
백준 문제를 풀다 보면 기본적인 오름차순 또는 내림차순 정렬 방식 이외에 커스텀 비교 함수를 사용해서 정렬하는 경우가 많다. 오늘 푼 문제에서는 priority_queue를 사용했는데, pair<pair<int, int>, pair<int, int>> 타입의 값을 사용했기 때문에 커스텀 정렬 함수가 필요했다. 편의상 위 타입을 간단하게 piipii라고 부르겠다.
piipii에 들어가는 값은, pair<pair<통과한 쓰레기 개수, 쓰레기 옆을 지나가는 칸의 개수>, pair<x좌표, y좌표>>였다.
내가 원했던 정렬 방식은 다음과 같았다.
- 통과한 쓰레기 개수가 더 적은 것을 앞으로(
top()으로) 보낸다. - 만약 통과한 쓰레기 개수가 같다면 쓰레기 옆을 지나가는 칸의 개수가 더 적은 것을 앞으로 보낸다.
이를 구현하기 전에 priority_queue에 대해 간단히 살펴보자.
priority_queue
std::priority_queue는 내부적으로 힙을 사용하여 요소를 관리한다.
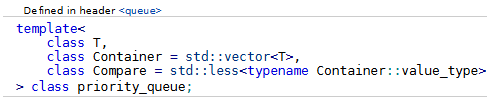
이때 세 번째 인자인 Compare에 비교 연산에 사용할 비교 함수 객체를 지정할 수 있다. 지정하면 우선순위 큐를 만들거나 갱신할 때 두 요소를 비교하기 위해 comp(a, b)와 같이 호출된다(comp를 지정했다면).
이때 함수 객체가 무엇인지 알아야 한다. 함수 객체는 객체를 함수처럼 쓸 수 있는 것으로, () 연산자를 오버로딩하면 사용 가능하다.
priority_queue는 설계상 기본적으로 저장된 비교 객체를 직접 호출해서 요소들 간의 우선순위를 결정한다. 이때 호출 연산자인 ()가 정의되어 있지 않으면 comp 객체를 함수처럼 사용할 수 없기 때문에 연산자 오버로딩이 필요하다.
struct Comp {
bool operator ()(int a, int b) {
return a > b;
}
}
priority_queue<int, vector<int>, Comp<int>> pq;▲ 위와 같이 연산자를 오버로딩할 수 있다.
세 번째 인자의 기본값은 less로, 가장 큰 값이 top으로 가서 점점 작아진다. 만약 가장 작은 값을 우선하고 싶다면 비교 함수를 greater로 지정할 수 있다.
sort
이 글을 쓰게 된 이유가 바로 이 std::sort의 비교 함수와 헷갈렸기 때문이다.
sort는 배열이나 vector 컨테이너를 한 번에 정렬하는 함수로, <algorithm> 헤더에 정의되어 있다.

sort 함수의 세 번째 인자에는 비교 함수를 지정할 수 있다.

파라미터에 대한 설명을 좀 더 읽어보면, comp(a, b)가 true를 반환할 경우 a가 b보다 앞에 와야 한다는 것을 알 수 있다.
만약 배열을 오름차순 정렬하고 싶다면
bool comp(int a, int b){
return a < b;
}과 같이 쓸 수 있다. a가 b보다 작다면 위 함수가 true를 반환하기 때문에 a가 b보다 앞에 온다. 즉, 오름차순으로 정렬된다. 만약 부등호 방향을 반대로 한다면? a가 더 클 때 true를 반환하기 때문에 내림차순으로 정렬된다.
처음 구현한 방식
위에서 priority_queue와 sort의 비교 함수를 간단하게 살펴보았다. 다시 맨 처음으로 돌아가서,
- 통과한 쓰레기 개수가 더 적은 것을 앞으로(
top()으로) 보낸다. - 만약 통과한 쓰레기 개수가 같다면 쓰레기 옆을 지나가는 칸의 개수가 더 적은 것을 앞으로 보낸다.
를 구현하는 연산자를 오버로딩했다.
#define piipii pair<pair<int, int>, pair<int, int>>
// ...
struct comp {
bool operator()(piipii& a, piipii& b){
if (a.first.first == b.first.first){
return a.first.second < b.first.second;
} else {
return a.first.first < b.first.first;
}
}
};sort의 비교 함수와 마찬가지로 < 부등호를 사용했으니 더 작은 값이 top으로 가겠지! 라고 생각했다.
문제점
하지만 코드를 제출해 보니 시간 초과가 발생했다. priority_queue를 사용해서 다익스트라 알고리즘을 구현했기 때문에 시간은 전혀 문제되지 않을 것이라 생각했다. 콘솔에 값들을 찍으며 디버깅을 반복하다가, priority_queue의 top에 가장 작은 값이 아닌 가장 큰 값이 오고 있다는 것을 알게 되었다.
다익스트라 알고리즘에서 비용이 작은 상태부터 꺼내면 처리하는 값의 개수를 줄일 수 있는데, 반대로 비용이 큰 상태부터 꺼내고 있었기 때문에 전체 연산량이 크게 늘어 시간 초과가 발생한 것이다.
비교 함수를 잘 작성했다고 생각했는데, 이 부분에 문제가 있었다.

priority_queue의 파라미터 설명을 읽어보자. comp(a, b)가 true를 반환하면 a는 b보다 우선순위가 낮다는 것을 알 수 있었다.
즉, a가 b보다 앞에 온다는 개념이 우선순위 큐에서는 우선순위가 낮다는 것이 되어버렸다.
따라서 원래 구현하고 싶던 비교 함수를 구현하기 위해서는 위 코드에서 부등호 방향을 반대로 바꾸어야 한다.
수정한 방식
struct comp{
bool operator()(piipii& a, piipii& b){
if(a.first.first==b.first.first){
return a.first.second>b.first.second;
} else{
return a.first.first>b.first.first;
}
}
};▲ 올바른 비교 함수
이전에도 한 번 부등호 방향 때문에 문제를 겪은 경험이 있었는데, 그때는 크게 생각하지 않고 답을 맞히는 데 급급했던 것 같다. 하지만 이번 기회에 sort와 priority_queue의 비교 함수에서 부등호 방향이 의미하는 것을 확실하게 알게 되었다.
앞으로는 부등호 방향 때문에 문제될 일이 없길 바란다!
