1. 멀티모달리티(Multimodality)의 서막
1) 멀티모달리티란 무엇인가?
- 멀티모달리티(Multimodality)란, 텍스트, 이미지, 음성, 오디오 등 여러 '모드(mode)'의 정보를 함께 처리하고 이해하는 인공지능 분야를 의미합니다.
- 인간은 세상을 이해할 때 시각, 청각 등 다양한 감각을 동시에 사용합니다. 예를 들어, 우리는 말하는 사람의 입 모양(시각)과 목소리(청각)를 함께 활용하여 소리를 인식하는데, 이를 맥거크 효과(McGurk effect)라고 합니다.
- AI가 인간처럼 세상을 온전히 이해하기 위해서는, 이처럼 여러 양식의 데이터를 통합적으로 학습하는 멀티모달리티가 필수적입니다.
2) 왜 멀티모달리티가 중요한가?
- 표현의 충실성(Faithfulness): 인간의 경험과 가장 유사한 방식으로 세상을 이해하고 표현할 수 있습니다.
- 실용성(Practicality): 인터넷의 데이터는 대부분 텍스트와 이미지가 결합된 멀티모달 형태입니다.
- 데이터 확장성(Data Scaling): 텍스트 데이터만으로는 모델을 확장하는 데 한계가 있으며, 이미지나 비디오 같은 다른 양식의 데이터를 통해 모델이 세상을 더 깊이 배울 수 있습니다.

3) 멀티모달의 주요 응용 분야
- 검색(Retrieval): 텍스트로 이미지를 찾거나, 이미지로 텍스트를 검색합니다.
- 생성(Generation): 이미지 캡션을 만들거나(Image Captioning), 텍스트 설명으로 이미지를 생성합니다(Text-to-Image).
- 시각적 질의응답(Visual Question Answering, VQA): 이미지에 대한 질문에 답합니다.
- 멀티모달 분류(Multimodal Classification): 이미지와 텍스트를 함께 분석하여 혐오 발언 등을 탐지합니다.

2. 멀티모달 모델의 발전사: Transformer 이전의 모델들
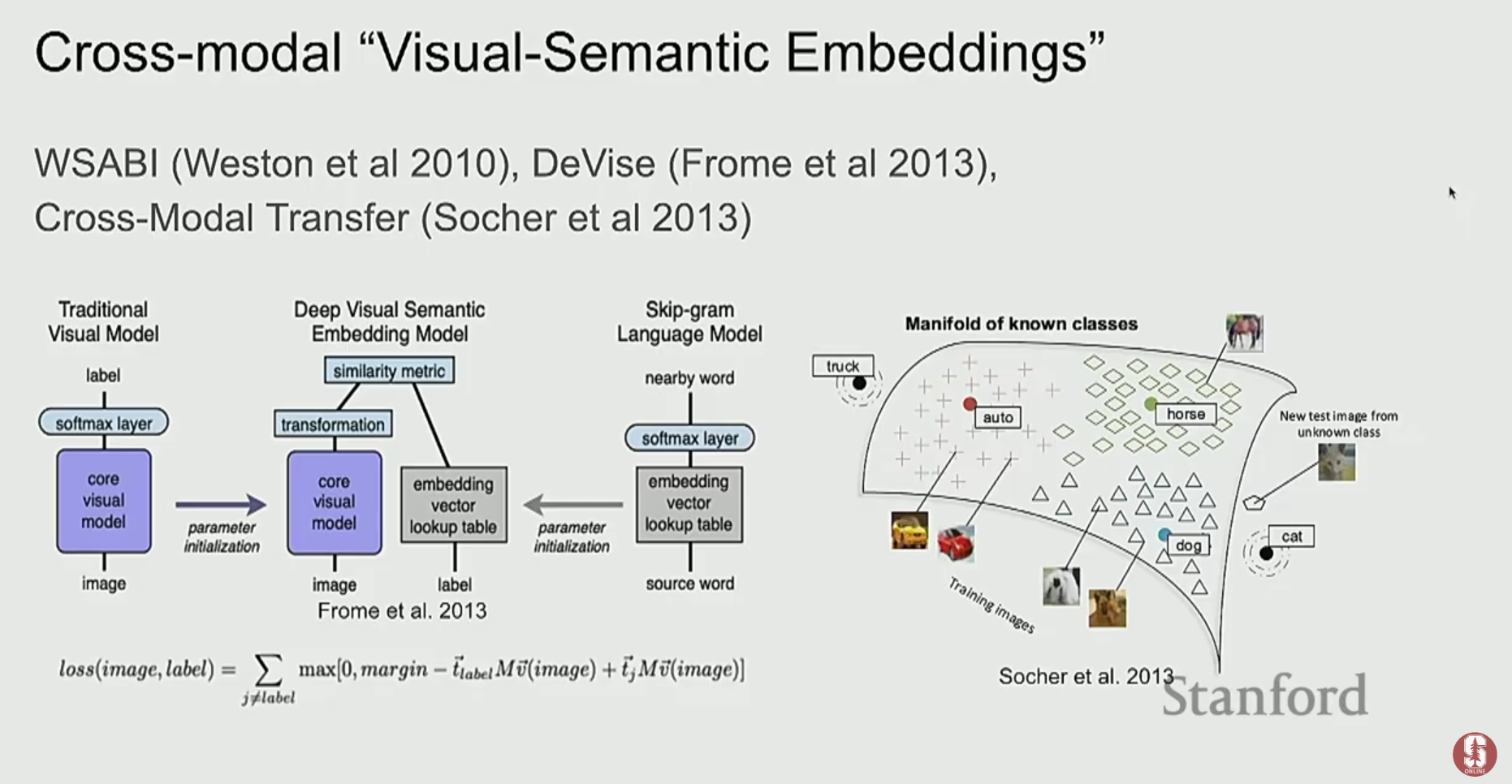

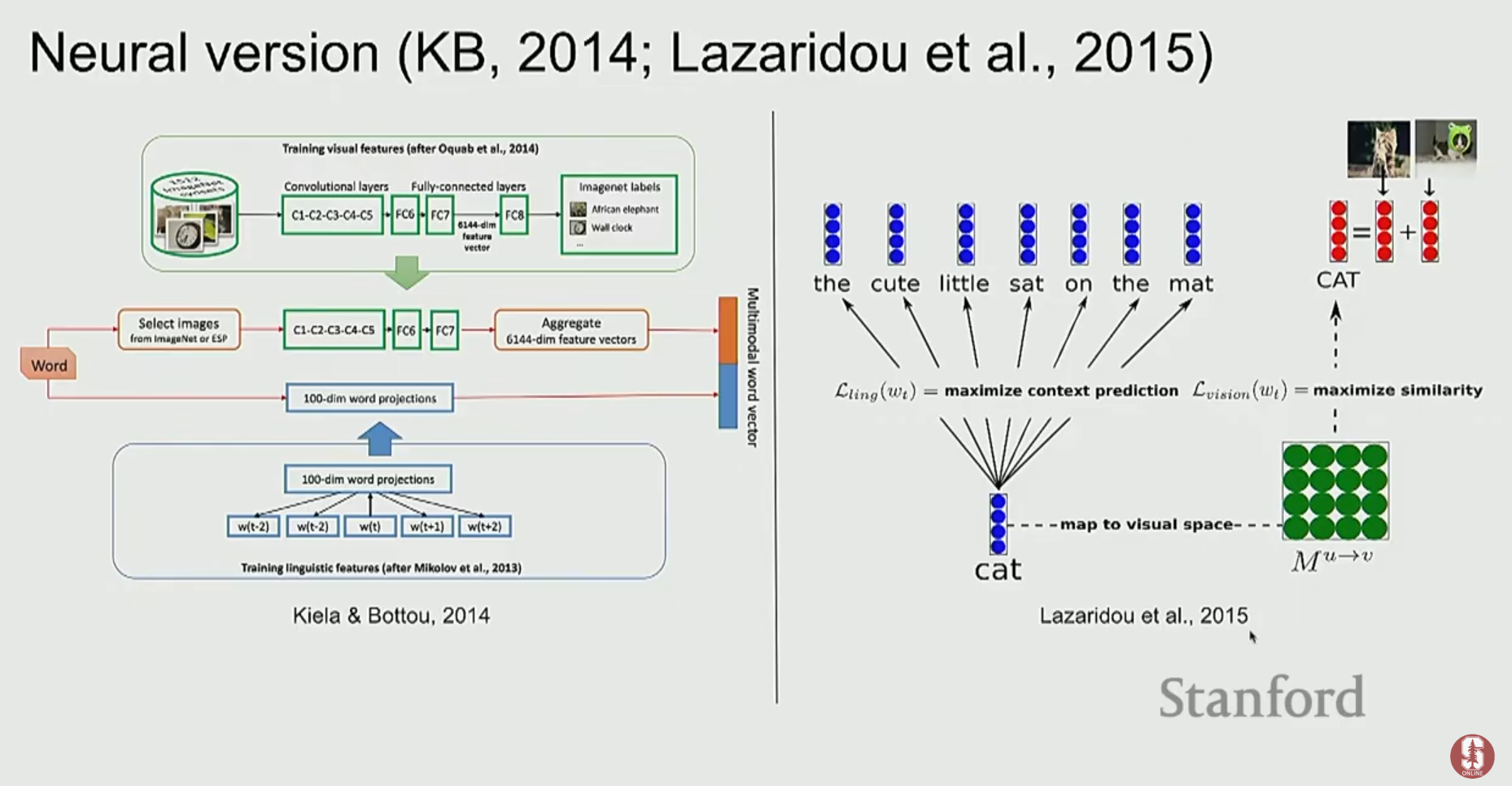
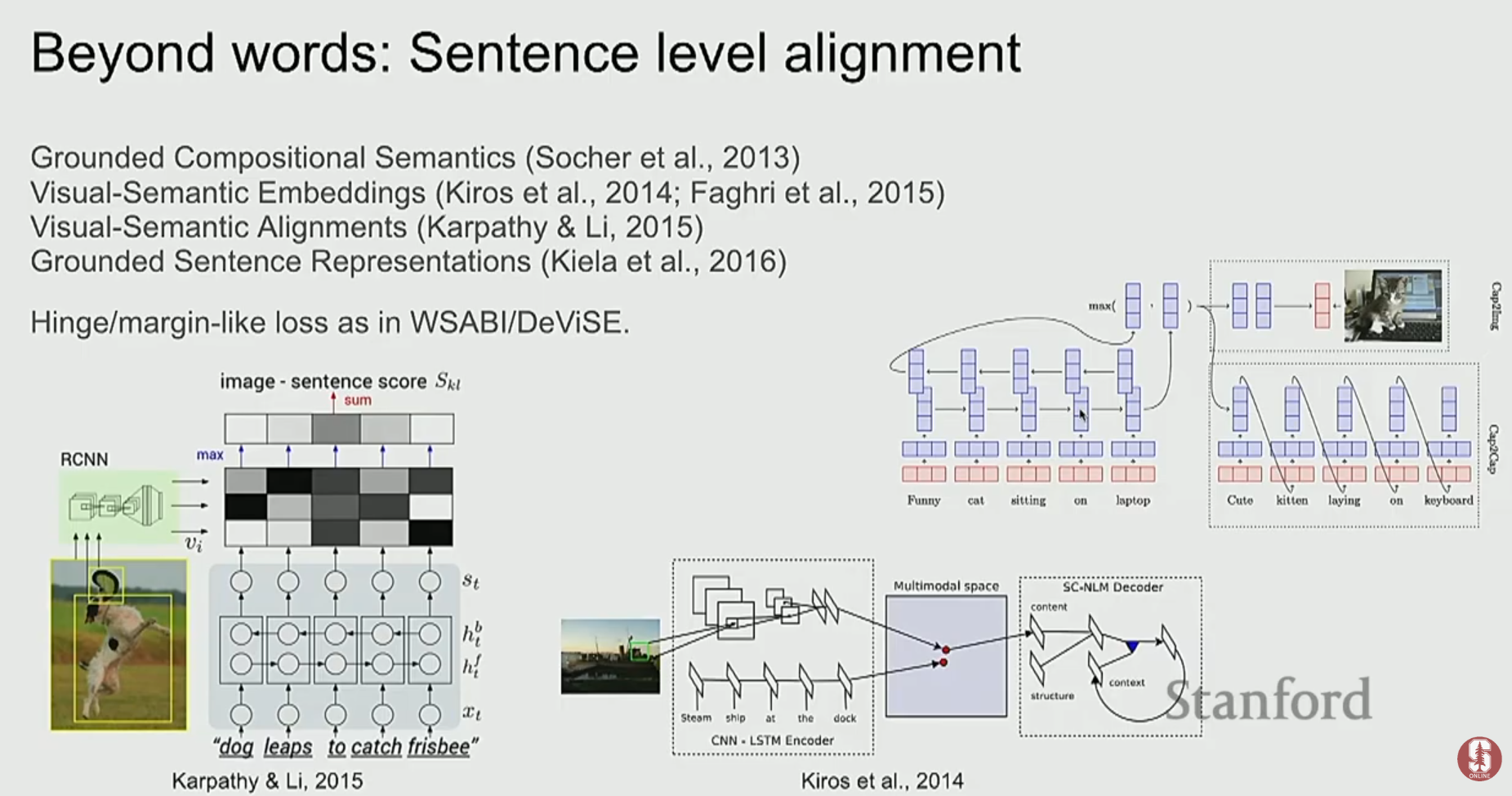
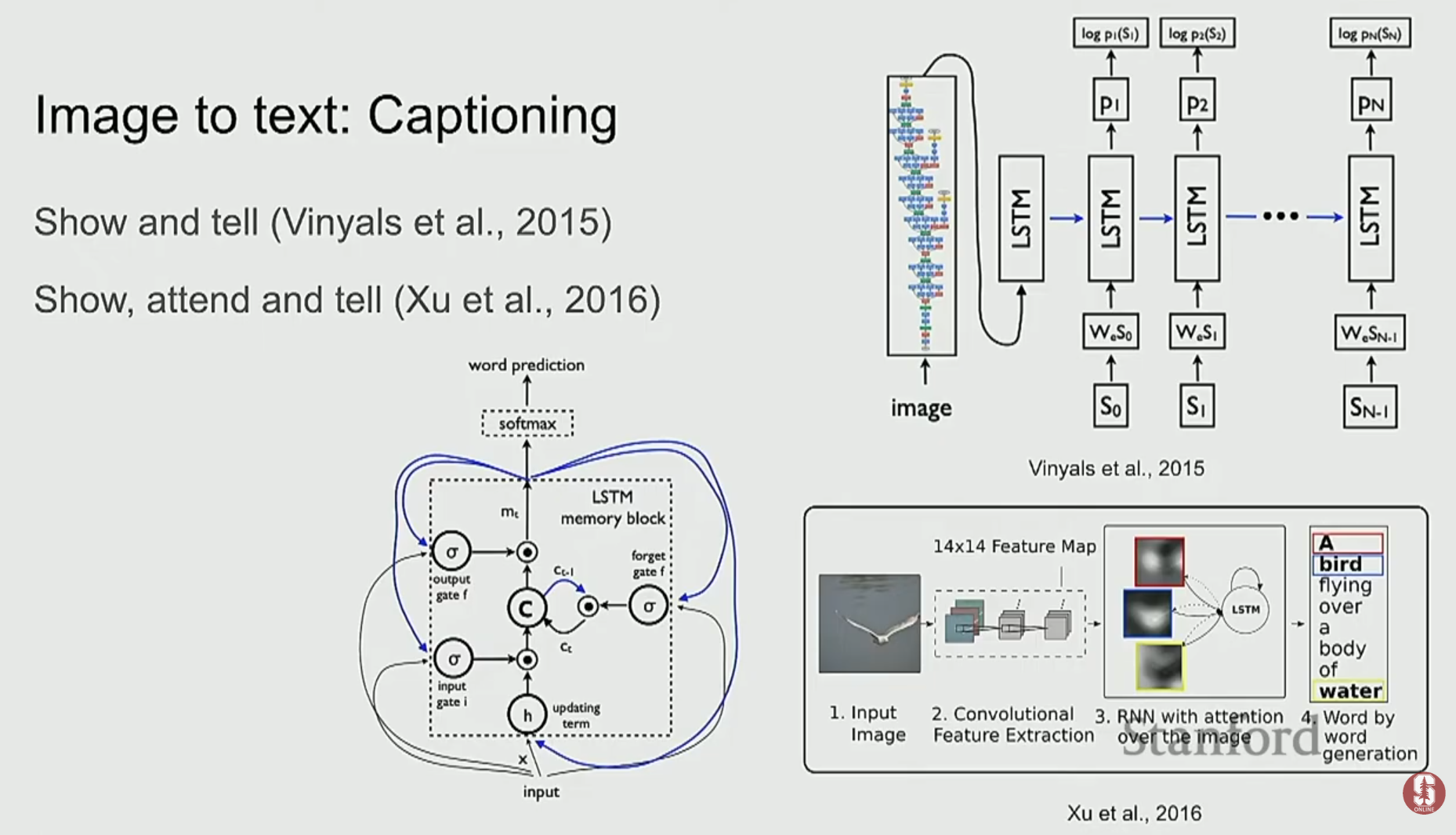

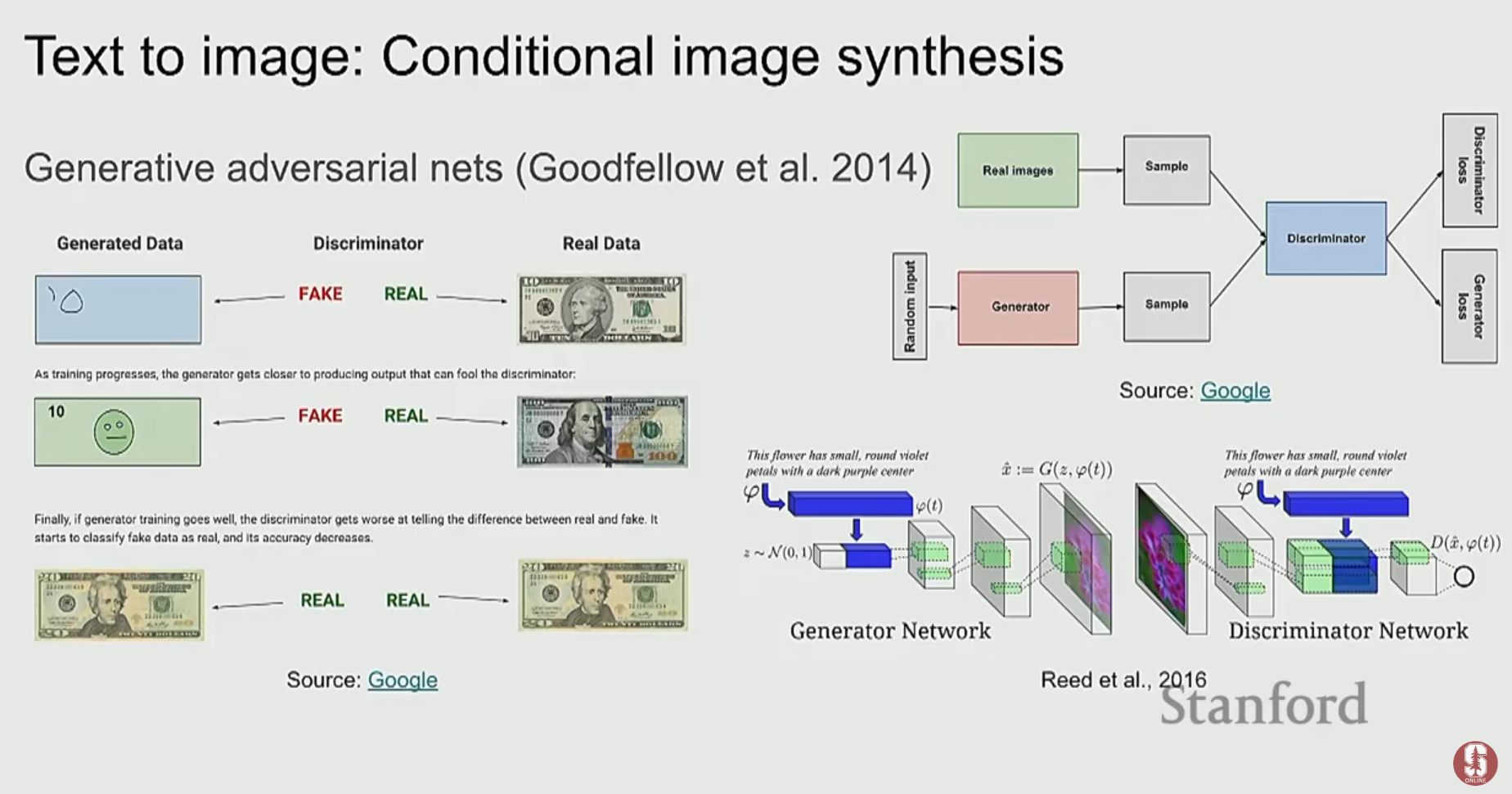
1) 초기 접근 방식: 임베딩 공간의 정렬
- 초기 연구들은 이미지와 텍스트를 각각 다른 인코더로 처리한 후, 이들을 공통된 임베딩 공간(shared embedding space)에 매핑하는 데 집중했습니다.
- 두 양식의 벡터가 가까워지도록 유사도(similarity)를 학습시키는 방식으로, 주로 검색(retrieval) 문제에 활용되었습니다.
- 예를 들어, '고양이'라는 단어의 임베딩과 고양이 이미지의 임베딩이 벡터 공간에서 가깝게 위치하도록 만드는 것입니다.
2) 이미지와 텍스트의 결합
- Bag of Visual Words (BoVW): 이미지를 텍스트처럼 다루기 위한 초기 접근법으로, 이미지의 주요 특징점(key points)들을 클러스터링하여 '시각적 단어'로 만들고, 이들의 집합으로 이미지를 표현했습니다.
- 딥러닝의 통합: CNN으로 이미지 특징을, Word2Vec 등으로 텍스트 특징을 추출한 뒤, 이 두 벡터를 단순 연결(concatenation)하거나 서로를 예측하는 방식으로 더 풍부한 표현을 학습했습니다.
- Sequence-to-Sequence 구조: CNN을 인코더로, RNN/LSTM을 디코더로 사용하여 이미지 캡션을 생성하는 모델이 등장했습니다. 특히 어텐션(Attention) 메커니즘을 통해, 캡션의 특정 단어가 이미지의 어떤 영역과 관련이 있는지 정렬할 수 있게 되었습니다.
3. 멀티모달 모델의 핵심: 특징 추출과 융합


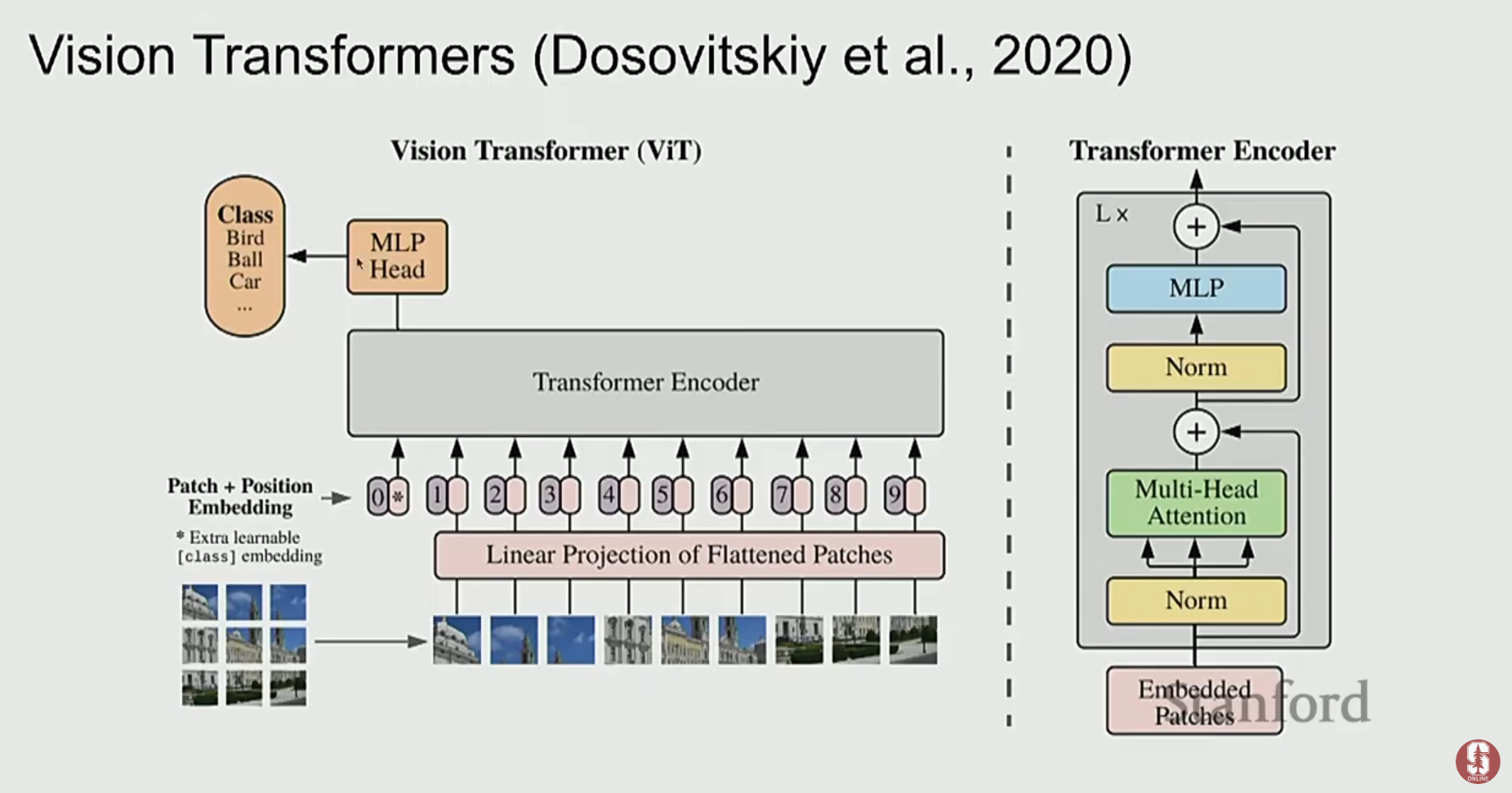


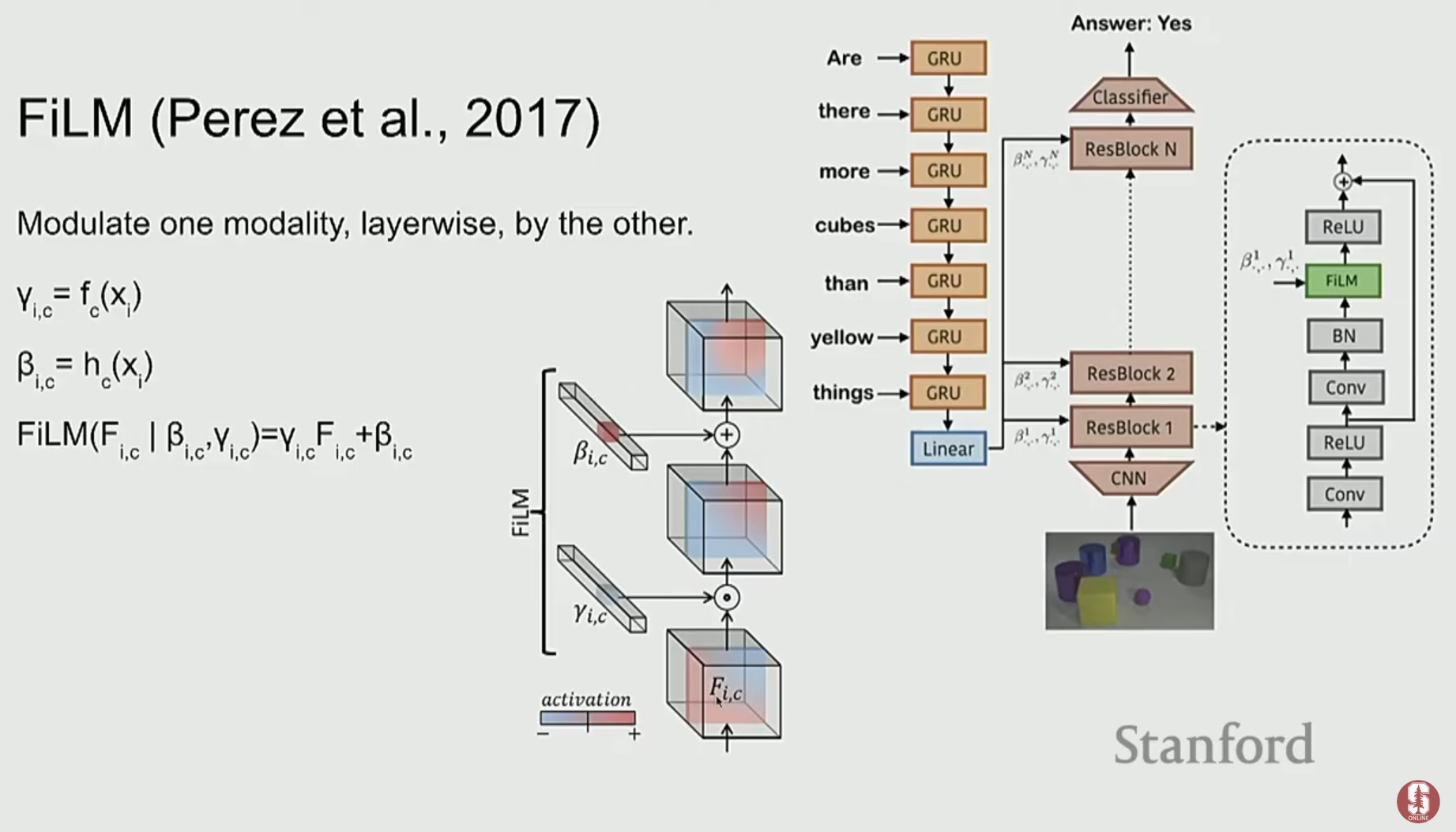
1) 이미지 특징 추출(Featurizing Images) 방식
- 영역 특징(Region Features): 객체 탐지 모델(Object Detector)을 사용하여 이미지 내의 특정 객체(예: 사람, 라켓, 셔츠)들의 위치(bounding box)와 특징을 각각 추출합니다.
- 밀집 특징(Dense Features): Vision Transformer (ViT)를 사용하여 이미지를 여러 개의 작은 패치(patch)로 나눈 뒤, 각 패치를 텍스트의 '토큰'처럼 취급하여 Transformer에 입력하는 방식입니다. 이는 이미지 전체의 맥락을 더 잘 포착할 수 있습니다.
2) 정보 융합(Fusion) 전략
- 서로 다른 양식에서 추출된 특징 벡터들을 어떻게 결합할 것인가는 멀티모달 모델의 핵심적인 설계 문제입니다.
- 초기 융합(Early Fusion): 모델의 가장 앞단에서부터 두 양식의 특징을 합쳐 하나의 큰 입력으로 간주하고 처리합니다. 모든 정보가 초반부터 상호작용할 수 있습니다.
- 중간 융합(Middle Fusion): 각 양식을 독립적으로 몇 개의 레이어에서 처리한 뒤, 중간 단계에서 특징을 결합합니다.
- 후기 융합(Late Fusion): 각 양식을 끝까지 독립적으로 처리하고, 최종 결과(예: 예측 점수)만을 결합합니다. 두 양식 간의 깊은 상호작용은 학습되지 않습니다.
4. 혁신을 이끈 주요 멀티모달 아키텍처
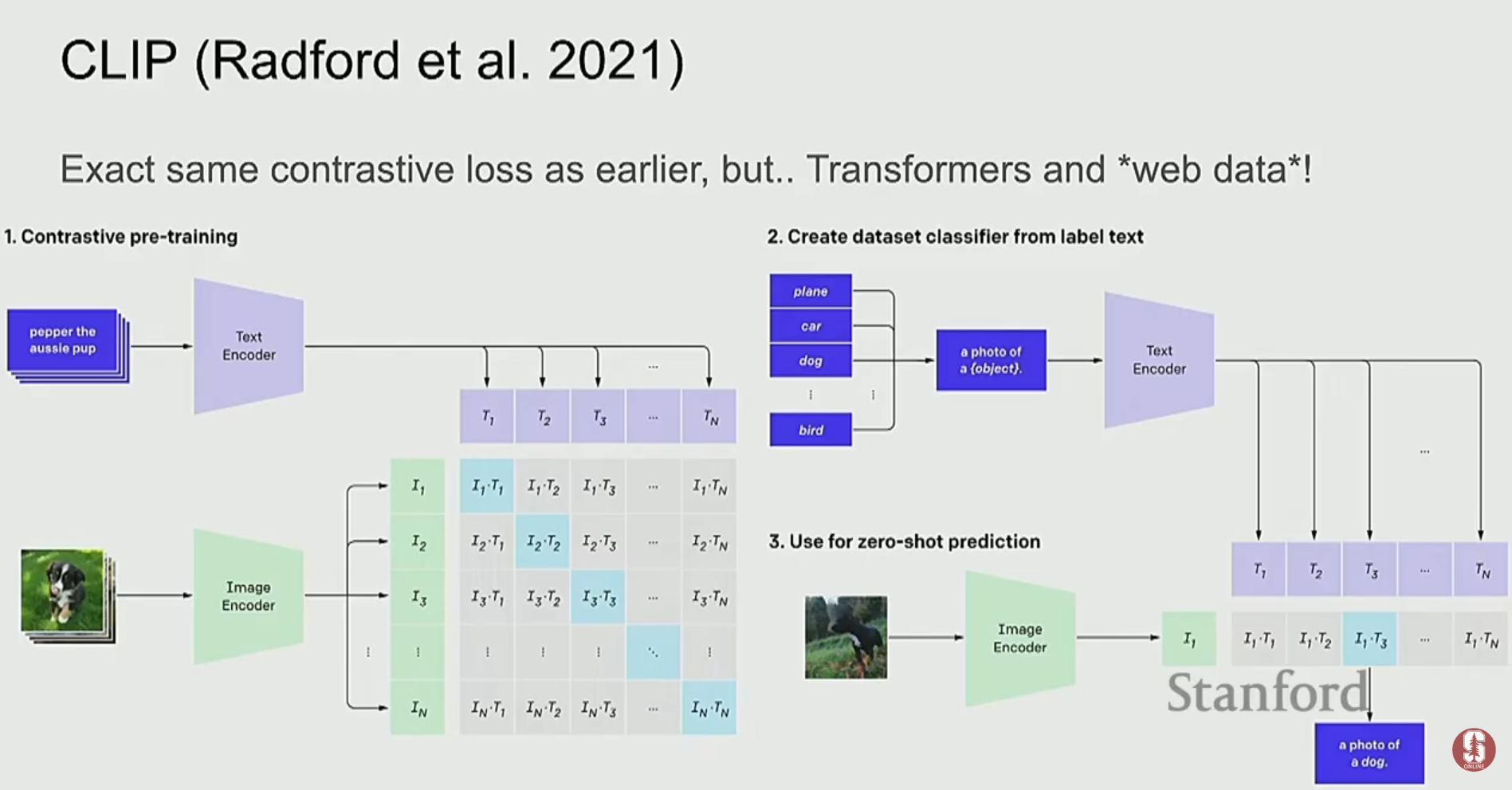
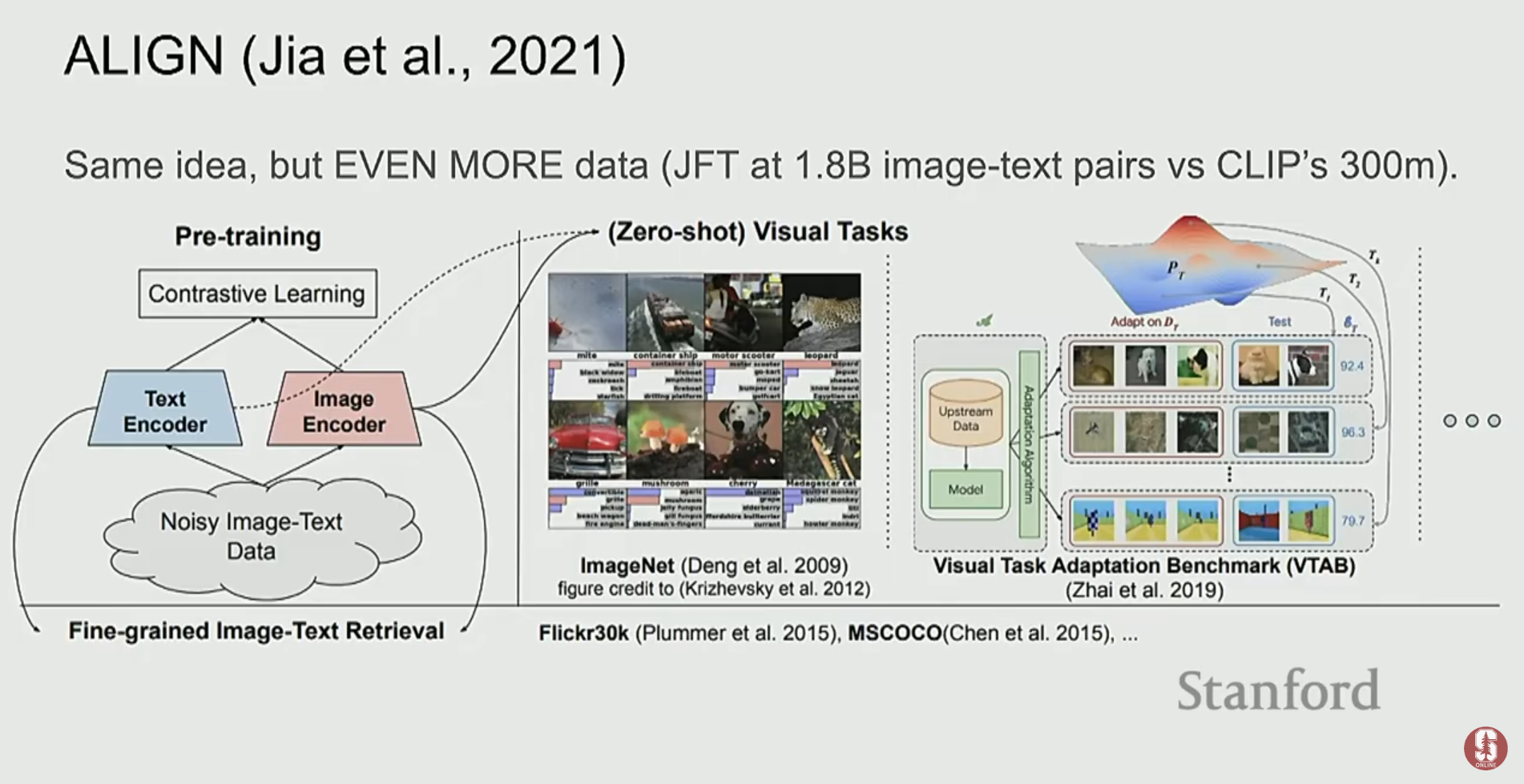
1) CLIP: 대조 학습의 위력
- CLIP (Contrastive Language-Image Pre-training)은 후기 융합 방식의 대표적인 모델로, 대조 학습(contrastive learning)을 사용합니다.
- 수억 개의 (이미지, 텍스트) 쌍 데이터를 학습하여, 서로 짝이 맞는 이미지와 텍스트의 임베딩은 가깝게, 짝이 맞지 않는 것들은 멀어지도록 이미지 인코더와 텍스트 인코더를 각각 학습시킵니다.
- 이 모델의 가장 큰 힘은 제로샷 일반화(zero-shot generalization) 능력입니다. 예를 들어, "a photo of a [label]" 형식의 프롬프트를 이용해, 한 번도 본 적 없는 데이터셋에서도 높은 분류 성능을 보입니다.
[심화 학습] CLIP의 기술적 배경과 한계
- 기술적 배경: CLIP의 성공은 단순하지만 강력한 학습 목표와 웹 규모의 방대한 데이터(4억 쌍) 덕분입니다. 두 개의 독립된 인코더를 학습시키는 구조는 확장성이 매우 뛰어납니다. 이 아이디어는 이후 Stable Diffusion과 같은 텍스트-이미지 생성 모델에서 텍스트를 이해하는 핵심 요소로 활용되었습니다.
- 최신 동향: CLIP의 임베딩 공간을 활용하여 이미지 생성 모델의 방향을 제어하거나, 비디오, 3D 등 다른 도메인으로 확장하려는 연구가 활발히 진행 중입니다.
- 명확한 한계점: CLIP은 '무엇'이 있는지는 잘 알지만, 객체 간의 관계나 속성, 개수(compositionality)를 파악하는 데는 취약합니다. 예를 들어, '말을 탄 우주비행사'와 '우주비행사를 탄 말'을 잘 구분하지 못할 수 있습니다. 또한 웹 데이터의 편향을 그대로 학습하여 사회적 편견을 재생산할 위험이 있습니다.


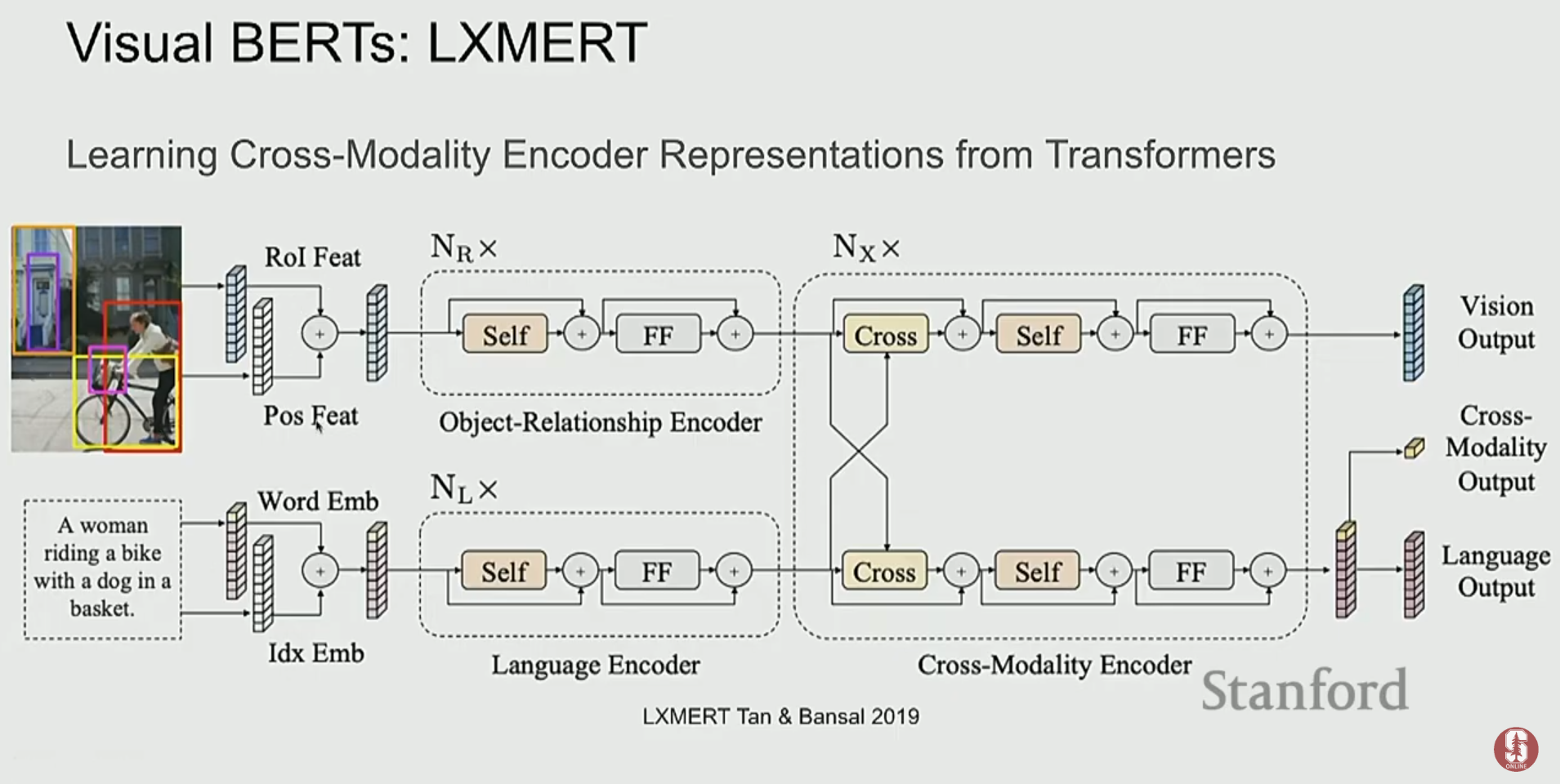
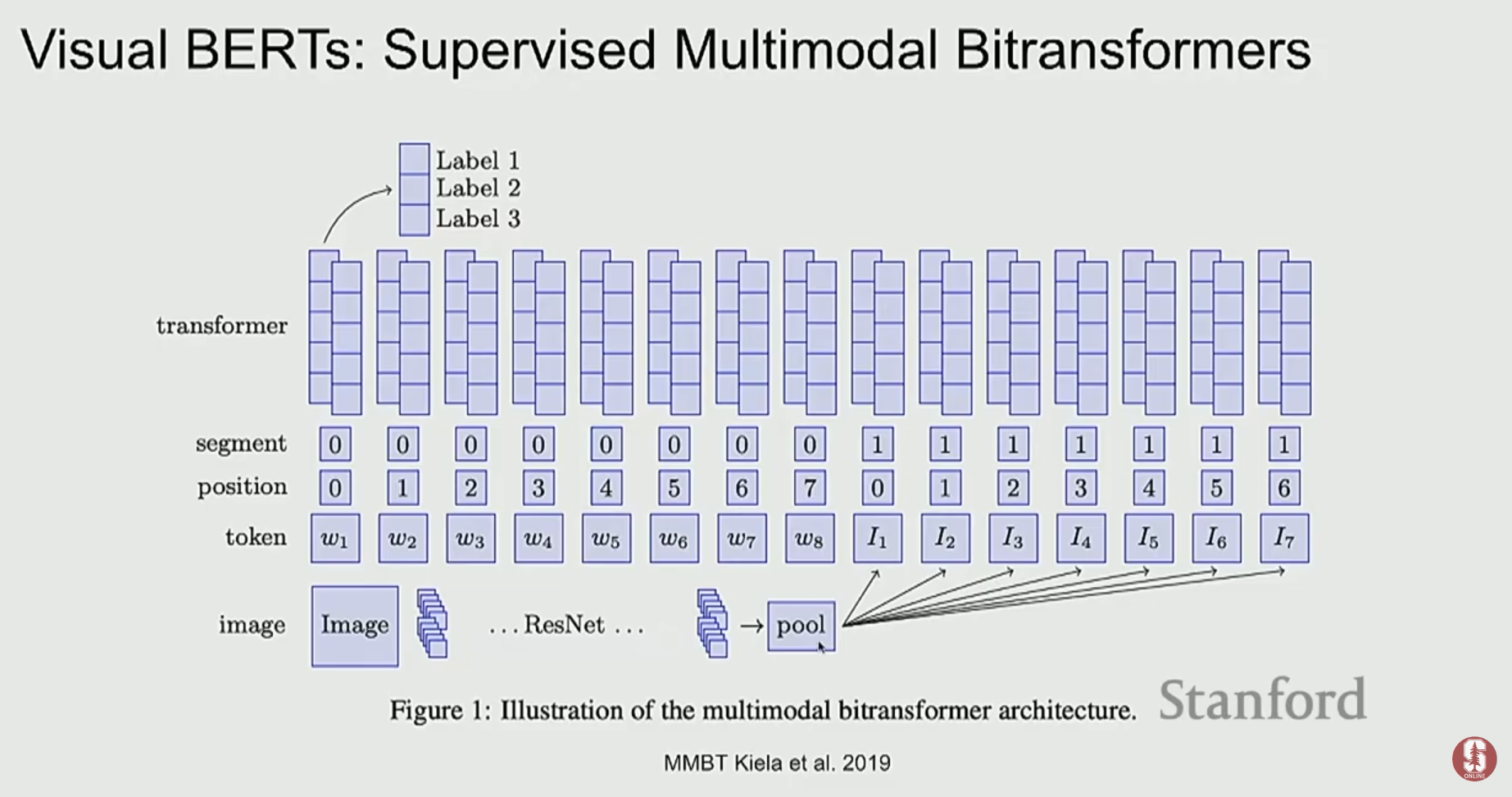
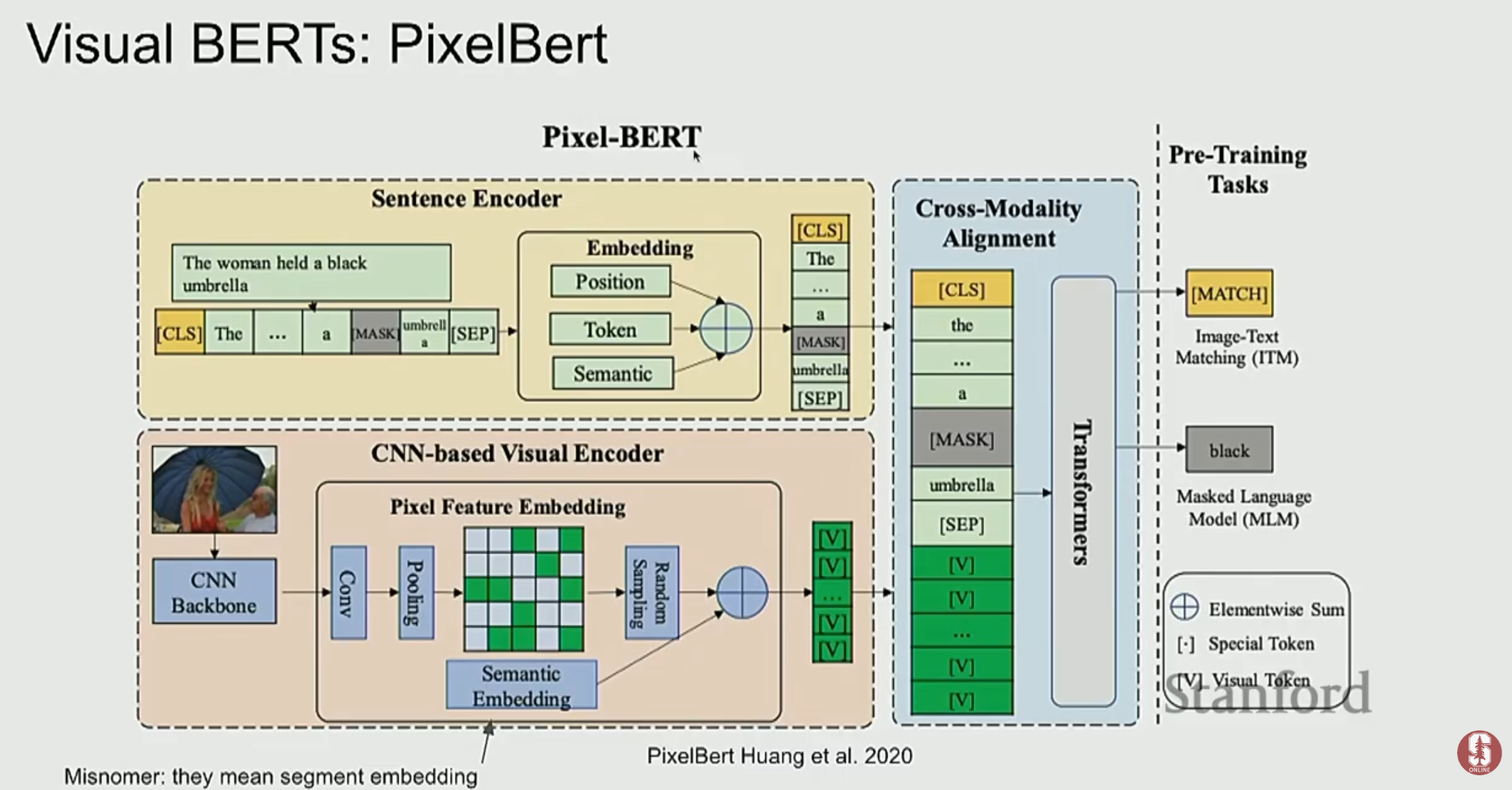
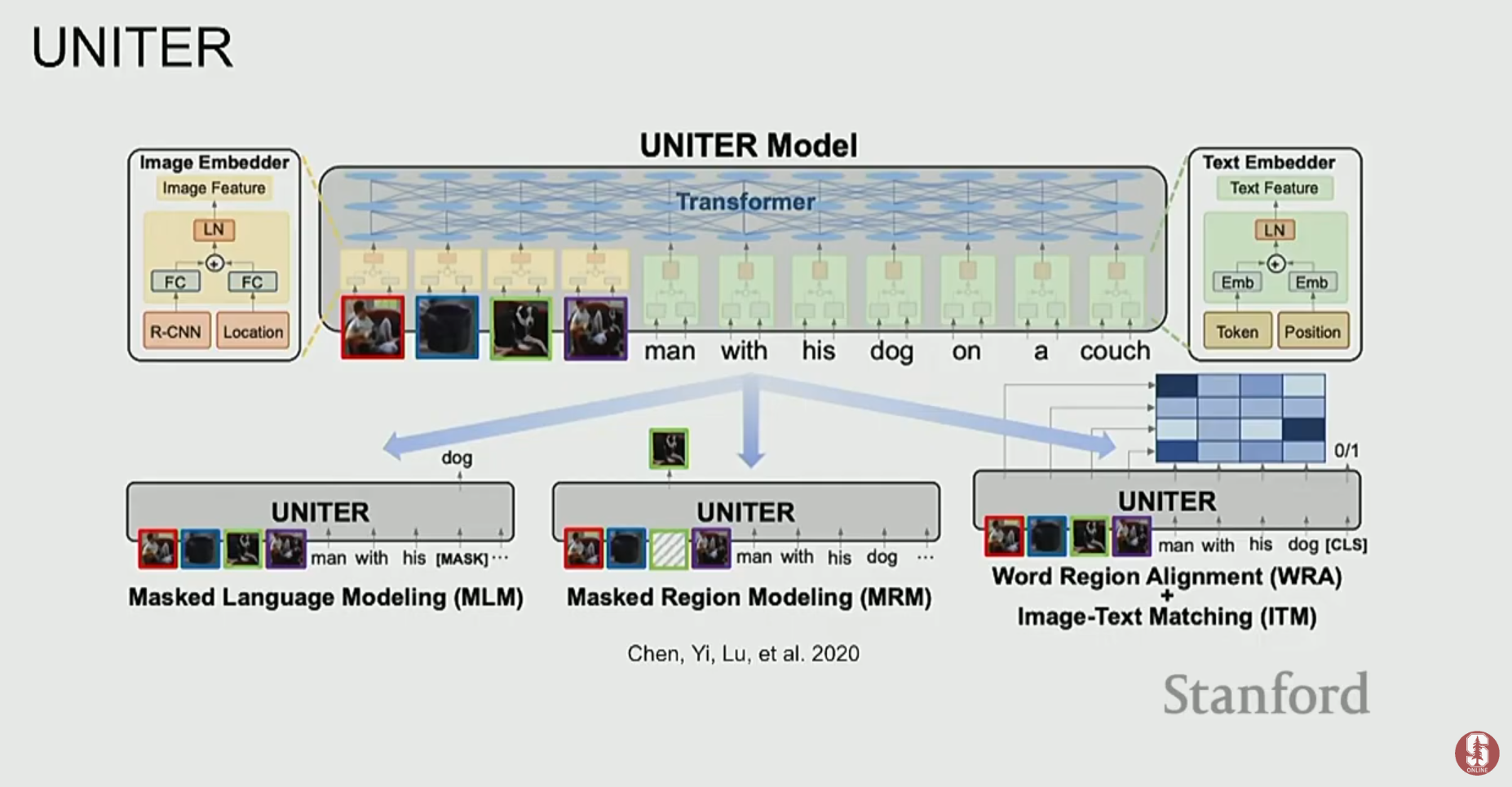
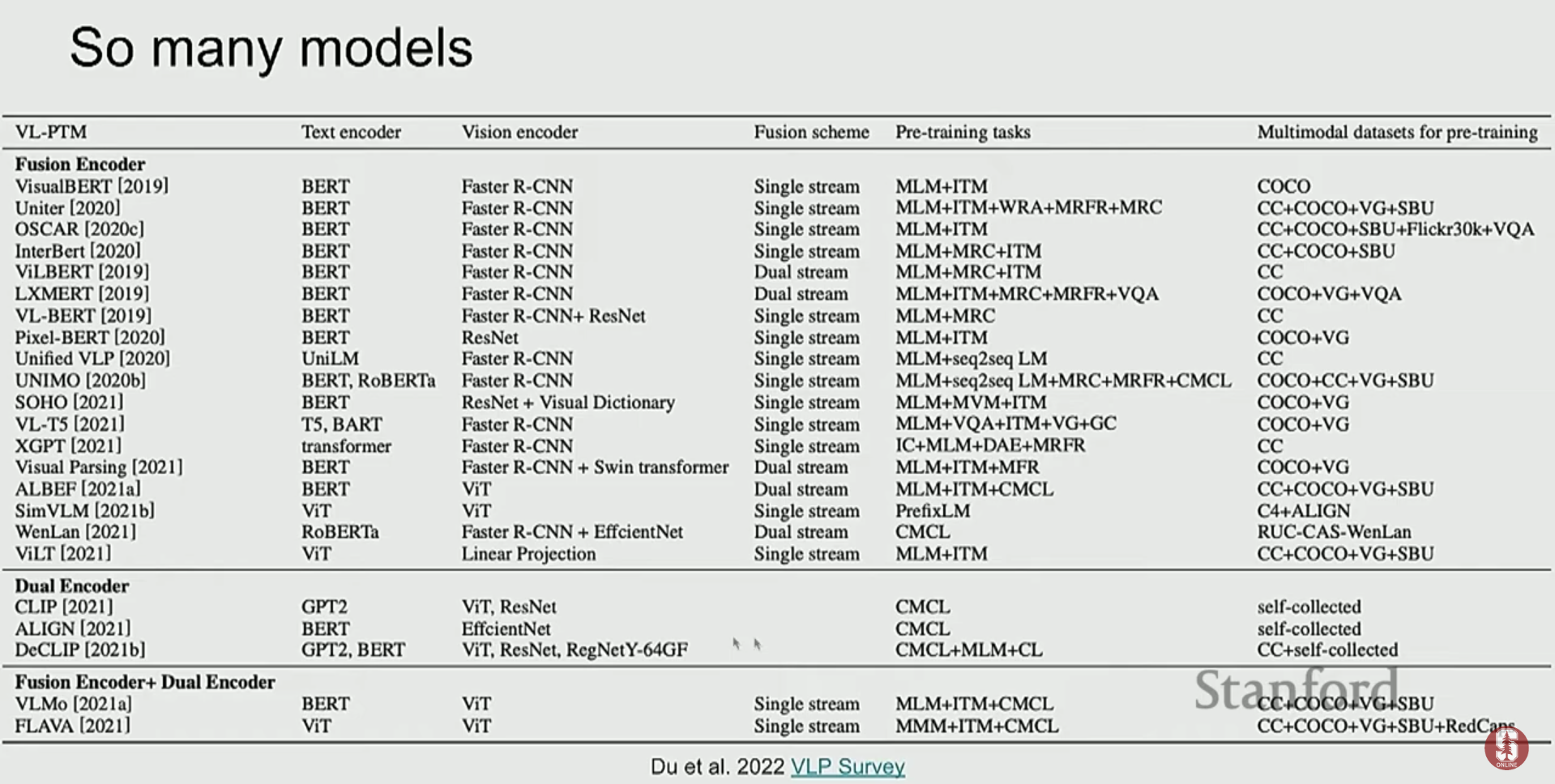
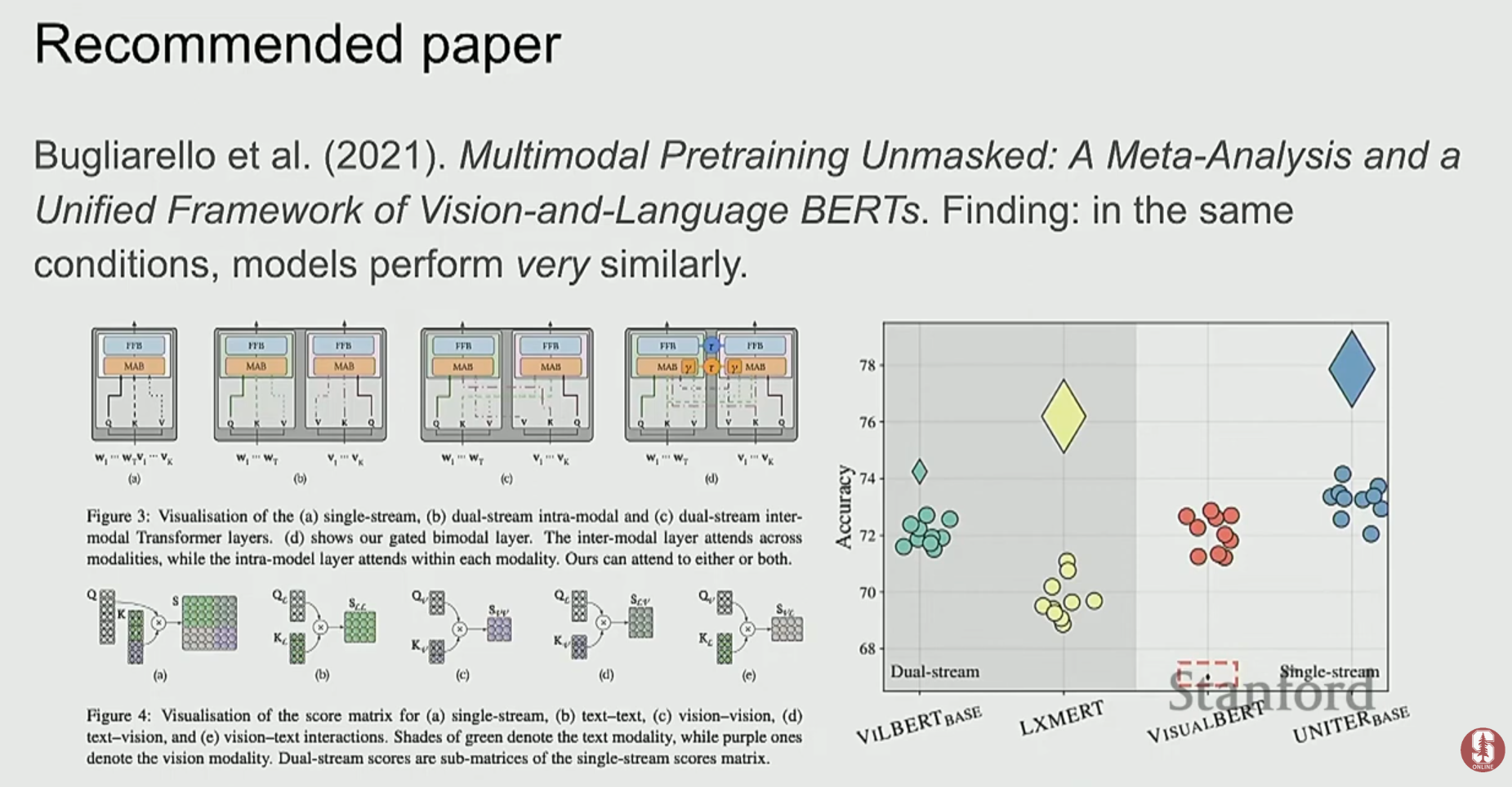
2) ViLBERT, UNITER: 더 깊은 상호작용을 향하여
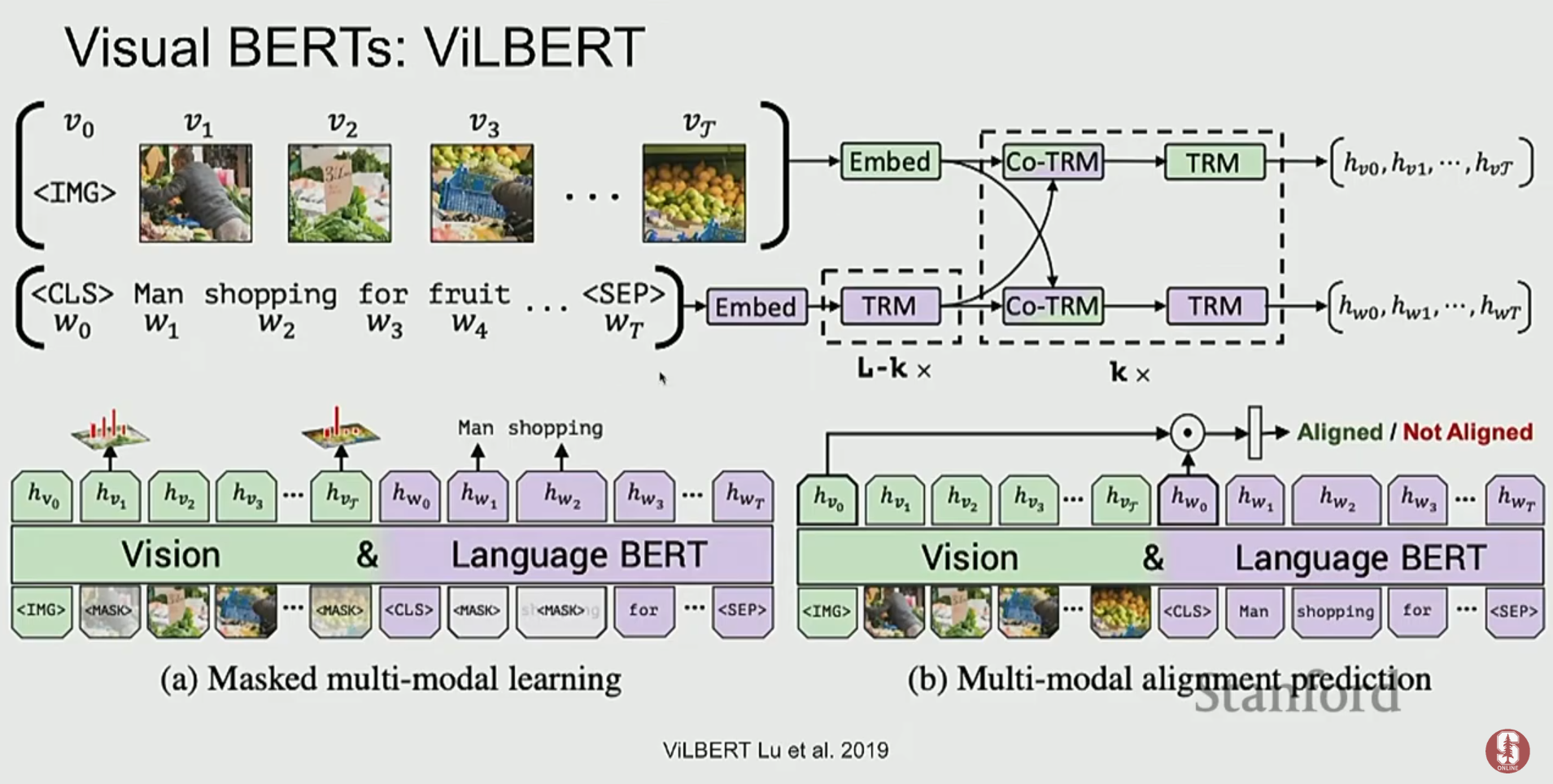
- ViLBERT는 이중 스트림(dual-stream) 구조로, 이미지와 텍스트를 위한 두 개의 Transformer를 병렬로 두고, 각 레이어마다 교차 어텐션(cross-attention)을 통해 정보를 교환합니다. 이는 두 양식 간의 깊은 상호작용을 가능하게 합니다.
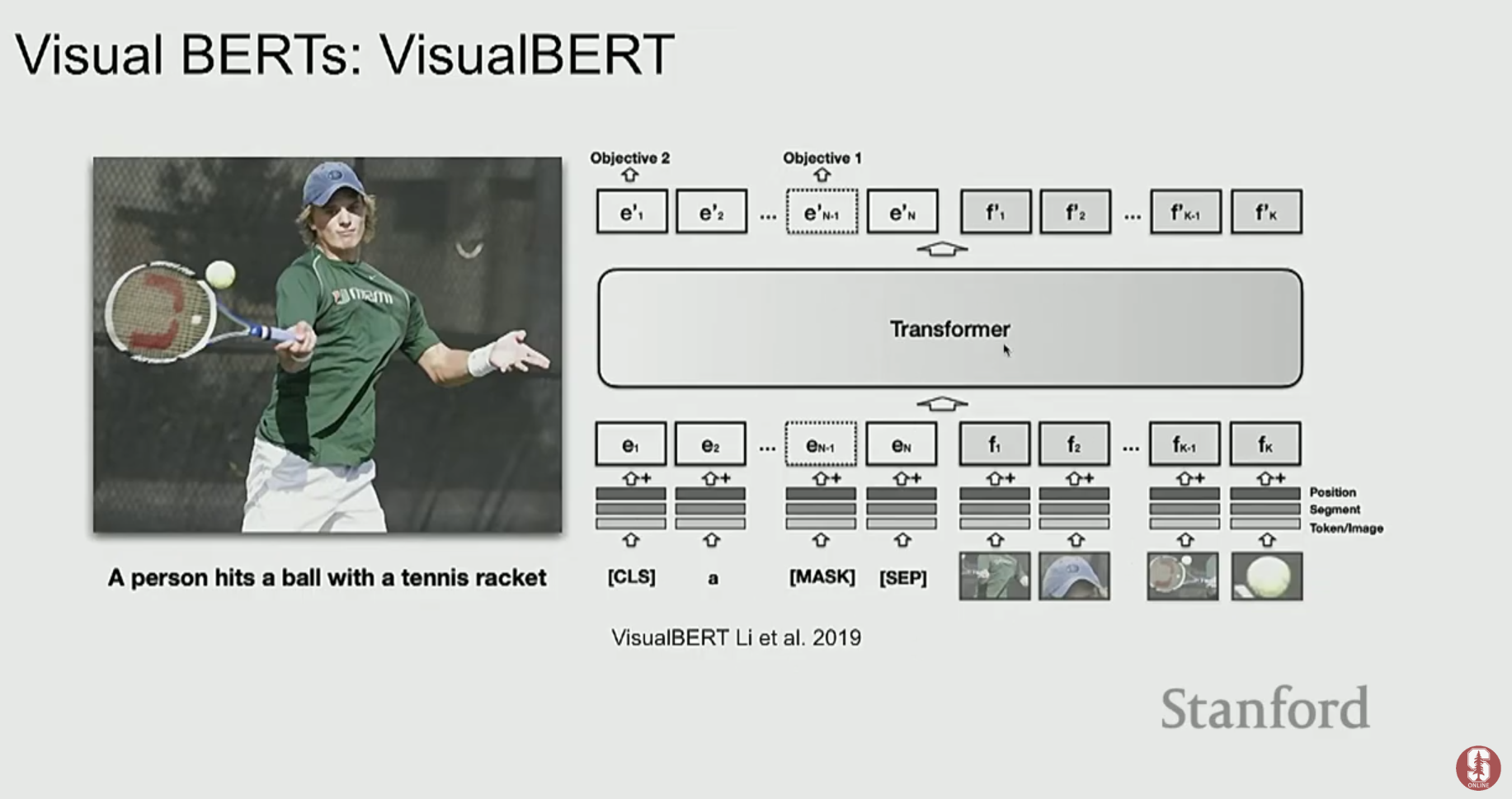
- UNITER나 VL-BERT 같은 모델들은 단일 스트림(single-stream) 구조로, 이미지 패치와 텍스트 토큰을 하나의 Transformer에 함께 입력하여 처리합니다.
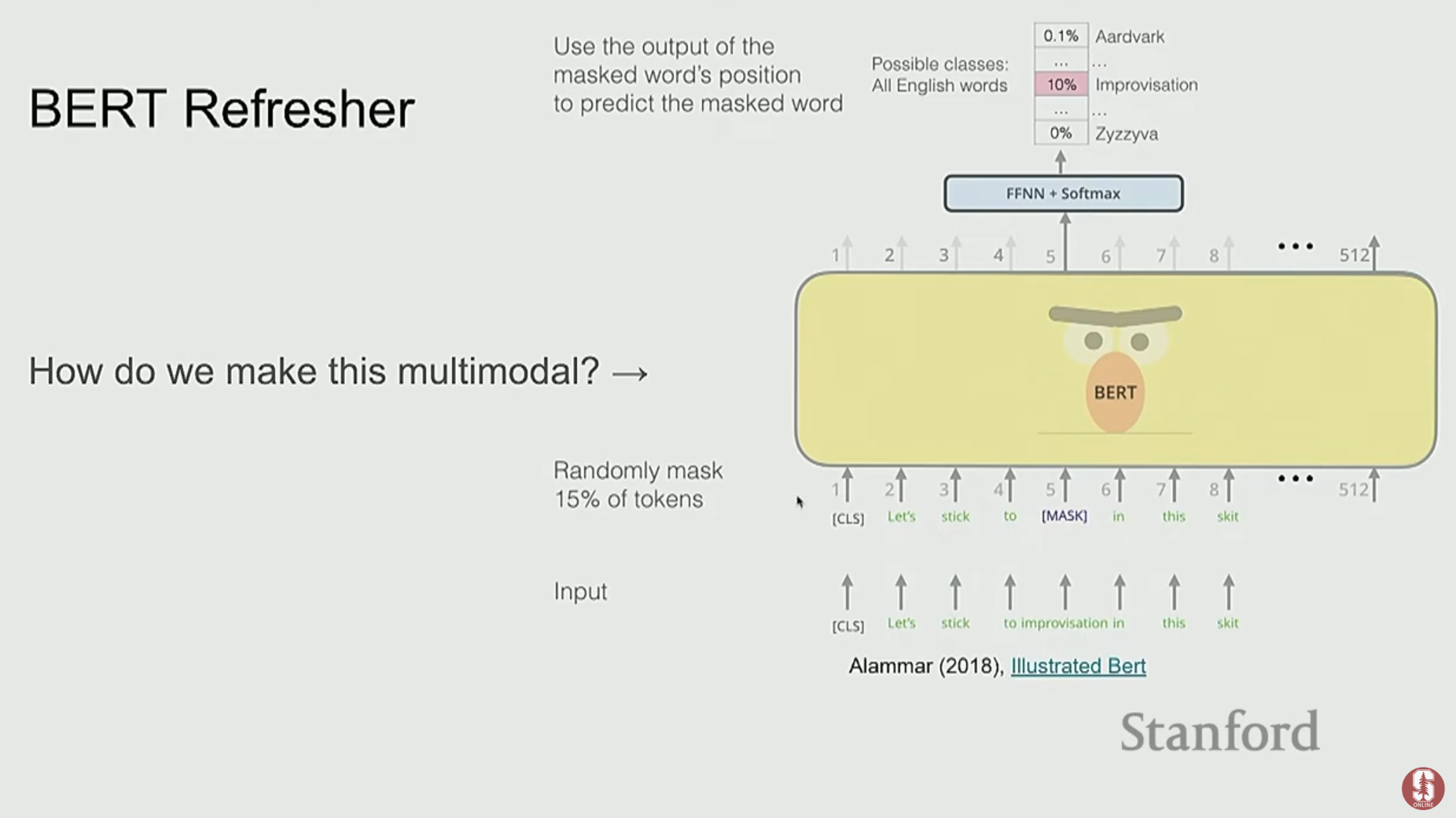
- 이러한 모델들은 Masked Language Modeling (MLM)이나 Image-Text Matching과 같은 태스크로 사전학습을 수행하며, VQA와 같은 다운스트림 태스크에서 강력한 성능을 보였습니다.
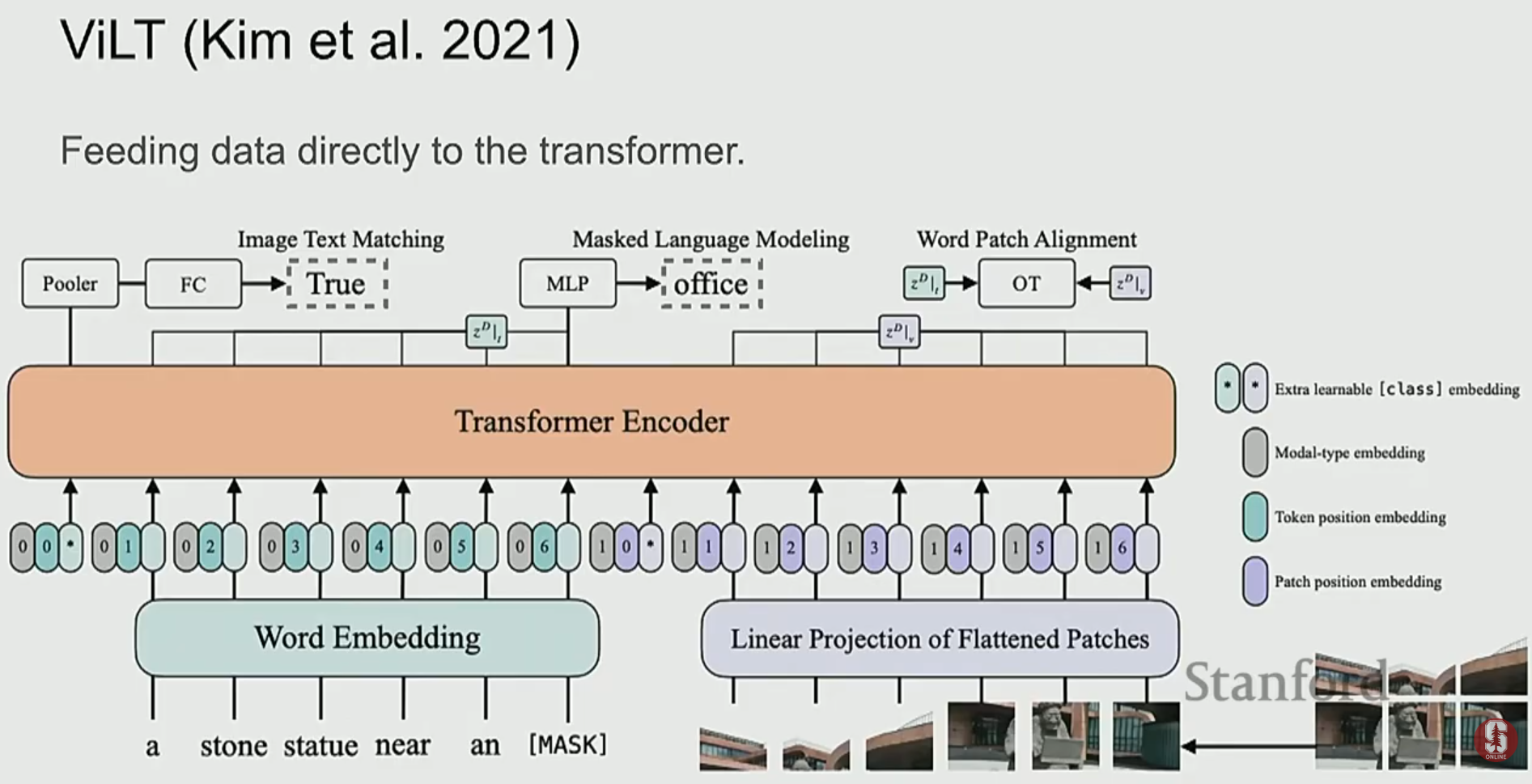
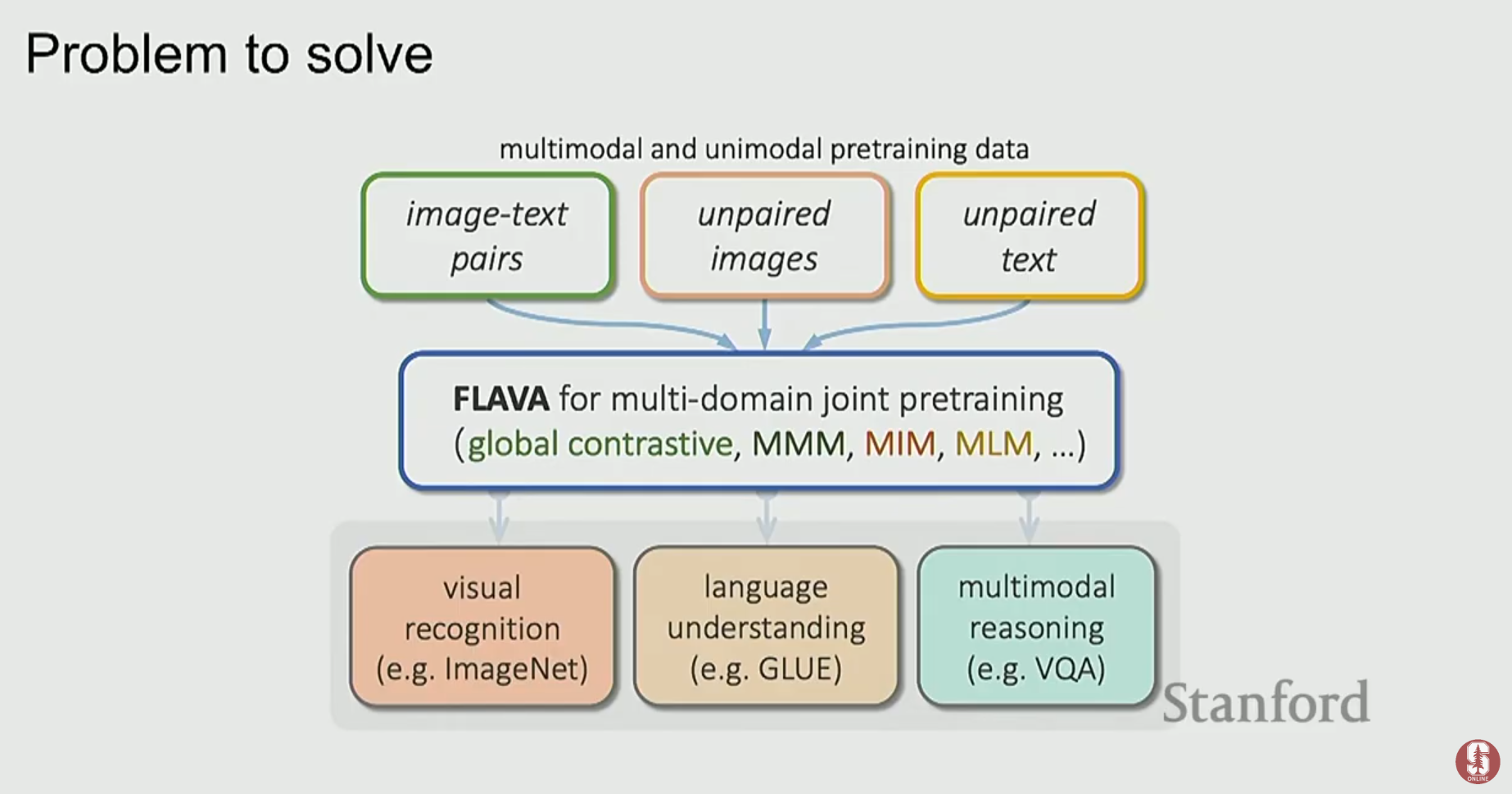
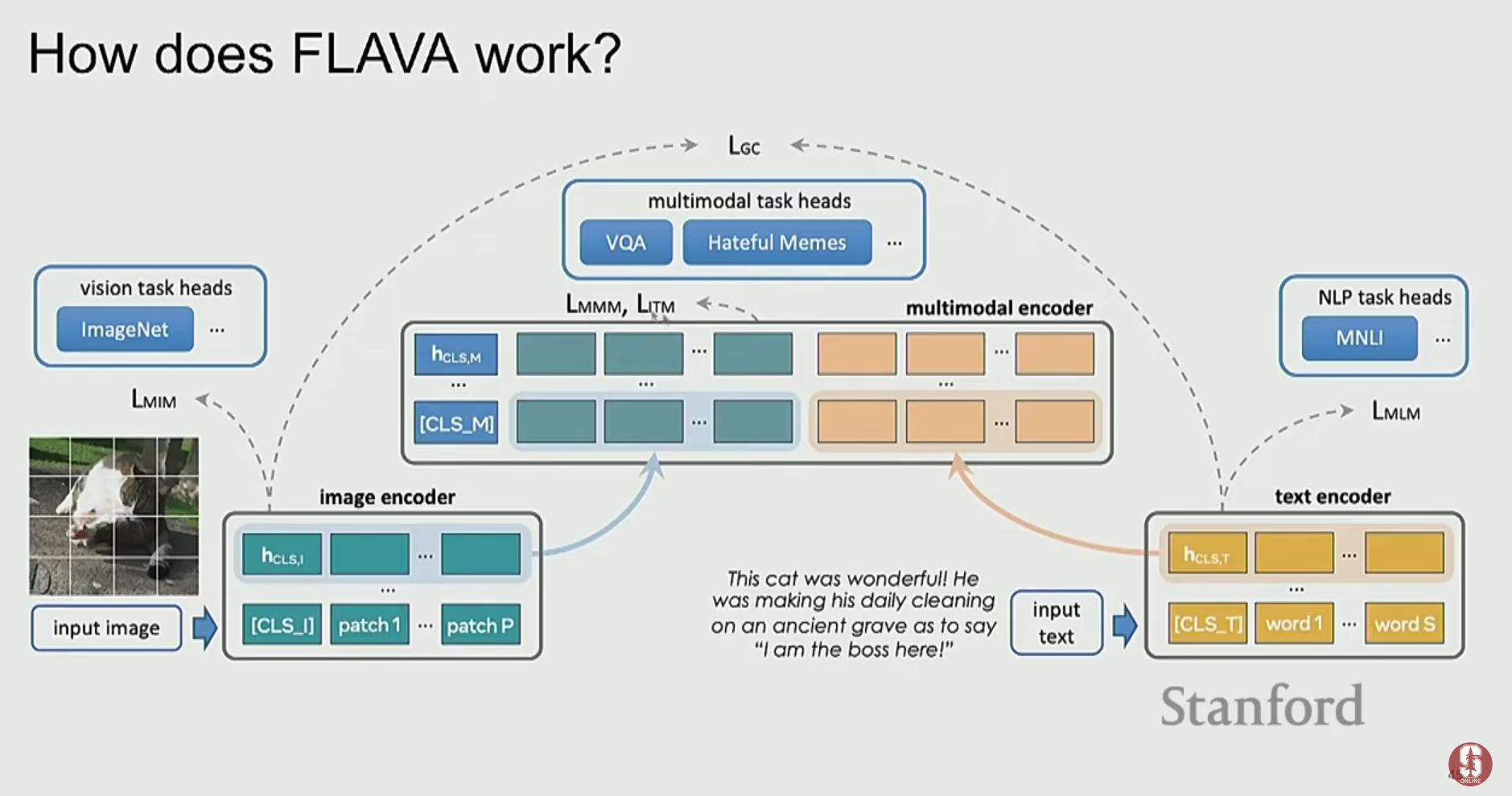
3) FLAVA: 하나의 모델로 모든 것을
- FLAVA (A Foundational Language And Vision Alignment)는 "모든 것을 지배할 하나의 모델"을 목표로 합니다.
- 단일 모드(이미지, 텍스트) 데이터셋과 멀티모달 데이터셋 모두를 사용하여 공동으로 사전학습을 진행합니다.
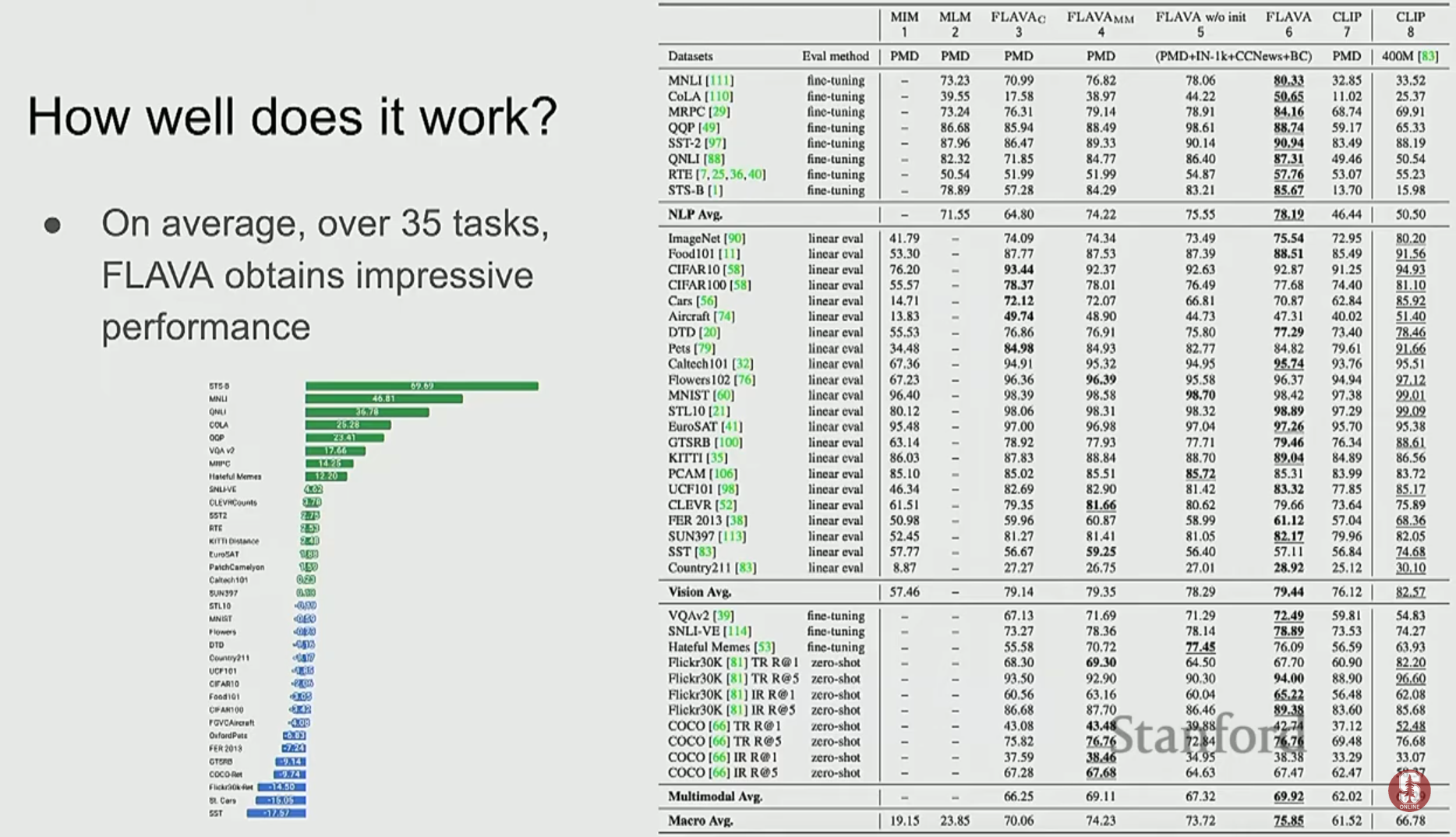
- 이미지-텍스트 매칭, MLM, 대조 학습 등 다양한 학습 목표를 하나의 Transformer 아키텍처 안에서 동시에 수행하여, 35개 이상의 광범위한 태스크에서 높은 성능을 달성했습니다.


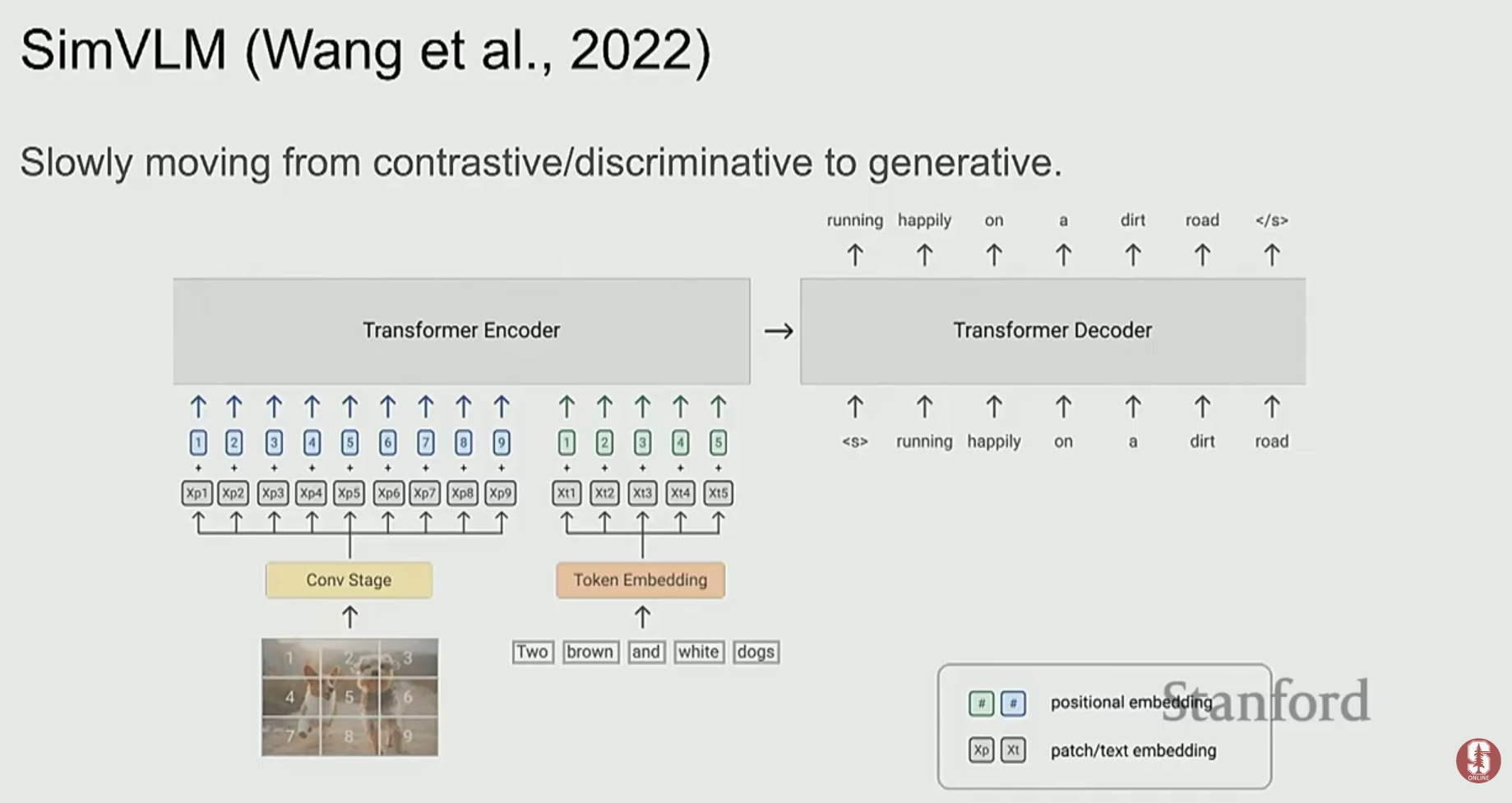
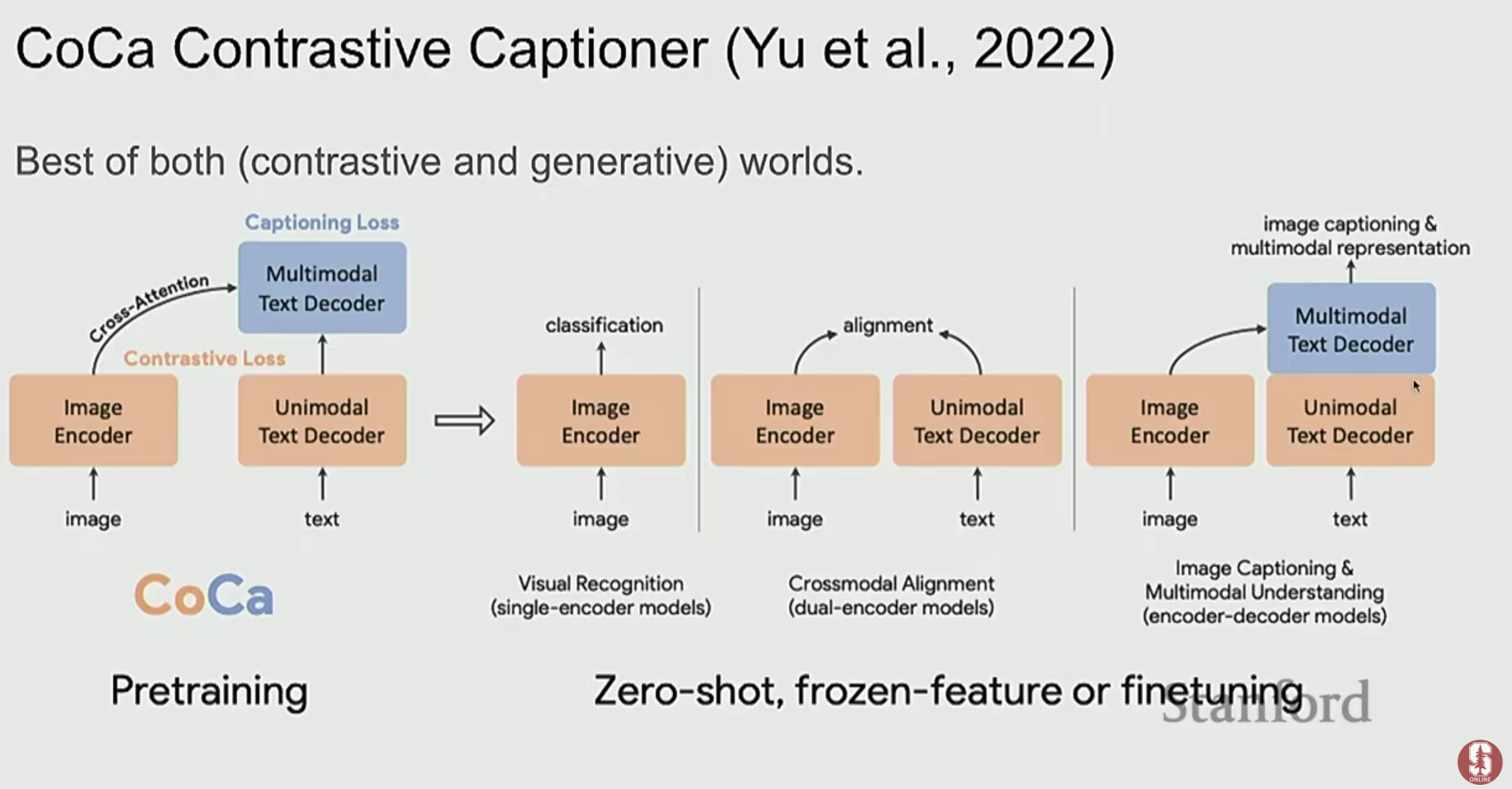
5. 세상을 생성하는 멀티모달 모델
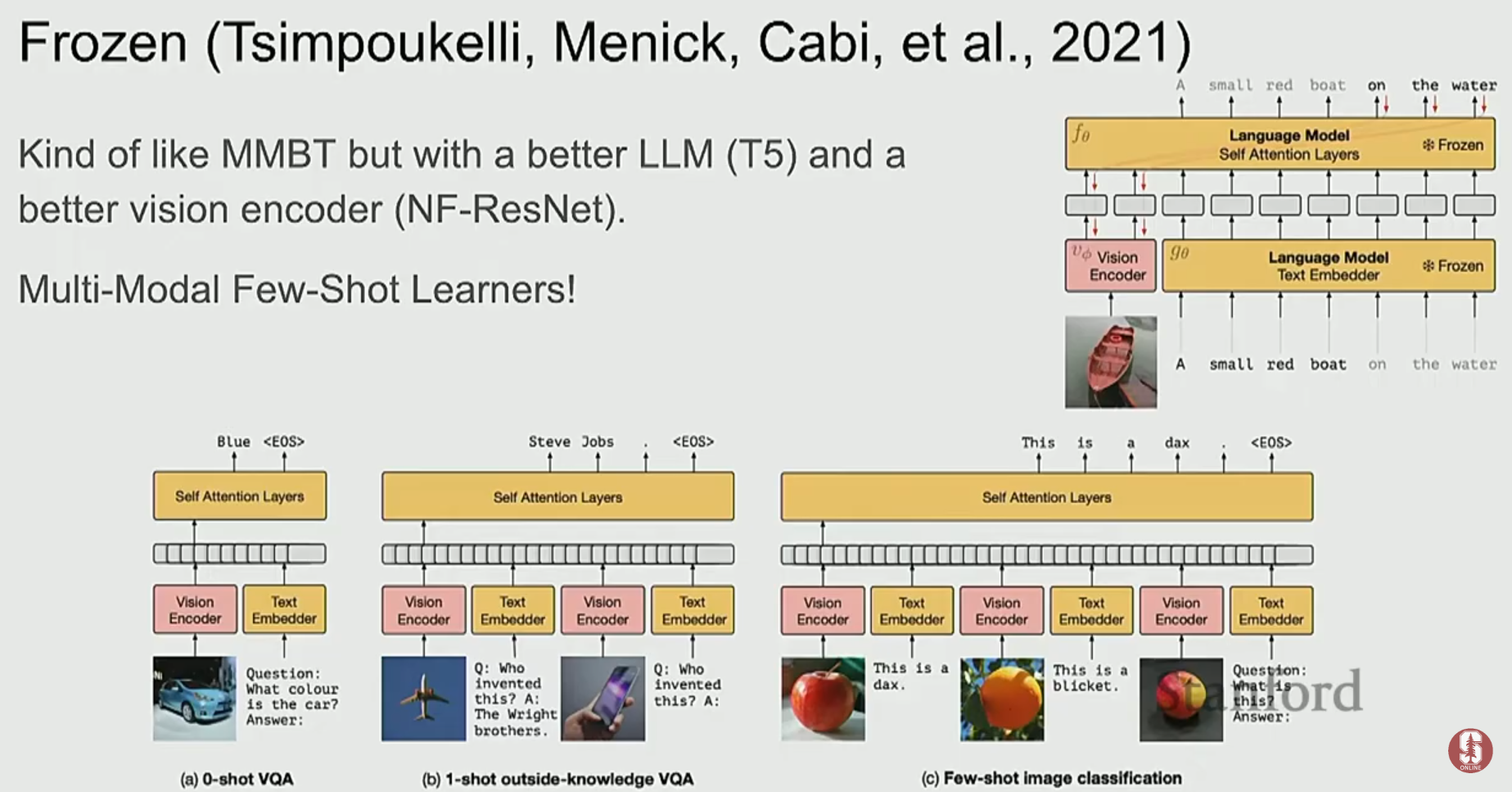
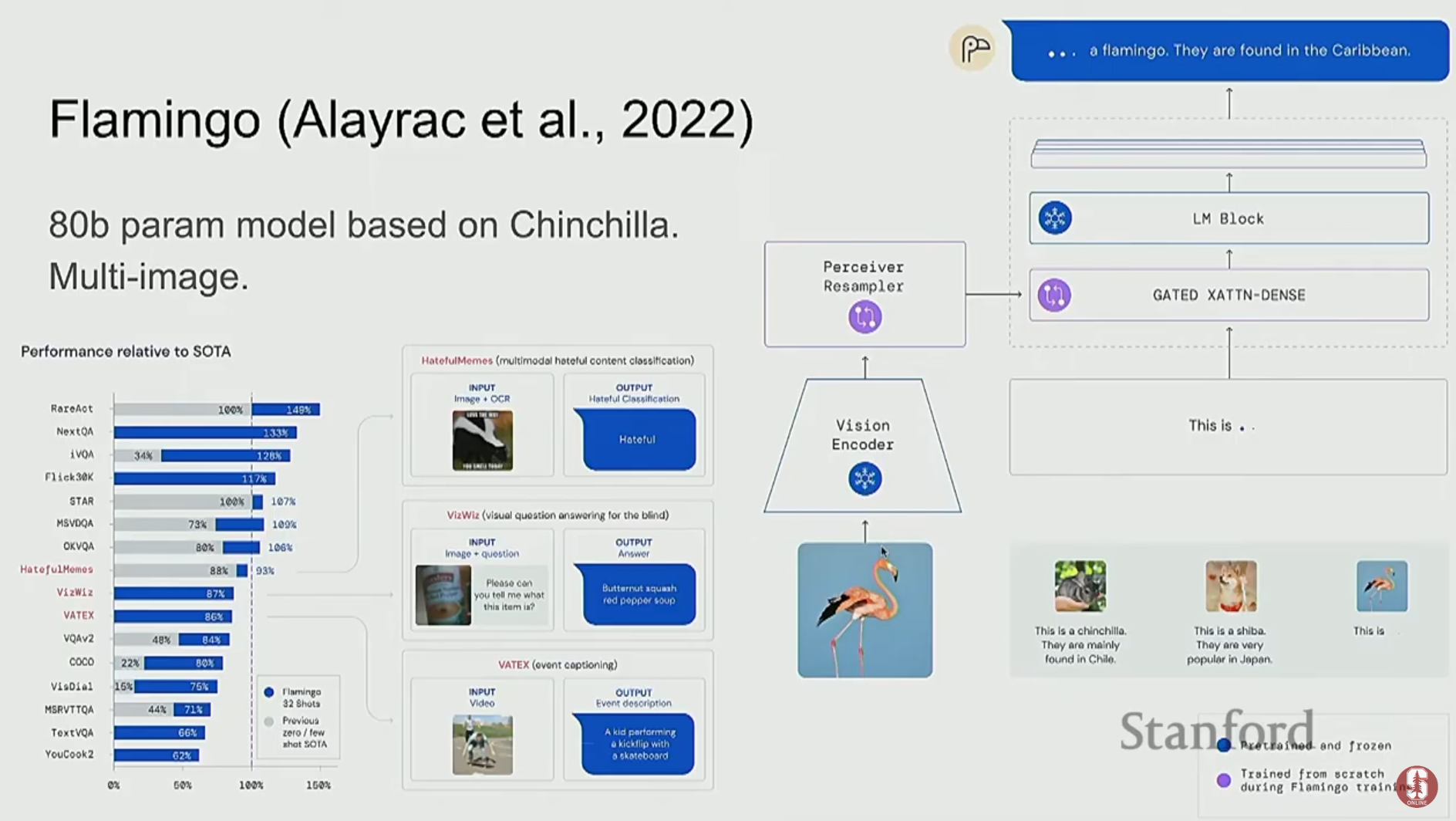
1) Flamingo: 소수샷 학습의 강자
- Flamingo는 사전학습된 거대 언어 모델(LLM)을 최대한 그대로 활용하는 접근 방식을 사용합니다.
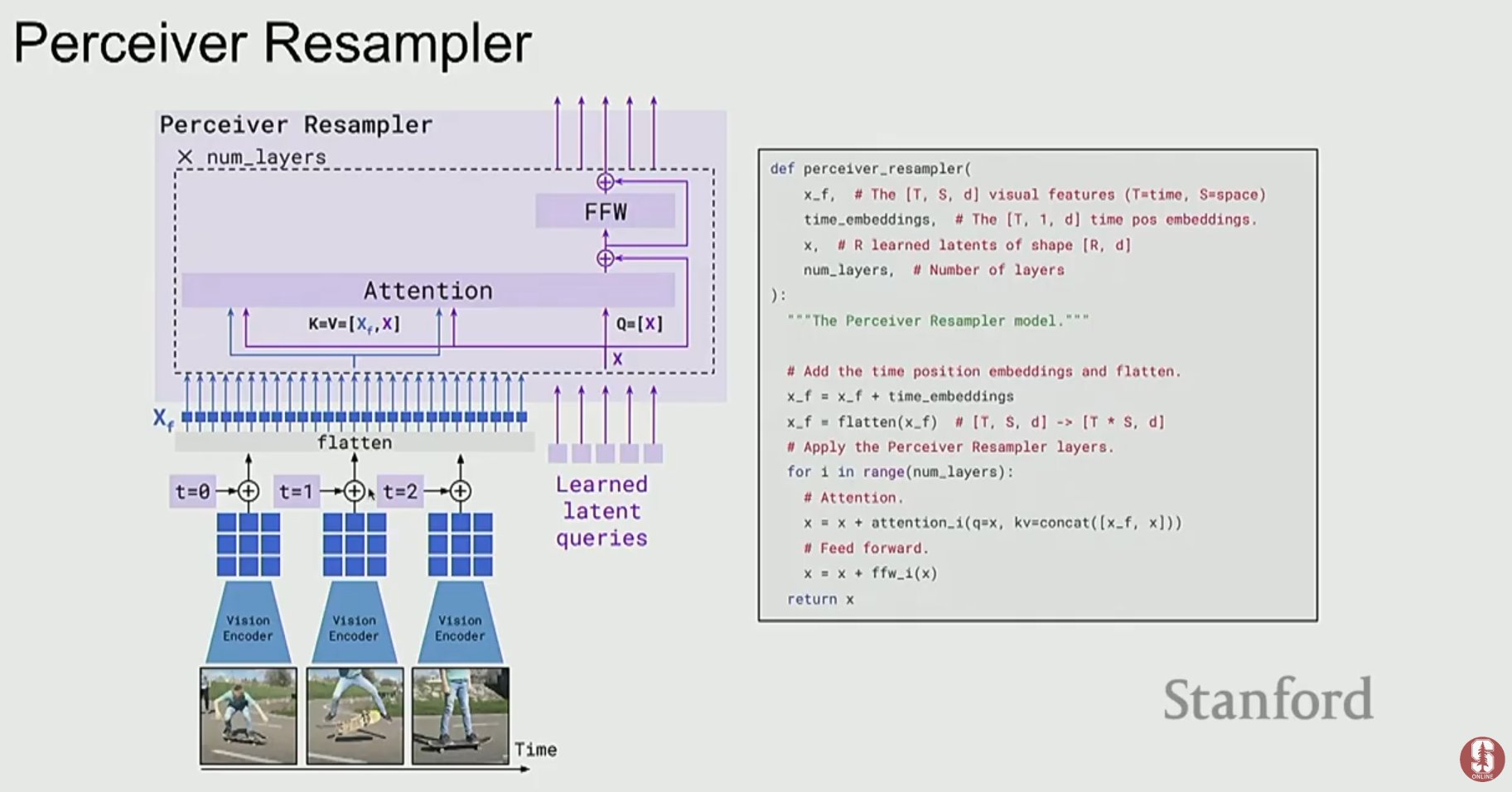
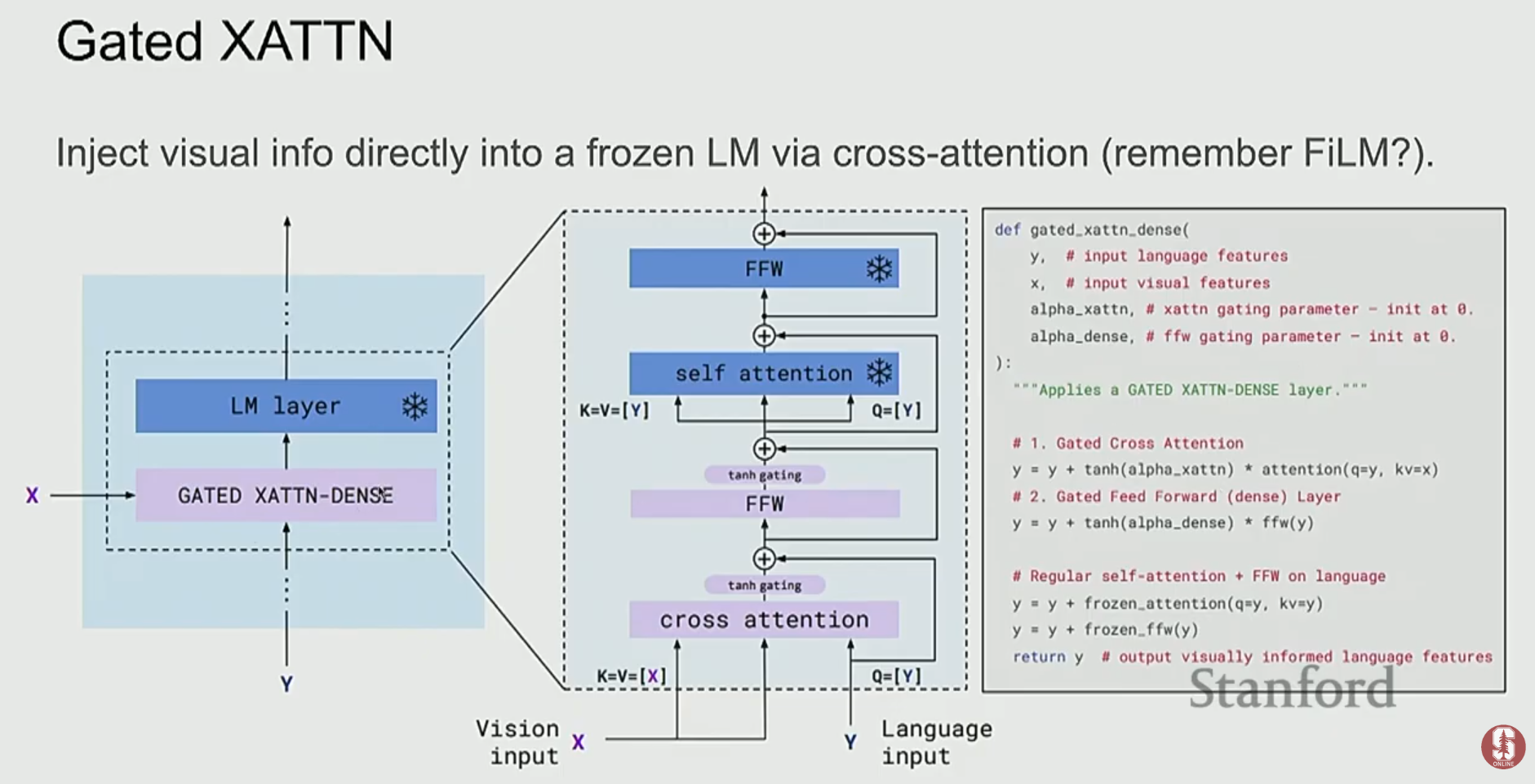
- Vision Encoder와 LLM을 두고, LLM은 얼린 채로(frozen) 파라미터를 업데이트하지 않습니다. 대신, 이미지 특징을 LLM이 이해할 수 있는 언어적 표현으로 변환해주는 소수의 레이어(Gated Cross-Attention)만 학습시킵니다.
- 이 접근법을 통해 소수샷 학습(few-shot learning)이 가능해졌습니다. 즉, 몇 개의 예시(이미지-텍스트 쌍)만 보고도 새로운 문제를 해결할 수 있게 되었습니다.
[심화 학습] Frozen LLM 접근법의 의미
- 기술적 배경: 수천억 개의 파라미터를 가진 LLM을 매번 미세조정(fine-tuning)하는 것은 엄청난 비용이 듭니다. LLM을 그대로 두고(frozen), 다른 양식의 정보를 LLM의 입력 공간에 맞춰주는 '어댑터'만 학습하는 방식은 매우 효율적입니다. 이는 LLM이 이미 학습한 방대한 언어적 지식과 추론 능력을 그대로 활용하면서 새로운 능력을 부여하는 효과적인 방법입니다.
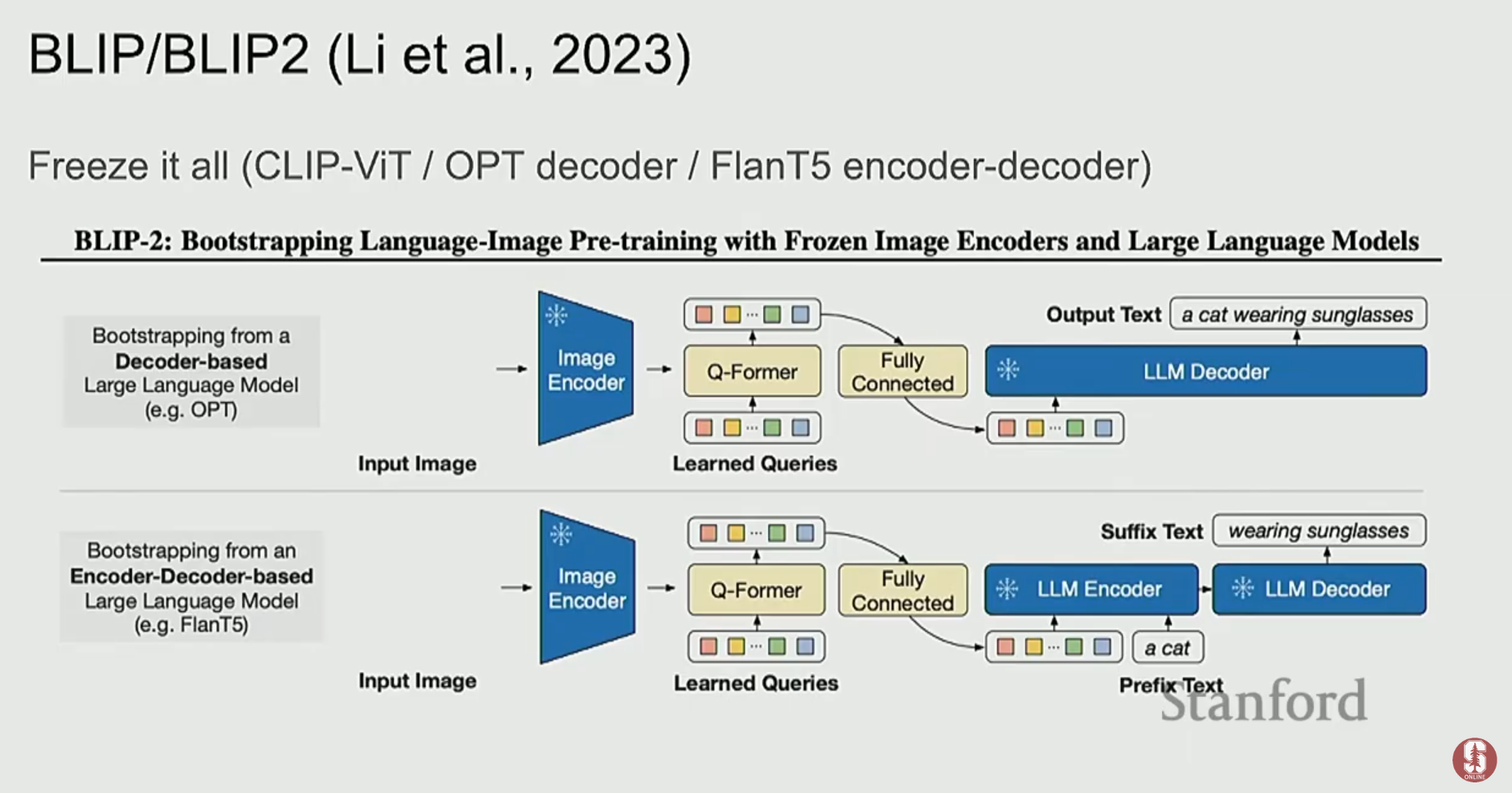
- 최신 동향: BLIP-2와 같은 최신 모델들은 이 아이디어를 극단으로 밀어붙여, 이미지 인코더와 LLM을 모두 얼리고 그 사이를 연결하는 작은 Q-Former 네트워크만 학습시킵니다. 그럼에도 불구하고 복잡한 이미지 캡셔닝 및 추론에서 놀라운 성능을 보여주며, 멀티모달 학습의 새로운 패러다임을 제시하고 있습니다.
- 명확한 한계점: 이 방식의 성능은 전적으로 기반이 되는 LLM의 성능에 의존합니다. 또한, 시각 정보를 언어 모델에 주입하는 과정에서 정보의 손실이 발생할 수 있으며, 여전히 언어 모델의 '환각(hallucination)' 문제로부터 자유롭지 못합니다.
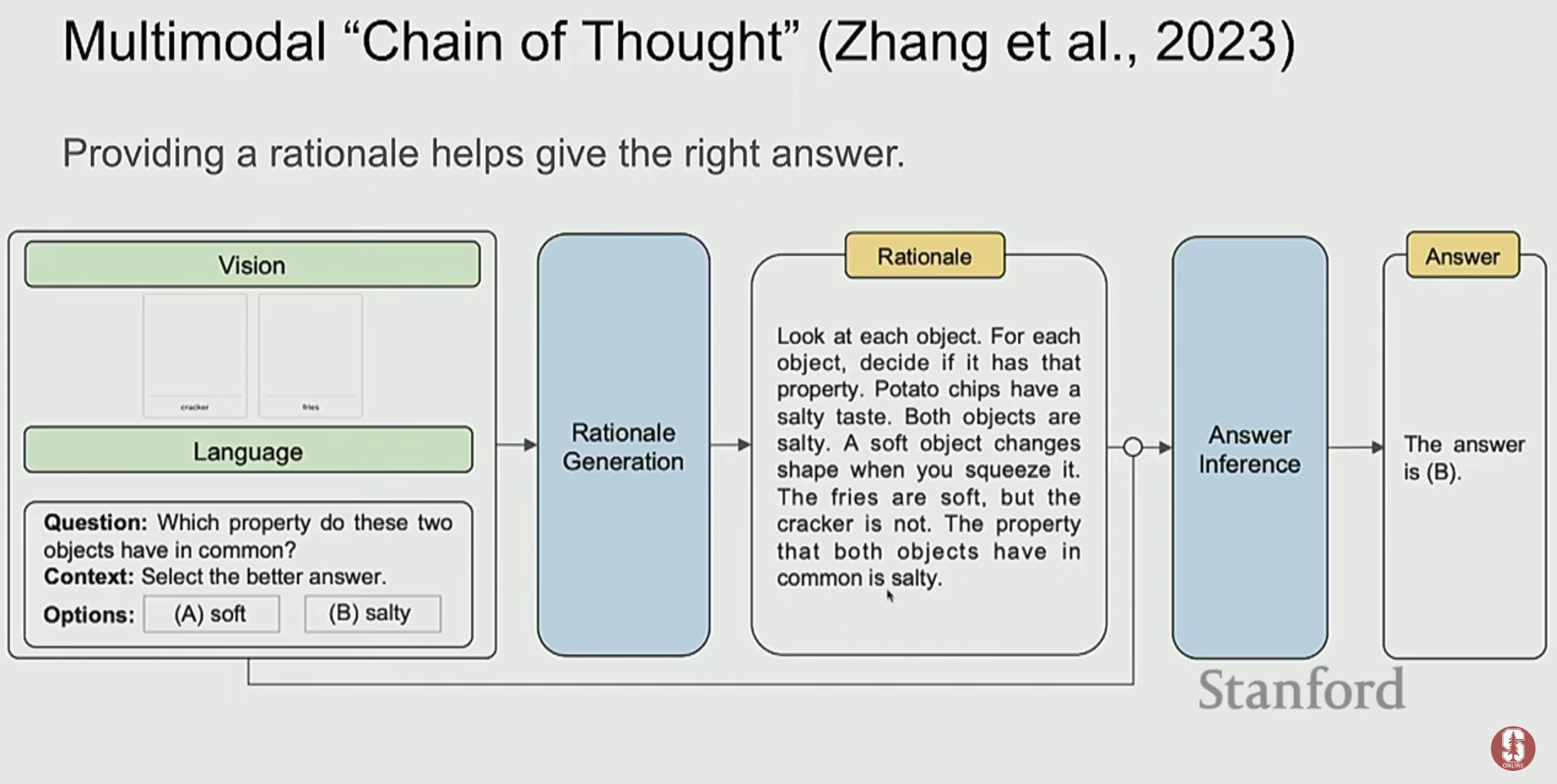
2) 멀티모달 생각의 사슬(Chain-of-Thought)
- 복잡한 시각적 질문에 대해, 모델에게 바로 답을 요구하는 대신 "먼저 근거를 생성하고, 그 다음에 답을 하라"고 지시하는 Chain-of-Thought 프롬프팅 방식이 효과적임이 밝혀졌습니다.
- 이 방식은 모델이 단계적으로 추론하도록 유도하여, 복잡한 과학 문제나 추론 문제에서 정확도를 크게 향상시켰습니다.
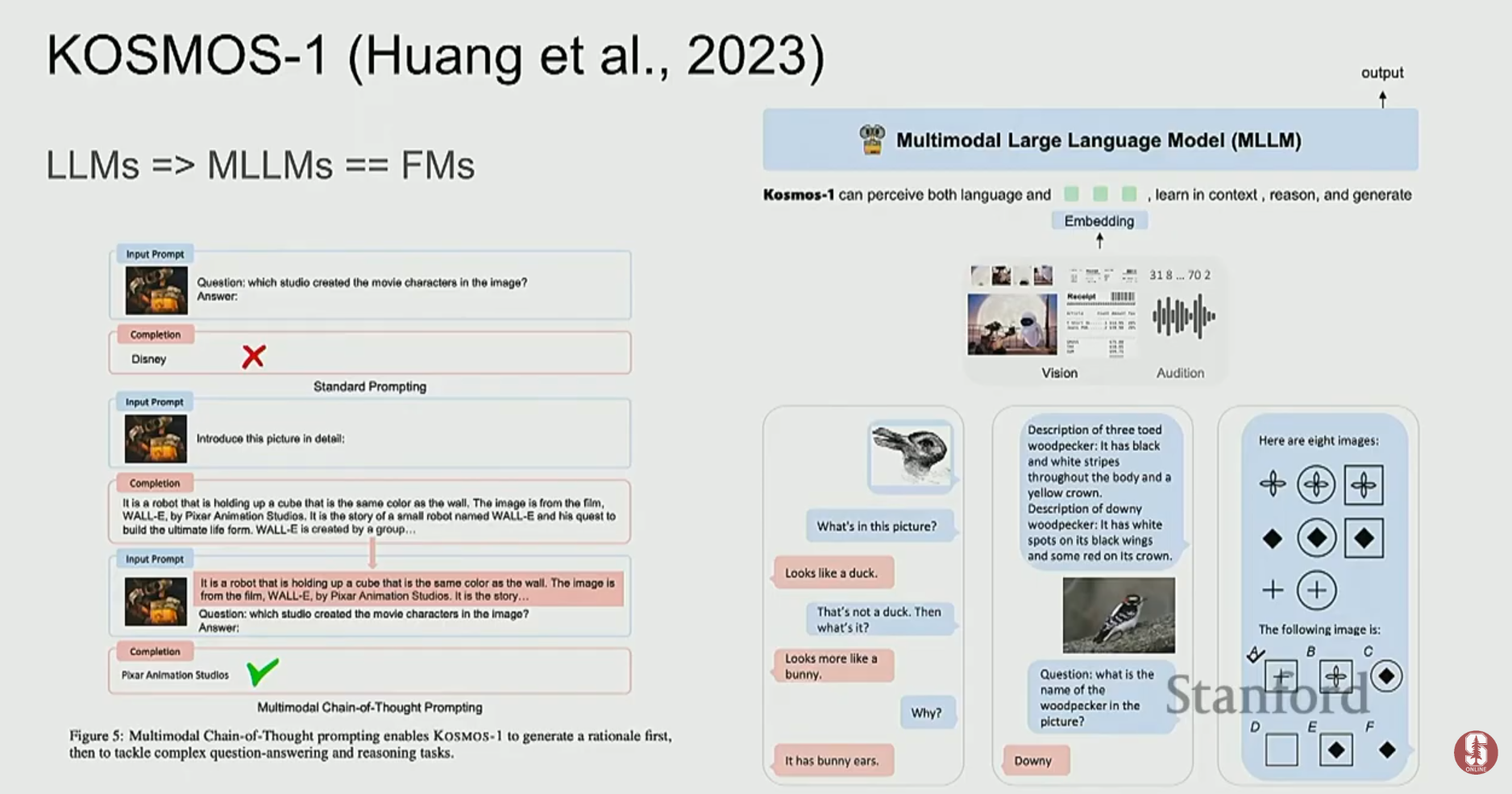
6. 멀티모달 모델 평가의 과제
1) 기존 데이터셋의 한계
- COCO, VQA와 같은 전통적인 데이터셋들은 모델의 진정한 멀티모달 추론 능력을 측정하기에는 너무 쉽거나, 데이터셋 자체의 편향이 존재한다는 문제점이 제기되었습니다.
- 예를 들어, VQA 데이터셋에서 "테니스 라켓이 몇 개 있니?"라는 질문에 모델이 이미지를 보지 않고도 '2개'라고 답하면 정답률이 높게 나오는 문제가 있었습니다.



2) 진정한 멀티모달 추론을 위한 데이터셋
-
Hateful Memes Dataset: 혐오 발언 밈(meme)을 분류하는 데이터셋으로, 이미지와 텍스트를 함께 이해해야만 올바르게 판단할 수 있도록 설계되었습니다. 예를 들어, "오늘 날씨 좋네"라는 텍스트가 평화로운 풍경 이미지와 함께 있으면 긍정적이지만, 재난 현장 이미지와 함께 있다면 혐오 표현이 될 수 있습니다.

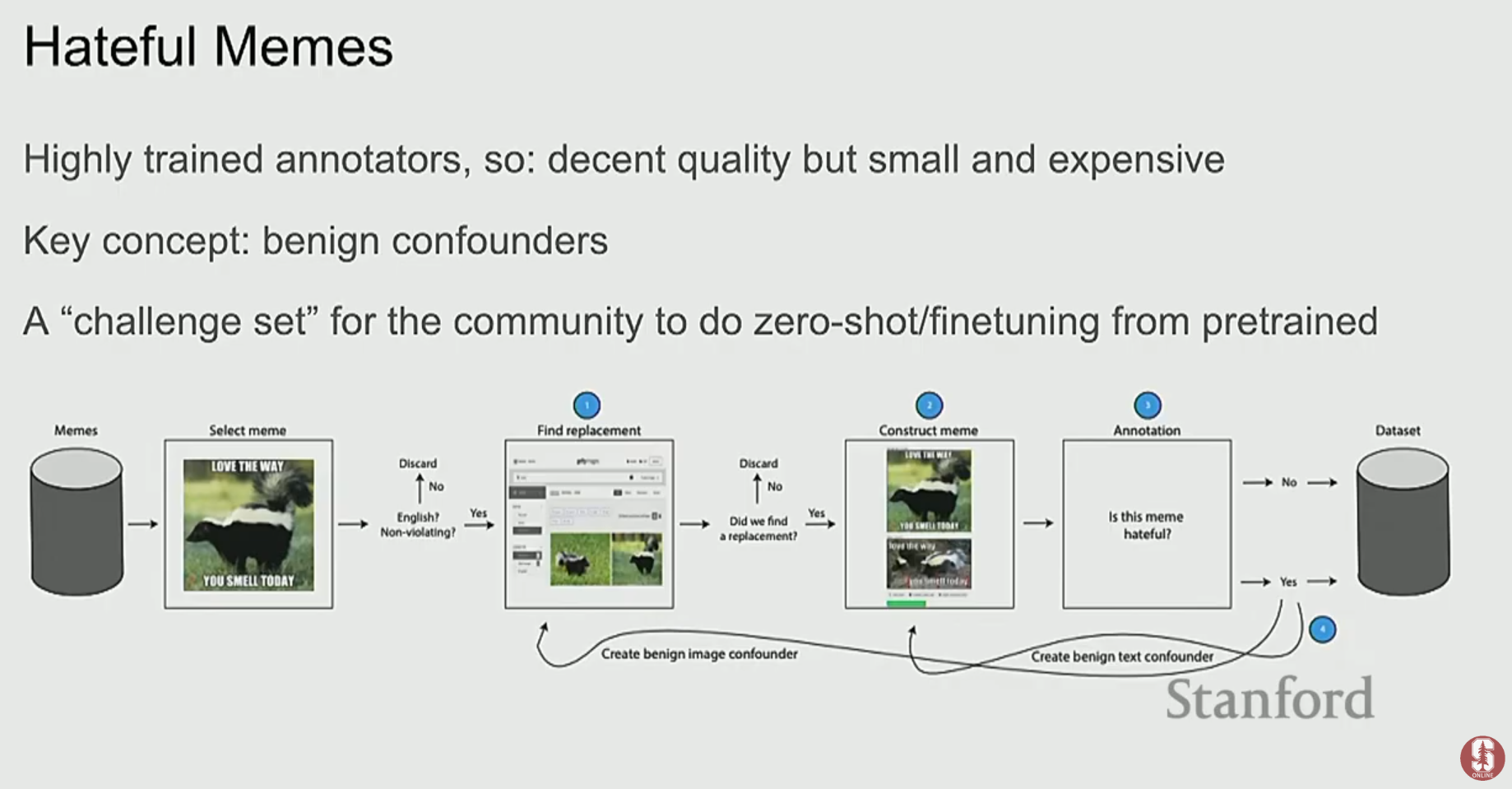

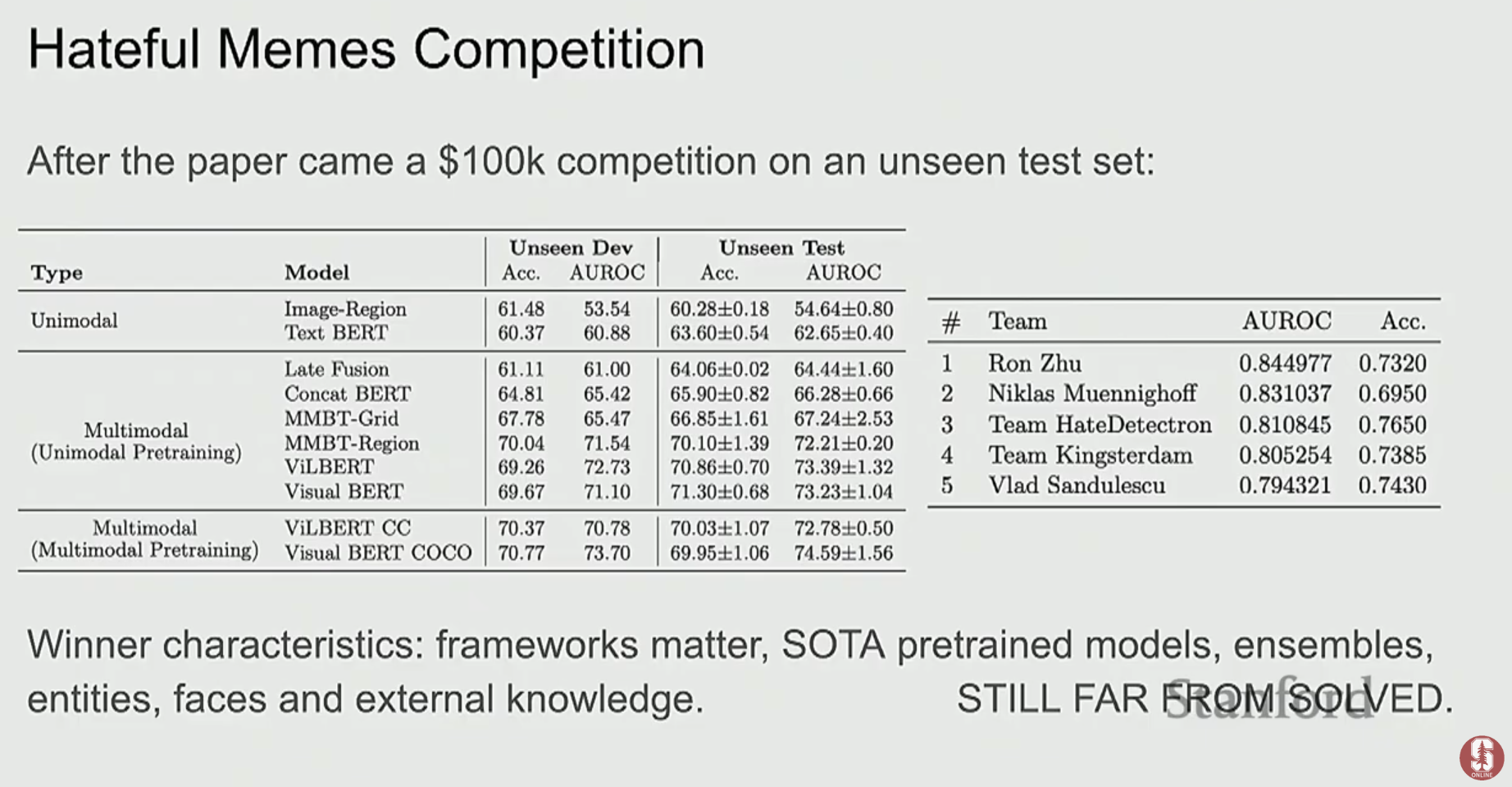
-
Winoground Dataset: 두 개의 (이미지, 텍스트) 쌍으로 구성되며, 텍스트는 단어는 같지만 순서만 다릅니다 (예: "전구를 둘러싼 식물들" vs "식물들을 둘러싼 전구"). 이 데이터셋은 모델이 **구성적 이해(compositional understanding)**를 제대로 하는지 측정하며, 현재 SOTA 모델들도 이 문제에서 매우 낮은 성능을 보입니다.



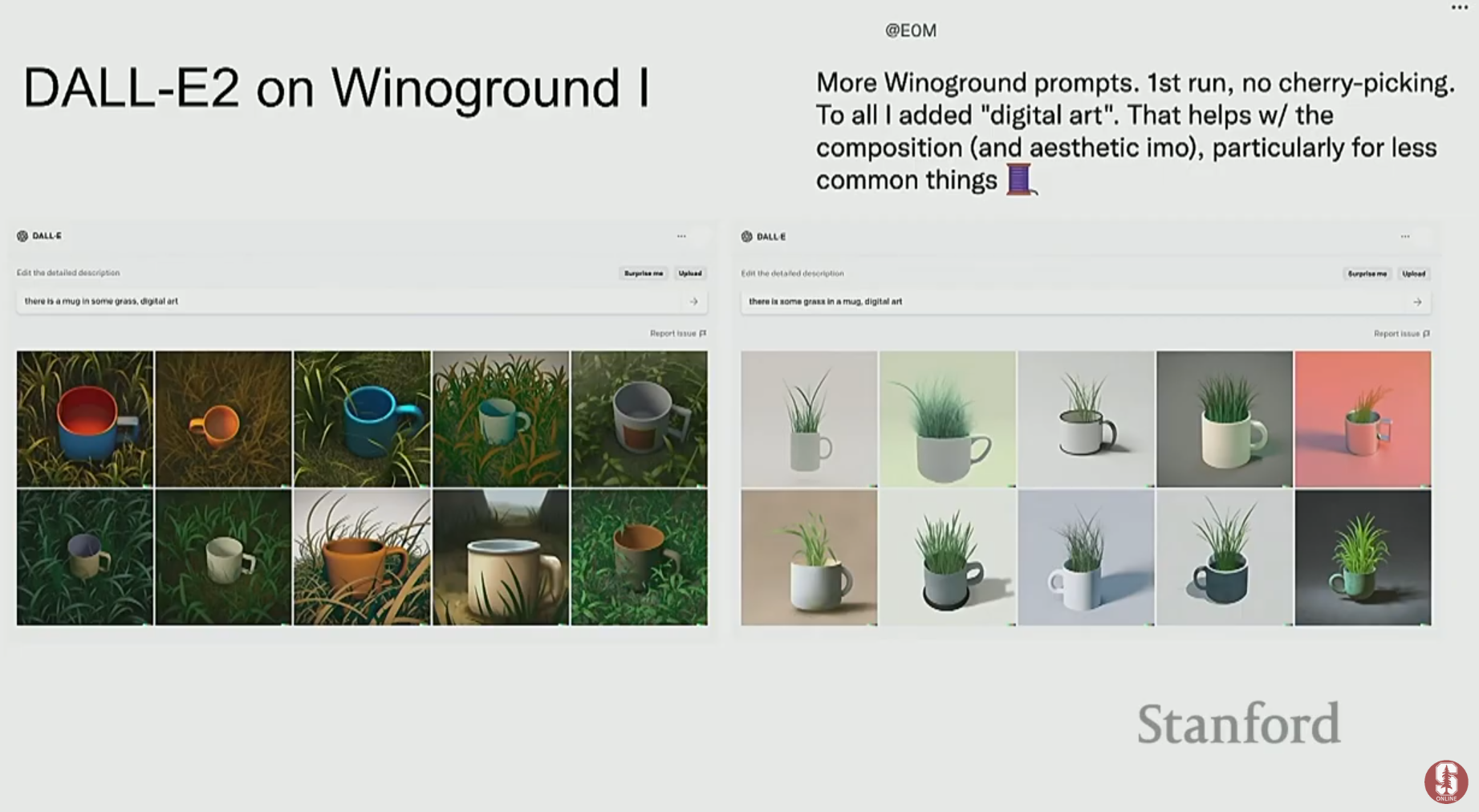
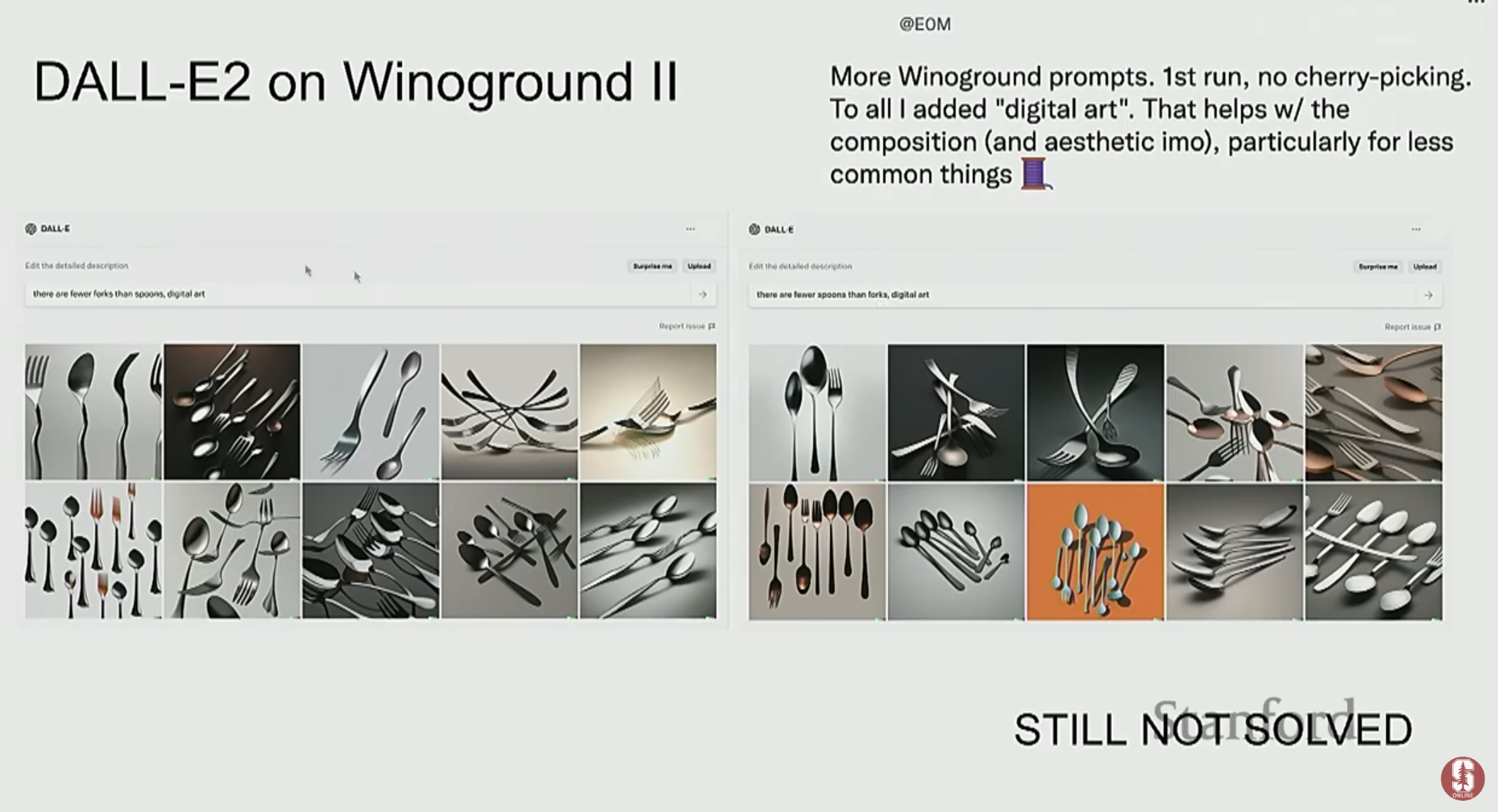
7. 이미지와 텍스트를 넘어: 새로운 모달리티
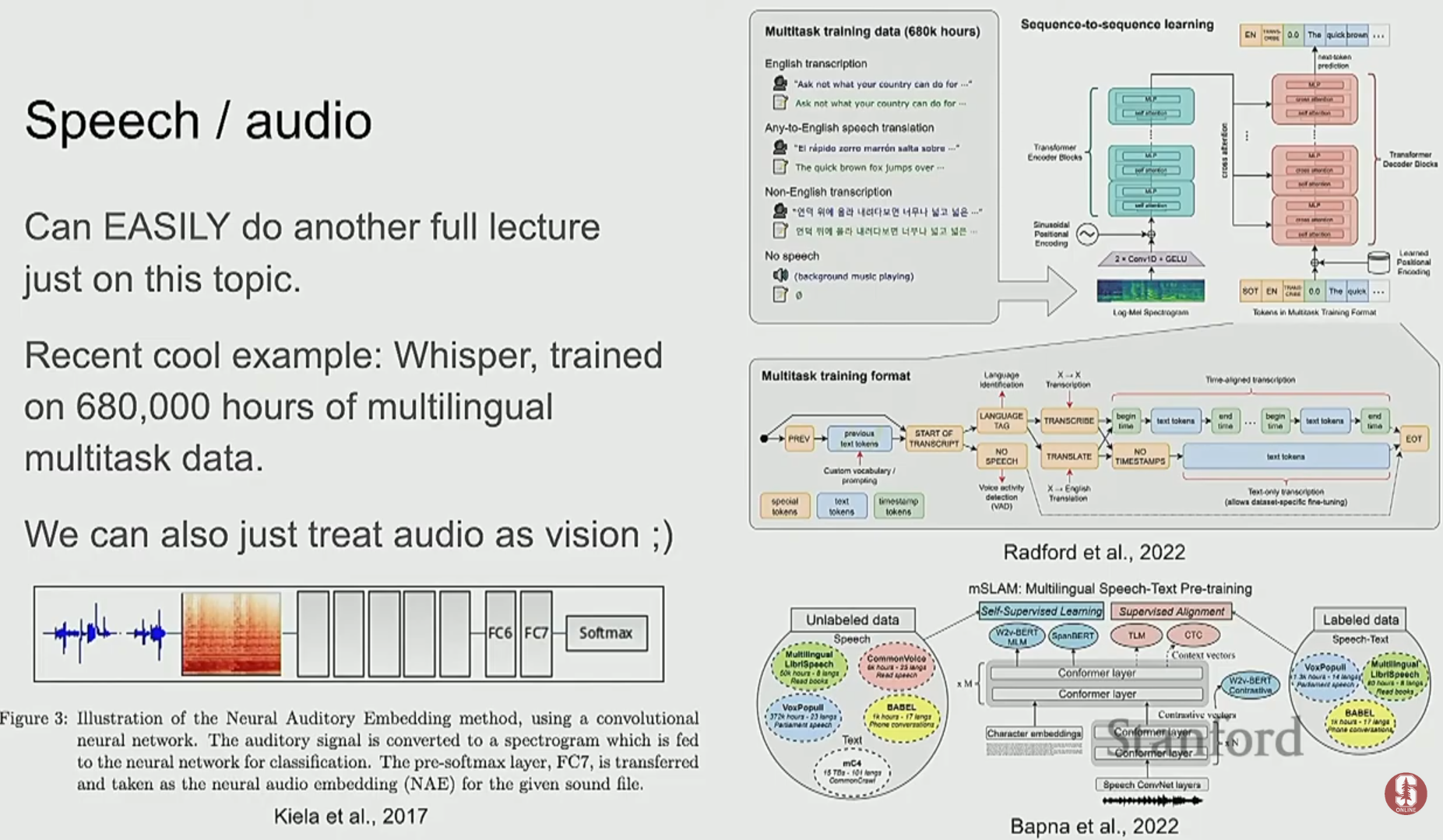
- 음성/오디오: OpenAI의 Whisper는 68만 시간 분량의 다국어 음성 데이터를 학습한 거대한 Transformer 기반 음성 인식 모델입니다.
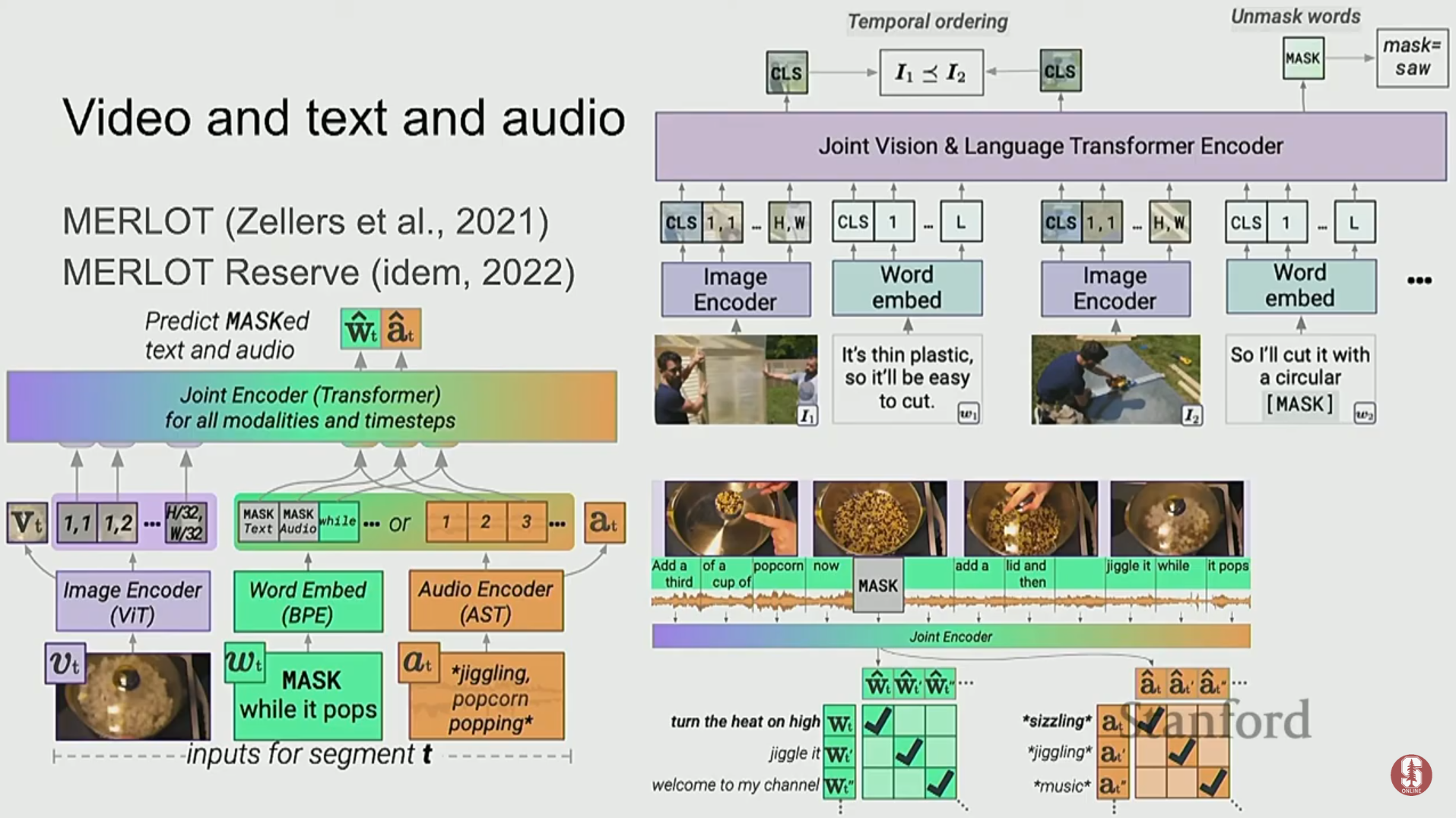
- 비디오: 이미지를 여러 프레임으로 보고, 여기에 음성 정보를 더하여 3중 모달(tri-modal) 모델로 확장하는 연구가 진행 중입니다.
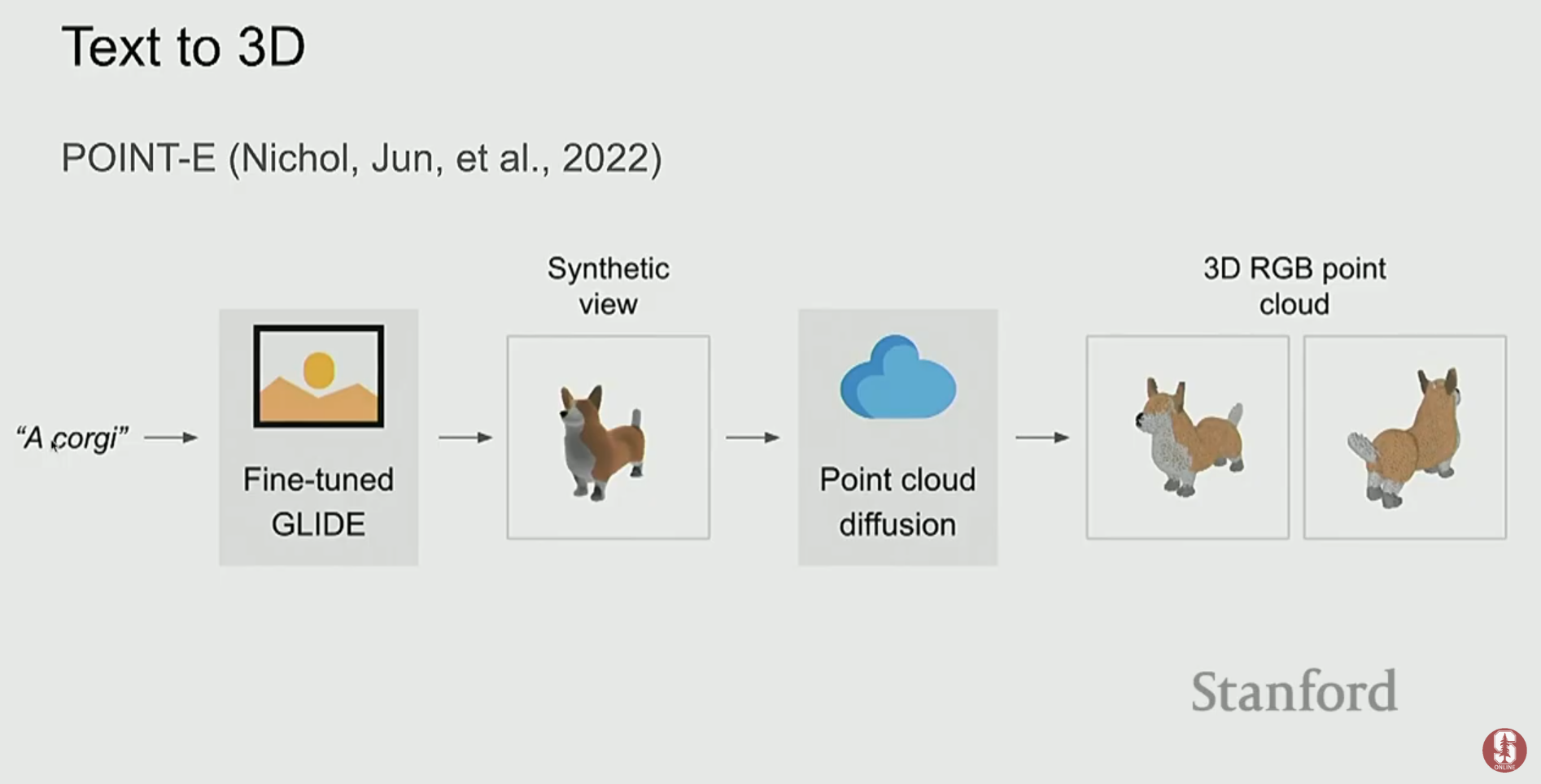
- 3D 포인트 클라우드: 텍스트 설명으로부터 3D 객체를 생성하는 기술입니다.
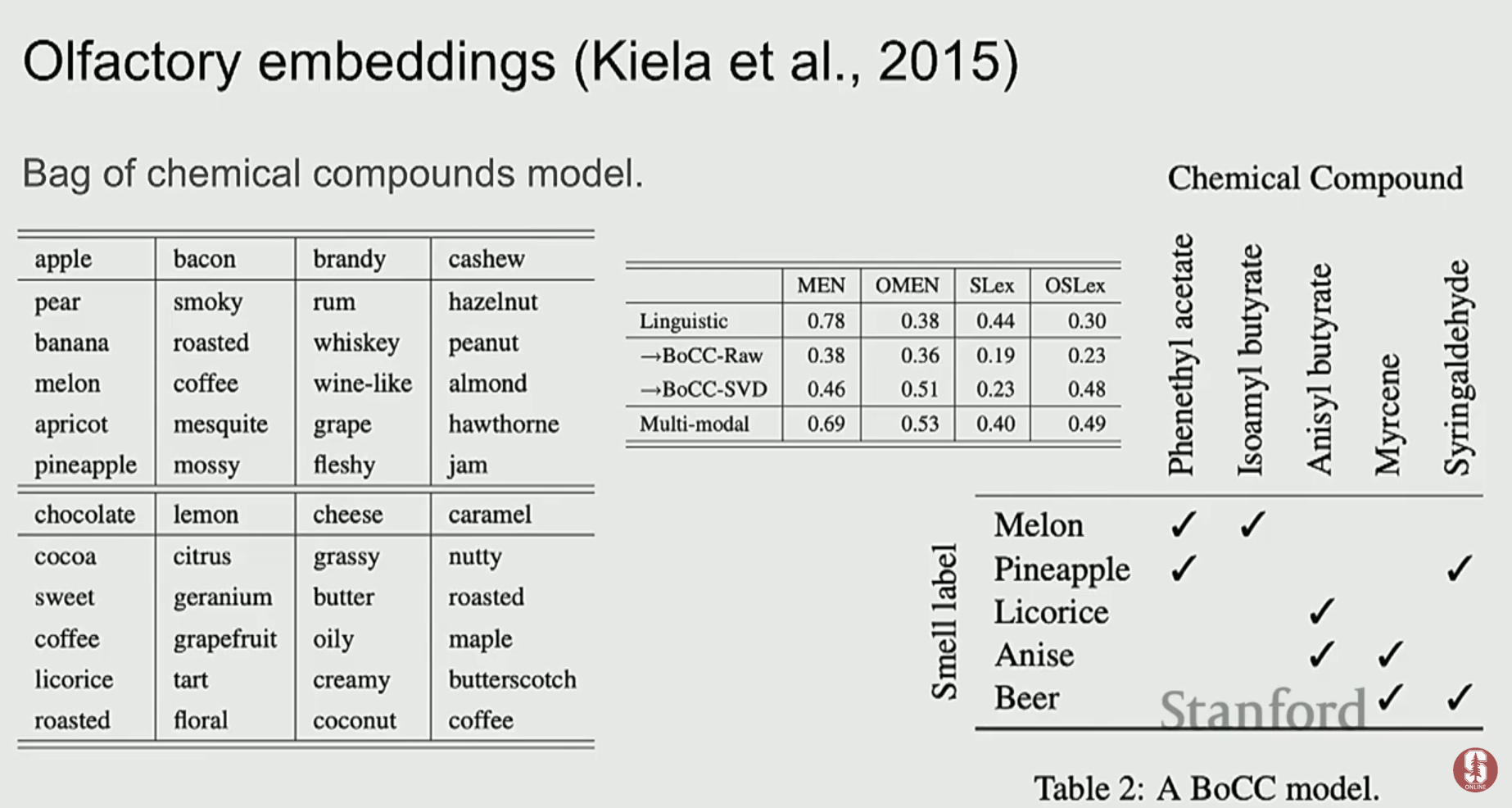
- 후각(Smell): 화학 분자 구조를 기반으로 '후각 임베딩'을 만들어, 특정 단어와 냄새 간의 연관성을 학습한 연구도 있습니다. 이는 인간의 의미 이해가 고대의 감각과 깊이 연결되어 있음을 시사합니다.
8. 미래 전망
- 하나의 거대 멀티모달 모델: 다양한 모달리티를 아우르는 하나의 파운데이션 모델이 등장할 것입니다.
- 스케일링 법칙의 확장: 텍스트를 넘어 멀티모달 데이터에서도 모델 크기, 데이터 양, 성능 간의 스케일링 법칙을 탐구하는 연구가 계속될 것입니다.
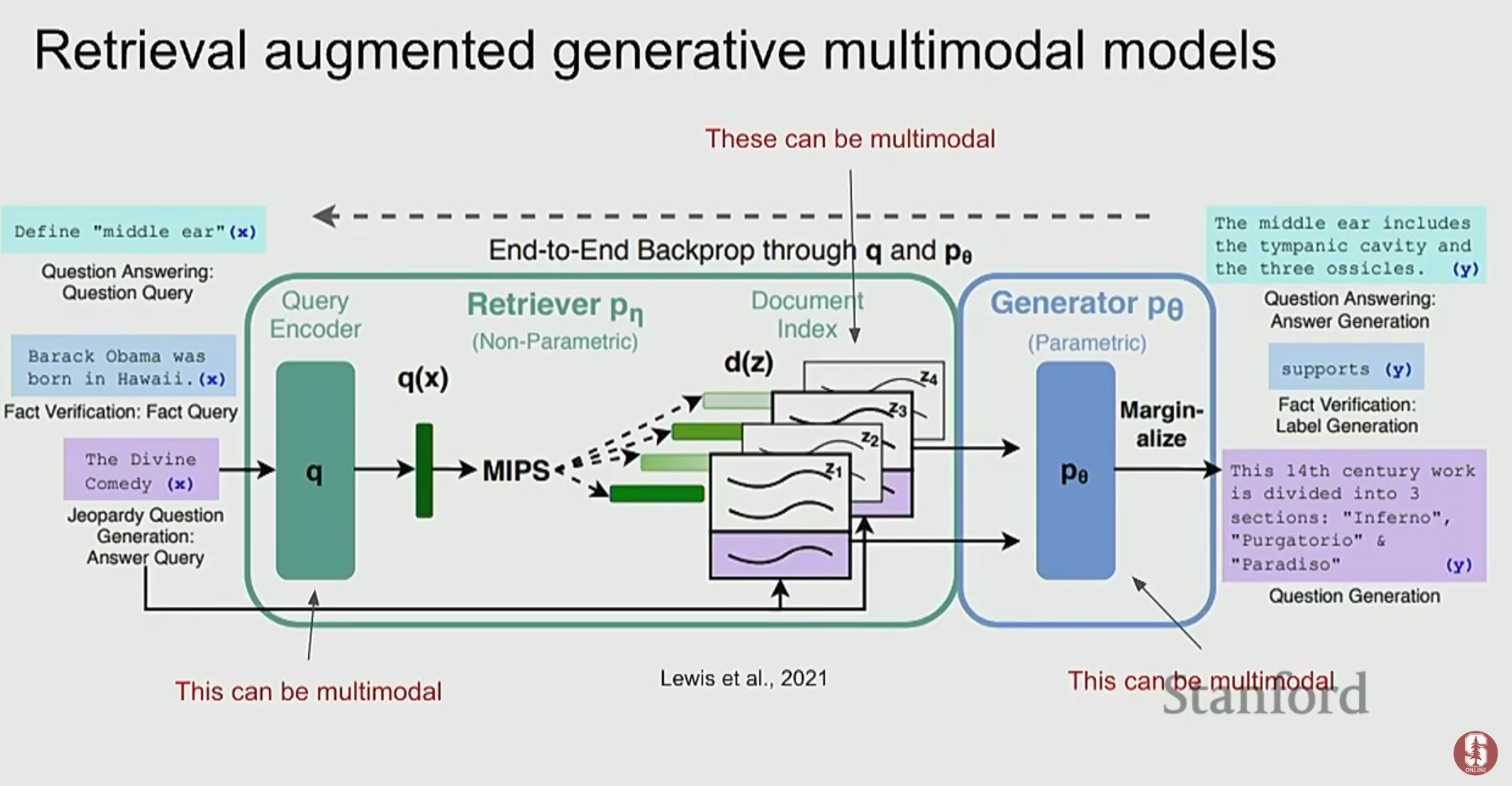
- 검색 증강 생성(RAG): 외부 지식을 검색하여 활용하는 RAG 기술이 멀티모달 분야에도 활발히 적용될 것입니다.
- 더 나은 평가 방법: 모델의 능력을 더 정확하고 깊이 있게 측정할 수 있는 새로운 벤치마크와 평가 방법론의 필요성이 더욱 중요해질 것입니다.


9. 강의 Q&A 세션
Q1: '모델을 얼린다(Freezing a model)'는 것의 의미는 무엇인가요?
-
모델의 가중치(weights)를 더 이상 업데이트하지 않도록 고정하는 것을 의미합니다.
-
특히 거대 언어 모델(LLM)을 얼리는 이유는, LLM이 이미 학습한 방대한 일반 지식을 그대로 보존하면서 특정 태스크에 과적합되는 것을 방지하기 위함입니다.
Q2: 초기 융합(Early Fusion)과 후기 융합(Late Fusion) 중 어떤 것이 더 좋은 전략인가요?
-
어떤 방식이 절대적으로 우월하다기보다는 풀어야 할 문제(task)의 특성에 따라 다릅니다.
-
후기 융합 (예: CLIP)은 각 인코더가 독립적이라 학습이 효율적이고 확장성이 좋습니다.
-
초기 융합은 두 양식 간의 더 깊고 풍부한 상호작용을 학습해야 하는 복잡한 추론 문제에 더 유리할 수 있습니다.
Q3: 이미지와 텍스트 중 어느 쪽이 학습하기 더 어렵고, 모델 크기는 어떻게 조절해야 하나요?
-
이미지는 텍스트보다 훨씬 더 많은 정보(더 높은 대역폭)를 담고 있어 복잡하지만, 어느 쪽이 더 학습하기 어렵다고 단정하기는 어렵습니다.
-
각 모달리티에 대한 스케일링 법칙(scaling laws)이 다를 수 있으며, 이는 아직 활발히 연구 중인 분야입니다.
Q4: 멀티모달 모델에도 편향(bias) 문제가 있나요?
-
매우 심각한 편향이 존재합니다. 웹에서 수집한 데이터로 학습하기 때문에, 데이터에 내재된 인종차별, 성차별 등 끔찍한 사회적 편향을 그대로 학습할 수 있습니다.
-
이는 AI 연구자들이 반드시 해결해야 할 중요한 과제 중 하나입니다.
Q5: 비디오 콘텐츠를 이해하는 데에는 어떤 어려움이 있나요?
-
비디오는 시간적 차원이 추가되어 복잡성이 높습니다.
-
하나의 접근법은 비디오에서 주요 프레임들을 샘플링하여 이미지 기반 모델처럼 처리하는 것입니다.
-
또는 객체 추적 기술과 모델의 어텐션 마스크를 시간 축에 따라 정렬하여 동적인 이해를 시도할 수도 있습니다.
Q6: 입력 데이터가 텍스트만 있거나 이미지만 있을 경우, 멀티모달 모델은 어떻게 작동하나요?
-
이는 많은 멀티모달 모델의 주요 약점 중 하나입니다. 두 가지 양식의 데이터가 모두 존재한다고 가정하고 설계되었기 때문입니다.
-
이 문제를 해결하기 위해 FLAVA와 같은 모델은 단일 모드 데이터(unimodal data)에 대해서도 강건하게 동작하도록 사전학습 단계부터 고려하여 설계되었습니다.
