
1. Introduction
- ImageNet : 1500만장의 이미지와 22000가지의 카테고리가 레이블된 데이터 셋
- 기존 MLP기법의 기술적 한계 존재 → 데이터 셋이 커짐에 따라 큰 용량의 모델 필요
- LeNet같은 기존 CNN기술이 존재 하였지만 모델 활용에 있어 비용 문제가 큼
- GPU활용과 오버피팅을 방지하기 위한 새로운 방법을 고안함으로써 기존 문제들을 어느 정도 해결
2. The Dataset
- ImageNet : 1500개의 이미지와 22000개의 카테고리가 레이블된 데이터셋
- ILSVRC에서는 ImageNet의 부분집합 1000가지 카테고리를 사용
- 학습 데이터는 약 120만 장, 검증 데이터는 5만 장, 테스트 데이터는 15만 장으로 구성
- Input Image size → 256x256 CenterCrop(가로/세로 중 작은쪽을 256픽셀로 줄여서 중심을 기준으로 리사이즈)
3. The Architecture
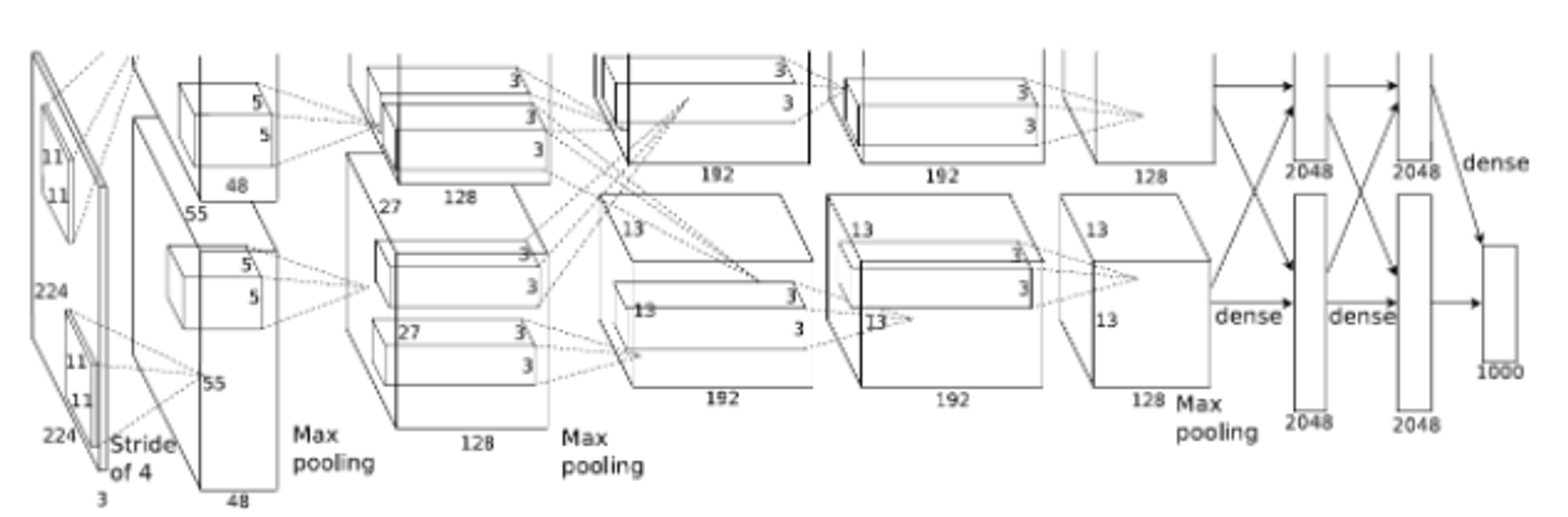
5개의 convolutional layer와 3개의 fully connected layer로 총 8개의 layer로 구성
(각 layer의 자세한 구조는 참조 https://deep-learning-study.tistory.com/376)
1) ReLU Nonlinearity
- 일반적인 활성함수(tanh or sigmoid)는 학습할 때 saturated되어 학습 속도를 매우 저하시킴
→ saturated : loss가 0인 최적의 w값을 찾는 과정에서 w값의 변화가 없어지는 시점 (기울기가 0이 되는 시점)
- 앞선 문제점을 개선한 non-saturating nonlinearity로 ReLU를 사용
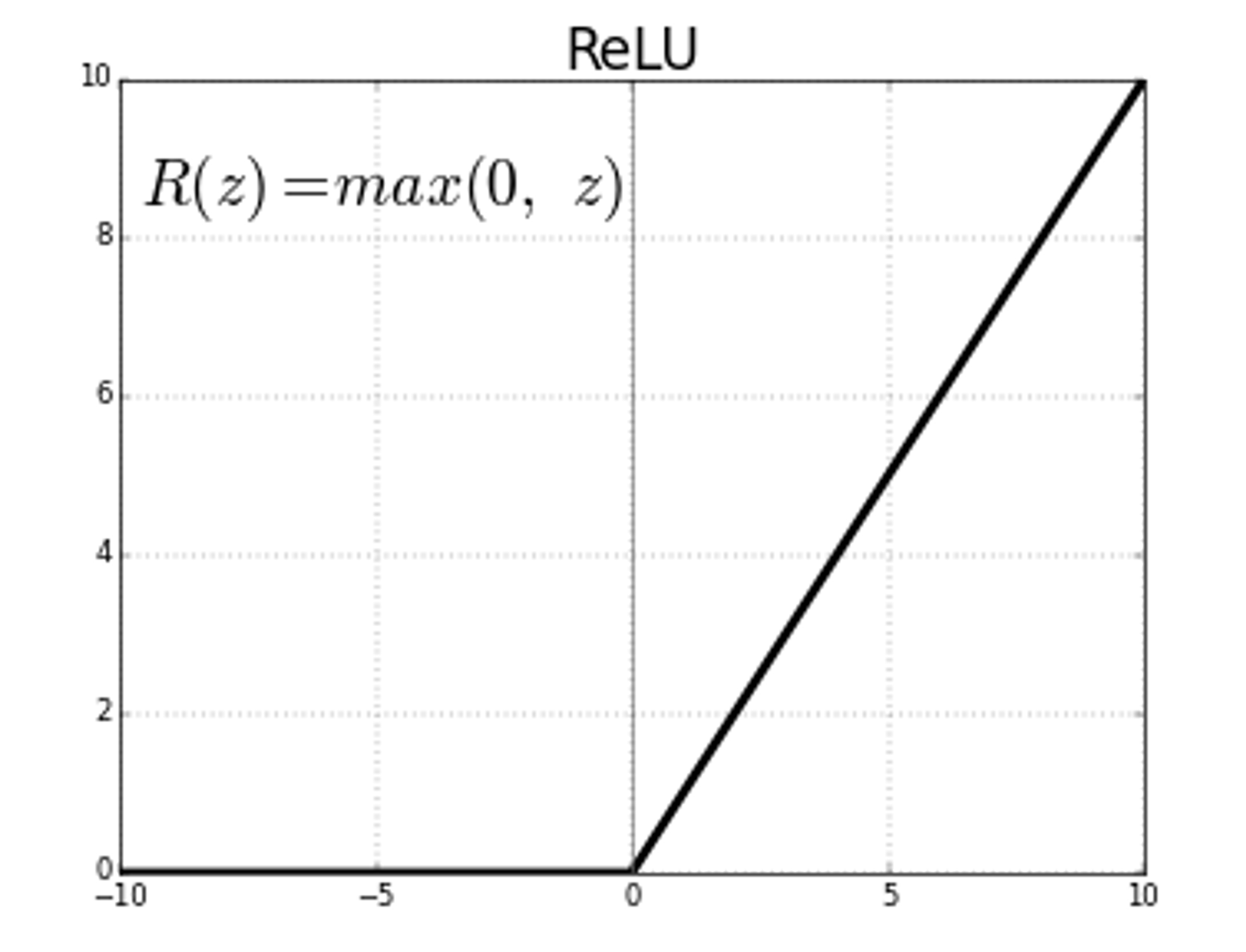
0미만의 값은 출력 x, 0이상인 경우 값 그대로 출력 → saturation문제 해결
2) Training on Multiple GPUs
- 하나의 network를 두개의 GPU에 나눠서 학습 → 처리 시간도 감소, error rate도 줄어듦
3) Local Response Normalization(LRN)
- LeLU특성은 양수 값을 받으면 그 값을 그대로 출력. 그러나, 너무 큰 값이 전달된다면 주변의 낮은 값에 영향을 미쳐 그 값들 또한 커질 수 있다.
→ 사람을 판단하는데 눈이 가장 큰 요소인 경우 눈에게 큰 가중치를 부여, 하지만 눈 근처 코 부분 또한 큰 가중치가 부여되어 사람을 판단하는데 오류가 발생할 수 있다.
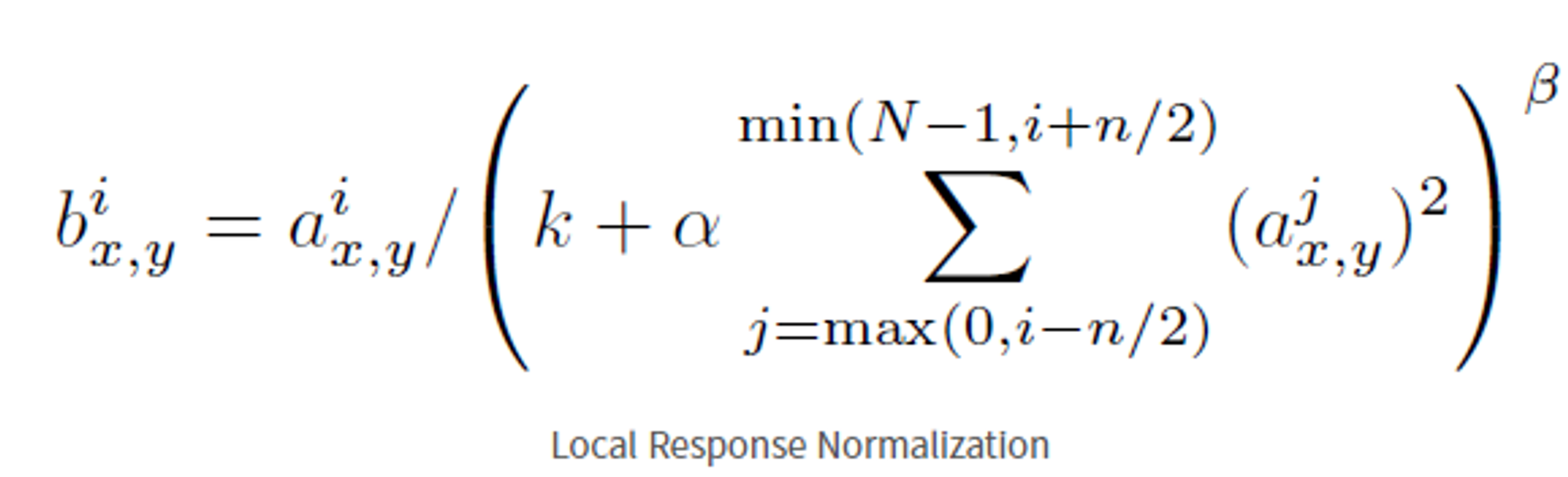
위 식을 통해 convoltion layer를 통과한 값을 normalization하여 큰 값을 축소시킴 (k, n α, β는 hyperparameter → 가장 최소화할 수 있도록 값 조정)
4) Overlapping Pooling
- 일반적으로 pooling layer에서 pooling의 중복을 허용하지 않음
→ pooling layer의 커널 사이즈를 z, stride를 s라고 할 때, s=z이면 보통의 overlap하지 않는 pooling layer
- 본 논문에서는 z=3, s=2로 하여 overlapping pooling을 구성
5) Overall Architecture
- The Architecture 에서 제공한 사이트 참조
4. Reducing Overfitting
1) Data Augmentation(데이터의 수를 증가)
- CPU를 통하여 진행하기 때문에 GPU의 계산비용을 방해하지 않음
- Image translation & horizontal reflection : 256x256 이미지를 224x224 크기로 Crop(중앙, 좌측 상단, 좌측 하단, 우측 상단, 우측 하단)
→ crop으로 생성된 5개의 이미지를 horizontal reflection → 하나의 이미지에서 10개의 이미지 생성
- altering intensities of RGB channels in training images : training set 이미지의 RGB에 PCA를 진행 → RGB색상에 대한 eigenvalue값 찾기
→ eigenvalue + 평균 0, 분산 0.1인 가우시안 분포에서 추출한 랜덤변수의 곱 + RGB값
2) Dropout(train set)
- 은닉층의 뉴런에서 발생하는 출력을 50%의 확률로 사용하지 않는 것
- dropout된 뉴런들은 다음 연산에 사용되지 않음 → 매번 다른 arcnitecture가 생성 → 뉴런에 의존한 결과값의 출력을 방지
- test set의 경우에는 적용 x , 그러나 모든 뉴런 결과값에 0.5를 곱함
- 두 개의 fully connected layer에만 dropout을 적용
- 결과적으로 overfitting을 피할 수 있었음
5. Details of learning(hyper parameter)
- AlexNet은 momentum=0.9, batch size=128, weight decay=0.005로 설정한 SGD(stochastic gradient descent)를 이용

- weight 초기화는 평균 0, 분산 0.01인 가우시안 분포를 이용
- bias 초기화는 Conv2,4,5와 FC layer에서는 1로, 나머지 layer에서는 0으로 초기화
- learning late는 0.01로 초기화 시켰고 validation error가 상향되지 않으면 10으로 나눠줌
6. Result
2010년도 ILSVRC대회 요약표Top-1 error / Top-5 error : 이미지 분류 성능을 평가하기 위한 것
→ 고양이, 강아지, 집, 축구공, 사자 → 0.1, 0.6, 0.05, 0.05, 0.2. then, top-1 class는 {강아지} , top-2 class는 {강아지, 사자} , top-5 class는 {강아지,사자,고양이,집,축구공}
→ Top-1 error : Top-1 class 중에 실제 강아지가 없을 확률
→ Top-5 error : Top-5 class 중에 실제 강아지가 없을 확률
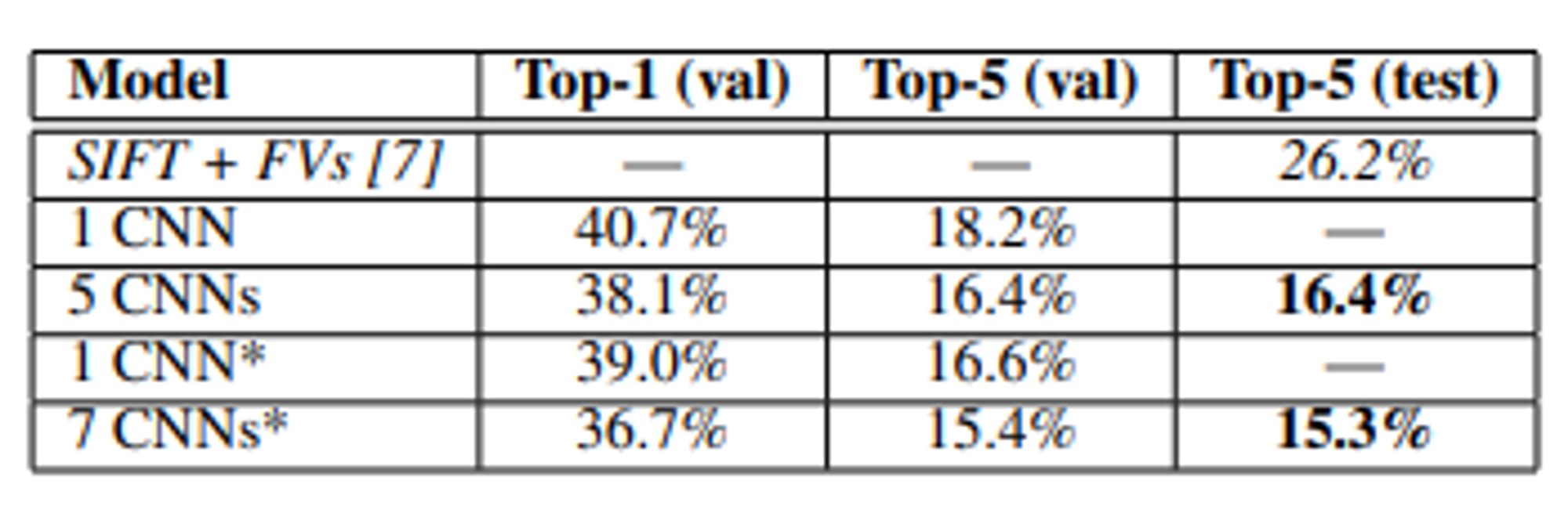
1 CNN : 본 논문에서 설명된 모델
1 CNN* (6번째 컨볼루션 레이어를 추가한 CNN 모델) - pre-trained된 모델로 ILSVRC-2012 dataset을 fine-tuning한 결과
5 CNN* : 5개의 CNN으로 pre-trained된 모델

- 물체가 중간에 있지 않아도 detection이 용이함
- Euclidean distance를 계산하여 거리가 짧을수록 유사한 사물로 인지함
- 은닉층에서의 이미지 분류방식에 대해 성과를 보임
- 그.러.나 2012년 때라 GPU성능이 좋지 않은 한계점 존재
