문제 상황
LM을 크게 만든다고 해서 사용자의 의도를 맞추는 것이 나아지지 않는다. 즉, LLM은 사용자에게untruthful, toxic, not helpful한 아웃풋을 생성할 수 있다. 이 맥락에서 모델은 사용자의 의도와 align하지 않다고 말한다. 이런 아웃풋을 생성할 수 있는 이유는 최근 여러 LLM에 사용된 언어 모델의 목적 함수는 "사용자의 지시문을 helpfully and safely 따라라"라는 목적을 포함하지 않기 때문이다. 이게 특히 문제되는 이유는 LM은 수백개의 application에서 배포되고 사용되기 때문이다.
본 논문에서 제안한 방안
LM의 아웃풋이 넓은 범위의 task에서 사용자 의도와 align될 수 있도록 "human feedback"을 사용한 fine-tuning 방식을 제안한다. (= RLHF)
여기서 사용자의 의도란,
1. explicit intention: following instruction
2. implicit intention: stay truthful/not being biased, toxic, and harmful
📌 RLHF: human preference로 reward를 주어 모델을 fine-tuning한다.
📝 RLHF 학습 순서
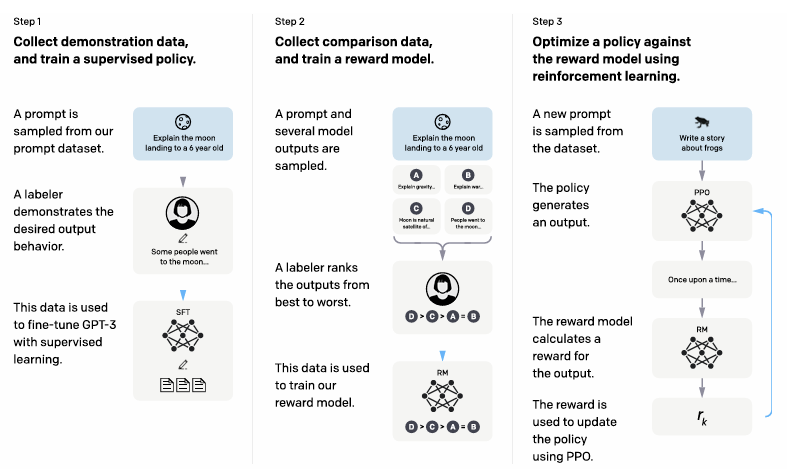
Step 1: Demonstration data를 수집하고 supervised policy를 학습한다
SFT 학습 단계
데이터 라벨링을 위해 40명을 screening test를 통해 고용한다.
OpenAPI에 제출된 prompt나 labeler가 작성한 prompt에 대해 모델이 내주길 바라는 desired output을 사람이 직접 작성하고 이를 모아 demonstration dataset을 만든다.
이 dataset으로 사용해 지도 학습으로 사전학습된 GPT-3를 fine tuning 해준다.
Step 2: Comparison data를 수집하고 RM을 학습한다
RM 학습
하나의 prompt에 대하 우리 모델이 생성한 여러 샘플을 비교한다. (Comparison data)
그리고 labeler가 output들의 순위를 매긴다.
이 dataset으로 RM을 학습시켜 human labeler들이 선호할 모델 output을 예측할 수 있도록 한다.
Step 3: 강화학습을 사용해 RM 모델을 policy에 대해 최적화한다
RM의 아웃풋을 scalar reward로 사용한다. 그리고 PPO로 reward를 최대화할 수 있도록 supervised policy를 fine-tune시킨다. 즉, supervised policy의 시작점인 SFT 모델을 점점 사람 취향에 맞는 policy로 바꿔가는 과정이다.
이론적으로 step 2와 step 3은 계속 반복될 수 있다.
1. 현재 가장 좋은 policy로부터 새로운 샘플을 생성
2. labeler가 그 응답들을 순위를 매겨 새로운 데이터 추가
3. 그 데이터를 이용해 새로운 RM을 학습
4. 그 RM으로 다시 policy를 PPO로 최적화
이 과정을 계속하면 점점 더 사람 선호를 잘 반영하는 policy 를 만들 수 있다.
그런데 실제 논문에서는 대부분의 comparison data는 SFT 모델로부터 얻는다. PPO policy에서 나온 샘플은 구하는데 비용이 많이 들어 SFT 모델 샘플을 더 많이 사용했다.
💻 Models
1. SFT (Supervised Fine-Tuning)
Labeler demonstration dataset으로 사전학습된 GPT-3를 fine tuning 한다.
실험 구성: 16 epochs, cosine learning rate decay, residual dropout of 0.2
2. RM (Reward Modeling)
RM의 목적: 사람이 어떤 응답을 선호할지를 예측하는 것
➝ "A와 B 중 사람이 A를 잘 고른다"라는 사건을 RM이 잘 맞추도록 두 보상값의 차이를 log odds로 해석해서 cross entropy로 학습한다.
SFT 모델의 마지막 unembedding layer를 제거한 후, 모델이 prompt와 response를 받았을 때 scalar 형태의 output을 내도록 한다.
RM은 하나의 인풋에 대해 두 개의 다른 output을 비교하며 훈련되다.
모델이 하나의 프롬프트에 대해 여러 응답 생성 후, 사람이 선호도에 따라 순위를 매긴다.
- 응답 개수: = 4 ~ 9
- 하나의 프롬프트로 부터 약 개의 comparison pair data가 생성된다. ()
❗여기서 문제
- 같은 프롬프트에서 생성된 comparison pair들은 서로 매우 correlated 되어 있어 이걸 전부 하나의 dataset을 뭉쳐 학습하면 한 번의 epoch만으로도 RM이 overfit될 수 있다.
그래서 이 문제를 해결하고자 프롬프트 단위로 묶어서 학습한다. 즉, comparison pair마다 RM을 매번 forward pass하지 않고 프롬프트가 생성한 응답 를 한 번에 모델에 넣는다. 그럼 RM은 각 응답에 대한 보상값을 를 한 번의 forward pass로 계산한다. 이제 이 개의 보상값으로부터 모든 pairwise loss를 동시에 만들고 이걸 다 더해 평균 낸다.
3. Reinforcement learning (RL)
이제 PPO를 사용해 SFT model을 우리의 환경(bandit environment)에 맞게 fine tuning한다.
Bandit Environment:
매번 프롬프트 하나가 주어지고 → 정책이 응답을 생성 → 에피소드가 바로 종료되는 단일 스텝 환경
1. PPO 학습
- SFT 모델을 초기화된 policy로 사용
- policy가 입력 프롬프트에 대한 응답 생성
- 생성된 응답을 RM에 넣으면 사람이 얼마나 선호할지에 대한 scalar reward가 나옴
- 추가로 token마다 KL penalty가 붙여서 reward만 쫓아가면서 SFT 분포로부터 너무 멀어지지 않도록 제약
- PPO로 policy 업데이트
- reward signal(RM 점수 - KL penalty)을 가지고 PPO 알고리즘으로 policy를 업데이트- 즉, 응답 확률을 보상을 높이는 방향으로 조정
2. PPO-ptx
- PPO만 학습할 경우, 일반 NLP 벤치마크 성능이 떨어지는 문제 발생
➝ 해결: PPO gradient에 pretraining gradient를 혼합 시킴 - 즉, 원래 언어모델링 목적도 일부 유지하여 catastrophic forgetting 방지
_
🎯 최종 목적 함수
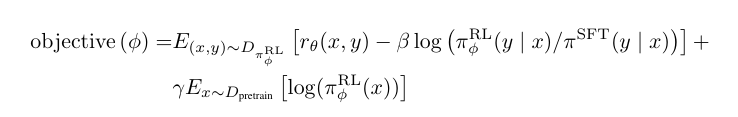
πRL : 학습된 RL policy
πSFT : Supervised Fine-Tuned policy
Dpretrain : pretraining 데이터 분포
β : KL penalty 계수
γ : pretraining loss 계수
📢 Evaluation: 모델이 얼마나 align한지에 대한 평가
본 논문에서의 Alignment란?
User intention과 일치하는 동작을 하도록 하는 것. User Intetion = Helpful, Honest, Harmless
Helpful 측정
➤ Human Labeler들이 평가 (instruction 뿐만 아니라 내재되어 있는 정보도 유추해야하므로
(다만, labeler들이 실제 prompt를 준 user가 아니므로 labeler들이 유추한 내용도 살짝 틀렸을 수도 있다.)
Honesty 측정
이걸 측정하려면 model의 output과 모델의 belief를 비교해야하는데 모델은 black box 모델이라 모델의 belief를 알 수 없다.
그래서 Honesty 대신 Truthfulness를 측정
➤ Closed domain task에서는 모델이 만들어내는 정보의 경향성을 평가
➤ TruthfulQA dataset으로 평가
Harmful 측정
output이 어느 곳에 쓰이는지에 따라 harmful한지 아닌지가 정해진다. 그래서 원래 사람이 ㅣ평가했는데 너무 많은 상황을 고려해야하므로 이 방식은 더이상 사용하지 않는다.
본 논문에서는
➤ 모델이 output이 사용자에게 도움되지 않거나, 취약층을 공격하거나 성적이고 폭력적인 문맥을 포함하는지 평가
➤ toxicity와 bias를 평가하기 위해 RealToxicityPrompts benchmark 사용
Evaluation on API distribution
InstructGPT가 사람 기준에서 GPT-3보다 실제로 더 좋은 응답을 내는지를 다양한 프롬프트 세트와 지표로 평가한 부분이다.
- 평가 세트: 학습에 안 쓴 프롬프트 + InstructGPT에만 유리한 프롬프트로 평가하지 않기 위해 API 고객 프롬프트(GPT-3 스타일) 추가
- 기준 모델: 175B SFT (성능이 중간 정도라 baseline으로 적합)
- 지표: 응답이 baseline보다 선호되는 비율 + 1–7 Likert scale 품질 점수
- 추가: 응답별 메타데이터도 함께 기록
Evaluation on public NLP datasets
- 평가 대상: 두 가지 유형의 공개 NLP 데이터셋 사용
- LM 안전성 관련: truthfulness, toxicity, bias 측정
- 전통적 NLP task에 대한 zero-shot 성능을 구함
- 추가 평가: RealToxicityPrompts 데이터셋으로 human evaluation 진행 → 모델 출력의 유해성 평가
📌 논문의 주요 발견
1. Labeler들은 주로 GPT-3의 output보다 InstructGPT의 output을 선호한다.
두 모델의 기본 구조는 GPT-3로 같지만 InstructGPT가 human feedback으로 fine-tune 됐다는 점만 다르다.
같은 파라미터 수를 가진 InstructGPT, GPT-3, few-shot prompted GPT-3 중 InstructGPT의 성능이 가장 좋았다.
성능 뿐만 아니라, InstructGPT 모델은 labeler에 따르면 더 적절한 output을 생성하고 instruction에 명시된 제한사항을 더 잘 지킨다.
2. GPT-3에 비해 InstructGPT의 trustfulness가 발전됐다.
TruthfulQA benchmark에 대해 GPT-3보다 InstructGPT의 결과가 2배 정도 더 truthful하고 informative했다.
Input에서 보이지 않은 정보에 대해서는 output은 생성하면 안되는 API prompt distribution으로부터 나온 "closed-domain" task에서는 InstructGPT가 GPT-3보다 절반정도 덜 input에 없는 정보를 지어냈다.
3. InstructGPT가 GPT3보다 toxicity는 좋아졌지만 bias는 아니다.
Toxicity 측정 benchmark dataset: RealToxicity Prompts에 대해서는 InstructGPT의 성능이 더 좋다.
그렇지만 Winogender, Crow&Pairs과 같은 bias benchmark dataset에 대해서는 GPT-3보다 발전이 없다.
4. RLHF의 사전학습 과정을 변형해 public NLP dataset에 대한 성능 regression을 낮출 수 있다.
RLHF 사전학습에서 SQuAD와 같은 특정 NLP dataset에서는 성능 저하가 있었음. 이는 alignment procedure를 했을 때 발생할 수 있는 비용이다. 여기서 나온게 PPO-ptx인데 뒤에서 더 설명하겠다.
5. 우리 모델은 training data를 구성할 때 포함되지 않은 "held-out" labelers에 대해서도 일반화 성능을 보였다.
일반화 성능을 비교하기 위해 우리는 held-out labeler에 대한 예비 실험을 진행했는데 그 결과 training labelers와 마찬가지로 InstructGPT의 output을 더 선호했다.
(그러나 이 분야에서는 더 많은 연구가 필요하다. 더 큰 group의 사람들의 input에 대한 모델의 성능과 일반적으로 선호되는 행동양식을 원치 않는 사람들의 input은 어떻게 처리할 것인지 등등)
6. Public NLP dataset은 LM이 어떻게 어떻게 사용하는지 반영하지 않는다.
FLAN과 같은 public NLP tasks는 여러 NLP task로 구성되어 있고, 각 task마다 자연어 instruction이 있다. API prompt distribution에서는 우리의 FLAN 모델이 SFT baseline 보다도 안좋았고 labeler들은 InstructGPT를 더 선호했다.
7. InstructGPT model은 RLHF fine-tuning distribution 밖의 instruction에서도 뛰어난 일반화 성능을 보였다.
8. 그럼에도 불구하고 InstructionGPT는 심플한 실수도 한다.
Discussion
Implications for Alignment Research
- 비용 대비 효율 ↑: RLHF로 alignment시키는 비용은 사전학습 모델 대비 매우 작다. 작은 비용으로도 모델 크기 100배 증가보다 더 효율적인 계산이 가능해진다.
- 일반화 조짐: InstructGPT가 supervise하지 않는 환경에서도 “following instructions”를 어느 정도 일반화할 수 있다. (단, 얼마나 확장되는지는 추가 연구 필요)
- 성능 저하(Alignment Tax) 완화: PPO-ptx로 전통 NLP 성능 저하를 대부분 줄일 수 있었다.
- 실사용 검증: 연구 아이디어를 실제 고객/프로덕션 환경에서 검증 → 무엇이 통하고 한계는 뭔지 피드백 루프 형성.
Who are we aligning to?
- 단일 “인간 선호”가 아님: 주로 영어권/미국이나 동남아권의 Labeler라 선호도의 상호 불일치가 27% 정도 존재한다.
- 연구자 영향: labeler 지침/인터페이스/질의 응답을 연구자가 설계한다. 이는 연구 조직의 가치가 간접적으로 반영된다.
- 고객 프롬프트 편향: 데이터는 OpenAI API 고객 프롬프트에 좌우된다. 이는 고객이나 최종사용자 가치와 불일치할 수 있다.
- 대표성 부족: 전 인구 집단을 대표하지 않다.
= 대안 제안: 집단별 조건부 정렬(조건부 프롬프팅/fine tuning) 로 다양성 수용하되, 누구의 선호를 반영/제외할지 사회적 결정 필요하다.
Limitation
- 방법론적 한계: 약 40명 내외 labeler, 영어 중심 데이터, 단일 label(비용 이슈) → 대표성/합의·소수자 가중치 설계 미흡.
- 모델 한계: 완전 안전/align하지 않다. output에 harmfulness/bias/toxicity가 존재할 수 있다.
