1. 모델 해석가능성 및 편집 (Model Interpretability and Editing)
이 스터디 노트는 구글 브레인의 김빈 박사님의 강의를 바탕으로 작성되었으며, 기계가 인류에게 이롭도록 돕는 효과적인 인간-기계 소통의 중요성을 탐구합니다.
1) 해석가능성(Interpretability)과 인간-기계 소통의 목표
- 강의 목표: 기계가 인류에게 이로움을 주도록 만드는 것으로, 이를 위해 효과적인 인간-기계 소통을 구축하는 것이 핵심입니다.
- LLM과 생성 모델의 현재: 현재의 대규모 언어 모델과 생성 모델들은 인상 깊지만, 동시에 그들의 장기적인 영향에 대한 불확실성 때문에 약간 두렵게 느껴질 수 있습니다.
- 인간과 기계의 관계: 기계를 다른 가치관과 경험을 가진 동료로 비유하며, 인간과 기계 사이의 지식 격차를 해소하기 위한 공통의 언어와 이해를 구축해야 함을 강조합니다.
- 예시: 알파고의 '37수'는 인간이 이해하기 어려운 기계 행동의 대표적인 사례입니다.
- 궁극적인 꿈: 기계와의 대화를 통해 의학, 과학 등 다양한 분야에서 새로운 것을 배우고 발전하는 것입니다. 이는 보상 해킹(reward hacking)이나 AI 안전(AI safety)과 같은 문제를 해결하는 데 필수적입니다.
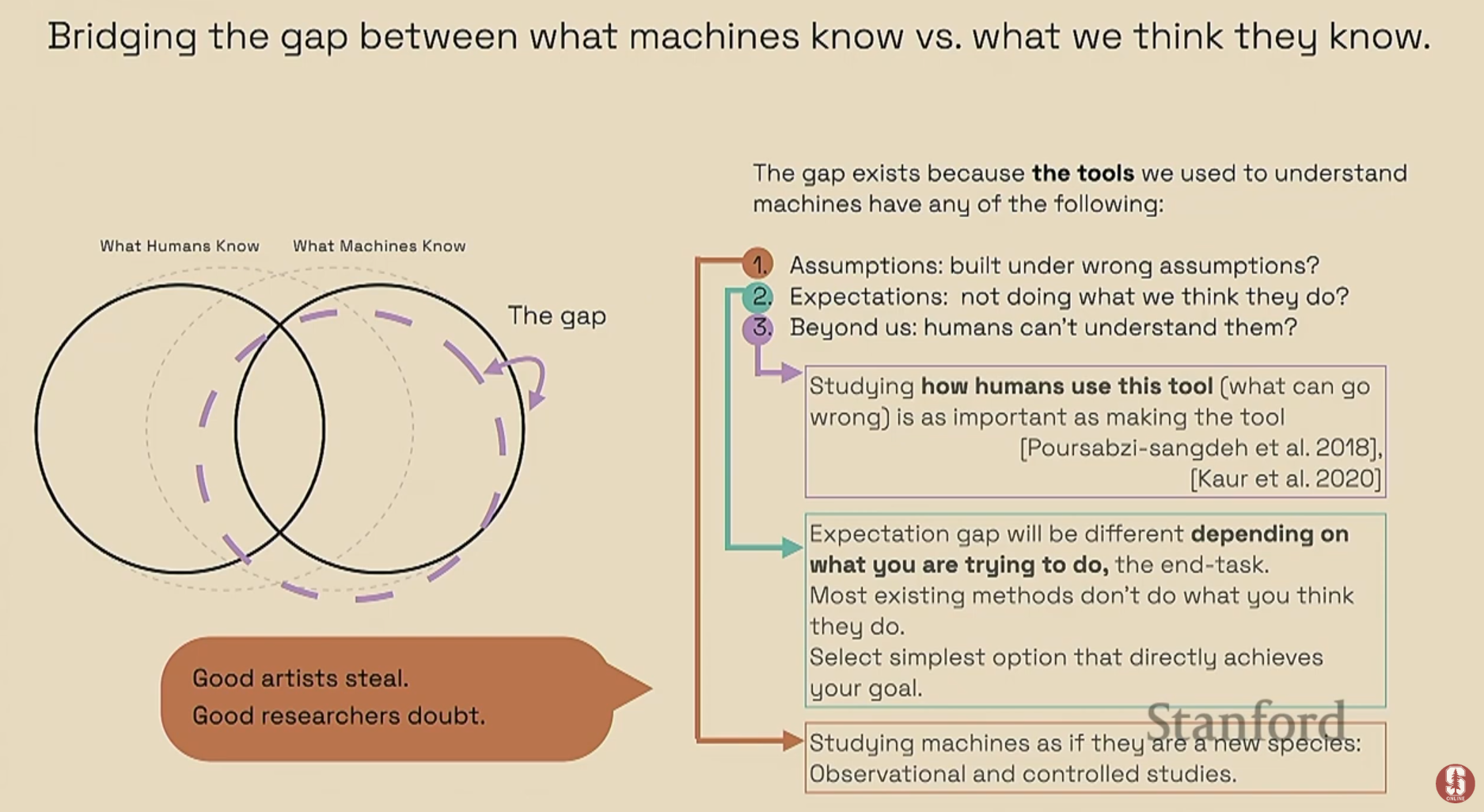
2. 기계 지식 이해의 격차
1) 기계 지식 이해의 어려움
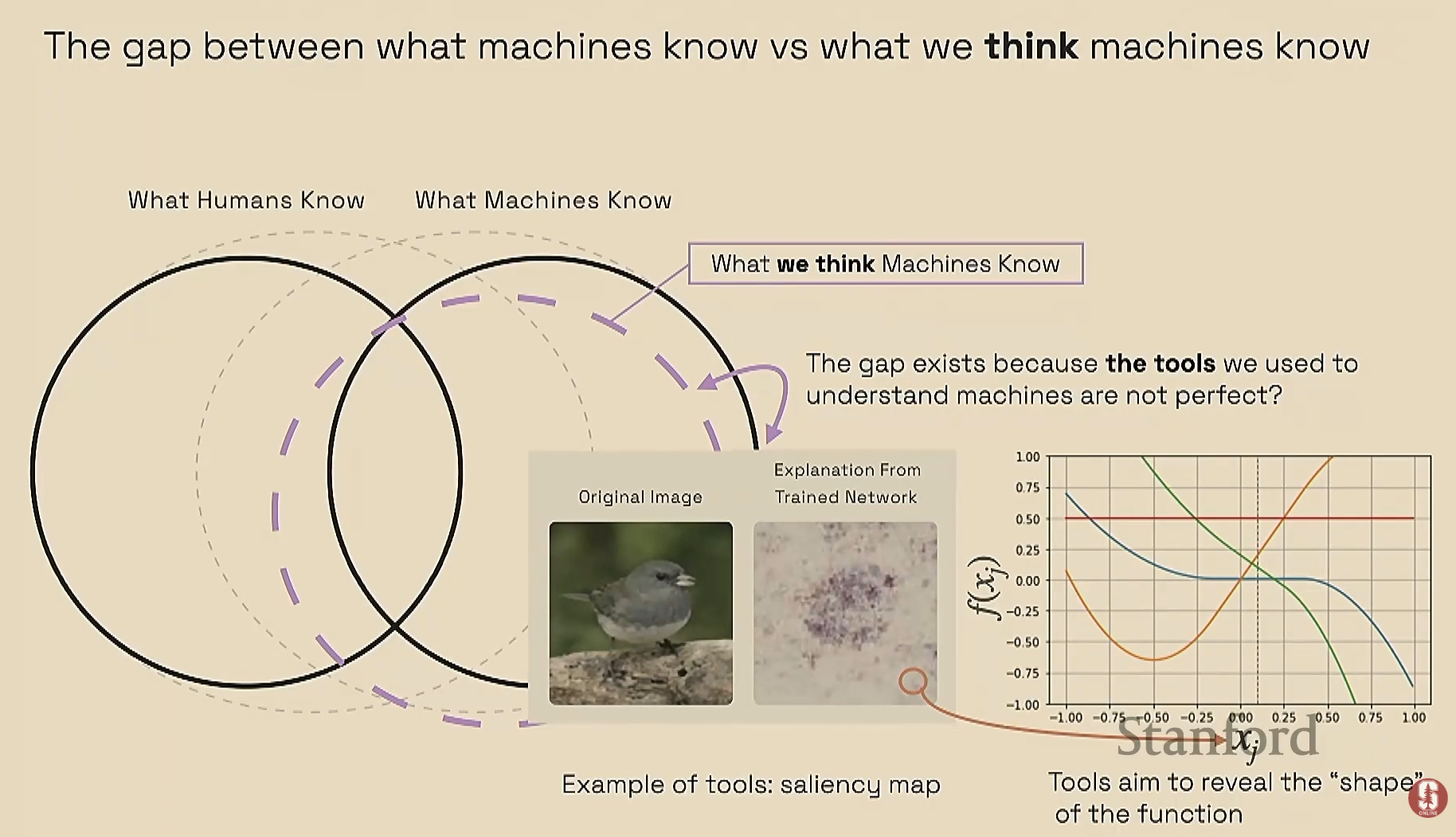
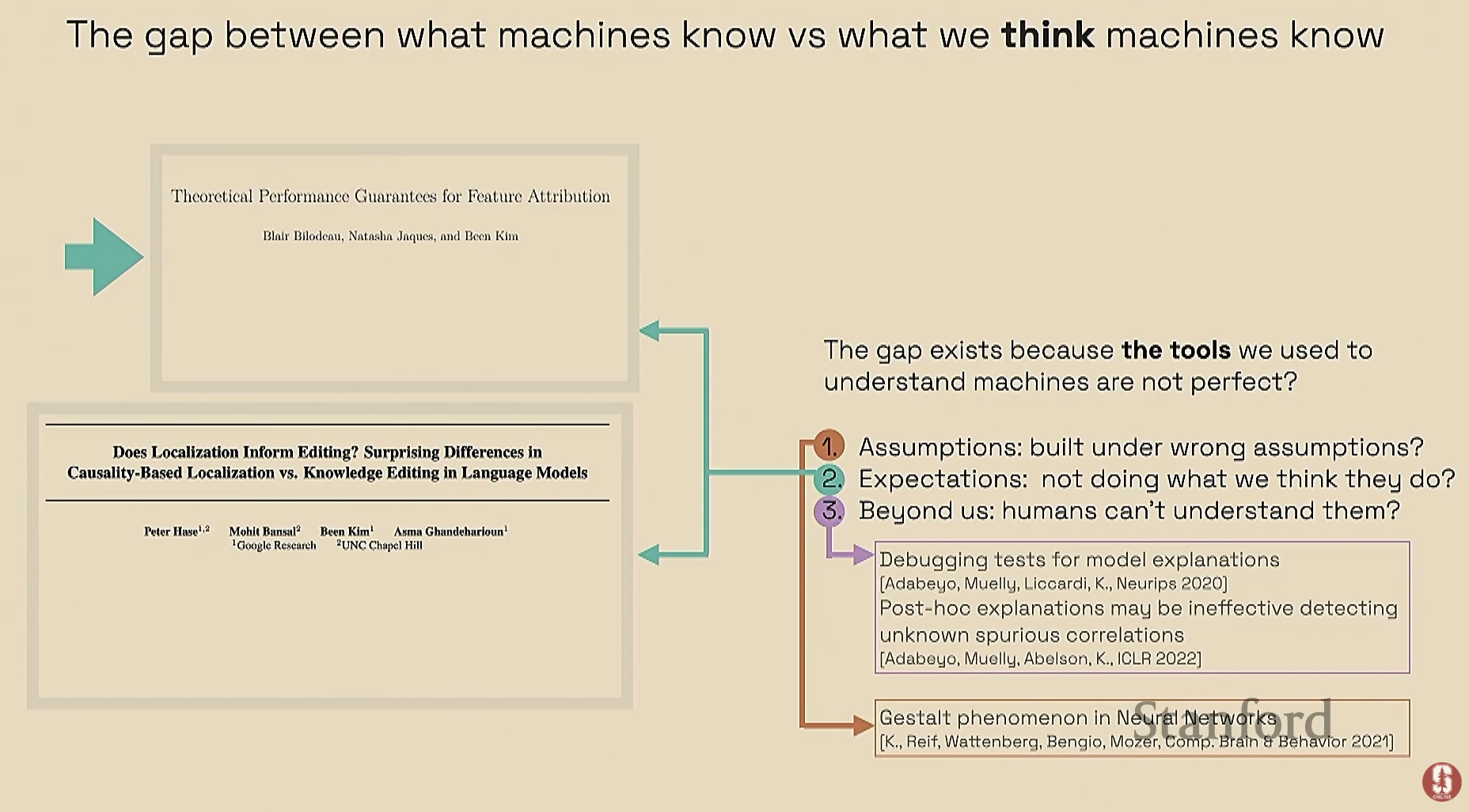
- 기계가 실제로 무엇을 알고 있는지 이해하는 데에는 우리가 인식하는 것과 실제 기계의 지식 사이에 상당한 격차가 존재합니다. 이 격차가 발생하는 세 가지 주요 원인은 다음과 같습니다:
- 잘못된 가정: 인간은 기계가 우리와 유사하게 세상을 인식할 것이라고 가정하여 잘못된 해석을 내리곤 합니다.
- 불일치하는 기대: 모델이 'X'를 수행할 것이라는 우리의 기대와 달리, 실제로는 'Y'를 수행하는 등 기대와 현실의 불일치가 발생합니다.
- 인간 이해의 초월: 기계가 인간이 단순히 파악할 수 없는 초인적인 능력을 보일 수 있습니다.
2) saliency map과 Attribution 방법의 한계
-
Saliency Map과 같은 유명한 해석가능성 방법들의 단점이 강의의 주요 부분을 차지합니다.
-
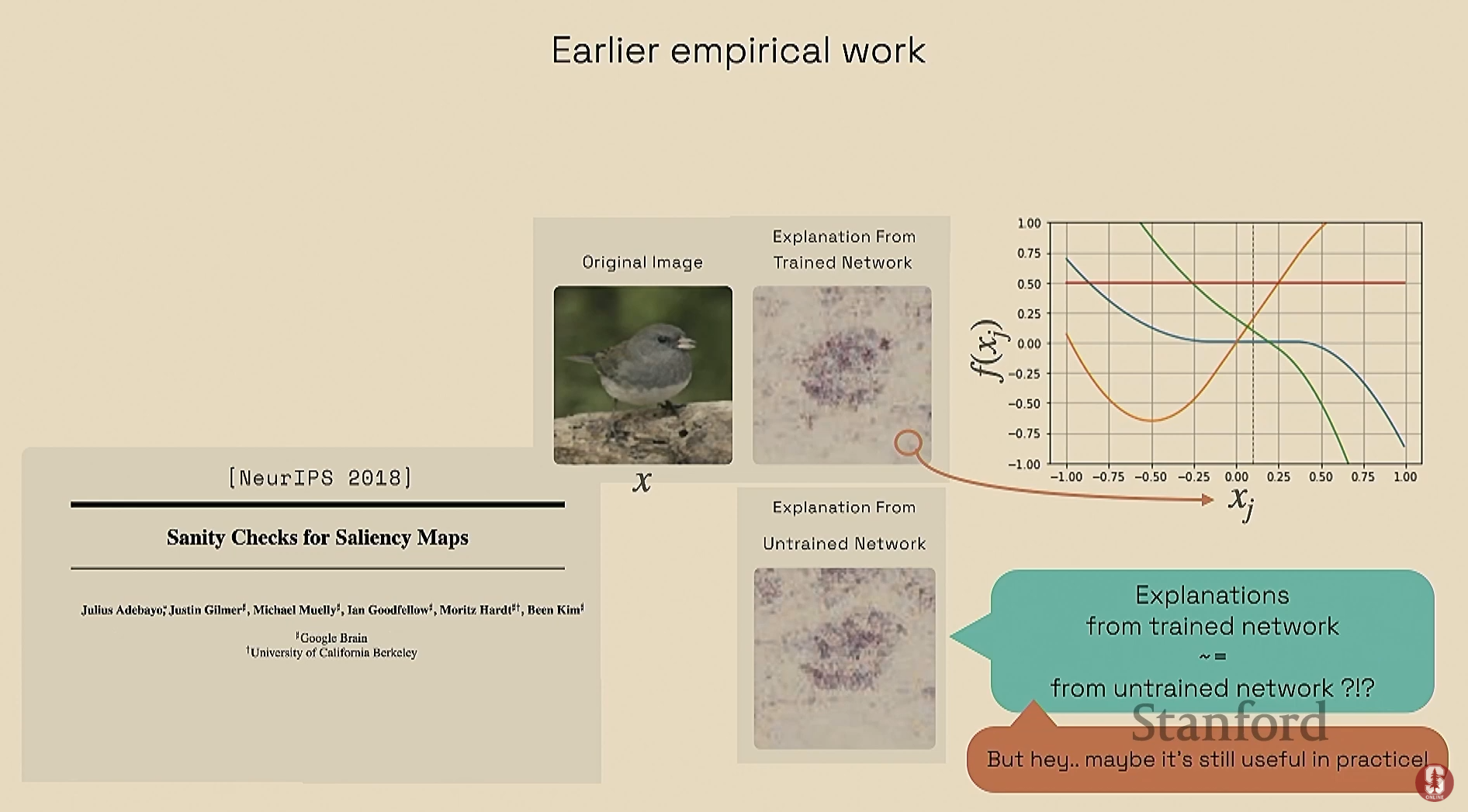
초기 연구 결과 (2018년): 훈련된 네트워크와 훈련되지 않은 네트워크의 Saliency Map이 놀랍도록 유사하다는 점을 발견했습니다. 이는 무작위 예측과 의미 있는 예측이 동일한 설명을 생성한다는 것을 의미합니다.
-
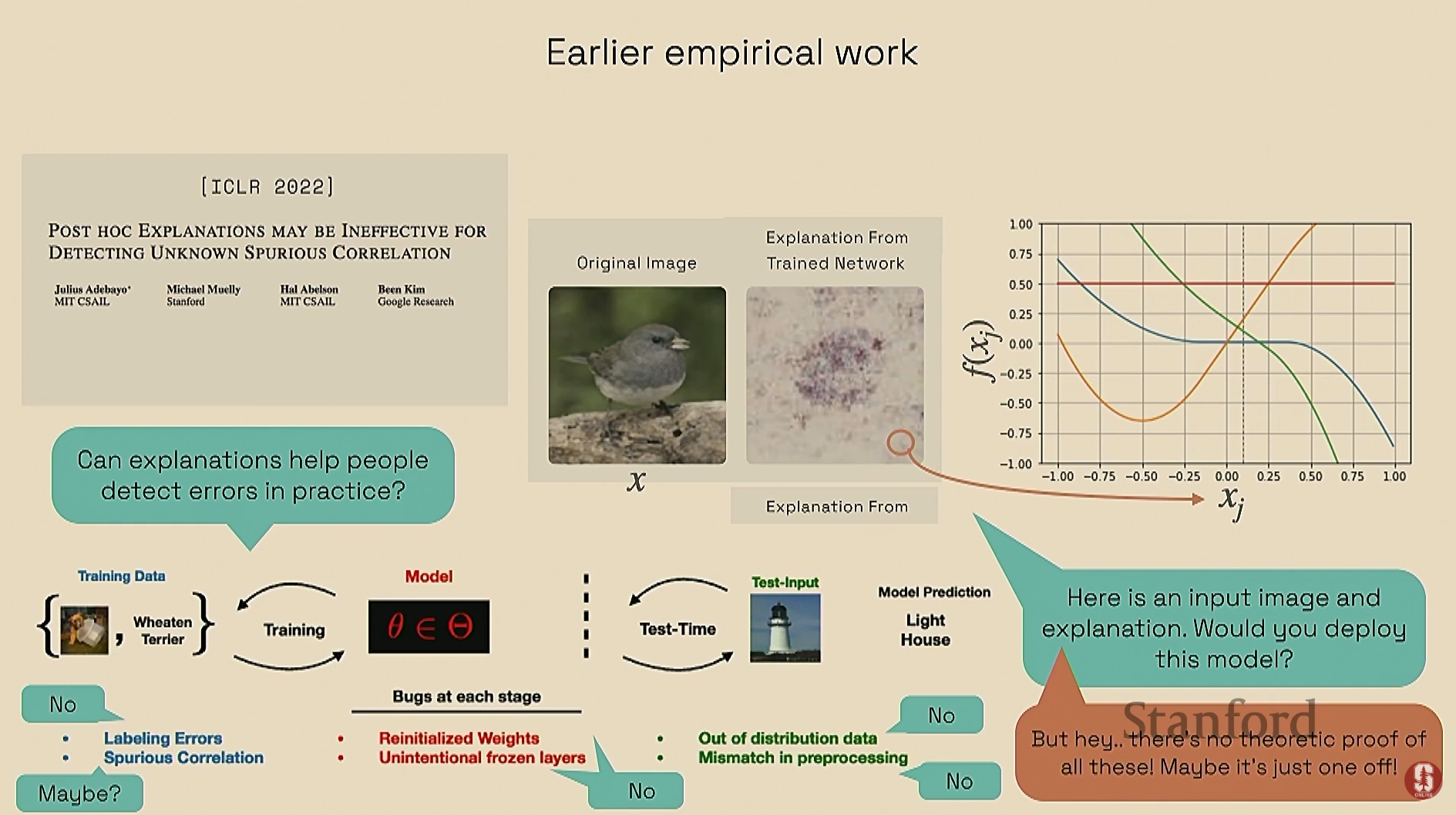
후속 연구: 이러한 방법들이 레이블링 오류, 가짜 상관관계, 분포에서 벗어난 데이터(OOD)와 같은 모델의 오류를 감지할 수 있는지 탐구했으나, 대부분 그렇지 못하다는 결론을 얻었습니다.
-
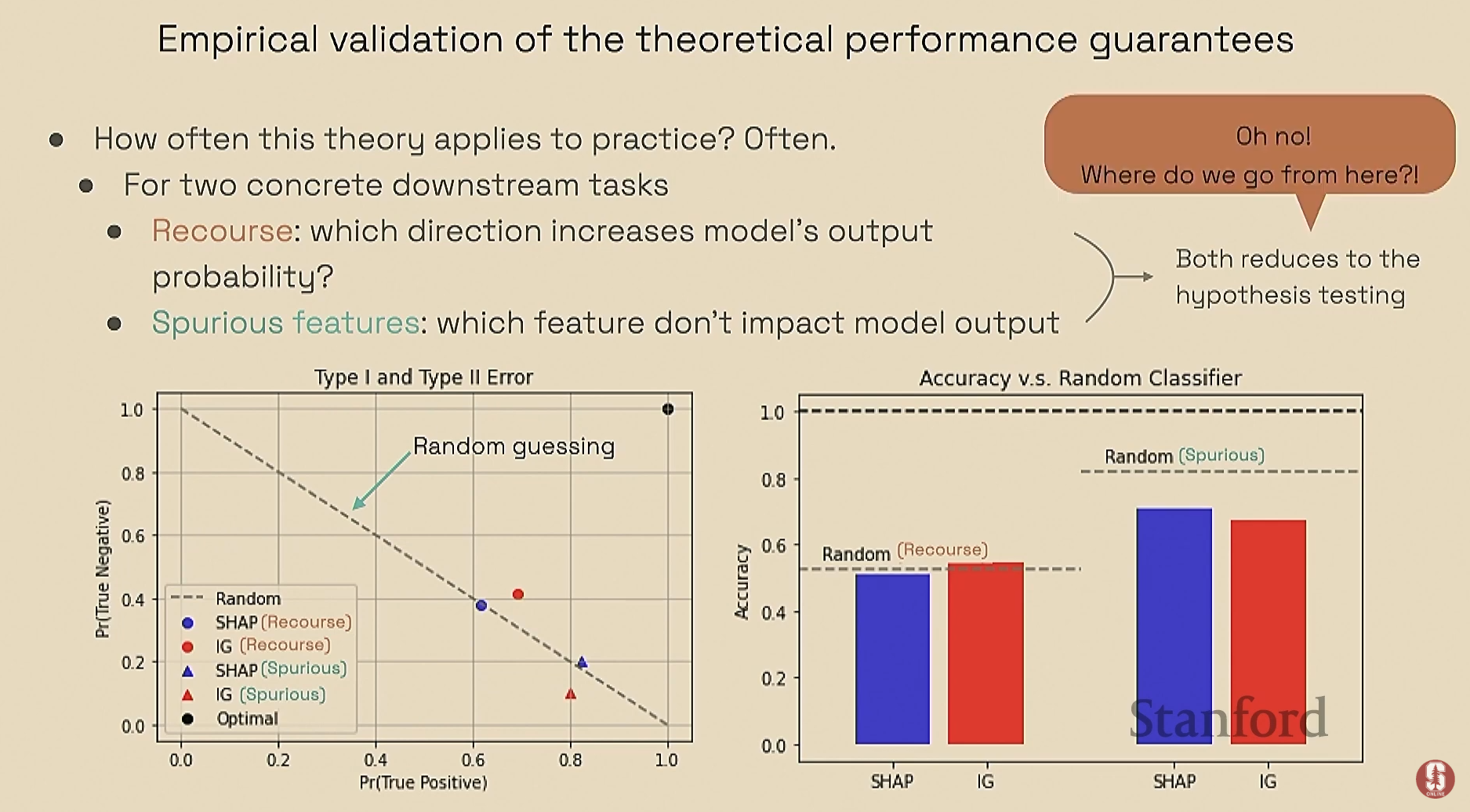
이론적 증명: 최근 연구에서는 일부 유명한 Attribution 방법들이 무작위 추측보다 나은 성능을 보일 수 없다는 이론적 증명을 제시했습니다.
- 이 증명은 해석가능성의 유효성을 가설 검증 프레임워크로 접근한 결과입니다. 사용자가 설명을 보고 세운 가설이 옳은지 틀린지를 검증할 때, SHAP나 Integrated Gradients(IG) 같은 방법론조차 무작위 추측(random guessing)보다 나을 수 없음을 수학적으로 보였습니다.
-
실용적 시사점: 이 이론적 발견은 더 큰 모델과 실제 과제(예: 가짜 상관관계)에서 경험적으로 검증되었으며, 해당 방법들이 일관되게 무작위 추측보다 나은 성능을 보이지 못함을 확인했습니다.
-
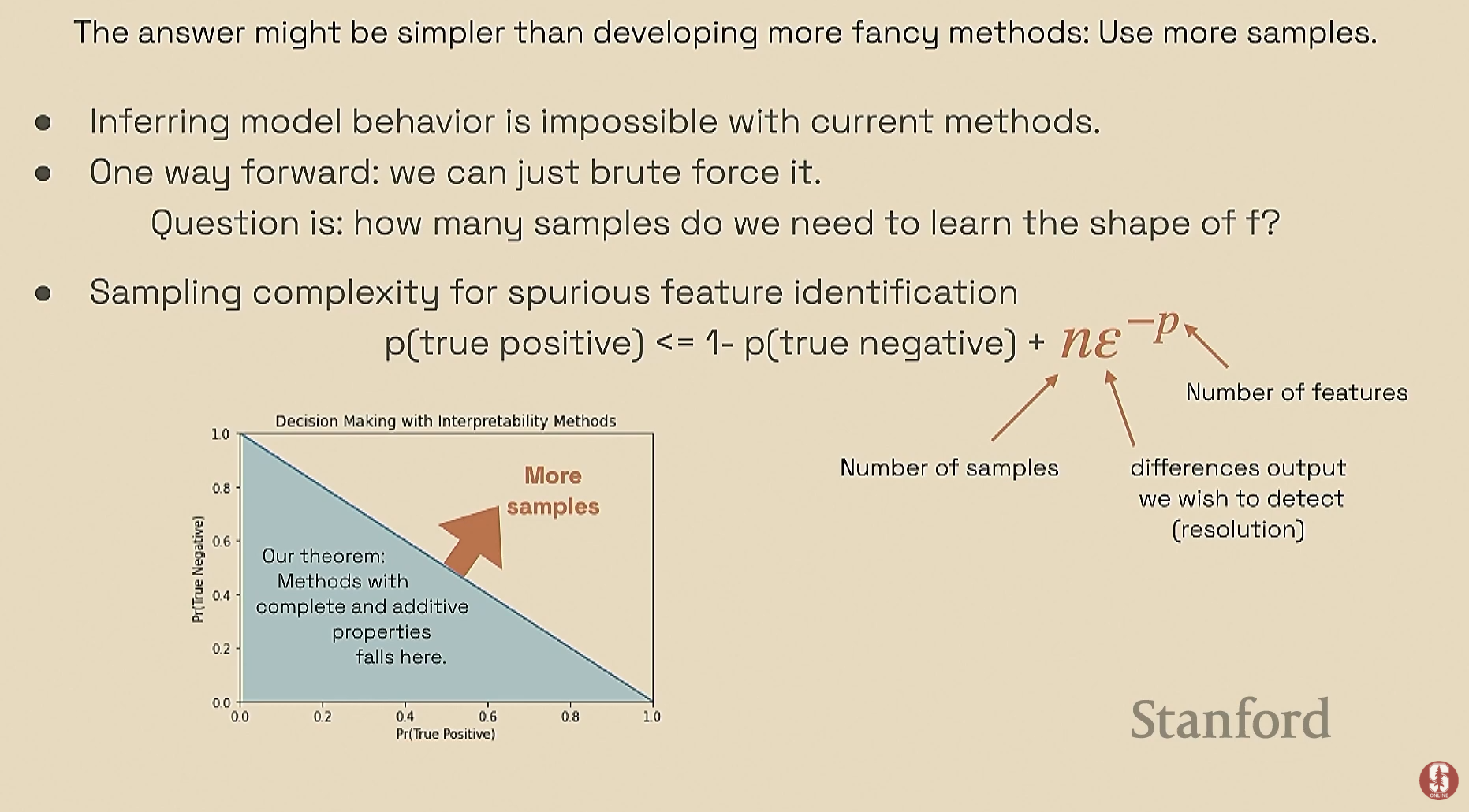
수학적 개념 및 해결책:
- 이 문제를 해결하기 위해 관심 지점 주변을 샘플링하여 함수의 모양을 추정하는 간단한 접근법을 제안했습니다.
- 필요한 샘플 수는 특성의 수와 원하는 출력 차이의 해상도에 비례하고, 출력 값의 차이에 반비례합니다. 이는 특정 방정식을 통해 수학적으로 표현됩니다.



3. NLP에서의 모델 편집과 지식 지역화
1) 대규모 언어 모델(LLM) 편집의 도전
- NLP 분야, 특히 대규모 언어 모델을 편집하는 연구로 주제가 전환됩니다.
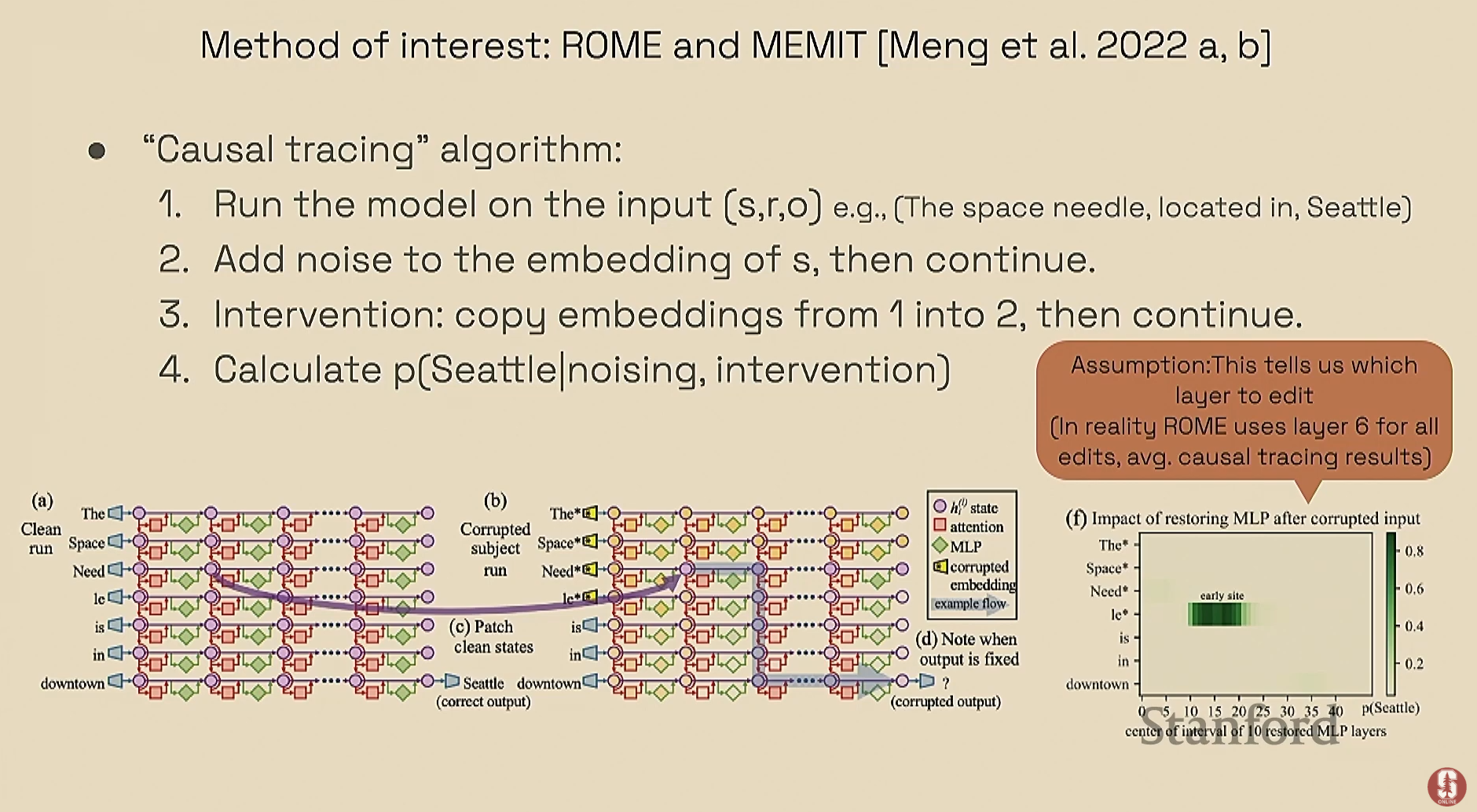
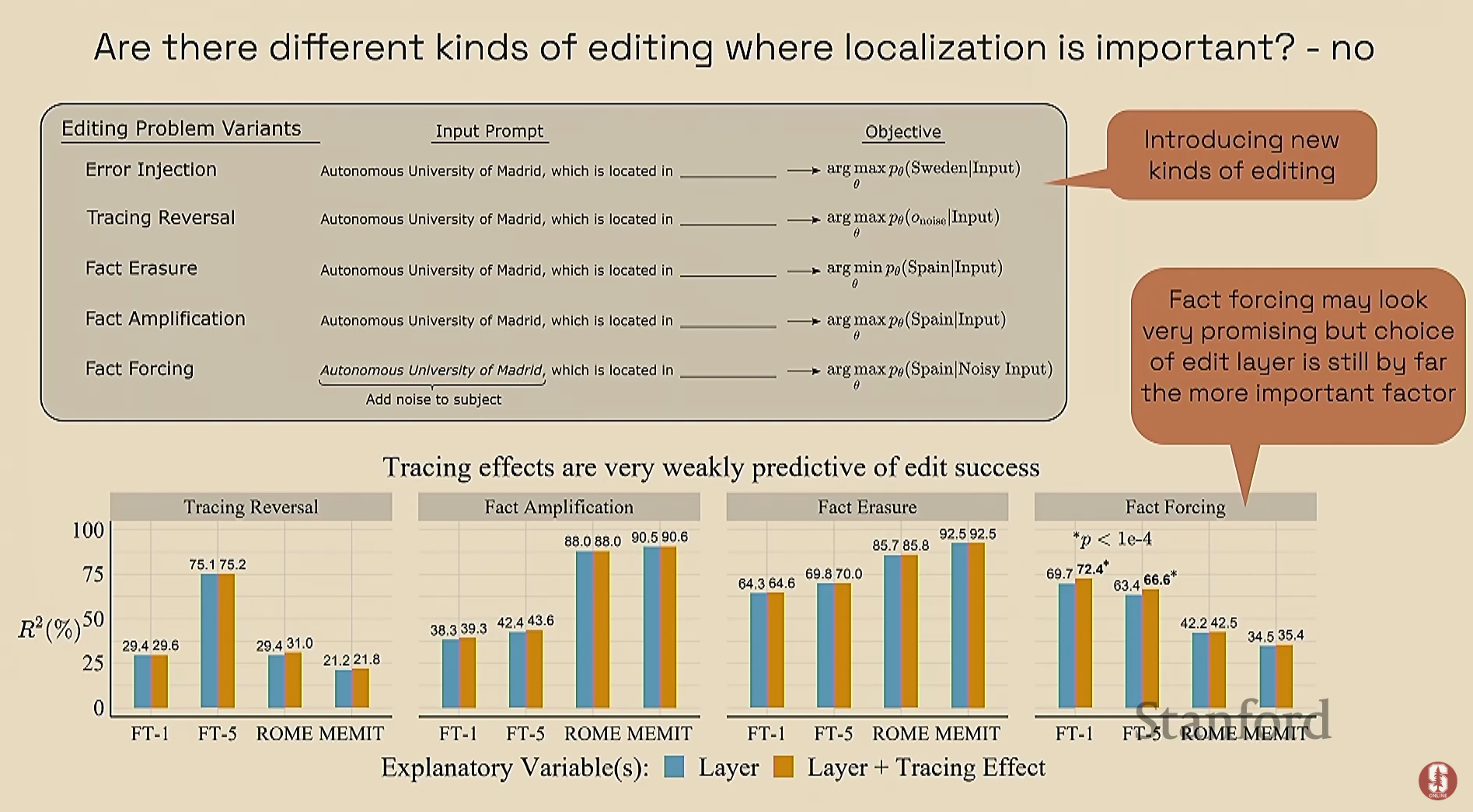
- The Rome Paper (2022년): 이 연구는 "인과적 추적 알고리즘(causal tracing algorithm)"을 사용하여 모델 내의 사실적 지식을 찾아내고 편집하는 것을 목표로 했습니다.
- 알고리즘: 깨끗한 실행(clean run)과 노이즈가 추가된 "손상된" 실행(corrupted run)을 비교하고, 다른 모듈에 개입하여 정답이 얼마나 잘 복구되는지 확인하는 방식입니다.

2) 지식 지역화(Localization)와 편집 성공의 불일치
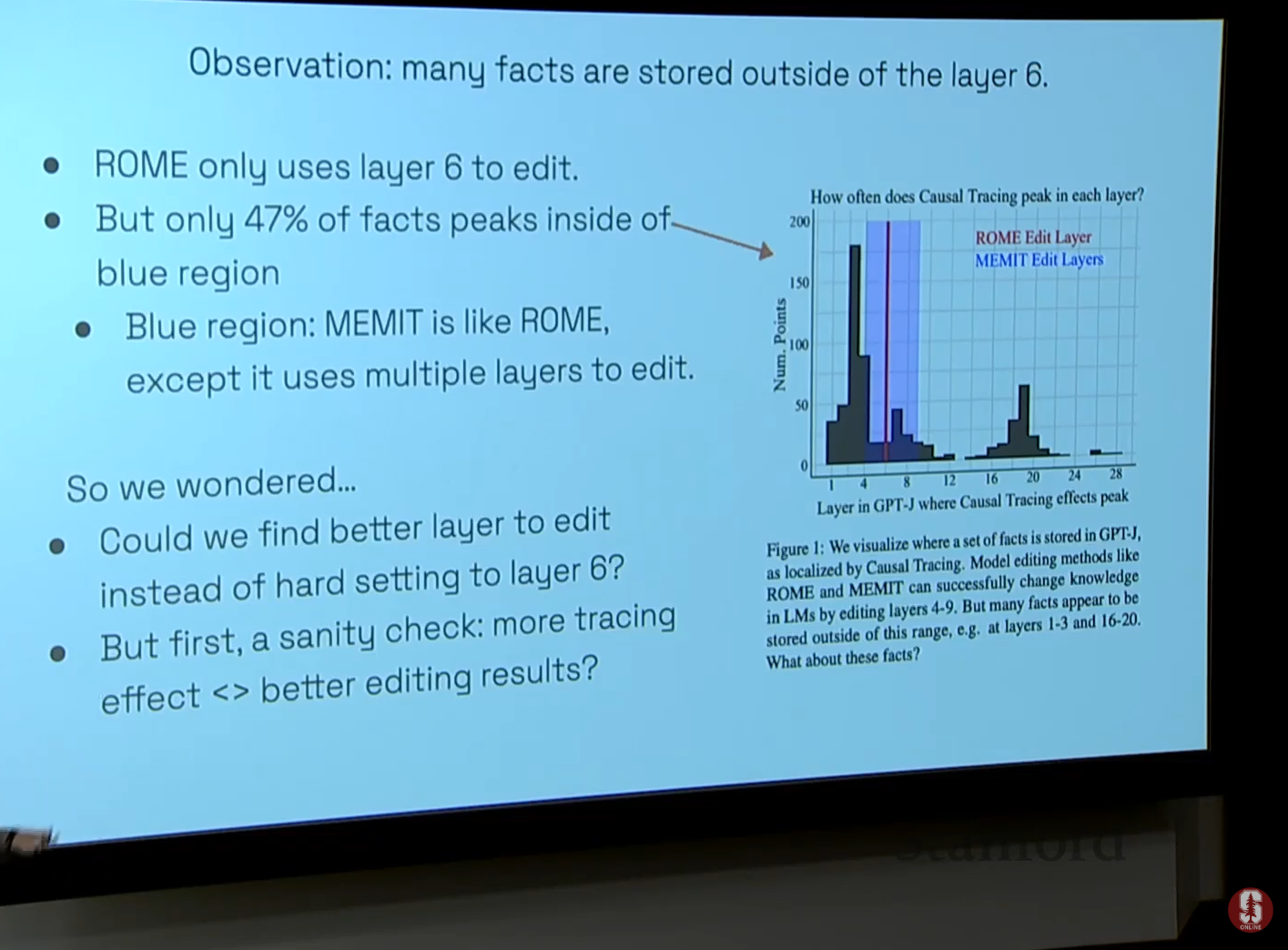
- 연구 결과의 차이: Rome 논문은 GPT-J의 6번 레이어에 사실적 지식이 주로 저장된다고 제안했지만, 김빈 박사님 팀은 사실에 따라 지식의 피크가 다른 레이어에서 나타남을 발견했습니다.
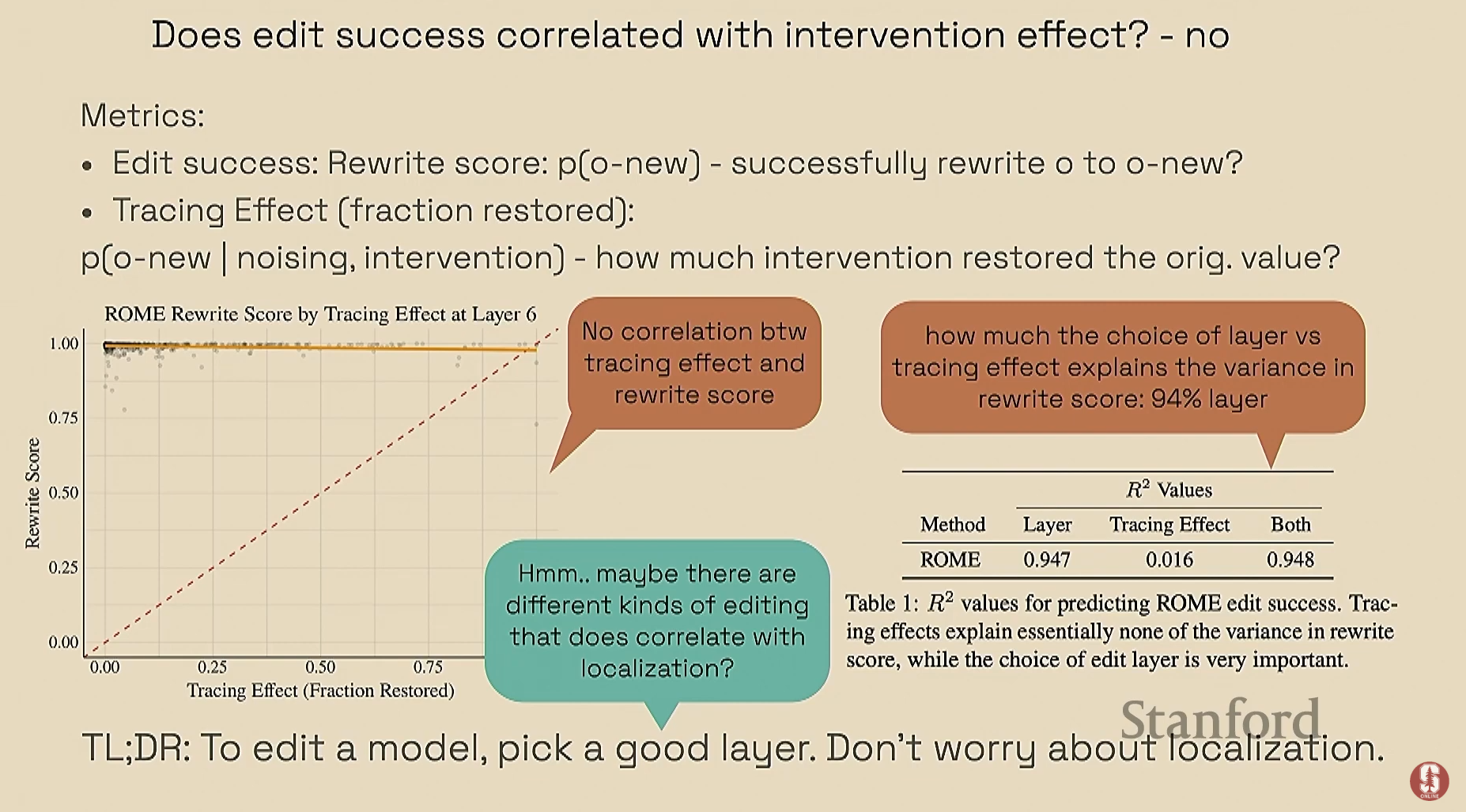
- 핵심 발견: 지역화("tracing effect")와 편집 성공("rewrite score") 사이에 상관관계가 거의 0에 가깝다는 것을 발견했습니다.
- 편집 성공의 분산 중 94%는 레이어 선택이 설명했으며, tracing effect는 단 0.016%만 기여했습니다. 이는 인과적 추적에 의한 지역화가 편집 성공을 예측하지 못함을 시사합니다.
- 결론: 지역화 방법은 정보의 흐름에 대한 통찰을 주지만, 모델 편집을 직접적으로 촉진하지는 않습니다. 따라서 편집 방법으로 지역화 방법을 검증하거나, 지역화를 통해 편집 방법을 정당화해서는 안 됩니다.
- 강의에서는 이 결론을 다음과 같은 강력한 문장으로 요약합니다: "지역화에 대해서는 전혀 걱정할 필요가 없습니다. 이건 추가적인 탄소 낭비일 뿐입니다." ("Don't worry about localization at all; it's extra wasted carbon")


3) 개념 정리
지식 지역화 (Localization)
- 정의: AI 모델 내부에서 '특정 지식'이나 '개념'이 정확히 어디에 저장되어 있는지 찾아내는 과정입니다.
- 예시: 거대한 도서관(AI 모델)에서 '파리의 수도는 프랑스'라는 정보가 담긴 특정 책(뉴런 또는 파라미터 그룹)을 찾아내는 것과 같습니다.
모델 편집 (Model Editing)
- 정의: 이미 학습이 완료된 모델을 전체 재학습(retraining) 없이 내부의 특정 지식만 직접 수정하거나 업데이트하는 기술입니다.
- 예시: 도서관 전체를 리모델링하는 대신, 내용이 틀린 책 한 권만 새 책으로 교체하는 것과 같습니다.
둘의 관계와 흥미로운 문제점
- 핵심: 논리적으로는 지역화에 성공하면 편집도 쉬워야 하지만, 실제 연구 결과는 둘의 상관관계가 거의 없다는 것을 보여줍니다. 이는 AI 모델 속 지식이 한곳에 깔끔하게 모여있지 않고, 여러 곳에 분산되고 얽혀서 저장되어 있음을 시사하는 매우 중요한 발견입니다.
1. 강화학습(RL)에서의 창발적 행동 심층 분석
강의의 이 부분에서는 지능형 에이전트, 특히 여러 에이전트가 상호작용하는 시스템에서 발생하는 예측하기 어려운 창발적 행동(Emergent Behaviors)을 어떻게 이해하고 분석할 수 있는지에 초점을 맞춥니다. 접근 방식은 마치 생물학자가 "야생의 새로운 종"을 연구하는 것과 같이, 관찰과 통제를 통해 그들의 행동 원리를 파악하는 것입니다.
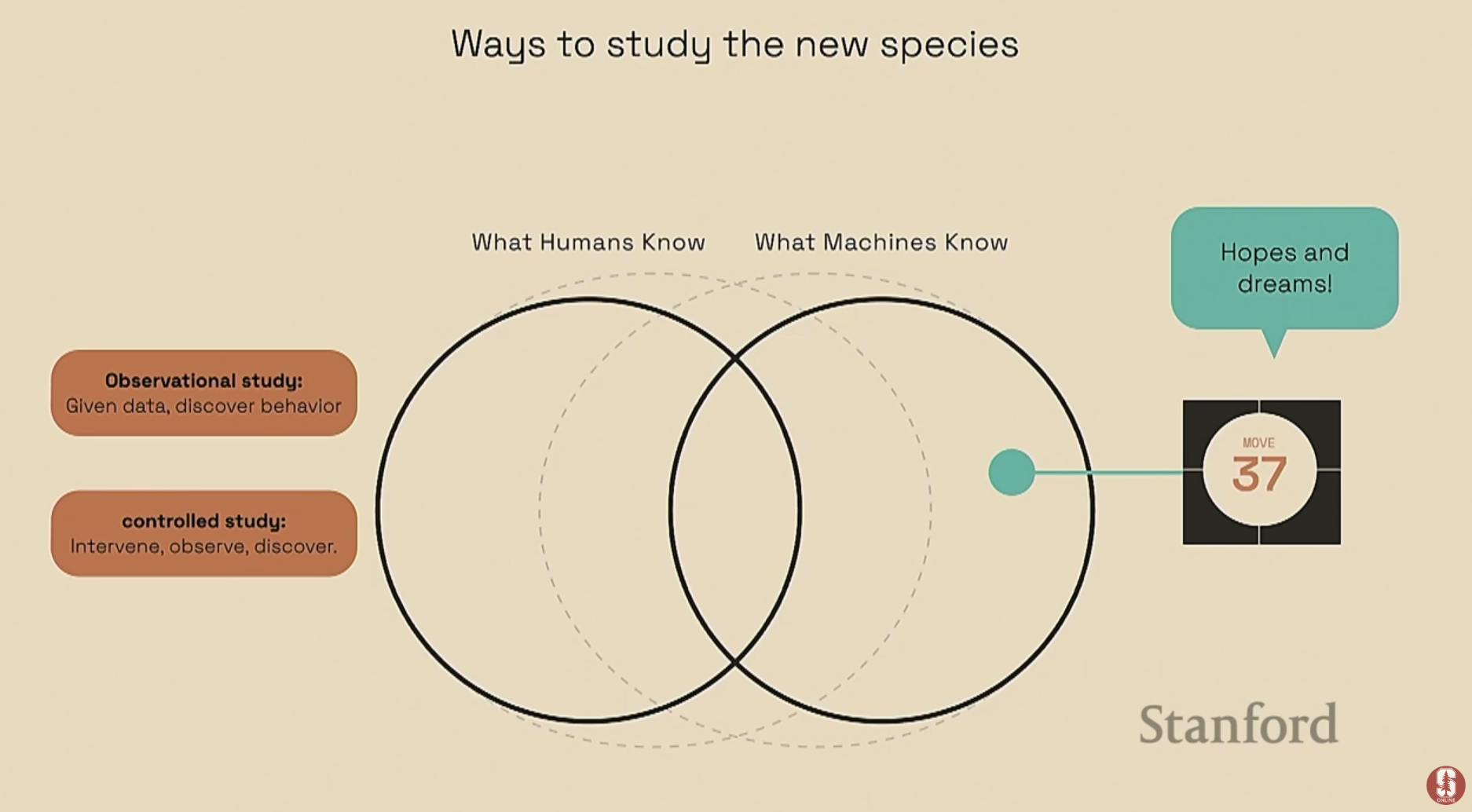
1) 관찰 연구: 행동의 발견 (Observational Study)
이 접근법의 목표는 인간이 미리 정의한 레이블 없이, 에이전트들이 스스로 학습하여 만들어내는 복잡하고 새로운 행동 패턴을 자연스럽게 발견하는 것입니다.
-
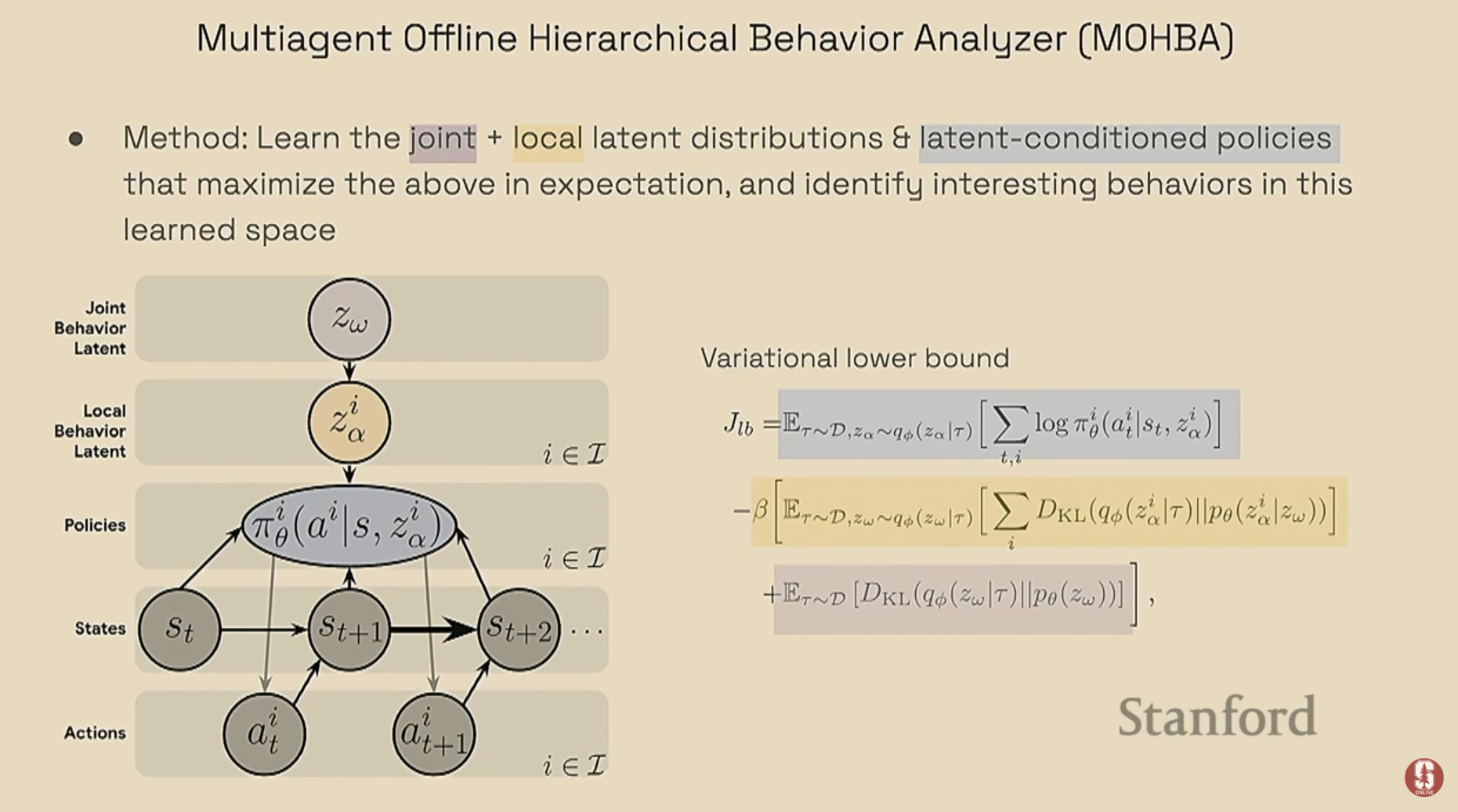
핵심 방법론: 베이지안 생성 그래픽 모델 (Bayesian Generative Graphical Model)
- 이 모델은 시스템 내에서 발생할 수 있는 모든 행동들을 하나의 공동 잠재 임베딩 공간(joint latent embedding space)에 표현합니다.
- 쉽게 말해, 비슷한 행동들은 이 가상의 공간에서 가까운 위치에 점으로 찍히고, 다른 행동들은 멀리 찍히게 됩니다. 이를 통해 행동들을 자동으로 그룹화(클러스터링)하고 시각화할 수 있습니다.
-
적용 사례:
- Mujoco (2에이전트 달리기): 간단한 환경에서 두 에이전트(앞다리, 뒷다리 제어)의 달리기 행동을 잠재 공간에 시각화했습니다. 그 결과, 효율적으로 잘 달리는 행동 그룹과 비효율적인 행동 그룹이 명확하게 구분되는 것을 확인하며, 방법론의 가능성을 입증했습니다.
- OpenAI 숨바꼭질 게임: 더 복잡한 다중 에이전트 환경에 이 모델을 적용했습니다. 분석 결과, 잠재 공간에서 명확한 행동 클러스터들이 형성되었고, 이 클러스터들은 인간이 나중에 확인했을 때 "요새 건설", "경사로 이용하기", "달리고 쫓기" 등 의미 있는 전략적 행동들과 정확히 일치함을 발견했습니다.


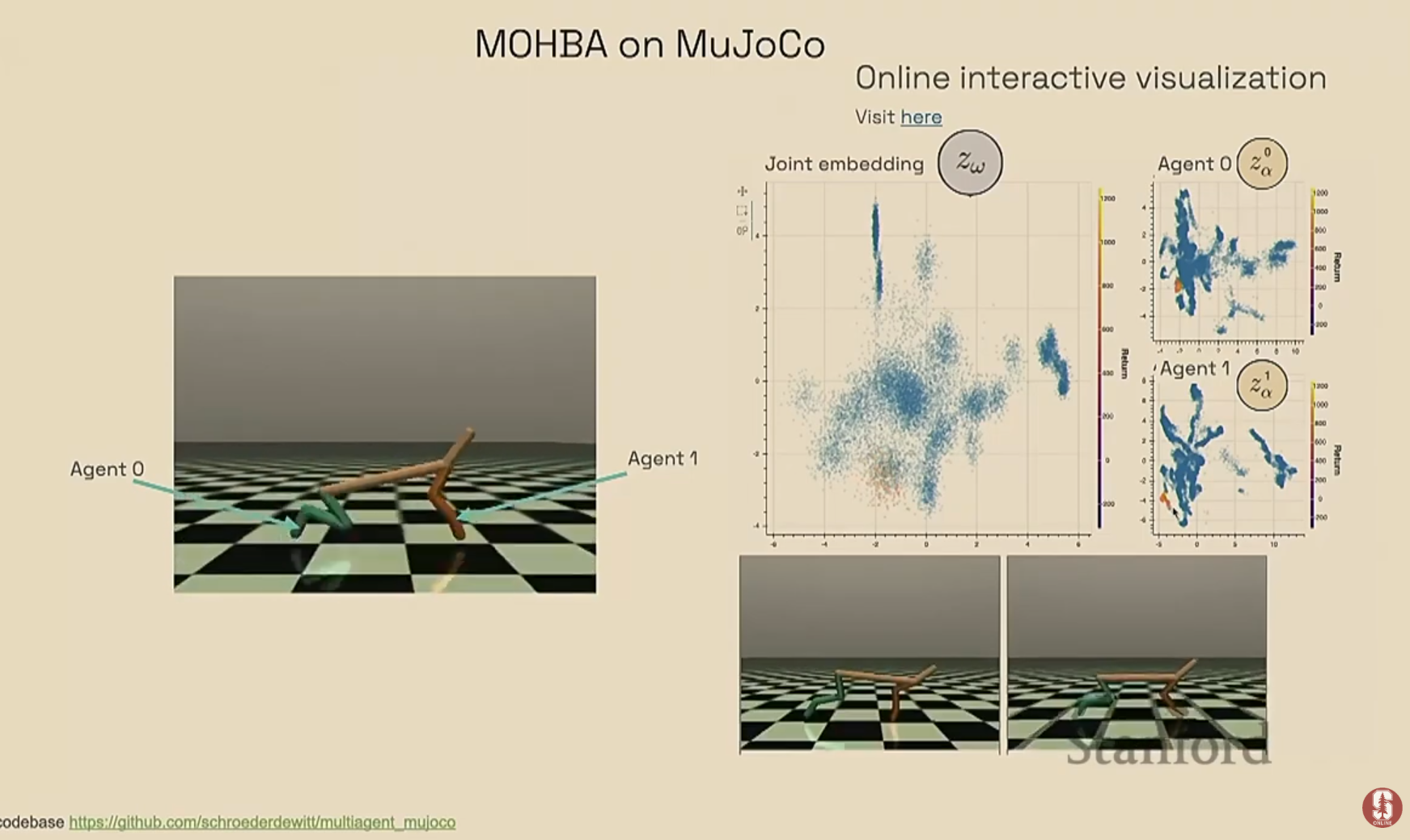
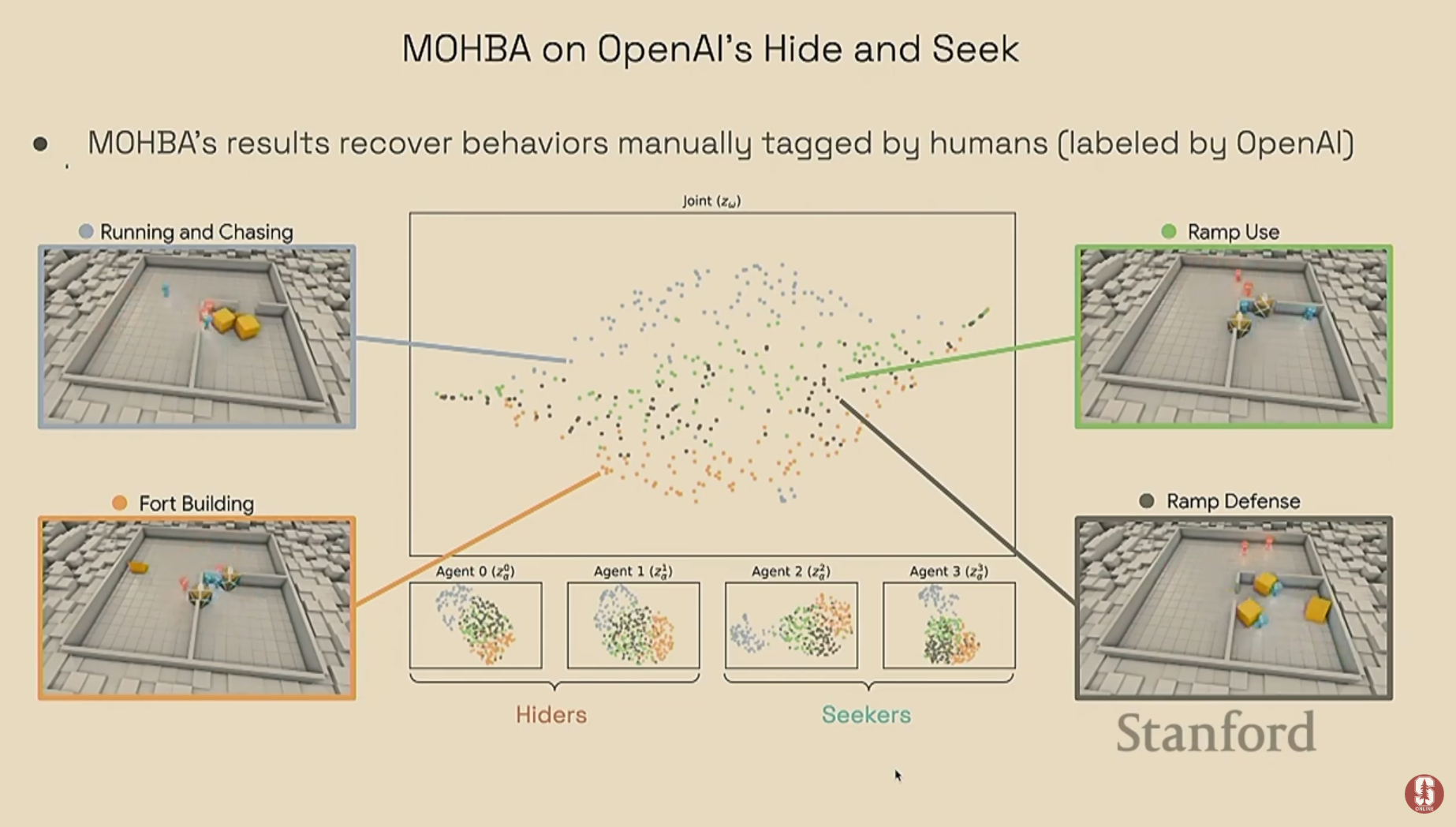

2) 통제 연구: 행동 원리의 증명 (Controlled Study)
관찰을 통해 행동을 발견했다면, 통제 연구는 특정 개념이 에이전트의 행동에 얼마나, 그리고 왜 중요한지 인과관계를 증명하는 것을 목표로 합니다.
-
핵심 방법론: 컨셉 병목 모델 (Concept Bottleneck Model)의 RL 적용
- 신경망의 특정 뉴런(병목)에 인간이 이해할 수 있는 개념(Concept)을 의도적으로 학습시킵니다. 예를 들어, '팀 지향성', '게으름', '자원(사과) 보기' 같은 개념을 각각의 뉴런에 할당하는 식입니다.
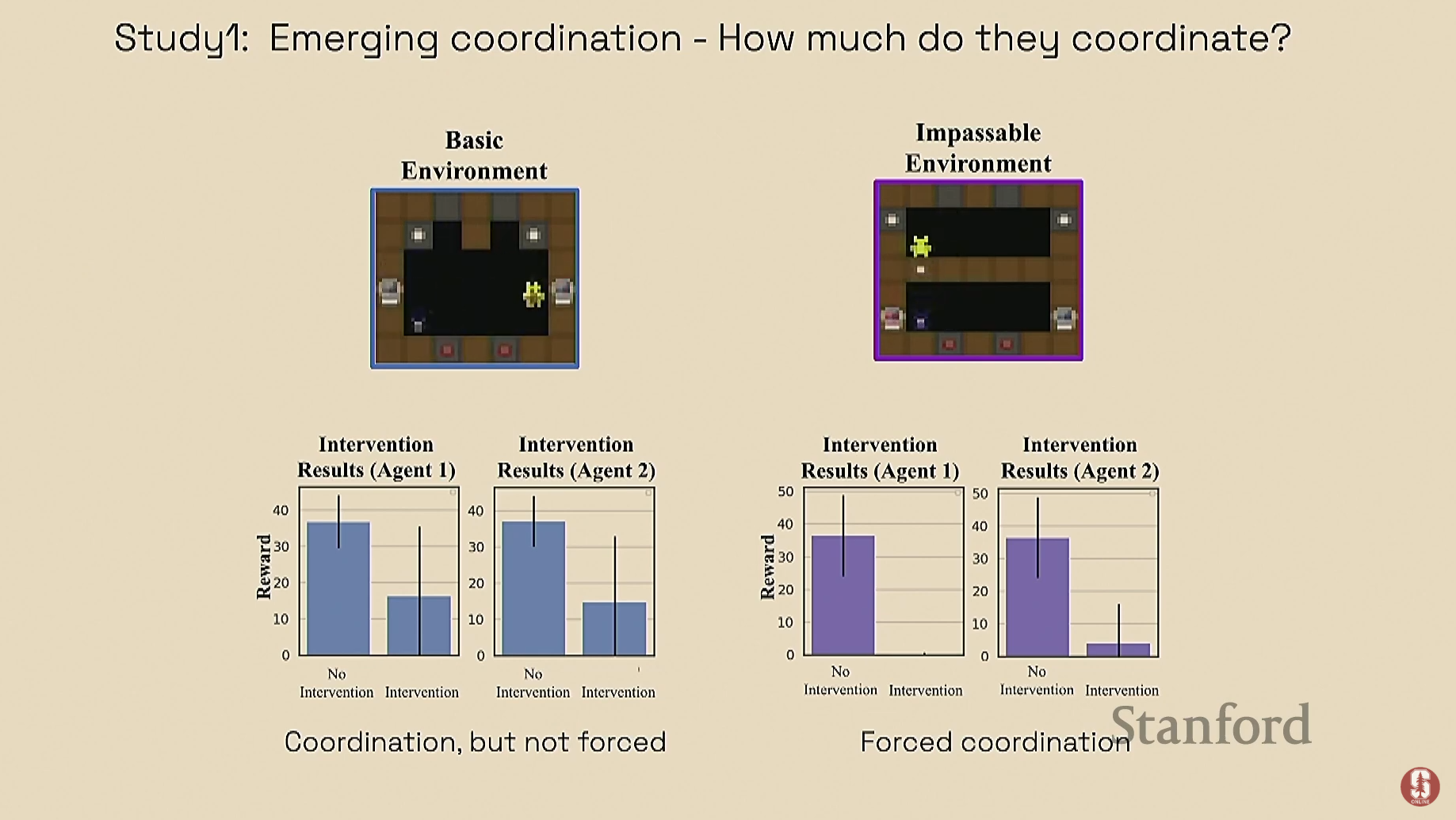
- 개입(Intervention): 모델이 행동할 때, 특정 개념에 해당하는 뉴런의 값을 강제로 0으로 만듭니다. 예를 들어, '팀 지향성' 뉴런을 비활성화하고 전체 시스템의 성과(보상)가 얼마나 떨어지는지를 측정합니다. 이를 통해 해당 개념의 인과적 중요도를 정량적으로 파악할 수 있습니다.
-
적용 사례:
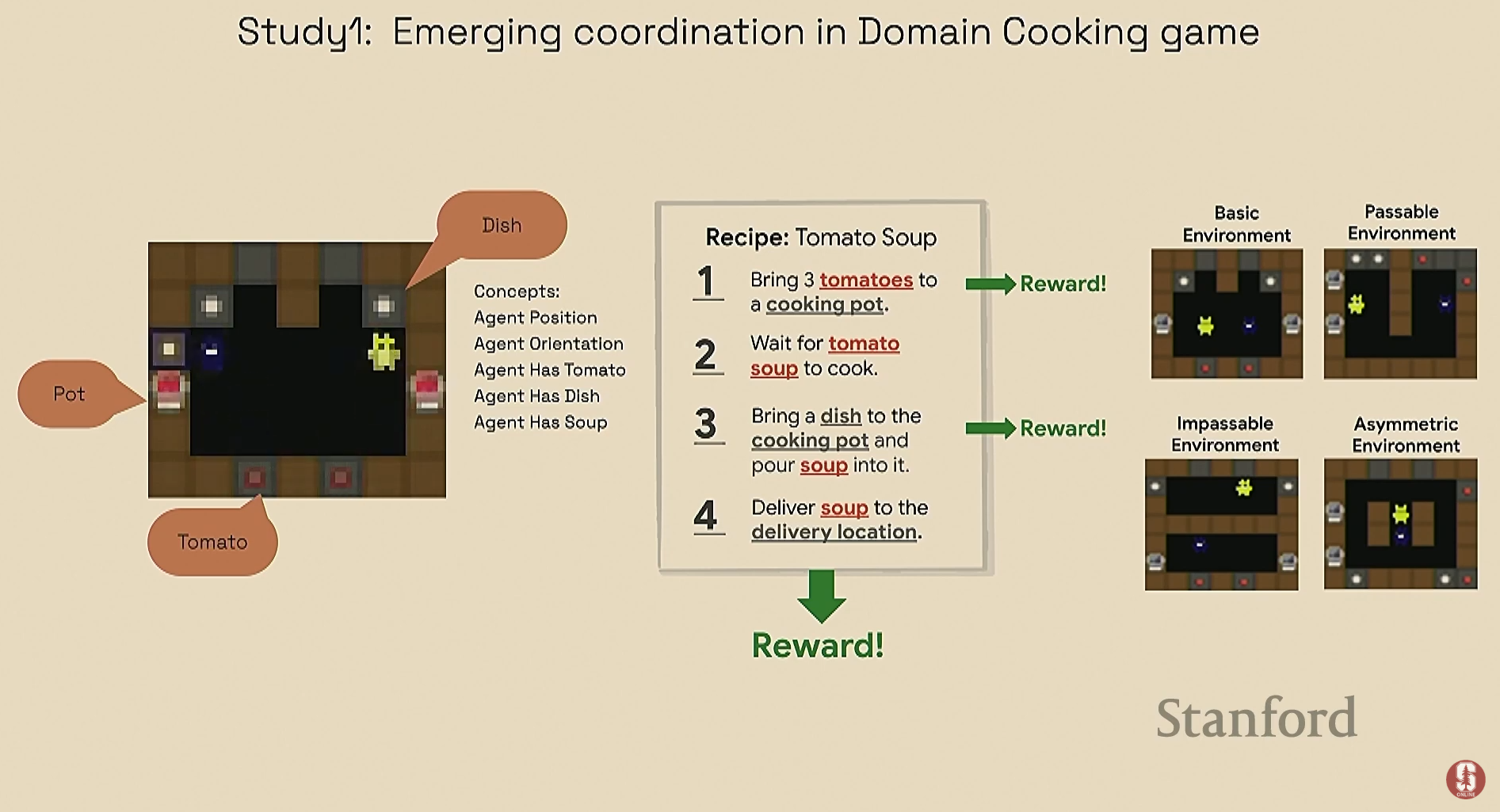
- 요리 게임 (2에이전트 수프 만들기):
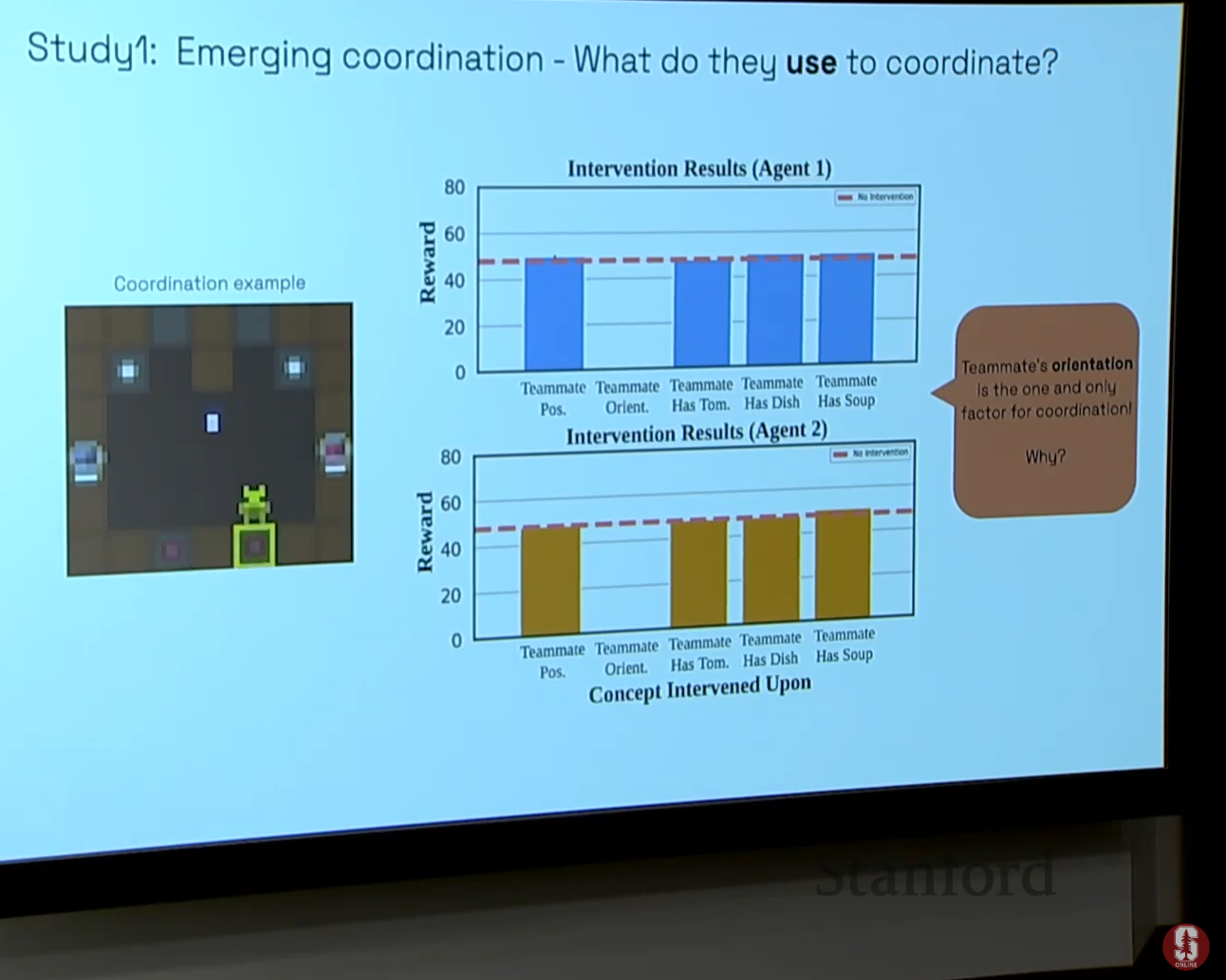
- 발견: 여러 개념(예: 양파 보기, 접시 보기 등) 중 "팀 지향성(Team Orientation)" 개념에 개입했을 때 성능이 가장 크게 저하되었습니다.
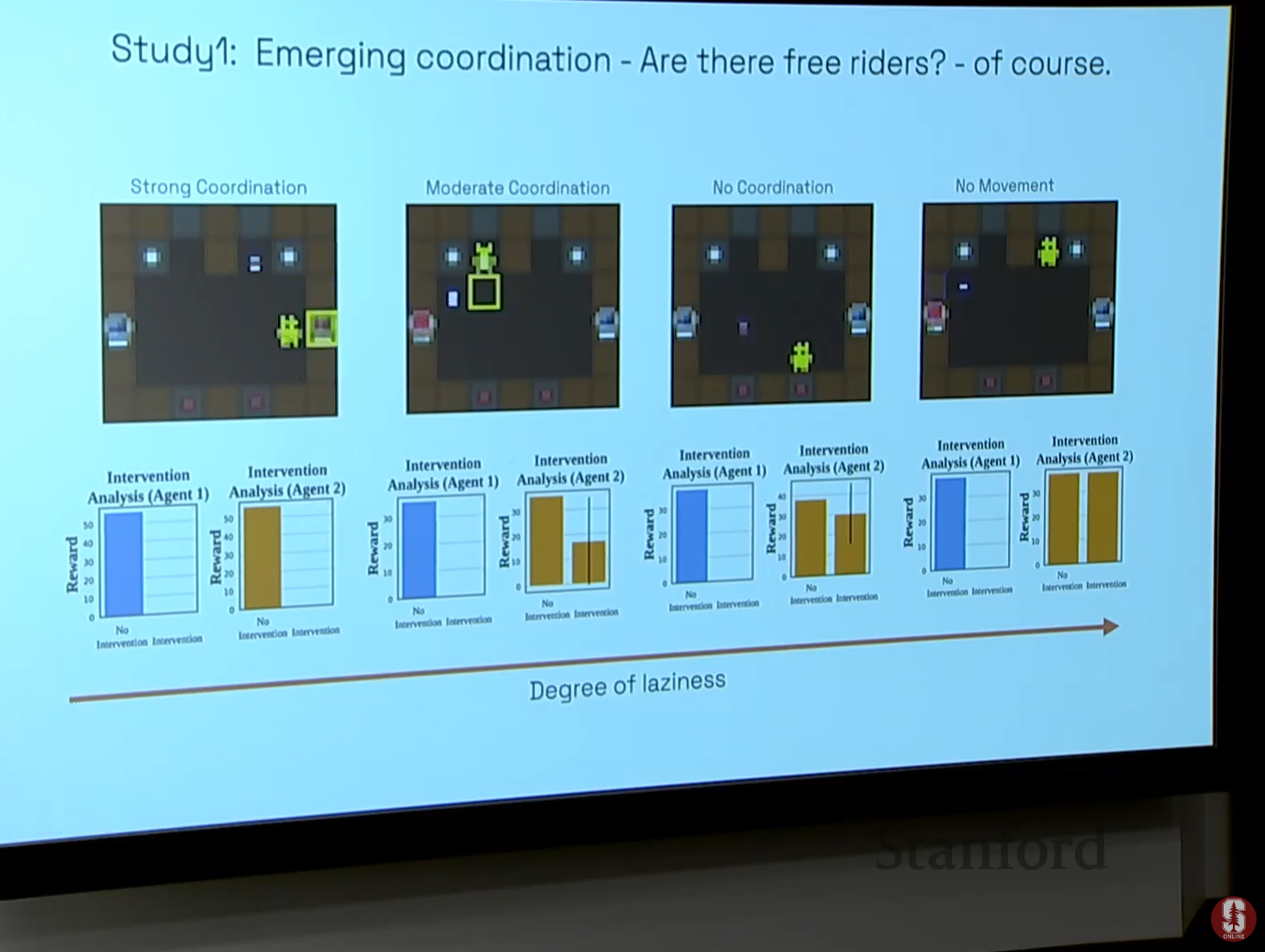
- 통찰: 이는 에이전트의 '방향'이 동료 에이전트의 다음 행동을 예측하는 가장 첫 번째 신호이기 때문이라는 중요한 원리를 밝혀냈습니다. 또한, 개입해도 성능에 거의 영향이 없는 "게으른 에이전트(Lazy Agent)"를 식별하는 데도 성공했습니다.
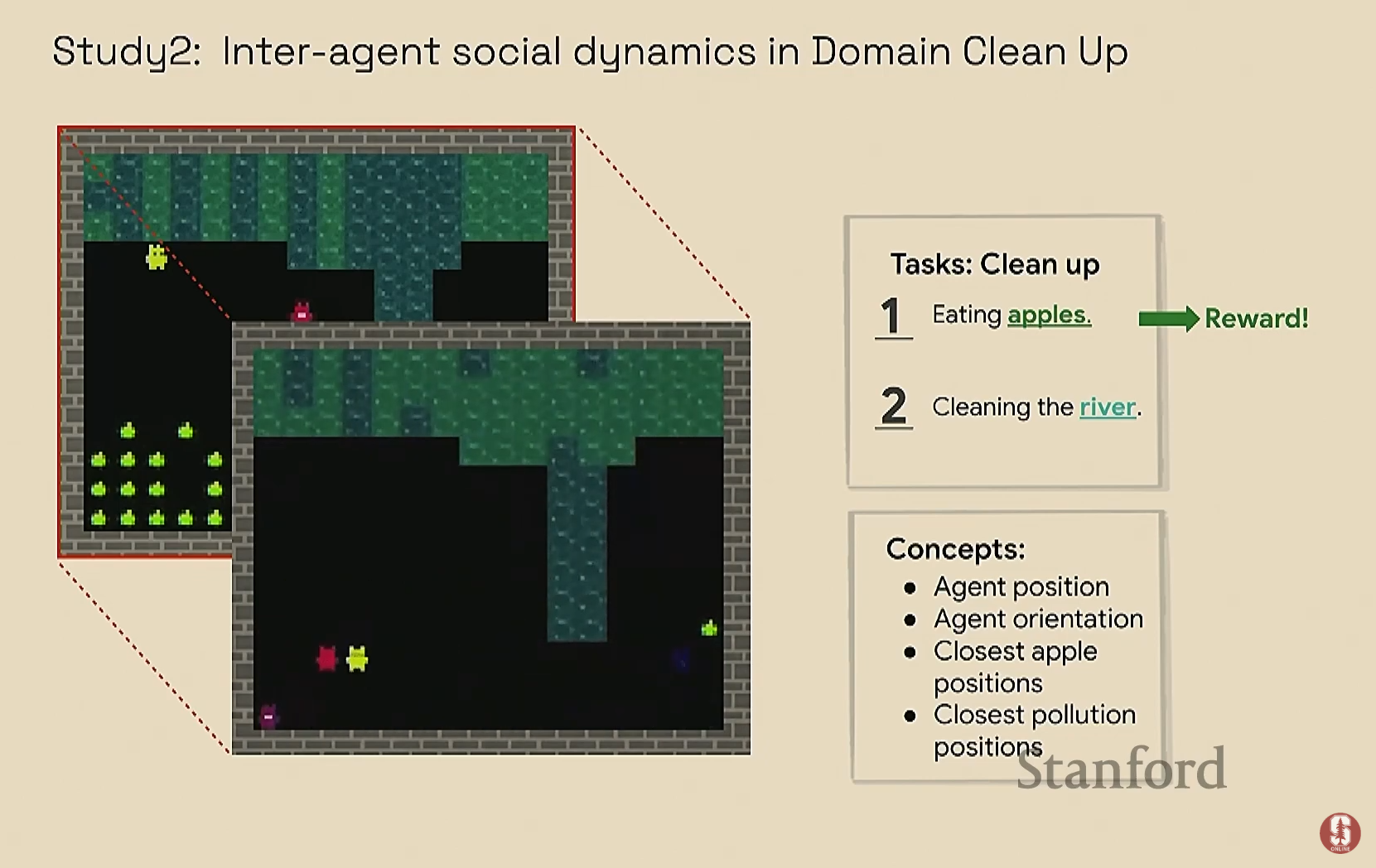
- 정화 게임 (4에이전트 사과 수집):
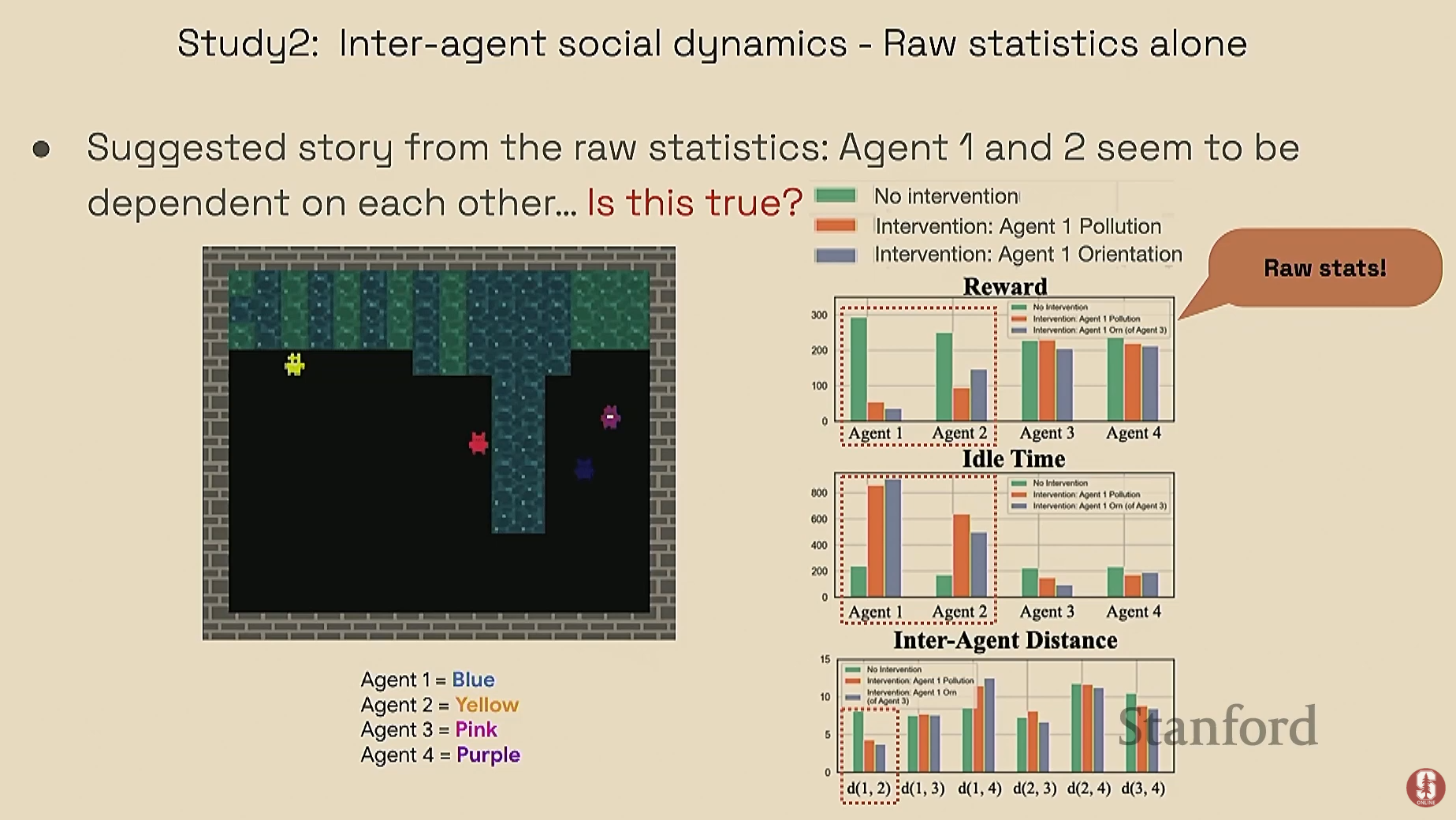
- 문제: 표면적인 통계만 보면 에이전트 1이 에이전트 2에게 영향을 주는 것처럼 보였습니다.
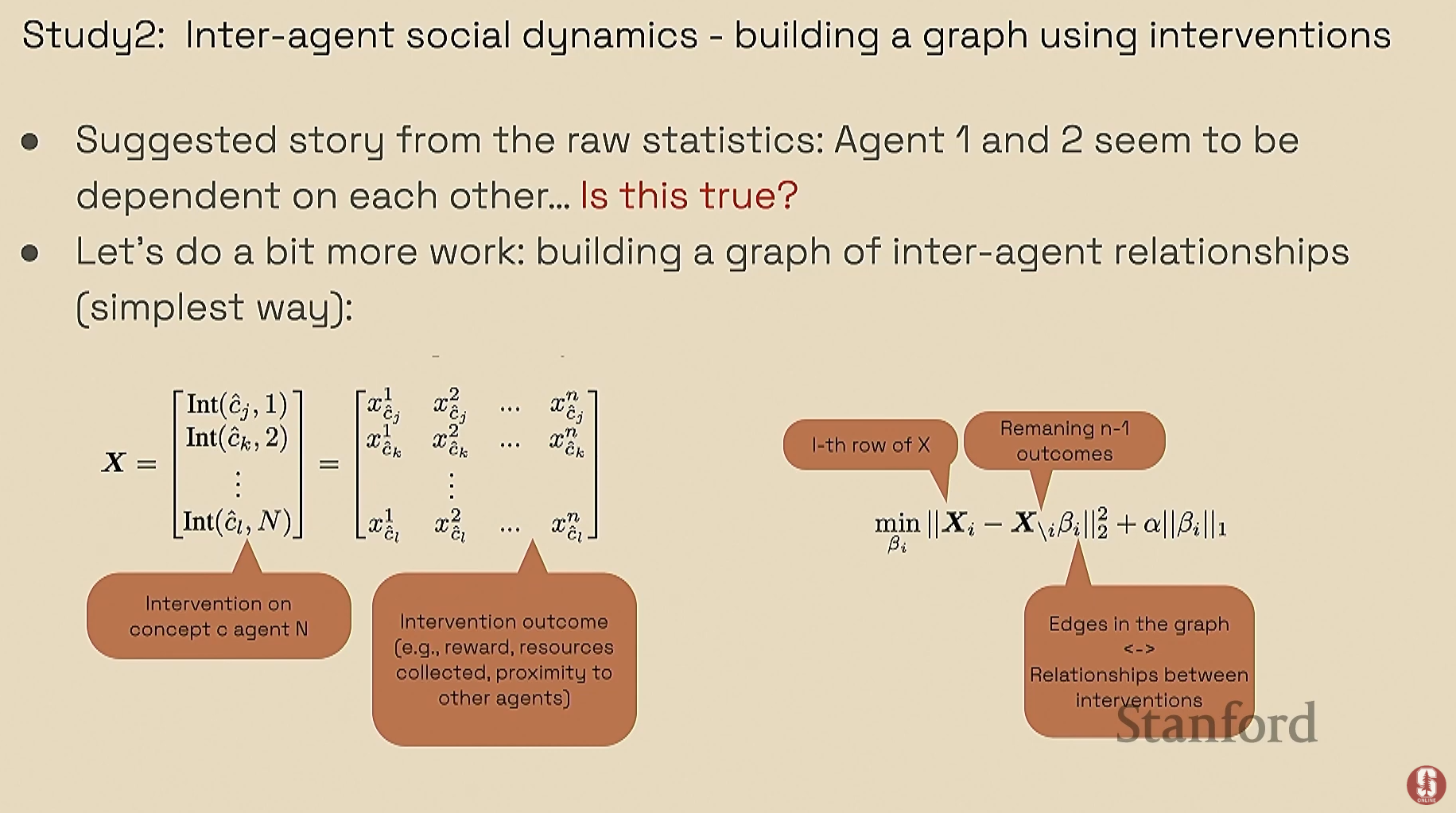
- 분석: 하지만 컨셉 병목 모델을 통해 개입 실험을 하고 그 결과를 그래프 기반으로 분석하자, 실제로는 에이전트 1과 4 사이에 강한 상호작용이 있다는 숨겨진 사실을 발견했습니다.
- 결론: 원래의 관찰은 두 에이전트가 협력한 것이 아니라, 좁은 길에서 우연히 함께 갇히는 바람에 발생한 현상이었음을 밝혀냈습니다. 이는 표면적 관찰만으로는 알 수 없는 행동의 진짜 원인을 파악하는 데 이 방법론이 매우 효과적임을 보여줍니다.
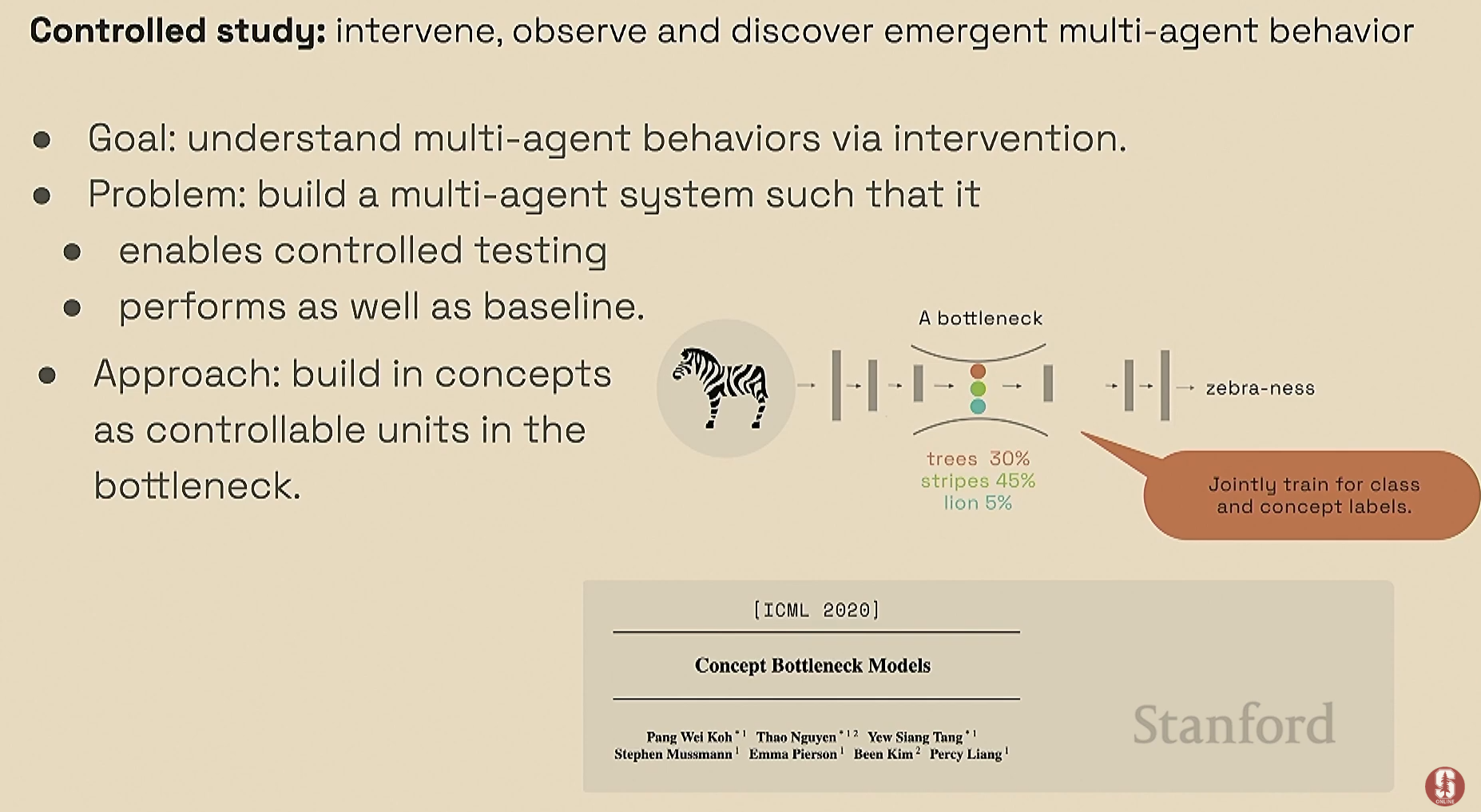
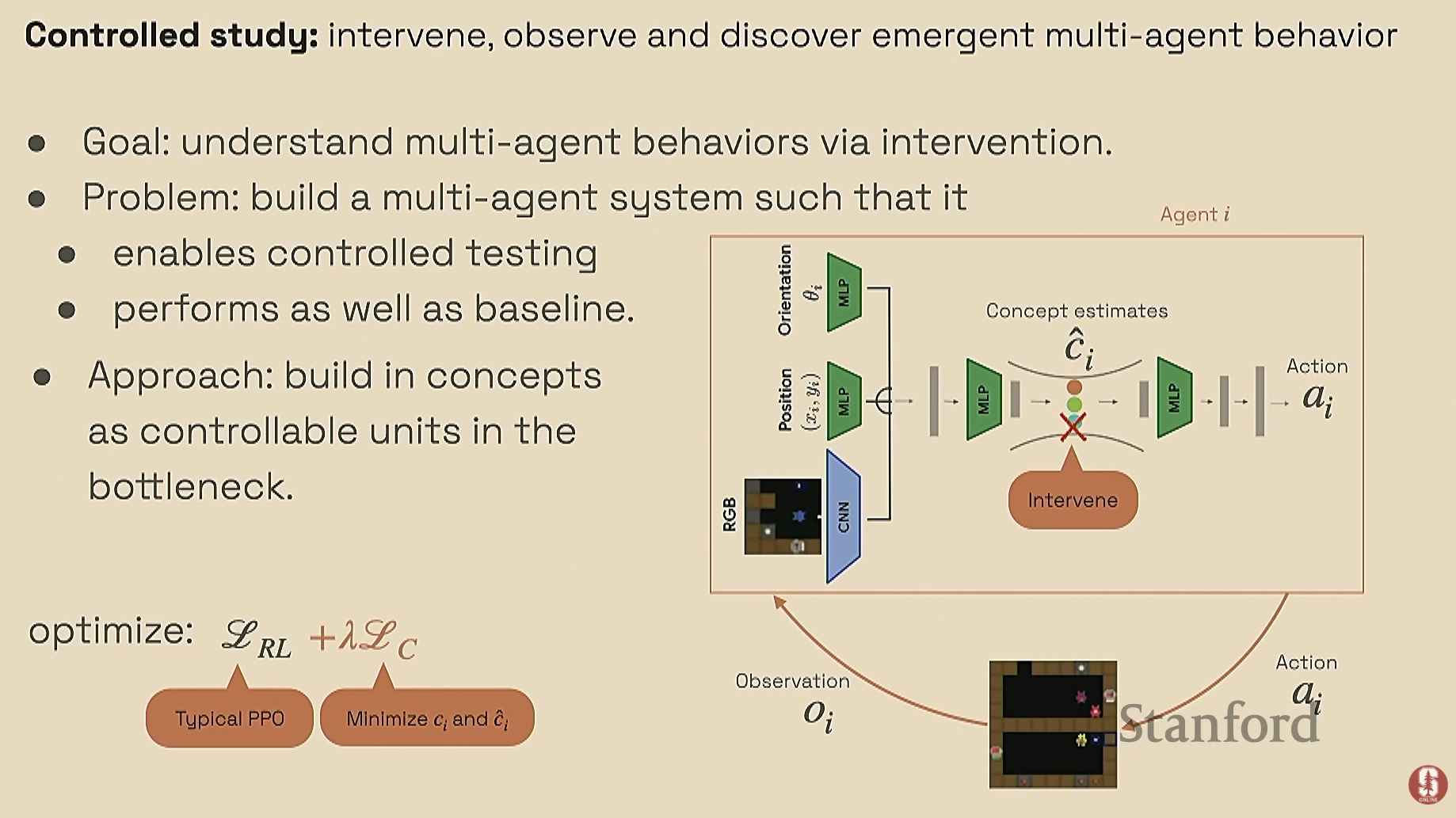

- 요리 게임 (2에이전트 수프 만들기):
이처럼 강화학습 에이전트 연구는 단순히 '무엇을 하는지'를 넘어, '왜 그렇게 행동하는지'를 발견(관찰)하고 증명(통제)하는 체계적인 방법론을 통해 AI의 복잡한 내면을 이해하려는 시도라고 할 수 있습니다.
5. 미래 연구 방향: 초인적 체스 전략 이해하기
1) AlphaZero의 초인적 체스 전략 탐구
- 현재 진행 중인 흥미로운 프로젝트는 AlphaZero의 초인적인 체스 전략을 이해하는 것입니다.
- 프로젝트 목표: 세계 체스 챔피언 매그너스 칼슨에게 새롭고 초인적인 체스 전략을 가르치는 것입니다.
- 방법론: 기존 체스 전략을 명시적으로 잊게 하고, 기존 개념 간의 관계를 기반으로 더 복잡한 그래프를 학습하여 새로운 개념을 추론합니다.
- 평가: 매그너스 칼슨이 새롭게 발견된 개념을 바탕으로 퍼즐을 풀게 하여 명확한 성공/실패 지표를 얻습니다.

2) 결론
- 김빈 박사님은 관찰 및 통제 연구를 통해 기계 지식의 격차를 이해하기 위한 작은 발걸음을 내딛고 있음을 재차 강조하며 강의를 마칩니다.
- 이 체스 프로젝트가 언젠가 알파고의 '37수'와 같은 복잡한 기계 행동을 이해하는 데 더 가까이 다가갈 수 있기를 희망합니다.
6. 질의응답(Q&A) 세션 상세 내용
Q1. Attribution 방법에 대한 이론적 증명이 컴퓨터 모델에만 국한되나요?
- A1. 아닙니다. 이 이론적 발견은 컴퓨터 모델뿐만 아니라 어떤 함수(any function)에도 적용될 수 있습니다. 특정 입력이 함수의 출력에 얼마나 기여했는지를 설명하려는 모든 시도에 해당될 수 있는 광범위한 결과입니다.
Q2. 지역화와 편집 사이에 상관관계가 없는 이유는 무엇인가요?
- A2. 여전히 수수께끼 같은(puzzling) 문제입니다. 하지만 강의자는 만약 노이즈가 많은 도구(noisy tools)라도 인간이 올바른 검증을 통해 유용하게 사용한다면 그것만으로도 가치가 있다고 언급했습니다. 즉, 이론적 완벽성보다 실용적 유효성이 중요할 수 있다는 점을 인정했습니다.
Q3. 해석가능성 기술이 다른 데이터 유형(modality) 간에 이전될 수 있나요?
- A3. 네, 가능합니다. 하지만 일반적으로는 각 응용 분야에 맞는 커스터마이징이 필요합니다. 핵심 아이디어는 공유될 수 있지만, 실제 적용을 위해서는 해당 데이터와 문제의 특성에 맞게 조정해야 합니다.
Q4. 인간이 알파고나 알파제로를 이길 수 있는 방법이 있나요?
- A4. 일부 아마추어 바둑 기사들이 분포를 벗어난(out-of-distribution) 수에 대한 인간의 지식을 활용하여 알파고를 이기는 "까다로운 전략"을 발견했습니다. 현재 체스 챔피언이자 연구 협력자인 '리사' 역시 알파제로를 상대로 비슷한 전략을 구사할 수 있다고 합니다.
Q5. 창발적 행동 연구의 궁극적인 목표는 무엇인가요?
- A5. 강화학습 시스템이 현실 세계에 배포되었을 때 발생할 수 있는 예상치 못한 놀라움(unexpected surprises)이 해를 끼치기 전에 미리 발견하고 이해하는 것을 돕는 것입니다. 이는 AI 안전과 직결되는 중요한 연구입니다.
Q6. 기계가 인간의 언어로 스스로를 설명하도록 가르치는 것에 대해 어떻게 생각하나요?
- A6. 이중적인 접근(dual approach)이 필요하다고 생각합니다. 인간의 언어를 기계의 공간에 매핑하는 것은 유용하지만, 인간의 개념 자체가 주관적이기 때문에(예: '펭귄'의 정의) 본질적으로 불완전합니다. 또한, 그 과정에서 인간을 넘어서는 초인적인 지식(superhuman knowledge)을 놓칠 위험이 있습니다. 따라서 두 가지 접근법을 모두 추구해야 합니다.
Q7. AI 해석가능성 연구가 뇌과학과 어떤 관련이 있나요?
- A7. 신경망의 기원이 인간 두뇌를 이해하려는 시도에 있었던 만큼 깊은 관련이 있습니다. 하지만, 뇌과학 연구의 편향(예: 도구의 한계로 단일 뉴런에만 집중하는 경향)이 오히려 AI 해석가능성 연구의 발전을 저해할 수도 있다는 점을 지적했습니다. 즉, 뇌과학에서 영감을 얻되, 그 방법론적 한계에 갇혀서는 안 된다는 의미입니다.
