
ShuffleNet.V1 논문 바로가기
ShuffleNet.V2 논문 바로가기
V1 참고 영상
V2 참고 영상
V2 Github
참고 자료(경량화를 위한 다양한 종류의 convolution)
ShuffleNet V1
Idea
- 기본적으로 Mobilenet의 구조를 사용
- Depthwise separable convolution (MobileNet참고)
- Grouped convolution (from ResNext) : 연산량 감소를 목적(MobileNet에서 1x1 convolution이 대부분을 차지하여 연산량을 감소 + 추가적으로 1x1 convolution을 더 줄이려함)
- Channel shuffle : 3x3 group convolution에서 발생하는 문제점(채널 간의 정보 교환이 어려워서 많은 정보를 이용 불가 > 독립적인 network 여러 개를 학습시키는 꼴 > 표현력 감소) 해결
Grouped convolution + Channel shuffle
- 1x1 convolution layer에서 채널 일부만 고려하되 모든 채널을 고려하기 위해 중간중간 채널을 섞는다.
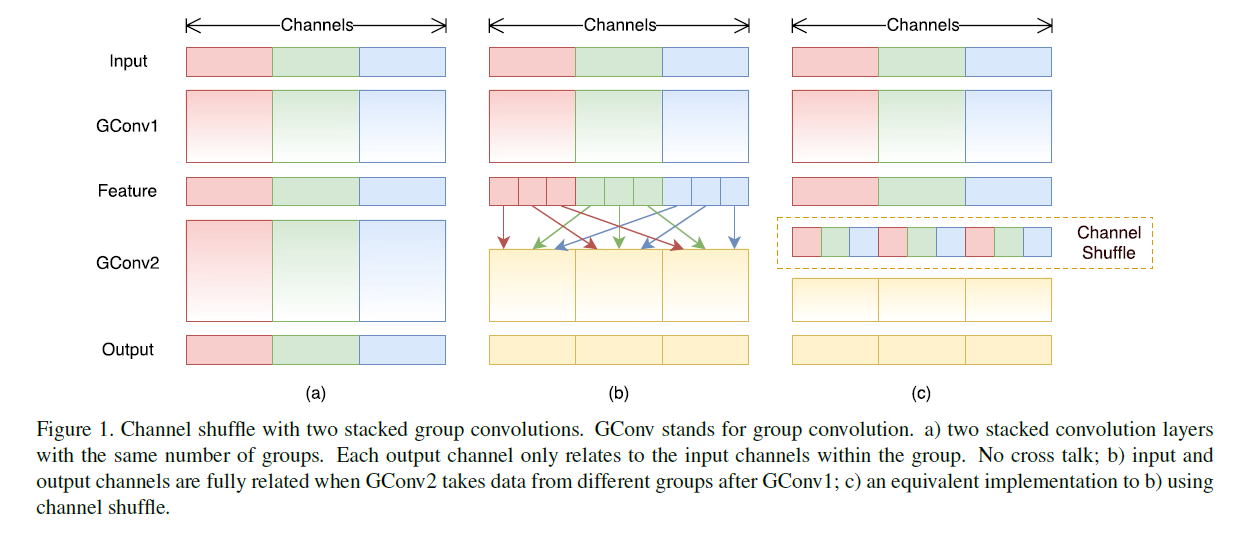 마구잡이로 섞는 것이 아닌, 모든 그룹이 한 번씩 포함할 수 있게(Figure 1. (c)참고) 섞는다.
마구잡이로 섞는 것이 아닌, 모든 그룹이 한 번씩 포함할 수 있게(Figure 1. (c)참고) 섞는다.
ShuffleNet Units (제한된 연산량 내에서 더 많은 input data를 활용 가능)
 (b,c가 ShuffleNet에서 사용하는 Unit)
(b,c가 ShuffleNet에서 사용하는 Unit)
a : MobileNet에 residual connection을 추가한 형태 (Depthwise convolution을 사용하는 BottleNeck 구조)
b : a의 첫번째 Conv > Grouped conv로 변환, channel shuffle, ReLU는 첫번째 layer 뒤에만 사용
c : b와 같은 형태이지만 stride를 2로 > size를 절반으로 줄인 후 residual 3x3 average pooling과 concatenation + ReLU > 원상태로 복구
Architecture
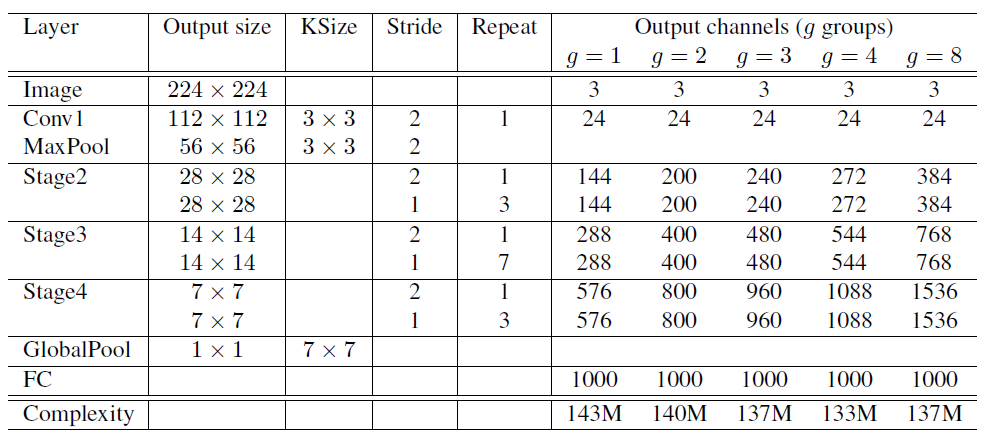
- stride 2는 위 그림에서 C unit을 사용한 것을 의미한다.
- group을 많이 나눈만큼 연산량이 줄어드는데 (채널 수가 줄어듦) 출력 채널 수를 늘려서 일정한 complexity로 맞춰준다.
Result
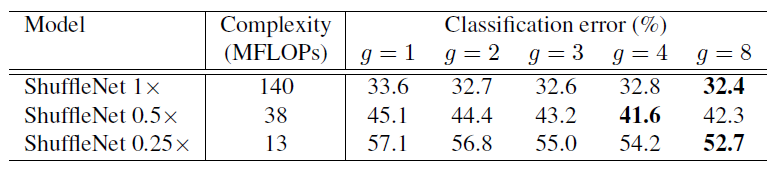
- filter 수를 scaling한 것에 따른 model 간 비교 : 채널 수가 적을 수록 complexity 감소 (error는 증가함)
- 더 작은 model일 수록 group 수에 따른 성능 변화가 큰 것을 확인할 수 있다. group 수가 늘 수록 error가 감소하는 것은 모든 model에서 확인 가능
ShuffleNet V2
차이점
- FLOPS(CNN에서 Conv간의 모든 연산의 총합) 외에도 memory access cost, gpu, arm device 등 플랫폼에 따른 다른 요소들도 고려
- 기본적으로 FLOPS는 직접적인 지표, 속도, latency 측면에서는 간접적인 지표(정확히 반비례하지 않기 때문에)
Guiedline
(FLOPS)
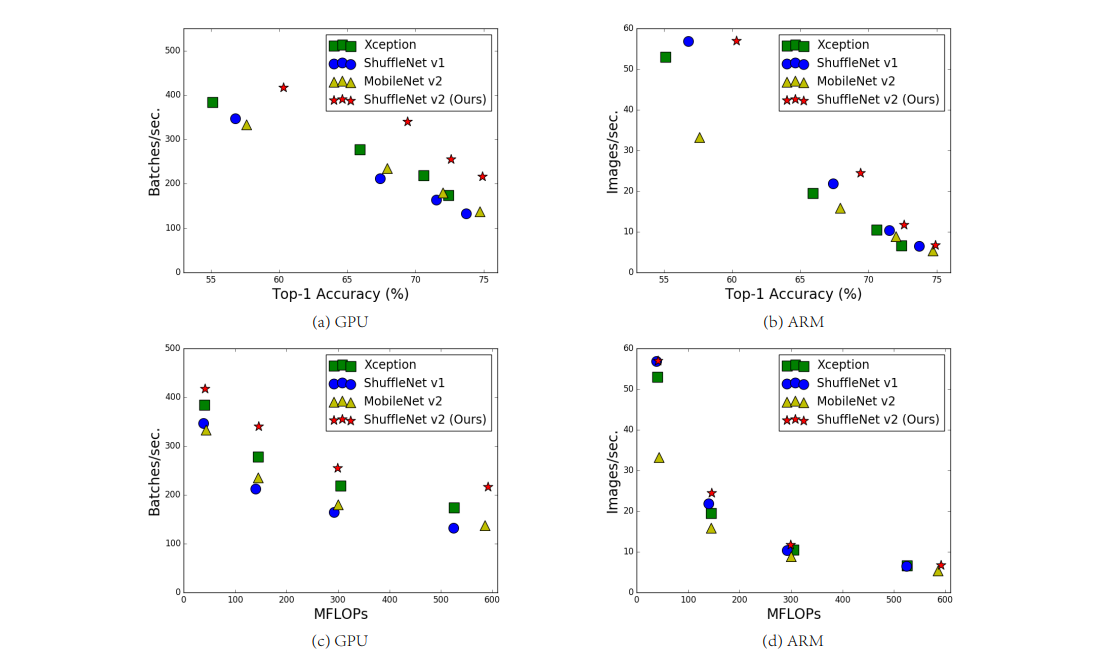
- FLOPS가 속도에 영향을 미치는 메모리 접근 비용, 병렬 정도 등을 고려하여 그 간극을 좁힌다. 같은 연산이어도 플랫폼마다 실행 시간에서 차지하는 비중이 다르기때문에.
- 따라서 연산량(FLOPS)가 아닌 inference speed에 집중한다.
1. Equal channel width minimizes memory access cost (MAC)
- 1x1 Convolution에서 입력 c1, 출력 c2, 크기 h,w일 때 FLOPS는 hwc1c2
- 이 때 MAC는 연산을 위해 입출력 feature map에 접근하고, 연산을 위한 kernel에 접근 > 1x1 Conv MAC는 hw(c1+c2) + c1c2
- 이러한 조건 하에 실험해본 결과 c1과 c2가 거의 같을 때 가장 빠른 것을 확인할 수 있다.
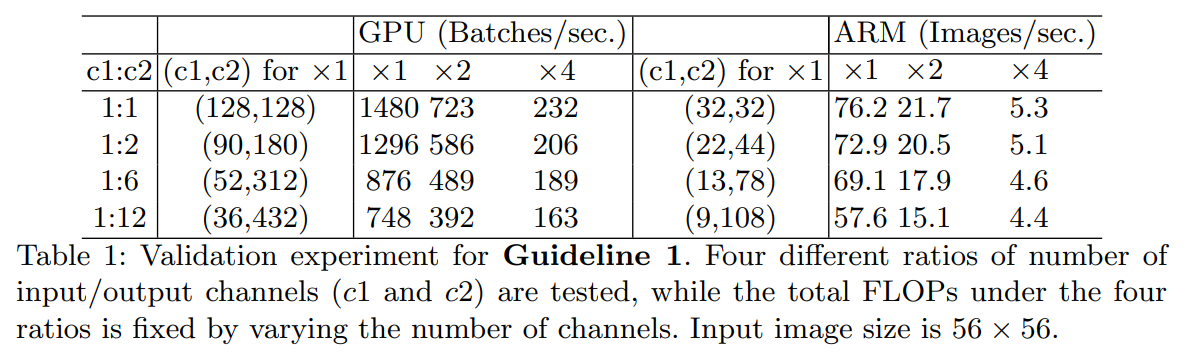
2. Excessive group convolution increases MAC
- grouped convolution을 사용할 때 FLOPS = FLOPS/g, MAC는 hw(c1+c2) + c1c2/g가 된다. 따라서 feature map이 고정되어 있을 때 g가 증가하면 MAC가 증가하므로 g값이 증가하면 속도가 급감한다.
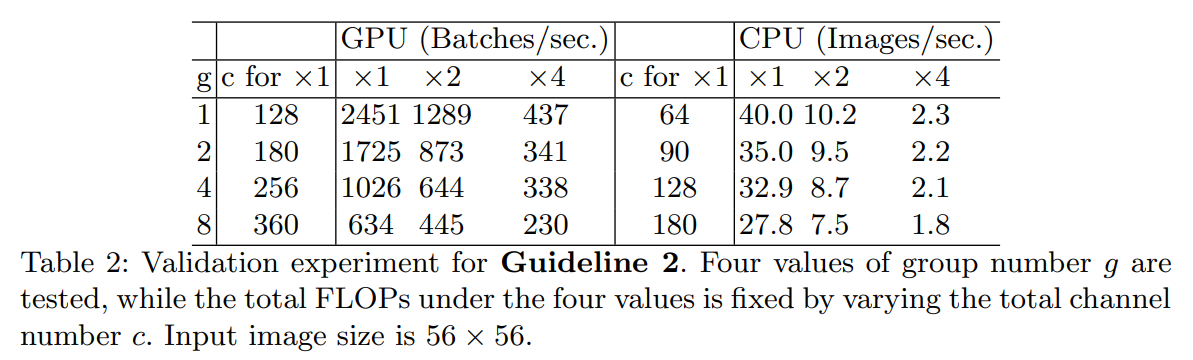
3. Network fragmentation reduces degree of parallelism
- Network fragmentation은 작은 연산(Conv,pooling operator을 의미)으로 쪼개는 것으로 GPU같은 병렬 계산에 특화된 플랫폼에서는 overhead가 발생
- fragment 수를 조절하여 실험한 결과 4-frag가 1-frag에 비해 속도가 감소한 것을 볼 수 있다.

4. Element-wise operations are non-negligible
- Element-wise operations는 각 tensor element 각각에 대한 계산으로 ReLU, tensor or bias 더하기 등이 포함 T(n)에 영향을 미친다
- 작은 FLOPS 대비 MAC가 높은 것으로 depthwise Conv도 같은 특징을 갖는다.
- ReLU와 shortcut을 제거했을 때의 속도를 보면 둘 다 제거했을 때 20%의 속도 향상을 확인할 수 있다.

ShuffleNet V2 Unit
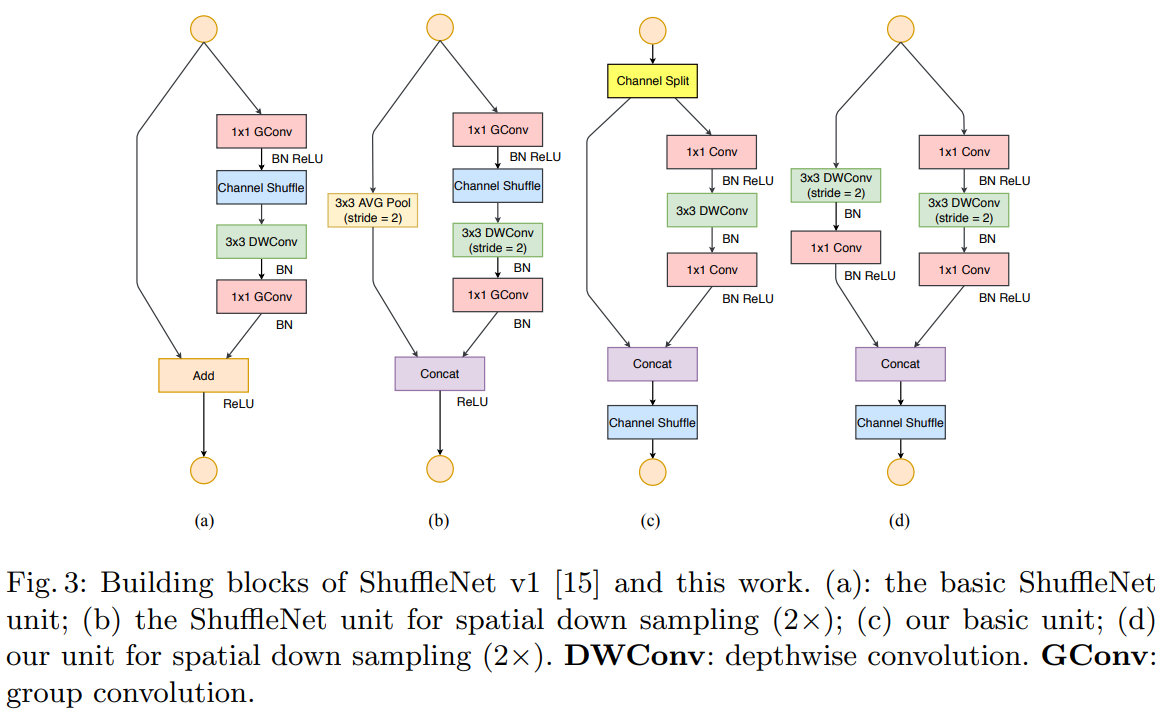 a, b : 기존의 ShuffleNet Unit c, d : SuffleNet V2 Unit
a, b : 기존의 ShuffleNet Unit c, d : SuffleNet V2 Unit
차이점
- 입력 단에서 channel split이 존재 > 입력 featur map을 절반으로 나눈다.
- 1x1 Conv에 grouped Conv적용 x > channel split에서 이미 수행
- 오른쪽 1x1 Conv, 3x3 DWConv, 1x1 Conv는 MAC에 의해 c1 = c2로 만드는 역할 수행
- elementwise operation인 add 대신 concat을 진행 후 channel shuffle 수행
- d는 입력 사이즈를 줄이면서 feature 개수를 2배로 증가시키기위해 channel split이 삭제 >> 이건 왜?
Architecture

- 마지막에 Global avg pooling에 1x1 Conv를 추가하여 feature들을 섞는다
- 입력의 절반 feature가 다음 block에 사용 > DenseNet이나 CondenseNet의 feature reuse와 동일 개념으로 block 간의 거리가 멀어지면 영향력이 감소하므로 feature redundancy를 줄일 수 있다.
Performance

- SE block과 residual을 사용하여 large model만들 수 있다. 위는 large model의 성능 비교

Department of Artificial Intelligence, EWHA