[논문 리뷰] Learning Deep Features for Discriminative Localization
- 본 포스팅은 Class Activation Map을 중심으로 리뷰한다
Abstract
GAP(global average pooling)는 CNN이 image-level labels로 학습하지만 localization(위치 정보) 능력을 가질 수 있게 한다.
원래 GAP는 CNN 학습 단계에서 Regularization을 위해 도입되었는데 추후에 generic localization deep representation에 탁월한 것을 발견하였다.
Introduction
CNN은 특별한 지도(supervision)가 없음에도 불구하고, object를 detect하는 localization 능력을 가지고 있다는 것이 특징이다. 다만, classification task에서 convolution layer 중 일부 fully-connected layer(FC layer)를 사용하면 이 능력은 사라진다.
이후, 기존에 fc layer를 사용하던 NN(Network in Network)이나 GoogLeNet에서 fc layer를 사용하지 않고 localization 능력에 뛰어나며 parameter 수를 줄일 수 있는 방안을 모색했다. 이 방안의 핵심은 GAP이다.
앞선 abstract에서도 언급했듯이 GAP는 본래 CNN의 overfitting을 억제하기 위한 regularization 역할로 도입되었다. 그런데 GAP에 약간의 tweaking을 가하여 CNN에 적용하면 CNN은 classfication을 비롯한 다양한 task에 대해 마지막 layer까지 localization 능력을 유지할 수 있게 된다.

그림에서 보는 것과 같이 GAP을 포함한 CAM을 사용한 classification-trained CNN은 두 가지 능력을 갖추게 된다.
1. image classification
2. action detection, localize class specific region
*CNN에서 FC layer 대신 GAP를 사용하면 CAM이 된다.
..
<Related Work는 스킵한다.>
Class Activation Mapping
이 절에서는 CNNs의 GAP를 사용하여 CAM(Class Activation Map)을 생성하는 절차에 대해 설명한다.
이 절차를 표현한 그림이다.
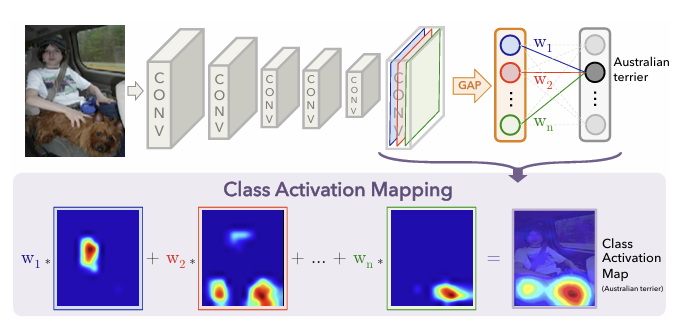
위 그림은 NN이나 GoogLeNet처럼 대부분 convolutional layer로 구성된 네트워크를 사용했으며 final output layer의 직전 단계에서 global average pooling을 추가했다. 그리고 이것을 fully-connected layer의 feature로 사용한다.
이 연결 구조를 감안할 때, 우리는 output layer의 가중치를 convolutional feature map에 다시 투영함으로써 image region의 중요도를 파악할 수 있는데, 이는 CAM(Class Activation Mapping)이라고 하는 기술이다.
GAP의 output은 마지막 convolutional layer의 각 unit(channel)의 평균값이다. 즉, GAP의 unit의 개수만큼 출력한다.
..
주어진 이미지에 대해서,
= 마지막 convolutional layer의 unit k의 위치에서의 activation
= , unit k에 대해 GAP를 수행한 결과값
= class c에 대한 unit k의 weight, class c에 대한 의 중요도
= , class c에 대한 softmax의 입력값
= , class c에 대한 softmax의 출력값
식을 에 대해 다시 표현한다며,
=
=
을 class c에 대한 CAM이라고 할 때,
모든 (x, y)에 대해,
=
그러므로 는 input image를 class c로 예측하는데 의 activation의 중요도라고 할 수 있다.
우리는 각 unit이 특정 visual pattern에 의해 시각화된다는 것을 직관적으로 알 수 있다. 그러므로, 는 이러한 visual pattern을 map으로 나타낸 것이라고 할 수 있다. CAM은 서로 다른 위치에서 나타나는 visual pattern을 가중합한 것이라고 할 수 있다.
<그림을 참고하길 바란다>
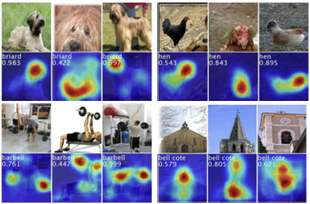
위의 그림은 CAM의 출력값으로, 4개의 class의 activation map이 표시되어 있다.
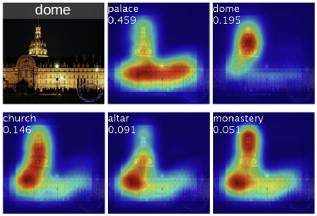
위의 그림은 하나의 input image에 대해 다른 classes c를 이용해 map을 생성했을 때 발생한 차이점을 나타낸 것이다.
Weakly-supervised Object Localization
- CNN의 supervised learning을 위해 모든 input image를 일일이 segmentation하거나 bounding box를 그리는 것은 수고스럽다.
- CAM을 활용하여 object label만 주어졌을 때 object localization을 할 수 있는지(weakly-supervised) 실험을 통해 증명하고자 한다.
이 장에서는 ILSVRC 2014 데이터를 사용해 다음을 증명한다.
1. CAM을 추가해도 object classification 성능이 나빠지지 않는다.
2. Weakly-supervised object localization의 성능이 좋다.
Classification 성능 비교
orginial network의 error vs. network에 GAP를 추가했을 때 error
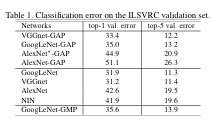
일반적으로 network의 fc layer를 삭제하게 되면, 1-2%의 정확도는 줄어든다. 이를 방지하기 위해, GAP를 추가하면서 GAP 전에 2개의 convolutional layer를 추가했다. 표에서도 확인할 수 있듯, GoogLeNet-GAP와 GoogLeNet의 성능은 비슷하다.
또한, 표에서 GoogLeNet-GMP와 GoogLeNet-GAP의 성능은 비슷한 것을 확인할 수 있다.
Localization 성능 비교
localization 성능을 평가하기 위해 predicted image에 bounding box를 추가해 성능을 평가할 수 있다.

위의 그림에서 GoogLeNet-GAP의 localization으로, 초록색 box는 grounded truth이고, 빨간색 box는 prediction이다.

위의 그림에서 상위 두 개의 사진은 GoogLeNet-GAP가 예측한 결과이고, 하위 두 개의 사진 GoogLeNet이 예측한 결과이다. GoogLeNet-GAP는 snow mobile과 apron의 위치를 정확히 파악했지만 backpropagation을 사용한 AlexNet은 그렇지 못하다.
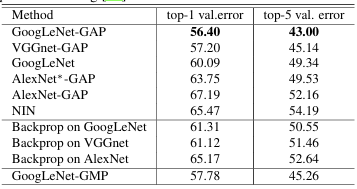
위의 표는 original network의 error vs. network에 GAP를 추가했을 때 error를 정리했다.
localization 성능은 top-5 val.error를 봤을 때, GoogLeNet-GAP가 GoogLeNet에 비해 10% 정도 error 값이 낮아진 것을 확인할 수 있다.
그러므로 GAP를 추가했을 때 Localization 능력은 향상되었다.
