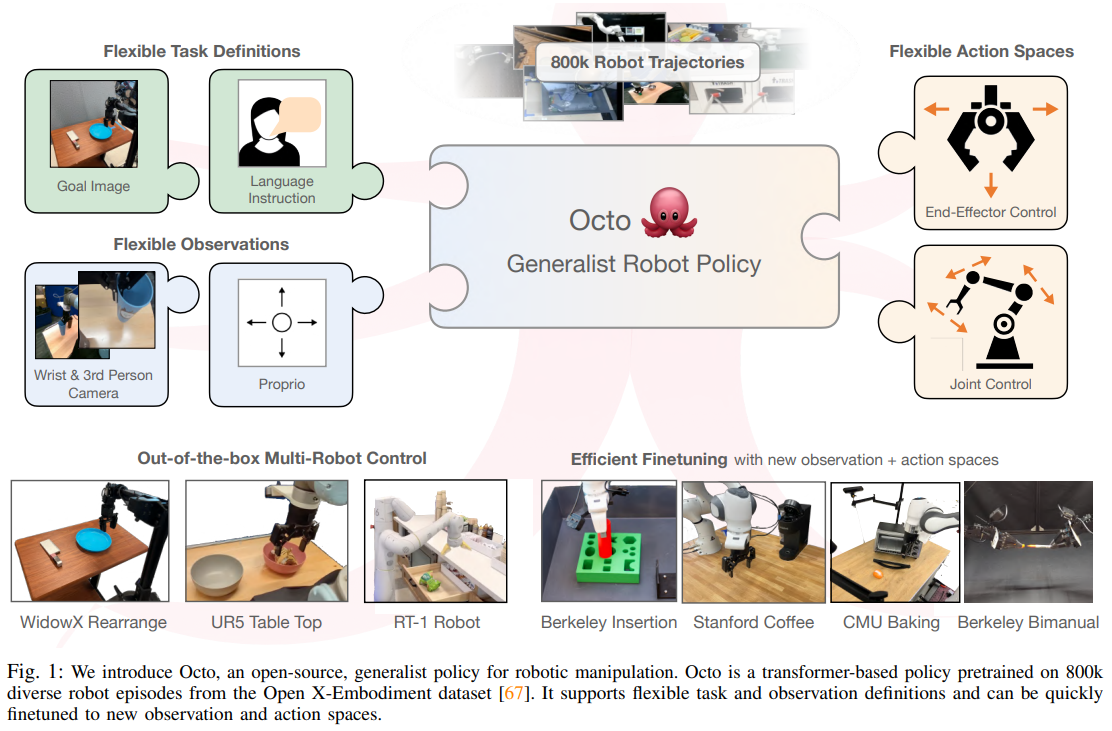
1. 배경 및 문제 정의
로봇 제어 분야에서는 특정 태스크와 환경에 종속된 정책(Policy)을 밑바닥부터 학습시키는 방식이 주를 이루었습니다. 그러나 최근 대규모 로봇 궤적 데이터를 활용하여 사전 학습(Pre-training)된 범용 로봇 정책(Generalist Robot Policies, GRPs)이 등장하며 패러다임이 변화하고 있습니다. GRP는 약간의 타겟 도메인 데이터만으로 파인튜닝(Fine-tuning)되어 새로운 환경에 일반화할 수 있는 잠재력을 가집니다.
기존의 RT-X, GNM, RoboCat과 같은 모델들은 단일 모델로 다양한 로봇과 태스크를 제어하는 데 성공하며 범용 모델의 가능성을 입증했습니다. 하지만 이들 기존 방법론은 치명적인 한계를 지닙니다. 첫째, 사전 학습에 사용된 관측(Observation) 입력과 액션(Action) 공간에 사용자를 강제로 종속시킵니다. 즉, 새로운 센서나 다른 제어 방식을 가진 로봇으로의 전이(Transfer)가 구조적으로 어렵습니다. 둘째, 사전 학습된 가중치를 활용하여 새로운 도메인으로 효율적으로 파인튜닝하는 기능이 부족합니다. 셋째, 가장 성능이 뛰어난 대규모 모델들은 오픈소스로 공개되지 않아 연구 커뮤니티의 접근이 제한적입니다.
Octo 논문은 이러한 한계를 극복하기 위해, 임의의 관측/액션 공간에 유연하게 적응할 수 있고 일반적인 소비자용 GPU 환경에서도 몇 시간 내에 파인튜닝이 가능한 완전한 오픈소스 범용 로봇 정책을 제안합니다.
2. 제안 방법 (Method)
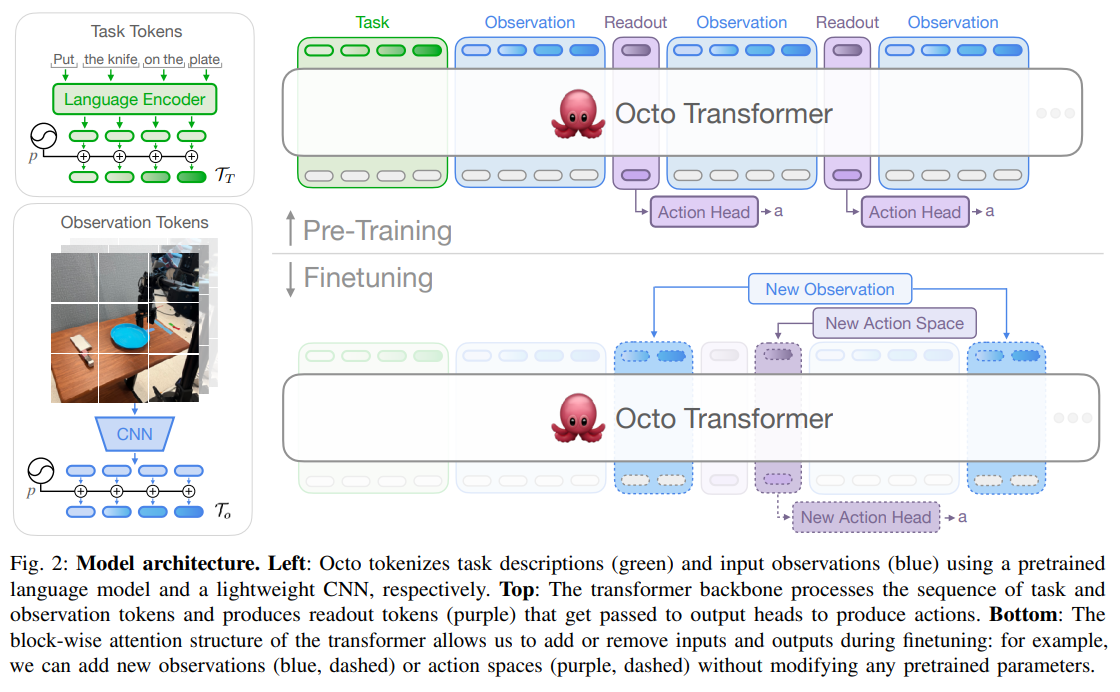
Octo의 핵심 아이디어는 모달리티에 특화된 토크나이저(Tokenizer)를 통해 입력 데이터를 통일된 형태의 토큰으로 변환하고, 이를 블록 단위 마스킹(Block-wise masking)이 적용된 대규모 트랜스포머 백본으로 처리한 뒤, 확산 모델(Diffusion model) 기반의 헤드(Head)를 통해 액션을 디코딩하는 구조에 있습니다.
입력 데이터의 표현 및 전처리 방식
데이터는 모달리티별로 분리되어 구체적인 변환을 거칩니다.
- 언어 입력: 사전 학습된 언어 모델을 통과하여 16개의 텍스트 임베딩 토큰 시퀀스로 변환됩니다.
- 이미지 관측 및 목표(Goal) 이미지: ResNet과 같은 무거운 인코더 대신, 얕은 합성곱(Convolution) 스택을 거친 후 크기의 패치(Patch)로 분할되어 평탄화(Flatten)됩니다. 3인칭 카메라는 256개의 토큰, 손목 카메라는 64개의 토큰으로 변환됩니다.
- 변환된 모든 토큰은 학습 가능한 위치 임베딩(Position embedding) 와 결합되어 단일 시퀀스 형태로 트랜스포머에 주입됩니다.
네트워크 구조의 엔지니어링 디테일
Octo는 시각적 인코더에 파라미터를 집중하던 기존(RT-1 등)과 달리, 파라미터의 대부분을 트랜스포머 백본에 집중하는 'Transformer-first' 아키텍처를 채택했습니다.
가장 중요한 기술적 차별성은 블록 단위 마스킹 어텐션(Block-wise masked attention)입니다. 관측 토큰은 현재와 과거의 토큰 및 태스크(언어/목표) 토큰에만 인과적(Causally)으로 어텐션할 수 있습니다. 데이터셋에 특정 센서 입력이 없다면 해당 토큰은 완전히 마스킹됩니다. 모델 후반부에는 [CLS] 토큰과 유사한 역할을 하는 리드아웃 토큰(Readout token) 가 삽입되어 내부 임베딩을 수집하며, 이 임베딩 구조 덕분에 파인튜닝 시 백본을 유지한 채 새로운 센서나 액션 헤드만을 탈부착할 수 있습니다.
학습(Training) 및 추론(Inference) 파이프라인
- 학습 단계: 리드아웃 토큰의 임베딩 를 조건부 확산 디코딩 헤드(Conditional Diffusion Decoding Head)로 전달합니다. 연속적이고 다중 모달(Multi-modal) 속성을 띠는 액션 청크(Action chunk, 미래 액션의 시퀀스)를 예측하기 위해 표준 DDPM 목적함수를 사용합니다. 수식은 다음과 같이 정의됩니다.
여기서 는 노이즈가 추가된 액션, 는 디노이징 네트워크, 는 확산 스텝을 의미합니다. 학습 데이터로는 Open X-Embodiment의 800k 궤적을 사용하며, 미래 상태를 목표 이미지로 삼는 Hindsight goal relabeling 기법을 적용합니다. - 추론 단계: 관측 및 태스크 토큰은 트랜스포머 백본을 단 한 번의 순전파(Forward pass)로 통과하여 임베딩 를 생성합니다. 이후 작은 확산 헤드 내에서만 다중 스텝의 디노이징 루프가 반복 실행되어 최종 액션 청크를 샘플링합니다. 이를 통해 이산화(Discretization)된 액션 공간을 사용하는 기존 방법론보다 훨씬 정밀하고 결정적인(Decisive) 제어가 가능합니다.
3. 실험 결과 (Experiments)
평가는 4개 기관의 9개 로봇 플랫폼(WidowX, UR5, ALOHA 등)에서 수행되었습니다. 비교 대상(Baseline)으로는 현재 공개된 최고 성능의 범용 정책인 RT-1-X와 사전 학습된 시각 표현 모델인 VC-1, 그리고 밑바닥부터 학습시킨 ResNet+Transformer 구조가 사용되었습니다.
- 제로샷(Zero-shot) 제어 성능: 사전 학습 환경과 유사한 세팅에서 Octo(93M 파라미터)는 RT-1-X(35M) 대비 평균 29% 더 높은 성공률을 기록했으며, 55B 파라미터를 가진 RT-2-X와 비견되는 성능을 입증했습니다.
- 파인튜닝(Finetuning) 성능: 약 100개의 타겟 도메인 데모만으로 새로운 환경에 적응하는 실험에서, Octo는 베이스라인 대비 평균 52% 더 높은 성능을 보였습니다. 특히 사전 학습 데이터에 없었던 힘-토크 센서(Force-torque input)를 새로운 관측으로 추가하거나, 말단 장치 제어(End-effector)에서 관절 위치 제어(Joint position control)로 액션 공간을 완전히 변경한 상황, 심지어 양팔 로봇(Bimanual)으로의 확장에서도 안정적으로 동작함을 확인했습니다.
- 어블레이션 스터디(Ablation Study): MSE 손실함수나 이산화 기반 크로스 엔트로피 대신 확산(Diffusion) 목적함수를 사용했을 때 성능이 압도적으로 향상되었으며, 데이터셋의 다양성이 증가하고 모델 크기가 커질수록 제로샷 일반화 성능이 비례하여 증가했습니다.
4. 한계점 및 시사점
한계 및 제약 조건
논문은 모델의 몇 가지 한계점을 명확히 밝히고 있습니다. 첫째, 현재 Octo 모델은 손목 카메라(Wrist camera) 정보를 적절히 활용하는 데 어려움을 겪어, 종종 3인칭 카메라 단독 사용 시 파인튜닝 성능이 더 높게 나타났습니다. 둘째, 언어 조건부 정책의 성능이 목표 이미지(Goal image) 조건부 정책보다 상대적으로 떨어집니다. 이는 사전 학습 데이터 중 손목 카메라와 언어 주석이 포함된 데이터 비율이 각각 27%, 56%에 불과한 데이터 편향성에 기인합니다.
실제 적용 시 과제 및 시사점
엔지니어링 측면에서 더 높은 조작 정밀도를 위해 입력 패치 크기를 줄이는 것(예: 에서 으로 감소)이 유리하지만, 이는 연산량(FLOPS)을 크게 증가시키므로 자원 대비 효율성의 균형을 맞추는 것이 향후 과제입니다.
Octo는 역사상 가장 거대한 로봇 데이터셋으로 학습된 트랜스포머 기반 정책의 가중치, 파이프라인, 데이터 로더를 모두 오픈소스로 공개했다는 점에서 중요한 의미를 지닙니다. 유연한 구조 덕분에 기존 단일 로봇, 단일 센서 환경에 갇혀 있던 로봇 제어 연구가 멀티 센서, 이기종 로봇 제어로 확장될 수 있는 강력한 파운데이션 모델(Foundation model) 생태계를 구축했다고 평가할 수 있습니다.
