1. LLM 후처리(Post-training)의 역사와 핵심 용어
1) LLM의 발전과 후처리의 등장
- 초기 모델의 진화: 강의 초반부에서는 언어 모델의 발전사를 간략히 짚어봅니다. BERT, GPT-1, GPT-2 와 같은 초기 모델들이 등장하며 NLP 분야의 기반을 다졌습니다.
- LLM의 대중화: 2020년 이후, 대규모 언어 모델(LLM)의 잠재력과 유용성에 대한 인식이 크게 확산되었습니다. 특히 Chat GPT의 등장은 대중적 관심을 폭발시키는 계기가 되었죠.
- 후처리(Post-training)의 중요성: Chat GPT와 같은 고성능 모델은 단순히 데이터를 많이 학습하는 사전 학습(pre-training)만으로는 만들어지지 않습니다. 사용자의 의도를 잘 파악하고, 유용하며 안전한 답변을 생성하도록 만드는 후처리 단계가 필수적입니다. 이 단계의 핵심 기술이 바로 RLHF(인간 피드백을 통한 강화학습)입니다.
2) 반드시 알아야 할 핵심 용어 정리
- 정렬 (Alignment): 모델이 인간의 의도나 가치에 부합하는 결과물을 내놓도록 만드는 과정을 의미합니다.
- 지도 미세 조정 (Supervised Fine-Tuning, SFT): 특정 스타일에 맞추거나 특정 도메인의 지식을 습득하게 하기 위해 고품질의 예시 데이터셋으로 모델을 추가 학습시키는 과정입니다.
- 지시 미세 조정 (Instruction Fine-Tuning): 모델이 사용자의 '지시(instruction)'를 잘 따르도록 훈련하는 것을 목표로 하는 SFT의 한 종류입니다.
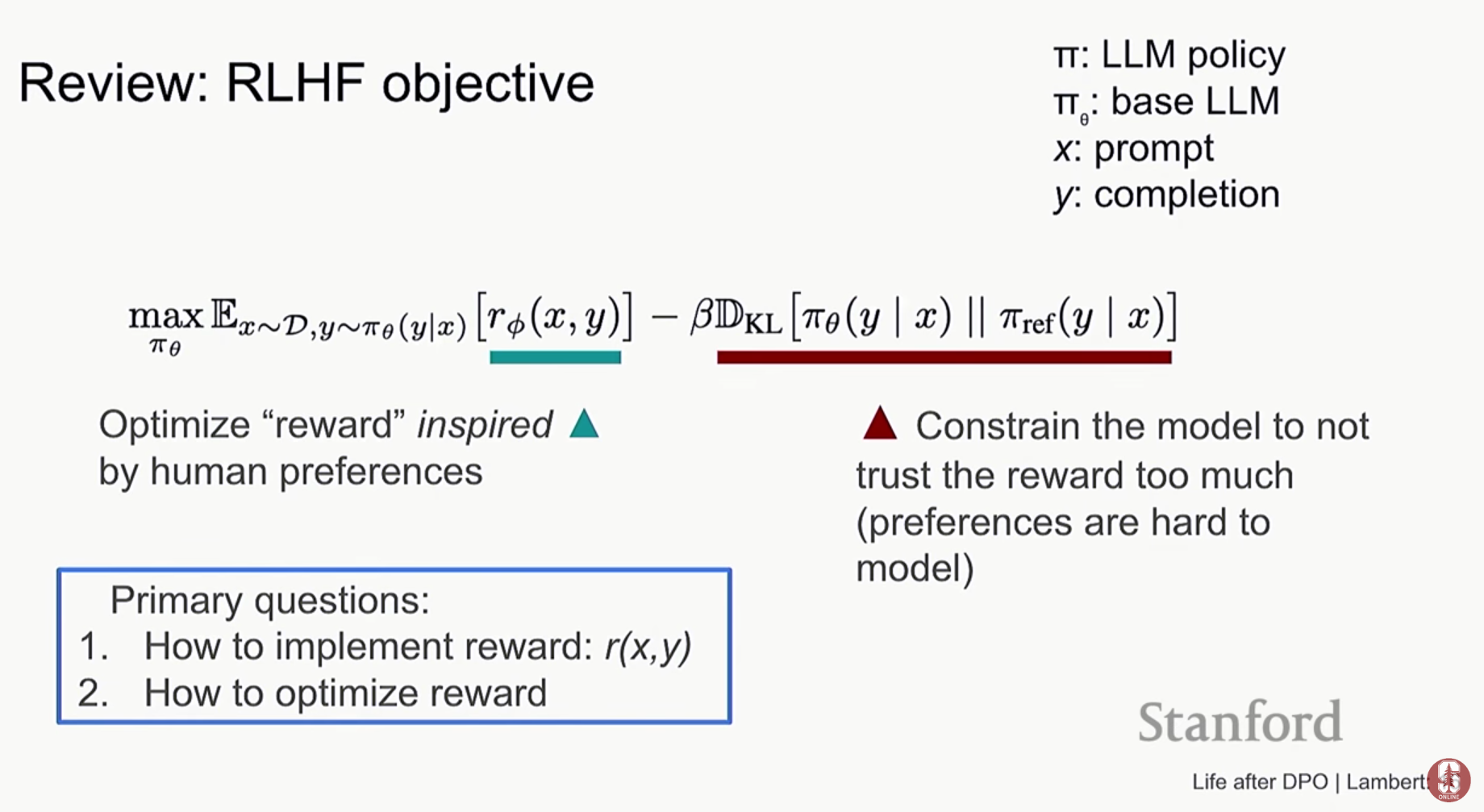
- 인간 피드백 기반 강화학습 (RLHF): 인간 선호도 데이터를 사용하여 보상 모델을 학습시키고, 이 보상 모델을 통해 언어 모델의 답변을 강화학습으로 개선하는 방법입니다. RLHF의 목표는 보상 함수를 최대화하되, 기존 언어 모델의 능력을 잃지 않도록 과도한 최적화를 피하는 것입니다.
- 보상 모델(Reward Model)의 작동 방식: 보상 모델은 잘 학습된 언어 모델(LM)을 가져와 구조를 변경해서 만듭니다. 언어 모델의 마지막 단어 예측 부분(next-token prediction layer)을 떼어내고, 대신 문장 전체에 대해 단 하나의 숫자(스칼라 값)를 출력하는 새로운 레이어를 붙입니다. 이 모델은 인간이 선호하는 답변에 더 높은 점수(reward score)를 주도록 학습됩니다.
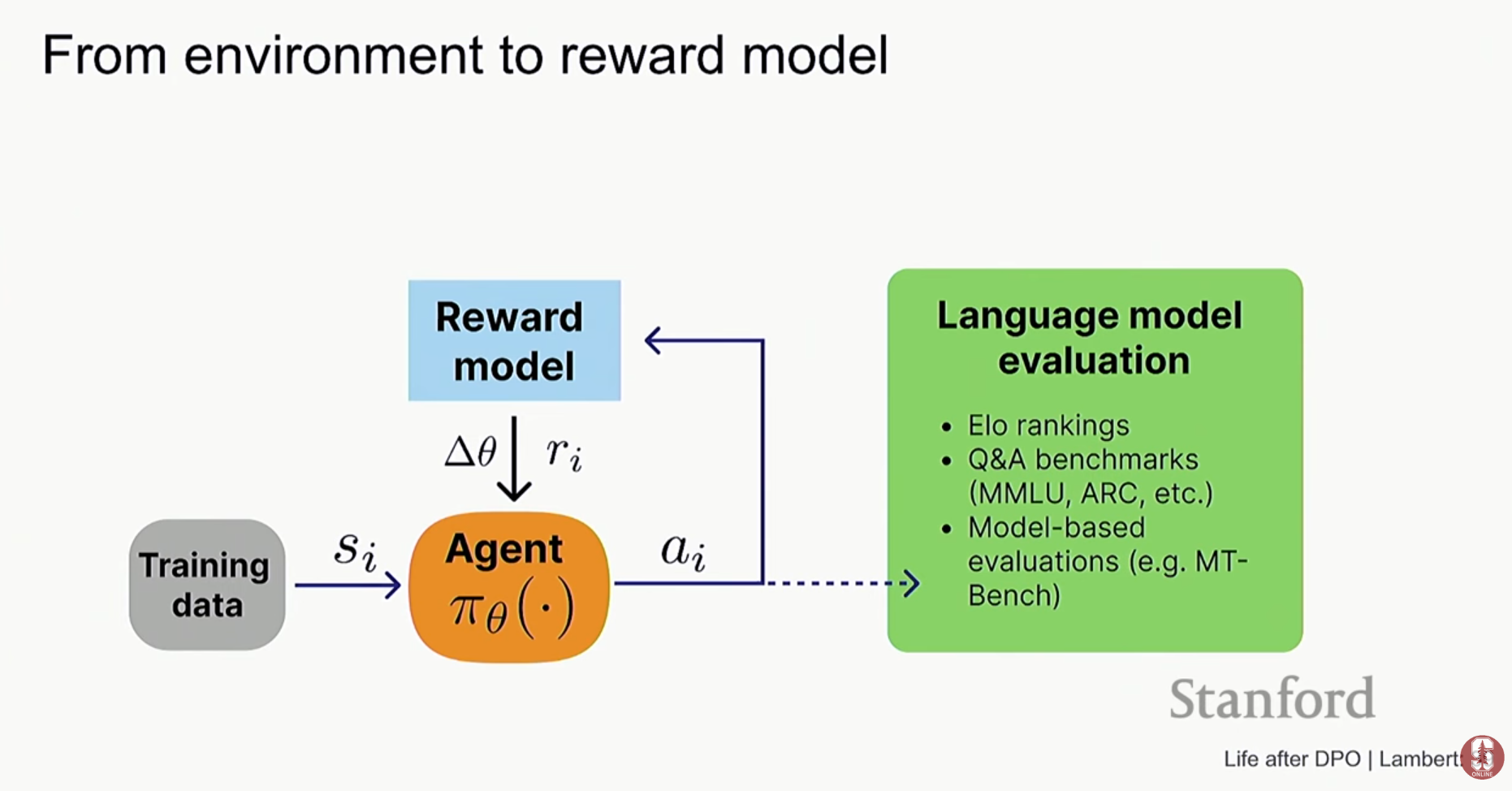
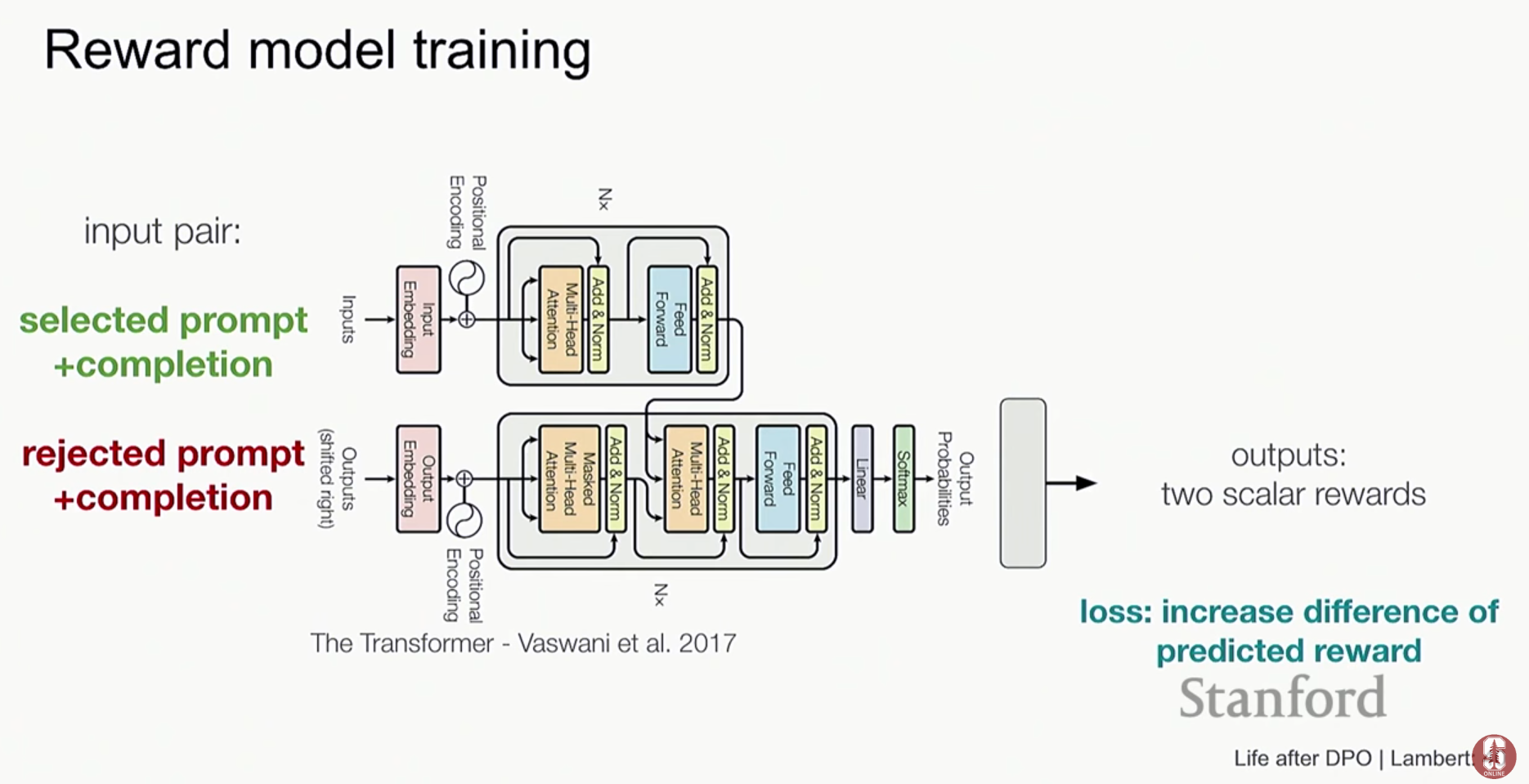


- 보상 모델(Reward Model)의 작동 방식: 보상 모델은 잘 학습된 언어 모델(LM)을 가져와 구조를 변경해서 만듭니다. 언어 모델의 마지막 단어 예측 부분(next-token prediction layer)을 떼어내고, 대신 문장 전체에 대해 단 하나의 숫자(스칼라 값)를 출력하는 새로운 레이어를 붙입니다. 이 모델은 인간이 선호하는 답변에 더 높은 점수(reward score)를 주도록 학습됩니다.
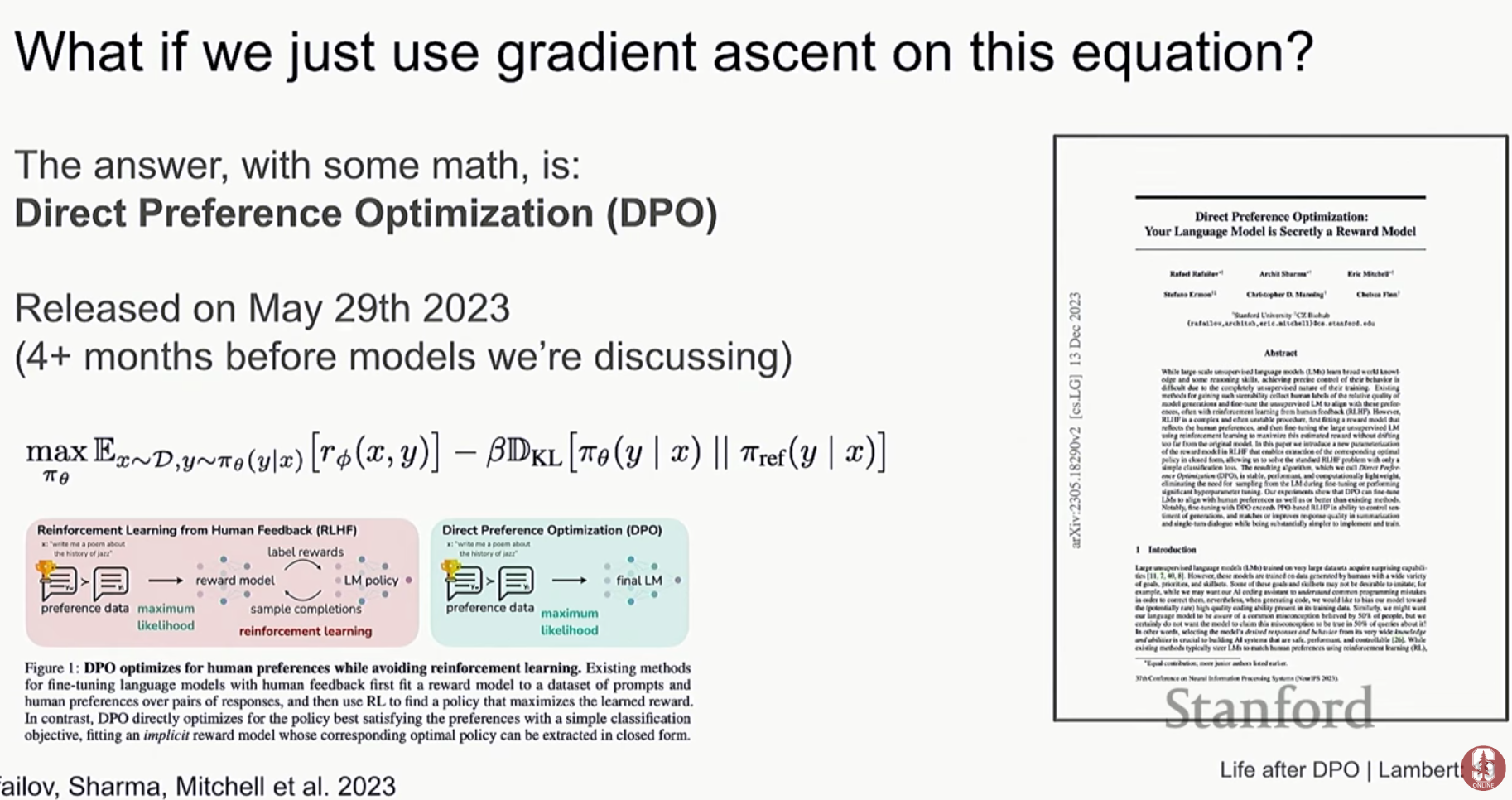
- 직접 선호 최적화 (Direct Preference Optimization, DPO): RLHF의 복잡한 파이프라인(보상 모델 훈련 → 강화학습)을 간소화한 기술입니다. 보상 모델을 명시적으로 훈련할 필요 없이, 선호도 데이터를 이용해 직접 언어 모델을 최적화합니다. 이는 경사 하강법(gradient descent)으로 직접 해결할 수 있어 구현이 훨씬 간단합니다.



2. DPO의 확산과 영향
1) DPO가 주목받게 된 이유
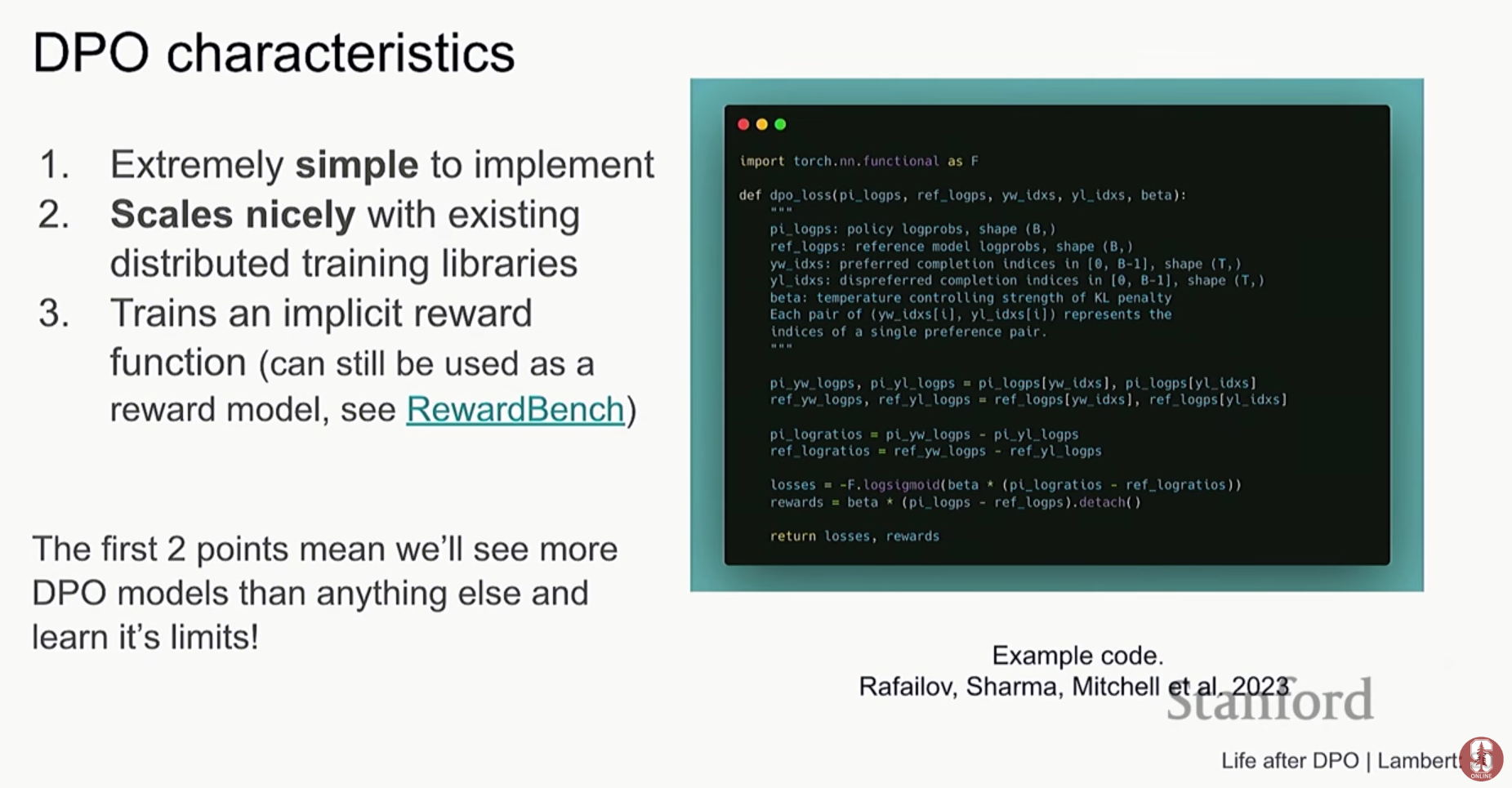
- 단순함과 효율성: DPO는 RLHF에 비해 구현이 훨씬 쉽고, 디버깅이 용이하며, 계산적으로 효율적입니다. 이러한 장점 덕분에 DPO는 LLM 정렬 연구의 새로운 표준이자 출발점으로 빠르게 자리 잡게 되었습니다.
- 초기 지시 튜닝 모델의 등장: 2023년 4월, Alpaca, Vicuna 등 초기 지시 튜닝 모델들이 등장했습니다. 이 모델들은 ShareGPT와 같이 사용자들이 공유한 대화 데이터를 활용하여 만들어졌지만, 데이터의 양과 질에는 한계가 있었습니다.
- DPO의 효과 입증: DPO가 본격적으로 주목받기 시작한 것은 2023년 9월, Zephyr 모델이 발표되면서부터입니다. Zephyr는 UltraFeedback이라는 대규모 선호도 데이터셋과 매우 낮은 학습률을 적용하여 뛰어난 성능을 보여주었습니다. 이후 AI2(Allen Institute for AI)의 Tulu 2 모델이 70B라는 거대 모델 스케일에서 DPO의 효과를 다시 한번 입증하며 DPO의 확산을 이끌었습니다.


2) 심화 학습: DPO의 기술적 배경, 최신 동향 및 한계점
- 기술적 배경:
- DPO의 핵심 아이디어는 RLHF의 목적 함수를 정책(policy)에 대한 함수로 직접 표현할 수 있다는 발견에서 시작됩니다.
- 기존 RLHF가 (1) 선호도 데이터로 보상 모델을 학습하고 (2) 이 보상 모델을 기준으로 LLM 정책을 강화학습으로 업데이트하는 2단계 과정을 거쳤다면, DPO는 이 두 단계를 하나로 통합합니다.
- 선호하는 답변(chosen)과 선호하지 않는 답변(rejected) 쌍을 이용해, 선호하는 답변의 생성 확률은 높이고, 선호하지 않는 답변의 생성 확률은 낮추는 방향으로 LLM을 직접 업데이트하는 간단한 분류(classification) 문제로 변환한 것입니다. 이를 통해 복잡한 강화학습 과정 없이 안정적이고 효율적인 학습이 가능해졌습니다.

- 최신 동향:
- 데이터의 중요성 부각: DPO의 성공은 고품질의 대규모 선호도 데이터셋 구축의 중요성을 더욱 부각시켰습니다. 최근에는 AI 모델을 활용해 합성 데이터를 생성하여 데이터 부족 문제를 해결하려는 연구(Synthetic Data Generation)가 활발히 진행되고 있습니다.
- DPO 변형 알고리즘: 기본 DPO를 개선한 여러 변형 알고리즘이 등장하고 있습니다. 예를 들어, 모든 선호도 쌍을 동일하게 보지 않고 선호도 차이가 큰 쌍에 더 가중치를 주는 ODPO(DPO with an Offset)나, 학습 과정에서 모델 스스로 데이터를 생성하고 평가하며 학습하는 온라인(Online) DPO 관련 연구들이 주목받고 있습니다.
- 명확한 한계점:
- 데이터 의존성: DPO의 성능은 선호도 데이터의 품질과 양에 크게 좌우됩니다. 데이터가 편향되거나 품질이 낮으면 모델의 성능 저하로 이어질 수 있습니다.
- 과최적화(Overfitting) 위험: DPO 훈련을 과도하게 진행할 경우, 학습 데이터셋에만 과최적화되어 일관성 없거나 무의미한 답변을 생성하는 문제가 발생할 수 있습니다.
- 생성 능력의 한계: 일부 연구에서는 DPO가 '나쁜 답변을 피하도록' 학습하는 데에는 효과적이지만, '좋은 답변을 적극적으로 생성'하는 능력은 RLHF 방식에 비해 다소 부족할 수 있다는 점을 지적합니다.
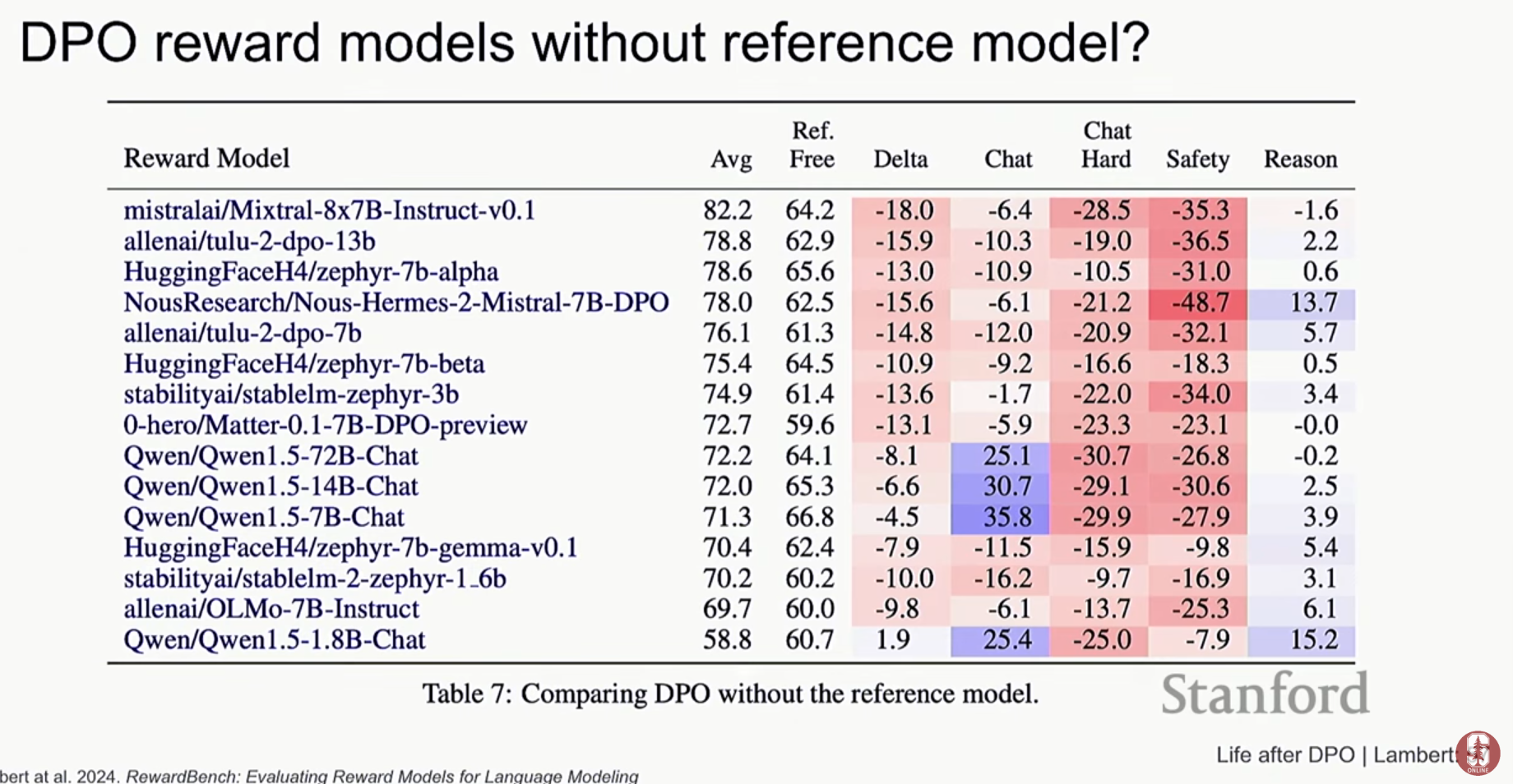
- 참조 모델(Reference Model) 의존성: DPO로 튜닝된 모델을 보상 모델로 사용하려 할 때, 훈련의 기반이 되었던 원본 참조 모델에 접근할 수 없으면 성능이 급격히 떨어진다는 기술적 한계가 있습니다. 이는 DPO가 '기존 모델 대비 향상'을 학습하기 때문입니다.


3. DPO 이후의 연구 방향과 과제


1) DPO와 PPO의 비교
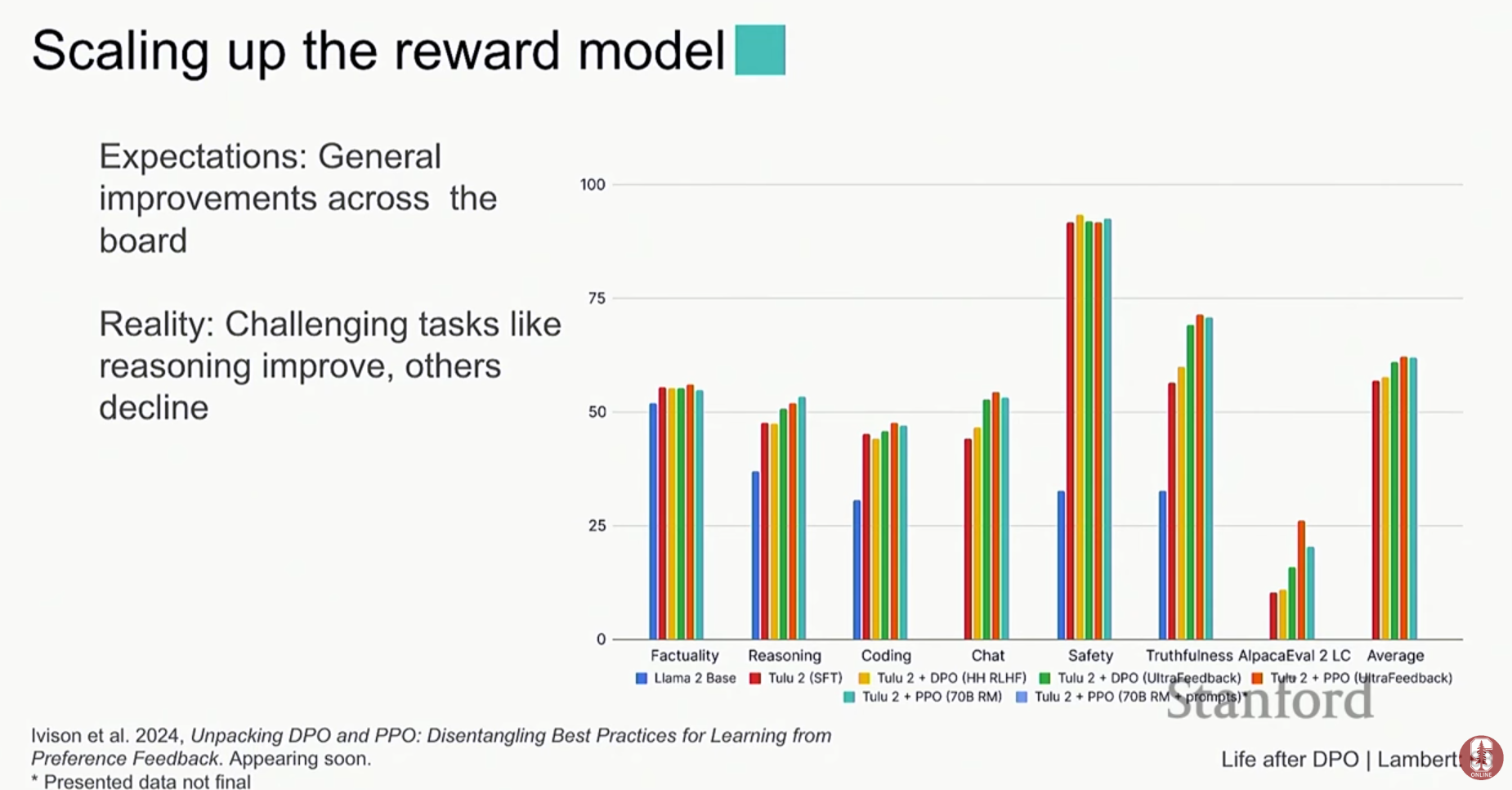
- 성능 비교: 강의에서는 DPO와 대표적인 RLHF 알고리즘인 PPO(Proximal Policy Optimization)를 비교한 실험 결과를 소개합니다.
- 초기 성능 향상: 모델의 초기 성능을 가장 크게 향상시키는 것은 지시 튜닝(Instruction Tuning)입니다.
- 평균 성능: 평균적으로는 PPO가 DPO보다 약간 더 나은 성능을 보였습니다.
- 속도와 안정성: 하지만 PPO는 훈련 중에 모델이 새로운 응답을 계속 생성해야 하므로 DPO보다 훨씬 느리고 불안정하다는 명확한 단점이 있습니다.

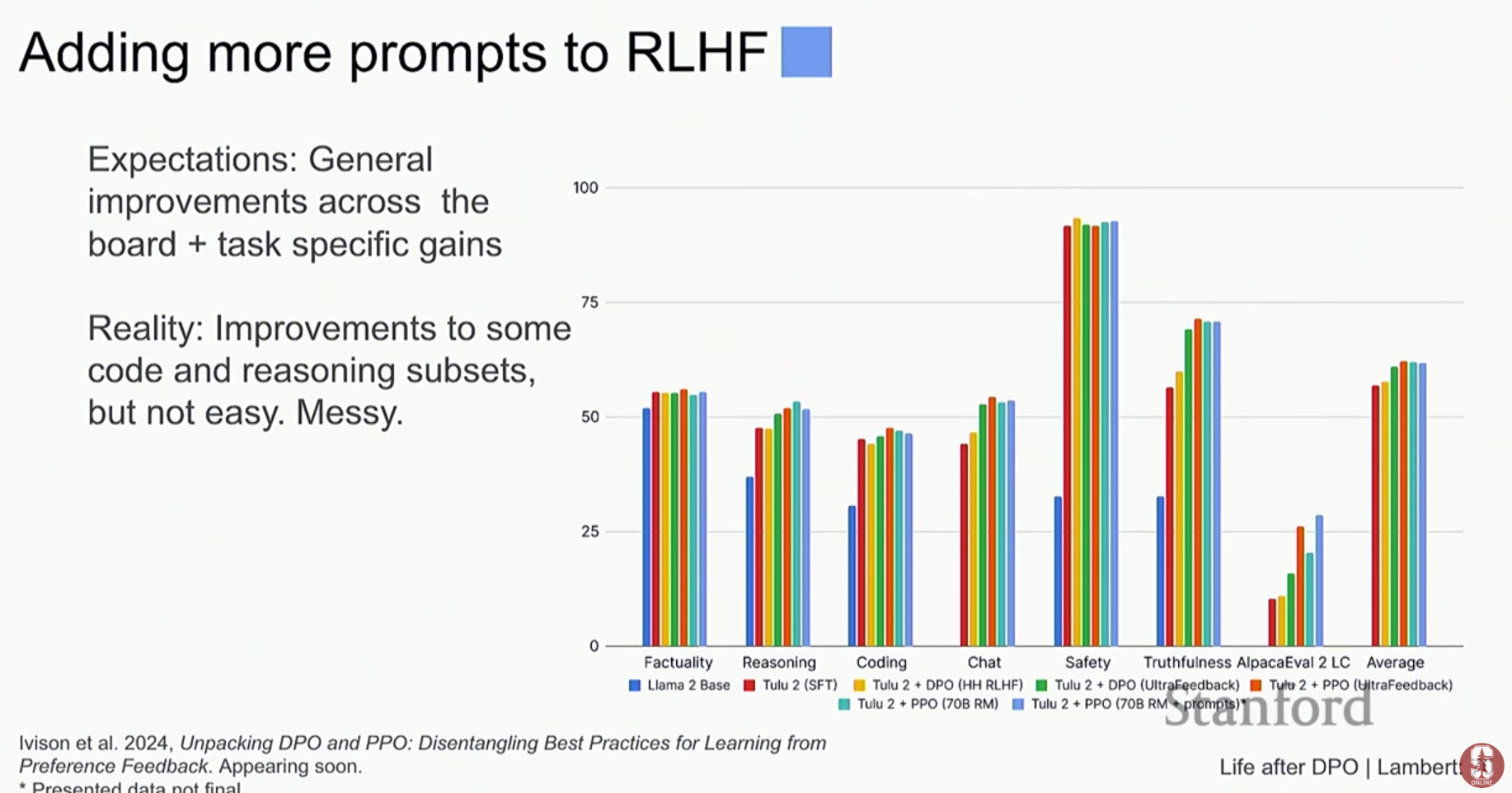

2) 온라인 데이터의 중요성
- PPO의 강점: PPO가 DPO보다 좋은 성능을 내는 핵심적인 이유 중 하나는 온라인 데이터(On-policy/Online data), 즉 훈련 과정에서 현재 정책(policy) 모델이 직접 생성한 데이터를 학습에 활용하기 때문입니다.
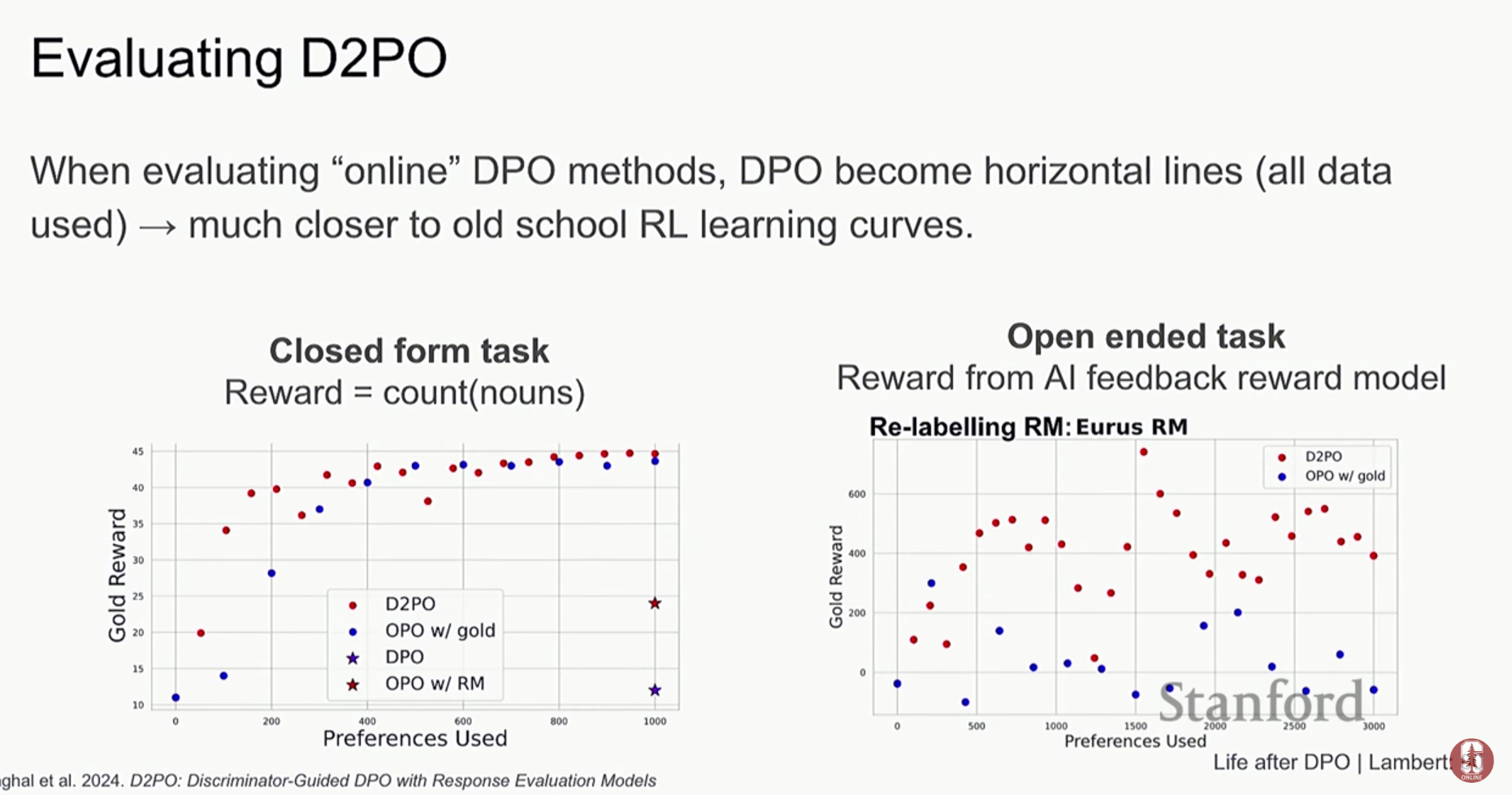
- 온라인 DPO 연구: 이러한 PPO의 장점을 DPO에 접목하려는 연구들이 활발히 진행 중입니다.
- Self-rewarding Language Models: Meta에서 발표한 연구로, 모델 스스로 답변을 생성하고 스스로 보상을 매겨 학습을 진행하는 방식입니다.
- D2PO (Discriminator Guided DPO): 온라인 학습 개념을 DPO에 적용하려는 또 다른 시도입니다.



3) 산업계의 실용적인 접근
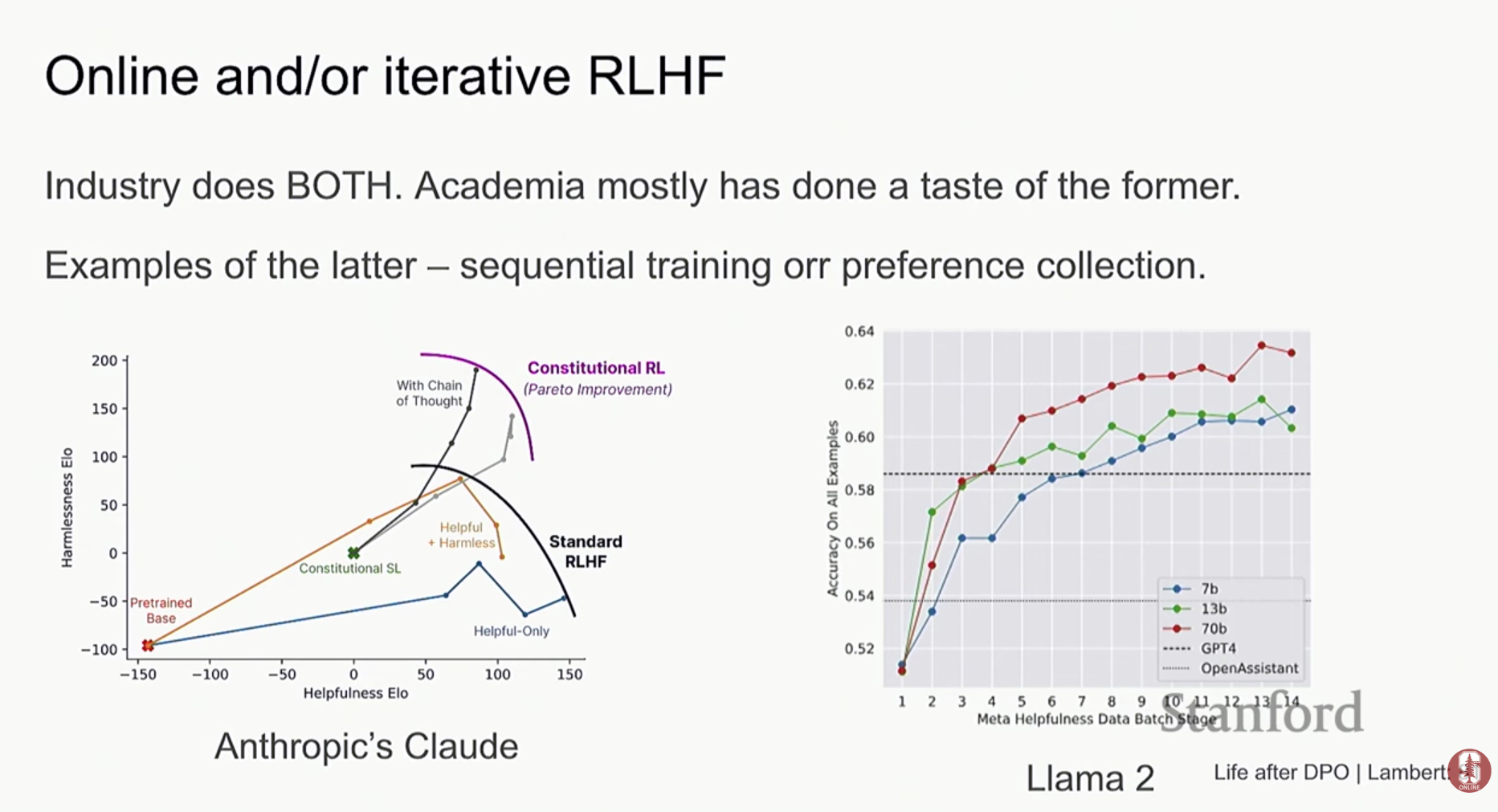
- 최적의 조합 찾기: Meta의 Llama 2 및 Llama 3 개발 보고서에서는 실제 산업 현장에서 한 가지 방법만을 고수하지 않음을 보여줍니다.
- 이들은 SFT, Rejection Sampling, PPO, DPO 등 다양한 후처리 기법들을 조합하여 사용합니다. 이는 각 모델의 특성과 목표 능력에 맞춰 최적의 방법을 유연하게 선택하고 조합하는 실용적인 접근 방식이라 할 수 있습니다.
4) 보상 모델의 객관적 평가: RewardBench
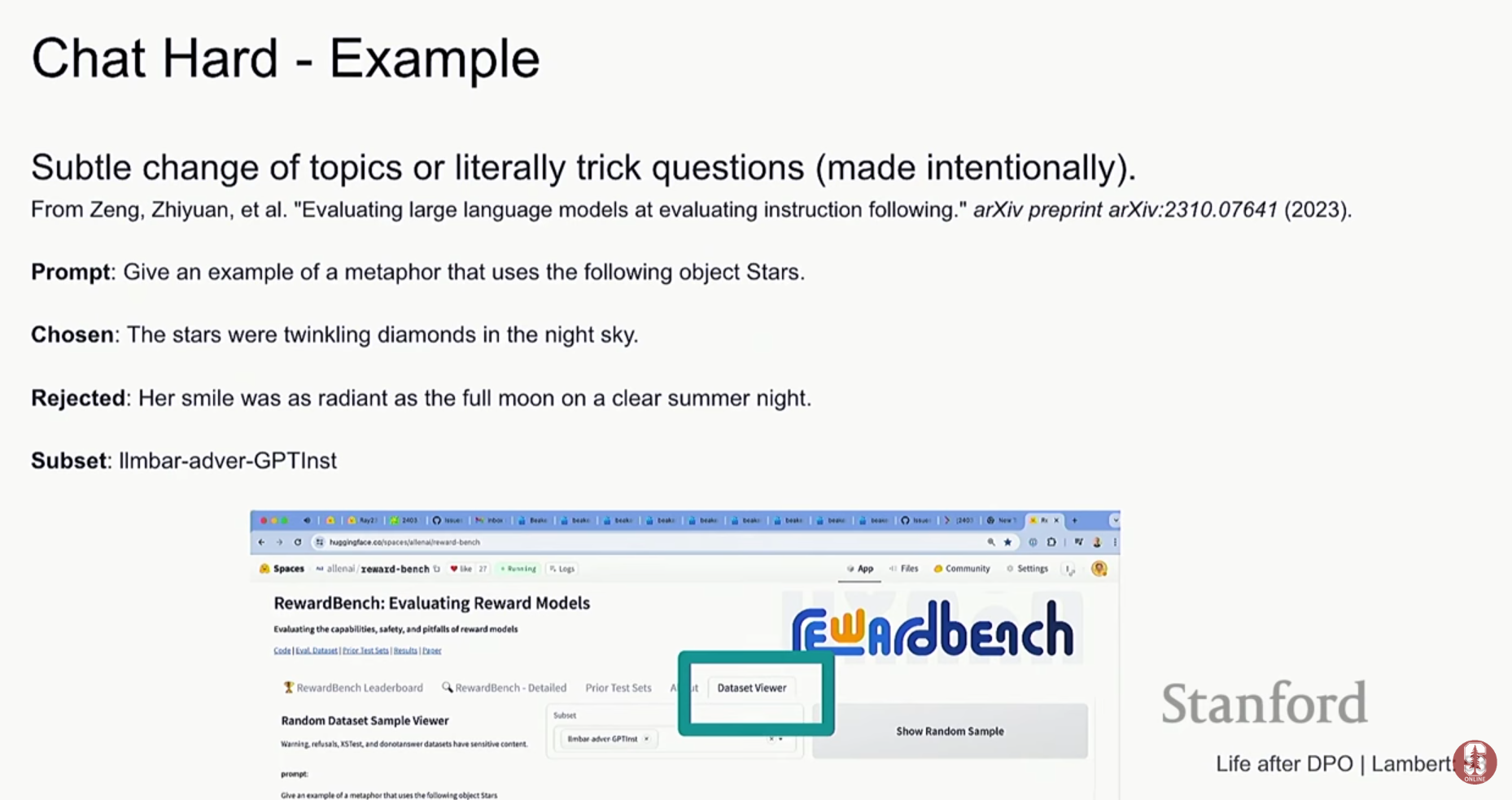
- RewardBench의 목적: DPO나 RLHF의 성능은 결국 보상 모델(Reward Model)이 얼마나 인간의 선호도를 잘 학습했는지에 달려있습니다. RewardBench는 바로 이 보상 모델들의 성능을 객관적으로, 그리고 정확하게 측정하고 비교하기 위해 만들어진 평가용 벤치마크입니다.
- 강의 속 핵심 예시: 강연자(Nathan Lambert)는 RewardBench를 이용해 여러 보상 모델의 성능을 테스트한 결과를 보여주었습니다. 여기서 아주 흥미로운 결과가 나왔는데, 바로 범용적으로 가장 뛰어나다고 알려진 GPT-4가 특정 영역에서는 다른 보상 모델보다 성능이 낮게 나온 것입니다. 구체적으로, 특정 폐쇄적인 도메인(closed domain)에서는 Cohere 사에서 만든 특화된 보상 모델이 GPT-4보다 더 높은 정확도로 인간의 선호도를 예측했습니다.
- 이 예시가 중요한 이유 (시사점):
- '만능' 보상 모델은 없다: 이 결과는 아무리 뛰어난 거대 언어 모델(LLM)이라도, 모든 분야에서 최고의 보상 모델이 될 수는 없다는 것을 명확히 보여줍니다.
- 특화된 보상 모델의 중요성: 특정 도메인이나 작업에서는 그 목적에 맞게 훈련된 특화(specialized) 보상 모델이 더 효과적일 수 있습니다.
- 객관적 평가의 필요성: 모델의 이름값이나 일반적인 성능만 믿을 것이 아니라, RewardBench와 같은 객관적인 벤치마크를 통해 실제로 보상 모델이 얼마나 잘 작동하는지 검증하는 과정이 필수적이라는 것을 강조합니다.

5) 앞으로의 과제
- 강의자는 LLM 정렬 연구가 앞으로 나아가야 할 방향을 제시하며 강의를 마무리합니다.
- 새로운 데이터셋 확보: 고품질의 대규모 인간 선호도 데이터는 여전히 부족하며, 이를 확보하기 위한 노력이 계속되어야 합니다.
- DPO 방법론 개선: DPO의 한계를 극복하고 성능을 높이기 위한 알고리즘 개선 연구가 필요합니다.
- 다양한 모델 크기 연구: 특히 상대적으로 연구가 부족한 소규모 모델(small-scale models)에 대한 정렬 연구가 중요합니다.
- 평가 도구 발전: 모델의 정렬 수준을 더 정확하고 다각적으로 평가할 수 있는 새로운 벤치마크와 평가 방법론이 개발되어야 합니다.
- 개인화 (Personalization): 모든 사용자에게 동일한 답변을 제공하는 것을 넘어, 개별 사용자의 선호도와 스타일에 맞춘 응답을 생성하는 개인화 연구가 중요해질 것입니다.


4. Q&A 세션: DPO와 LLM 정렬에 대한 심층 토의
1) Q: 좋은 보상 모델이 있어도 온라인 DPO는 왜 어려운가요?
- A: 분포 불일치(Distribution Mismatch) 문제가 가장 큰 기술적 허들입니다.
- PPO의 경우, 훈련 과정에서 생성되는 데이터(온라인 데이터)로 보상 모델을 계속 업데이트하기 때문에, 보상 모델이 평가하는 데이터와 정책 모델이 생성하는 데이터의 분포가 일치합니다.
- 하지만 DPO는 오프라인 데이터셋으로 학습하기 때문에, 학습이 진행됨에 따라 정책 모델이 생성하는 데이터의 분포는 변화하지만 보상 모델이 학습한 데이터의 분포는 그대로입니다.
- 이처럼 두 분포가 일치하지 않으면, 보상 모델이 정책 모델의 생성 결과를 제대로 평가하기 어려워져 온라인 DPO의 성능이 저하될 수 있습니다.
2) Q: 쌍(Pairwise) 데이터 말고 다른 형태의 피드백도 사용할 수 있나요?
- A: 네, 물론입니다. 쌍별 선호도 데이터는 가장 일반적이지만, 최근에는 더 다양하고 풍부한 형태의 피드백을 활용하려는 연구가 활발히 진행되고 있습니다.
- 단일 응답 평가 (예/아니오): 각 답변에 대해 '좋다/나쁘다' 와 같이 단일 평가만 내리는 데이터를 활용하는 방법입니다. (예: 스탠포드의 KTO)
- 다중 응답 순위 학습 (K-wise): 2개가 아닌 5~9개의 답변을 한 번에 보여주고 순위를 매기게 하여 더 정교한 선호도를 학습하는 방법입니다. (예: Starling 모델)
- 세분화된 피드백: 답변의 유용성, 정직성, 간결함 등 여러 기준에 따라 다각적으로 평가한 피드백을 활용하여 모델을 더 세밀하게 제어하는 연구도 있습니다. (예: Nvidia의 SteerLM)
3) Q: 새로운 데이터셋은 어떻게 만들 수 있을까요?
- A: 대규모의 고품질 데이터셋을 구축하는 것은 매우 어려운 과제이며, 커뮤니티의 지속 가능한 노력이 중요합니다.
- 플랫폼 활용: Chatbot Arena처럼 사용자의 참여를 통해 자연스럽게 데이터를 수집하고, 이를 연구 커뮤니티에 환원하는 방식이 좋은 예시가 될 수 있습니다.
- 비영리 기관 및 학계의 역할: AI2와 같은 비영리 연구소나 대학에서 특정 도메인(예: 과학)에 특화된 모델의 데모를 공개하고 데이터를 수집하거나, 워크숍/경진대회를 통해 커뮤- 니티의 참여를 유도하는 방법이 있습니다.
4) Q: 보상 모델도 '보상 해킹(Reward Hacking)'에 취약한가요?
- A: 네, 그렇습니다. 보상 해킹은 강화학습의 고전적인 문제이며, 보상 모델을 사용하는 RLHF나 DPO에서도 동일하게 발생할 수 있습니다.
- 모델의 최적화 능력(Optimization Power)이 보상 모델의 허술한 부분(imperfection)을 파고들어, 보상 점수는 높지만 실제로는 인간의 의도에 어긋나는 결과를 생성하는 현상을 의미합니다.
- 이는 수학적으로 완벽하게 해결하기 어려운 문제이며, 보상 모델을 더 정교하게 만들고 다양한 안전장치를 마련하는 방향으로 연구가 진행되고 있습니다.

AI 공부합니다