
Selenium과 webdriver를 이용한 크롤링
지난 학기 본 프로젝트를 진행할 때는 selenium과 webdriver를 이용하여 크롤링을 진행했다.
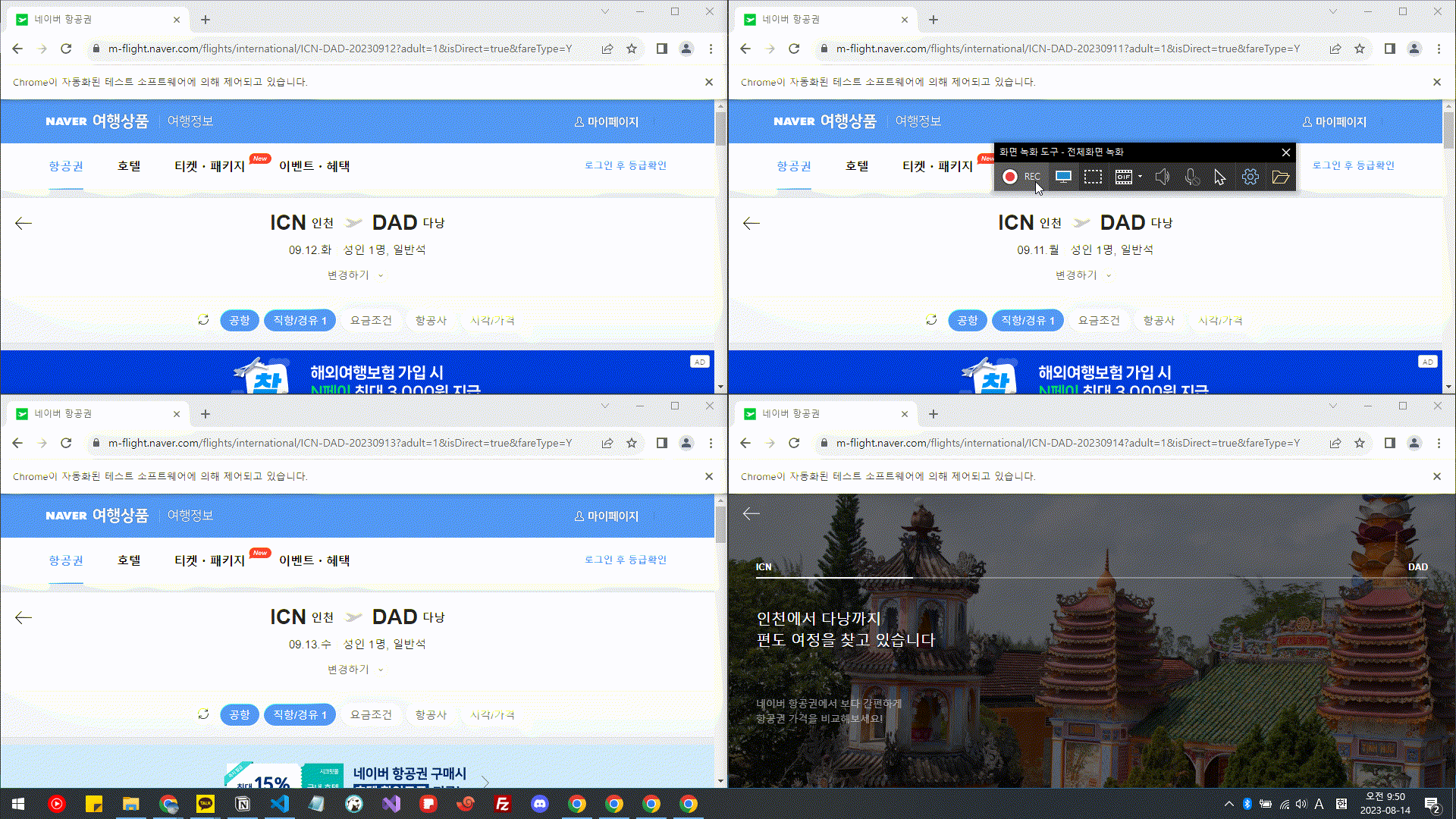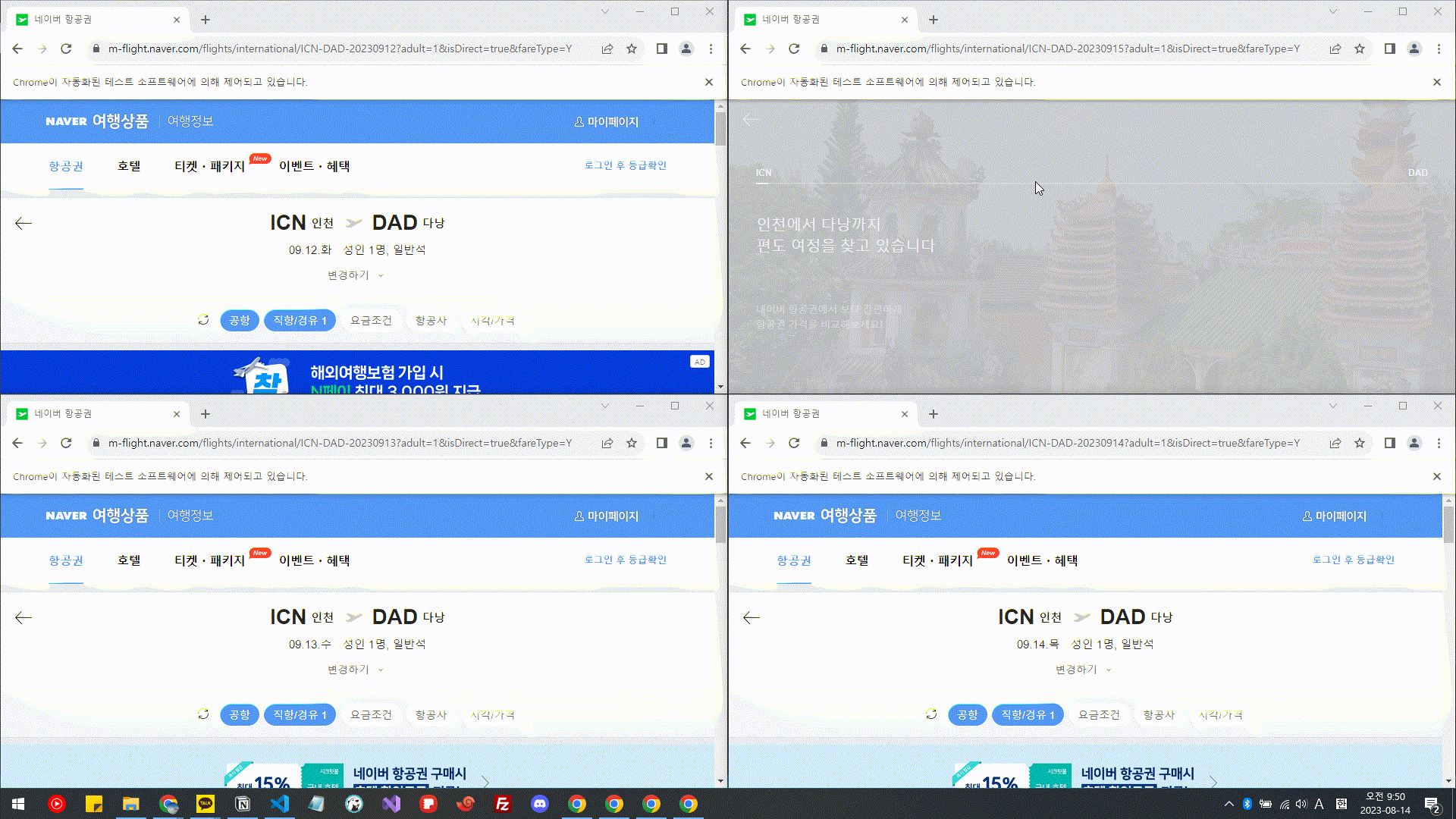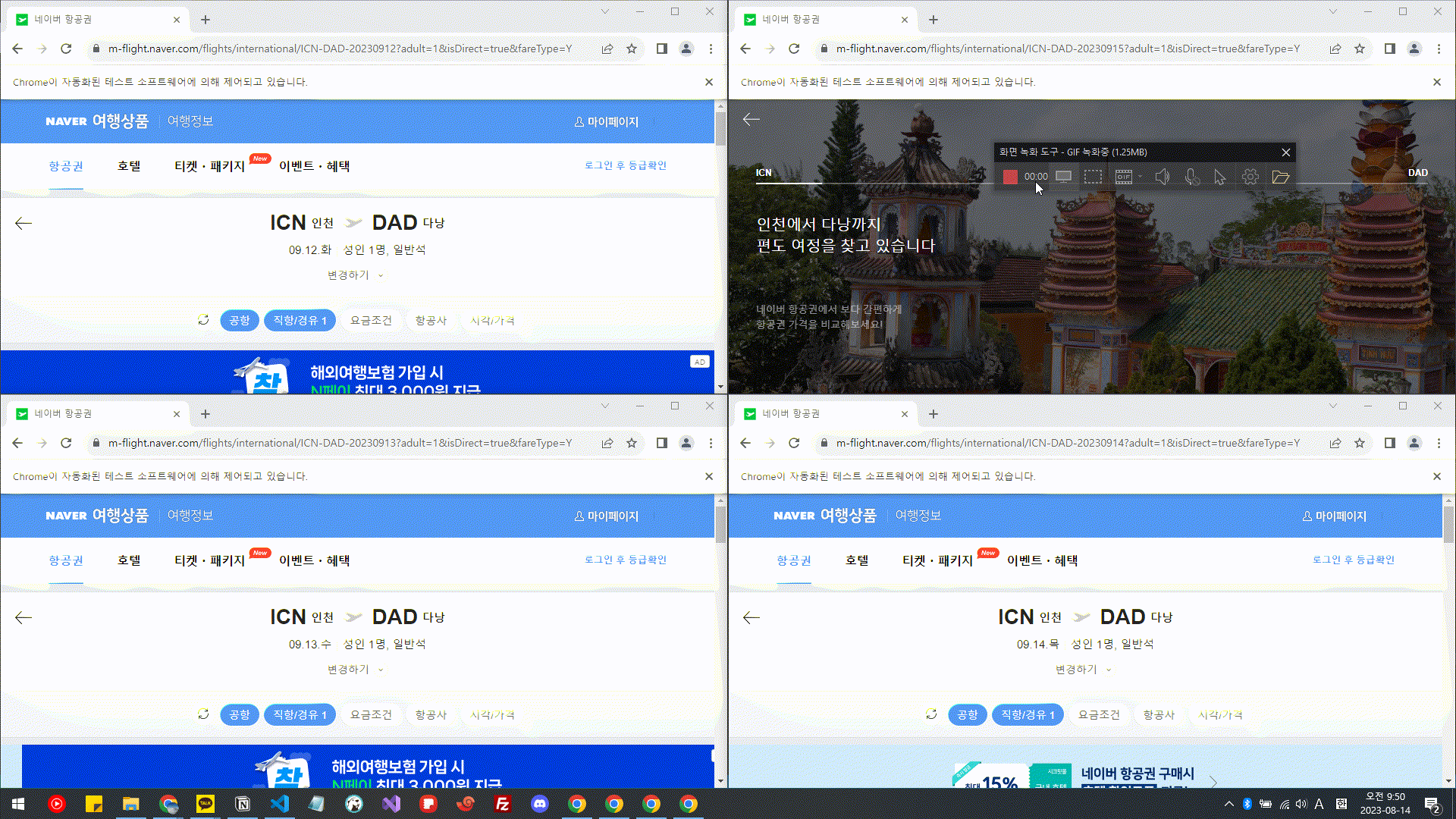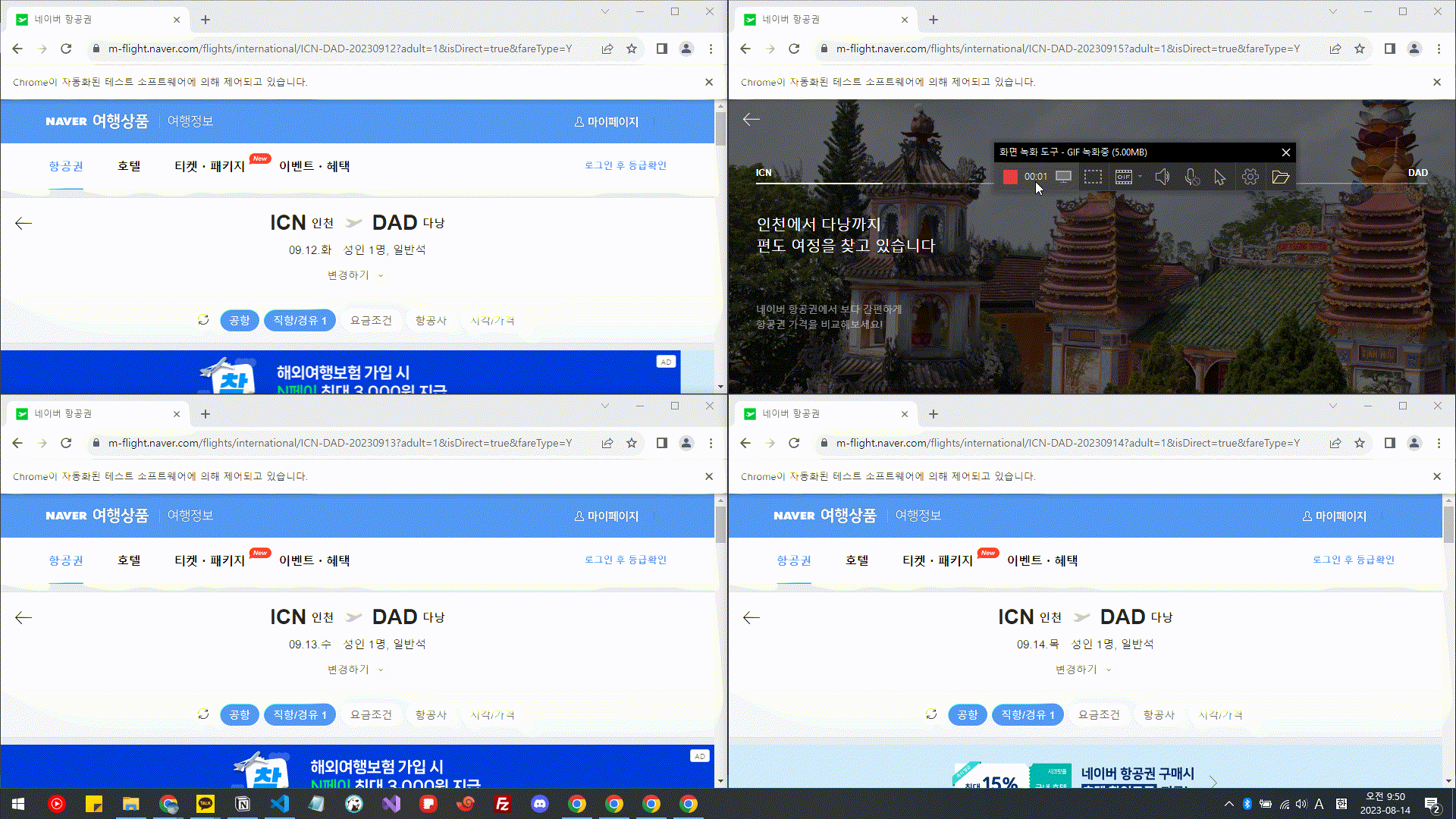
대충 이런 방식으로 백그라운드로 동작시켰다. 그 당시에는 되게 그럴싸했지만, 프로젝트를 진행할 수록 문제점이 많이 드러났다.
문제 1. 느리다
사실 느리다는 문제점이 가장 큰 문제이자 전부이다.
Selenium을 이용한 크롤링은 느리다. 뭐가 느리다는 걸까? 난 빠르고 혁신적이라고 생각했는데?
왜 느린지 이해할려면 Selenium의 작동 방식을 이해해야 한다.
Selenium
Selenium이란 웹 어플리케이션 테스트를 자동화하는데 사용되는 프레임워크이다. 웹 페이지의 동작 테스트, 스크래핑, 크롤링 등에 사용된다.
Selenium은 웹 드라이버와 같이 사용되며, 나는 크롬 브라우저를 제어하기 위해 크롬 웹 드라이버와 함께 사용했다. 브라우저를 조종하는 방식이므로 javascript엔진이 내장되어 있다. 그러므로 클릭이나 세션 조작을 통한 크롤링이 매우 편하지만 느린 것이다!
특정 웹 페이지가 렌더링이 되는 과정을 전부 기다린 후 페이지를 스크래핑하고, html로 변환된 파일에서 원하는 데이터를 얻기 위해 파싱하는 과정까지 기다려야 한다.
멀티스레딩 불가능
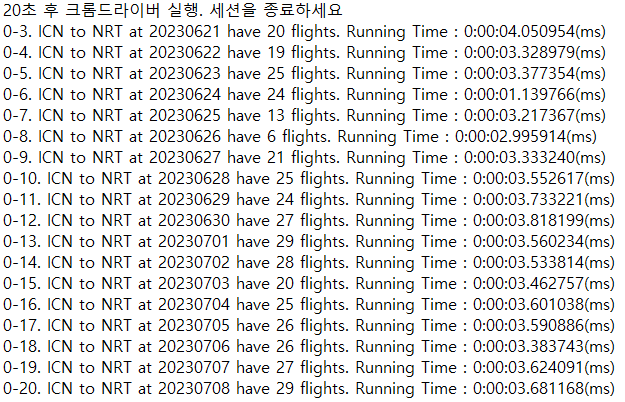
위의 움짤을 보면 항공권 데이터를 가져오는 로딩 시간이 대부분을 차지한다. 나는 로딩 시간을 줄이기 위해 멀티스레딩을 하려고 하였지만, 실패했다.
일단 웹 드라이버에서 멀티스레딩 기능을 제공하지 않는다. 파이썬이나 다른 언어에서 멀티스레딩 전용 라이브러리를 제공하는 것과 다르게 없다.
그래서 브라우저 창을 여러개 띄워 멀티프로세싱을 사용하려고 했다. 위의 움짤을 보면 알겠지만, 저게 멀티프로세싱이 맞나 싶다. 뭔가 의도한대로 동작하지 않았기 때문.
try:
# 15초 이내 비동기 로딩 실패시 예외처리
element = WebDriverWait(currBrowser, 20).until(
EC.presence_of_element_located(
(By.CLASS_NAME, "flights.List.international_InternationalContainer__2sPtn")
)
)
위의 코드 처럼 특정 클래스를 가진 html element가 로딩되면 넘어가는 방식인데, 조건 검사를 위해서는 웹 드라이버에서 busy-wating을 해야하므로, 멀티프로세싱이 되지 않았다.
인스턴스 서버의 자원 문제
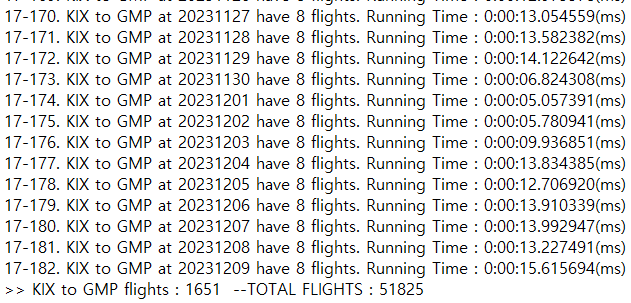
셀레니움으로 진행한 크롤링에서, 한 번의 크롤링 당 3000개 정도의 url을 조사하였다. 뒤로 갈수록 크롤링 시간이 길게는 30초까지도 걸렸고, 이거 때문에 많이 고생했다. 적당한 시점에 브라우저를 재시작하는 방식으로 해결했지만 아무튼 브라우저를 이용하는 방식은 문제가 많다는 것이다.
가능한 많은 항로를 조사하고 싶었지만 50000개 정도의 데이터를 모으면 10시간 정도가 걸렸다. 비효율적인 방법을 사용한 것도 맞고, aws ec2의 우분투 프리티어 사양을 사용했기에 인스턴스 서버에 무리가 되지 않게 하고 싶었다.
문제2. 원하는 데이터를 가져오기 힘들다
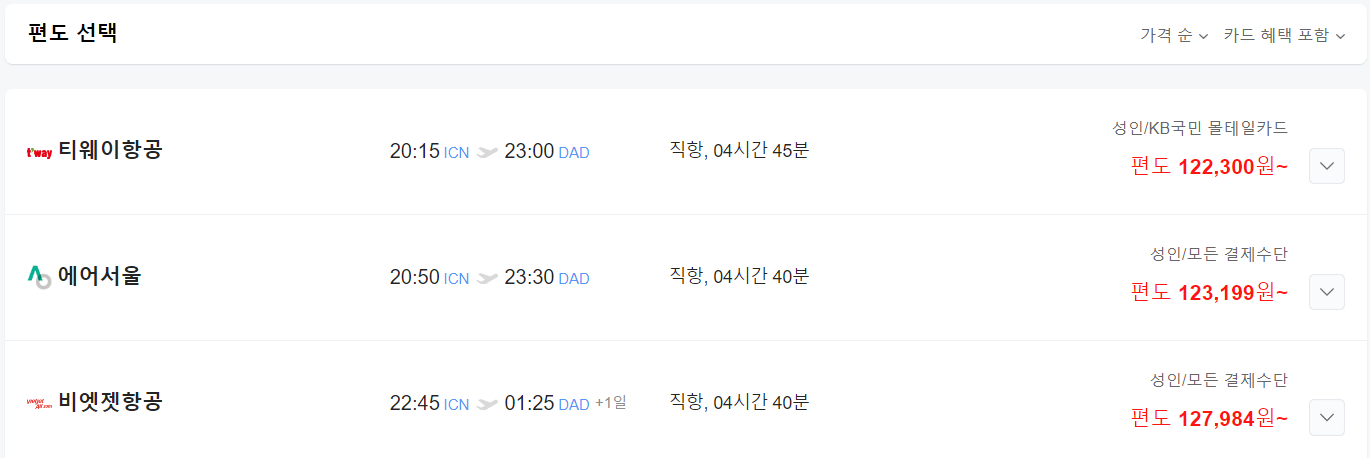
네이버 항공권에서 조회를 누르면 다음처럼 결과가 나타난다.
항공사, 시간, 날짜, 가격 등 내가 원하는 정보가 전부 나타나긴 하나, 두 가지 아쉬운 점이 있었다.
1. 카드 혜택 미포함
네이버 항공권에서 기본값은 카드 혜택 포함이다. 최저가중에 최저가를 보여주고 싶었기 때문이겠지만, 가격 변동의 추이를 수집하는 나로서는 카드 혜택이 포함되지 않은 정보가 필요했다. Selenium으로 해당 요소의 XPath를 가져와서 클릭하는 게 가능하지만, 내가 원하는 방식은 아니었다.
2. 비행기 편명
항공편의 이름과 부가적인 정보를 알려면 항공편을 클릭해야 나타난다. 하지만 api를 이용하여 데이터를 가져오면 말 그대로 모든 정보를 얻을 수 있다.
위에서 서술한 방식에 대해서 어떻게 사용했는지는 여기에서 자세히 확인할 수 있다. 코드 뿐이지만.
이러한 문제점들 때문에 셀레니움이 아닌 파이썬의 requests 라이브러리를 이용하여 데이터를 직접 가져오는 방법을 찾아보며 많은 시도를 하다 좋은 방법을 찾아냈다.
파이썬의 Requests를 이용한 크롤링
Requests
파이썬을 이용한 크롤링에 대해 검색하면 동적 크롤링은 Selenium을 이용하고 정적 크롤링은 Requests를 이용한다.
왜냐면 Selenium은 웹 브라우저의 동작 방식을 이용하고, Requests 라이브러리는 http프로토콜을 이용하여 바로 데이터를 요청하기 때문이다. 그래서 더욱 빠르기도 하다.
내가 크롤링 하는 네이버 항공권에서 데이터를 가져올 때는 동적으로 가져와야 한다. 하지만 나는 Selenium을 이용하기는 싫었고 Requests 라이브러리를 사용하기 위해 정말 많은 시도를 했다...
Requests.get()
get 방식을 이용해서 데이터를 가져오기 위해서는, 해당 url에서 정적인 데이터를 제공해야 하나, 네이버 항공권에서 조회할 때 로딩하는 비동기적으로 데이터를 가져오므로 위 방식은 사용할 수가 없다.
데이터가 어디서 오는가?
네트워크에 대해 잘 모르지만, 데이터가 어떻게 어디서 들어오는지 궁금해서 구글링하며 개발자도구를 뜯어보았다. F12를 눌러 개발자도구 - 네트워크 탭에서 모든 걸 확인할 수 있었다.
나는 다른 것 말고 항공권 정보가 들어있는 json형식의 데이터가 필요했고, Fetch/XHR탭에서 확인할 수 있다. xhr과 fetch는 둘 다 비동기적인 데이터 요청을 처리하는데 사용되며, fetch가 최신 방식이라고 생각하면 된다. graphql도 api를 사용하는 한 가지의 방식이다.
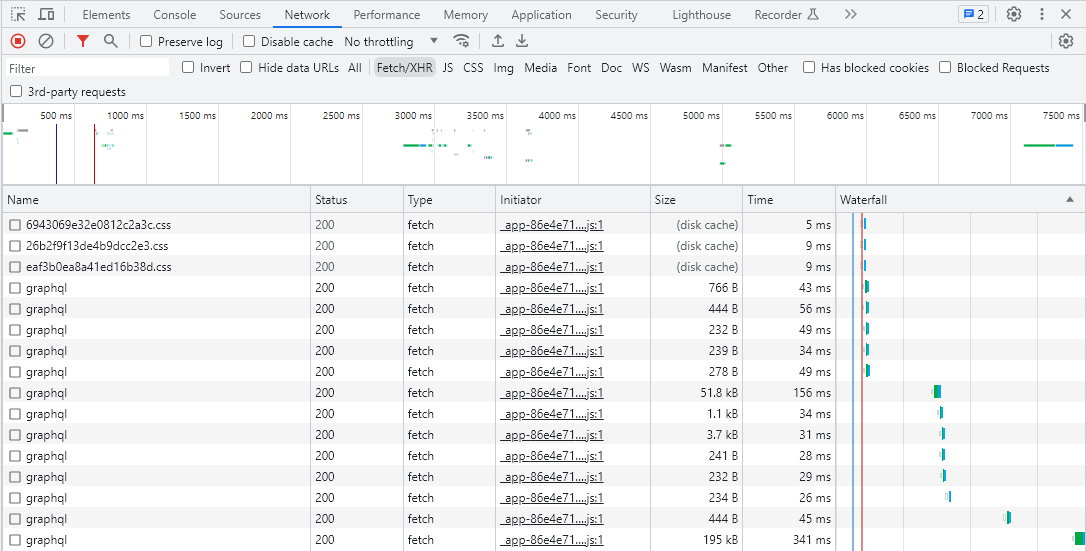
graphql이 많은데, 전부 항공권 정보는 아니고 이미지, 배너, 프로모션 등 전부 다른 내용의 api요청이다.
각각을 눌러보면 http 헤더, 응답, 페이로드(본문) 등 모든 정보가 들어있었다. 그래서 이것을 사용하여 내가 직접 post요청을 보내면 데이터를 가져올 수 있지 않을까 생각했고, 많은 노력 끝에 성공했다!
위에서 Request URL이 네이버 항공 api길래, 오픈 api를 제공하는 줄 알았는데 아니었다. 오픈 api가 아닌 private-api를 내가 사용할 수 있는지 몰라서 진짜 이틀동안 개고생했다..
해결 - 데이터가 한번에 들어오지 않음!
의기양양하게 메세지 바디와 헤더를 추출하고 request.post() 하였지만 당연히 안됐다. 알고보니 같은 데이터 요청에 대해 총 3번정도 데이터를 받아오고 있었다.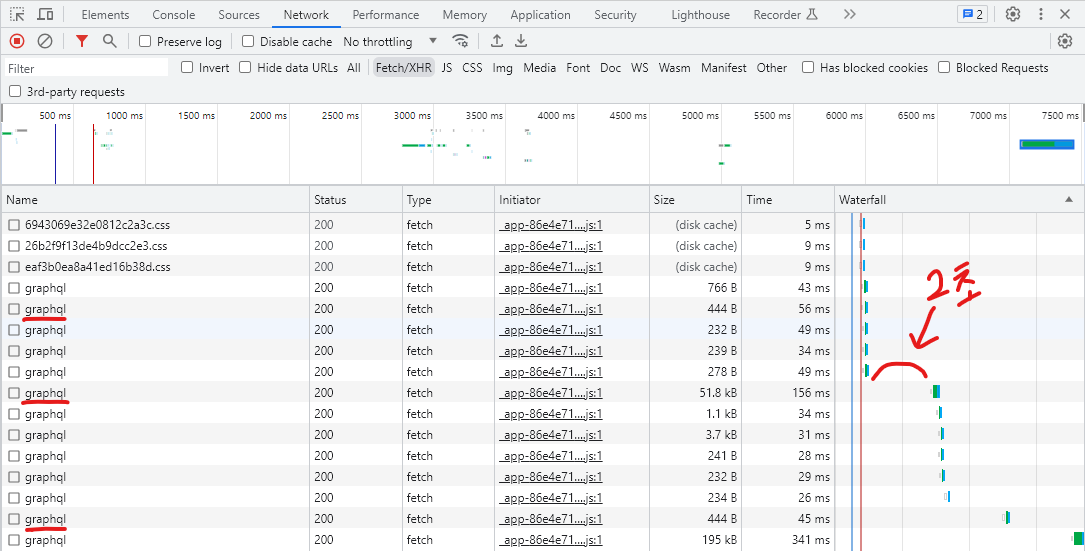
빨간색으로 밑줄 그은 graphql이 내가 원하는 항공권 정보를 담은 getInternationalList쿼리를 요청하고 있었다. (graphql은 본문에 쿼리가 들어감)
그리고 문제는 첫번째 요청과 두번째 이후 요청의 페이로드가 미세하게 달랐다.
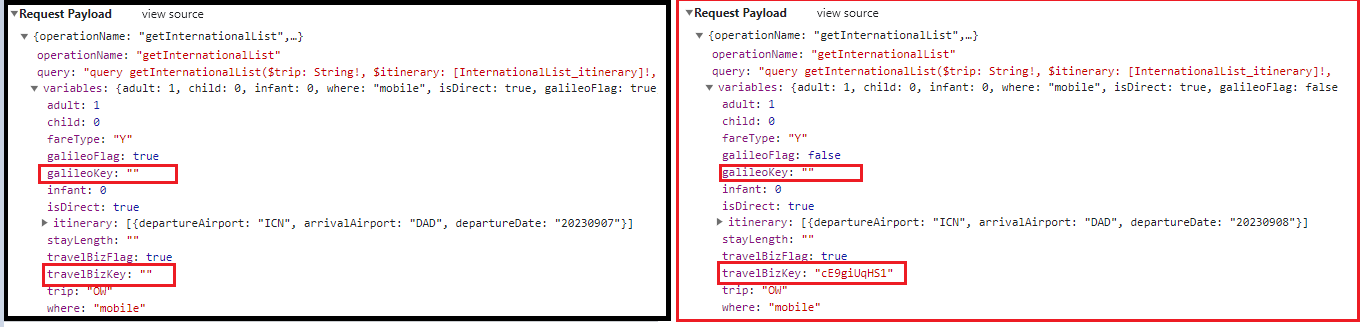
첫 번째 요청에는 galileoKey와 travelBizKey라는 속성의 값이 비어있는데, 두 번째 이후 요청에는 필요했다.
첫 번째 요청에서 두 키의 값이 들어오는 경우, 두 번째 요청에서 해당키flag : true로 만들어주고 키 값을 넘겨주면 된다. 두 키의 값이 있는경우도 있고 없는 경우도 있었다.
첫 번째 요청에는 데이터가 들어오지 않고, 두 번째 요청에서 부터 데이터가 들어왔다. 또한 두 키의 값은 새로고침할 때마다 계속 변하는 값이었다.
그러니까, 첫 번째 요청을 통해 두 키의 값을 가져와서, 두 번째 post요청을 보내어 사용하면 된다. 이때도 첫 번째 요청 이후 1초정도의 딜레이를 주어서, 서버에서 데이터를 만들 시간을 벌어줘야 되는 것 같았다. 솔직히 왜그런건지 진짜 모르겠다. galileoKey와 travelBizKey가 어떤 역할을 하는 값인지도 나와있지 않아서 그냥 별 짓 다 하면서 알아낸 것이다.
Requests.post()
import json # json 파싱용
import time
from datetime import datetime, timedelta # 크롤링 시간 측정
import requests #
url = "https://airline-api.naver.com/graphql"
headers = {
"Content-Type": "application/json",
"Referer": "https://m-flight.naver.com/flights/international/ICN-DAD-20230907?adult=1&isDirect=true&fareType=Y",
}
payload1 = {
"operationName": "getInternationalList",
"variables": {
"adult": 1,
"child": 0,
"infant": 0,
"where": "pc",
"isDirect": True,
"galileoFlag": True,
"travelBizFlag": True,
"fareType": "Y",
"itinerary": [{"departureAirport": "ICN", "arrivalAirport": "DAD", "departureDate": "20230907"}],
"stayLength": "",
"trip": "OW",
"galileoKey": "",
"travelBizKey": "",
},
"query": 'query getInternationalList($trip: String!, $itinerary: [InternationalList_itinerary]!, $adult: Int = 1, $child: Int = 0, $infant: Int = 0, $fareType: String!, $where: String = "pc", $isDirect: Boolean = false, $stayLength: String, $galileoKey: String, $galileoFlag: Boolean = true, $travelBizKey: String, $travelBizFlag: Boolean = true) {\n internationalList(\n input: {trip: $trip, itinerary: $itinerary, person: {adult: $adult, child: $child, infant: $infant}, fareType: $fareType, where: $where, isDirect: $isDirect, stayLength: $stayLength, galileoKey: $galileoKey, galileoFlag: $galileoFlag, travelBizKey: $travelBizKey, travelBizFlag: $travelBizFlag}\n ) {\n galileoKey\n galileoFlag\n travelBizKey\n travelBizFlag\n totalResCnt\n resCnt\n results {\n airlines\n airports\n fareTypes\n schedules\n fares\n errors\n }\n }\n}\n',
}
response = requests.post(url, json=payload1, headers=headers)
response_data = response.json()
travel_biz_key = response_data["data"]["internationalList"]["travelBizKey"]
galileo_key = response_data["data"]["internationalList"]["galileoKey"]
print("travel key: ", travel_biz_key)
print("galileo key: ", galileo_key)
time.sleep(5)
payload2 = {
"operationName": "getInternationalList",
"variables": {
"adult": 1,
"child": 0,
"infant": 0,
"where": "pc",
"isDirect": True,
"galileoFlag": galileo_key != "",
"travelBizFlag": travel_biz_key != "", # 값이 없으면 false
"fareType": "Y",
"itinerary": [{"departureAirport": "ICN", "arrivalAirport": "DAD", "departureDate": "20230907"}],
"stayLength": "",
"trip": "OW",
"galileoKey": galileo_key,
"travelBizKey": travel_biz_key,
},
"query": 'query getInternationalList($trip: String!, $itinerary: [InternationalList_itinerary]!, $adult: Int = 1, $child: Int = 0, $infant: Int = 0, $fareType: String!, $where: String = "pc", $isDirect: Boolean = false, $stayLength: String, $galileoKey: String, $galileoFlag: Boolean = true, $travelBizKey: String, $travelBizFlag: Boolean = true) {\n internationalList(\n input: {trip: $trip, itinerary: $itinerary, person: {adult: $adult, child: $child, infant: $infant}, fareType: $fareType, where: $where, isDirect: $isDirect, stayLength: $stayLength, galileoKey: $galileoKey, galileoFlag: $galileoFlag, travelBizKey: $travelBizKey, travelBizFlag: $travelBizFlag}\n ) {\n galileoKey\n galileoFlag\n travelBizKey\n travelBizFlag\n totalResCnt\n resCnt\n results {\n airlines\n airports\n fareTypes\n schedules\n fares\n errors\n }\n }\n}\n',
}
response2 = requests.post(url, json=payload2, headers=headers)
response_data2 = response2.json()
results = response_data2["data"]["internationalList"]["results"]["schedules"][0] # dict obj
print(json.dumps(results, indent=4))
결과
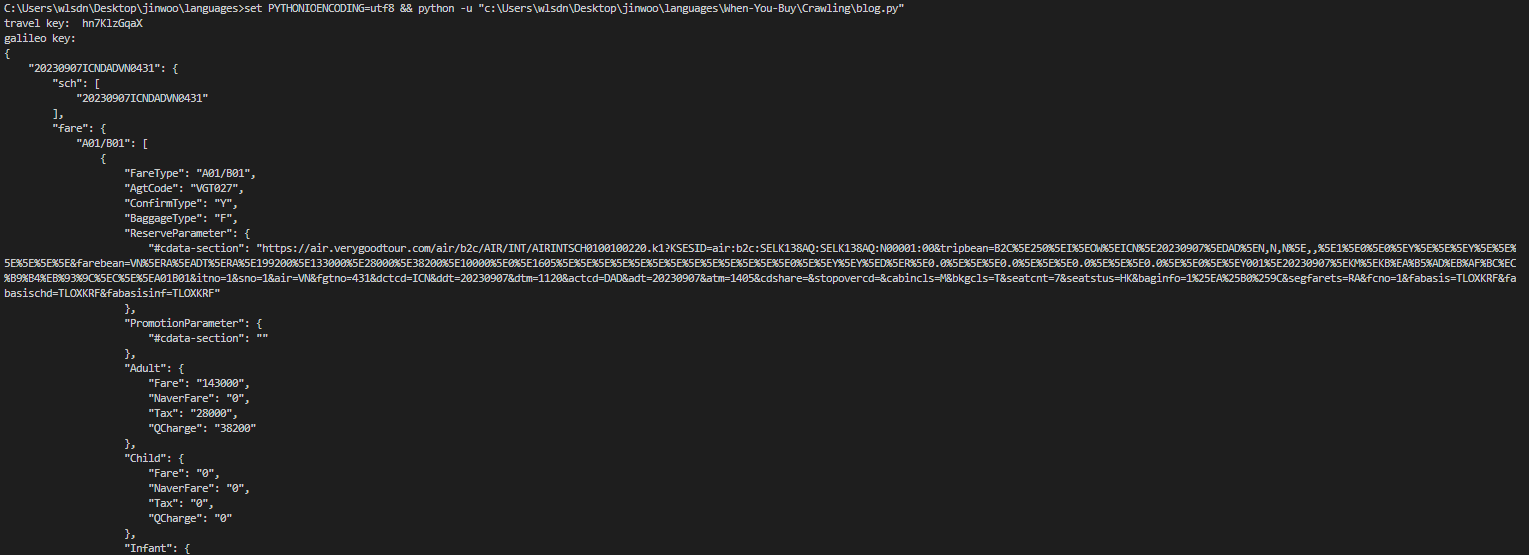
네트워크 탭에서 post요청의 response에 모든 정보를 받아올 수 있다. 위의 페이로드에 쿼리문이 굉장히 긴데, 이걸 잘 만져보면 원하는 값을 가져올 수도 있을 것 같다.
이제 어떻게 활용해야 할지 막막하지만. 큰 문제는 해결된 것 같다. open-api 만들어주세요 네이버관계자님
참고로 네이버 항공권은 robots.txt가 존재하지 않으므로, 크롤링 해도 문제가 없다고 생각한다.

좋은 글 감사합니다.