
1. Introduction
❗기존의 Adaptive Gradient Method의 문제점
- Feed Forward Network나 Recurrent Neural Network에서는 Adaptive Gradient Method(ex. AdaGrad, RMSProp, Adam)가 디폴트 옵티마이저이지만, 이미지 분류 데이터셋을 처리하는 모델에 대해서는 여전히 SGD with momentum을 옵티마이저로 사용하는 것이 더 좋다고 알려져 있다.
- 뿐만 아니라, 다양한 딥러닝 테스크에 테스트해 보았을 때, Adaptive Gradient Method가 SGD with momentum보다 일반화 성능이 좋지 않다는 것도 알려져 있다.
🤔 이런 문제들에 대해 두 가지 가설이 있다.
1. Adaptive Gradient Method가 Sharp local minima에 빠질 가능성이 더 높다.
2. Adaptive Gradient Methods의 여러 내부 메커니즘에 의한 것이다.
본 논문은 딥러닝 모델 학습 시 SGD와 Adam(대표적인 adaptive gradient method) 옵티마이저에 대해, L2 regularization과 weight decay regularization 중 어느 방법이 더 효과적인지를 비교, 분석하였다.
그 결과, Adam의 일반화 성능이 낮게 나타나는 주요 원인은 L2 regularization이 SGD에서처럼 제대로 작동하지 않기 때문임을 증명했다.
_
🎯 본 논문에서 특히 핵심적으로 다루는 Adam 관련 5가지 분석 내용을 아래에 정리하였다.
1. L2 regularization and weight decay are not identical
먼저 SGD의 경우, learning rate을 기준으로 weight decay 항을 재구성하면 L2 regularization과 weight decay가 동일한 효과를 낸다.
그러나 Adam에서는 두 방식이 동일하게 작동하지 않는다. L2 regularization을 적용하면 파라미터가 gradient의 누적(history) 에 더 큰 영향을 받게 되어, weight decay에 비해 gradient 증폭에 대한 억제 효과가 약화된다.
2. L2 regularization is not effective in Adam
Adam을 비롯한 adaptive gradient method의 성능이 SGD with momentum보다 낮게 나타나는 한 가지 타당한 이유는, 대부분의 딥러닝 라이브러리들이 weight decay 대신 L2 regularization을 기본적으로 사용하기 때문이다.
이로 인해, 이미지 분류처럼 SGD에서 L2 regularization이 효과적으로 작동하는 테스크에서는 Adam이 상대적으로 불리하다.
이는 Adam과 같은 adaptive optimizer에서는 L2 regularization의 효과가 weight decay에 비해 훨씬 약하게 나타나기 때문이다.
3. Weight decay is equally effective in both SGD and Adam
SGD에서는 weight decay가 L2 regularization과 동일하게 작동하지만,
Adam에서는 두 방법이 동일하지 않다.
그러나 weight decay를 직접 적용(decoupled) 하면, SGD와 Adam 모두에서 동일한 regularization 효과를 얻을 수 있다.
4. Optimal weight decay depends on the total number of batch passes/weight updates
Adam과 SGD 모두에서 실험적으로 관찰된 결과에 따르면,
학습 시간(runtime) 또는 batch 업데이트 횟수가 많아질수록
최적의 weight decay 값은 점점 작아지는 경향을 보인다.
5. Adam substantially benefit from a scheduled learning rate multiplier
Adam과 같은 adaptive gradient method는 각 파라미터마다 적응형 학습률(adaptive learning rate)을 적용하지만,
여기에 사용자가 정의한 전역 학습률 스케줄(global learning rate schedule), 예를 들어 cosine annealing과 같은 learning rate decay 방식을 함께 적용하면 성능을 더욱 향상시킬 수 있다.
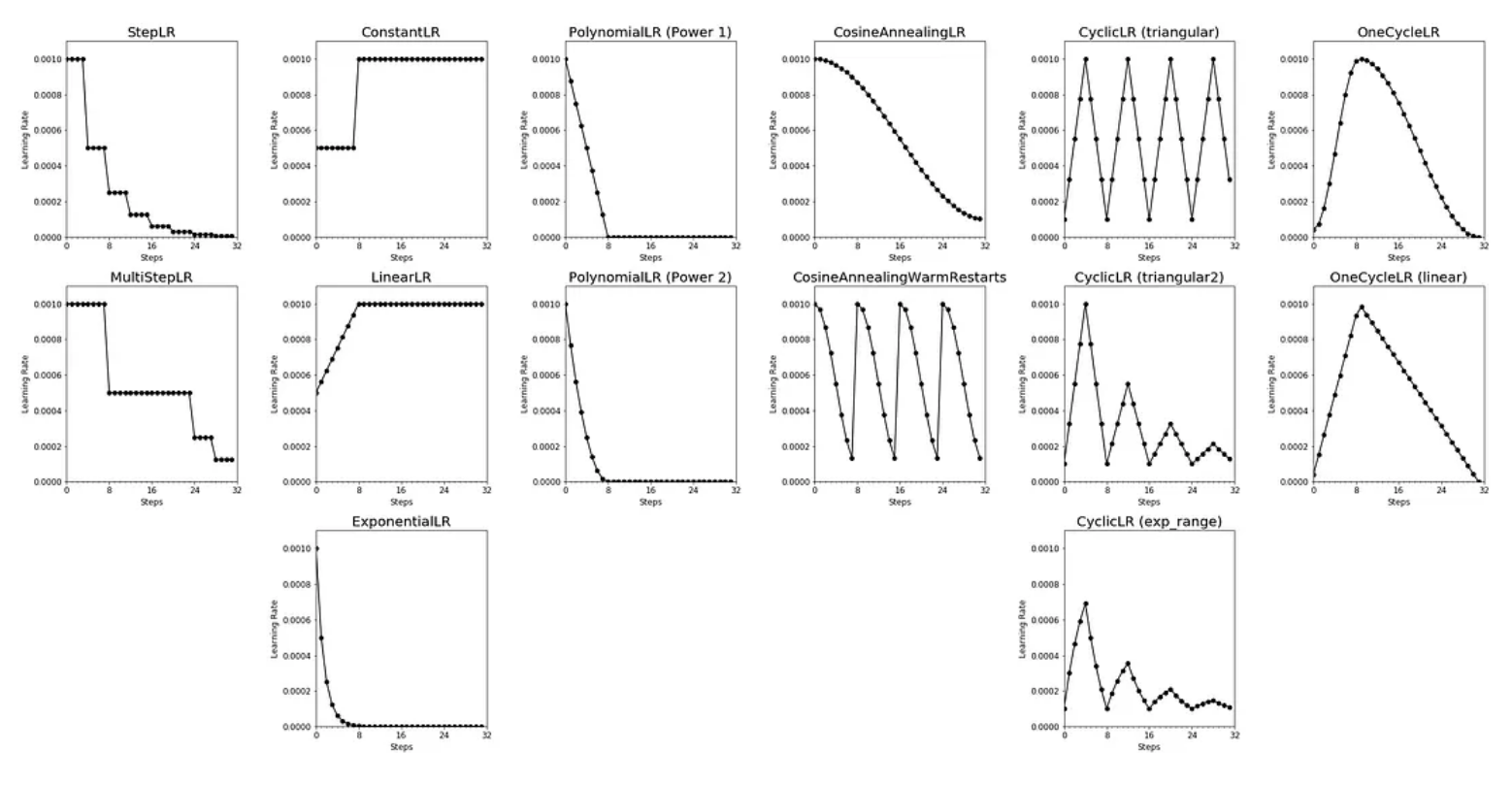 learning rate scheduler 종류 (출처: https://medium.com/data-science/a-visual-guide-to-learning-rate-schedulers-in-pytorch-24bbb262c863)
learning rate scheduler 종류 (출처: https://medium.com/data-science/a-visual-guide-to-learning-rate-schedulers-in-pytorch-24bbb262c863)
정리하자면, 본 논문의 핵심은 gradient-based update로부터 weight decay 항을 분리(decouple) 하여 Adam의 regularization 효과를 향상시키는 것이다.
실험 결과, 여러 image recognition dataset에서 Adam + decoupled weight decay를 사용했을 때, L2 regularization을 적용한 경우보다 test error가 약 15% 감소함을 확인하였다.
또한, decoupled weight decay를 사용하면 learning rate과 weight decay factor의 최적 값을 서로 독립적으로 조정할 수 있어, hyperparameter 최적화가 훨씬 용이해진다.
2. Decoupling the Weight Decay from the Gradient-Based Update
🟢 weight 는 일반적으로 아래의 weight decay 식을 따르며 지수적으로 줄어든다.
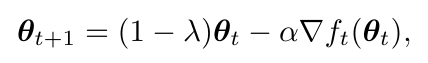 (: weight decay per step, : learning rate, : -th batch gradient)
(: weight decay per step, : learning rate, : -th batch gradient)
Proposition 1:
SGD: weight decay L2 regularization
표준 SGD에서 weight decay 계수 를 사용하는 경우와, weight decay 없이 L2 regularization을 적용한 을 사용하는 경우 모두 base learning rate 는 batch loss function 에 동일한 크기의 step을 적용한다.
🔻단 이 관계는 일 때만 성립한다!
따라서 Adam에서는 이 조건을 만족시키지 않기 때문에 weight decay와 L2 regularization의 효과가 동일하지 않다.
와 , 두 개의 hyperparameter의 효과를 명확히 분리시키려면 weight decay step을 gradient-based update로부터 분리(decouple) 해야 한다.
아래는 SGD+L2 regularization 그리고 SGD+decoupled weight decay를 사용한 알고리즘의 pseudo code다.
초록색 형광펜: SGDW (SGD with momentum + decoupled weight decay)
SGDW는 SGD with momentum에 decoupled weight decay를 적용한 알고리즘이다.
(자주색 형광펜 부분은 SGDW 알고리즘에 존재하지 않는다.)
SGDW를 구혁하기 위해서는,
- Line 6: gradient를 구하는 과정에서 regularize term을 없애고,
- Line 9: 파라미터 를 업데이트함과 동시에 weight decay를 별도로 적용한다.
즉, 자체에 decay를 적용하면서 gradient에서 regularization 효과를 분리(decoupled)하는 것이다.
추가적으로 와 를 scheduling하기 위해 scheduling factor인 를 사용한다. (이때, 는 사용자 정의 함수인 SetScheduleMultiplier(t)로 정의한다. 위의 그림 참고.)
아래는 Adam + L2 regularization과 Adam + decoupled weight decay의 알고리즘을 비교한pseudo code다.
Adam과 같은 adaptive gradient method는 과거의 gradient 크기를 기반으로 각 파라미터의 gradient를 적절히 scale하여 업데이트 크기를 조절한다.
따라서 Adam의 loss function에 L2 regularization을 적용할 경우(자주색 형광펜),
gradient가 커질수록 regularization 효과가 상대적으로 약화되는 문제가 발생한다.
아래의 그림에서 더 자세히 설명하면,


Proposition 2:
Weight decay L2 reg for adaptive gradients

L2 regularization은 gradient을 계산할 때,
손실함수의 gradient와 regularizer의 gradient를 합한 후, 이를 adaptive하게 스케일링한다.
반면, decoupled weight decay에서는 손실 함수의 gradient만 adaptive하게 계산되며
정규화 항은 weight update 단계에서 별도로 적용된다.
이로 인해 L2 regularization을 사용할 경우,
gradient의 크기가 큰 weight일수록 regularization 효과가 상대적으로 약해지는 문제가 발생한다.
그러나, decoupled weight decay는 weight update 시 항을 모든 weight에 동일하게 적용하므로, gradient의 크기와 무관하게 균일한 정규화 효과를 낼 수 있다.
그래서 gradient가 큰 weight에 대한 정규화 효과는 decoupled weight decay가 L2 regularization보다 더 강력하다.
Proposition 3:
Weight decay = scale-adjusted L2 reg for adaptive gradient algorithm with fixed preconditioner
(scale-adjusted L2 regularization을 쓰면 weight decay와 같은 효과를 낸다.)
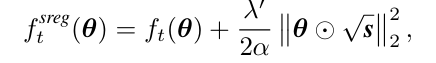
(scaled-adjusted L2 regularization을 적용한 손실함수)
scale-adjusted L2 regularization을 적용한 손실 함수는
이미 weight decay에 해당하는 항을 내포하고 있으며,
그 항이 preconditioner (즉, gradient의 스케일을 조정하는 요소)에 맞춰 scaling된 형태로 포함되어 있다.
따라서, adaptive optimizer에서 preconditioner가 고정되어 있을 경우,
이 scaling된 L2 regularization 항이 weight decay와 동일한 역할을 수행하게 된다.
즉, gradient를 통해 학습이 진행될 때,
regularization 항이 이미 preconditioner의 크기 조정 효과를 반영하고 있으므로,
scale-adjusted L2 regularization = weight decay 관계가 성립한다.
📕 결론적으로, 본 논문은 adaptive gradient method에서의 일반화 성능 저하 원인을 L2 regularization과 weight decay의 비등가성으로 분석하고,
이를 해결하기 위해 gradient update로부터 weight decay를 분리(decouple) 하는 방식을 제안하였다.
