1. Introduction
-
NLP분야에서 뛰어난 성능을 가진 Transformer 구조를 CV분야에 적용해보자! 하지만 ...
- CV의 경우 시각적 객체들이 서로 다른 scale을 갖는다. 그러나 기존 ViT모델의 경우 고정된 scale로 접근하기 때문에 성능이 떨어진다.
-> detection하려는 물체는 이미지 내에서 특정 부분에만 존재함. 특정 부분을 제외하면 중요도가 낮으니까 전체 scale을 고려해줄 필요가 없다는 의미 - 고해상도 이미지의 경우 연산량이 n^2으로 증가하여 학습에 굉장한 시간과 비용이 든다.
-> What is Transformer(self-attention)? https://wdprogrammer.tistory.com/72
- CV의 경우 시각적 객체들이 서로 다른 scale을 갖는다. 그러나 기존 ViT모델의 경우 고정된 scale로 접근하기 때문에 성능이 떨어진다.
-
위 문제점을 극복하기 위해 Swin Transformer는 Shifted Window개념을 통해 다양한 scale을 살필 수 있는 계층적 구조로 만들었다. (마치 FPN구조)
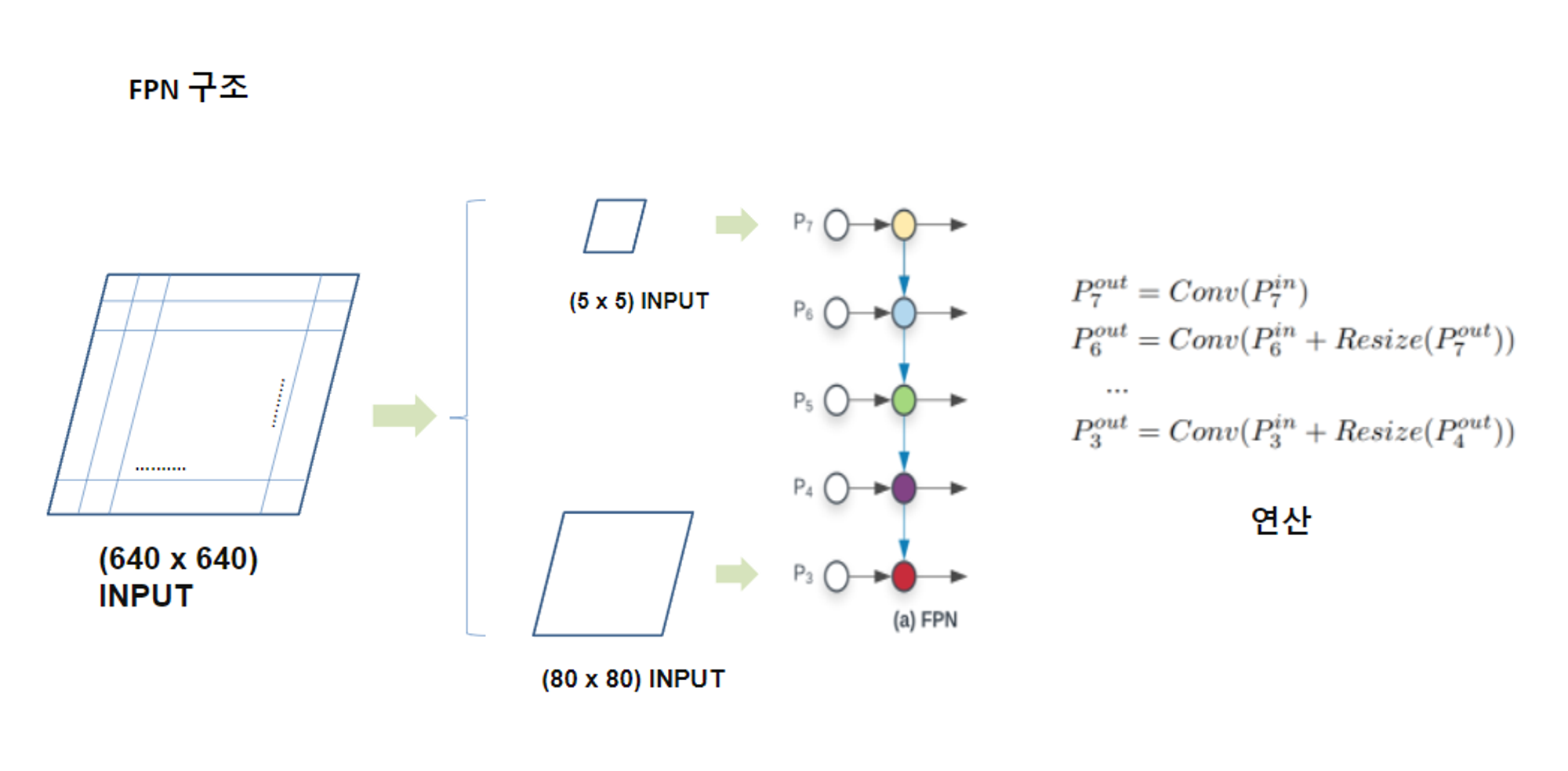
1. small-size patch 부터 점점 병합을 통해 큰 patch-size까지 확인
2. patch들 간에만 Self Attention을 계산하는 방식2. Patch Partition & Merge
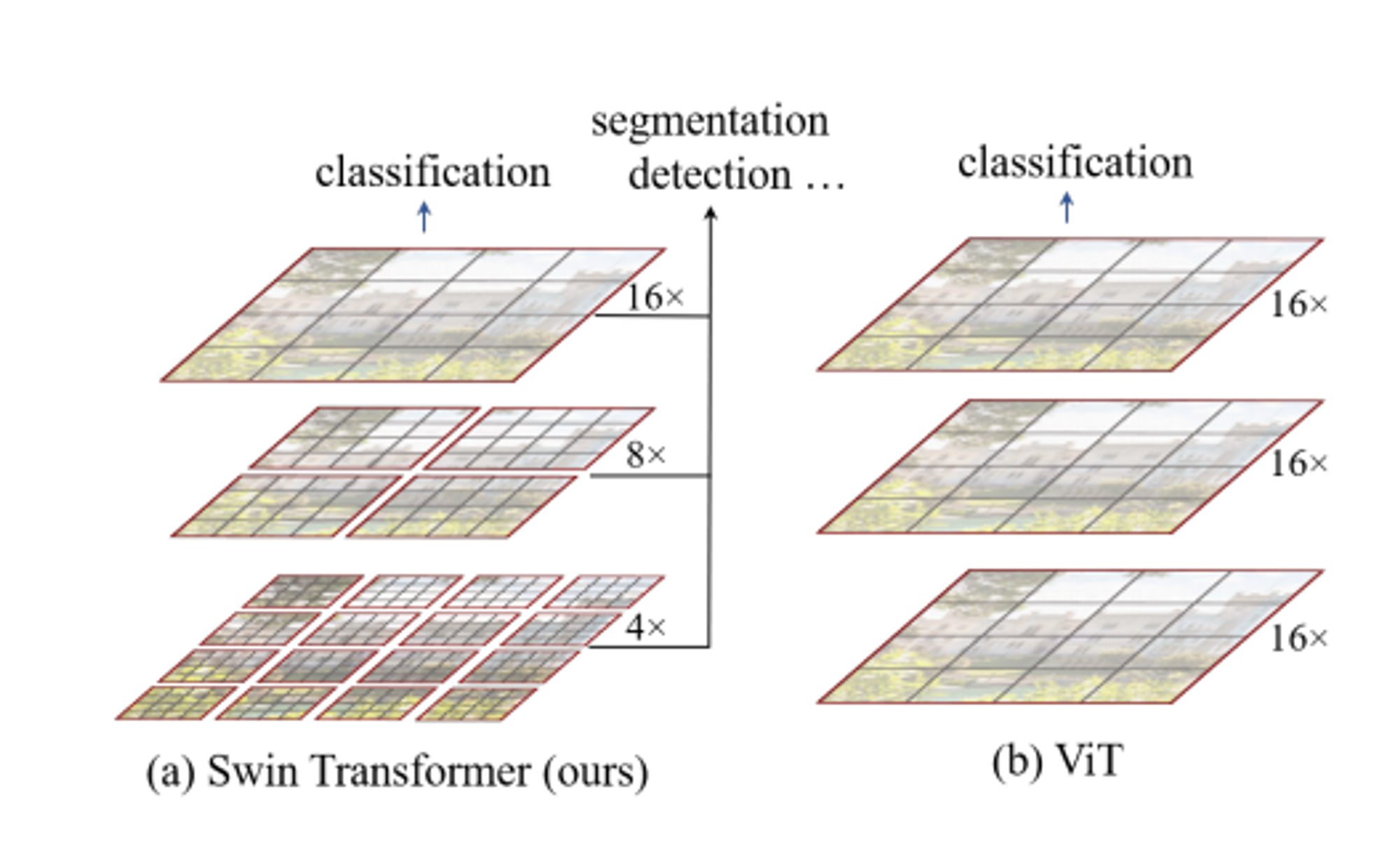
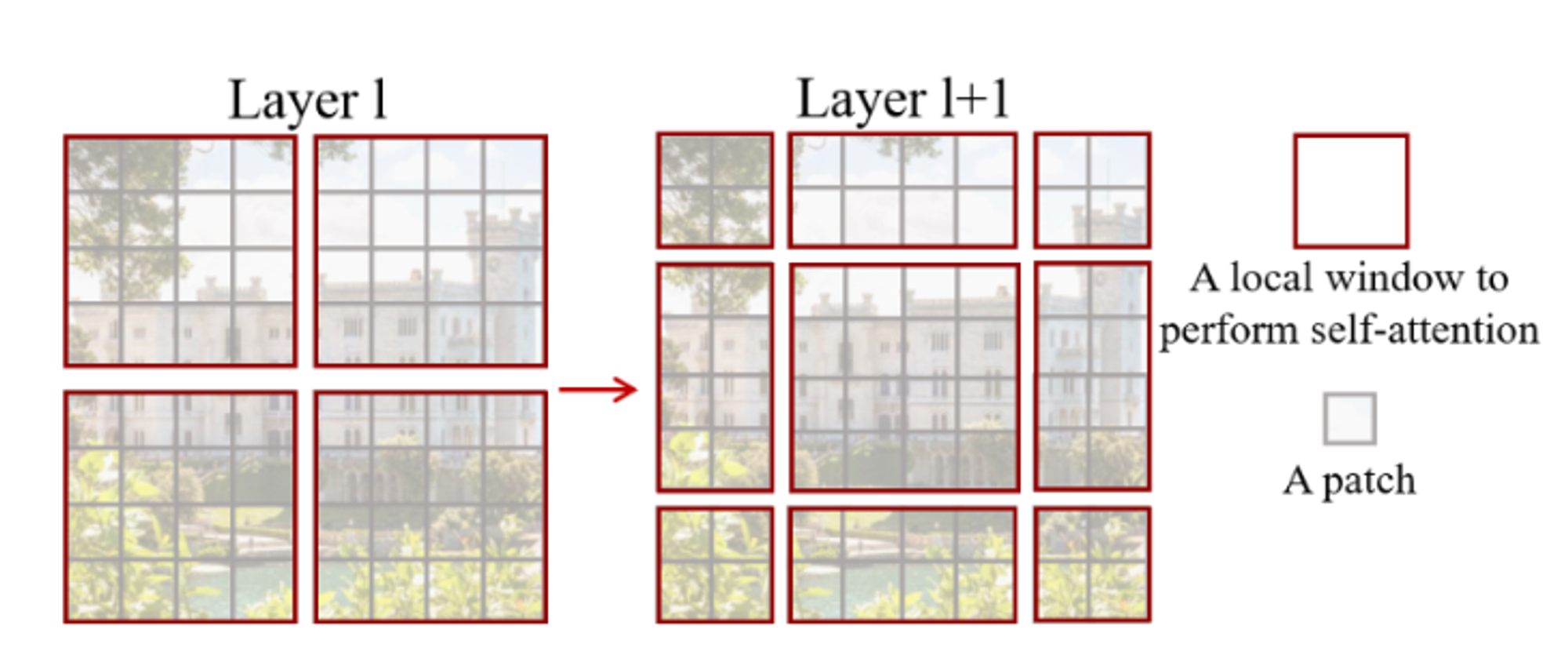
- 작은 크기의 patch 안에서만 self-attention을 수행 (논문에서는 7x7 image input)
- layer를 통과하면서 인접한 patch들을 점점 합치면서 계산 → 계층적인 정보를 활용 가능(like FPN)
- patch수가 고정 되어있기 때문에 이미지 크기에 선형적으로 비례하는 계산량만 필요(4K image도 거뜬)
W-MSA SW-MSA-
W-MSA의 경우 window 내부에 있는 patch들끼리만 self-attention을 수행된다.
-
SW-MSA는 shifted된 window에서 self-attention을 수행하여 고정된 위치뿐만이 아니라 여러 영역에서의 self-attention이 수행된다.
→ 위의 예시를 기준으로 W-MSA는 4개의 window에서 self attention을 각각 수행하고, SW-MSA는 9개의 window에서 self attention을 각각 수행
긍까 ViT처럼 고정적인 패치에대한 연산을 수행하는게 아니라 이미지를 shift & merge 하고 그 결과를 반영해서 다음 스텝으로 넘어가니까 detection하는데 있어서 더 잘된다고 함 (기억나실진 모르겠지만 efficientdet에서 weighted feature fusion처럼 이전 결과값과 현재 노드의 값에 대해서 중요도(weight)를 반영해서 다음 노드값을 연산하면 성능이 더 뛰어난것 처럼)
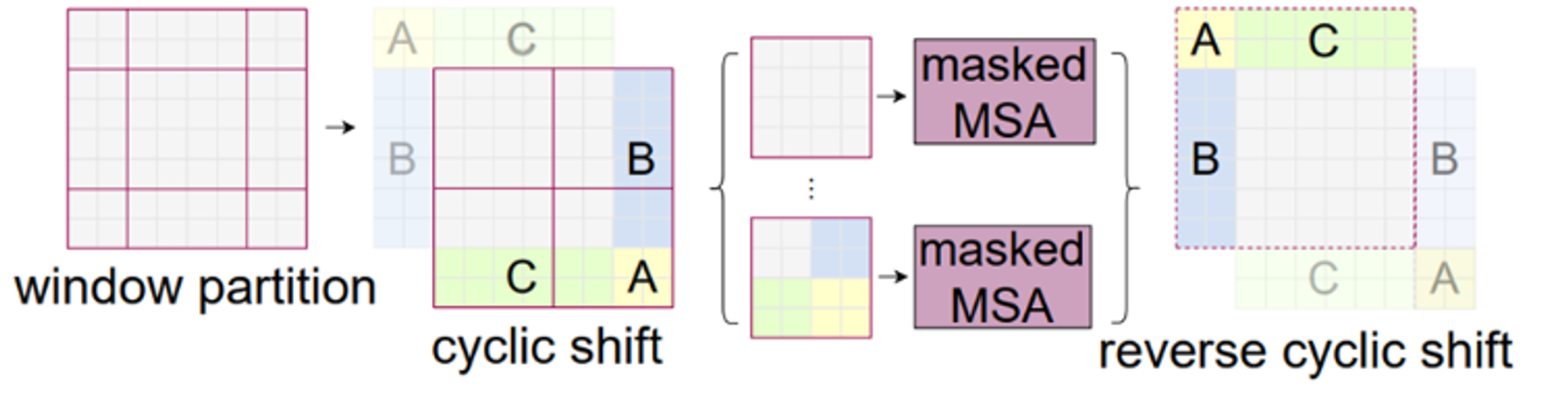
SW-MSA Cyclic Shift- 예시 디그다 회전
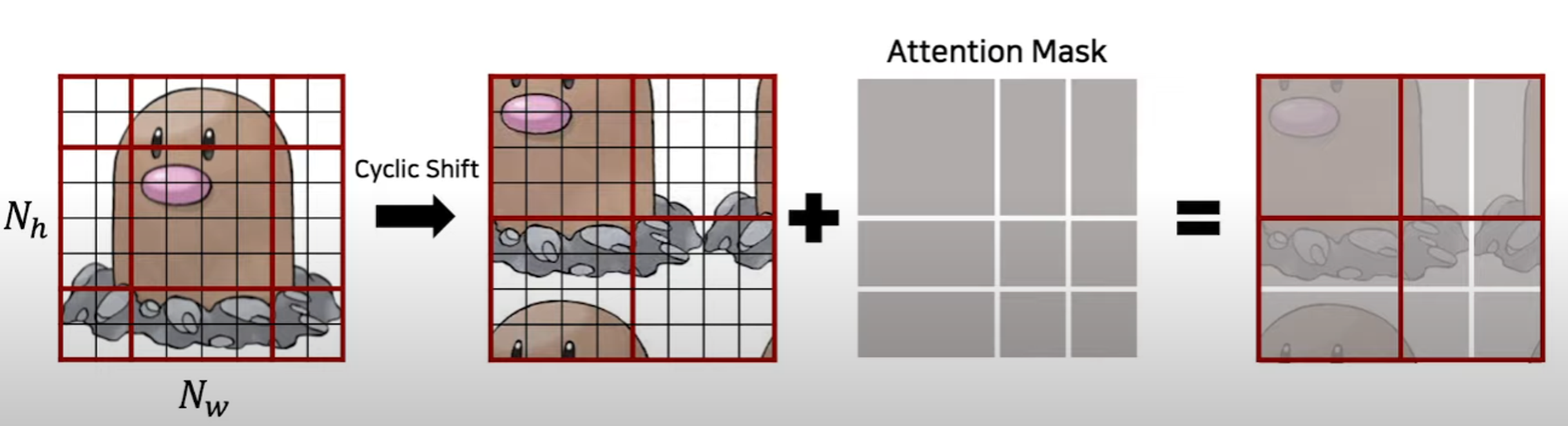
- 윈도우를 window size//2 만큼 우측 하단으로 이동(좌측 상단의 A, B, C 구역을 우측하단으로) 그리고 4개로 나누어진 window 에서 각각 self attention을 수행하는데 2사분면의 window 를 제외하고는 이미지들이 연결된 부분이 아니기 때문에 각각 다른 mask를 씌워서 연결된 patch들간의 self attention을 수행한다.
3. Method
- 종류 Swin-Transformer( Tiny, Small, Big, Large) version / 아래는 Tiny version
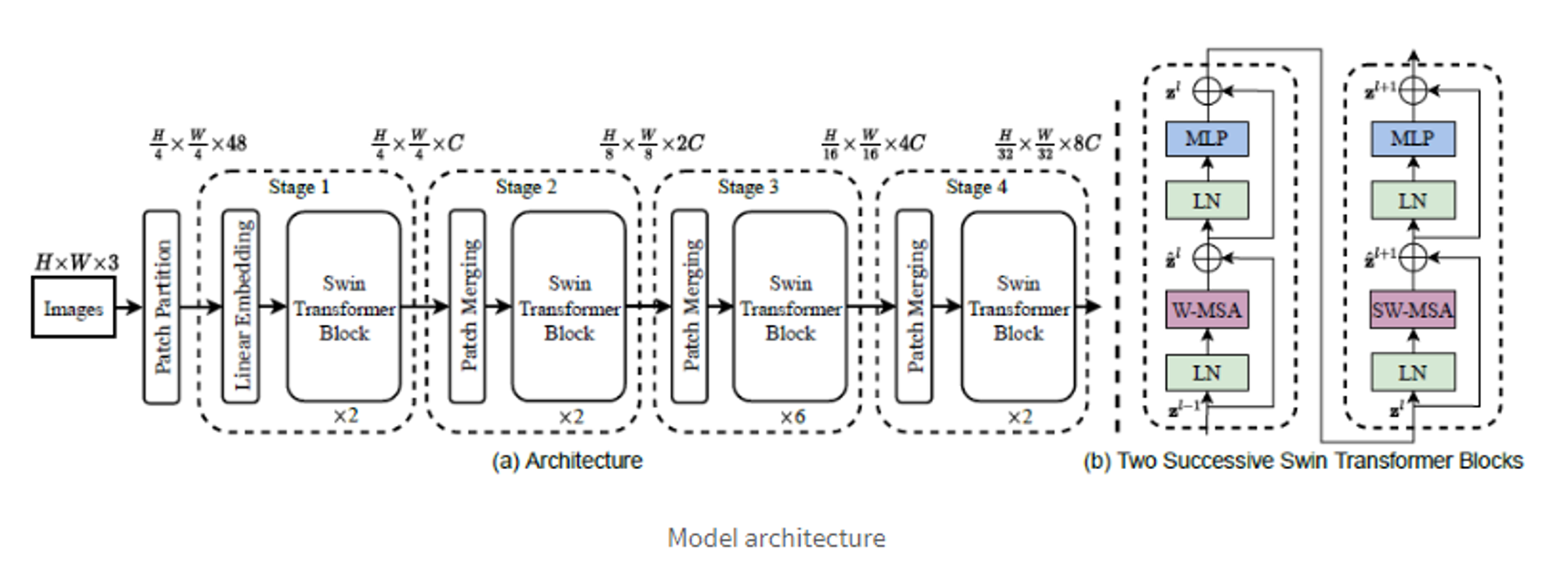
1. Images → Patch Partition
이미지를 4x4x3 patch size (16pixel, RGB) 로 나눔 → 이는 NLP token같은 역할(문장들을 형태소 단위로 분리한 느낌)
2. Linear Embedding
4x4x(C/16) size → channel차원 증가(C는 사용자가 정의함)
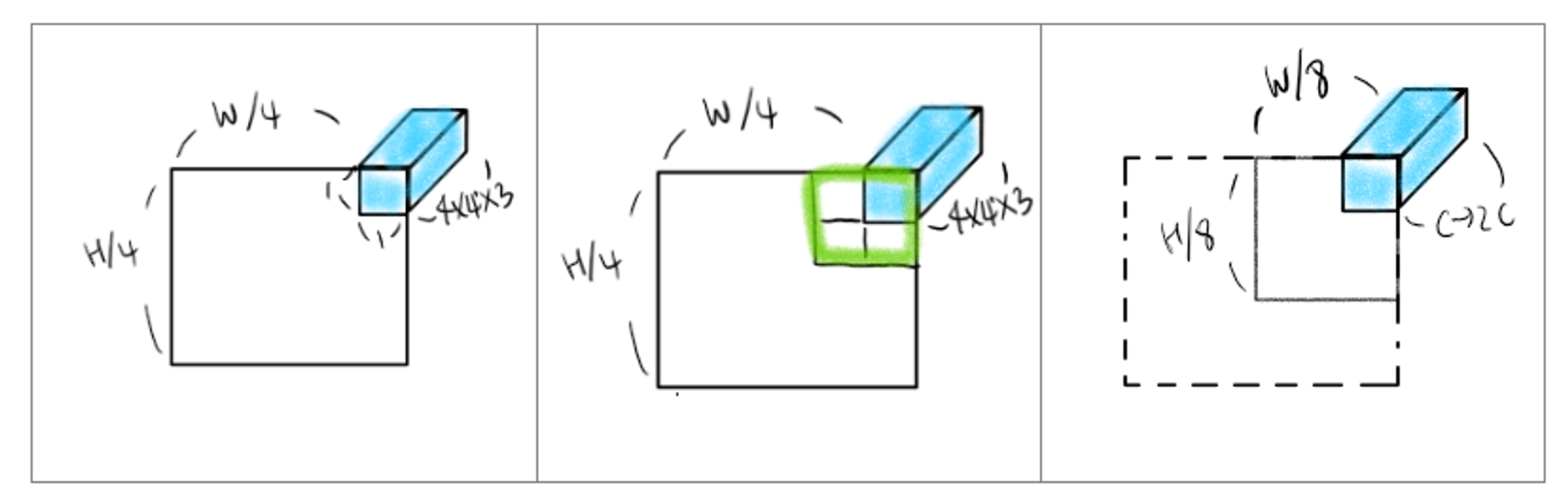
3. Patch Merging & Swin Transformer Block
2x2개씩 patch들을 합치며 채널수를 2배로 늘림
→ transformer block에서는 W-MSA & SW-MSA 두 과정 연속적으로 진행
4. Experiments & Conclusion
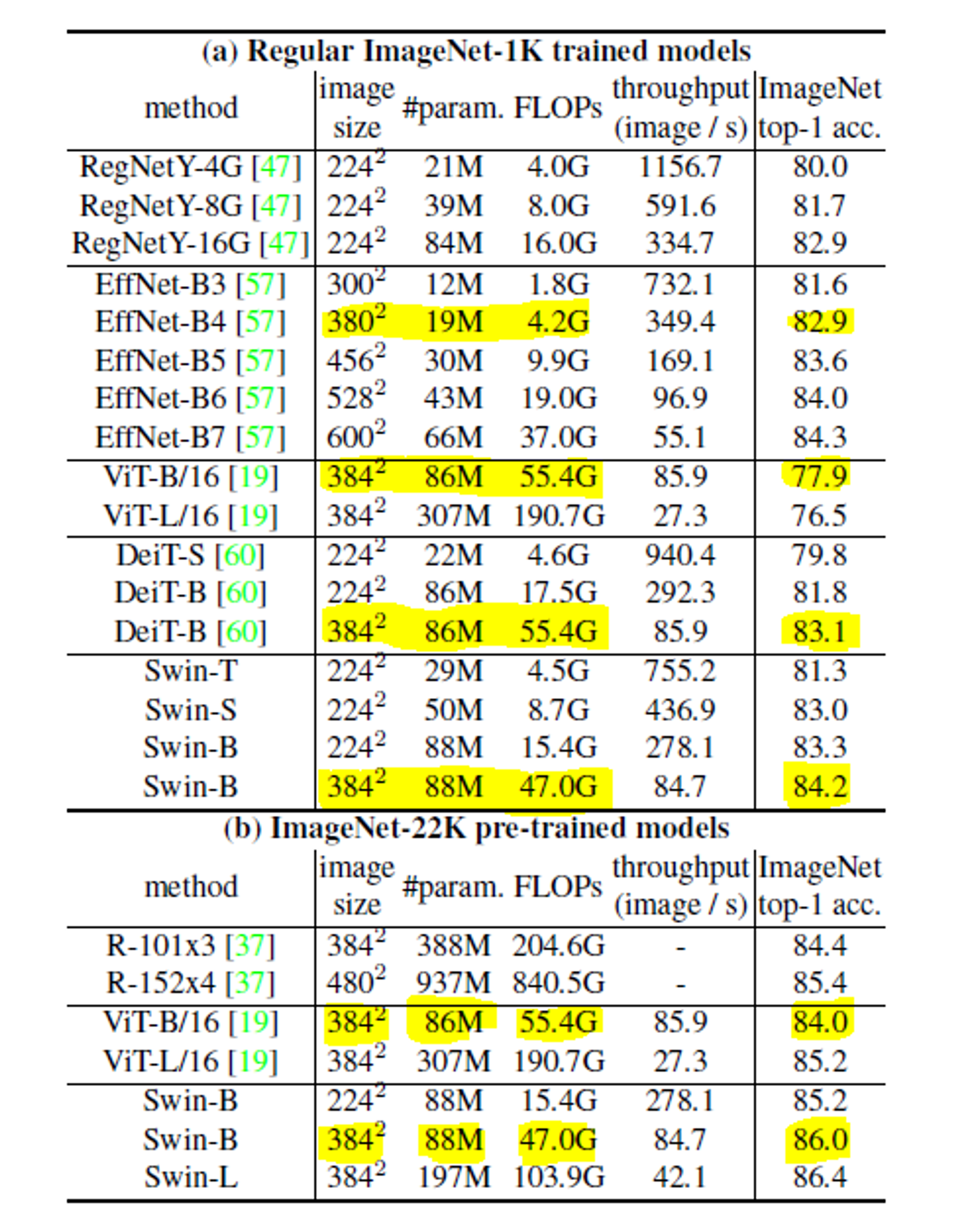
- ViT, DeiT 셋 다 파라미터 수는 비슷하지만, FLOPs (처리속도) 면에서 Swin이 더 좋고, 정확도 면에서도 좀 더 높다.
- EfficientNet은 확실히 파라미터 수가 훨씬 적어서, FLOP도 더 낮다. 그렇지만 Swin이 이보다 더 좋은 정확도를 냈다는 점에서 주목할만하다.
