1. 배경 및 문제 정의
로봇 공학에서 학습 기반 제어 정책(Learned Policies)의 가장 큰 약점은 학습 데이터의 범위를 벗어난 환경(새로운 객체, 조명, 지시어 등)에 대한 일반화(Generalization) 능력이 부족하다는 점입니다. 반면, 인터넷 규모의 데이터로 사전 학습된 비전-언어 파운데이션 모델(VLMs, e.g., CLIP, Llama)은 우수한 일반화 및 추론 능력을 보유하고 있습니다.
기존 연구들은 이러한 VLM을 로봇의 표현 학습(Representation Learning)이나 모듈형 시스템의 고수준 계획(Task Planning)에 간접적으로 통합하거나, 로봇의 제어 명령을 직접 출력하는 비전-언어-행동 모델(Vision-Language-Action, VLA) 형태로 발전시켜 왔습니다. 특히 RT-2-X와 같은 기존 VLA 모델들은 새로운 시각적 환경과 언어 지시어에 대해 뛰어난 제어 능력을 보여주었습니다.
그러나 기존 VLA 방법론은 두 가지 치명적인 한계를 지닙니다. 첫째, 현재 가장 뛰어난 성능을 보이는 모델들은 대부분 비공개(Closed) 상태로, 아키텍처나 학습 데이터 구성에 대한 접근이 불가능합니다. 둘째, 새로운 로봇 하드웨어나 작업 환경에 모델을 이식하기 위한 효율적인 파인튜닝(Fine-tuning) 방법론이 제대로 연구되지 않았습니다.
이 논문은 이러한 문제를 해결하기 위해 70억 개(7B)의 매개변수를 가지는 오픈소스 일반화 VLA 모델인 OpenVLA를 제안합니다. 이는 대규모의 Open X-Embodiment 데이터셋을 활용하여 기존 비공개 모델들을 능가하는 제어 성능을 확보함과 동시에, 일반적인 소비자용 GPU 환경에서도 효율적인 학습과 추론이 가능한 파이프라인을 구축하는 것을 핵심 목표로 합니다.
2. 제안 방법 (Method)
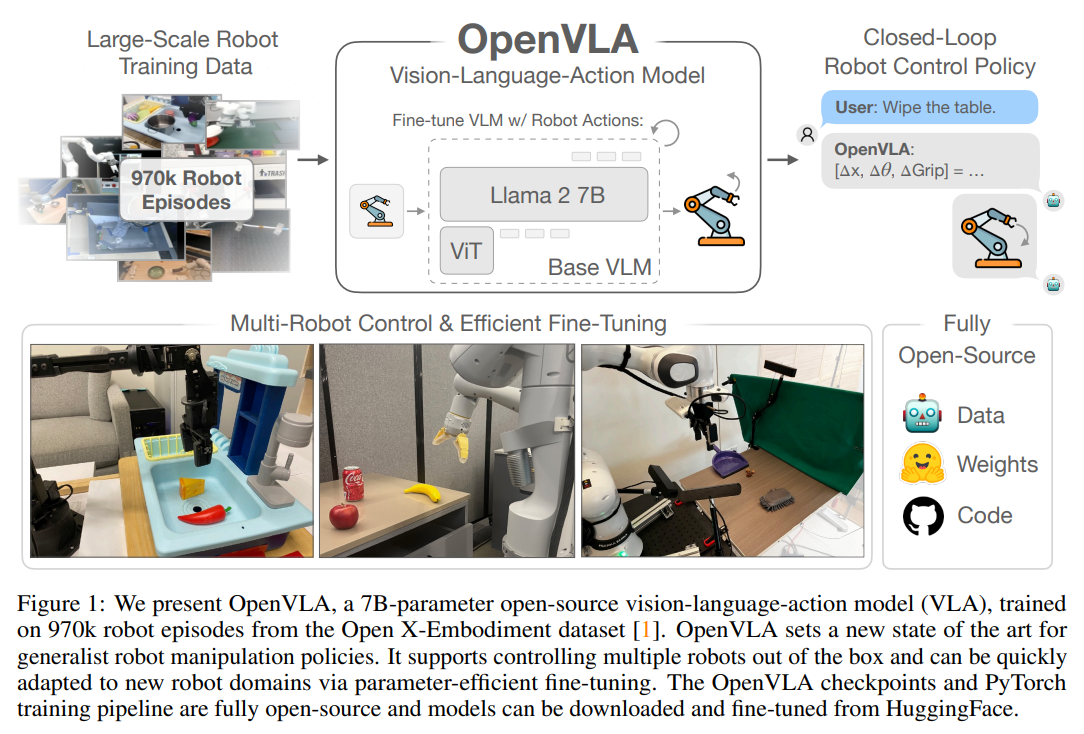
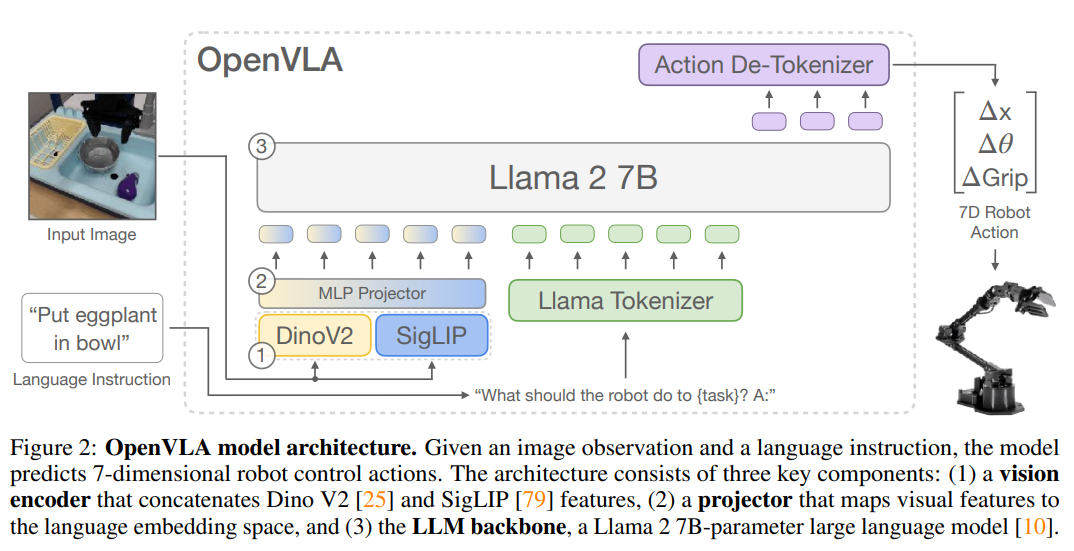
OpenVLA의 핵심 아이디어는 로봇의 연속적인 제어 명령을 언어 토큰으로 변환하여, 로봇 제어 문제를 '비전-언어 모델의 다음 토큰 예측(Next-Token Prediction)' 문제로 치환하는 것입니다.
입력 데이터의 표현 및 전처리 방식
모델은 해상도의 단일 이미지 관측값과 자연어 작업 지시어를 입력으로 받습니다. 로봇의 행동은 7차원(3D 위치, 3D 회전, 그리퍼 개폐)의 연속형 벡터 공간 에 존재합니다. OpenVLA는 각 행동 차원 를 256개의 구간으로 이산화(Discretization)합니다. 극단적인 이상치(Outlier)로 인해 해상도가 떨어지는 것을 방지하기 위해, 단순히 최솟값과 최댓값을 기준으로 삼지 않고 학습 데이터의 1분위수(1st quantile)와 99분위수(99th quantile) 사이를 256개의 균등한 구간으로 나눕니다. 이 과정을 거쳐 연속형 제어 명령은 범위의 이산 정수형 토큰으로 변환됩니다. Llama 2 토크나이저의 어휘(Vocabulary) 확장에 따른 복잡성을 피하기 위해, 사용 빈도가 가장 낮은 마지막 256개의 기존 토큰을 해당 행동 토큰으로 덮어씌워 매핑합니다.
네트워크 아키텍처의 구성
OpenVLA는 Prismatic-7B VLM을 백본으로 사용하며, 크게 세 가지 구조로 이루어져 있습니다.
1. 시각 인코더 (Vision Encoder): 고수준의 의미론적(Semantic) 특징을 추출하는 SigLIP과 저수준의 공간적(Spatial) 특징을 포착하는 DINOv2를 결합(Fusion)한 600M 파라미터 구조입니다. 각 인코더에서 추출된 패치 특징은 채널 단위로 결합(Concatenation)되어 로봇 제어에 필수적인 공간 지각 능력을 극대화합니다.
2. 프로젝터 (Projector): 2계층의 MLP로 구성되어 시각적 특징 벡터를 언어 모델의 임베딩 차원으로 투영합니다.
3. 언어 모델 백본 (LLM Backbone): Llama 2 7B 아키텍처를 사용하여 이미지 패치 토큰과 언어 지시어 토큰을 바탕으로 행동 토큰을 자기회귀적(Autoregressive)으로 생성합니다.
학습(Training) 파이프라인
학습은 Open X-Embodiment 데이터셋에서 선별한 970,000개의 로봇 궤적 데이터를 활용합니다. 기존 VLM 학습과 달리 시각 인코더를 동결(Freeze)하지 않고 전체 네트워크를 엔드투엔드(End-to-End)로 파인튜닝합니다. 손실 함수는 예측된 행동 토큰에 대해서만 교차 엔트로피 손실(Cross-Entropy Loss)을 적용합니다.
여기서 는 입력 이미지, 은 언어 지시어, 는 이전에 예측된 행동 토큰을 의미합니다. 학습률(Learning rate)은 로 고정하고, 총 27 에포크(Epoch)를 학습하여 일반적인 VLM 학습 대비 훨씬 긴 기간 동안 로봇 제어 데이터를 학습시킵니다.
추론(Inference) 및 적응(Adaptation) 파이프라인
새로운 로봇 환경에 모델을 이식할 때, 전체 파라미터를 업데이트하는 대신 선형 계층(Linear layers)에 저랭크 적응(LoRA, Low-Rank Adaptation, ) 기법을 적용합니다. 이를 통해 전체 파라미터의 단 1.4%만 학습하면서도 전체 파인튜닝과 동등한 성능을 냅니다. 추론 단계에서는 생성된 토큰 시퀀스를 다시 연속형 행동 공간으로 역변환(De-tokenization)하여 제어 명령으로 사용합니다. 특히 4-bit 양자화(Quantization)를 적용하여 VRAM 사용량을 7GB 수준으로 줄이면서도 소비자용 GPU(RTX 4090) 환경에서 성능 저하 없이 6Hz의 제어 주파수를 달성했습니다.
3. 실험 결과 (Experiments)
다중 로봇 일반화 및 OOD 평가
WidowX 및 Google Robot 플랫폼 환경에서, 배경, 방해 요소, 객체 외형 변경 등의 다양한 비분포(Out-of-Distribution, OOD) 상황에 대한 평가를 진행했습니다.
- OpenVLA는 기존의 최고 수준의 비공개 모델인 RT-2-X(55B) 대비 파라미터 수가 7배 적음에도 불구하고 WidowX 환경의 29개 작업에서 절대 성공률을 16.5% 향상시켰습니다.
- 처음부터 학습된 RT-1-X 및 Octo와 같은 베이스라인 모델들이 다수의 객체가 존재하는 환경에서 시각적 방해 요소에 의해 목표를 상실하는 반면, OpenVLA는 DINOv2와 SigLIP이 결합된 시각 인코더 덕분에 정확한 목표물 파악 및 자세 정렬 등 강력한 시각적 강건성을 보였습니다.
새로운 작업으로의 데이터 효율적 파인튜닝
Franka 로봇 암 환경(Franka-Tabletop 및 Franka-DROID)에서 10~150개의 데모 데이터만으로 정책을 미세 조정하는 실험을 진행했습니다. 단순 모방 학습 베이스라인인 Diffusion Policy가 단일 지시어 작업(단순 피킹 등)에서는 높은 성능을 보였으나, 다중 지시어 및 언어 기반 객체 추론이 필요한 복잡한 작업에서는 OpenVLA의 성능이 압도적이었습니다.
어블레이션 스터디 (Ablation Study)
네트워크 내 시각 인코더를 동결(Frozen)할 경우 성능이 절반 가까이 급락했으며, DINOv2 없이 SigLIP만 사용했을 때 역시 공간 정밀도가 요구되는 작업에서 성능 저하가 관찰되었습니다. 이는 사전 학습된 비전 모델의 특징(Feature)을 로봇 환경의 물리적 공간 정밀도에 맞게 재학습하는 과정이 절대적으로 필요함을 시사합니다.
4. 한계점 및 시사점
명확한 한계점
1. 관측 데이터의 제약: 현재 OpenVLA는 단일 카메라 시점의 이미지만을 관측값으로 사용합니다. 다중 시점(Multi-camera) 이미지나 로봇의 고유 수용성 감각(Proprioceptive state), 그리고 과거의 관측 기록(History)을 활용하지 못하므로 복잡한 물리적 피드백이 필요한 작업에는 한계가 있습니다.
2. 추론 속도와 동역학적 한계: 4-bit 양자화를 통해 제어 주파수를 약 6Hz 수준으로 확보했으나, 이는 ALOHA와 같은 50Hz 이상의 고주파수 제어가 필요한 동적 로봇 조작에는 적용하기 어렵습니다.
3. 행동 예측의 구조적 한계: Diffusion Policy 등에서 사용하는 행동 청킹(Action Chunking)이나 시간적 평활화(Temporal Smoothing) 기술이 적용되지 않아 섬세한 양팔 조작이나 정밀 제어에서의 움직임 부드러움이 떨어집니다.
시사점 및 의미
이 연구는 비공개로 유지되던 최고 성능의 VLA 아키텍처 구조를 7B 파라미터 수준으로 경량화하여 성공적으로 오픈소스화했다는 데 매우 큰 의미가 있습니다. 특히, 대규모 모델을 특정 로봇에 맞게 조정할 때 값비싼 클러스터가 아닌 단일 A100 GPU 환경에서도 PEFT(LoRA) 기법과 4-bit 양자화를 통해 성능 저하 없이 효율적인 파인튜닝과 추론이 가능함을 입증했습니다. 이는 후속 연구자들이 쉽게 자신들의 로봇 하드웨어에 기반 파운데이션 모델을 결합하고 확장할 수 있는 실질적인 엔지니어링 표준을 제시한 결과입니다.
