머신러닝을 위한 데이터 전 처리 이해하기
-
과정
크롤링 또는 DB데이터를 통하여 데이터 수집
데이터를 분석하고 train에 사용할 형태로 전 처리
머신러닝 모델을 사용하여 데이터 학습
학습된 머신러닝 모델을 test데이터를 사용하여 평가 -
머신러닝의 입력 형태로 데이터 변환
대부분의 머신러닝 모델은 숫자 데이터를 입력 받기 때문에
-
결측값 및 이상치를 처리하여 데이터 정제
결측값, 이상치가 있을 경우 모델 입력이 불가능하거나 성능이 확연히 떨어짐
-
학습용 및 평가용 (train data, test data의 분리)
범주형 자료 전 처리
- 타이타닉 생존자 데이터를 이용
수치에 의미가 없는 값 > 범주형 자료임을 알기
명목형 자료 > 수치 맵핑 변환, 그 수치에 따른 성능 변화가 생김
순서형 자료 > 마찬가지로 수치 맵핑 변환, 수치 간 크기 차이는 커스텀 가능함(이 값의 차이가 결과에 영향)
수치형 자료 전 처리
-
머신러닝의 입력으로 바로 사용할 수 있으나, 모델의 성능을 높이기 위해서 데이터 변환이 필요
-
방법
1. Scaling : 변수 값의 범위 및 크기를 변환하는 방식, 변수 간의 범위가 차이가 많이 나면 사용-
정규화(Normalization) (0~1사이의 값으로)
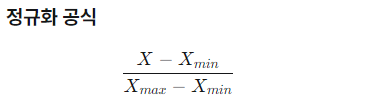
-
표준화(Standardization)
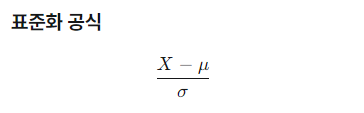
- 범주화 : 변수의 값보다 범주가 중요한 경우 사용
-
데이터 정제 및 분리하기
-
결측값(Missing Data) 처리하기 ex) Null, None, NaN 등의 결측값
결측값이 존재하는 샘플 삭제 (= 행 삭제)
결측값이 많이 존재하는 변수(feature) 삭제 (= 열 삭제)
결측값을 다른 값으로 대체 (평균값, 중앙값, 머신러닝의 예측값으로 대체) -
이상치(Outlier) 처리하기
이상치가 있으면, 모델의 성능을 저하시킬 수 있으므로 일반적으로 제거. 어떤 값이 이상치인지 판단하는 기준이 중요하다.- 이상치 판단 기준 방법
통계지표(카이제곱 검정, JQR 지표 등)를 사용하여 판단
데이터 분포를 보고 직접 판단
머신러닝 기법을 사용하여 이상치 분류
- 이상치 판단 기준 방법
-
데이터 분리하기
머신러닝 모델을 평가하기 위해서는 학습에 사용하지 않은 평가용 데이터가 필요. 약 7:3~8:2(데이터가 많을 경우엔 9:1로까지)의 비율로 train data, test data를 분리한다.
+지도학습의 경우 feature 데이터와 label 데이터를 분리하여 저장
