Paper
1.논문 리뷰(1) MM-RLHF: The Next Step Forward in Multimodal LLM Alignment

Multimodal Large Language Model에 RLHF를 적용해 기존의 한계점들을 보완한 MM-RLHF에 대해 정리하겠습니다. MM-RLHF-Dataset, MM-RLHF-Reward Model, MM-DPO를 다뤄보겠습니다.
2.논문 리뷰(2) Critique-out-LOUD Reward Models

오늘 리뷰할 논문은 Critique-out-LOUD Reward Models입니다! 저번에 읽었던 논문 MM-RLHF: The Next Step Forward in Multimodal LLM Alignment과 Reward Modeling 측면에서 유사합니다. 따라서
3.논문 리뷰(3) You Only Look Once: Unified, Real-Time Object Detection
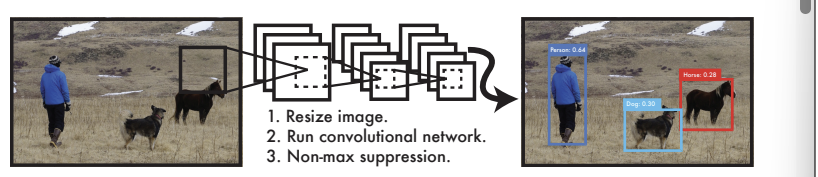
오늘은 아주 유우명한 객체 탐지(object detection) 분야의 논문을 읽어보겠습니다. 바로 YOLO입니다!오늘도 Abstract부터 읽어보겠습니다.논문에서는 "한 개의 신경망이 한 평가에서 전체 이미지를 기반으로 bounding boxes를 예측 ➡️ 클래스
4.논문 리뷰(5) U-Net: Convolutional Networks for Biomedical Image Segmentation
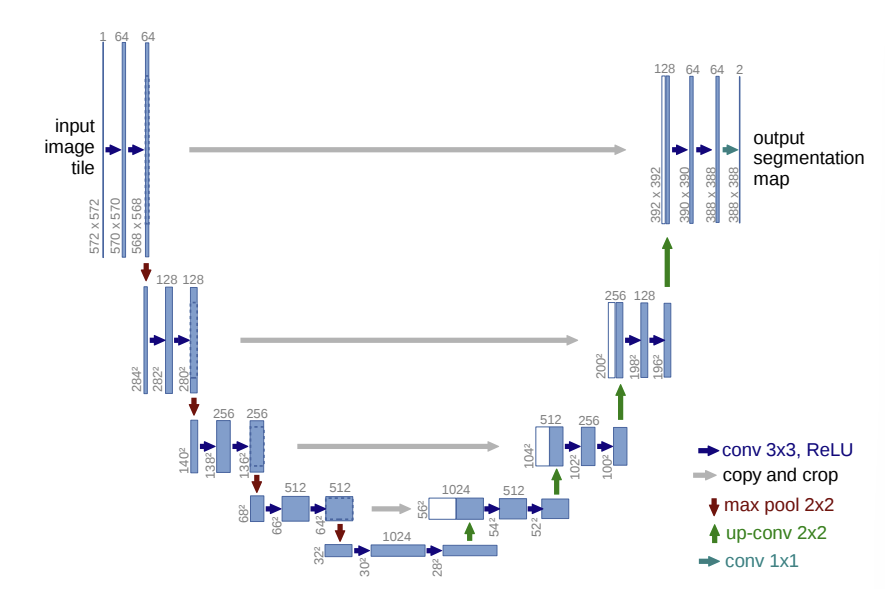
이번주 CV스터디 논문은 U-Net입니다. Segment의 기초 논문 중 하나이기에 꼼꼼하게 다뤄보도록 하겠습니다!본 논문에서는 data augmentation에 기반한 네트워크와 training strategy를 제시함구조는 contracting path & symm
5.논문 리뷰 (4) Self-Generated Critiques Boost Reward Modeling for Language Models
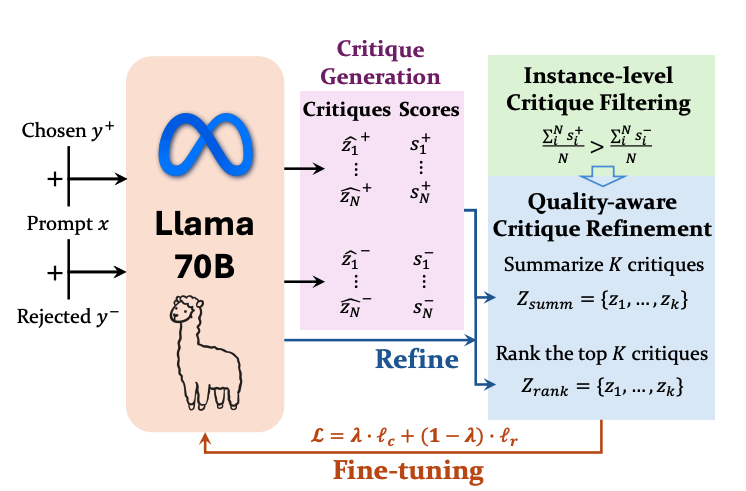
오늘 다룰 논문은 [Self-Generated Critiques Boost Reward Modeling for Language Models](https://arxiv.org/pdf/2411.16646)입니다. 2025년 4월에 NAACL에 publish된 논문입니다.
6.논문 리뷰 (6) Self-Rewarding Language Models
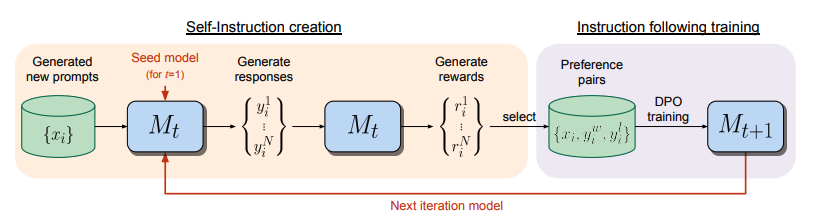
논문을 파도타며 리서치하다보니 찾은 논문입니다. 제가 생각하는 연구 주제의 방향성과는 약간 다르지만 인사이트를 얻을 수 있을 것 같아 선정했습니다. 나는 언제쯤 연구 주제를 찾을 수 있을까! (●´⌓`●)
7.논문 리뷰(7) Self-Evolved Reward learning for LLMs
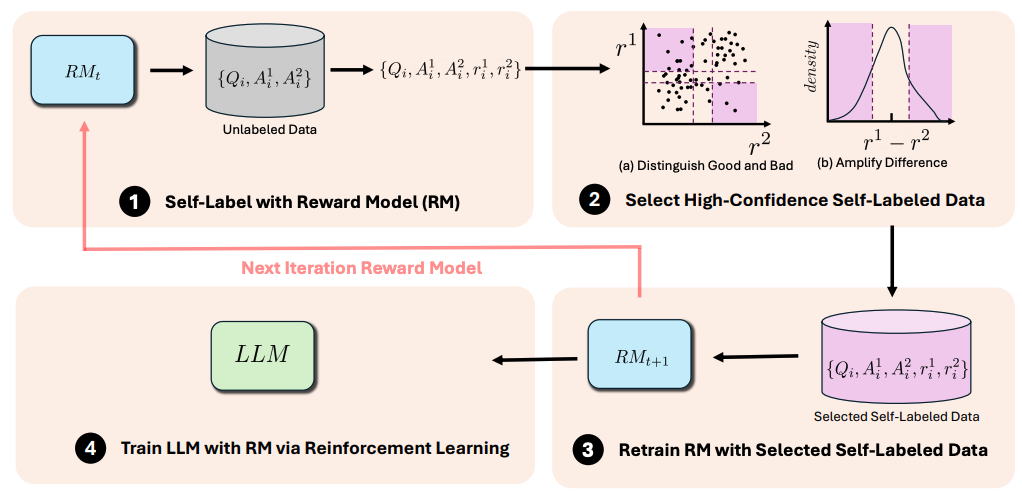
요즘 RLHF의 분야에서 human preference 데이터의 한계를 뛰어넘고자 하는 self-evolve 아이디어가 많이 나오는 것 같습니다. 오늘 읽어볼 Self-Evolved Reward learning for LLms도 유사한 맥락입니다. (참고로 이 논문은
8.논문 리뷰(8) TTRL: Test-Time Reinforcement Learning
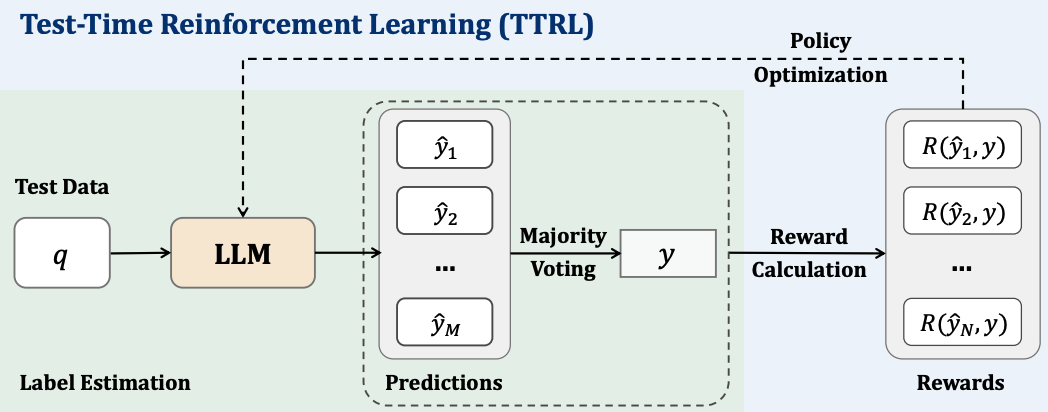
이번에는 TTRL: Test-Time Reinforcement Learning