1. 언어 모델을 활용한 추론 (Reasoning)
1) 추론의 다양한 유형과 언어 모델
- **추론(Reasoning)**이란 주어진 정보를 바탕으로 논리적인 결론을 이끌어내는 과정을 의미해요. 언어 모델의 추론 능력은 복잡한 문제를 해결하는 데 핵심적인 역할을 합니다. 강의에서는 다음과 같은 여러 추론 유형을 소개했어요.
- 연역적 추론 (Deductive Reasoning): "모든 포유류는 신장을 가진다"와 같은 일반적인 전제에서 "모든 고래는 신장을 가진다"는 구체적인 결론을 도출하는 방식입니다. 결론이 전제로부터 반드시 따라 나와요.
- 귀납적 추론 (Inductive Reasoning): 여러 관찰(예: 날개 달린 생물을 여러 번 보고 모두 새였다는 경험)을 통해 일반적인 결론(저 날개 달린 생물은 새일 것이다)을 이끌어내는 방식입니다.
- 가추적 추론 (Abductive Reasoning): 불완전한 관찰(예: 차 시동이 안 걸리고 엔진 아래 액체가 고여있다)로부터 가장 그럴듯한 설명(라디에이터 누수)을 추론하는 방식입니다.
- 형식적/비형식적 추론: 형식적 추론은 수학처럼 정해진 공리와 논리 규칙을 사용하는 반면, 비형식적 추론은 일상생활에서 상식을 바탕으로 결론을 내리는 것을 말해요. 이 강의에서는 주로 비형식적 연역 추론에 초점을 맞춥니다.
2) 언어 모델의 추론 능력을 이끌어내는 방법들
- 단순히 질문만 던지는 것보다, 모델이 스스로 생각하는 과정을 거치도록 유도하는 여러 기법들이 개발되었어요.
- CoT (Chain of Thought) 프롬프트: 모델에게 최종 답변을 내기 전에, 생각의 흐름이나 문제 해결 과정을 단계별로 먼저 생성하게 만드는 기법이에요. 프롬프트에 "단계별로 생각해보자 (Let's think step by step)"와 같은 간단한 문장을 추가하는 것만으로도 성능이 크게 향상될 수 있습니다.
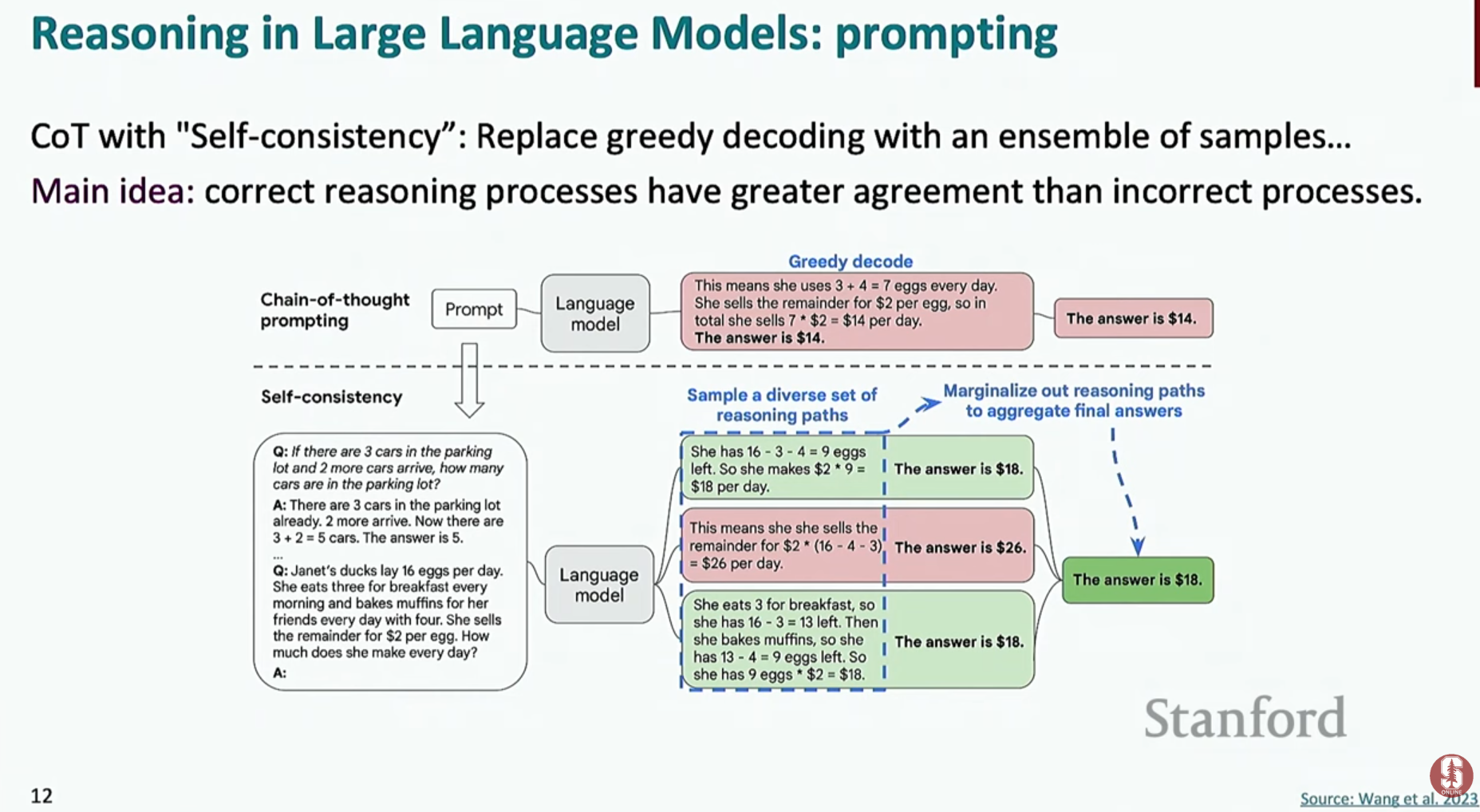
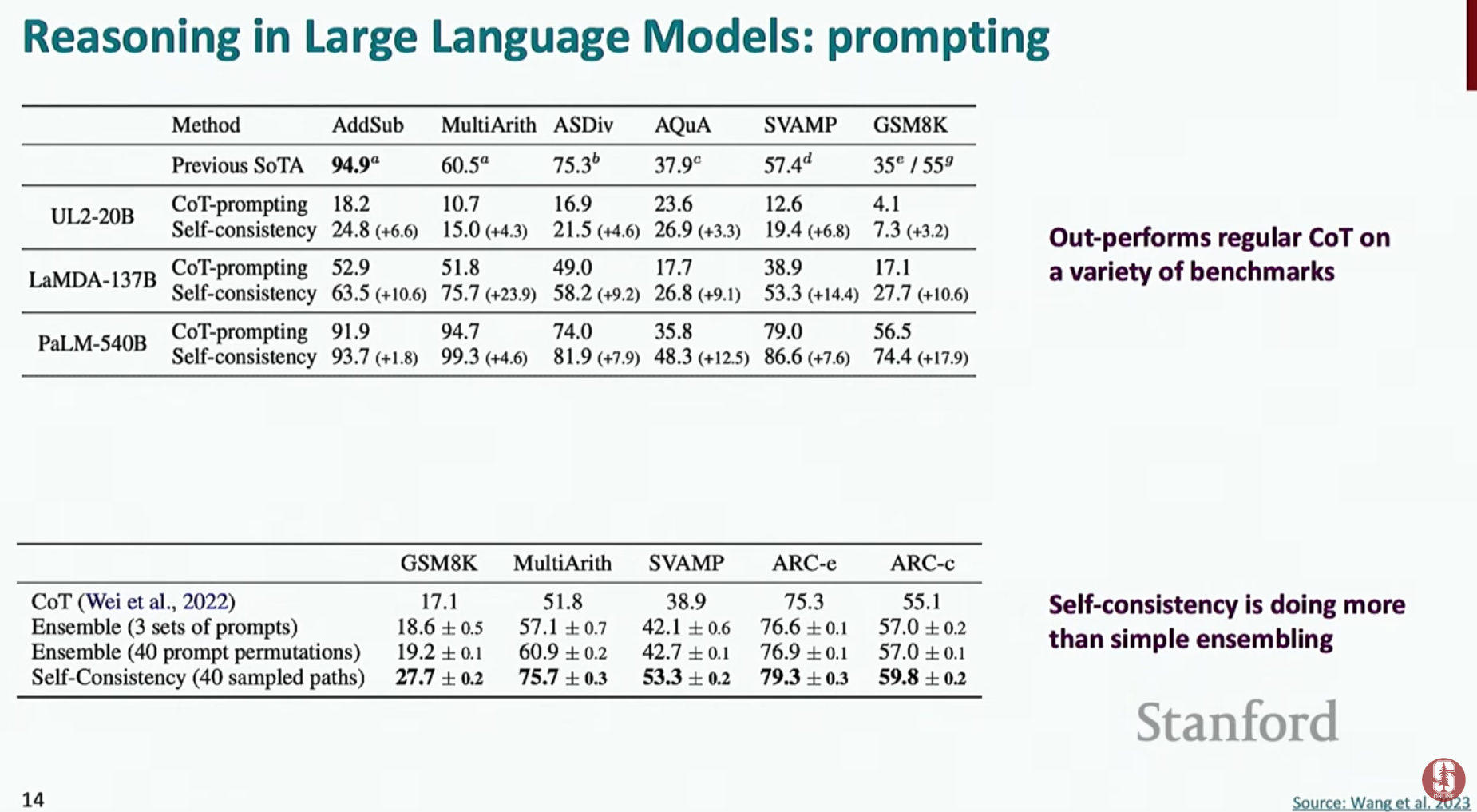
- 자기 일관성 (Self-Consistency): 하나의 문제에 대해 여러 개의 다른 추론 과정(Chain of Thought)을 생성하게 한 뒤, 그중 가장 많이 나온 답변을 최종 결론으로 채택하는 방식입니다. 마치 여러 전문가에게 자문을 구하고 가장 일치하는 의견을 따르는 것과 비슷하죠. 이는 단순 앙상블보다 더 좋은 성능을 보여줍니다.
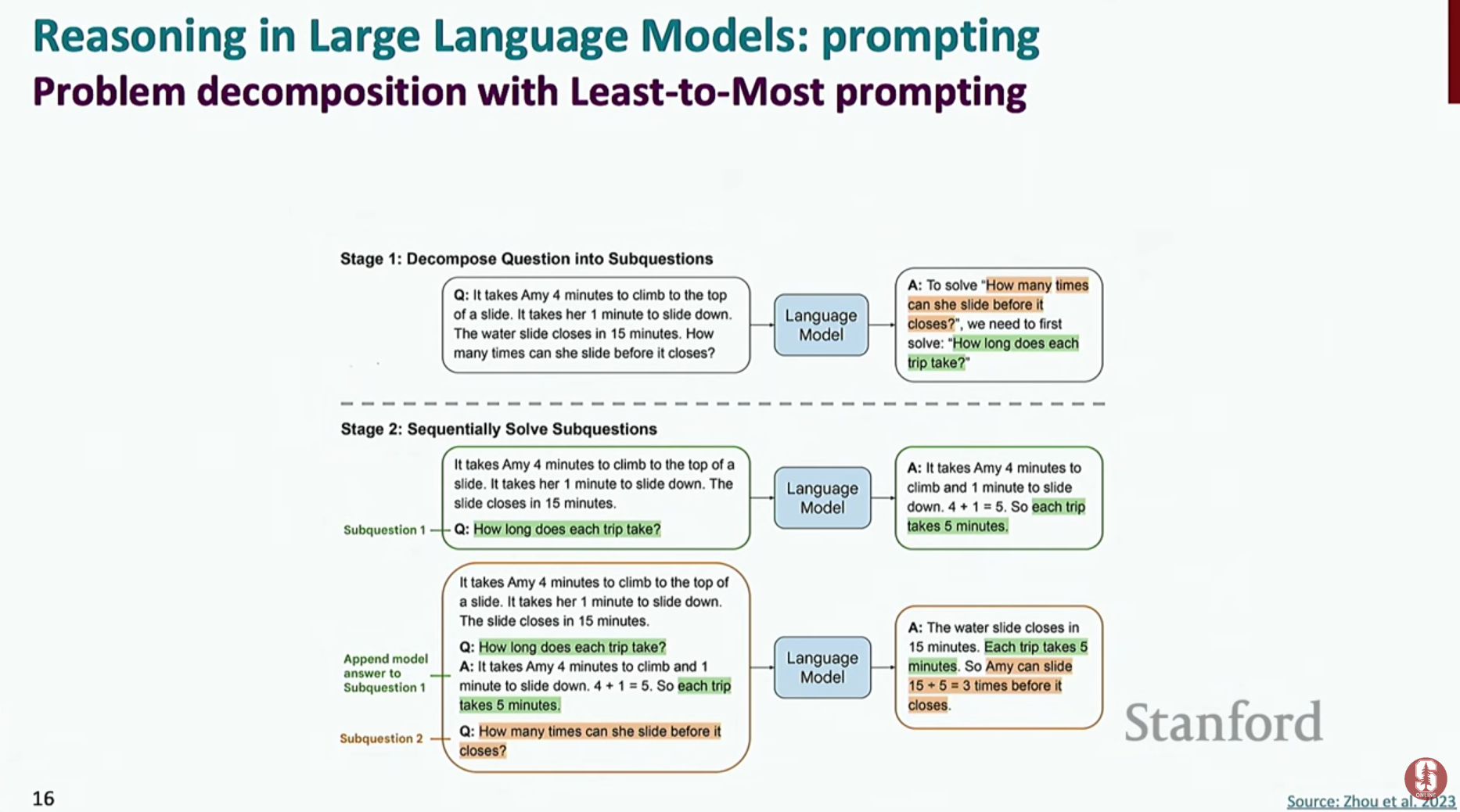
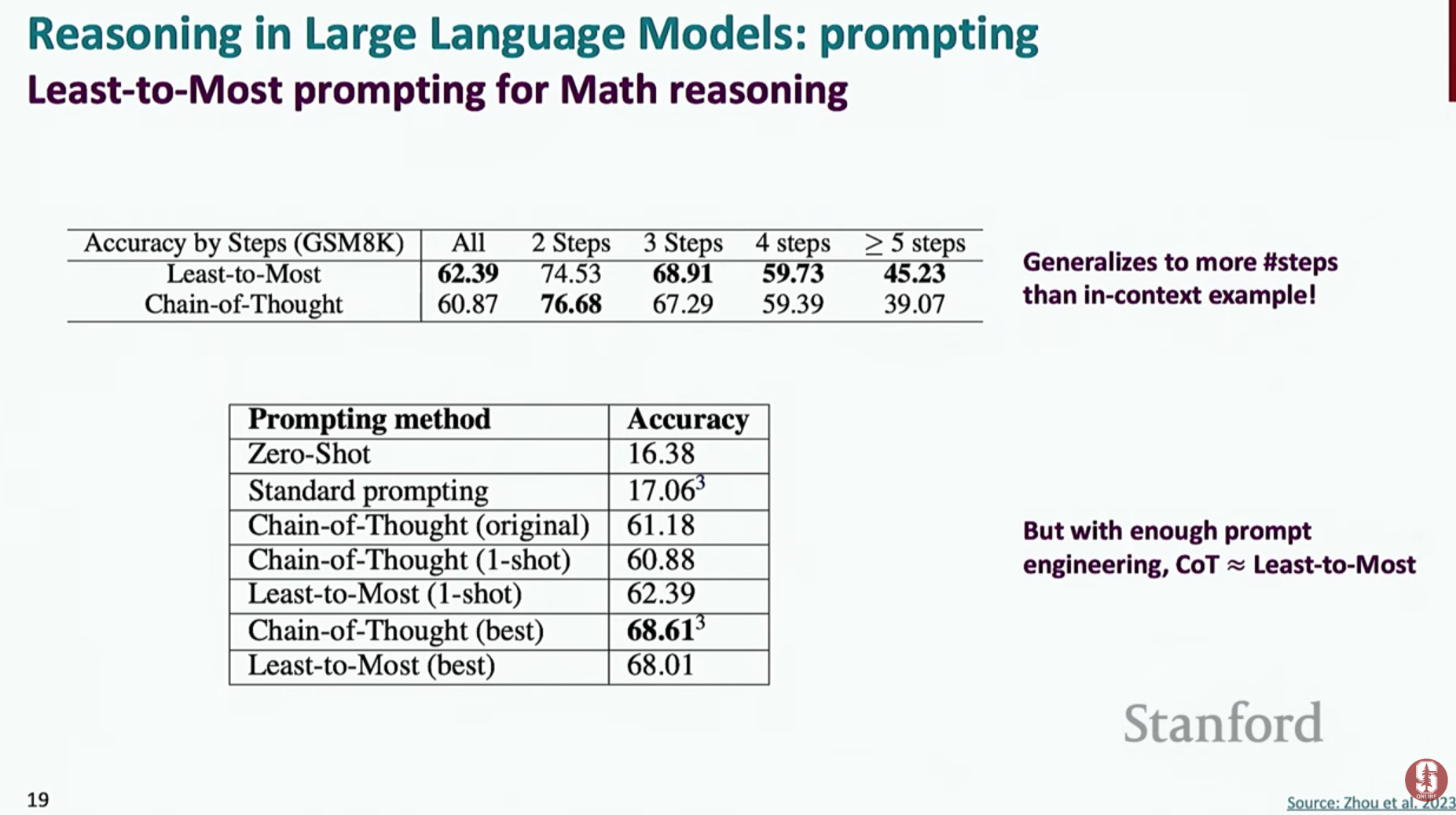
- Least-to-Most 프롬프트: 복잡한 문제를 한 번에 풀게 하는 것이 아니라, 더 쉬운 여러 개의 하위 문제로 분해하고, 그 하위 문제들의 답을 조합하여 최종 답을 구하게 하는 전략입니다.
- 증류 (Distillation)를 통한 소형 모델 훈련: GPT-4와 같은 거대 모델이 생성한 상세한 추론 과정과 설명을 데이터로 삼아, Orca와 같은 더 작은 모델을 학습시키는 방법입니다. 이를 통해 작은 모델도 큰 모델의 추론 능력을 효과적으로 배울 수 있어요.

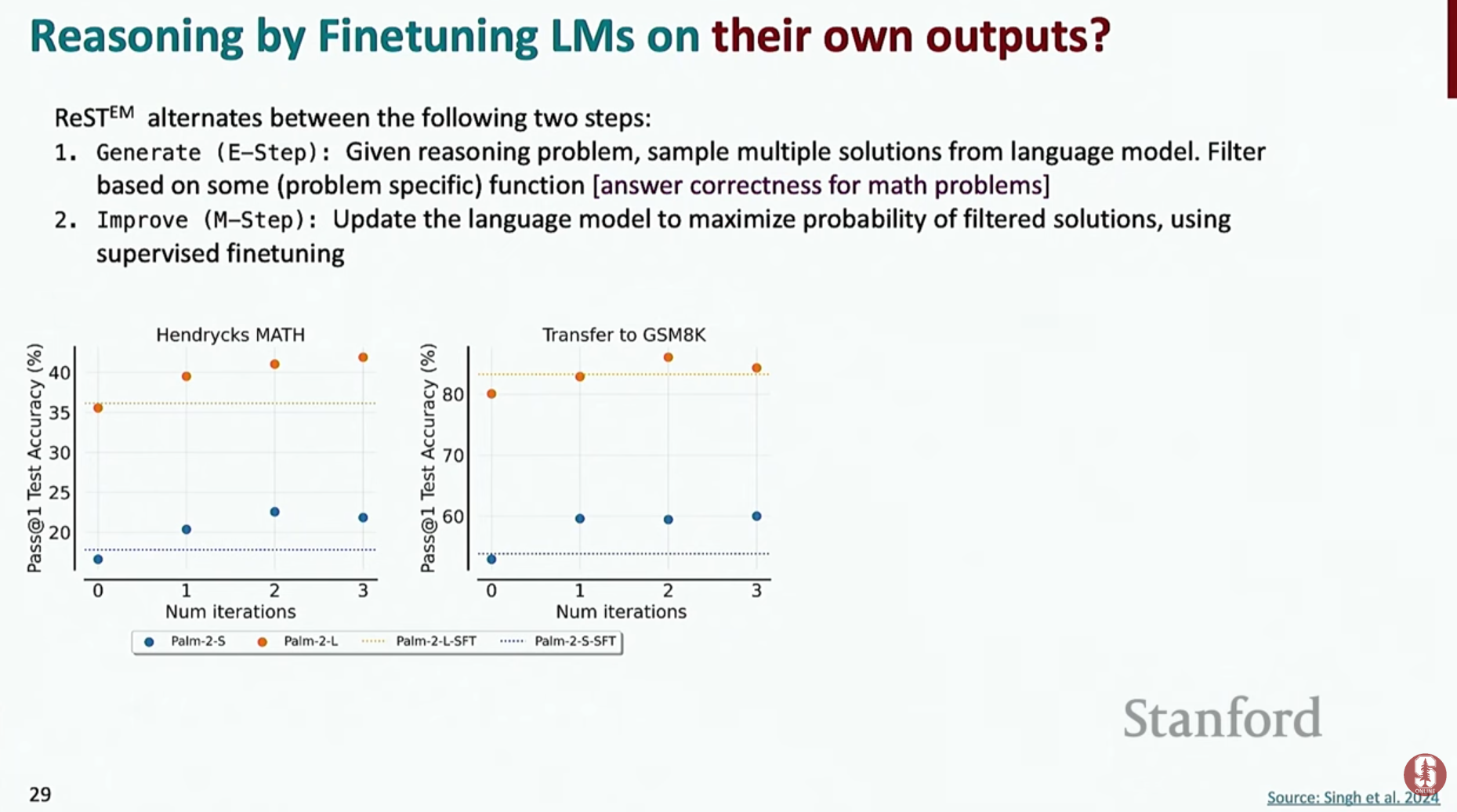
- 강화된 자기 훈련 (Reinforced Self-Training, ReST): 모델이 생성한 여러 추론 과정 중, 정답을 맞힌 추론들만 골라서 다시 모델을 미세 조정하는 과정을 반복하는 기법입니다. 이 과정을 거칠수록 모델의 추론 능력은 점점 더 정교해집니다.
3) 심화 학습: 추론의 충실도와 일반화의 한계
- 강의에서는 모델이 생성한 추론 과정이 정말로 답변에 영향을 미치는지, 그리고 학습 데이터와 다른 새로운 상황에서도 추론 능력이 유지되는지에 대한 중요한 질문을 던졌어요.
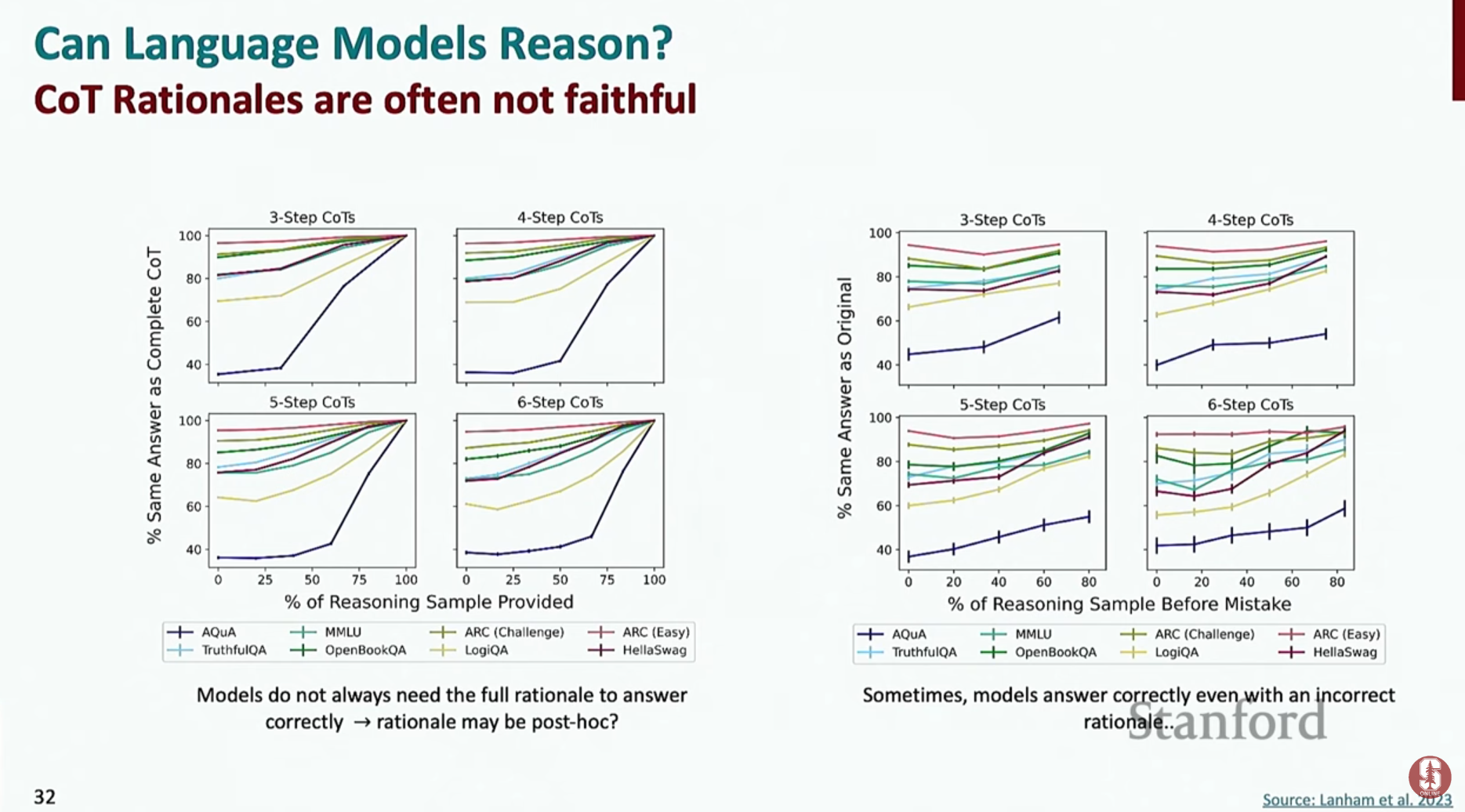
- 추론의 충실도 (Faithfulness) 문제: 모델이 제시한 추론 과정이 그럴듯해 보여도, 실제로는 답을 먼저 정해놓고 나중에 그에 맞춰 설명을 지어내는 **사후 설명(post-hoc explanation)**일 수 있다는 의문이 제기됩니다.
- 기술적 배경: 충실도란 모델이 생성한 설명(추론 과정)이 모델의 실제 예측 과정과 얼마나 일치하는지를 의미합니다. 연구에 따르면, 추론 과정에 의도적으로 오류를 주입해도 최종 답변이 바뀌지 않는 경우가 있어, 현재 CoT 방식의 충실도가 높지 않을 수 있음을 시사합니다.
- 최신 동향: 이 문제를 해결하기 위해, 설명이 결론에 미치는 인과적 영향을 측정하거나, 모델이 단계별 추론에 더 의존하도록 강제하는 새로운 학습 방법들이 연구되고 있습니다.
- 일반화 (Generalization) 및 반사실적(Counterfactual) 추론의 한계: 모델이 훈련 데이터에 있는 패턴은 잘 따라 하지만, 현실과 다른 가상의 조건이나 전제를 기반으로 추론하는 '반사실적(counterfactual)' 상황에서는 성능이 급격히 떨어지는 현상이 발견되었습니다.

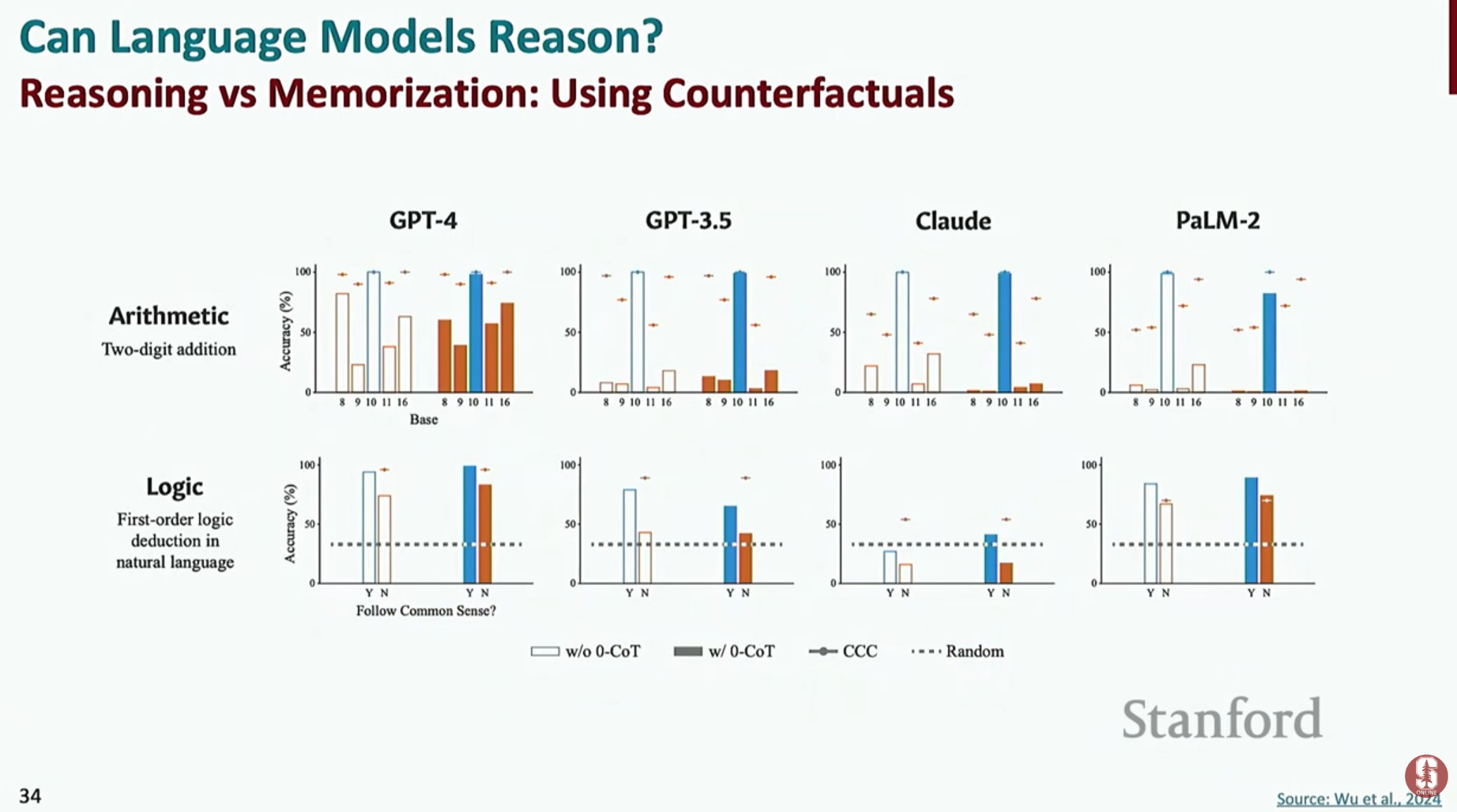
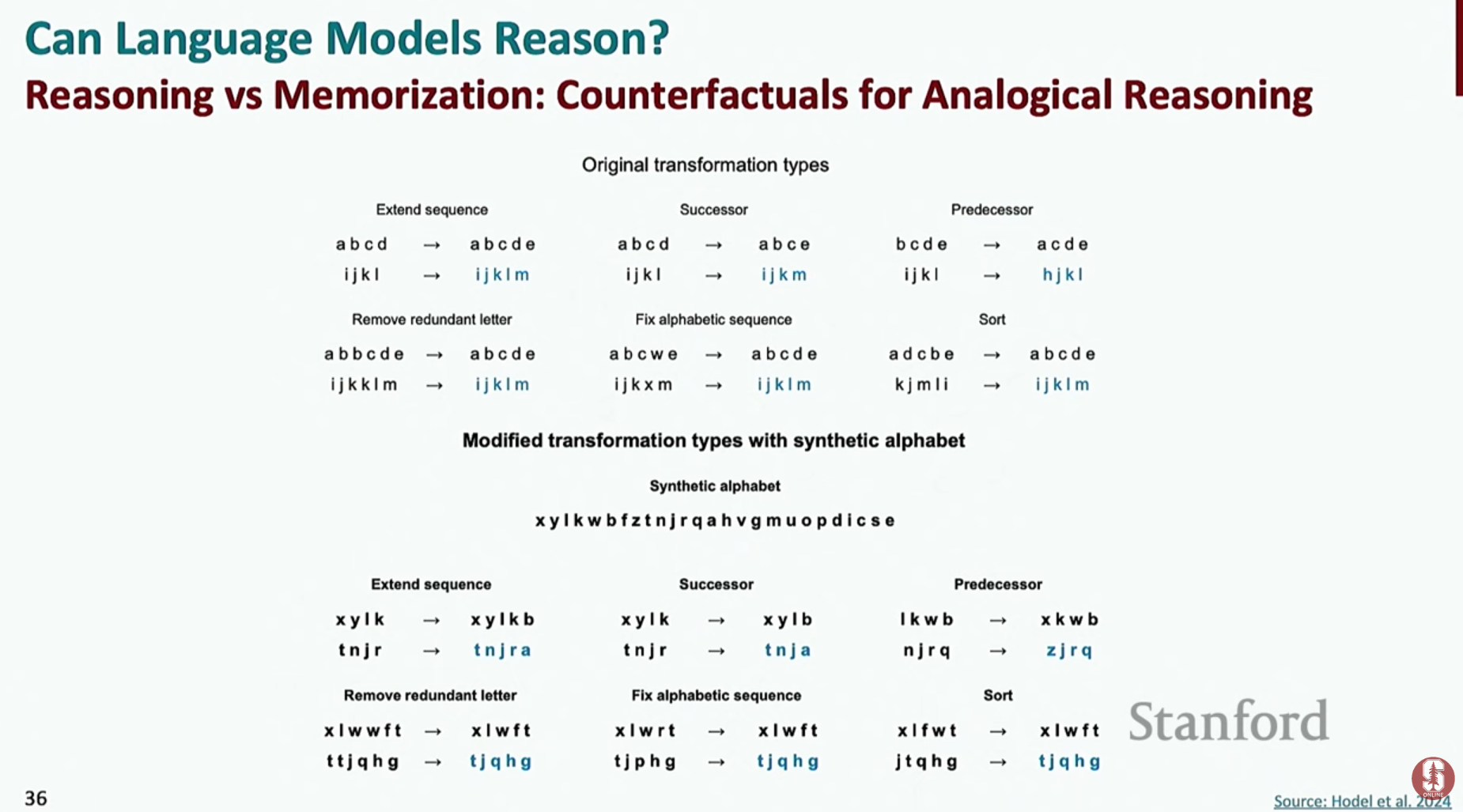
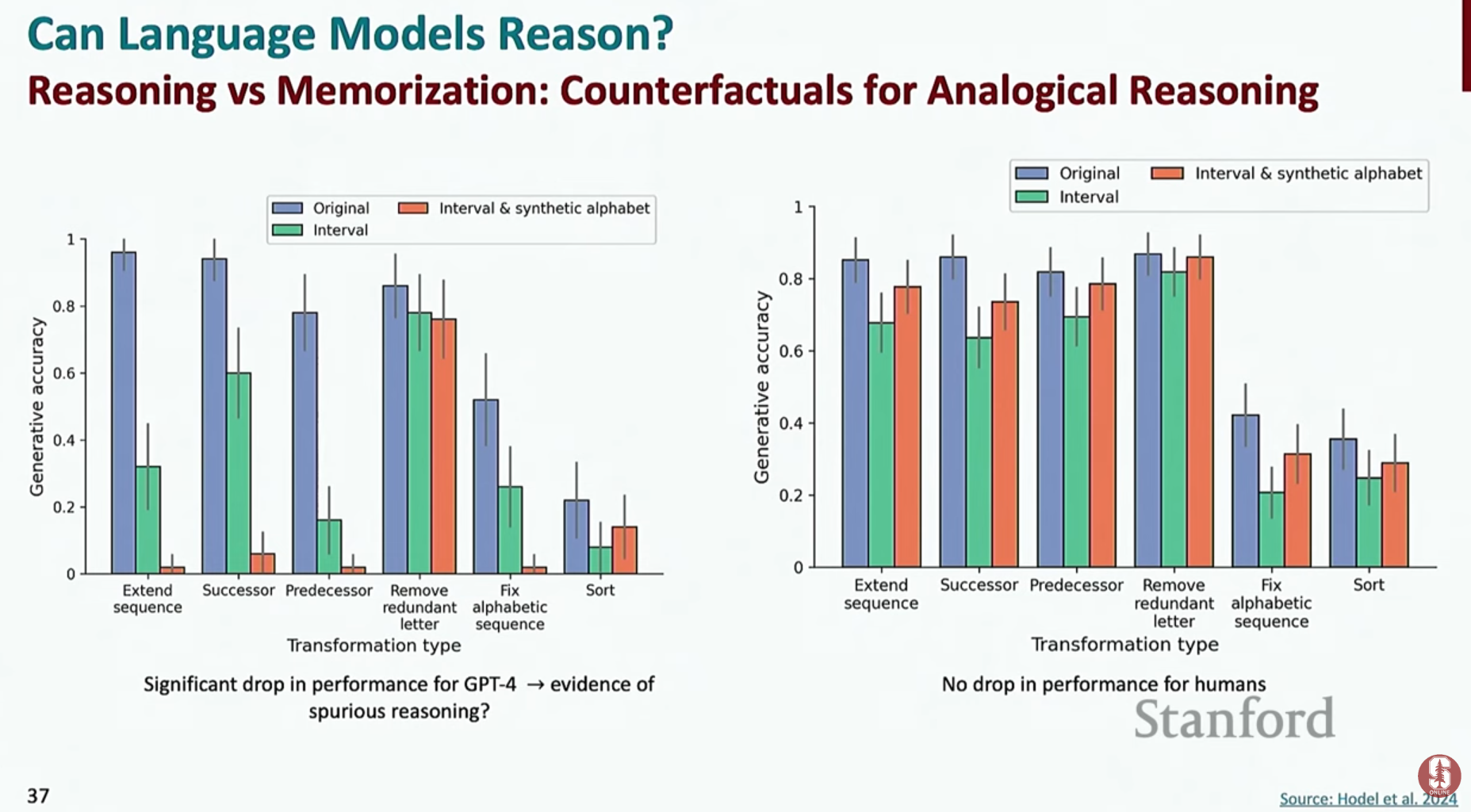
- 명확한 한계점: 이는 현재 언어 모델이 진정한 의미의 추상적 추론을 하는 것이 아니라, 훈련 데이터에 나타난 패턴을 정교하게 암기하고 모방하는 데 더 가깝다는 것을 보여주는 한계입니다. 진정한 일반화 능력을 갖추는 것이 앞으로의 큰 과제예요.
2. 언어 모델 에이전트 (Agents)
1) 에이전트의 기본 개념
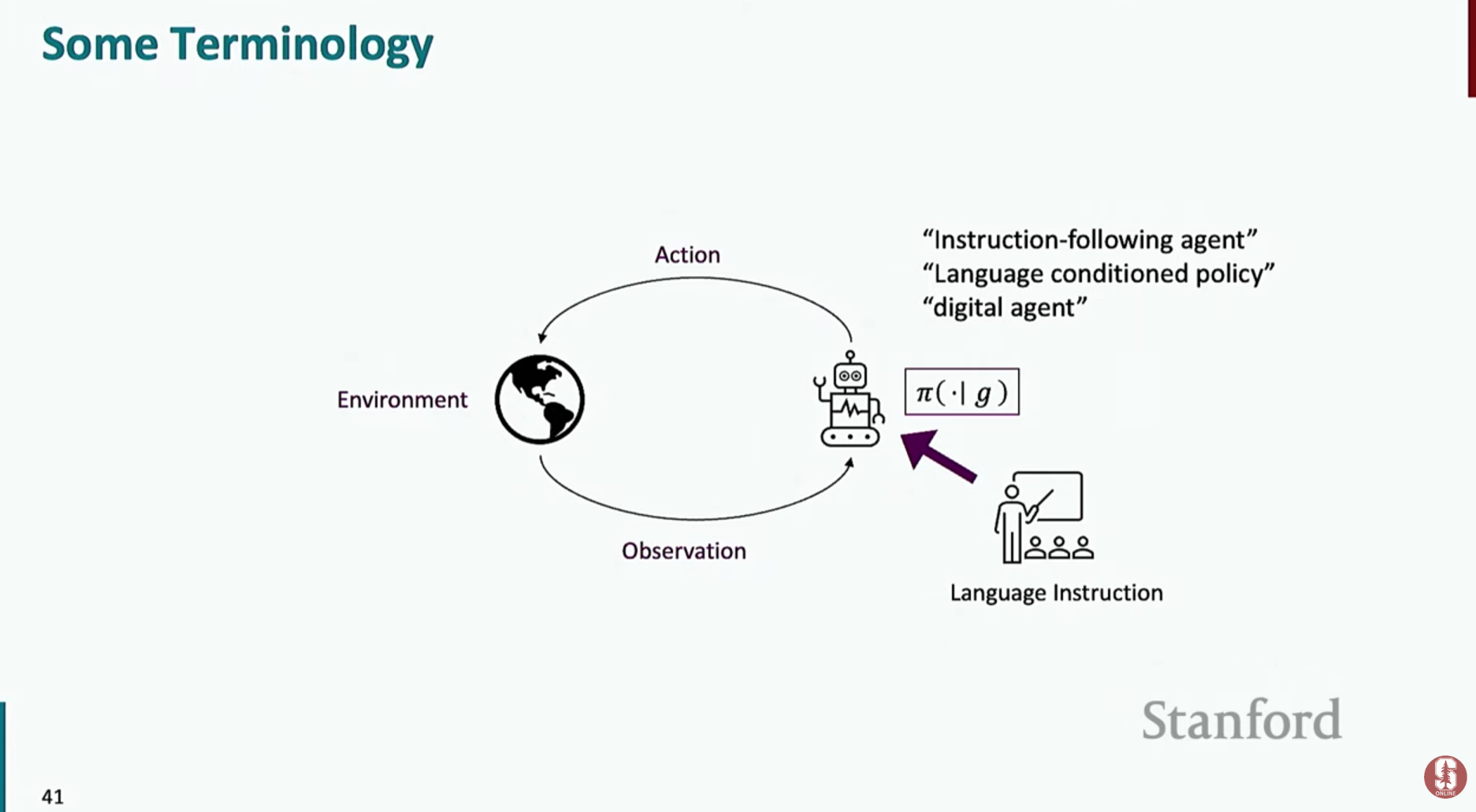
- **에이전트(Agent)**란 **환경(Environment)**을 관찰하고, 주어진 목표(언어 지침, G)를 달성하기 위해 **행동(Action)**을 수행하는 주체를 말합니다.
- 예를 들어, "LA행 가장 저렴한 비행기 표를 예약해줘"라는 언어 지침을 받은 에이전트는 웹 브라우저라는 환경과 상호작용하며 클릭, 타이핑 등의 행동을 수행하여 목표를 완료합니다.
- 주요 용어:
- 에이전트: 신경망(언어 모델)으로 구현됩니다.
- 환경: 웹 브라우저, 앱 UI, 파일 시스템 등 에이전트가 상호작용하는 모든 공간을 의미합니다.
- 관찰 (Observation): 환경의 현재 상태 (예: 웹페이지의 HTML 코드, 스크린샷)
- 행동 (Action): 에이전트가 환경에 가하는 변화 (예: 버튼 클릭, 텍스트 입력)
2) 언어 모델 기반 에이전트의 작동 원리
- 과거에는 의미 분석기(Semantic Parsers)나 강화학습(Reinforcement Learning) 같은 복잡한 방법론이 사용되었지만, 최근에는 언어 모델 자체의 능력을 활용하는 방식으로 패러다임이 바뀌었어요.
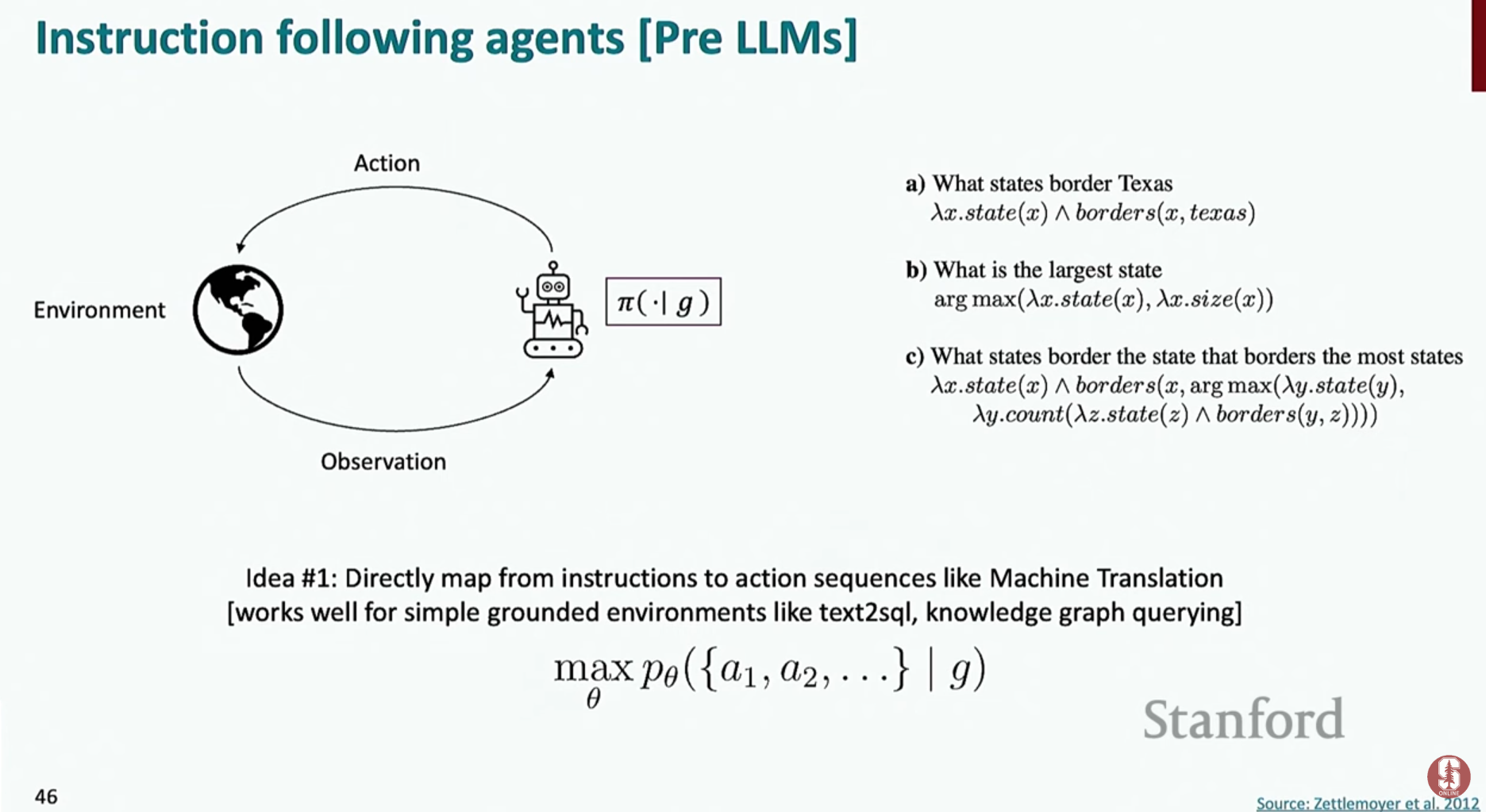
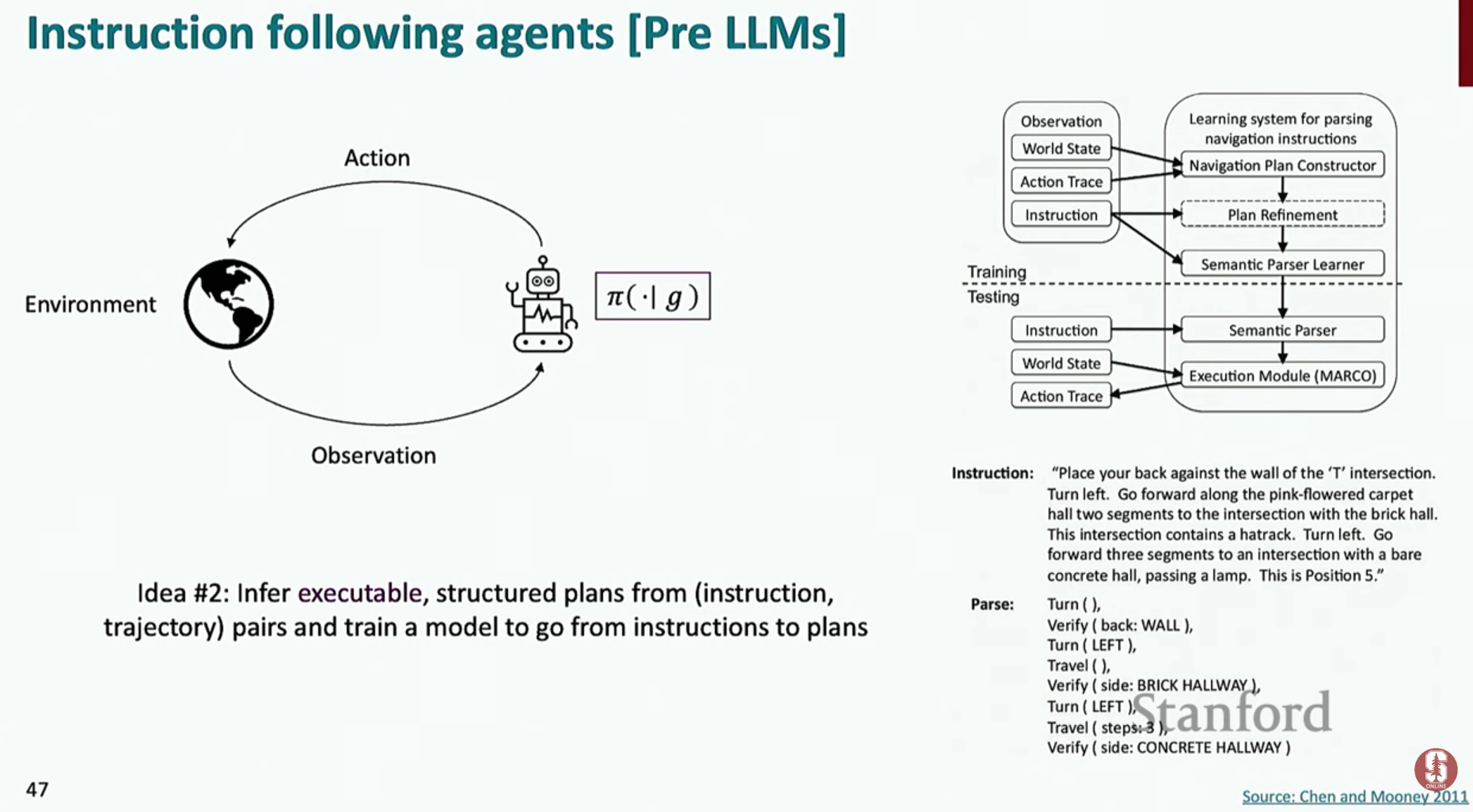

- 궤적 모델링 (Trajectory Modeling): 에이전트의 의사결정 문제를 언어 모델링 문제로 재구성한 것입니다.
(과거의 행동 이력, 현재 상태, 목표)를 입력(prompt)으로 받아,(다음에 해야 할 행동)을 예측하도록 모델을 학습시킵니다. 이는 본질적으로 다음에 올 단어를 예측하는 것과 같아요.
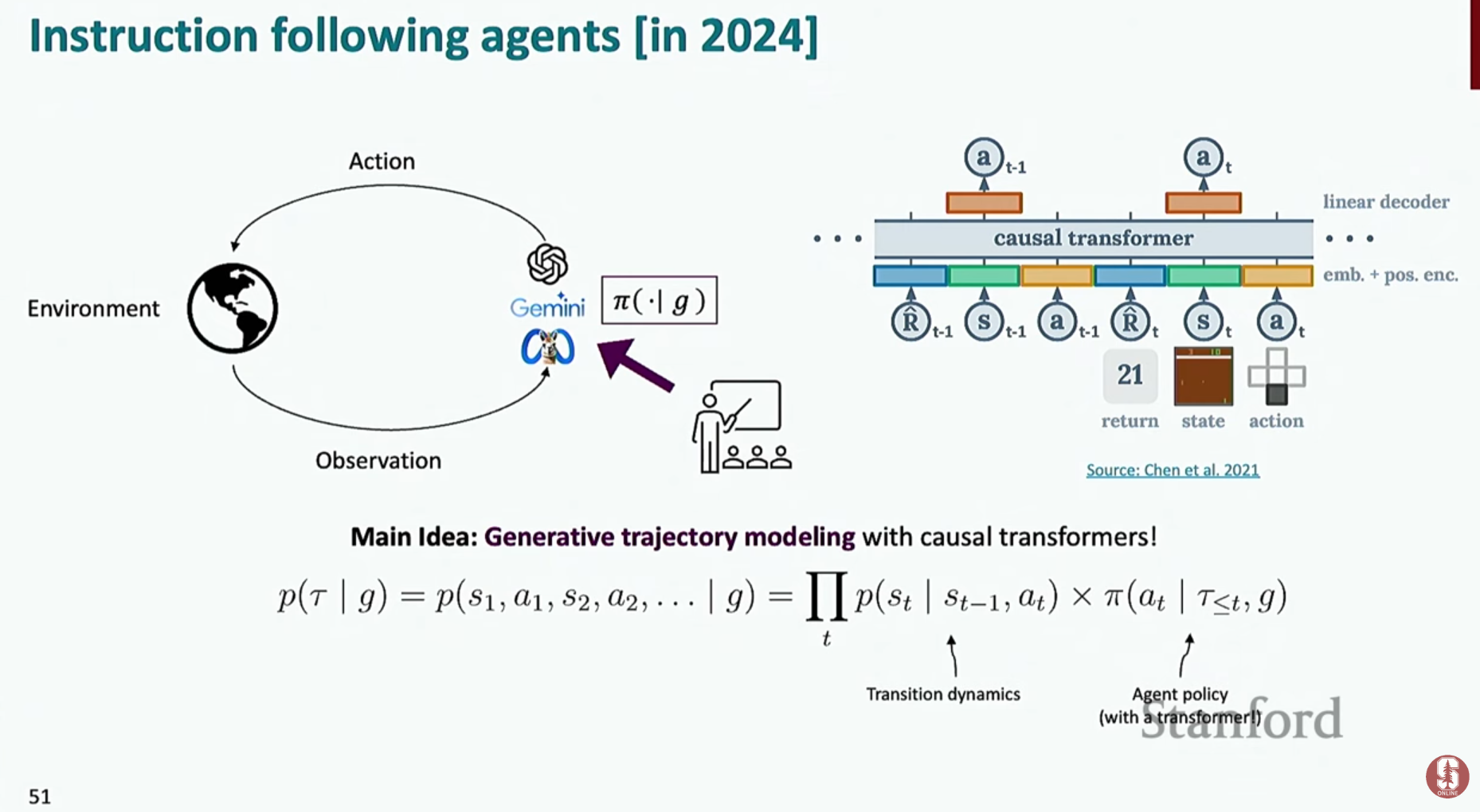
- 프롬프트를 이용한 루프 (Prompting in a Loop): 모델에게 현재까지의 행동/관찰 기록과 목표를 계속해서 프롬프트로 제공하며, 다음 행동을 반복적으로 예측하게 만드는 방식입니다. 이는 추론에서 사용된 CoT를 행동 결정에 반복적으로 적용하는 것과 유사해요.

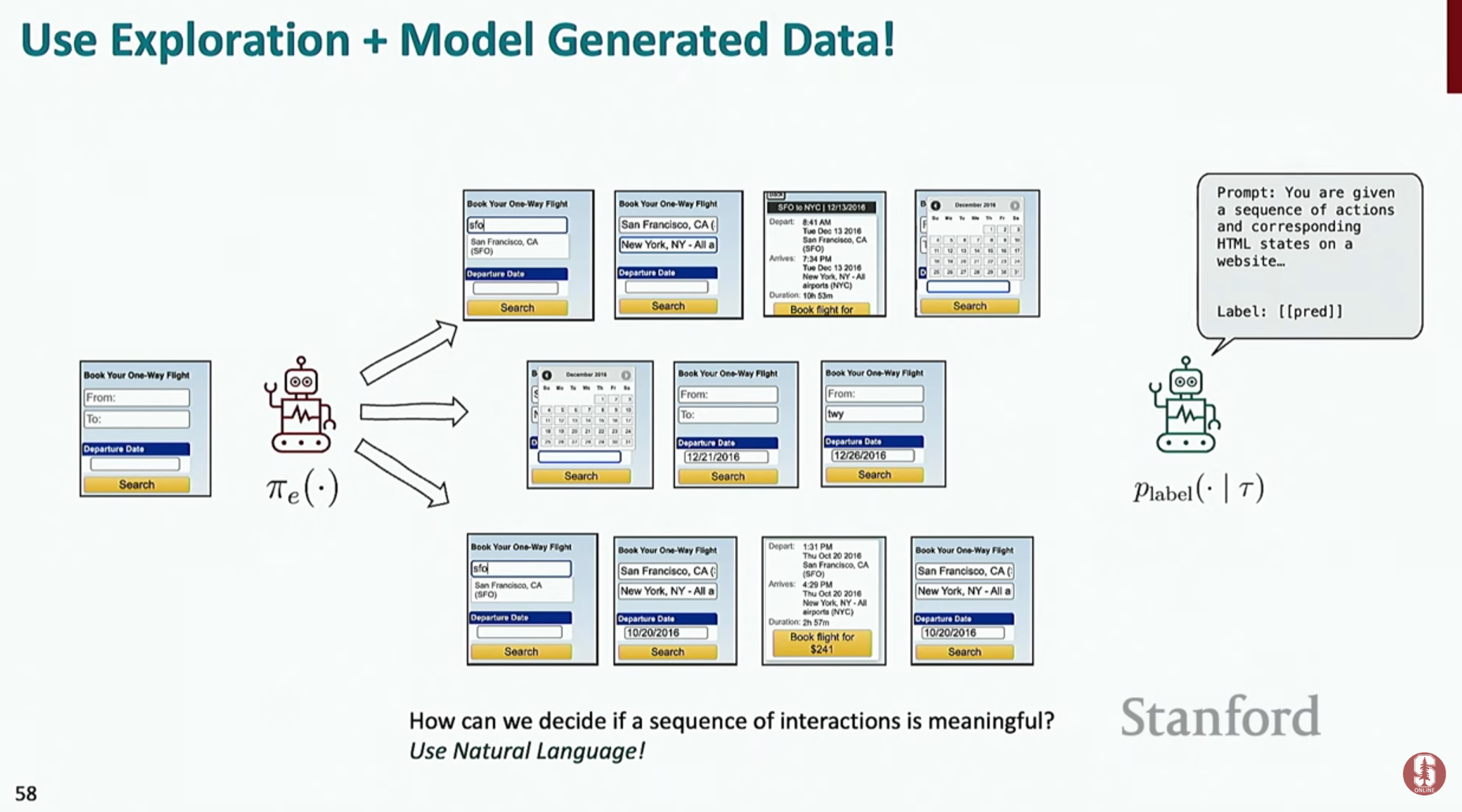
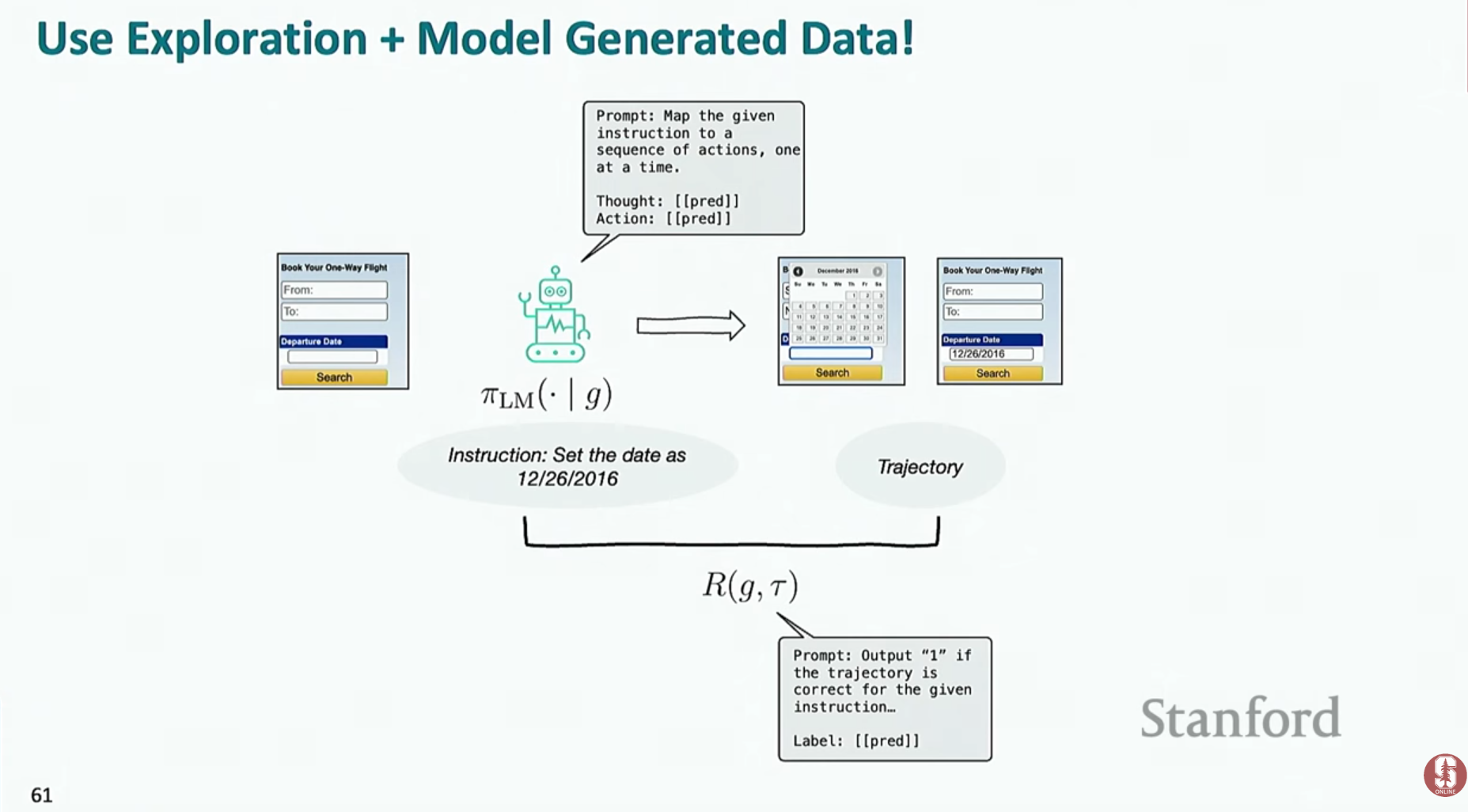
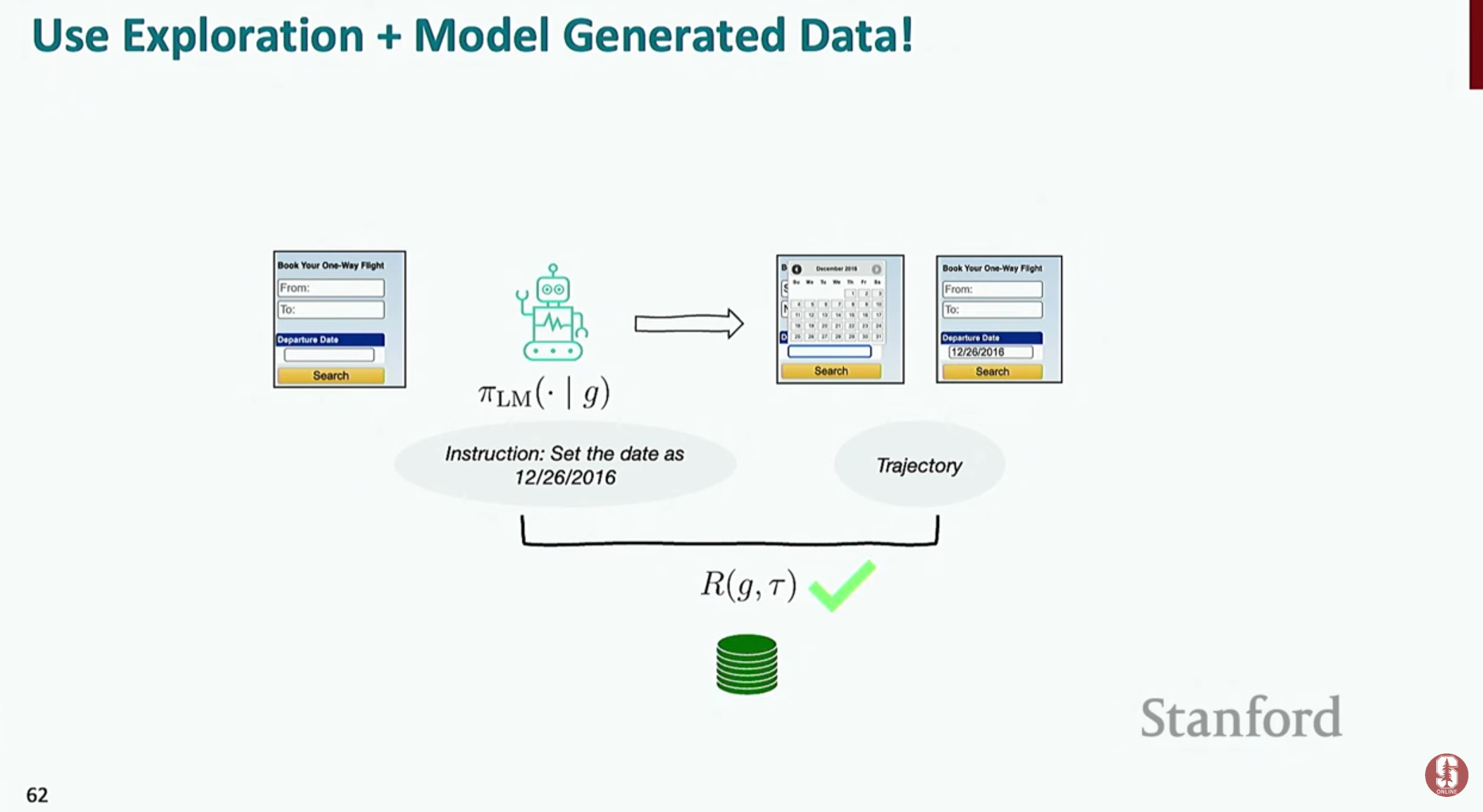
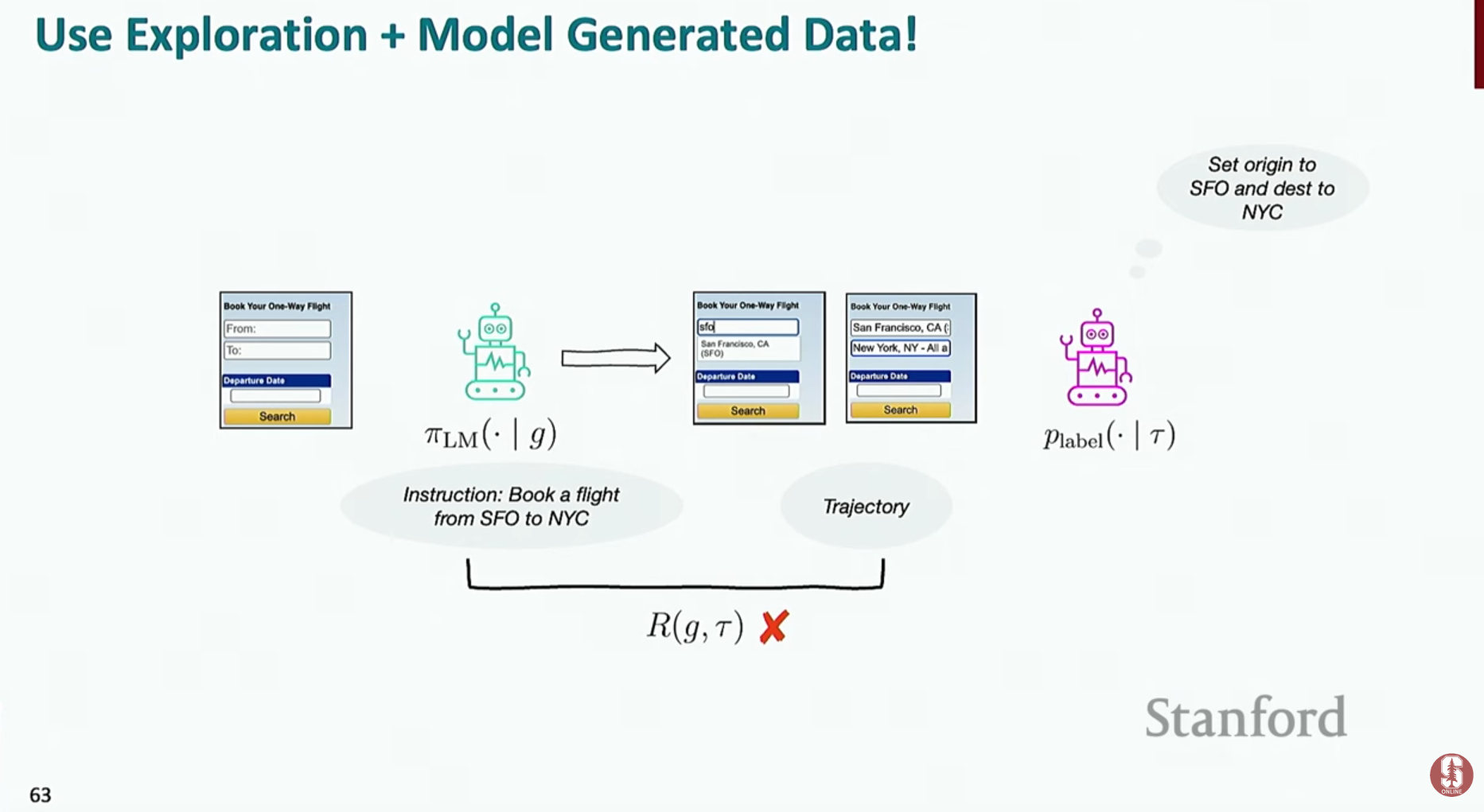
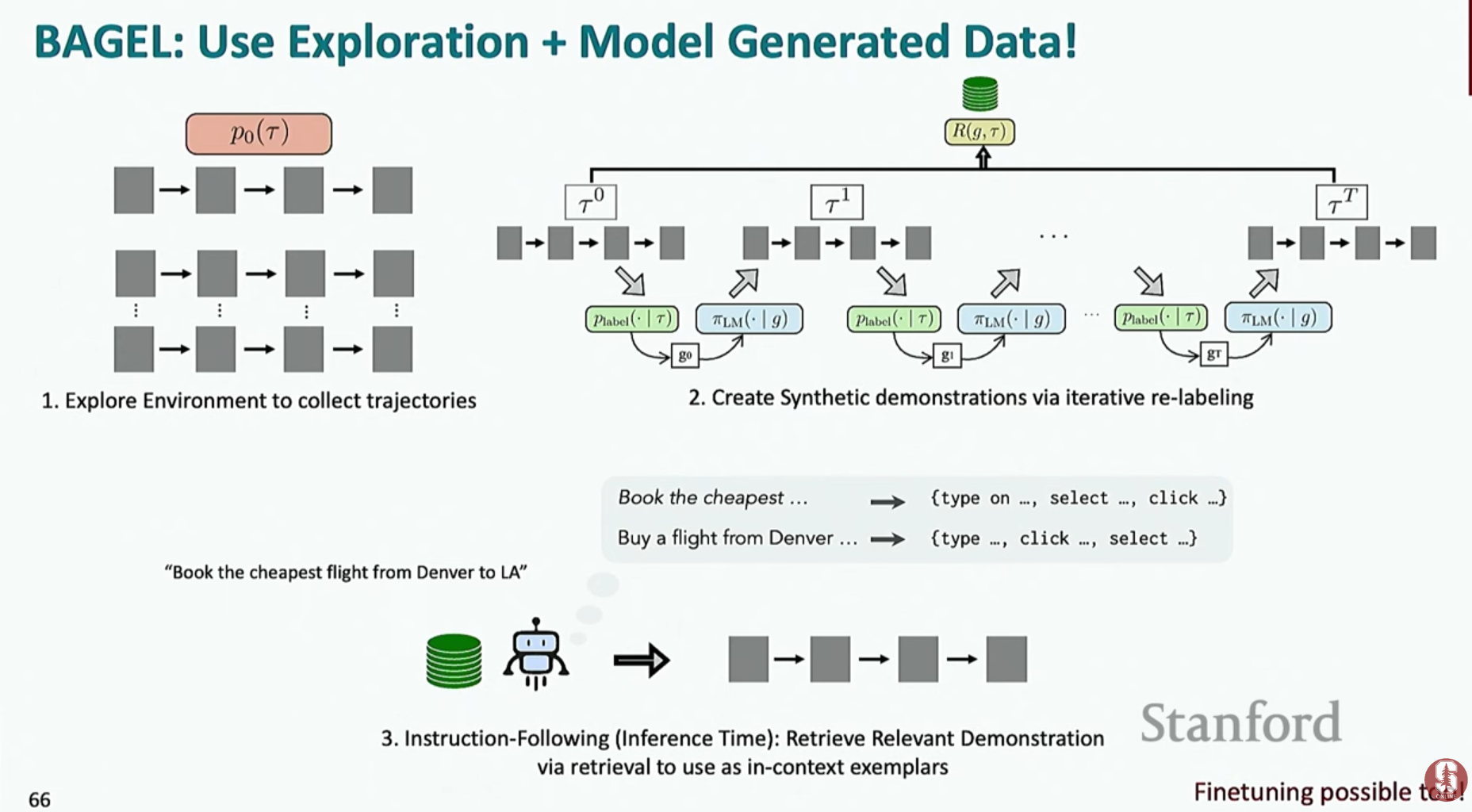
- 합성 데이터 생성 (Synthetic Data Generation): 실제 사람의 행동 데이터 없이도 에이전트를 훈련시키기 위한 기법입니다.
- 1단계 (탐색): 언어 모델을 이용해 환경 내에서 자유롭게 행동하며 다양한 경험 데이터(궤적)를 수집합니다.
- 2단계 (재라벨링): 수집된 궤적에 대해 언어 모델이 "이 행동은 ~라는 목표를 달성하기 위한 것이었어"라고 자연어 설명을 붙입니다.
- 3단계 (학습): 이렇게 생성된 (설명, 행동 궤적) 쌍을 고품질의 합성 훈련 데이터로 사용하여 모델을 학습시킵니다.
3) 시각 정보를 활용하는 에이전트 (VLM Agents)
-
에이전트가 텍스트뿐만 아니라 스크린샷과 같은 시각 정보를 이해하고 행동할 수 있게 하는 시각 언어 모델(Vision Language Models, VLM) 기반의 접근 방식도 활발히 연구되고 있습니다.
-
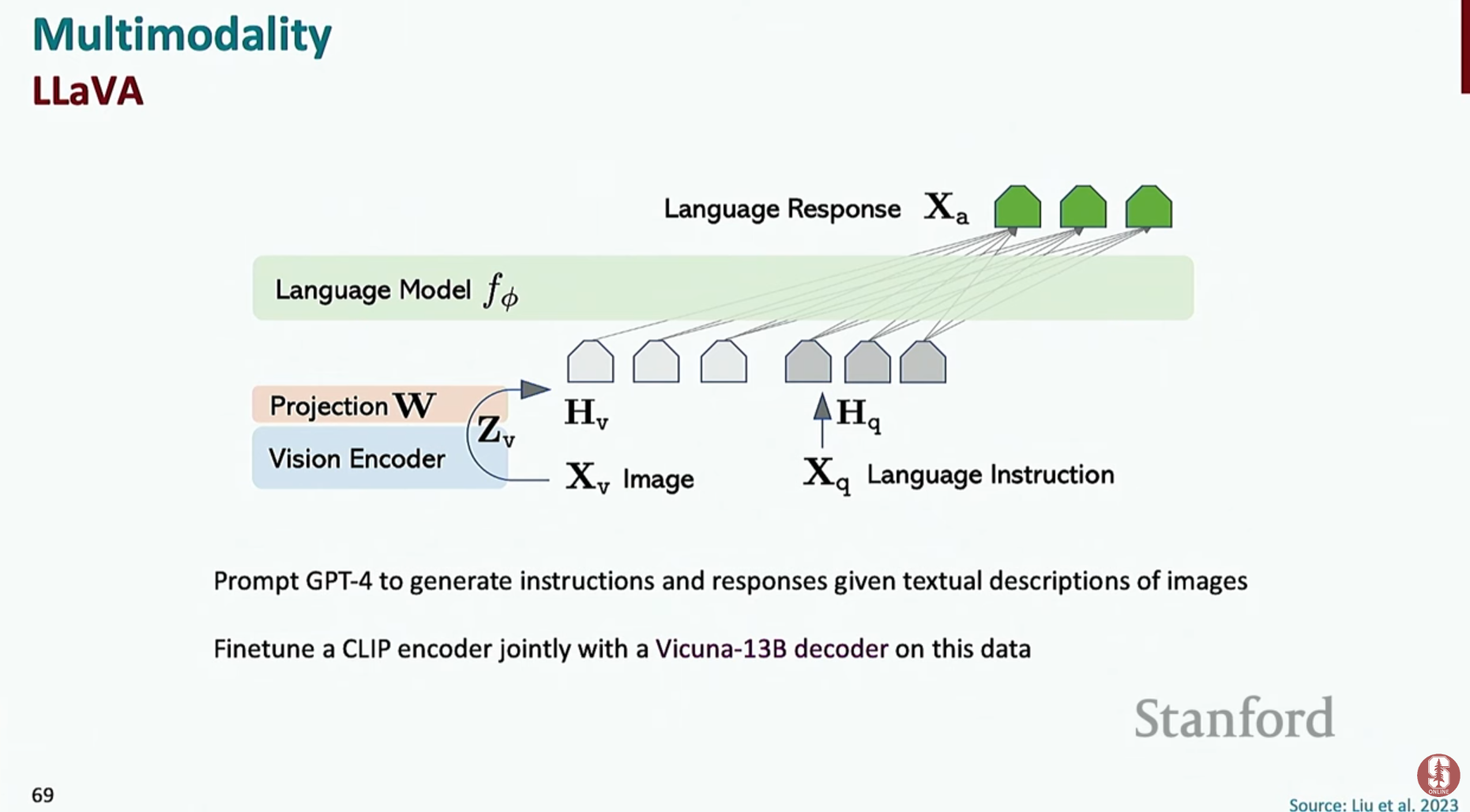
LAVA (Language And Vision Assistant): 이미지 인코더(CLIP)와 텍스트 디코더(LLaMA)를 결합하여, 이미지에 대한 질문에 자연어 답변을 생성하도록 훈련된 모델입니다.
-
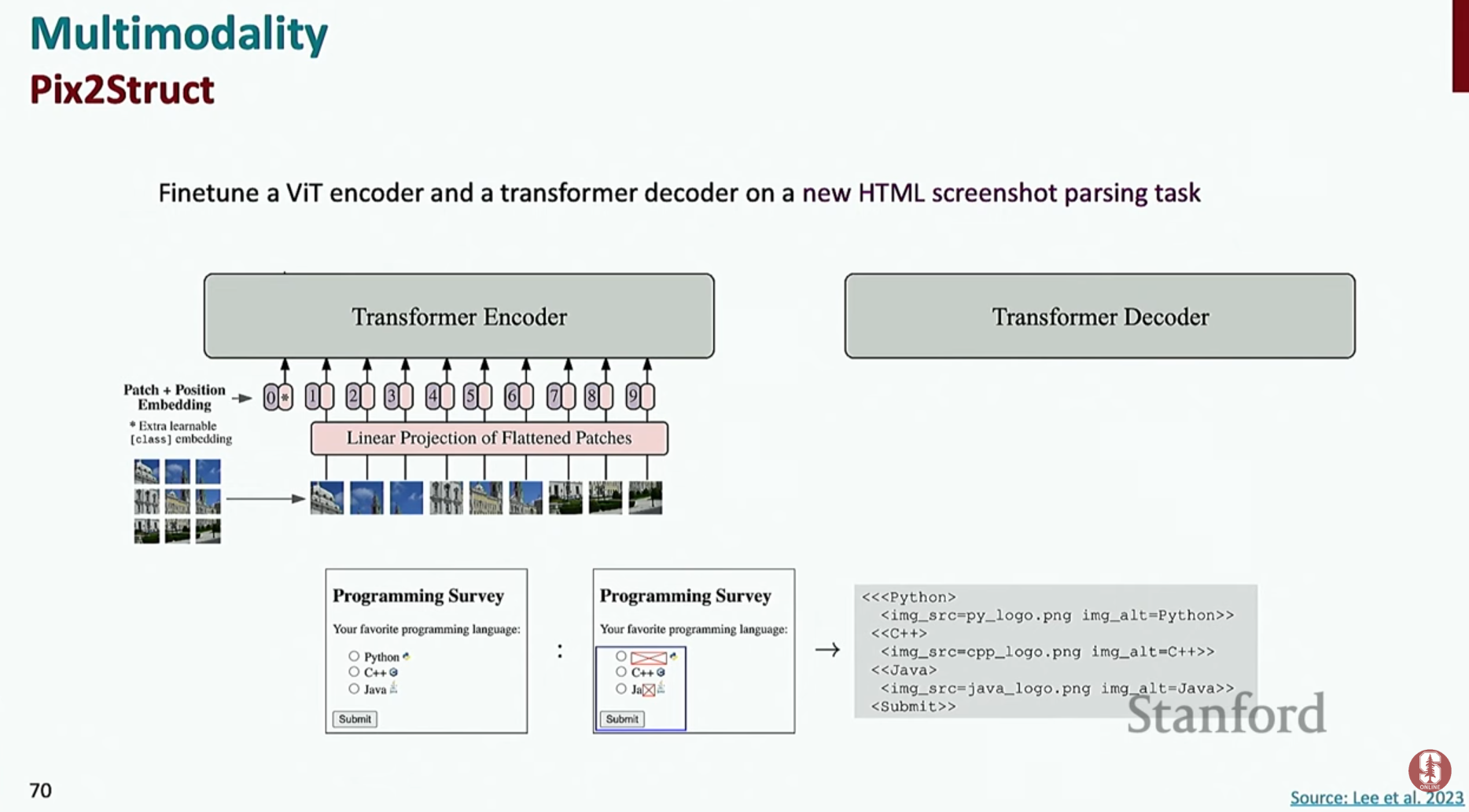
Pix2Struct: 웹페이지 스크린샷의 일부를 가리고, 모델이 그 부분에 해당하는 HTML 코드를 생성하도록 학습시키는 새로운 사전 훈련 방식을 사용합니다. 이를 통해 모델은 시각적 레이아웃과 코드 구조 간의 관계를 더 깊이 이해하게 됩니다.
4) 심화 학습: 현재 에이전트 기술의 도전 과제
- 강의에서 언급된 것처럼, 언어 모델 에이전트는 엄청난 가능성을 보여주지만 아직 넘어야 할 산이 많습니다.
- 장기 계획의 어려움 (Long-Horizon Planning): "이메일 보내기"처럼 몇 단계면 끝나는 작업에 비해, "여행 계획 세우기"처럼 수십, 수백 개의 행동이 필요한 장기적인 작업에서는 성공률이 급격히 떨어집니다.
- 최신 동향: 이 문제를 해결하기 위해 복잡한 목표를 여러 하위 목표로 자동 분해하고, 각 단계를 독립적인 에이전트가 처리하는 멀티 에이전트(Multi-Agent) 시스템이나 Chain-of-Agents 같은 연구가 주목받고 있습니다.
- 현실 세계 환경의 복잡성과 취약성: WebArena와 같이 실제 웹 환경을 모방한 복잡한 벤치마크에서는 아직 인간의 성공률에 크게 미치지 못합니다.
- 명확한 한계점: 모델은 종종 "사용자 이름" 칸에 "이메일 주소"를 입력하는 것과 같은 아주 사소하고 이상한 실수를 저지르며, 한 번 실수하면 그 상황에서 벗어나지 못하고 계속해서 실패하는 경향이 있습니다. 이는 에이전트의 **강건성(robustness)**이 아직 부족하다는 것을 의미하며, 예측 불가능한 실제 환경에 바로 적용하기 어려운 이유이기도 합니다.
- 프롬프트 엔지니어링 의존성: 최고의 언어 모델조차도, 특정 작업에 맞춰 세심하게 설계된 프롬프트와 소수의 예시(few-shot examples)가 없으면 간단한 작업도 제대로 수행하지 못하는 경우가 많습니다. 이는 에이전트의 범용성을 제한하는 주요 요인입니다.

AI 공부합니다