MobileNet.V1 논문 바로가기
MobileNet.V2 논문 바로가기
MobileNet.V3 논문 바로가기
참고 영상
참고 자료
MobileNet V1
설계 배경
- 고성능의 디바이스가 없는 환경(컴퓨터 성능이 제한되거나 배터리 퍼포먼스가 중요한 곳)에서 CNN을 구동하기 위해 만들어진 구조
Idea
-
Channel Reduction
-
Distillation & Compression
-
(main)Depthwise Separable Convolutions(Factorized convolutions의 한 형태)
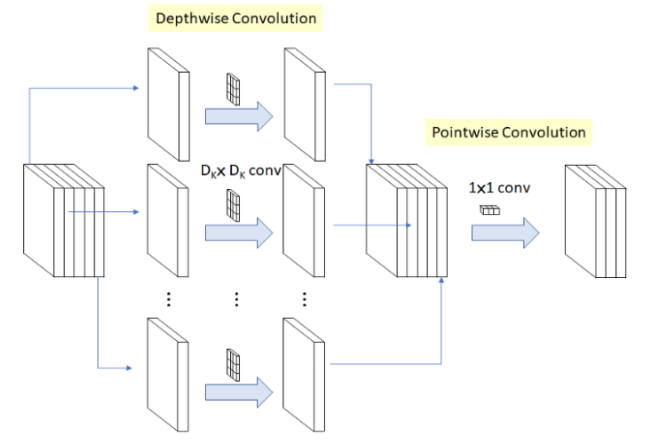
Depthwise Convolution 이후에 Pointwise Convolution을 결합한 것
1. Depthwise convolution(dwConv) : 각 입력 채널에 대해 3x3 conv하나의 filter가 연산을 수행하여 하나의 featuremap을 생성. 각 채널마다 독립적으로 연산을 수행하여 spatial correlation을 계산
- 각 채널 별로 출력된 feature map의 크기가 1이므로 연산량이 감소
2. Pointwise convolution(pwConv, 1X1 convolution) : Depthwise convolution이 생성한 featuremap을 1x1 conv로 채널 수를 조정한다.
- 입력/출력 채널 수에 입력 feature map의 해상도를 곱한 값이다.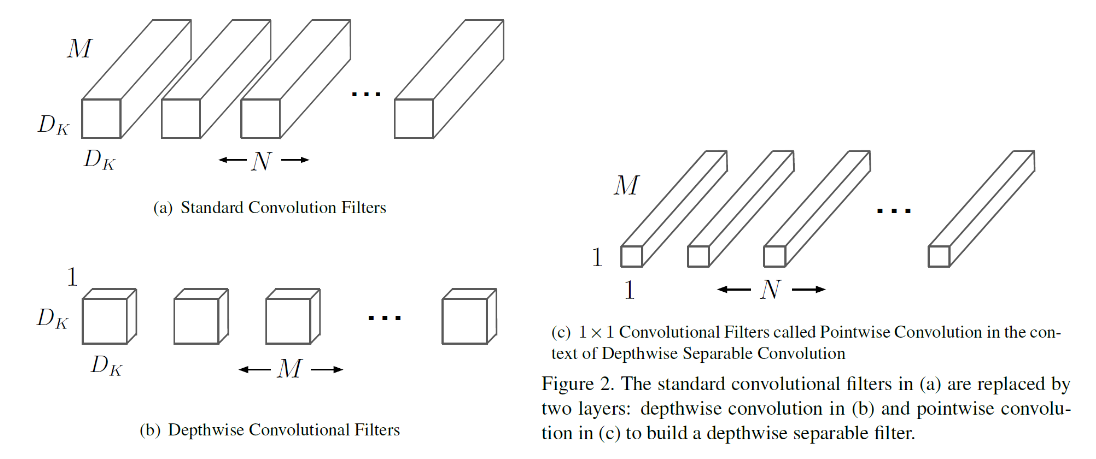
최종 depthwise separable convolution의 연산량
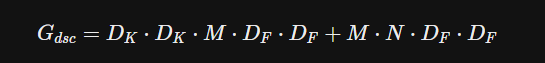
MobileNets Architecture
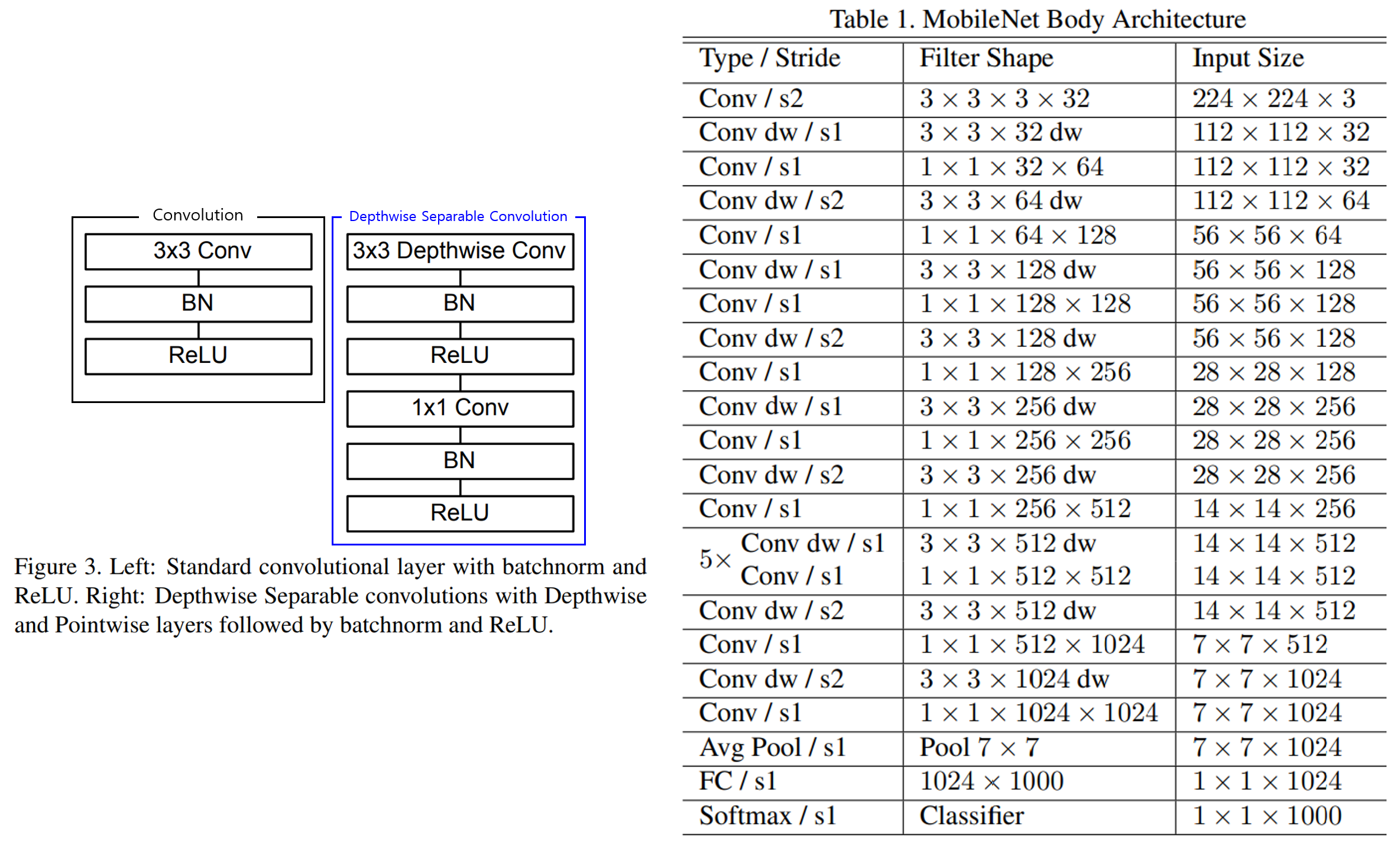
- 첫 번째 conv를 제외하고 depthwise separable convolution을 사용한다
(Conv dw가 Depthwise Convolution을 의미한다) - 마지막 FC레이어를 제외하고 모든 레이어에 BN, ReLU를 사용 (이유는 딱히 언급 x)
- Down-sampling은 depthwise convolution, 첫 번째 conv layer에서 수행
- 총 28개의 layer를 갖는다.
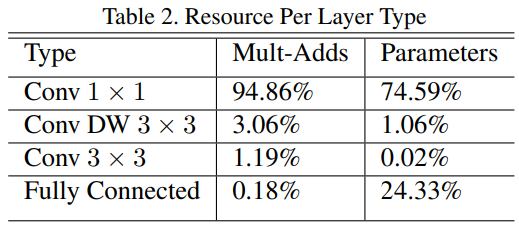
- 1x1 Convolution이 전체 연산의 약 95%를 차지하고, 파라미터 비율은 75%정도를 차지하는 것으로 보아 연산효율이 매우 높다는 것을 짐작할 수 있다. (1x1 Convolution은 연산할 때 메모리 복사과정이 필요 x)
Hyper parameters(를 통한 경량화)
- MobileNet을 최적으로 하기위해 latency와 accuracy의 균형을 조절 (latency의 최적화에 초점이 맞춰진다)
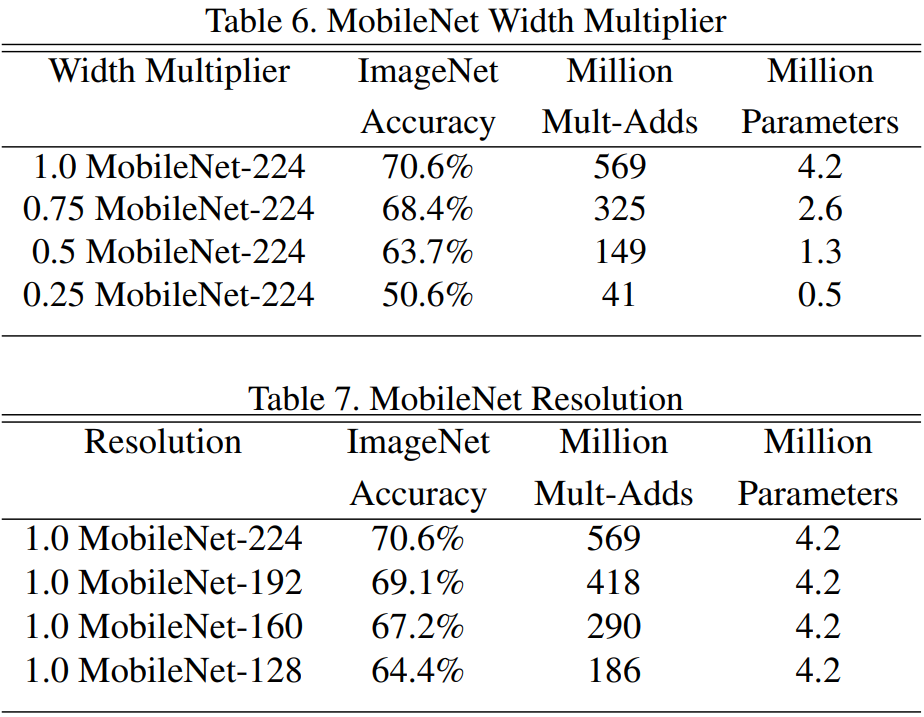
Width Multiplier : Thinner Models :MobileNet의 두께를 결정한다. (각 layer에서의 필터 수를 의미)
1을 기본형태로 0.75, 0.5, 0.25를 사용, Width Multiplier를 낮추면 parameter 수가 감소한다.
- input channel M과 output channel(=filter 수) N에 Width Multiplier을 곱해서 채널을 줄이는 역할을 한다.
- Depthwise separable convolution의 연산량
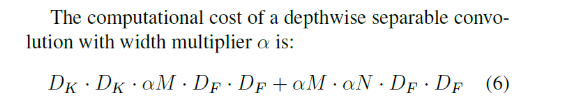
Resolution Multiplier : Reduced Representation : 모델의 연산량을 감소시키기 위해 사용. 이미지의 해상도를 낮춘다.
1을 기본적으로 사용했으며, 해상도를 224, 192, 160, 128로 조절
- input의 가로 세로 크기를 줄여서 연산량을 줄인다. input의 width와 height에 곱해서 연산
Hyper-parameter에 따른 변화
MobileNet V2
차이점
-
Inverted Residual with linear Bottlenect을 도입하여 업그레이드하였다.
-
메모리 효율, 계산량에서 이점을 보이나 정확도는 떨어지지 않는다.
Idea
-
shortcut connection이 얇은 bottleneck layer 사이에 존재하는 inverted residual 구조에 기반한 Mobilenet V2를 제안
-
모델의 representational power를 보존하기 위해 narrow layer 안에서의 비선형성을 제거 (linear bottleneck layer)
-
ImageNet 분류, COCO object detection, VOC image segmentation에서 성능을 측정하여 작은 모델로도 높은 성능을 기록
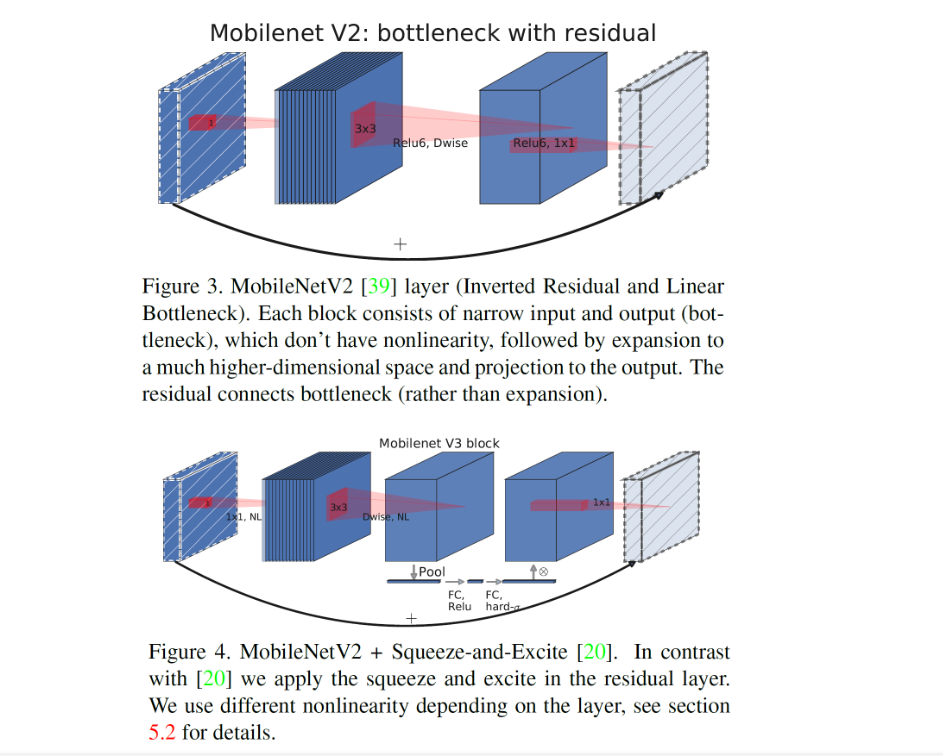
Inverted residual with linear bottleneck
- 저차원의 압축된 표상을 받아 고차원으로 확장한 다음 다시 lightweight depthwise convolution으로 필터링을 거친다. feature는 이러한 linear convolution을 통해 저차원의 표상으로 투영
- 효율적이고 어떤 모델에도 사용 가능
Linear Bottlenecks
- n개의 layer로 구성된 신경망에서 각 픽셀 및 채널에 대해 h x w x d 크기의 activation이 존재한다. 이를 d채널을 갖는 1X1크기의 pixel h x w 개 있다고 생각했을 때 이 pixel에 encoding되어 있는 정보는 어떤 manifold of interest를 생성하며, 이를 저차원의 subspace로 embeded될 수 있다고 가정.
- 이를 가지고 저차원의 subspace로 보냈다가 다시 복구시키는 bottleneck layer를 적용하여 activation space의 차원을 줄일 수 있다. 그러나 정보가 일부 소실될 수 있다.
- ReLU와 같은 비선형 activation이 없는 layer를 하나 더 추가하여 linear bottleneck의 역할을 하도록 한다.
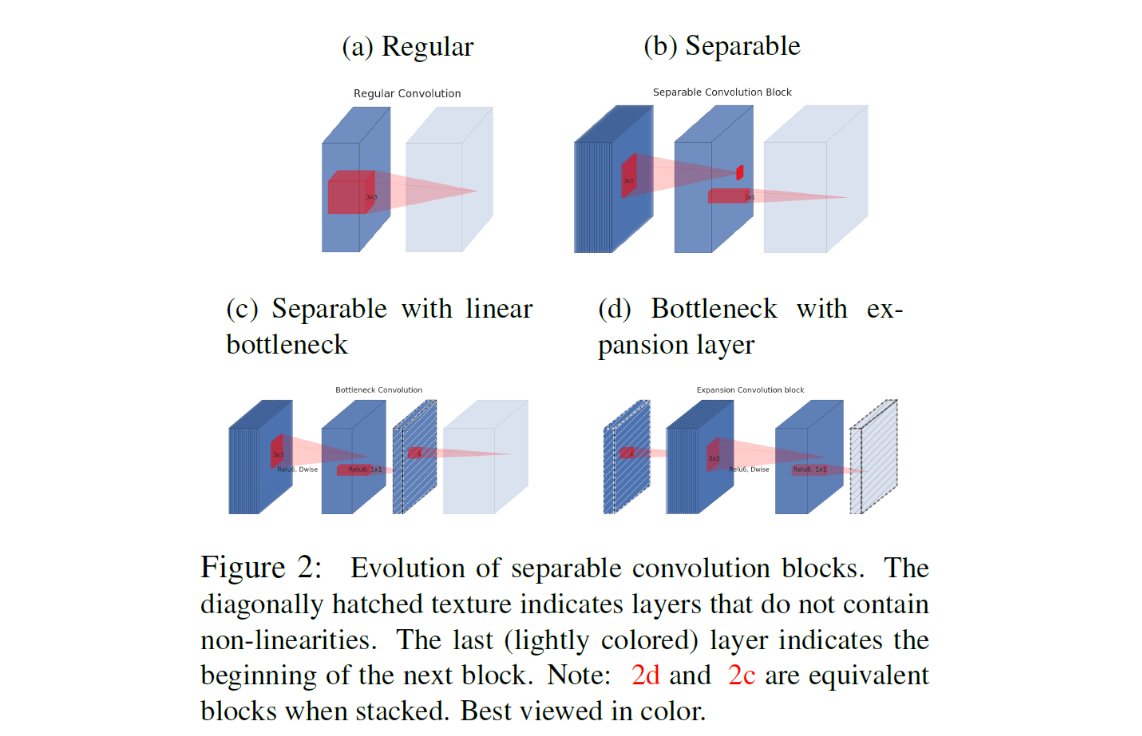
Inverted residuals
- 일반적인 residual connection은 wide - narrow - wide의 layer가 있고, wide layer끼리 연결했다면 Inverted residual에서는 narrow - wide - narrow layer가 기본으로 narrow layer끼리 연결했다.
- narrow에 해당하는 저차원의 layer에 필요한 정보가 압축되어 저장되어 있다고 가정했기 때문에 skip connection이 사용가능할 것이라고 추측
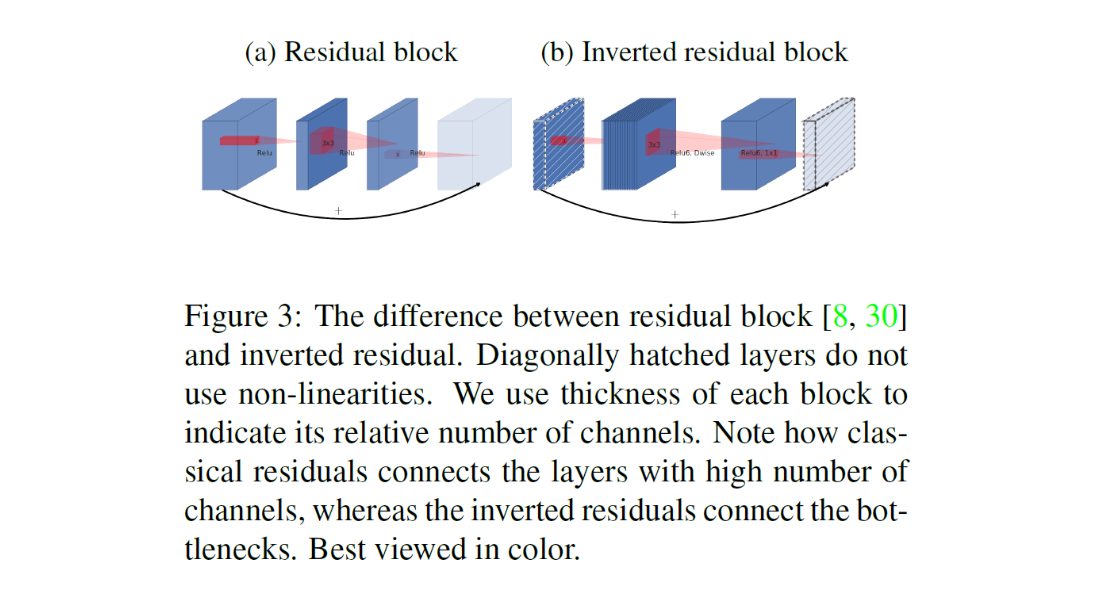
inner layer depth가 0인 경우 다음 convolution은 항등함수가 된다. 이로서 모델의 capacity와 표현력을 분리하여 생각할 수 있다.
Architecture
- Bottleneck depth-separable convolution with residuals


Object Detection
- SSDLite는 기존의 SSD의 conv를 separable conv로 바꾼 것으로 기존 SSD와 비교했을 때 parameter 수와 계산량을 획기적으로 줄인다.
MobileNet V3
Idea
- NetAdapt 알고리즘과 Hardware-aware NAS(Network Architecture Search), novel architecture advances에 기반해 있다.
- 두 가지 크기의 모델을 제안한다
- MobileNetV3-Large : V2에 비해 latency는 20% 줄이고, 정확도는 3.2% 증가했다.- MobileNetV3-Small : V2에 비해 정확도는 비슷하지만 25% 더 빠르다.
- Semantic Segmentation task에서 Lite Reduced Atrous Spatial Pyramid pooling(LR-ASPP)라는 새로운 decoder를 제안한다.
- V1에서는 Depthwise Separable Convolution을 제안, V2에서는 linear bottlenexk & inverted residual 구조를 제안 V3에서는 이러한 layer들의 조합을 building block으로 사용하여 효율적인 구조를 제안한다.
Network Search (다시)
- Mnastnet과 같은 접근법을 사용하지만 w = -0.15로 latency가 다를 때의 정확도 변화를 방지
Network Improvements
- Redesigning Expensive Layers : 7x7 spatial resolution 대신 1x1 spatial resolution을 사용하여 연산량을 줄인다.
- projection과 filtering을 이전 bottleneck layer에서 제거
- filter가 좌우 반전의 image를 처리하는 경우가 있으므로 중복을 줄이기 위해 filter 수를 16개로 감소
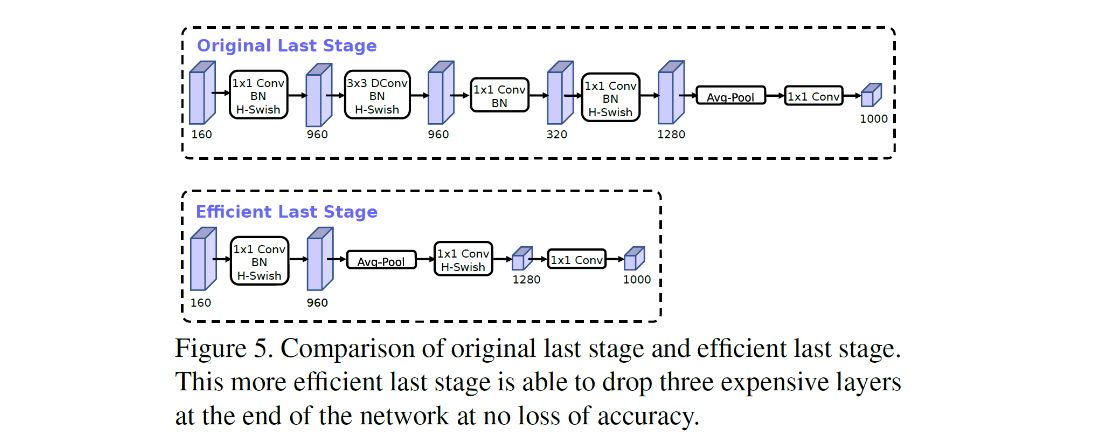
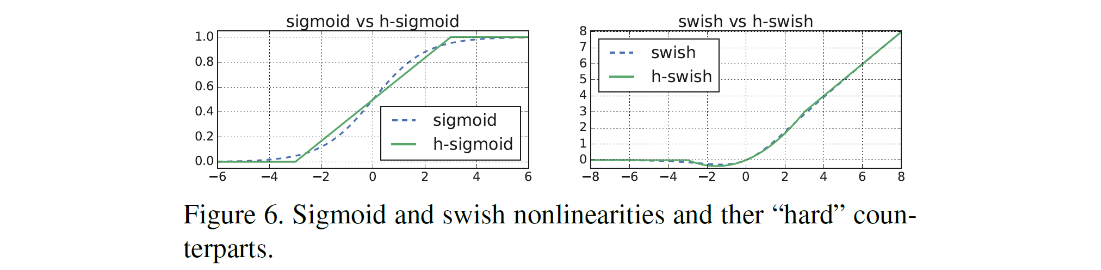
- Nonlinearities
- swish라 불리는 비선형성을 ReLU에서 사용
- sigmoid 함수를 swish와 ReLU를 이용해서 바꾼다.
비선형성 및 gradient변화를 유지하면서 계산량도 줄어드는 것을 볼 수 있다.
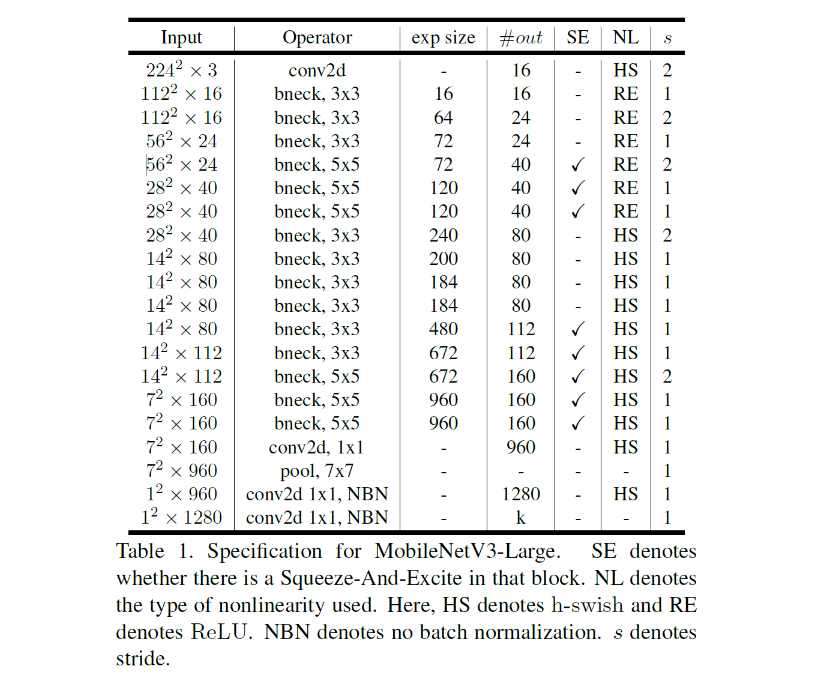
Architecture
- MobileNet V3.Large
- MobileNet V3.Small