Abstract
주요 Natural language understanding tasks
1. Textual Entailment
2. Question Answering
3. Semantic Similarity Assessment
4. Document Classification
이 tasks들을 수행하는 모델을 학습할 때 가장 문제가 되는 것은 labeled text corpus가 부족하다는 것!
→ 다양한 unlabeled corpus에 대해 language model을 사전 학습(generative pre-training)한 뒤, 각 특정 과제에 대해 discriminative fine-tuning을 함으로써 해당 task들에 대해 큰 성능 향상을 얻을 수 있다.
- 이 모델의 특별한 점: general task-agnostic model (구체적으로 어떤 하나의 task를 수행하는지 정해져 있지 않고 여러 task를 수행할 수 있다)
- fine-tuning 할 때, task-aware input transformation을 해줌으로써 모델 구조에 최소한의 수정을 거쳐 효과적인 전이학습을 할 수 있게 한다.- 12개의 natural language understanding tasks 중 9개에서 SOTA 성능을 냈다.
1. Introduction
raw text로부터 효과적인 학습을 하려면 우선 NLP task에서의 supervised learning의 의존을 줄이는 것이 중요하다.
그런데 대부분의 딥러닝 모델들은 인간이 라벨링한 대량의 데이터가 필요한데 이건 라벨링된 데이터가 적은 여러 도메인에 적용하기 어려워진다.
만약 모델이 라벨링되지 않은 데이터로부터 언어 정보를 학습할 수 있으면 많은 노력과 자본이 들어가는 데이터 라벨링을 하지 않아도 된다.
뿐만 아니라, 모델이 라벨이 없는 데이터로부터 좋은 representation을 학습할 수 있는 능력을 갖춘다면 성능이 크게 좋아진다.
이에 대한 증거로, word embedding 사전학습이 다양한 NLP tasks들의 성능을 향상 시키기 위해 널리 사용되고 있다.
❗그런데 라벨링되지 않은 text로 단어 수준 정보 이상의 정보를 학습하는데 두가지 문제점이 있다.
1. 전이 학습에 유용한 text representation을 학습하는데 어떤 최적화 objective가 가장 효과적인지 명확하지 않음
2. 학습된 text repressentation을 target task에 전이하는 가장 효과적인 방법에 대한 합의가 없음
- 현재 알려진 기술로는 여러 learning schemes와 보조적인 학습 objective을 사용해 모델 구조에 task-specific 변화를 추가한 조합을 사용하는 방법이 있다.
→ 이런 문제점들로 NLP task에서 semi-supervised 학습 방법을 효과적으로 발전시키는 데에 어려움이 있다.
본 논문에서는 (Unsupervised Pre-training + Supervised Fine-tuning) 방식의 semi-supervised 학습 방법에 대해 탐구한다.
🎯 목표!
language의 universal representation을 학습하여 작은 변화만 주고도 여러 NLP task에 적용할 수 있도록 한다.
이걸 하려면
1. 다양한 데이터셋의 unlabeled text corpus를 학습하고
2. target task의 labled training example으로 fine-tuning 시킨다.
- target task의 training example은 unlabeled corpus와 같은 도메인일 필요는 없다!
Training Procedure
1. 라벨링 없는 데이터로 Language modeling objective을 학습해 Neural Network model의 초기 파라미터를 구한다.
2. 각 task에 해당하는 objective을 사용해 이 파라미터들을 adapt한다.
모델 - Transformer
이유: long range dependencies를 다루는데 rnn과 같은 다른 모델에 비해 성능이 좋아 다양한 task에 전이했을 때도 robust한 성능을 낼 수 있음
전이 학습:
task-specific input adaptation: structured text input traversal-style approaches
결과
네 가지 language understanding task에 대해 평가!
1. natural language inference
2. question answering
3. semantic similarity
4. text classification
그 중에서 9/12의 task에서 SOTA 성능을 냄!
2. Related Work
Semi-supervised learning for NLP
이전에 사용하던 semi-supervised learning:
라벨링 없는 데이터로 word-level이나 phrase-level의 통계치를 계산하고 이 통계치를 supervised model의 feature로 사용했다.
최근 몇 년 간, 연구자들은 라벨링 없는 데이터로 학습한 word embedding을 사용하면 여러 task에서 높은 성능을 낼 수 있다고 알아냈다. 그런데 이 연구들은 world-level의 정보만 전달할 수 있고 더 포괄적인 정보를 나타낼 수는 없었다.
목표: Phrase-level이나 sentence-level의 embedding을 통해 text를 여러 NLP target tasks에 맞는 vector representation으로 encoding하려고 한다.
Unsupervised pre-training
Semi-supervised learning의 특별한 case로 목표는 supervised learning objective을 수정하는 대신 좋은 초기화 point를 찾는 것이다.
관련해서 가장 비슷한 선행연구
Dai et al. and Howard and Ruder: language modeling objective으로 neural network를 사전 학습시키고 target task로 fine-tuning 시켜 text classification을 함
BUT 이 연구는 사전 학습을 통해 언어 정보를 학습할 수는 있지만 LSTM을 사용하기 때문에 short range prediction 밖에 할 수 없다.
이 외의 연구들: 사전 학습 모델에서 나온 hidden representation을 보조 feature로 사용해 target task에 관한 supervised model을 훈련시킨다.
BUT 이렇게 하면 각 target task에 대해 꽤 많은 양의 파라미터를 새로 학습해야한다.
반면, 본 논문에서는 transformer를 사용해 long-range 언어 구조를 학습하고 더 다양한 task에서도 효과적으로 작동한다. 또한, fine-tuning 과정에서 모델 구조에 최소한의 변화만 줄 수 있다.
Auxiliary training objective
Semi-supervised learning의 대안으로는 auxiliary unsupervised training objectives를 추가해주는 것이 있다.
Collobert and Weston: POS tagging, chunking과 같은 다양한 NLP auxiliary NLP tasks을 사용해서 언어 모델의 semantic role labeling을 발전시켰다.
본 논문에서도 auxiliary objective을 사용하지만 unsupervised 사전 학습을 통해 target tasks과 관련된 여러 linguistic aspects를 학습시켜 두었다.
3. Framework
앞에서 계속 언급했듯 학습 단계는 크게 두 단계로 구성되었다.
1. Unsupervised Pre-training
2. Supervised fine-tuning on a specific task
3.1 Unsupervised pre-training
Unsupervised corpus of tokes를 이라고 할 때, 아래의 표준 언어 모델링 objective를 사용해 아래의 likelihood를 최대화하고자 한다.
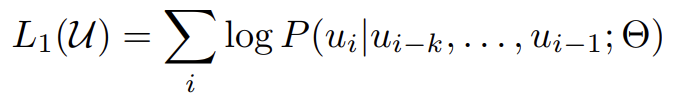
: context window size
: conditional probability
: parameters trained using stochastic gradient descent
Model: Transformer Decoder
- input context tokens에 대해 multi-headed self-attention operation을 하고,
- target token에 대한 output distributio을 생성하기 위해 position-wise feedforward layers를 통과시킨다
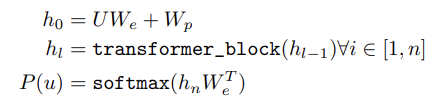
: context vector of tokens
: number of layers
: token embedding matrix
: position embedding matrix
3.2 Supervised fine-tuning
위의 식으로 pre-training된 모델을 가지고 supervised target task에 맞게 parameter를 adapt한다.
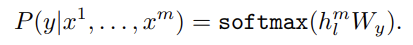
: labeled dataset
: 를 구성하는 input tokens
: 사전 학습된 모델에 를 입력했을 때 나온 마지막 tranformer block의 활성화 값
: linear output layer에서 과 곱해져 를 예측할 때 필요한 weight matrix
Objective function (maximization):
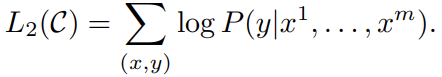
추가적으로! auxiliary objective (language modeling)을 추가해 (a) supervised model의 일반화 성능과 (b) 수렴 속도를 빠르게 해주었다.
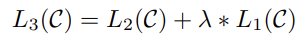
: weight of language modeling
→ fine-tuning 과정에서 추가로 학습해야 하는 파라미터는 와 delimiter token의 embedding밖에 없다!!
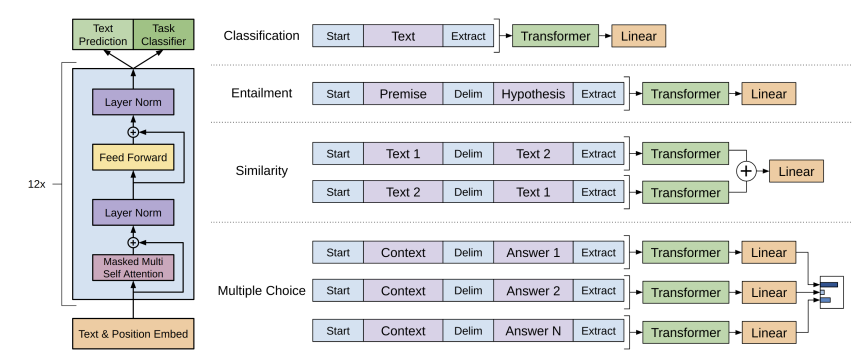
3.3 Task-specific input transformations
Fine-tuning 과정에서 어떤 task는 바로 fine-tune 시켜도 되지만 어떤 task(question-answering, textual entailment)에서는 특정 형태의 input 구조가 있어 바로 fine-tune시키면 안된다. (이전 연구들은 전이된 representation을 가지고 특정 task에 맞게 모델의 architecture를 수정했지만 이렇게 하면 새로 배워야하는 양이 너무 많아지고 추가된 구조적인 구성들은 전이가 되지 않는다는 문제가 있다.)
Pre-trained Model: contiguous sequences of text로 학습된 model
Traversal-style fine tuning: 특정 형태의 input 구조를 contiguous ordered sequence 형태로 변환해 우리의 pre-trained model이 이해할 수 있도록 해준다.
→ 특정 task마다 모델의 구조를 바꾸지 않아도 됨!!
(모든 transformation은 랜덤하게 초기화된 start/end token이 추가된다. (<>, <>)
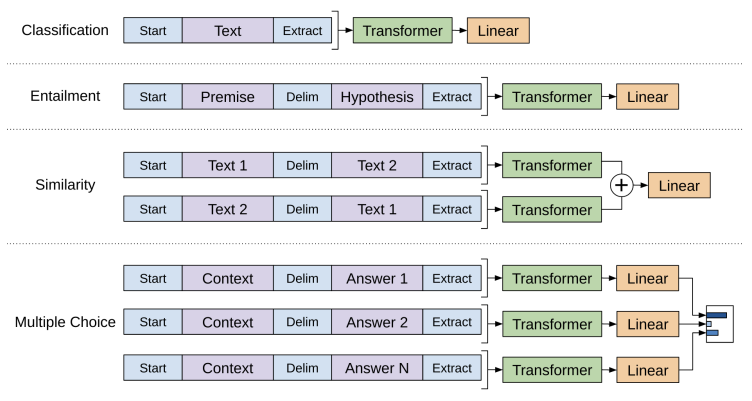
Delimiter Token ($) : 텍스트 사이의 구분자 역할을 하는 token
Textual Entailment
하나의 문장(전제)이 주어졌을 때 다른 문장이 그로부터 논리적으로 추론 가능하지 판단하는 task
Premise 와 hypothesis 를 이어붙이고 (concate) 그 사이에 Delimiter token ($)을 추가했다.
Similarity
두 문장의 유사도를 검증하는 task로, 두 문장 간의 순서가 학습에 의미가 없다. 그래서 모델이 가능한 순서를 반영한 두 가지 경우를 모두 포함시키도록 input sequece를 수정했다.
그리고 이 두 경우를 독립적으로 처리해서 두 개의 sequence representation인 이 만들어지고 이걸 element-wise로 더해준 후, linear output layer에 입력된다.
Question Answering and Commonsense Reasoning
context document 와, question , 그리고 가능한 answer 집합인 { }가 주어지는데 이걸 모두 이어 붙인다. 그때, delimiter token은 와 { } 사이에 들어가 input sequence는 [; ; $; ] 이런 형태를 가진다.
모델은 각 sequence는 독립적으로 처리하고 softmax layer에서 정규화한 후, 가능한 answers에 대한 output distribution을 생성한다.
📕 결론적으로, 본 논문에서 핵심적으로 소개한 내용은 (Unsupervised Pre-training + Supervised Fine-tuning) 방식의 semi-supervised 학습 방법이고 이를 통해, 여러 NLP 테스크에 대해 SOTA 성능을 달성했다.
논문 출처: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
