자료의 형태
- 머신러닝은 데이터라는 디지털 자료를 바탕으로 수행하는 분석 방식
자료의 형태를 파악함은 머신러닝을 사용하기 위한 필수 과정
(데이터의 구성 파악, 데이터 전 처리 형태를 대략적으로 짐작 가능)
범주형 자료(Qualitative data)의 요약 (순위형 자료, 명목형 자료)
-
범주형 자료가 숫자로 표현되었다고 해서 Numerical data가 되는 것은 아님
ex) 남녀 성별 구분 시, 남자를 1, 여자를 0으로 표현하는 경우
-
다수의 범주가 반복되거나 관측값의 크기보다 범주에 관심이 있는 경우에 사용
-
요약
각 범주에 속하는 관측값의 개수를 측정
각 범주의 비율을 파악 > 범주 간의 차이점을 비교 가능
-
value_counts() :각 범주에 속하는 관측값의 개수
value_counts(normalize = True) : 도수를 자료의 전체 개수로 나눈 비율 (상대 도수)
import matplot as plt를 이용해서 그림으로 나타내는 것이 가능함.
수치형 자료(Numerical data, Quantitative data)의 요약 (연속형 자료, 이산형 자료)
-
수치로 구성되어 있기 때문에 통계값을 사용한 요약이 가능
-
의미 있는 수치로 요약하여 대략적인 분포 상태를 파악 가능
-
np.mean() : 평균을 의미, 관측값들을 대표. None에 대한 대체값으로 많이 사용
평균의 특징 - 관측값의 산술평균으로 사용 - 통계에서 기초적인 통계 수치로 많이 사용 - (-) 극단적으로 큰 값이나 작은 값(이상치)의 영향을 많이 받음 -
이상치에 의한 왜곡 > 평균만으로는 분포를 파악하기 부족
평균 외에 분포가 퍼진 정도를 파악하기 위해 분산, 표준편차를 이용 -
분산(variance) : 자료가 얼마나 흩어졌는지 숫자로 표현, 평균으로부터 떨어진 정도를 의미
from statistics import variance variance()
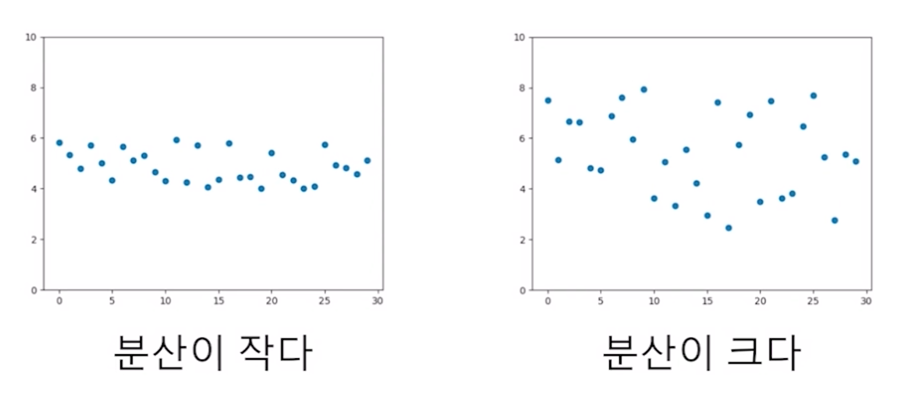
-
표준편차(standard deviation)
분산의 단위 = 관측값의 단위의 제곱 (관측값의 단위와 불일치) > 일치시키기 위해 표준편차를 사용from statistics import stdev stdev()

Department of Artificial Intelligence, EWHA