매일 알고리즘 문제 풀기 611일차이다. 오늘 푼 문제는 27111번, 출입 기록이다. 문제를 풀면서 탐구했던 내용에 대해 다뤄보려 한다.
https://www.acmicpc.net/problem/27111
▲ 문제 링크
bool 타입의 visited 배열로 각 번호의 사람이 부대 내에 있는지를 관리한다. 출입 기록이 끝난 뒤에 visited를 순회하면서 부대 내에 있는 사람이 있는지 확인하고, 부대 내에 있으면 해당 사람의 기록이 누락되었다고 판단한다.
이번 글에서 탐구할 것은 출입 기록이 끝난 뒤에 부대에 남아 있는 사람이 있는지 어떻게 효율적으로 확인하는가? 이다.
v1: 배열 접근, 1~최댓값까지 순회
처음 작성했던 v1의 코드이다. v1 코드는 1부터 (등장한 사람의 번호 중 최댓값)까지 for문으로 순회한다.
#include <iostream>
#include <algorithm>
using namespace std;
bool visited[200001];
int main()
{
ios::sync_with_stdio(false);
cin.tie(NULL); cout.tie(NULL);
int N, ans=0, mx=-1;
cin>>N;
for(int i=0; i<N; i++){
int A, B;
cin>>A>>B;
mx=max(mx, A);
if(B==1){
if(visited[A]) ans++;
else visited[A]=true;
} else{
if(!visited[A]) ans++;
else visited[A]=false;
}
}
// 1부터 등장한 번호 중 최댓값까지 순회
for(int i=1; i<=mx; i++){
if(visited[i]) ans++;
}
cout<<ans;
}

▲ 메모리 2216KB, 시간 36ms
정답 코드지만, 마음에 들지 않았다. 만약 1개의 기록이 있었는데, 그 기록의 사람 번호가 200,000이라면? for문으로 20만 번 순회하면서 등장하지도 않은 번호를 199,999번 확인해야 한다. 즉, A가 sparse(희소)하게 분포되어 있고 최댓값이 큰 경우 비효율적이다. 좀 더 효율적으로 코드를 작성할 수는 없을지 고민하다가 v2 코드를 작성하게 되었다.
v2: set 사용
set 자료구조를 사용해서 기록에 등장한 사람의 번호만 기억해두었다가 확인하는 방법을 떠올렸다.
#include <iostream>
#include <set>
#include <algorithm>
using namespace std;
bool visited[200001];
set<int> s;
int main()
{
// ...
int N, ans=0;
cin>>N;
for(int i=0; i<N; i++){
int A, B;
cin>>A>>B;
s.insert(A);
// ...
}
// set의 원소를 순회
for(auto a: s){
if(visited[a]) ans++;
}
cout<<ans;
}
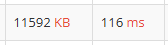
▲ 메모리와 시간 모두 v1보다 크게 증가했다
시간이 줄어들길 기대했지만 오히려 늘어났다. 왜 성능이 나빠졌을까?
set vs 배열 접근
연산의 시간 복잡도
C++의 set 자료구조는 노드 기반 컨테이너로, 균형 이진트리(Balanced Binary Tree)로 구현되어 있다. 원소 값을 기준으로 정렬 상태를 유지한다.
삽입, 삭제, 탐색 모두 의 시간이 소요된다. 그렇기 때문에 인 배열에 비해 느리다.
입력 데이터의 특성
입력 데이터가 sparse한 경우에는 set이 효율적일 수 있다. 하지만 dense(밀집)한 경우에는 삽입하는 데 시간이 많이 걸리기 때문에 이득을 볼 수 없다.
위 코드에서 시간 복잡도를 비교해보자. 총 N개의 입력에 대한 시간이다.
K는 set에 저장된 고유한 값의 개수이다.
| 방식 | 삽입 | 순회 | 전체 시간 복잡도 |
|---|---|---|---|
| set 사용 | |||
| 배열 접근 |
따라서 set을 사용하는 것은 일반적인 경우에 이득을 볼 수 없다는 결론을 얻을 수 있었다. 그렇다면 해시 테이블로 구현된 unordered_set을 사용하면 어떨까? 그렇게 v3 코드를 작성하게 되었다.
v3: unordered_set 사용
세 번째로 unordered_set 자료구조를 사용해 보았다. unordered_set은 set과 다르게 원소들이 정렬되어 있지 않다. 그리고 해시 테이블로 구현되어 있다.
삽입, 삭제, 탐색 모두 평균 에 가능하다. 하지만 최악의 경우(충돌이 많이 발생할 경우)에는 의 시간이 걸린다.
#include <iostream>
#include <unordered_set>
#include <algorithm>
using namespace std;
bool visited[200001];
unordered_set<int> s;
int main()
{
// ...
int N, ans=0;
cin>>N;
for(int i=0; i<N; i++){
int A, B;
cin>>A>>B;
s.insert(A);
// ...
}
for(auto a: s){
if(visited[a]) ans++;
}
cout<<ans;
}v2의 코드와 모두 똑같고, unordered_set을 사용한다는 것만 달라졌다.
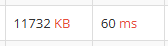
▲ set을 사용할 때보다 시간이 절반 정도로 줄었다.
그럼에도 여전히 배열을 사용하는 것보다는 시간이 더 많이 걸린다. 그 이유를 다음과 같이 정리할 수 있겠다.
unordered_set vs 배열 접근
- 배열에 값을 쓰거나 읽을 때는 단순히 메모리 주소 계산만 필요하다. 하지만
unordered_set은 해시 함수 계산과 충돌 처리를 해야 하기 때문에 같은 이라 해도 추가적인 비용이 발생할 수 있다. 특히 충돌이 많이 발생할수록 에 가까워진다. - 배열은 데이터가 메모리 공간에서 연속적으로 위치하기 때문에 캐시 친화적이다. 하지만 해시 테이블은 버킷에 저장하기 때문에 메모리 공간에서 불연속적으로 배치된다. 캐시 친화적인 경우 순회하는 데 드는 비용이 줄어든다.
지금까지는 배열 접근 코드가 가장 빠른 시간을 보여주었다. 그렇다면 조금 더 효율적인 코드를 위해 순회 범위를 줄여볼 수 있지 않을까?
v4: 배열 접근, 최솟값~최댓값 순회
v4의 코드는 첫 번째 버전과 아주 유사하지만 배열을 순회할 때 1부터 순회하는 것이 아닌, 입력 값들 중 최솟값부터 순회한다.
#include <iostream>
#include <algorithm>
#define INF 987654321
using namespace std;
bool visited[200001];
int main()
{
// ...
int N, ans=0, mn=INF, mx=-1;
cin>>N;
for(int i=0; i<N; i++){
int A, B;
cin>>A>>B;
mx=max(mx, A);
mn=min(mn, A);
//...
}
// 최솟값~최댓값 순회
for(int i=mn; i<=mx; i++){
if(visited[i]) ans++;
}
cout<<ans;
}
▲ v1 코드보다 4ms 줄어들었다.
4ms 정도는 서버의 오차 범위로 볼 수 있기 때문에 같은 코드로 총 3번 채점해보았다. 세 번의 결과가 모두 같았기 때문에 코드의 효율성이 조금이나마 개선되었다고 판단했다.
배열 접근하는 것이 unordered_set을 사용하는 것보다 더 적은 시간이 걸린다는 것을 확인할 수 있었다.
unordered_set을 사용하더라도 입력 데이터의 특성에 따라서 배열 접근하는 것보다 효율적일 수 있지 않을까? 하는 궁금증이 생겼다.
단순히 생각해 보면 데이터가 dense한 경우에는 배열이 효율적이고, sparse한 경우에는 unordered_set이 효율적일 것 같다. 하지만 구체적인 기준을 계산해 보고 싶었다.
언제, 누가 더 효율적일까?
누가 더 효율적인지 계산하기 위해서는 데이터의 분포, 탐색 범위, 고유한 원소 개수를 고려해야 한다. 이를 바탕으로 확률 모델을 만들어 계산해 보자.
1. 모델 정의
<변수>
- : 입력 데이터 개수 (여기서는 20만)
- : 탐색 범위의 최댓값
- : 고유한 원소 개수
<시간 복잡도>
배열 접근의 전체 시간 복잡도:
unordered_set의 시간 복잡도:
위의 두 시간 복잡도를 비교하면 된다.
<가정>
다음을 가정하자.
1. 1부터 까지 탐색하고, 위에서 언급한 탐색 범위는 그 최댓값이다.
2. 배열 원소는 [1, ] 범위에서 균등하게 분포되어 있다.
3. 각 원소가 고유할 확률은 이다.
2. 고유 원소 개수 K 계산
두 방식의 시간 복잡도를 비교할 때 mx, N는 고정되어 있고, 효율성을 결정하는 데 K가 큰 영향을 미친다. 따라서 K의 기댓값을 구해보자.
입력의 번째 원소가 고유 원소일 확률
기댓값을 구하기 앞서 번째 원소가 고유 원소인 확률을 구해보자.
번째 원소가 고유하려면 이전의 개의 원소에 번째 원소가 포함되지 않아야 한다.
따라서 가능한 값의 전체 개수 개에서 이미 사용된 개를 제외한 값들 중에서 번째 원소를 선택하면 된다.
따라서 의 기댓값 는
3. 시간 복잡도 비교
의 기댓값을 구했으므로 위의 시간 복잡도에 대입하자.
배열 접근:
unordered_set:
4. 효율성 비교
배열이 더 효율적일 조건
일 때이다.
즉
정리하면 이다.
즉, 탐색 범위 가 의 약 3배 미만일 경우 배열 접근이 더 효율적이다.
unordered_set이 더 효율적일 조건
반대로 인 경우에 unordered_set이 더 효율적이다.
5. 문제에 적용

위에서 얻은 결론을 문제에 적용해보자. 과 모두 20만 이하라는 조건에서 배열이 더 효율적일 확률이 크기 때문에 이 문제에서는 배열로 접근하는 것이 일반적으로 더 효율적이라는 결론을 얻을 수 있다.
하지만 과 같이 일부 극단적인 케이스에서는 unordered_set이 효율적일 수 있다.
마무리
문제 자체는 쉬운 문제이지만, 좀 더 효율적인 코드를 작성하는 과정에서 set, unordered_set에 대해 자세히 학습할 수 있었다. 또한 확률 모델을 설계해서 언제 어떤 자료구조를 사용하는 것이 효율적일지 계산할 수 있었다.
틀린 부분이 있다면 언제든 피드백 남겨주세요 :)

전 문제 맞으면 뒤도 안 돌아보고 나가는데 개선하려고 한 게 대단하네요... 수학 넘 오랜만^__^