논문을 파도타며 리서치하다보니 찾은 논문입니다. 제가 생각하는 연구 주제의 방향성과는 약간 다르지만 인사이트를 얻을 수 있을 것 같아 선정했습니다.
나는 언제쯤 연구 주제를 찾을 수 있을까! (●´⌓`●)
지금까지 읽었던 논문들과는 달리
reward를 self로 준다는 점이 특징적입니다.
지금은 구조에 대해서만 간단히 설명하고 추후에 논문 전체에 대해 리뷰하겠습니다.
방법론의 구조는 아래와 같습니다.
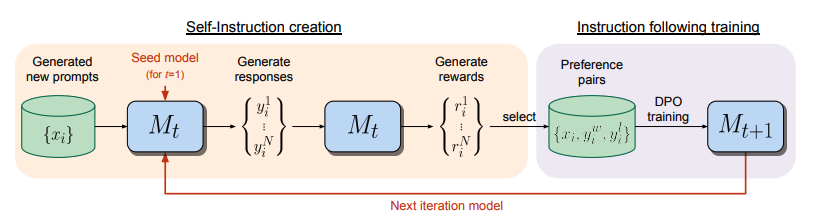
위 구조에서 알 수 있듯이 prompt, response, reward를 생성하는 self-instruction creation과 생성된 pair를 기반으로 DPO를 진행하는 instruction following training 단계로 나누어져 있습니다.
각 단계는 아래와 같은 흐름으로 구성됩니다.
Self-Instruction creation
1. Generate a new prompt
2. Generate a candidate responses
3. Evaluate candidate responses (Generate rewards)
Instruction following training
1. Preference building
- 높은 score -> chosed
- 낮은 score -> rejected
➡️ (x, chosen, rejected) pair 만듦
- 위 pair로 DPO 진행
- DPO loss를 최소화하도록 fine-tuning
- Evaluate
➡️ 2-3 반복

얼렁뚱땅 요리조리