회사에서 친절히 제공해주는 기초 강의로 내 학부 전공(feat.도시환경..)이 아닌지라 야매로 머신러닝 문제를 해결하며 배운 지식을 이 강의를 통해서 기억하고 싶은 내용이나 새로 알게된 혹은 알고 있으나 명확하지 않았던 내용을 정리하고자 하였다.
Part 1. 머신러닝을 위한 최소한의 수학/통계
ch1. 기초대수학
6. 함수
- Injective function (人jective) : 둘 이상의 x가 하나의 y를 선택하지 않음. y는 남을 수 있음.
- Surjective function : 둘 이상의 x가 하나의 y 선택할 수 있음. 남는 y는 없음
- Bijective function : injective, surjective 둘 다 만족해야됨
8. 초월함수
- 삼각함수

-
하이퍼볼릭 함수

-
우함수와 기함수(even & odd function)
10. 선형함수
딥러닝쪽으로 배우다보면 맨날 리니어 하는데 개념이 조금씩 다른가? 하는 느낌이 있었는데 실제로 다르게 쓰이고 있는게 맞았더라..
다른 의미를 가지는 linear function (수학 vs 공학)
- linear function : linear한 Decision Boundary를 가지는 함수(공학)
linear function을 기준으로 linear 한 Decision Boundary를 가지고 있어 데이터를 분류할 수 있는 함수.
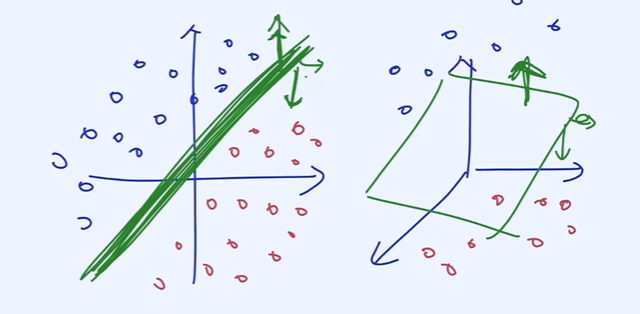
- linear function : linear한 Decision Boundary를 가지는 함수(공학)
시그모이드 함수가 대표적인 linear function으로 Homogeneity와 Additivity를 만족하지 않으나 아웃풋 layer를 통과 후 시그모이드 함수를 거치면 linear한 decision boundary를 만들어주기 때문.
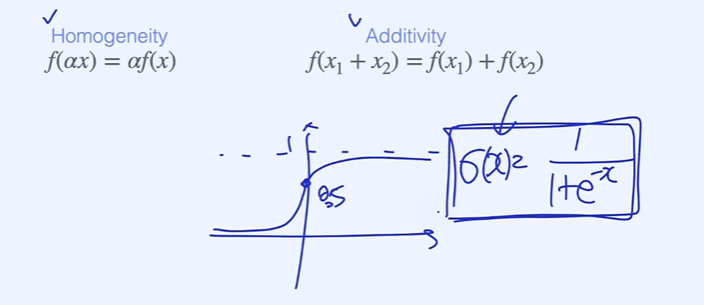
- linear function : linearity를 만족하는 함수(수학)
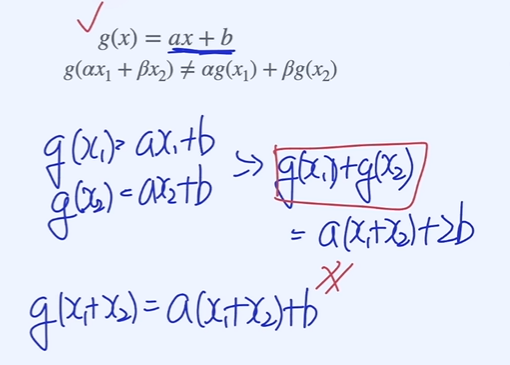
bias 텀이 들어간 위 그림의 g(x)의 경우 Homogeneity와 Additivity를 만족하지 않기 때문에 linear function이 아니지만 linear한 Decision Boundary를 만든다는 점에서 linear function이라고 할 수 있다.
- linear function : linearity를 만족하는 함수(수학)
같은 경우 명확히 linear function이 아님. linear decision boundary function을 만들지도 않고, linearity를 만족하지도 않기 때문에.
11. Parametric Models
논문을 보다보면 처음보는 notation이라 당황스러웠는데 이제 무슨 말인지 알게되었다..

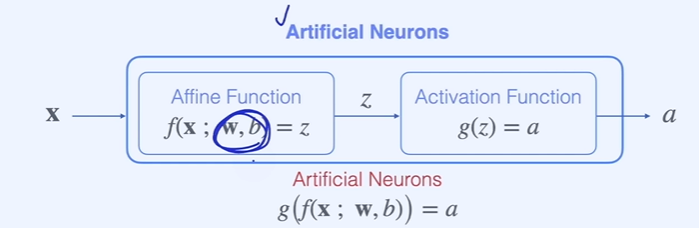
ch2. 미적분학
3. 미분법
- 자주 쓰이는 미분
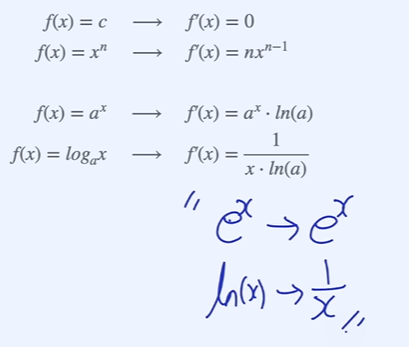
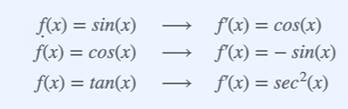
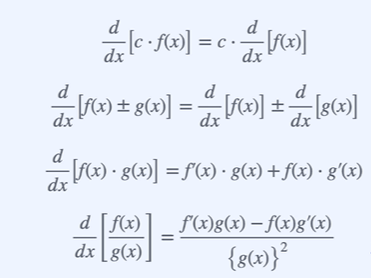
체인룰

Gradient-based Optimization
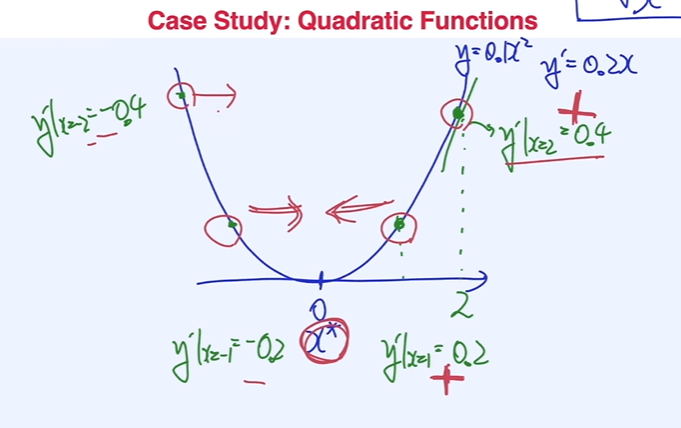
- 도함수 값 부호의 반대로 가야 최소점에 도달할 수 있음
다변수함수와 그래디언트
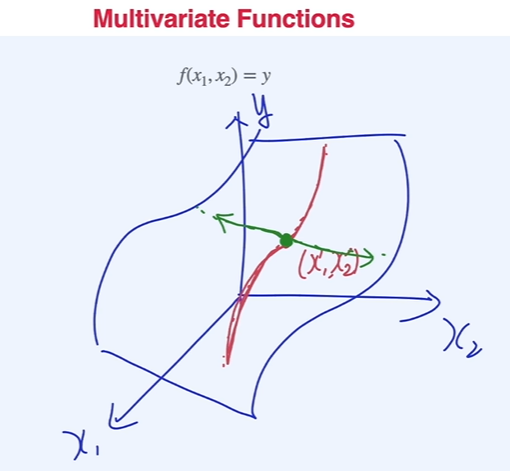
- 다변수 함수의 경우 x1, x2를 모두 최적점으로 이동시키면 전체 함수의 최적점을 찾을 수 있다.
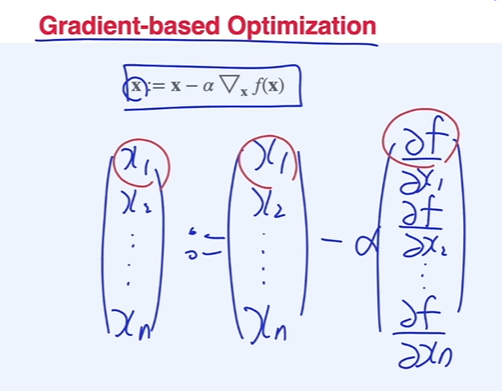
- 각 x의 변수에 따라 편미분을 통해 업데이트하면 최적점에 도달이 가능

인공지능 뉴런의 최적화
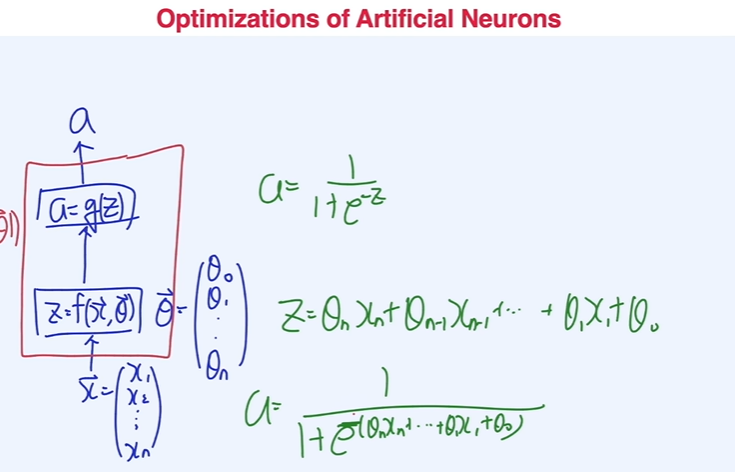
- 는 데이터(input), 학습의 대상이 되는 업데이트 시켜야할 파라미터는 , 는 output 일 경우
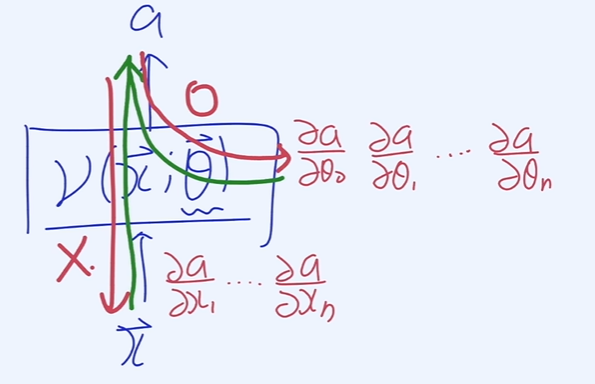
- 는 데이터기 때문에 Back Propagation 시 에 대한 편미분을 구할 필요가 없음


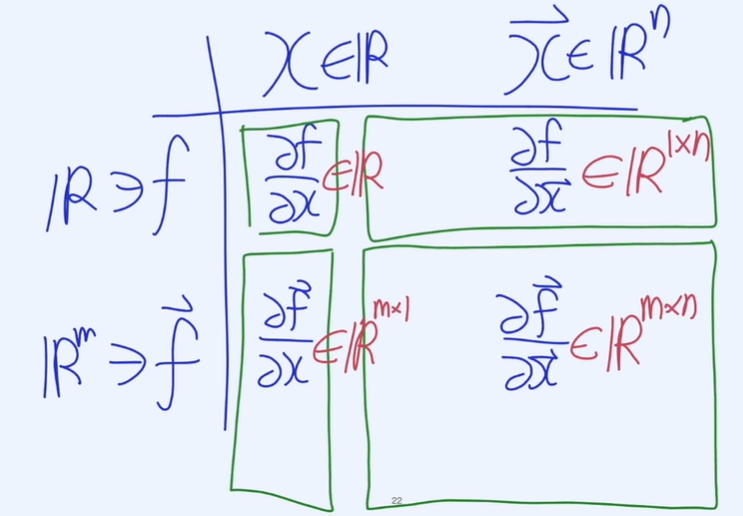
벡터함수와 그래디언트
-
x는 하나(스칼라)일 때 출력이 m개(벡터)

-
어떻게 활용될까?
딥러닝의 layer는 아래 그림과 같이 vector function이 됨.
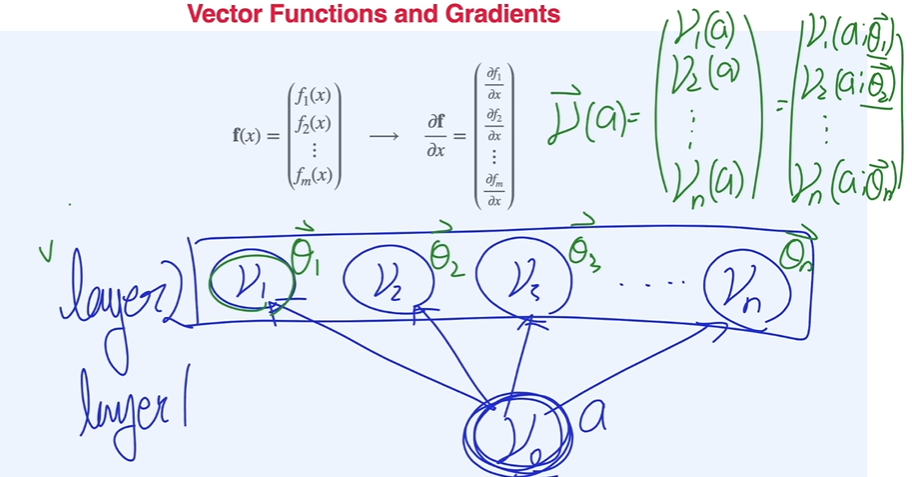
야코비안과 체인룰
입력이 n 크기의 vector, 출력이 m 크기의 vector function.
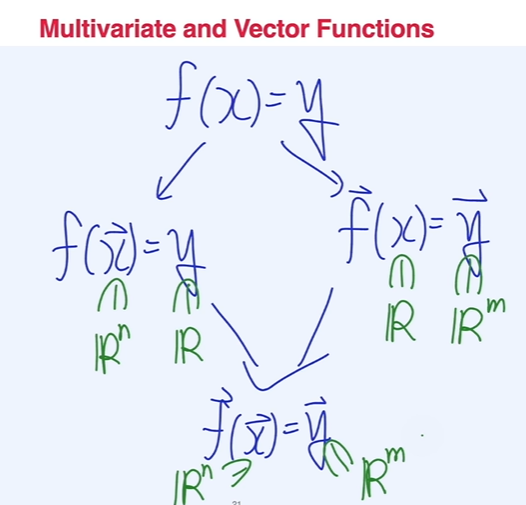
스칼라 표현은 (기본), 벡터 표현은 (볼드)로
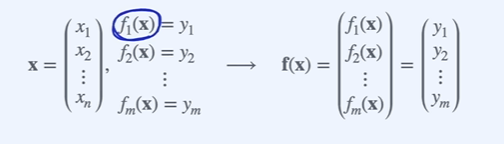
- 미분값은 개를 가질 수 있음.
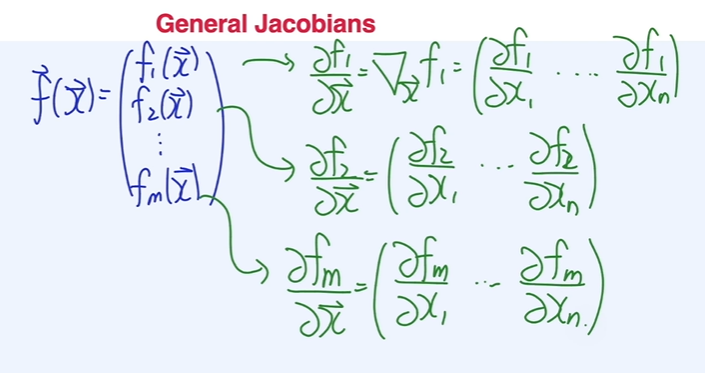
- multivariate 의 미분을 한 개념(가로로 정리)과 vector function(세로로 정리)의 미분 개념 ~ 추후 행렬의 곱셈에서 체인룰을 적용하기 위함
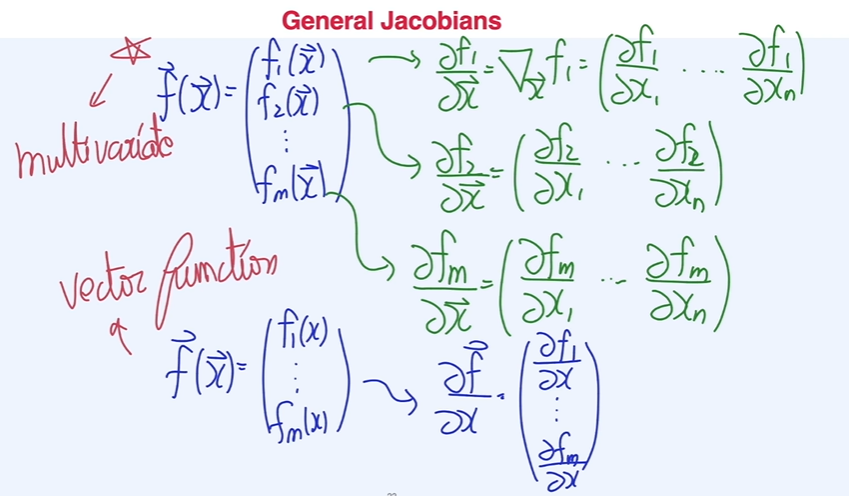
- 일반적인 형태의 야코비안 matrix
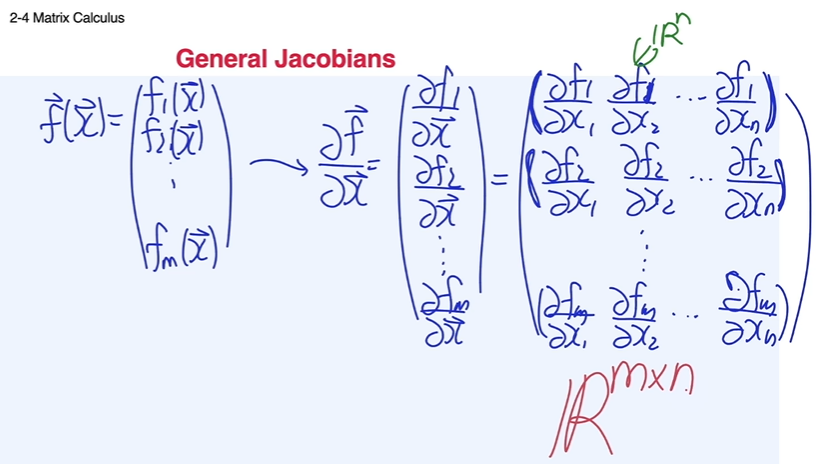

딥러닝 분야에서는 아래 그림의 모든 미분을 gradient라고 일컫는 편이다.

적분공식과 부정적분

ch3. 선형대수
벡터의 연산
자료구조에서
set과list가 다르듯이
벡터는 집합과 달리 중복이 가능하나 순서가 중요함.
벡터의 norm : L1 Norm = Manhattan distance // L2 Norm = Euclidean distance
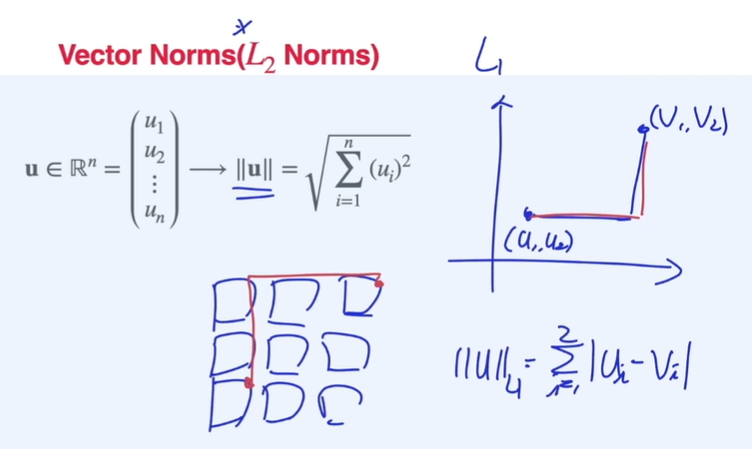
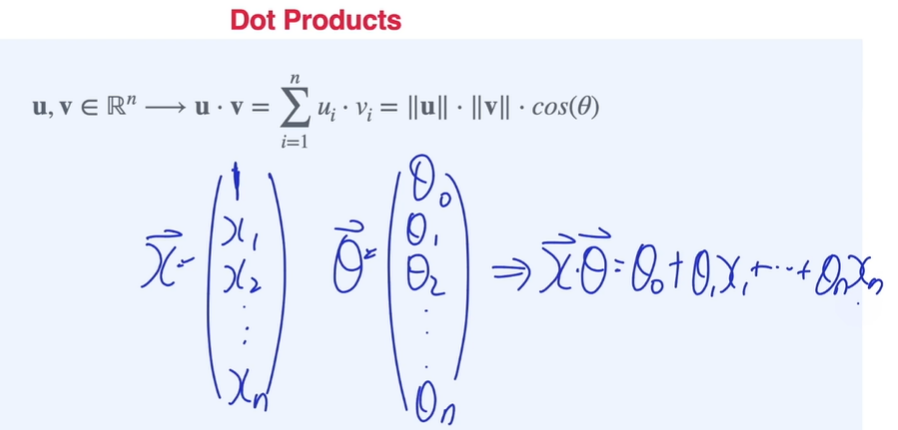
Dot product -> dummy variable을 만들어서
affine function형태로 만들 수 있음
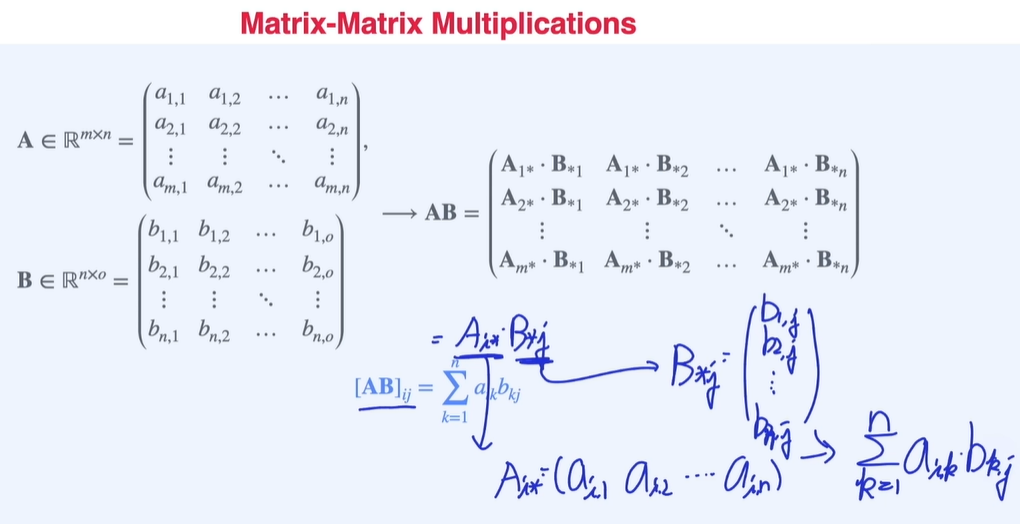
행렬의 연산
행렬의 표현 - row vector(행벡터 - 가로) 와 column vector(열 벡터 - 세로)

행렬의 곱셈 표현
연립선형방정식
- System of Linear Equations
연립방정식을 행렬로 표현하여 행렬()과 벡터()의 곱으로 표현할 수 있음.
-
Column spaces of matrices
연립선형방정식은 그림과 같이 linear combination으로 표현해줄 수 있음. 이말인 즉,
의 솔루션()이 존재하기 위해선 의 column space 안에 가 포함되어야 함.

-
Triangular Matrices
Upper Triangular Matrices를 배우는 이유는 연립방정식을 손으로 풀 때처럼 변수를 소거시켜 triangular 형태로 만들어 System of Linear equation의 계산을 쉽게, 쉬운 형태로 변형 하기 위함(a.k.a. Gaussian Elimination)

-
Diagonal Matrices
Diagonal 형태로 만들어 주면 아래 예시와 같이 x, y를 바로 구할 수 있는 형태가 된다. 이 형태를 만드는 계산을 Gauss Jordan Elimination라고 함.

선형변환
- Reflection Matrices
축변환을 해주는 행렬로, 역행렬 시 원래 있던 행렬과 같음.
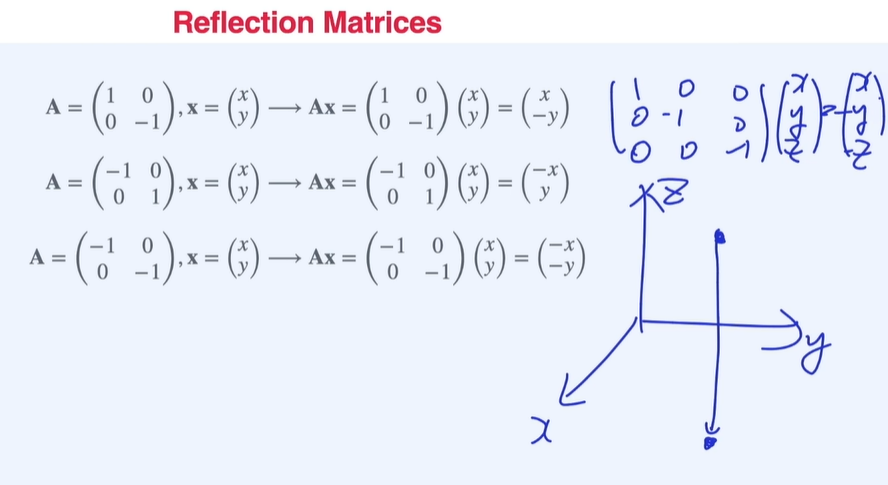
-
Scaling matrices
인 경우 너비가 배 만큼 변하는 것으로 해석할 수 있다.
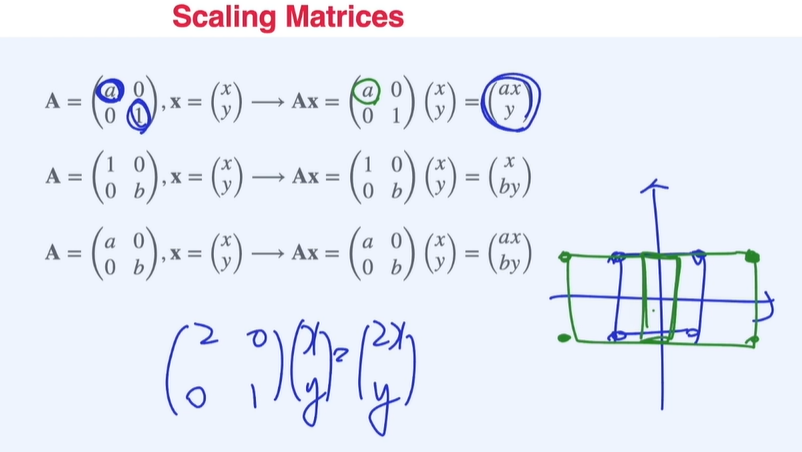
-
Rotation matrices
시계 반대방향으로 각도만큼 이동
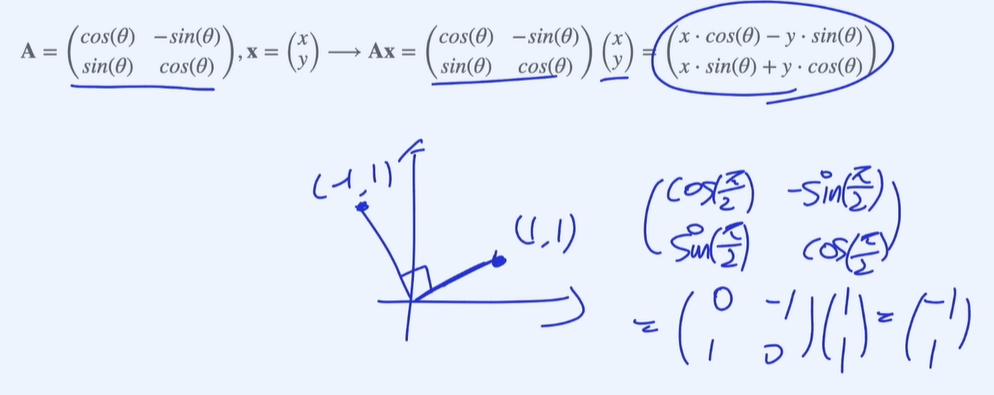
determinant 가 음수일 경우 x, y축이 서로 순서가 바뀐다고 생각할 수 있음.

정사영행렬
축 및 평면에 대한 projection

스칼라정사영과 벡터정사영
-
scalar projection
u 벡터가 얼마만큼의 v 벡터 성분을 가지고 있는지를 나타냄
그림과 같이 로 표현하며 스칼라값으로 정의
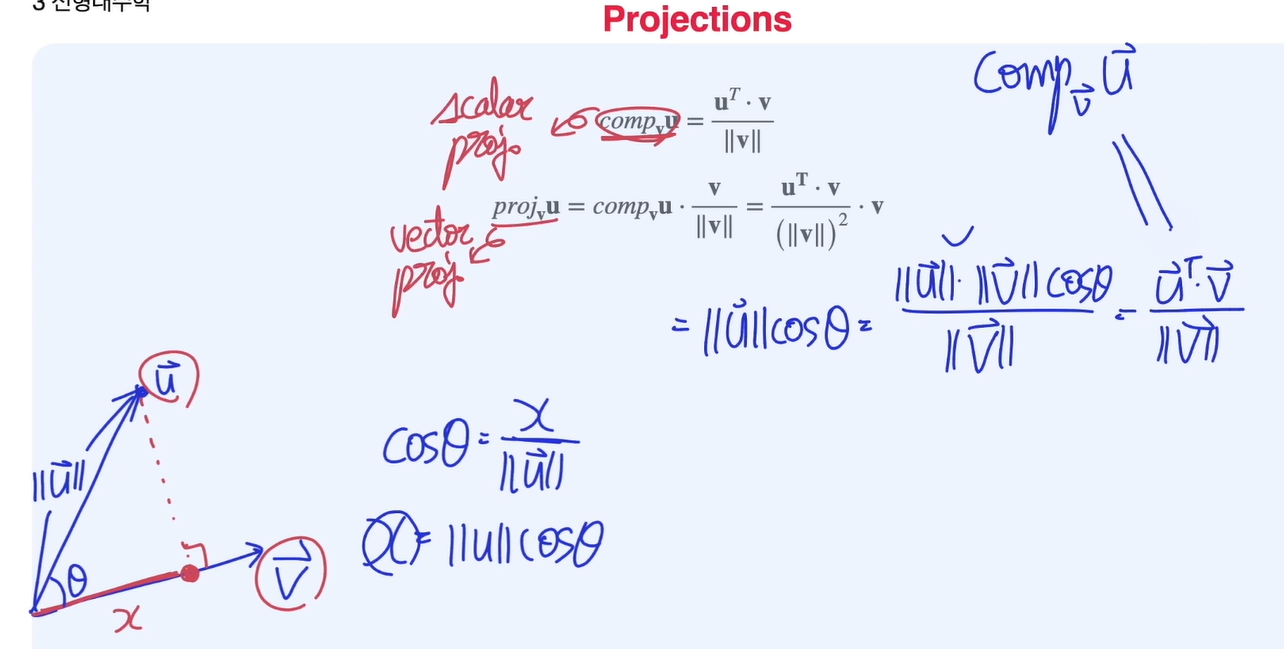
-
vector projection
그림과 같이 로 표현하며 scalar projection에 유닛벡터를 곱하여 정의함
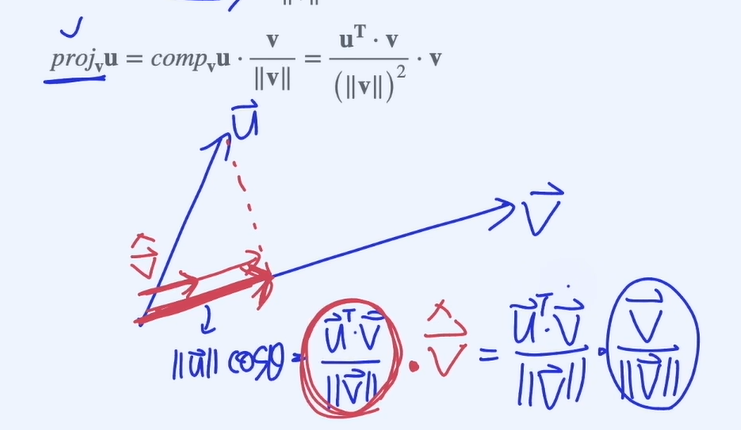
정사영행렬2
-
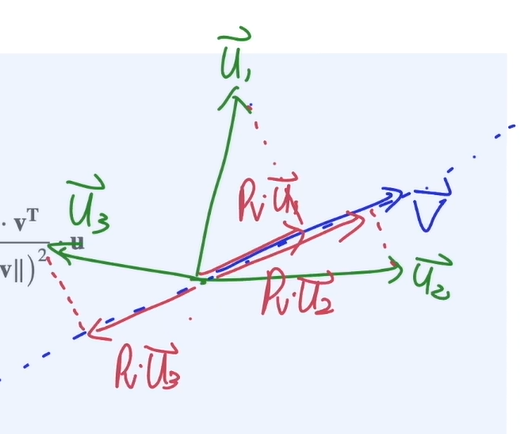
projection을 이용하여 벡터를 나누는 방법
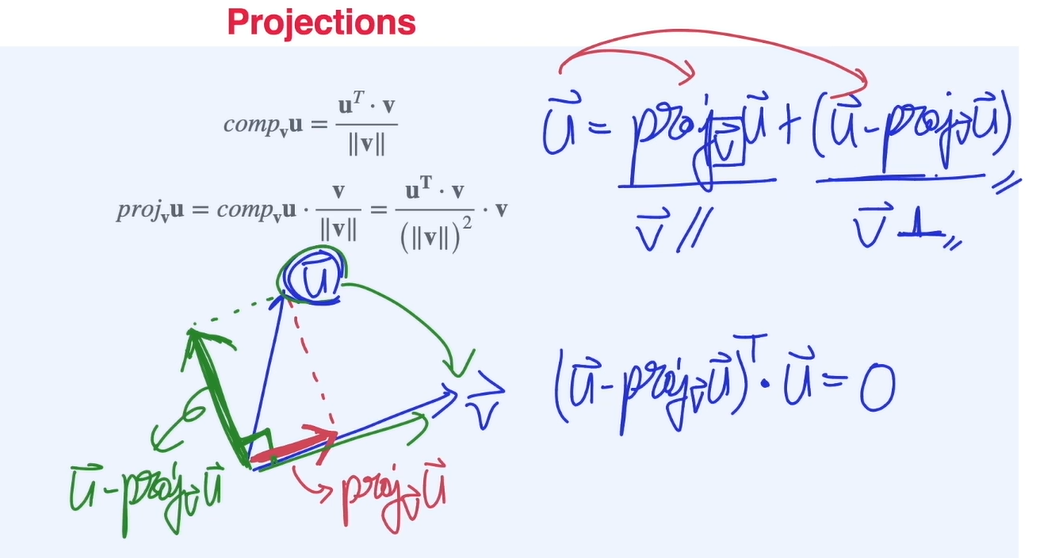
-
Projection matrix (=)를 derive 하는 방법.

-
Projection의 수직인 matrix
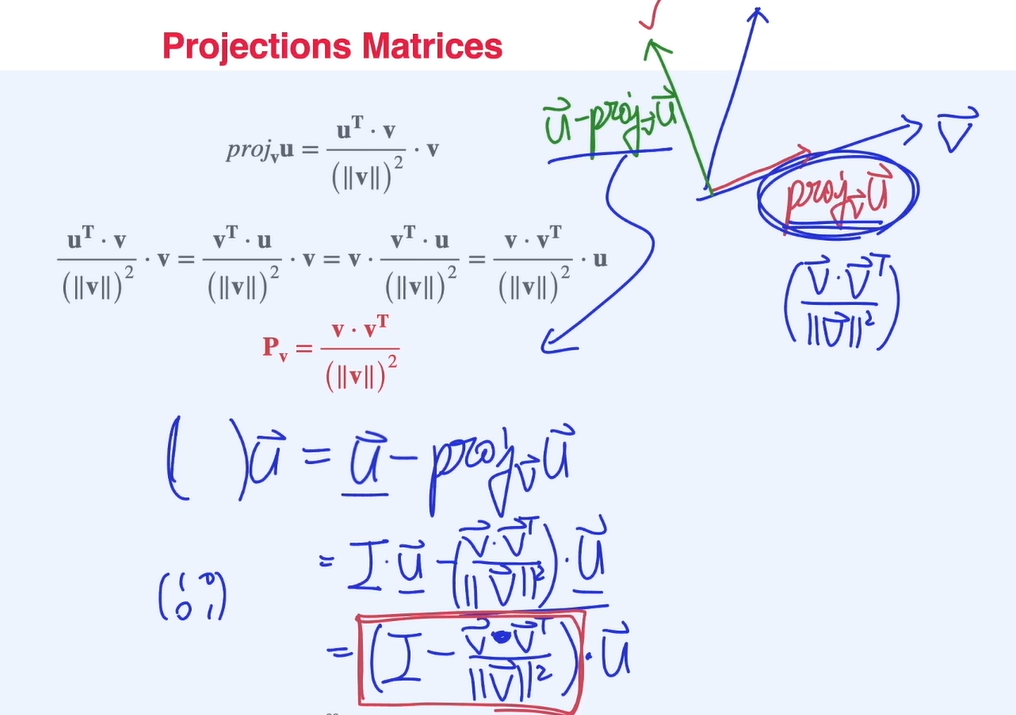
가역선형변환
A 행렬의 역행렬이 없을 경우 non Invertable Transformation , 즉 여러개의 x가 하나의 y에 대응되는 경우
Ex. projection matrix의 경우 non Invertable Projetion 이라고 할 수 있다.
행렬의 고유값(eigenvalue)과 고유벡터(eigenvector)
아래 식과 같이 행렬()을 이용해서 벡터 를 변환시켰을 때 의 방향은 변하지 않고, 크기만 변환되는 벡터를 eigenvector(), 그 때의 상수 곱을 eigenvalue()라고 한다.

-
eigenvalue 구하기
가 역행렬이 존재한다면 x가 0행렬일 경우만 식이 만족해버리므로 trivial 한 상황임
아래 그림과 같이 non-trivial한 상황에서 를 구하면 그 값이eigenvalue

-
eigenvector 구하기
아래 그림과 같이
eigenvalue를 이용하여 벡터 를 구하면 여러개의eigenvector가 나올 수 있는데 이것을 모아eigenspace라고 한다.

-
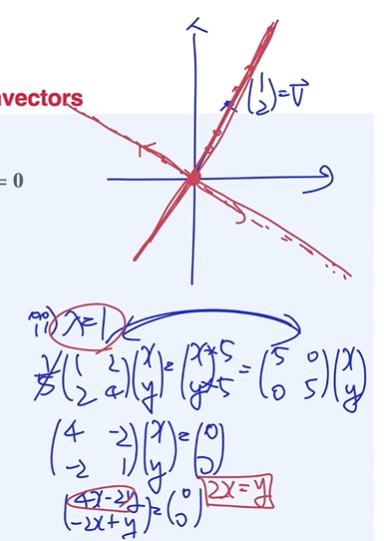
Projection matrix의 고유값과 고유행렬
그림과 같이 projetion matrix의 고유값은 0, 1

고유값이 0인경우의 eigenvector는 위에 있는 모든 벡터, 이 직선이 eigenspace

고유값이 1인경우의 eigenvector
ch4. 확률
베이즈 정리
도대체 어디다 써먹는지 처음 배울때는 몰랐으나 예시를 들으면 쉽게 이해가 되는 활용법.
검사 결과 암을 진단(positive) 받았을 때 실제 암일 확률을 알고 싶을 때 그 확률을 구하는 것은 어려움. 실제 암에 걸렸을 때 진단결과가 positive인 확률은 그나마 실제 암에 걸린 환자를 대상으로 확률을 구하면 되니 쉬운 문제(그나마 현실에서 가능한 문제)가 된다.

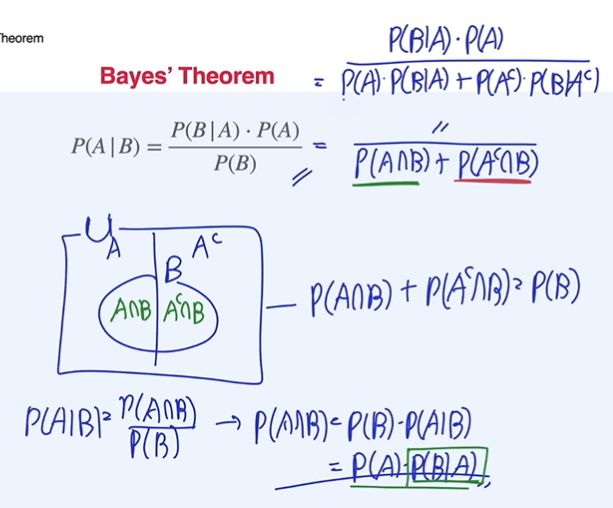
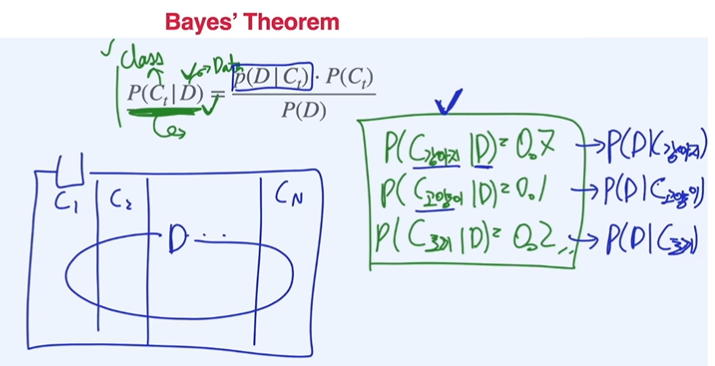
데이터에서 클래스를 분류하는 경우, 강아지라는 클래스에서 데이터를 추출하는 경우가 더 쉬울 수 있다.

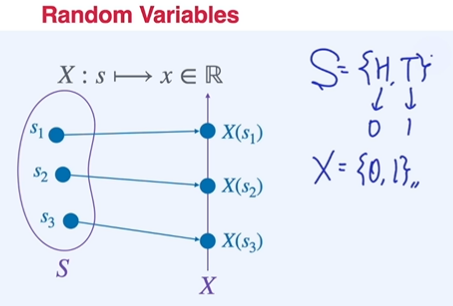
확률변수
이름은 변수이나 실제로는 함수로 생각하는 것이 더 편함. 주사위의 확률을 구하는 경우 확률변수화 할 필요가 없음 이미 outcome이 실수 값을 가지기 때문.
즉, sample space가 실수가 아닌 경우 프로그래밍이나 사칙연산 등을 적용하기 힘들기 때문에 아래 동전과 같이 Head / Tail 이라는 outcome을 random variable이라는 함수에 집어 넣어 0 / 1로 대응하는 것이 확률변수의 개념
결과적으로 같은 sample space 더라도 어떤 문제를 풀고 싶은지에 따라서 다른 확률변수값으로 정의할 수 있음.
연속형/이산형 확률변수가 존재. Ex. 전구의 수명,사람의 키(연속형) , 주사위에 나올 수 (이산형)
시그모이드와 소프트맥스
확률의 다른 표현
logits
odds :
odds의 분포를 보면 비대칭이기 때문에 log를 씌워 대칭형태로 만들어줌
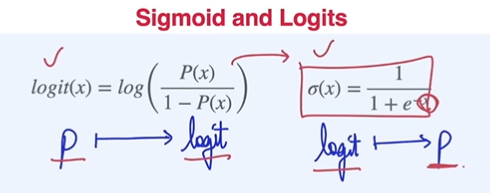
logits :
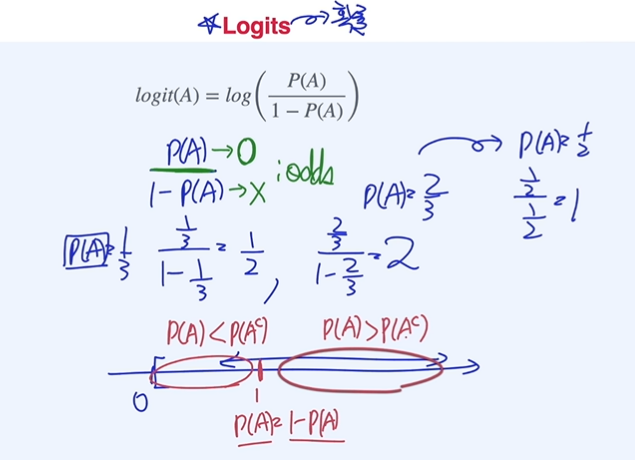
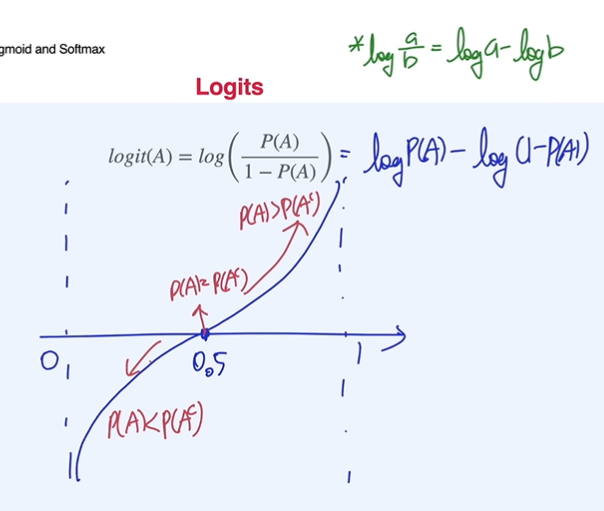
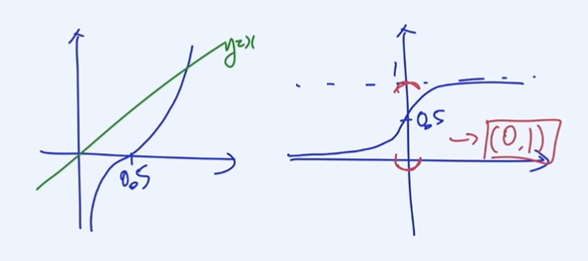
logit의 역함수 관계가 시그모이드 함수
logit은 확률을 받아서 logit값으로 만들어주는 것. 시그모이드 함수는 logit을 받아서 확률값으로 만들어주는 것이다.
인공지능에서 affine function 값을 logits이라고 생각하면 시그모이드 함수를 통과하면 확률값으로 치환된다.

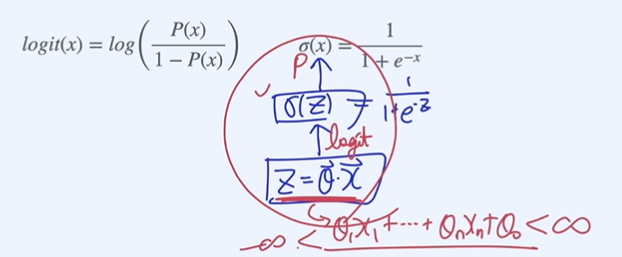
정보와 엔트로피
Shannon Information : 정보는 어떻게 수치화할까?
Shannon Entropy : 정보량의 기댓값

크로스 엔트로피
Binary Entropy
불확실성이 크다는 것은 앞면이 나올지 뒷면이 나올지 모르는 상태가 된다. 즉, 예측이 어려워지는 상태가 된다는 것을 말하며 두 사건이 일어날 확률이 같은 경우 가장 큰 불확실성, 엔트로피값을 가진다.

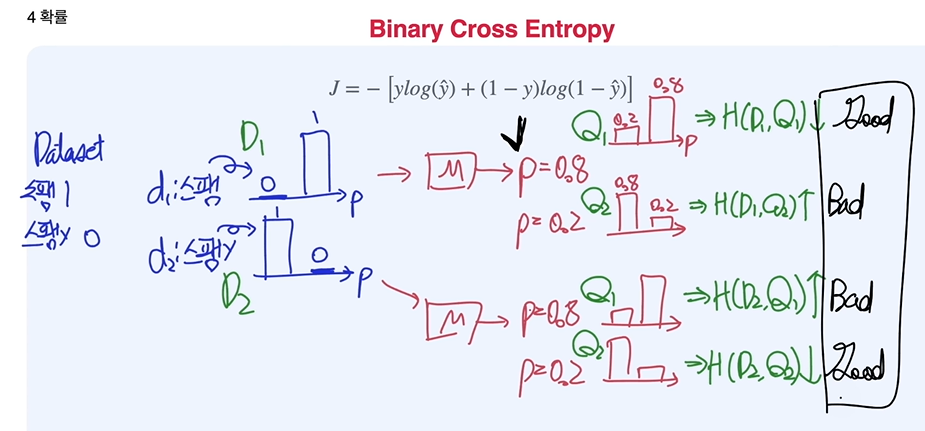
Binary Cross Entropy
Cross Entropy : 확률 분포 간 유사성을 보여주는 수치로 비슷할 수록 값이 낮고, 다를수록 값이 큼.
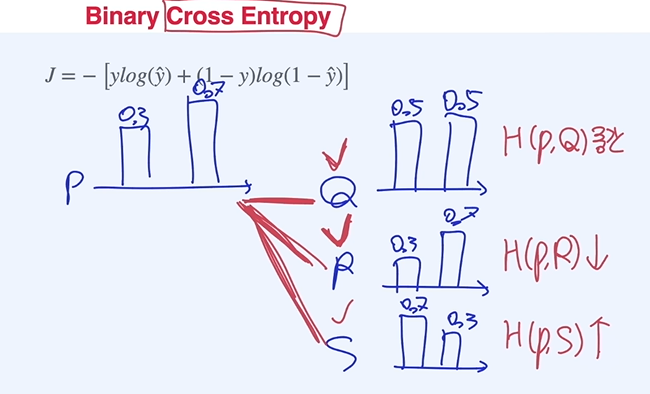
유사성이 클수록 값이 작기 때문에 머신러닝에서 Loss function으로 활용할 수 있다.
Cross Entropy
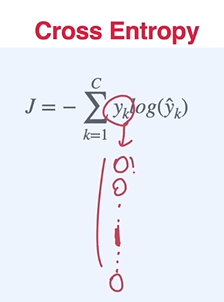
Appendix
Usage of Set

Infinite Sets의 종류

Unary/Binary Operations
Power Sets : 집합 A의 모든 subset들의 집합, 모든 원소들은 "집합"
Complements : 집합 A에 포함되지 않은 모은 집합A의 complement, 표현은


Logical Implications
전제가 False인 경우나 전제가 공집합일 경우 결론은 항상 True, Vacuous truth
왜냐면 거짓임을 밝힐 수 있는 수단이 없기 때문에 결국 True임을 말함
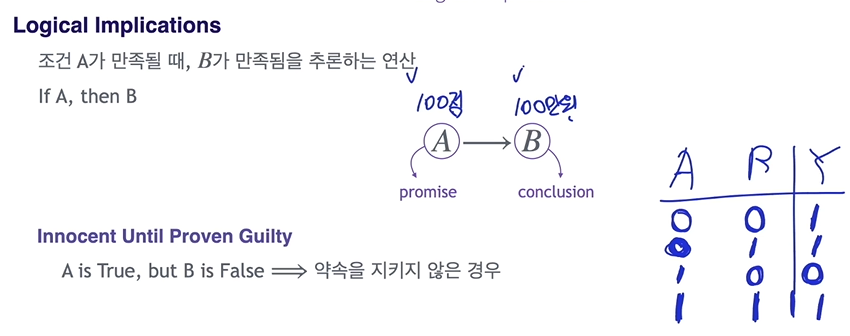
Sufficiency and Necessity
p q의 해석 p는 q이기 위한 충분 조건이다. q가 True임을 보이기 위해 p가 True임을 보이면충분하다
q는 p이기 위한 필요 조건이다.
p가 True이기 위해 q가 True임이필요하다.


IFF condition
If and only IF

For all, There Exists
: x가 될 수 있는 모든 경우에 대해 조건 p가 만족된다.
: 어떤(최소한 하나 이상의) x의 값이 조건 q를 만족시킨다.
: 어느 실수 x도 다음의 식을 만족하지 않는다.
항등원 역원의 표현

Polynomials

Division of Polynomials
용어: dividend(나눌애), divisor(나누는애), quotient(몫), remainder(나머지)
remainder의 차수는 quotient의 차수보다 낮다.

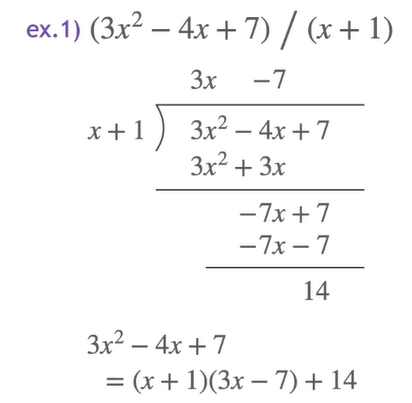
Solutions of Cubic Equations
3차 방정식부터는 정규과정이 아니니 제대로 생각해본 적이 없어서 낯설게 느껴진 내용. 실근이 최소 1개 이상 존재한다는 거부터 의문이었는데.. 물론 3차 방정식을 x, y좌표에 표현하면 무조건 실근 하나는 나오는 게 맞긴하지만 좀 더 논리적으로 이해하고 싶었다.
허근은 쌍으로만 존재한다?
정확히 말하면 실수 계수로된 다항식(polynomial with real coefficients)에서 한 복소수가 그 다항식의 근이라면 conjugate pair 한 복소수도 그 다항식의 근이어야 한다. 라는게Complex conjugate root theorem(https://en.wikipedia.org/wiki/Complex_conjugate_root_theorem)
If is a polynomial with real coefficients, and , then
Complex conjugate Theorem Proof
let
let be a root of
즉, 최소 실근 한 개를 해로 가지며 이차방정식의 Discriminants(판별식)에 따라 아래 그림과 같이 3차 방정식의 해집단을 분류할 수 있다.
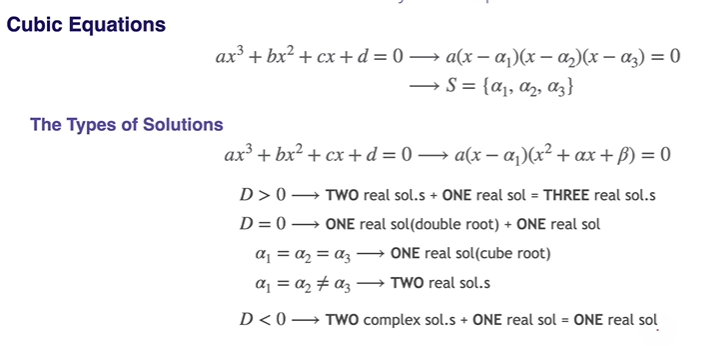
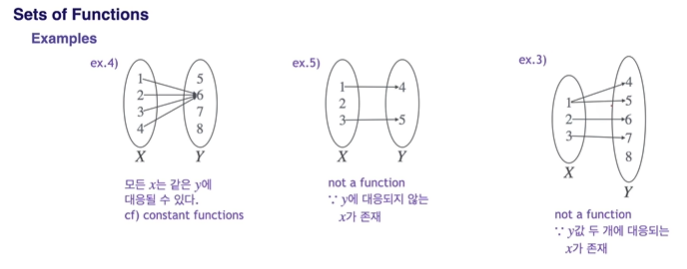
Sets of Functions
Domain(X) : 함수의 입력값이 될 수 있는 모든 값들의 집합
Codomain(Y) : 함수의 출력값이 될 수 있는 모든 값들의 집합
Range(R) : 함수의 실제 출력값들의 집합
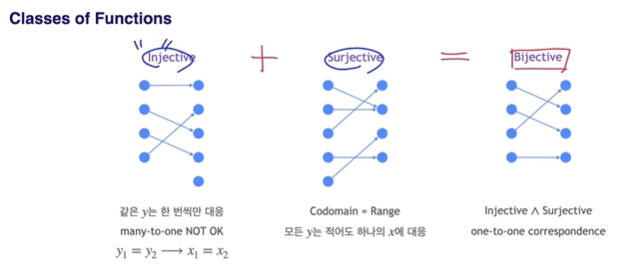
Classes of Functions
Injective : many to one 불허
Surjective : Codomain = Range
Bijectvie : One to One, , 즉, 같은 Cardinality
Point Distances to Lines
SSAFY에서 포켓볼 알고리즘 대회를 했을 때 동기 중 한명이 직선의 방정식을 굉장히 좋아하는 친구라 아직도 기억에 남는..
한 점에서 어떤 직선까지의 거리는 아래와 같이 정의할 수 있다.
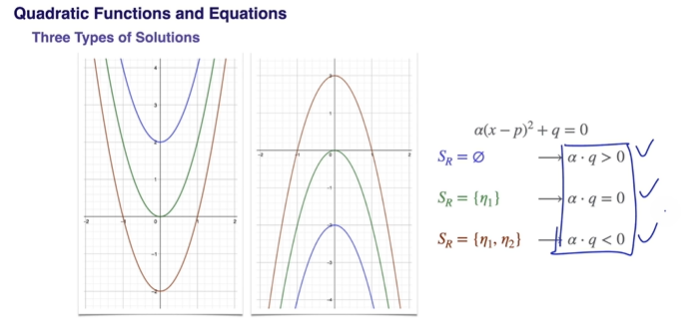
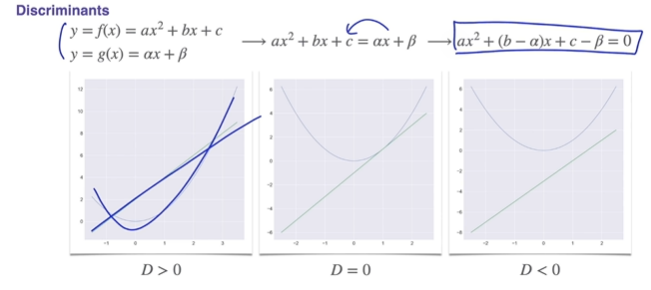
Quadratic Functions and Equations의 판별식(Discriminants)
분명히 중등교육 과정 때 판별식 유도를 배웠겠지만 잊어버린..
직선과 만나는 경우도 생각할 수 있다.
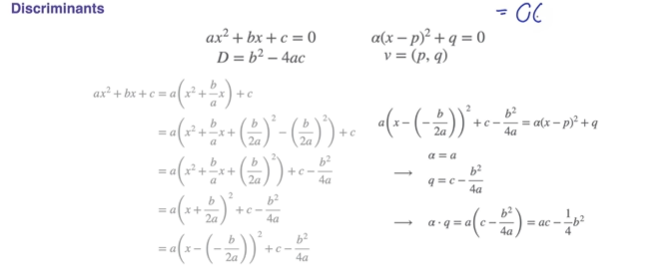
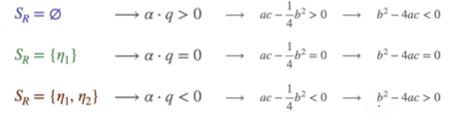
Polynomial Functions 그리기 - 인수분해꼴로 나타낸 후 해를 하나를 가져 뚫고 지나가느냐 중근을 가져 꺾여서 올라가느냐로 나뉨

Dilations of Functions

Concatenated Transformations

Decomposing Function => Even / Odd Components of a Function
적분, Transform 등을 쉽게 적용시키기 위해 분해
을 분리하는 방법

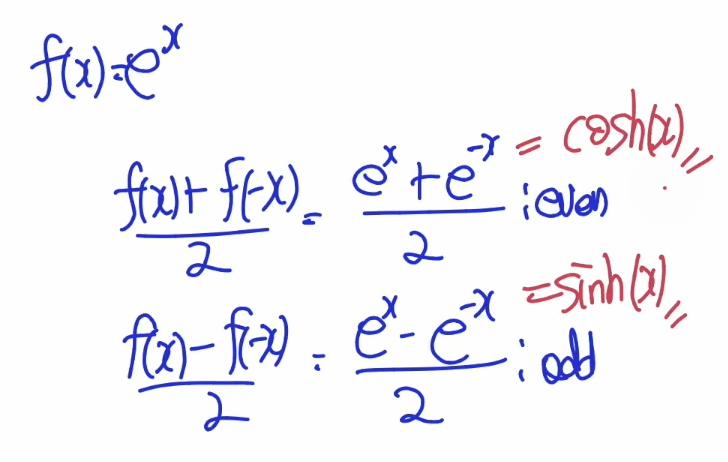
Subtractions of Polynomials
Special Cases
활용 예시
Other Special Cases
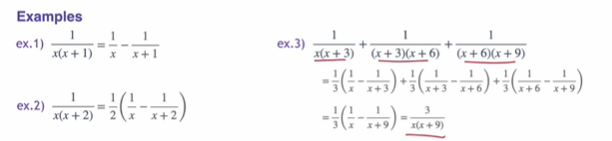

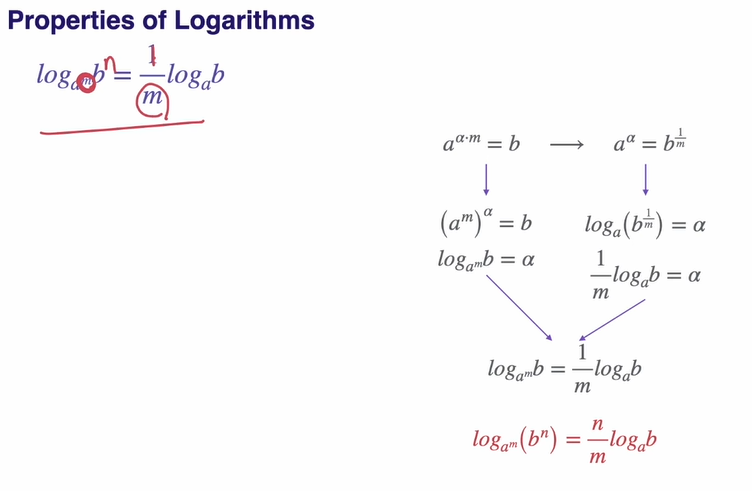
Porperties of Logarithms
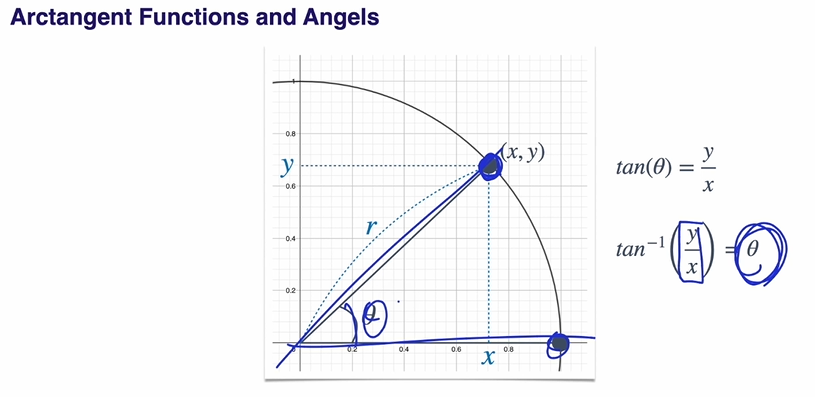
Trigonometric Ratios on Coordinate Planes
얼싸안코라니..
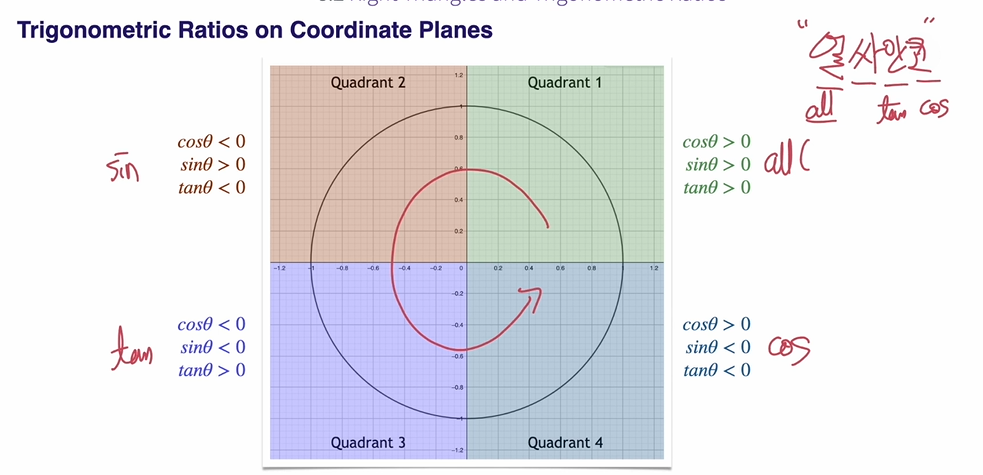
공학에서 가 많이 쓰이는 이유
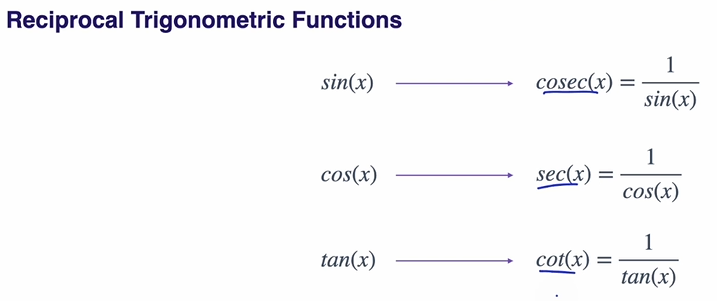
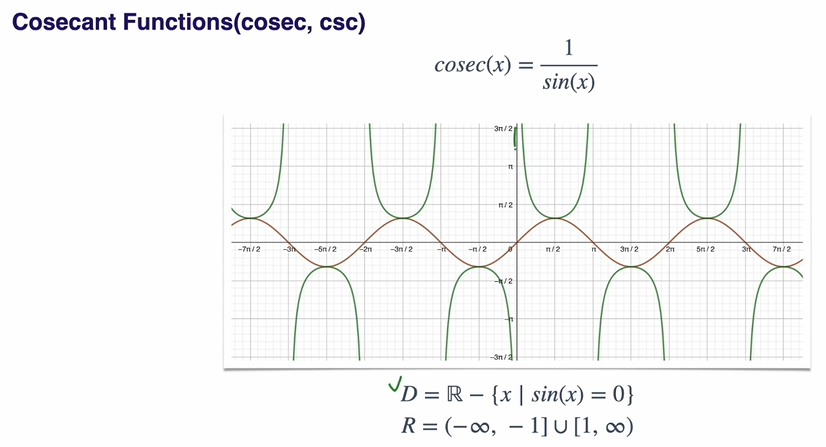
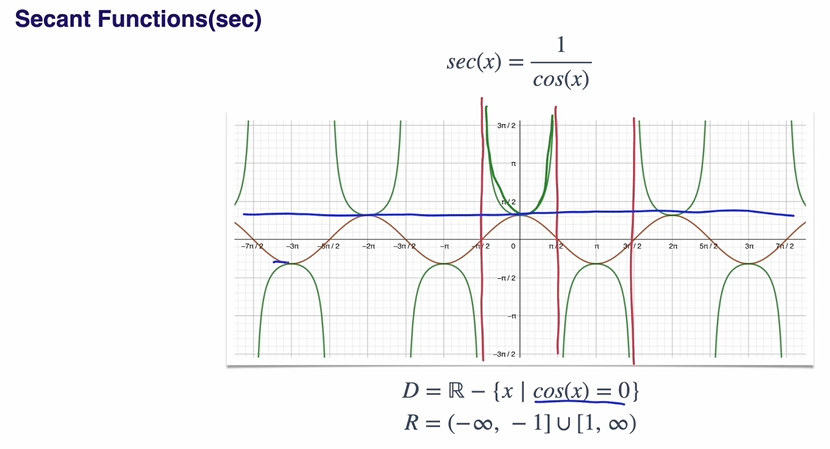
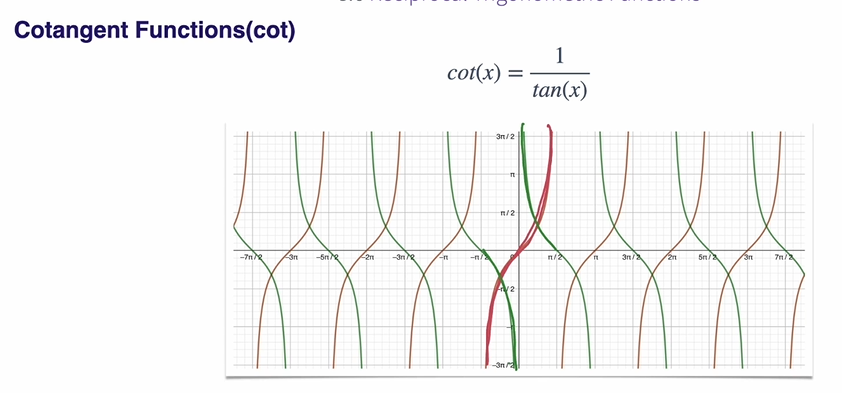
Trigometric Functions의 역수 함수
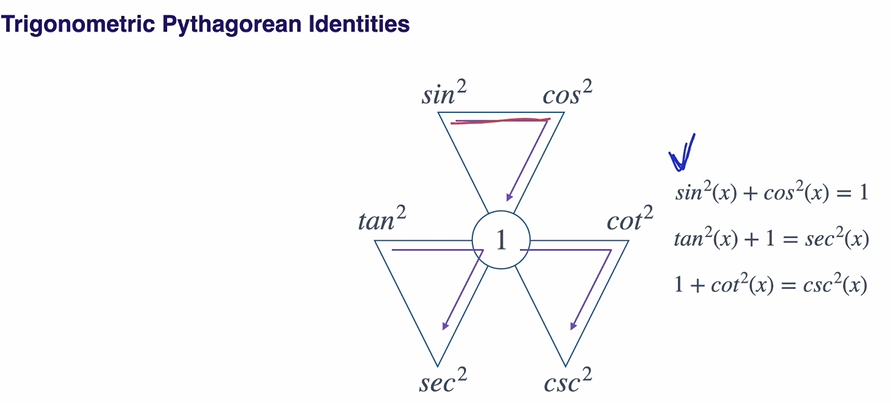
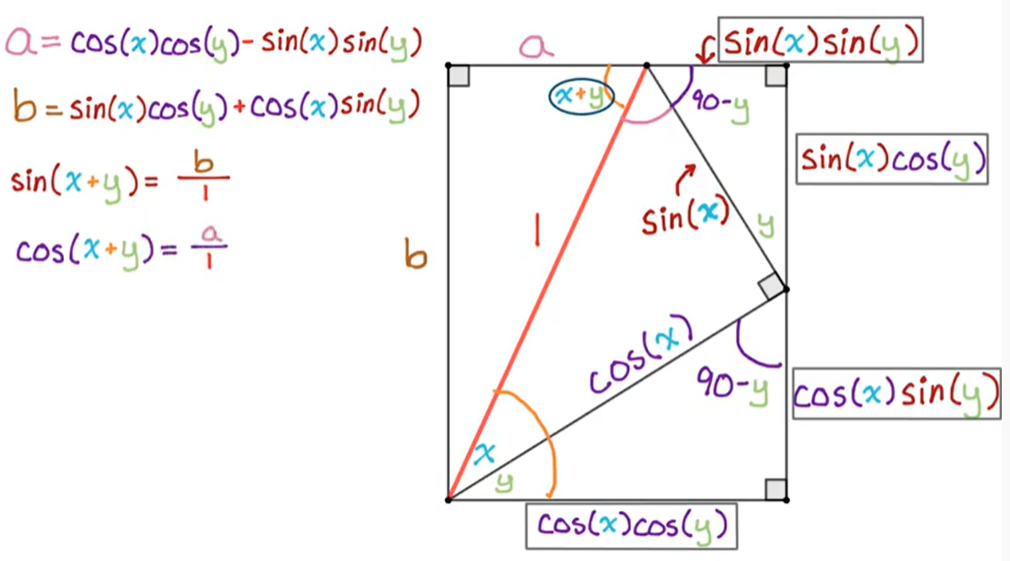
Sums and Differences of Angles
싸코코싸.. 코코마싸싸..
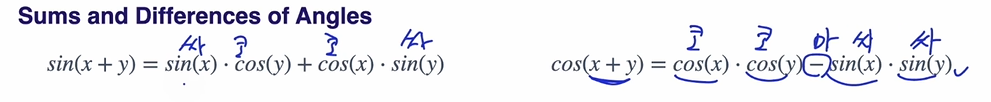
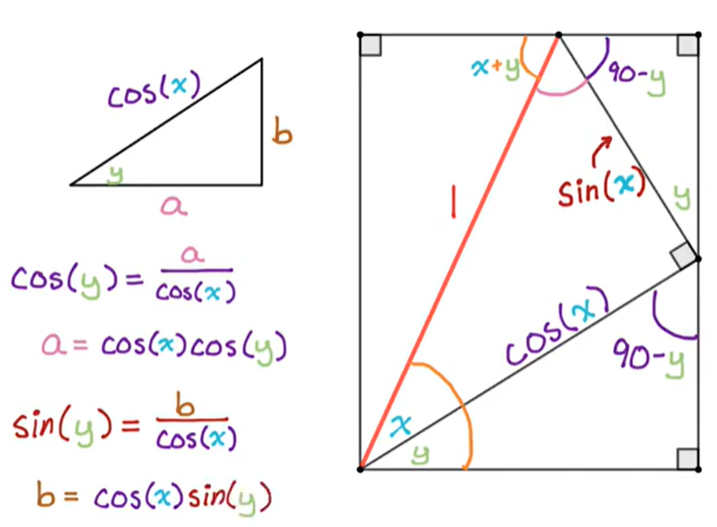
Deriving Sum Formulas for Sine and Cosine Geometrically
Double Angles

Half Angles
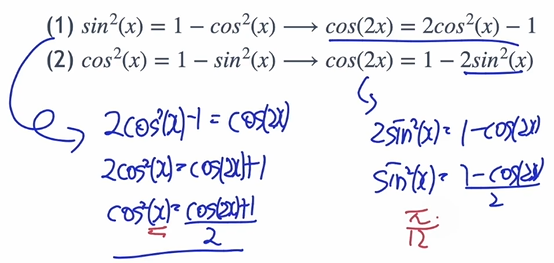
Products to Sums
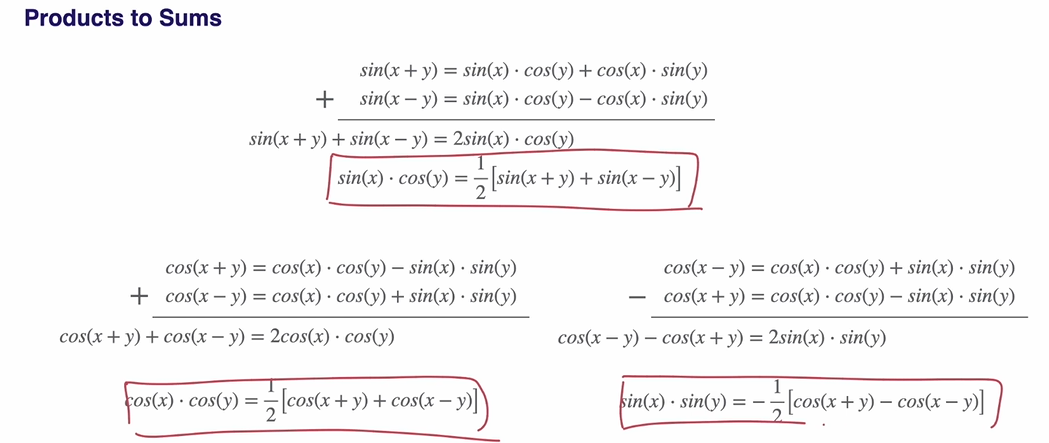
Sum to Product
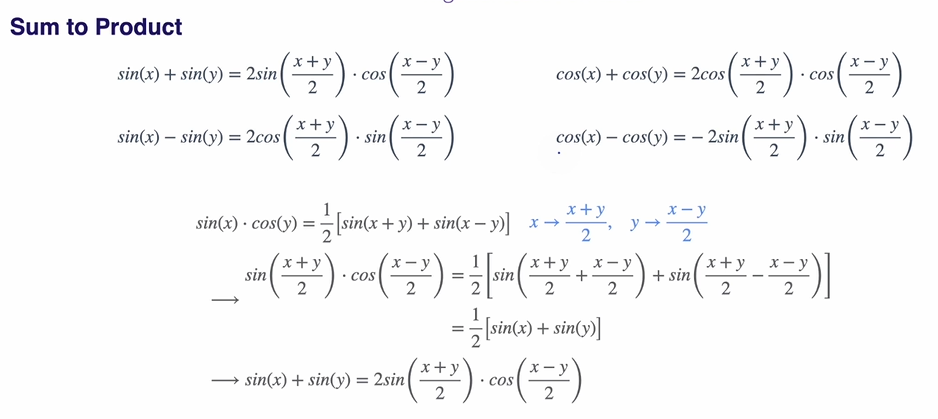
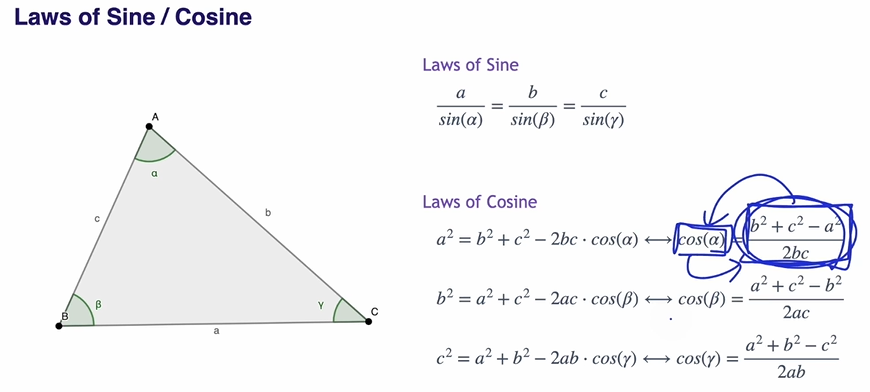
Laws of Sine/Cosine
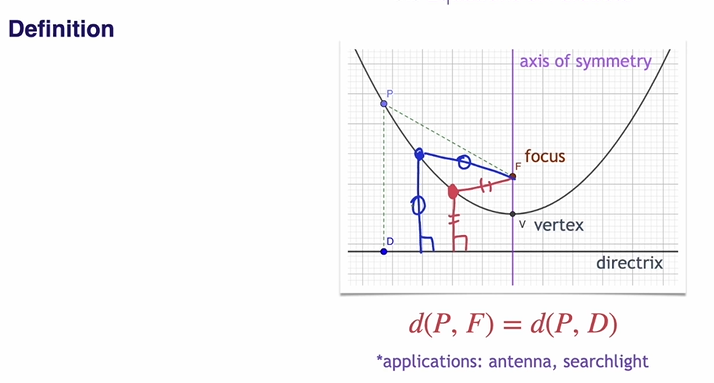
Definition of Parabola(포물선)
포물선의 광학적 특징을 이용해 antenna, searchlight에 활용 가능.
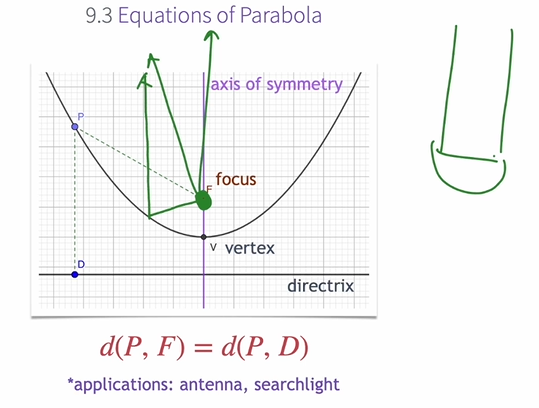
Vertices at the Origin

