분류 개념 알아보기
-
label이 범주형인 경우 분류 알고리즘을 이용해서 풀이한다.
-
주어진 입력 값이 어떤 class(label은 분류에선 class)에 속할지에 대한 결과 값을 도출하는 알고리즘
-
어떠한 기준을 가지고 class를 구분한다.
-
분류 알고리즘
트리 구조 기반 : 의사 결정 나무, 랜덤포레스트
(특히 의사 결정 나무는 앙상블과 쓰일 때 높은 정확도를 보임)
확률 모델 기반 : 나이브 베이즈 분류기
결정 경계 기반 : 선형 분류기, 로지스틱 회귀 분류기, SVM 등
신경망 : 퍼셉트론, 딥러닝, 모델
등이 존재
의사결정나무 - 모델 구조
-
스무고개와 같이 특정 질문들을 통해 정답을 찾아가는 모델 (질문은 직접 설정)
-
뿌리 마디에서부터 끝 마디까지 아래 방향으로 진행
-
각 마디마다 하나의 feature에 대해 분리하는 방식으로 여러 개의 feature 구분 가능 (중간 마디가 추가됨)
분류 평가 지표
-
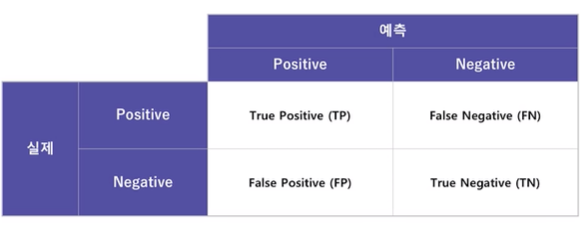
혼동행렬 : 분류 모델의 성능을 평가하기 위함
- 분류 결과를 전체적으로 파악할 때

- 분류 결과를 전체적으로 파악할 때
-
정확도 : 전체 데이터 중에서 알맞게 분류된 데이터의 비율, 모델의 정확도를 나타냄
- 클래스 비율이 불균형하면 평가 지표의 신뢰성은 떨어짐

- 클래스 비율이 불균형하면 평가 지표의 신뢰성은 떨어짐
-
정밀도 : Positive라고 분류한 데이터 중에서 실제로 Positive인 데이터의 비율
- Negative가 중요한 경우 : 실제로 Negative인 데이터를 Positive라고 판단하면 안되는 경우

- Negative가 중요한 경우 : 실제로 Negative인 데이터를 Positive라고 판단하면 안되는 경우
-
재현율 : Positive인 데이터 중에서 Positive로 분류한 데이터의 비율
- Positive가 중요한 경우 : 실제로 Positive인 데이터를 Negative라고 판단하면 안되는 경우
- Positive가 중요한 경우 : 실제로 Positive인 데이터를 Negative라고 판단하면 안되는 경우
-
분류 목적에 따라 다양한 지표를 계산하여 평가

Department of Artificial Intelligence, EWHA