
나는 수 년 전부터 네이버 항공권 페이지를 크롤링을 시도하고 있었다.
크롤링 도전기 1
크롤링 도전기 2
하지만 번번이 크롤링 차단에 막혀서 실패했고, 아직까지 다양한 방법으로 시도중이다. 그리고 낸 결론은 다음과 같다.
크롤링 대신 다른 방법을 선택하자...
1. 크롤링을 포기한 이유
1.1. 시간이 오래 걸린다.
뉴스기사같은 정적 크롤링과 다르게, 네이버항공권을 비롯한 항공권 정보는 동적 크롤링을 필요로 한다. 항공사 뿐 아니라 외국항공사, 여행사, 여가플랫폼 등 많은 곳에서의 최저가 정보를 취합하기 때문이다.
하나의 항공권에 대한 정보를 조회하는데 10초 이상 걸리고, 내 프로젝트 특성상 수천~수만개의 정보를 필요로 하는데 양질의 데이터 수집이 힘들다.
해당 문제를 타파하기 위해 2년전 멀티스레딩을 이용한 방법을 시도하긴 했으나, 근본적 문제를 해결하긴 어려웠다.
1.2. DOM 기반 파싱 방법의 비유동성
동적 크롤링을 위해 사용하는 BeautifulSoup는 DOM 구조를 분석하여 정보를 파싱한다. 웹 페이지의 구조가 변하지 않는다면 유지보수에 불편함은 없다. 그러나 지금까지 크롤러도구에 여러 번 에러가 발생했고, 원인을 분석하면 HTML태그가 변하여 문제가 발생했던 경우가 종종 있었다.
네이버 항공권 페이지는 다양한 변화를 시도하는데, 최저가 그래프, 할인 프로모션 등 기능을 추가할 때 마다 파싱하는 HTML Tag에도 변화를 주어야했다. 자주 발생하는 일은 아니지만, 네이버 항공권 HTML 구조에 의존적이라는 단점이 존재한다.
1.3. 사람이 아닌 크롤링 봇이라는게 티가 남
HTTP Request를 받을 때, 사람과 프로그램의 차이는 뭘까?
python의 request 라이브러리는 User-agent의 값을 python-requests/2.x으로 요청을 보낸다. 그리고 이것은 저는 프로그램입니다를 알려주는 것이다.
물론 HTTP Request를 보낼 때 임의의 값으로 설정 가능하다. 나는 이 값을 바꾸고, 랜덤하게 설정하기 위해 아래와 같이 사용했다.
def generate_gecko_user_agent():
random_days = random.randint(0, 365)
fake_date = (datetime(2020, 1, 1) + timedelta(days=random_days)).strftime("%Y%m%d")
return f"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:123.0) Gecko/{fake_date} Firefox/123.0"위와 같은 식으로 요청을 보낼 때 마다 랜덤한 값을 사용하는 식으로 탐지를 피할 수 있다.
그러나, 요청시간이 일정한 패턴을 가지거나, 쿠키와 세션의 값이 비정상적이고, 다른 Header가 일정하면 의심을 피할 수 없게 된다.
위 문제를 해결하는 방법은 쉽고 실제로 적용을 했다. 하지만 네이버 항공권측에서 어떤 방식으로 봇을 탐지하는지 알 수 없다.
무엇보다 근본적으로 https://flight.naver.com/~ 으로 시작하는 URL로 지속적인 GET요청을 보내는 것이므로 뻔한 크롤링 수법이라는게 티가 날 수 밖에 없다.
그래서 나는 아주 기가막힌 방법을 떠올렸다.
2. api를 직접 호출해보자
네이버 항공권이 정보를 가져올 때, 사용하는 api가 있을 것이다. 그리고 모든 HTTP요청은 개발자도구를 이용하여 확인 가능하다.
네이버 항공권이 사용하는 api를 내가 사용하여 정보만 가져오면 되지 않을까?
네이버 항공권에서 사용하는 api를 직접 사용한다면?
- 동적 크롤링을 위해 수십초를 기다릴 필요가 없다.
- HTML태그가 바뀌어 발생하는 문제점을 걱정할 필요가 없다.
- 아무도 시도하지 않은 방법이라 기분이 좋다.
물론 호락호락하진 않았지만, 내가 수많은 시도 끝에 얻은 정보는 아래와 같다.
3. 네이버 항공권이 데이터를 가져오는 방법
하나의 완성된 항공권 정보를 가져오기 위해, 호출하는 api는 총 3개이다.
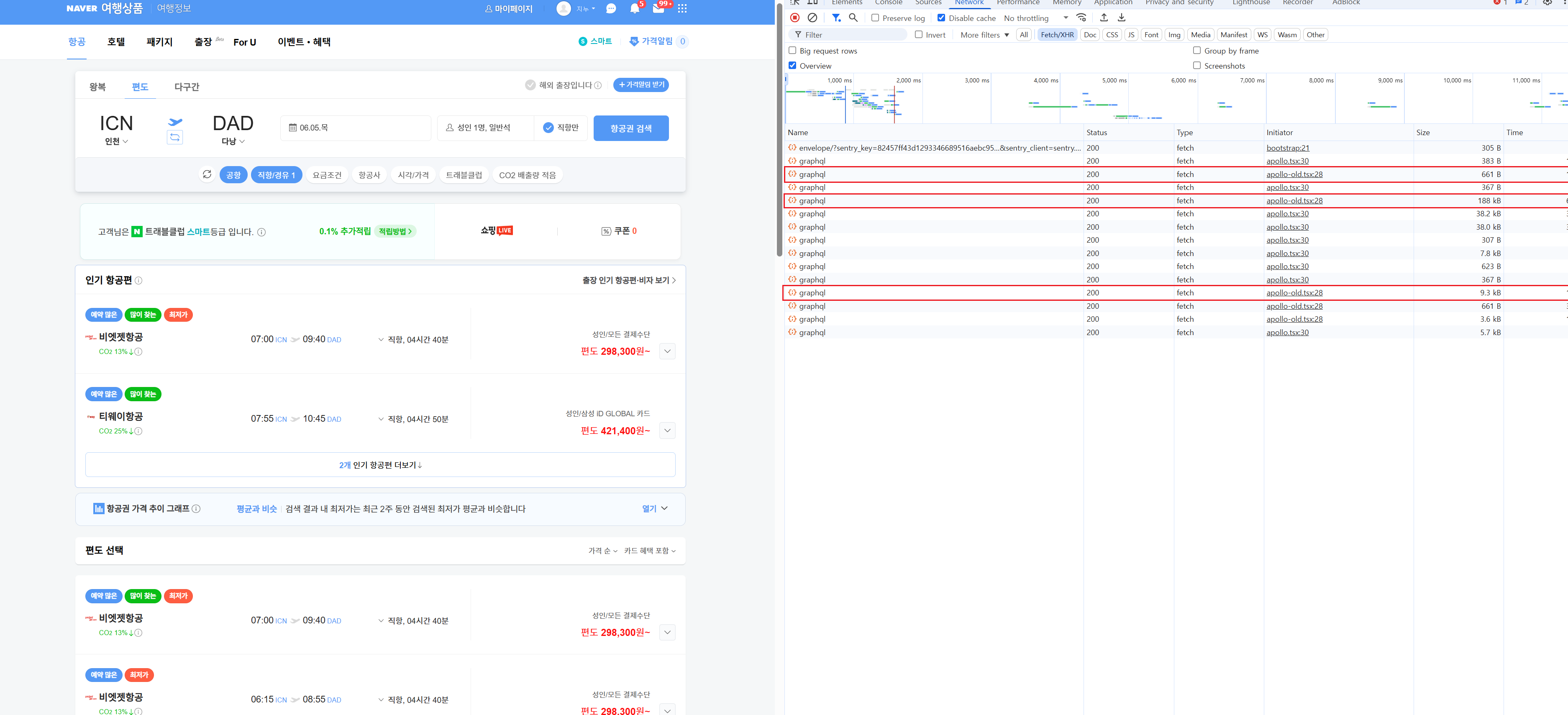
getInternationalList라는 이름을 가진 요청이며, 해당 요청은 총 3번의 요청-응답 과정을 거쳐 완전한 데이터를 가진다.
3.1. HTTP Request
Request Header
{
"authority": "airline-api.naver.com",
"method": "POST",
"scheme": "https",
"accept": "*/*",
"accept-encoding": "gzip, deflate, br, zstd",
"accept-language": "ko-KR,ko;q=0.9,en-US;q=0.8,en;q=0.7",
"cache-control": "no-cache",
"content-type": "application/json",
"origin": "https://flight.naver.com",
"pragma": "no-cache",
"referer": "https://flight.naver.com/flights/international/ICN-OSA-20250605?adult=1&isDirect=true&fareType=Y",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36",
"x-client-language": "ko",
"cookie": "..."
}Request Payload
{
"operationName": "getInternationalList",
"variables": {
"trip": "OW",
"itinerary": [{
"departureAirport": "ICN",
"arrivalAirport": "OSA",
"departureDate": "20250605"
}],
"adult": 1,
"child": 0,
"infant": 0,
"fareType": "Y",
"where": "pc",
"isDirect": True,
"stayLength": "",
"galileoFlag": True,
"galileoKey": "",
"travelBizFlag": True,
"travelBizKey": ""
},
"query": "..."3.2. n 번의 HTTP Response
첫 번째 요청과 응답
{
"galileoFlag": True,
"galileoKey": "",
"travelBizFlag": True,
"travelBizKey": ""
} {
"data": {
"internationalList": {
"galileoKey": "136_c343d8fb-1491-478c-8c4f-f049f5b644ec_258",
"galileoFlag": true,
"travelBizKey": "HMR_h0_0MC",
"travelBizFlag": true,
"totalResCnt": 24,
"resCnt": 0,
"results": {
"airlines": {},
"airports": {},
"fareTypes": {},
"schedules": [],
"fares": {},
"errors": [],
"carbonEmissionAverage": {
"directFlightCarbonEmissionItineraryAverage": {
"20250605ICNDAD": 48.47076
},
"directFlightCarbonEmissionAverage": 48.47076
}
}
}
}
}두 번째 요청과 응답
{
"galileoFlag": True,
"galileoKey": "136_c343d8fb-1491-478c-8c4f-f049f5b644ec_258",
"travelBizFlag": True,
"travelBizKey": "HMR_h0_0MC"
} {
"data": {
"internationalList": {
"galileoKey": "136_c343d8fb-1491-478c-8c4f-f049f5b644ec_258",
"galileoFlag": true,
"travelBizKey": "HMR_h0_0MC",
"travelBizFlag": false,
"totalResCnt": 24,
"resCnt": 20,
"results": {
"airlines": {세 번째 요청과 응답
{
"galileoFlag": True,
"galileoKey": "136_c343d8fb-1491-478c-8c4f-f049f5b644ec_258",
"travelBizFlag": false,
"travelBizKey": "HMR_h0_0MC"
} {
"data": {
"internationalList": {
"galileoKey": "136_c343d8fb-1491-478c-8c4f-f049f5b644ec_258",
"galileoFlag": false,
"travelBizKey": "HMR_h0_0MC",
"travelBizFlag": false,
"totalResCnt": 20,
"resCnt": 4,
"results": {
"airlines": {
"RS": "에어서울",
3.3. 규칙 분석
네이버 항공권에서는 모든 데이터를 가져오기 위해, 약 3~5번의 동일한 요청을 보낸다. 그리고 그 과정에서 일정한 규칙이 존재함을 깨달았다.
galileoFlag와 travelBizFlag
내가 n번째 요청의 응답에서 다음과 같은 데이터를 받았다.
{
"data": {
"internationalList": {
"galileoKey": "136_c343d8fb-1491-478c-8c4f-f049f5b644ec_258",
"galileoFlag": true,
"travelBizKey": "HMR_h0_0MC",
"travelBizFlag": false,
...
그럼 나는 해당 Flag의 값으로 n+1번째 요청을 보내야 한다.
{
"galileoFlag": True,
"galileoKey": "136_c343d8fb-1491-478c-8c4f-f049f5b644ec_258",
"travelBizFlag": false,
"travelBizKey": "HMR_h0_0MC"
} totalResCnt
n번의 요청을 가쳐, totalResCnt의 값이, 누적된 resCnt의 값과 같을때 까지 요청을 보낸다.
위의 규칙을 지킨다면, 모든 데이터를 최적의 시간에 받을 수 있는 것이다.
4. 결론은?
실패했다. 실패의 원인은 다음과 같다.
HTTP Request IP 기반 차단 방식 + AWS 클라우드 IP 대역 차단
수 많은 사이트에서 크롤링이나 공격 방지를 위해 많은 방법을 도입한다. HTTP Header의 User-agent를 변경하는 방식으로 크롤링을 회피하라는 방법이 대표적이긴 한데, 네이버 항공권에서는 IP를 이용하고 있었다.
물론 예상한 방법이라, Request를 보내는 IP를 변경하는 다양한 시도를 했다.
4.1. AWS EC2 재시작 & AWS Lambda
IP차단으로 인해 503이 응답으로 올 때 마다 AWS EC2를 재시작하였다. 그러나 수십번 요청을 거치면 다시 IP Block을 당했다.
네이버 항공권에서 크롤링 방지를 위해 AWS 클라우드에서 사용하는 IP대역을 차단하는 것이다.
4.2. AWS Lambda
서버리스 솔루션인 AWS Lambda를 사용하면 IP를 지속적으로 변경할 수 있다. 하지만 상술했듯 AWS 클라우드 IP 대역을 차단하는 방식이라 지속적 수집이 불가능했다.
5. 해결법?
주기적 수집을 위해 AWS를 이용해야 하므로 다른 방법을 찾아야 한다.
그래서 나는 프록시IP를 적용해 보려고한다. HTTP 요청의 IP를 위조하는 것이므로 해결책이 될 거라 생각한다.
물론 대표적인 무료 프록시의 경우 이미 알려진 IP대역이 있기 때문에 AWS와 같은 문제가 발생할 확률이 높다. 각종 유료 & 무료 프록시를 이용한 후 성공 후기를 남겨보도록 하겠다.

다른 방법으로 해결하셨나요? 저도 항공권 데이터 수집에 관심이 있는데 고민이 많네요.