Enhanced Deep Super Residual Networks

Preknowledge
- SRReNet? (EDSR이 SRReNet으로부터 파생된 알고리즘)
- ResNet구조를 SR에 그대로 적용 (MSE를 이용하기 때문에 image자체는 흐릿하게 도출)
- SRResNet은 residual learning을 통해 시간, 메모리 문제를 해결. 그러나 그 자체를 low-level image에 적용시키는 데에는 한계가 있다.
Review
Abstract
- 최근 DCNN(Deep convolutional neural netowkrs)의 발전으로 SR(super-resolution)의 연구가 가속화
- 현 sota model의 정확도를 뛰어 넘는 EDSR을 제시
- Conventional residual network(SRResNet을 차용)에서 불필요한 module을 제거(뒤에서 자세히 설명) > model size의 확장에도 불구하고 training procedure은 안정화
- MDSR는 후첨
Introduction
- 기존의 SR의 (particulrary single image super-resolution(SISR)) 목표 : reconstruct a high-resolution image from a single low-resolution image
- Limitation of such networks
- Sensitive to minor architectural changes
same model have different levels of performance by different initialization and training techniques- Most of existing SR algorithms treat different scale factors as independent problems(각각의 scale에 대해 독립적으로 다룸)
- SRReNet는 ResNet을 이용해서 time, memory issue를 해결하긴 했으나, high-level image problem을 해결하기 위해 고안된 모델로, low-level image problem인 SR에 단순히 적용시키는 것에는 한계가 있다.
- 이를 해결하기 위해 SRResNet에서 optimize분석, unnecessary module을 제거
- 각각 다른 scale에서 train, fewer parameter에서 multi-scale model을 제안
- Standard benchmark dataset과 DIV2K dataset으로 평가.
Related Works
- Aim to learn mapping functions between I(LR) and I(HR) image pairs.
- Not only treat the inter-relation of learned feature for each scale but also propose a new multi-scale model that efficiently reconstructs high-resolution images for various scales.
- Use L1 loss function which achieved improved performance compared with the L2
Proposed Methods
EDSR : handles a specific super-resolution scale
MDSR : 나중에~^^
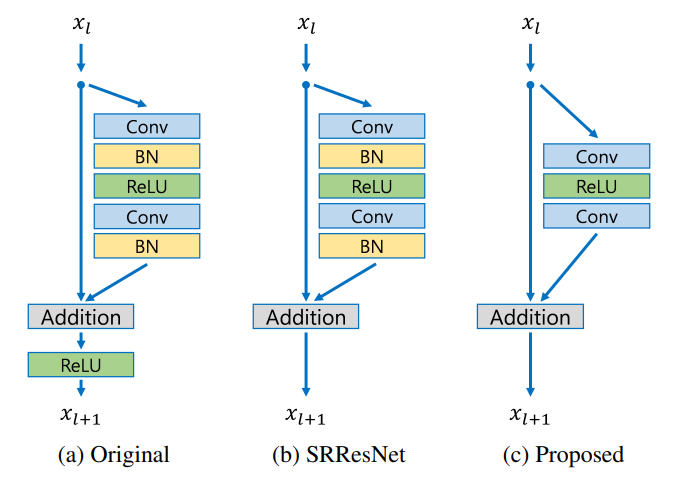
- Residual blocks
Batch normalization layer을 제거 (BN은 관례적으로 SR 알고리즘에 쓰였다) : Batch normalization은 feature map을 정규화 하므로 feature의 flexibility를 저하시킨다.(texture detail이 사라짐) 따라서 이를 제거하여 feature map이 최대한 보존될 수 있도록 하였다.
Residual block의 밖에서 ReLU activation layer을 제거.
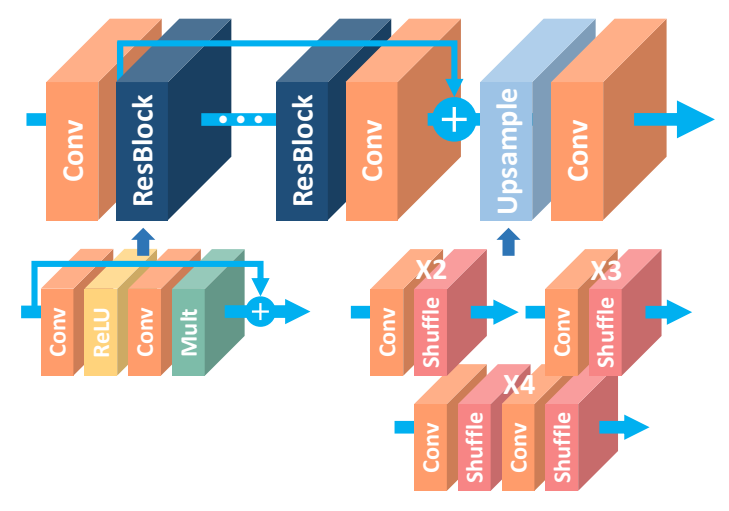
Residual scaling layer역시 제거 > only use 63 feature maps for each convolution layer. - Final model
- B(the number of layers) = 32
- F(the number of feature channels) = 256
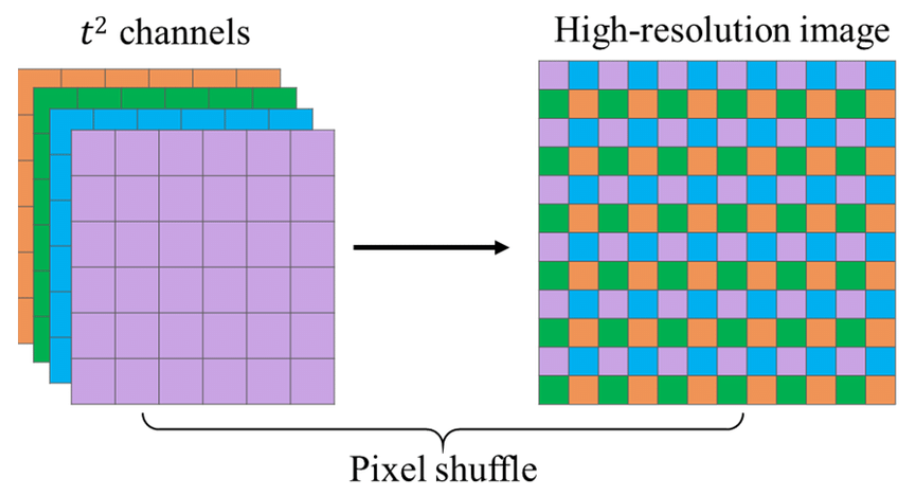
- pixel shuffle을 통해 upsampling을 진행
- pixel shuffle이란 LR의 feature map들의 pixel을 이용해서 HR의 pixel을 construct하는 기법
- 모델을 살펴보면 기존의 SR 알고리즘은 각각의 scale을 독립적으로 다뤘는데 EDSR에서는 pre-trained model의 parameter를 이용하므로 다른 scale의 HR 간의 관계를 이용할 수 있다.
- Single-scale model
- To enhance the performance, increase the number of parameters by stacking many layers or increasing the number of filters.
- However, increasing the number of feature maps makes the training pro-cedure numberially unstable >> instead adopting the residual scaling with factor 0.1
- Need scale X2 model's parameter to train X3 and X4 model.
Experiments
- Dataset : DIV2K dataset is a newly proposed high-quality image dataset for image resoration task.
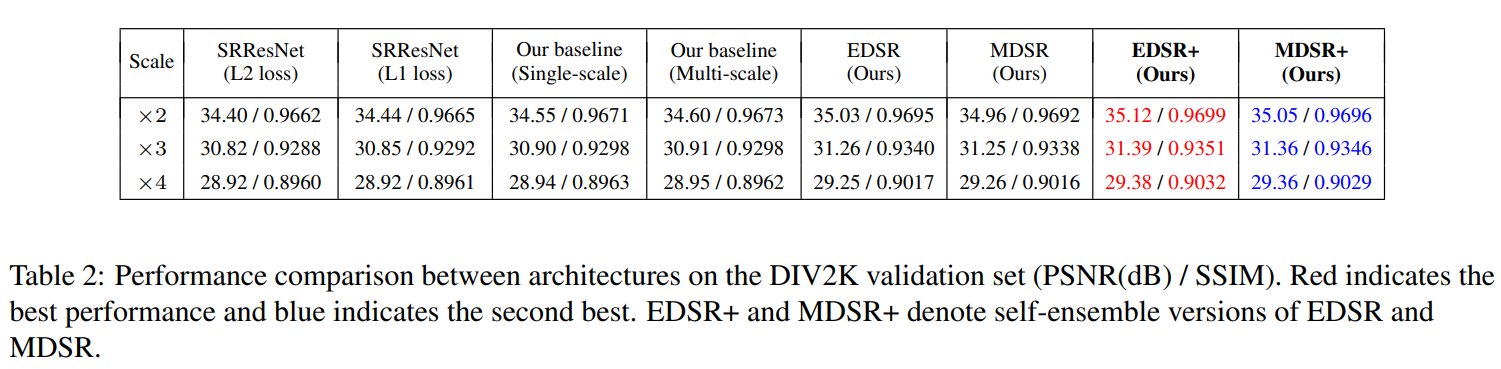
- Use L1 loss because it provides better convergence than L2 (Usually use L2 to maximizes the PSNR)
- to generate seven augmented inputs trough flip and rotate the input image. > apply inverse transform to those output images and average the transformed outputs all together to make the self-ensemble result.
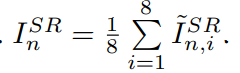
Train
DIV2K를 이용해서 train
-
conda activate EDSR-pytorch
git clone https://github.com/sanghyun-son/EDSR-PyTorch -
Readme. 절차를 따라 진행

-
src의 option.py에서 아래와 같이 수정
 으로 data path입력 (Desktop에 DIV2K.tar의 압축을 해제한 DIV2K 폴더가 위치)
으로 data path입력 (Desktop에 DIV2K.tar의 압축을 해제한 DIV2K 폴더가 위치) -
실행

Test1
-
sudo.sh 에서 Test your own images를 이용

-
결과 (unknown)


-
결과 (bicubic)




Test2 (Use own image)
-
에러
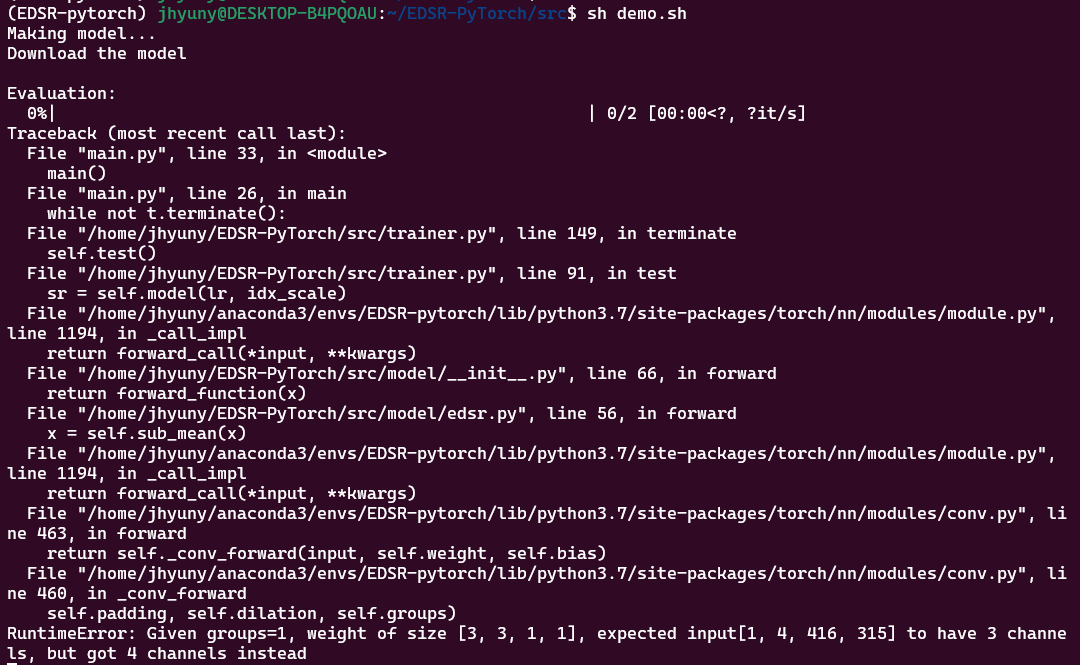
- RuntimeError: Given groups=1, weight of size [3, 3, 1, 1], expected input[1, 4, 416, 315] to have 3 channels, but got 4 channels instead
- pytorch의 경우 NCHW dimension으로 데이터를 처리. channel이 4로 입력됨.
- lr의 두번째 요소를 항상 3으로 고정시켜서 해결
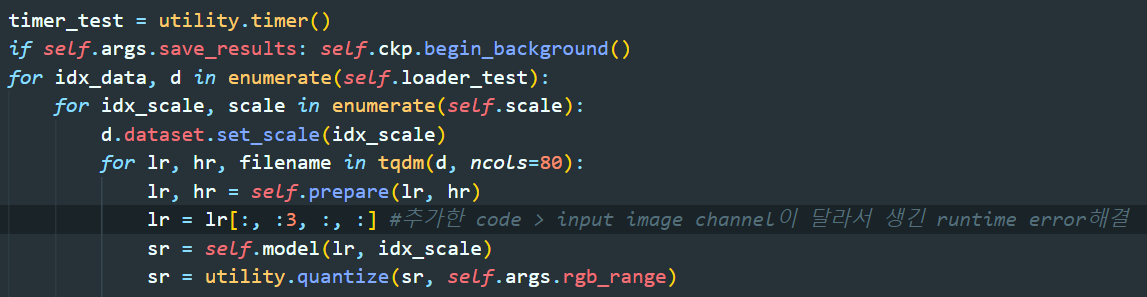 참고 링크
참고 링크
-
결과
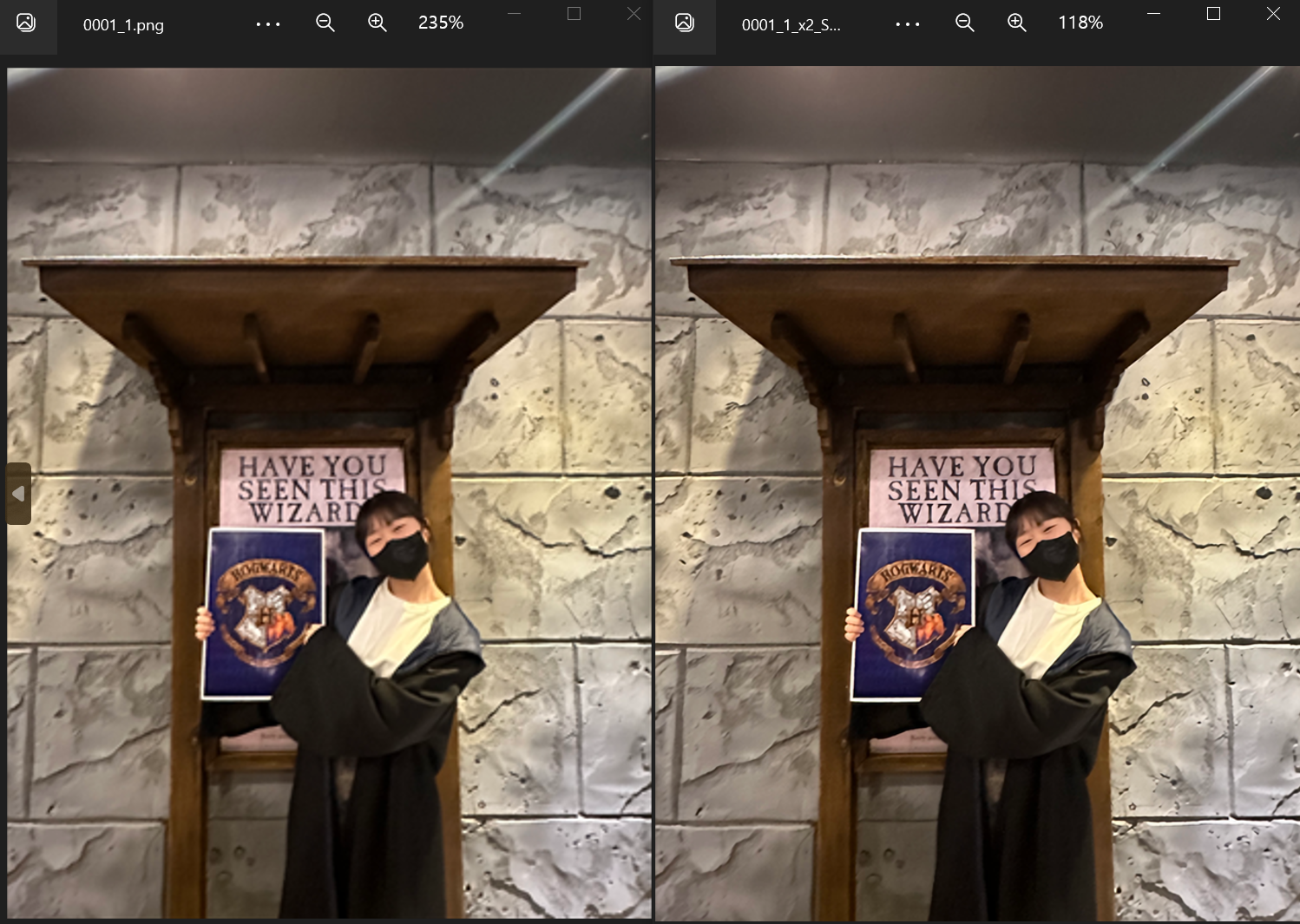
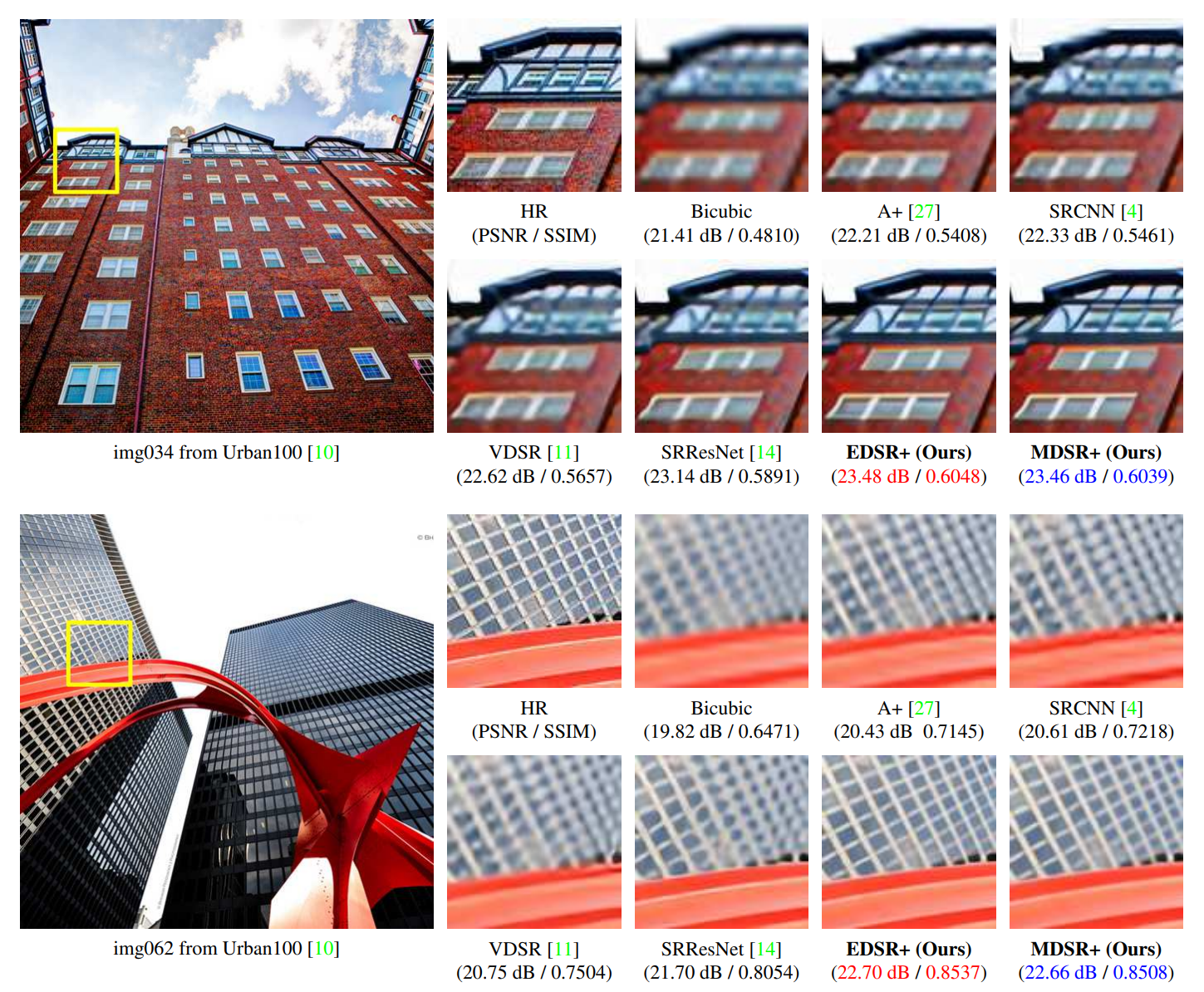
배율을 참고하면 scale 2 model로 학습해서 2배가 확대 되었음을 알 수 있다.

Department of Artificial Intelligence, EWHA