1. Introduction
Batch Normalization을 사용하면 아래와 같은 장점이 있다.
1. training time 감소
2. regularization 효과
❗그러나 Batch Normalization을 사용하며 아래와 같은 단점이 있다.
- RNN에서 BN을 사용하기 어려움
- RNN 같은 경우, sequence의 length에 따라 recurrent neuron의 개수가 달라진다. 그럼 time step마다 BN을 해줘야하므로 매 time step마다 통계치를 계산해줘야 한다.
- online learning task처럼 mini-batch의 크기가 1이거나 너무 작으면 BN을 사용할 수 없음
🎯 Batch Normalization의 이러한 문제를 해결하고자 본 논문에서는 Layer Normalization을 제안한다.
Layer Normalization
하나의 hidden layer에 입력되는 모든 input간의 평균과 분산을 계산해 input을 정규화해주자
본 논문에서 제안하는 Layer Normalization의 장점은 아래와 같다.
1. RNN에 효과적으로 적용할 수 있음
2. 학습 속도가 빨라짐
3. 일반화 성능이 좋아짐
3. Layer Normalization
"하나의 layer 안에서 평균과 분산을 고정시켜서 input을 정규화해주자"
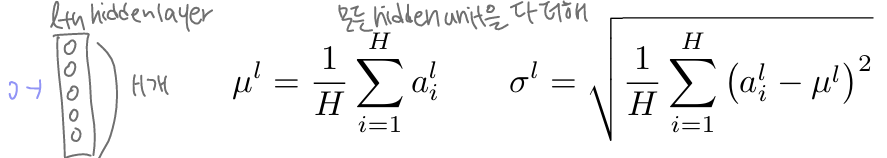
📢 LN과 BN의 다른 점:
1. LN은 BN과 달리 하나의 layer 내의 모든 hidden unit은 같은 평균과 분산을 공유한다.
2. LN은 BN과 달리 훈련 샘플끼리 다른 평균과 분산을 가진다.
📢 LN의 장점:
1. mini-batch size가 어느정도 커야한다는 BN이 가진 제한점이 없어져 batch size가 1인 online learning에서도 사용 가능하다.
2. RNN에도 적용 가능하다.
3.1 Layer normalized recurrent neural networks
❗RNN에 BN을 사용할 수 없는 이유:
- RNN에서는 mini-batch의 평균과 분산을 매 time step마다 추정해야 한다. 그런데 test sequence가 train에서 본 가장 긴 sequence보다 길어지면 길어진 time step에 대해서는 계산해둔 평균과 분산이 없어 BN을 해주지 못한다.
(BN은 일반적으로 train할 때 평균과 분산을 추정하고 test할 때 이 평균과 분산을 가져다 쓴다.)
➤ 즉, RNN에서 BN을 적용할 때 time 축이 추가돼서 발생하는 문제 - mini-batch내의 sequence 길이는 모두 제각각이니까 모든 sequnece를 제일 긴 sequence의 길이로 padding해서 맞춰줄 수 있다. 예를 들어, 제일 긴 sequence의 길이가 8이면 모든 sequnece의 길이를 8로 padding해준다. 이때 t=5이면 여러 개의 sample로 평균과 분산을 계산할 수 있지만 t=8일땐 padding된 값은 무효화돼서 1개의 sample만으로 mean과 variance를 구해야한다. 결국 BN으로 인한 효과가 미미해 학습은 불안정해진다.
📌 LN의 작동 방식 (RNN에서)
위의 식에서 하나의 샘플에 대해서면 평균과 분산을 계산한다. 즉, 샘플마다 독립적으로 정규화하므로 test 때 어떤 길이의 sequence가 들어와도 상관없다. 왜냐하면, 각 time step에서 LN을 해줄 때는 sequence 하나만 보면 된다.
➤ 모든 t마다 다른 평균과 분산을 가지는 것은 같지만 샘플별로 정규화해주므로 sequence 길이로 인한 문제는 없음
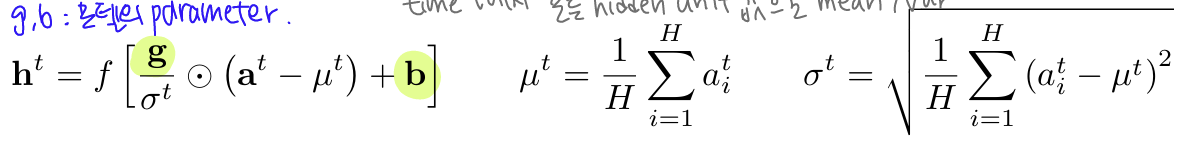
- 하나의 샘플에 대해, time t에서 모든 hidden unit 값을 가지고 평균과 분산을 구하고 이 값으로 time t에서의 input을 정규화한다.
: time t에서의 hidden state
: 모델의 parameter, 와 같은 차원을 가짐
: time t에서의 activation 값,
: layer의 hidden unit
LN으로 RNN의 고질적인 문제인 vanishing/exploding gradient 문제를 어느정도 완화시킬 수 있다. (이후에 더 자세히 설명할 것이다.)
5. Anaylsis
5.1 Invariant under weight and data transformations
비록 LN, BN, WN이 평균, 분산을 계산하는 방식은 서로 다르지만
공통적으로 뉴런에 들어가는 를 평균 와 분산 라는 두 스칼라를 이용해 정규화한다.
또한, 정규화 이후에는 각 뉴런마다 학습 가능한 bias 와 gain 를 추가로 학습한다.
🔹Batch Normalization:
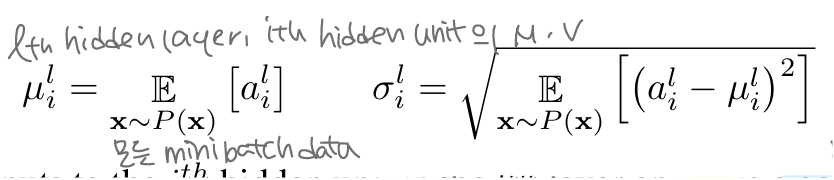
🔹Layer Normalization:
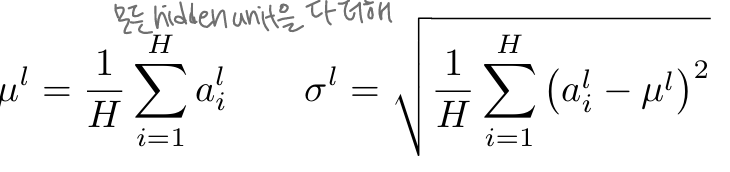
🔹Weight Normalization:
,
⭐ 세 가지 normalization에 대한 invariance 결과를 정리한 표:

Weight re-scaling and re-centering:
- Batch, Weight Normalization
- 하나의 뉴런 weight vector 에 대해 scaling이 일어나면 도 같은 비율로 scaling → 정규화 결과는 변하지 않음.
⇒ Weight Scaling에 불변- Layer Normalization
- 개별 weight vector scaling에는 invariant하지 않음
- 대신 전체 weight matrix scaling이나 모든 incoming weight에 동일한 shift 추가에는 invariant
⇒ 특정 변환(weight matrix rescaling, recentering)에 대해 출력이 동일
Data re-scaling and re-centering:
- 모든 Normalization
- 데이터셋 전체를 scaling해도 뉴런 입력은 변하지 않음 → invariant
- Layer Normalization
- 개별 데이터 포인트 를 상수배 해도 () 평균과 분산이 함께 scaling되므로, 최종 출력은 그대로 유지됨
- ⇒ 개별 샘플 re-scaling invariant
- Batch Normalization
- 데이터셋 전체를 re-centering(shift) 및 re-scaling 모두 invariant
5.2 Geomettry of parameter space during learning
지금까지 모델 예측이 파라미터의 re-centering 및 re-scaling을 해도 invariant하다는 것을 살펴보았다. 그러나 학습 과정은, 비록 모델이 invariant한 값을 출력하더라도, 파라미터화(parameterization)의 방식에 따라 매우 다르게 동작할 수 있다.
이 절에서는 파라미터 공간의 기하(geometry)와 매니폴드(manifold) 관점에서 학습 동작을 분석한다. 본 논문에서는 normalization scalar가 learning rate을 암묵적으로 줄여주고, 그 결과 학습을 더 안정적으로 만든다는 것을 보여준다.
5.2.1 Riemannian metric
- 파라미터 공간 = 리만 매니폴드 (출력 분포 간 KL divergence로 정의)
- Riemannian metric: 접공간에서의 무한소 거리, 파라미터 변화 → 출력 변화량을 측정
- Amari (1998): KL 기반 계량은 2차 근사로 Fisher Information metrics로 표현 가능
- 수식:
- 파라미터 공간의 기하학적 시각을 통해 정규화 기법이 학습 안정성에 기여하는 원리를 이해할 수 있다
5.2.2 The geometry of normalized generalized linear model
- GLM: Exponential family를 기반으로 로 파라미터화되는 확률모델
- 출력 특성
- 기대값:
- 분산:
- 다차원 출력 GLM의 Fishe information metrics
- 출력 공분산 × 입력 특징의 Kronecker product로 표현됨
- 정규화를 적용한 경우
- 입력 합 를 평균/분산으로 정규화
- 추가적인 gain parameter 를 도입
- 결과적으로 정규화된 FIM 는
출력 공분산, 정규화된 입력, gain 파라미터를 반영하는 블록 행렬 구조로 표현됨
Implicit learning rate reduction through the growth of the weight vector
정규화된 GLM의 Fisher information 행렬 블록 gain 파라미터와 정규화 스칼라에 의해 scaling 된다. 가 커져도 출력은 동일하지만, Fisher information metrics의 곡률은 변한다.
→ 가 2배면 곡률은 절반
따라서 weight normalization은 사실상 learning rate의 크기를 조절할 수 있다. weight normalization이 커지면 방향을 바꾸기 어려워져서, 정규화 기법이 implicit early stopping 효과를 낸다.
Learning the magnitude of incoming weights
정규화된 모델에서는, 들어오는 weight의 크기가 gain 파라미터로 명시적으로(parameterize) 표현된다. 저자들은 학습 과정에서, 정규화된 GLM에서 gain 파라미터를 업데이트하는 경우와, 원래 파라미터화된 모델에서 weight 크기를 직접 업데이트하는 경우를 비교해 보았다.
- 표준 GLM: weight 크기 방향의 Riemannian metrics이 입력 크기(norm)에 의존
- BN / LN 모델: gain 파라미터 학습은 예측 오차의 크기에만 의존.
⇒ Normalize된 모델은 입력 스케일 변화나 파라미터 크기 변화에 더 robust하다.
