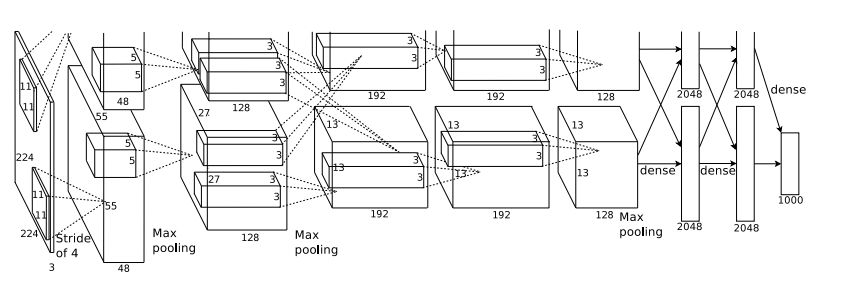
알렉스넷(AlexNet)
🎈알렉스넷의 등장
이미지넷 프로젝트는 2009년에 시작된 대규모 데이터셋 구축 및 활용 프로젝트로, 매년 ILSVRC라는 대회를 통해 뛰어난 성능을 보이는 이미지 분류 알고리즘을 선정해왔습니다.
알렉스넷(AlexNet)은 2012년 ILSVRC에서 우승을 차지한 모델로, 딥러닝을 활용한 최초의 컨볼루션 신경망 기반 이미지 분류 모델입니다. 알렉스넷은 이전 최저 오류율인 25.8%를 크게 개선하여 16.4%라는 혁신적인 성과를 기록하며, 딥러닝이 기존의 전통적인 머신러닝 접근법을 넘어설 수 있음을 증명했습니다.
🎯알렉스넷의 특징
- ReLU
- 병렬처리
- LRN(지역응답정규화)
- 오버랩 풀링
-
ReLU
기존에 사용하던 tanh함수, sigmoid함수를 사용하지않고 ReLU함수를 사용해 빠른 학습이 가능했습니다.
오류율 25%로 낮추는 시간이 기존의 tanh방식보다 무려 6배 단축되었습니다.
(실선은 ReLU, 점선은 tanh)
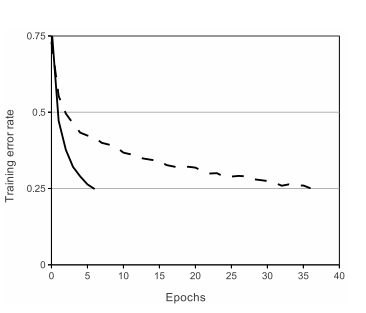 출처:ImageNet Classification with Deep Convolutional Neural Networks
출처:ImageNet Classification with Deep Convolutional Neural Networks -
병렬처리
당시 GPU의 한계로 120만장의 이미지를 하나의 GPU로 감당할 수 없었습니다. 따라서, 두개의 GPU로 병렬처리하여 이미지를 처리했습니다. 비록, 한정적인 계층에서만 정보교환이 이루어졌지만 해당 방식은 이후 모델에 좋은 아이디어로 작용했습니다. -
LRN(Local Response Nomalization)
픽셀별로 이웃 채널의 픽셀을 이용하여 정규화 하는 방식으로, ReLU값이 무한히 커져 주변 값이 무시되는 현상을 방지합니다.
현재는 Batch Normalization의 등장으로 잘 사용되지 않습니다.
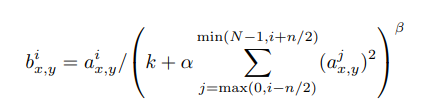 출처:ImageNet Classification with Deep Convolutional Neural Networks
출처:ImageNet Classification with Deep Convolutional Neural Networks -
오버랩 풀링
오버랩 풀링은 풀링필터의 Stride를 필터 크기보다 작게하여 겹치는 부분이 생기게하는 기법으로 과적합을 방지하기위해 사용됩니다. 다만, 많은 연산량을 요구하여 이후 모델에서는 잘 사용되지 않습니다.
🧮알렉스넷의 구조
알렉스넷은 2개의 GPU를 활용하여 병렬 처리하는 특징이 있습니다.
각각의 GPU는 이미지 전체를 입력받아 개별적으로 처리하고, 중간 계층에서 정보를 교환한 후 최종 결과를 한쪽으로 합칩니다.
알렉스넷은 크게 [CONV계층 5개] -> [FC계층 3개] 총 8개의 계층으로 이루어져있습니다.
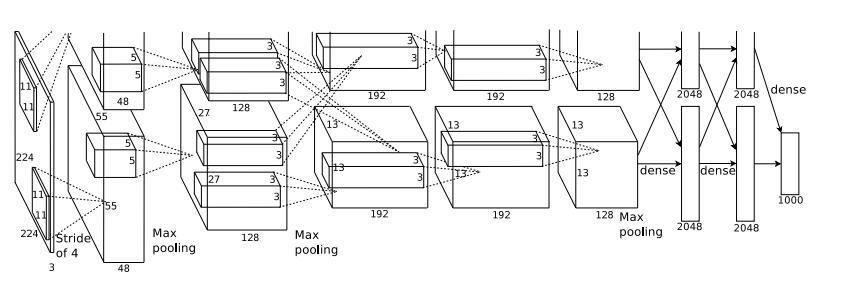
3번째 층에서는 GPU간 정보 교환을 통해 이전 층에서 계산된 2개의 GPU결과를 모두 받아옵니다.
또한, 1,2,5번째 층에서는 Pooling을 거쳐 이미지의 크기를 줄입니다.
- CONV1
- 입력: 227 x 277x 3(원본 이미지)
- 필터: 11x11x3, Stride:4, Padding:0, 96개
- 출력: 55x55x48
- 풀링: 27x27x48
첫 번째 합성곱 계층에서는 각각의 GPU가 전체 이미지를 입력받고 각각의 GpU에서 필터를 통해 합성곱 계산을 수행합니다.
(227 - 11) / 4 + 1 = 55
이후, 맥스 풀링을 거쳐 출력은 (27x27x48)의 크기로 변환됩니다. 이 과정에서 오버랩 풀링 방식이 사용됩니다. 오버랩 풀링은 필터의 크기와 스트라이드 크기가 다른 방식으로, 여기서는 (3x3, Stride:2)의 필터가 사용됩니다. 이를 통해 과적합을 방지합니다.
((55 - 3) / 2) + 1 = 27
- CONV2
- 입력: 27x27x48
- 필터: 5x5x48, Stride:1, Padding:2, 256개
- 출력: 27x27x128
- 풀링: 13x13x128
두 번째 합성곱 계층에서는 128개 필터를 사용합니다. 두 번째 이후의 합성곱에서는 패딩을 사용하여 합성곱 계층 내에서 이미지 크기를 유지합니다.
((27 + 2 x 2) - 5) / 1 + 1 = 27
이후, 풀링층을 거쳐 출력은 (13x13x128)로 변환됩니다.
((27 - 3) / 2) + 1 = 13
- CONV3
-
입력: 13x13x128x2(두개의 GPU 데이터 모두 반영)
-
필터: 3x3x256, Stride:1, Padding:1, 384개
-
출력: 13x13x192
-
풀링: X
-
정보교환 발생
세번째 합성곱계층에서는 정보교환이 발생합니다.
각각의 GPU는 양쪽의 데이터를 모두 입력받아 처리합니다.
그 결과, (13x13x192)의 이미지로 변환됩니다.4.CONV4
-
입력: 13x13x192
-
필터: 3x3x192, Stride:1, Padding:1, 384개
-
출력: 13x13x192
-
풀링: X
- CONV5
- 입력: 13x13x192
- 필터: 3x3x192, Stride:1, Padding:1, 256개
- 출력: 13x13x128
- 풀링: 6x6x128
- FC6, FC7, FC8
완전 연결층에서는 정보 교환과 드롭아웃이 진행됩니다. 3번의 완전 연결층을 거쳐 최종적으로 1000개의 벡터가 생성됩니다. 소프트맥스 함수를 사용하여 1000개의 클래스로 분류를 수행합니다.
