으로 학습된다는 것임.
- 그리고 model이 트레이닝 데이터를 충분히 피팅하여 데이터를 잘 표현한다면, negative feedback으로 학습된 것들은 무조건 0으로 예측할 것임.
- 만약 이런 머신러닝 방법이 ranking을 잘 예측한다면, 그것의 단 한가지 이유는 regularization 등으로 오버피팅을 방지했기 때문이라고 함
-
그래서 단순히 missing values를 negative ones로 교체하는 것보다 문제를 더 잘 표현하는 방법으로, 아래의 design matrix와 같이 single item(u,i)가 아닌 item pairs(u,i,j)를 트레이닝 데이터로 사용함
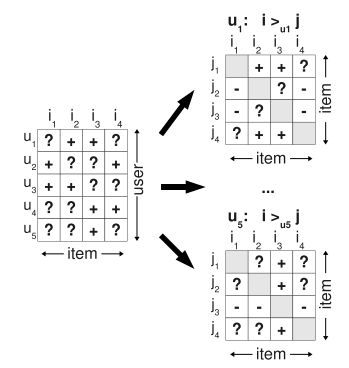
- S에서 각 유저의 Personalized ranking인
>_u를 아래와 같은 가정으로 재구성함.- user는 user가 소비한 item i를 non-observed items보다 더 선호함
- user가 소비한 item 사이에서는 어떤 추론도 할 수 없음 (Implicit Feedback이므로)
- 마찬가지로 user가 소비하지 않은 item 사이에는 어떤 추론도 할 수 없음
- 트레이닝 데이터를 아래와 같이 표현할 수 있음
-
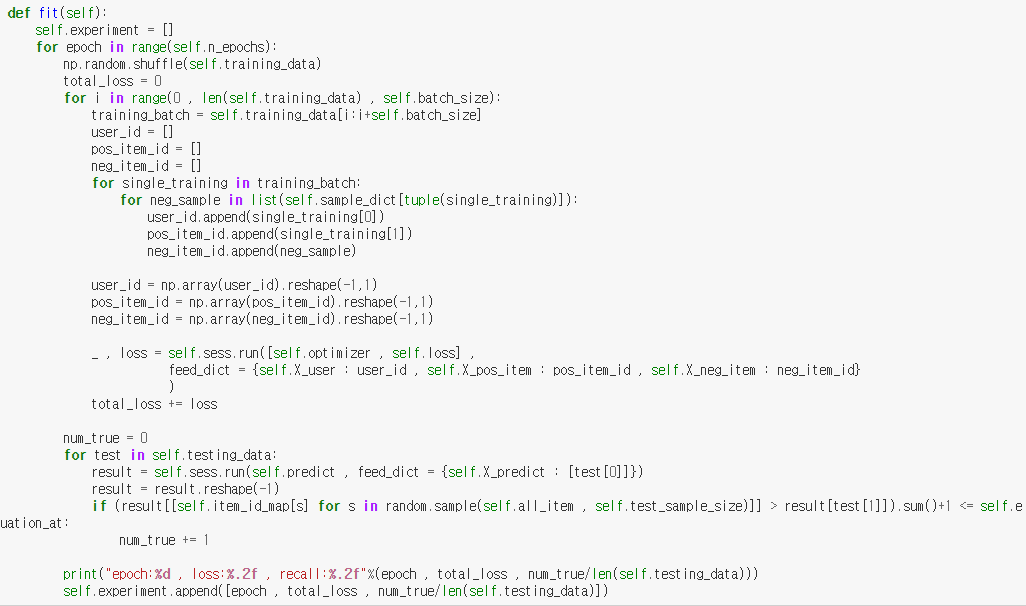
실제 TensorFlow로 구현된 코드를 보면 더 쉽게 이해가 됨
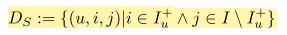
BPR Optimization Criterion
- Bayesian optimization이란, 아래의 사후 확률을 최대화 하는 파라미터 Θ를 찾는 것이며, 이를 최대 사후 확률 추정(Maximum A Posteriori Estimation)이라고 함
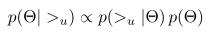
- Bayesian analysis를 통해 파생되었으며, 일반적으로 알려진 수식처럼 오른쪽 텀에서
- 오른쪽: prior probability(사전 확률)로 모델의 파라미터
- 왼쪽: likelihood function(가능도 함수)
- Posterior probability(사후 확률)을 maximize하는 것이 목표
likelihood
-
likelihood란
>_u에 대한 확률 분포로, i>_uj, j>_ui 두 가지 경우만 존재하므로, 베르누이 분포를 따른다고 볼 수 있다.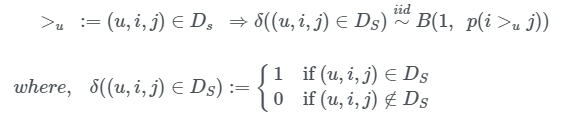
- ex) 어떤 유저 u가 i보다 j를 선호할 확률이 p라고 하면, j보다 i를 선호할 확률은 1-p
-
베르누이 분포에서 likelihood function은 아래와 같음
-
user가 item i보다 j를 선호할 확률은 아래처럼 정의되며,
x_uij는 Matrix Factorization(MF)이나 adaptive kNN으로 구함
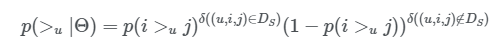
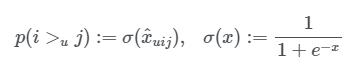
prior probability
- 사전 확률은 파라미터 Θ에 대한 확률 분포를 가정하는 것으로, 특별한 사전 정보가 없다면 일반적으로 uniform이나, normal을 사용하며, 여기서는 normal을 사용함.
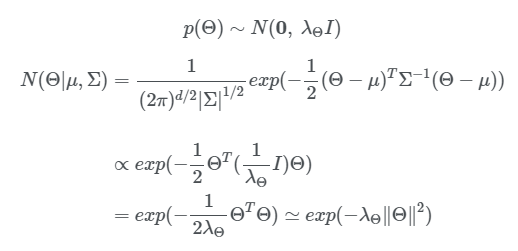
BPR-OPT
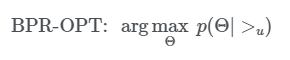
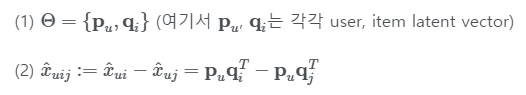
- Optimization function은 아래와 같이 정리된다
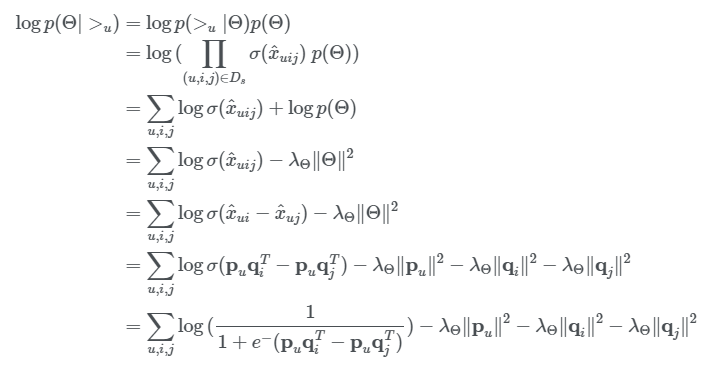
Matrix Factorization
- Matrix Factorization을 사용한 방법을 BPR-MF라고 부르는 것 같음.
- 구현된 코드를 보면 좀 더 잘 정리되는 것 같다

- sigmoid는 결국 확률인 0~1 사이로 만들어주기 위함인 것 같음
Adaptive k Nearest Neighbor
- TBD
Bootstrap sampling, SGD

- 트레이닝 데이터의 순서는 연속된 (u,i)의 (u,i,j) 쌍들이 연속적으로 트레이닝되지 않도록, uniform random하게 섞었다고 함.
- full gradient descent는 오래걸려서 sotchastic gradient descent를 사용
Experiments
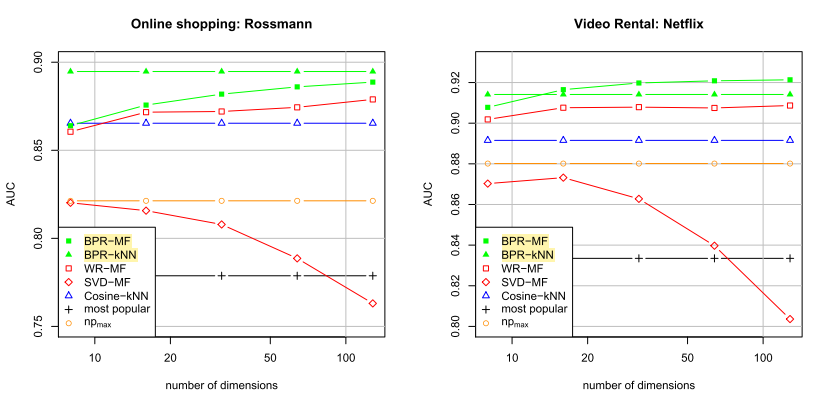
- 기존 방법들 보다 좋았고, kNN보다는 MF가 더 좋았다는 것이 결론
Reference

개인 학습 및 복습을 위한 머신러닝 엔지니어의 블로그입니다 :)