오늘 한줄 요약
- 내가 입력한 대로 그래프가 그려지는게 신기하고 재미있다..!! 하지만, 가끔 튀어나오는 error를 바로 해결하지 못할 때 무척...당황스럽다..😱
0. 시작 전 설정
📌
# ★matplotlib 기본 설정★
import matplotlib.pyplot as plt
import matplotlib as mpl
# 마이너스 부호가 깨지는 걸 방지하기 위한설정
plt.rcParams["axes.unicode_minus"] = False
# ▼ 한글 설정을 위한 명령 코드
from matplotlib import rc
rc("font", family="Malgun Gothic")
get_ipython().run_line_magic("matplotlib", "inline")
1. 데이터 훑어보기
■ CCTV_Seoul 데이터
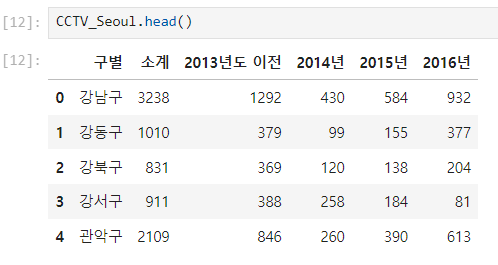
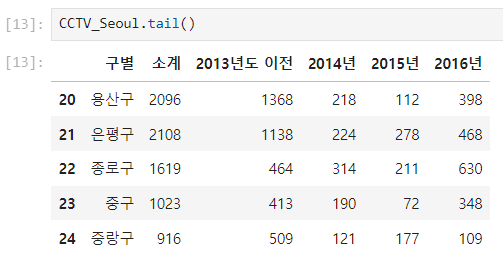
.head(), .tail() : 데이터 보기
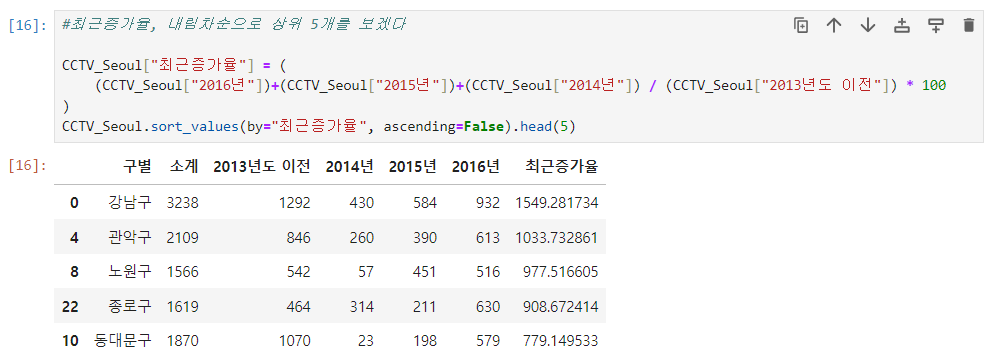
- 상위 5개의 데이터 확인
- 하위 5개의 데이터 확인
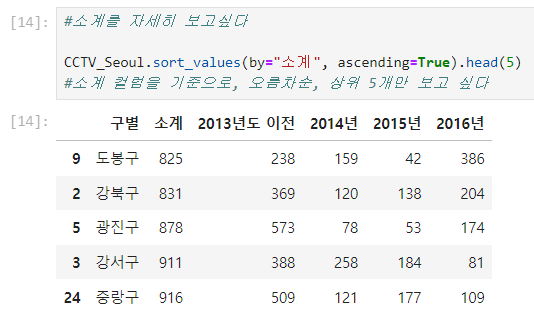
.sort_values() : '특정 컬럼' 만 보기
- .sort_values(by="소계")
파일명[추가컬럼] = () : 컬럼 추가/기존 수정

ascending=True : 내림차순 상위 5개 보기
- ascending=False (내림차순)
- ascending=True (오름차순)
■ pop_Seoul 데이터
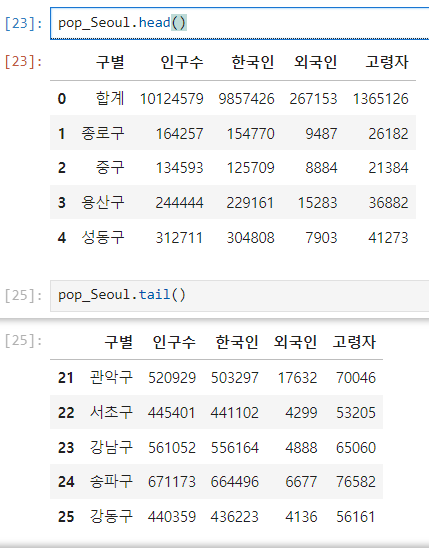
.head() : 데이터 보기
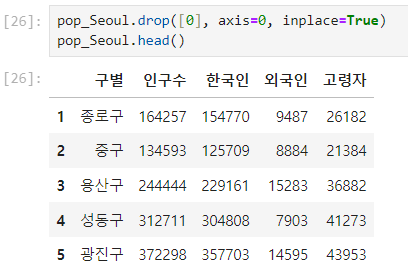
.drop() : [0]번 컬럼 삭제
- drop([0], axis=0, inplace=True)
- drop(삭제 컬럼, 가로줄, 저장)
- axis=0(가로), axis=1(세로)
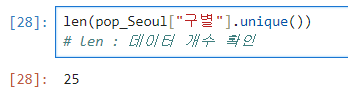
.unique() : 데이터 확인 (중복 X)

len() : 데이터 수 확인
파일명[추가컬럼] = () : 컬럼 추가/기존 수정
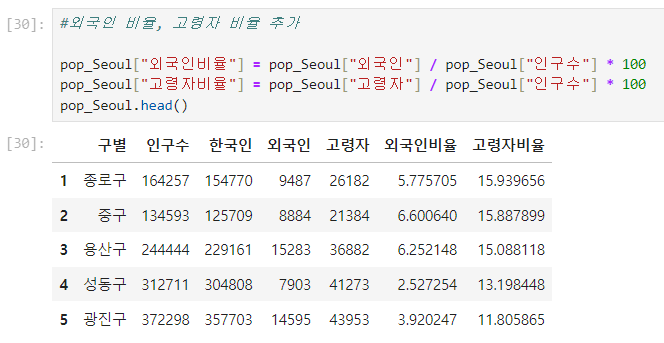
.sort_values([""], ascending=False).head() : 특정컬럼 내림차순 확인
- ascending=False (내림차순)
- ascending=True (오름차순)
2. Pandas 데이터 합치기
데이터 만들기
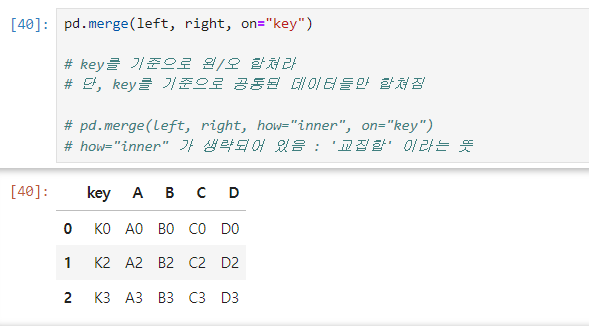
pd.merge() : 합치기
- ⭐
pd.merge(A, B, how="inner", on="G"): A+B를 G를 기준으로 합친다 - 두 데이터 프레임에서 컬럼이나 인덱스를 기준으로 잡고 병합하는 방법
- 기준이 되는 컬럼이나 인덱스를 키값이라고 한다
- 기준이 되는 키 값은 두 데이터 프레임에 모두 포함되어 있어야 한다
how="inner" : 합친 그래프 > 교집합 출력
- pd.merge(left, right, 📌
how="inner", on="key") - how="inner" : '교집합', 동일한 값만 출력
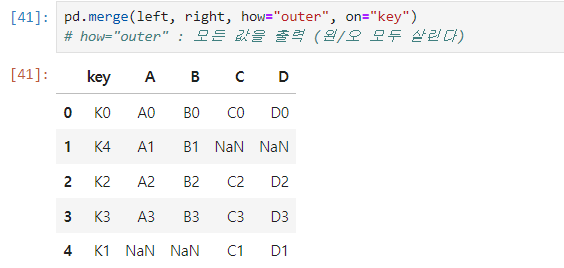
how="outer" : 합친 그래프 > 모든 값 출력(NaN)
- pd.merge(left, right, 📌
how="outer", on="key") - how="outer" : 모든 값을 출력 (A, B 모두 살린다)
- 모두 출력 시 없는 값의 경우 'NaN'으로 출력
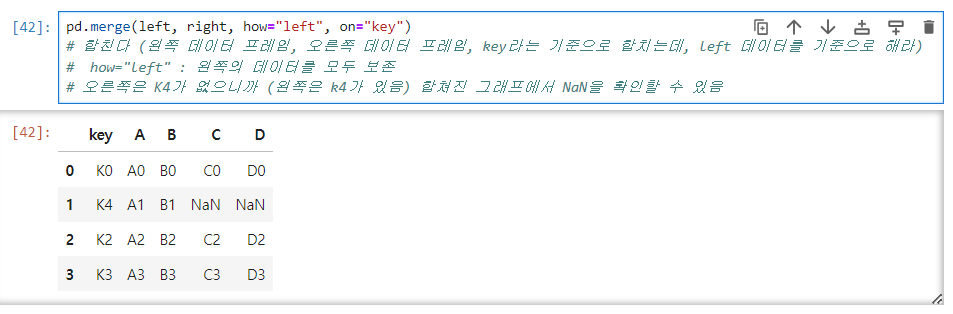
how="A", on="key" : A그래프 값 모두 보존, key 값 기준
- how="left" : 왼쪽의 데이터를 모두 보존
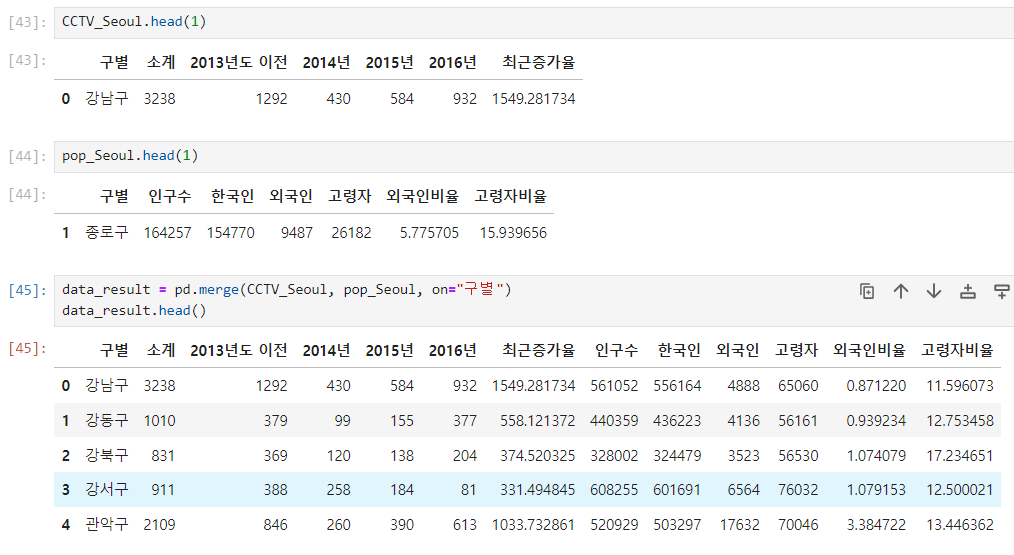
pd.merge(on="A") : A인덱스로 데이터를 합침
- CCTV_Seoul, pop_Seoul 데이터를
- on="구별" 인덱스를 기준으로 합쳐서 정렬
del 파일명[삭제값] : 컬럼 삭제
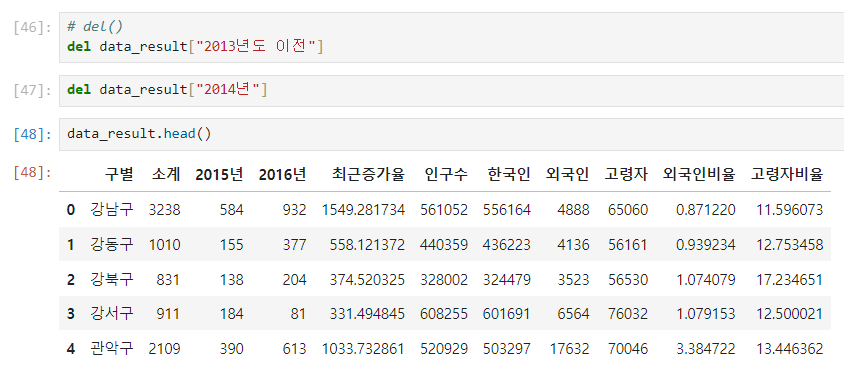
파일명.drop([삭제값], axis=0/1, inplace=True) : 컬럼 삭제
- data_result.삭제(2015. 2016 데이터, 세로값(가로:axis=0),객체들 저장)
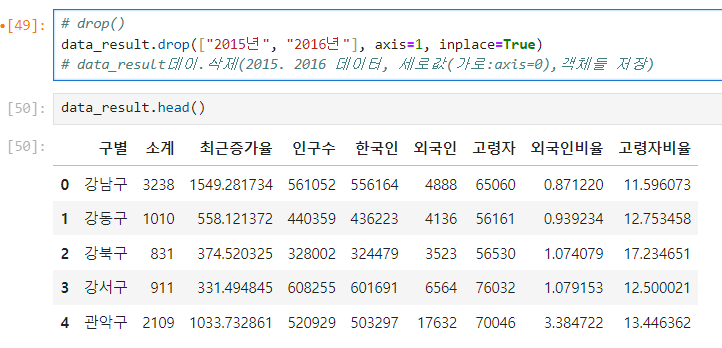
set_index() : index로 지정
- 선택한 컬럼을 데이터 프레임의 인덱스로 지정
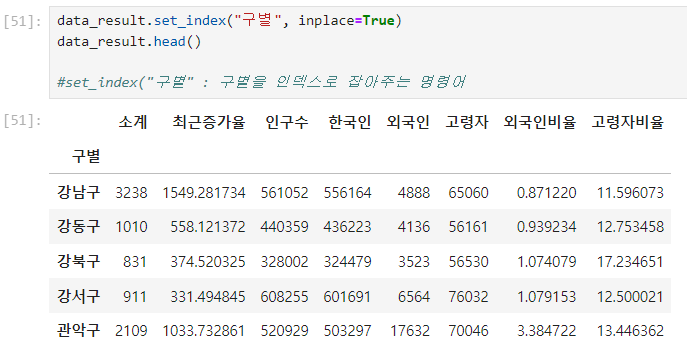
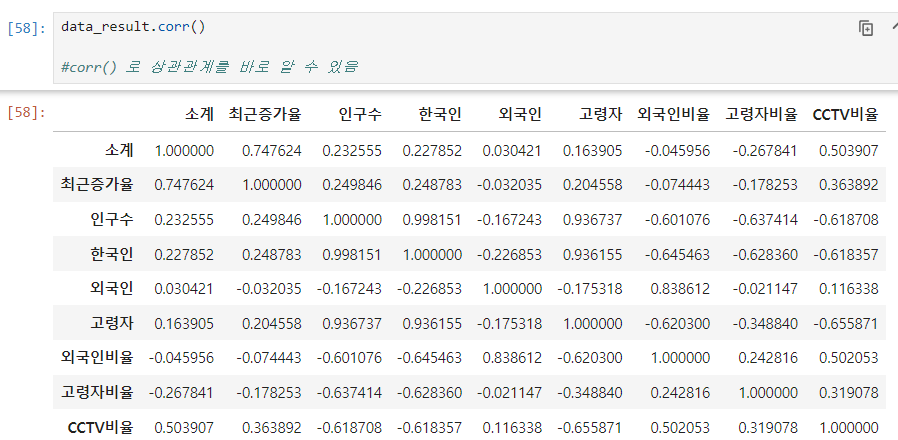
파일명.corr() : 상관계수 확인
- corr() : correlation의 약자
- 상관계수가 0.2 이상인 데이터를 비교
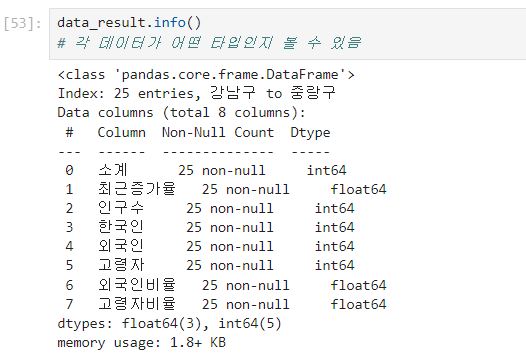
파일명.info() : 데이터 타입 확인
'비율' 컬럼 만들기
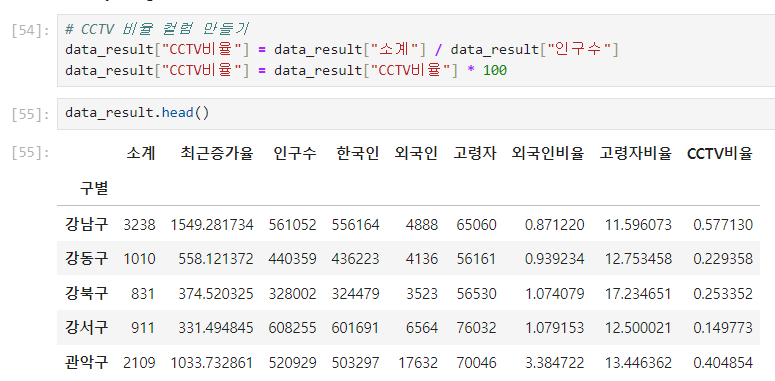
'비율' 기준 내림차순 정렬
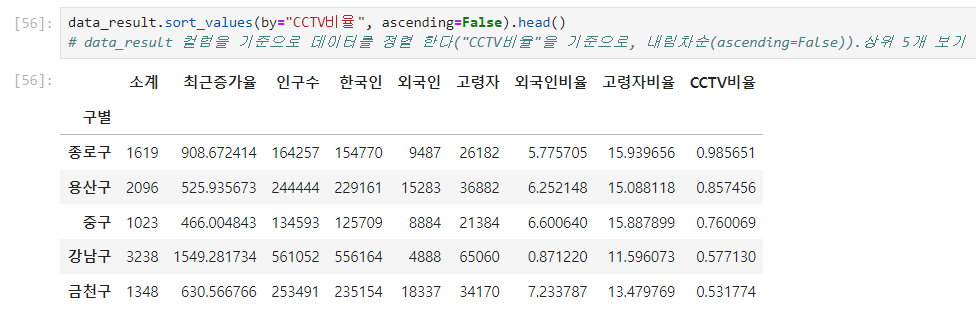
3. Matplotlib
[📌이전 자료 참고] : https://velog.io/@jaam_mini/EDA-matplotlib-Seaborn-기초
4.데이터 시각화 (그래프로 표현하기)
.head() : 데이터 확인
특정 'A'컬럼 시각화
data_result["소계"].plot(kind="barh", grid=False, figsize=(8,8));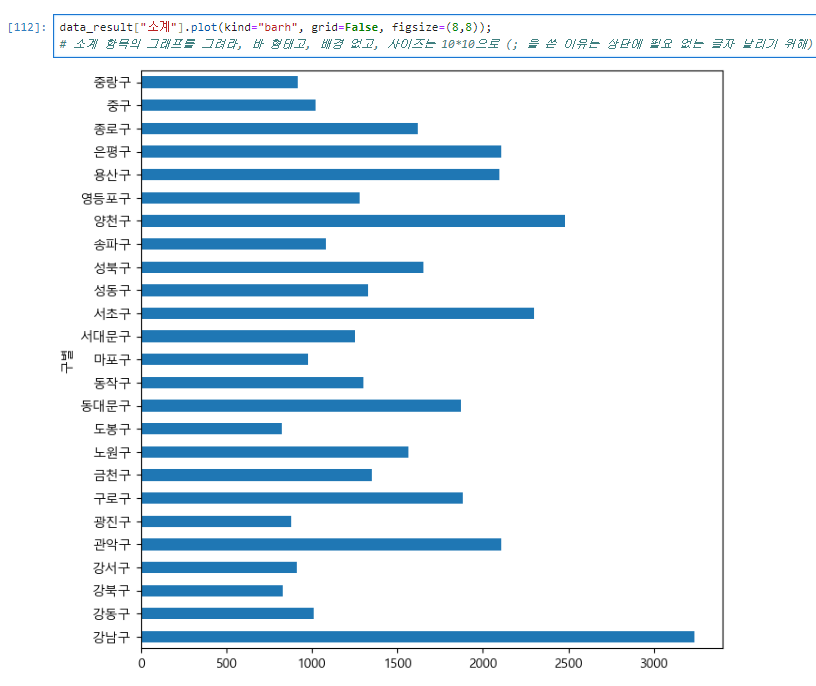
B[A].sort_values().plot() : B데이터의 'A'컬럼 "내림차순" 시각화
data_result["소계"].sort_values().plot(kind="barh", grid=False, figsize=(8,8));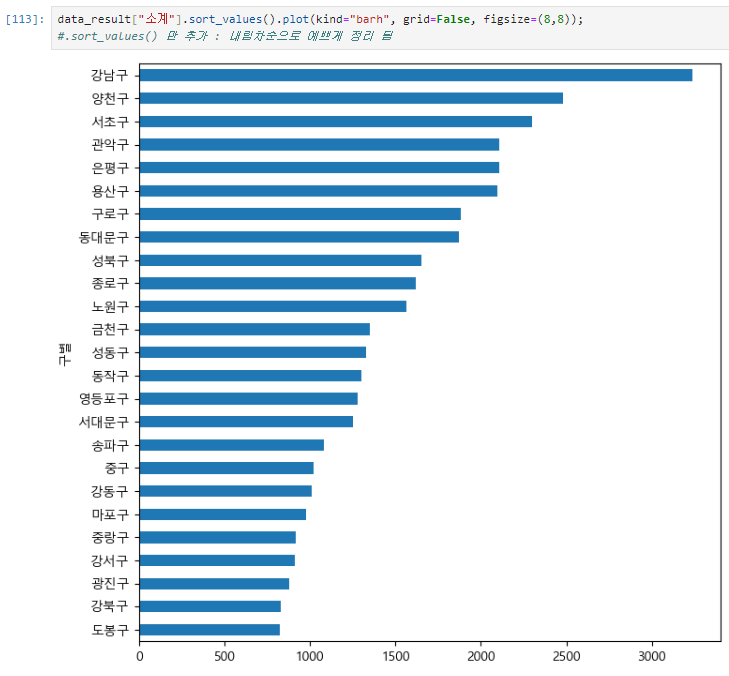
def 그래프 함수 ⭐
def drawGraph():
data_result["소계"].sort_values().plot(
kind="barh", grid=False, figsize=(10,10));
drawGraph()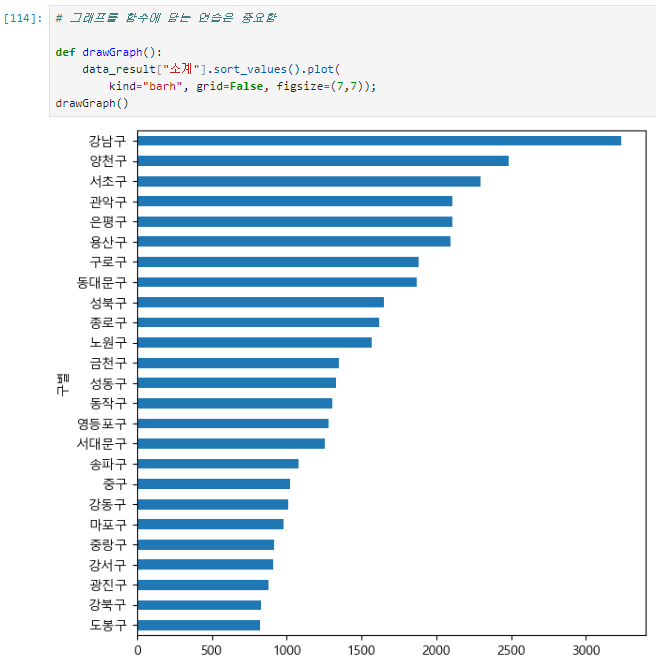
title="" : 제목 붙이기
def drawGraph():
data_result["소계"].sort_values().plot(
kind="barh", grid=False, title="가장 CCTV가 많은 구", figsize=(7,7));
drawGraph()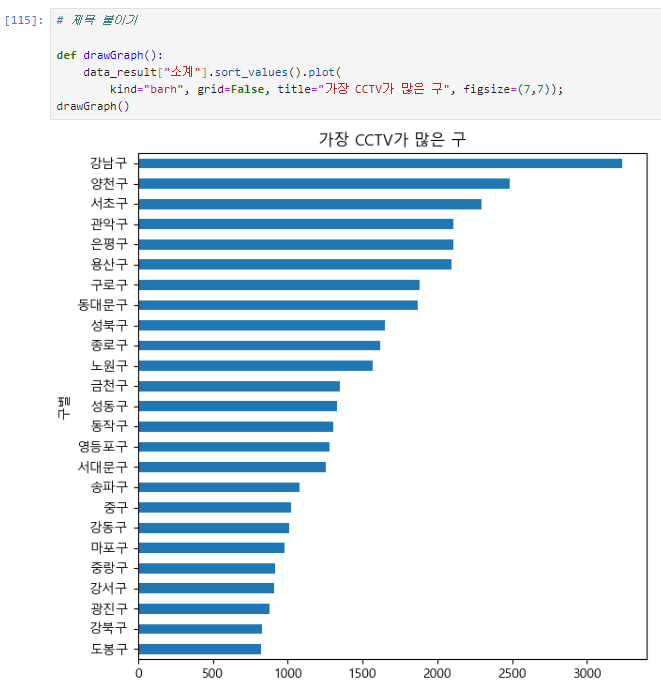
B[A].sort_values().plot() : B데이터의 'A'컬럼 "내림차순" 시각화
def drawGraph():
data_result["CCTV비율"].sort_values().plot(
kind="barh", grid=False, title="CCTV비율 - 가장 CCTV가 많은 구", figsize=(10,10));
drawGraph()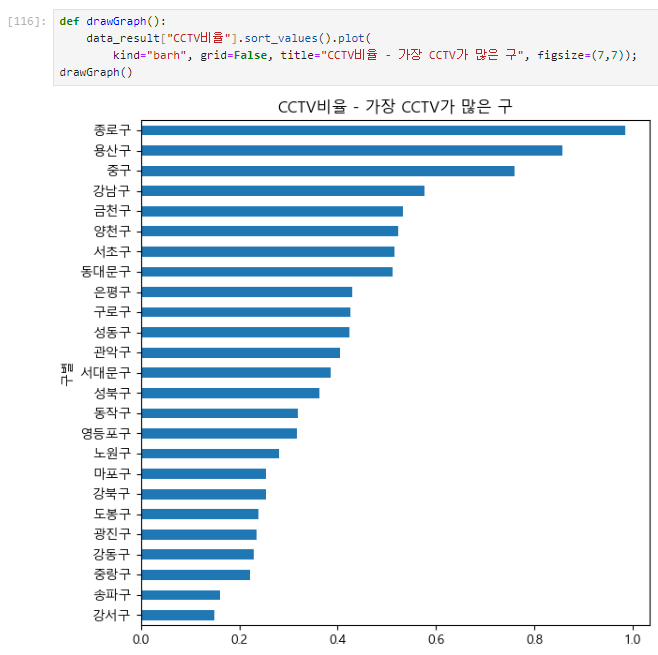
5.데이터 경향 파악
.head()
plt.scatter() : 점 그래프
def drawGraph():
plt.figure(figsize=(14,10))
plt.scatter(data_result["인구수"], data_result["소계"], s=50) #plt.scatter(x축, y축, 사이즈)
plt.xlabel("인구수") #x축 제목
plt.ylabel("CCTV") #y축 제목
plt. grid(True) #격자무늬
plt.show()
drawGraph()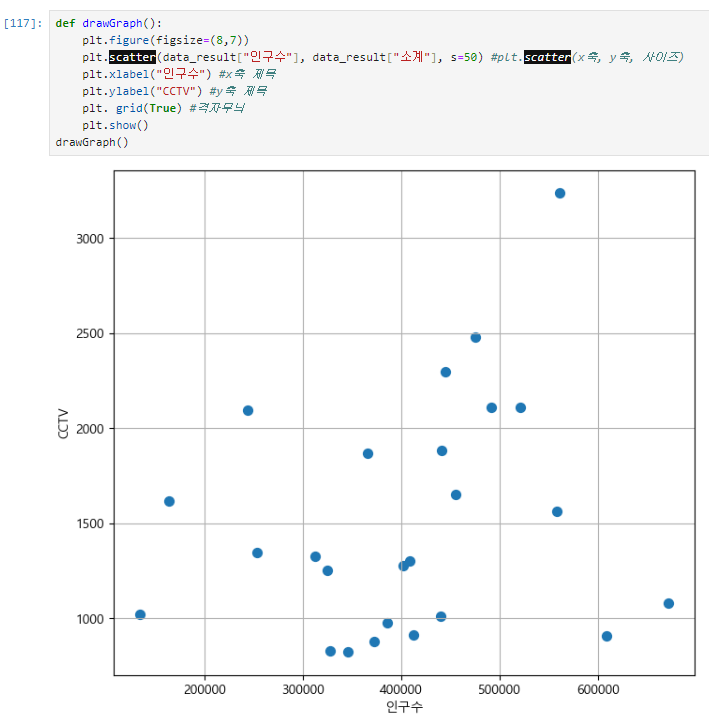
Numpy를 이용한 1차 직선
- np.polyfit() : 직선을 구성하기 위한 계수를 계산해주는 기능
- np.poly1d() : np.polyfit()로 찾은 계수를 파이썬에서 사용할 수 있는 함수로 바꿔주는 기능
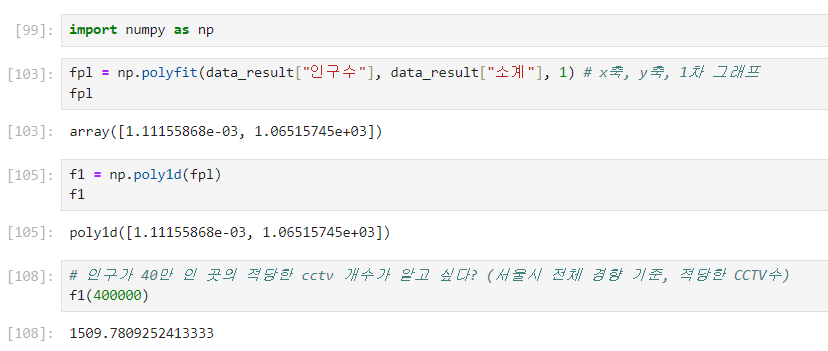

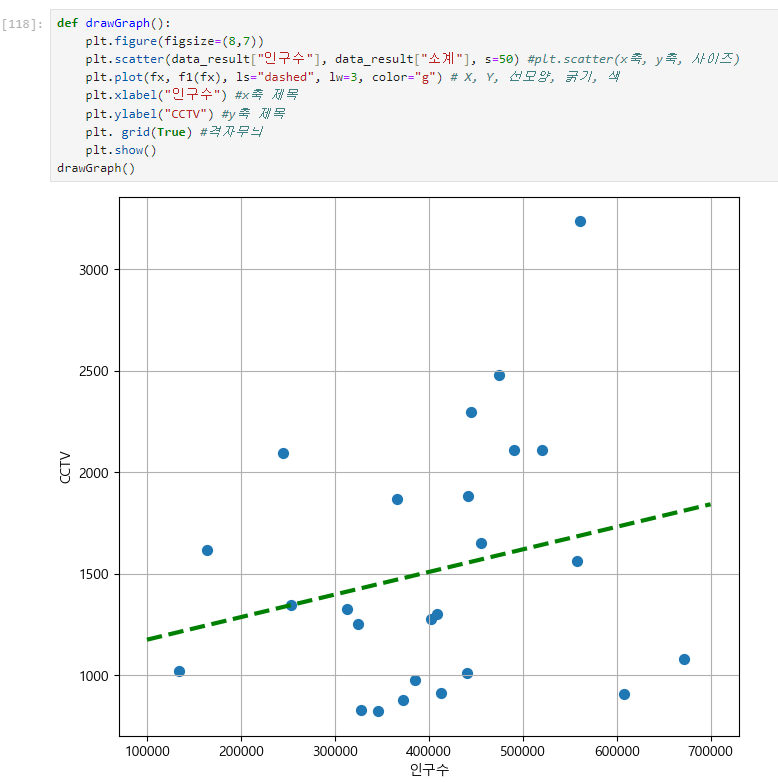
제로베이스 데이터 스쿨
데일리 학습 노트

비전공자의 데이터 공부법