1. Word2Vec 이전의 단어 표현 방식: One-Hot Encoding
- 단어의 의미를 컴퓨터가 이해할 수 있는 형태로 바꾸는 가장 단순한 방법은 원-핫 인코딩(One-Hot Encoding)입니다.
1) 개념
- 어휘집(vocabulary)에 있는 모든 단어를 고유한 숫자(인덱스)로 매핑하고, 각 단어를 해당 위치에만 1이 있는 벡터로 표현하는 방식입니다.
- 예를 들어, 어휘집에 "사과", "바나나", "호랑이"가 있다면 "사과"는 [1, 0, 0], "바나나"는 [0, 1, 0], "호랑이"는 [0, 0, 1]로 표현됩니다.
2) 한계점
의미적 유사성 반영 불가
- 모든 단어 벡터는 서로에게 직교(orthogonal)하므로, [1, 0, 0]와 [0, 1, 0]의 내적 값은 0이 됩니다.
- 이는 "사과"와 "바나나"가 아무런 관계가 없다고 간주합니다. 하지만 실제로는 둘 다 과일이라는 공통점을 가집니다.
- 즉, 단어 간의 유사도를 전혀 계산할 수 없습니다.
희소성(Sparsity) 문제
- 어휘집의 크기가 커질수록 벡터의 차원도 급격히 늘어나 대부분의 값이 0인 거대한 벡터가 만들어집니다.
- 이는 저장 공간을 낭비하고 계산 효율을 떨어뜨립니다.
2. Word2Vec
1) 핵심 개념
- 단어의 의미는 그 단어가 문맥에서 어떤 단어들과 함께 나타나는지에 따라 결정됩니다.
- 즉, 비슷한 문맥에서 사용되는 단어들은 비슷한 의미를 가진다는 것입니다.
2) Word2Vec의 목표
- 이 개념을 바탕으로, 의미적으로 유사한 단어들은 벡터 공간에서 가까운 위치에 배치하는 밀집된 실수 벡터(dense real-valued vectors)를 학습하는 것이 Word2Vec의 목표입니다.
- 이 벡터를 단어 임베딩(Word Embedding) 또는 단어 벡터(Word Vectors)라고 부릅니다.
3) 주요 학습 방법
- 말뭉치(Corpus) 준비: 방대한 양의 텍스트 데이터(예: 위키피디아, 뉴스 기사)를 준비합니다.
- 중심 단어(Center Word)와 주변 단어(Context Words) 설정: 문장을 순회하며, 중심이 되는 단어와 그 주변의 단어를 정의합니다.
- 확률 계산 및 최적화: 중심 단어가 주어졌을 때 주변 단어가 나타날 확률을 계산하고, 이 확률이 실제 텍스트의 분포와 일치하도록 단어 벡터들을 업데이트합니다. 이 과정에서 경사 하강법(Gradient Descent)을 사용해 오차를 줄여나갑니다.
4) Word2vec의 손실함수

- 위 손실함수를 통해서, 문맥상의 비슷한 단어가 많도록(즉, 중심 단어 주변의 단어간의 유사도가 높은) 다음 단어를 고르게 됩니다.
- 는 softmax 함수의 확률 수식을 활용한, 단어간의 관계성을 나타내는 확률입니다.


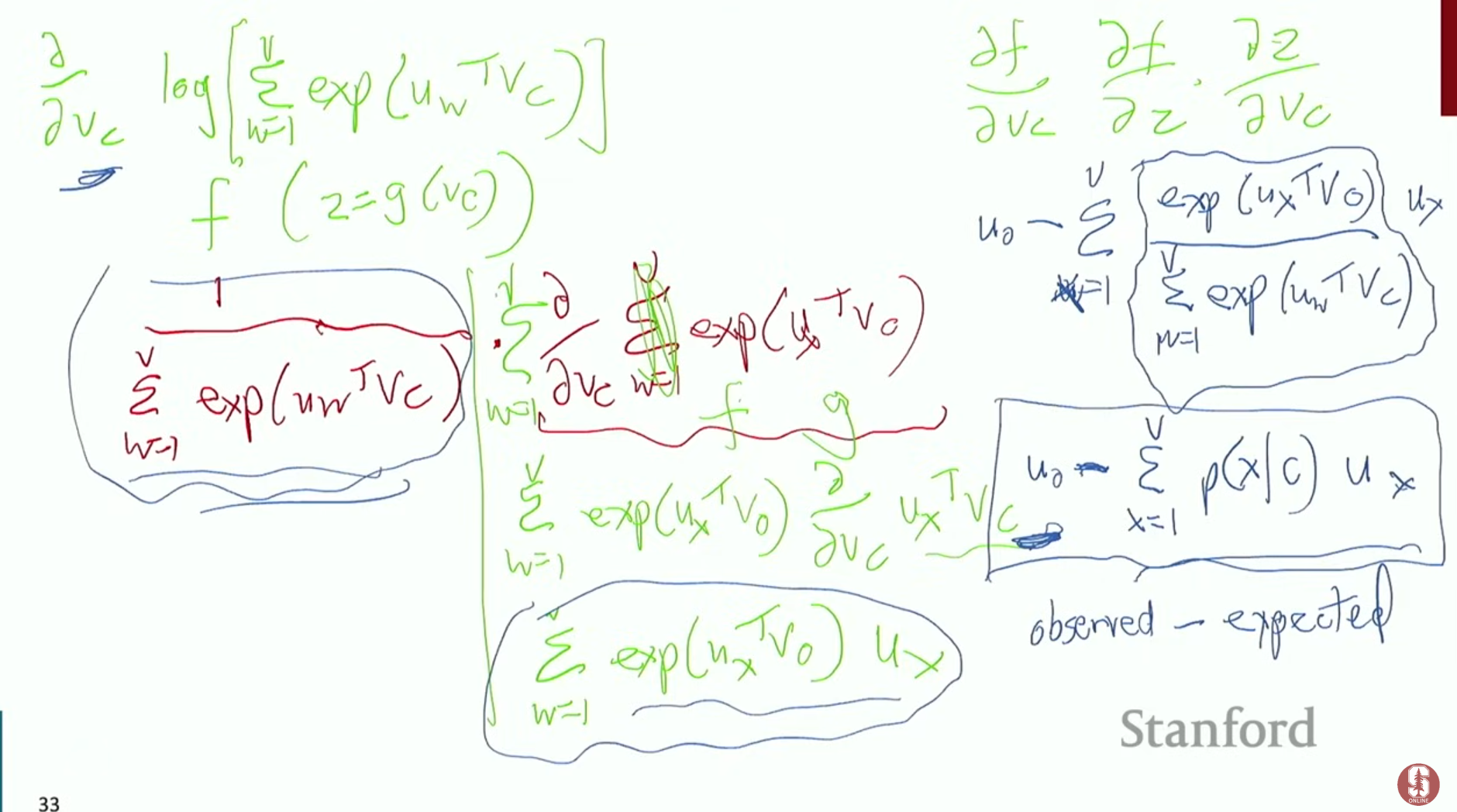
- 또한, 위와 같은 증명과정을 통해서, 손실함수의 미분이 나타내는 것이 실제 문장에 존재하는 observed 벡터와 이 가중치가 말뭉치(vocabulary)로부터 주변 단어를 예측한 벡터의 차이를 의미합니다.
- 즉, 오차 벡터라고 볼 수 있습니다.
5) Word2vec의 특징
- 모든 단어는 2개의 동일한 벡터가 합쳐진 형태를 띄게 됩니다.
- 왜냐하면, 각각 그 단어가 중심 단어일 때와 주변 단어일 때 사용하는 벡터입니다.
- 이렇게 나누는 이유는 이렇게 하면 벡터가 더 풍부한 의미를 담고 있게 되고, 중심 단어와 주변 단어의 유사도를 구하는 내적 계산을 단순하게 할 수 있게 됩니다.
- 왜냐하면, 중심 단어 벡터와 주변 단어 벡터는 서로 다른 값을 가지기 때문입니다.
- 중심 단어 벡터는 '이 단어와 함께 나타날 가능성이 높은 단어는 무엇인가?'를 학습하는 방향으로 업데이트되고 주변 단어 벡터는 '이 단어가 어떤 단어와 함께 나타났는가?'(즉, 메모리의 역할을 하는 방식)를 학습하는 방향으로 업데이트됩니다.
- 또한, word2vec는 결국 특정 단어에 대한 정보를 담는 vector를 학습하는 것이기 때문에, vector의 size에 대해서는 하이퍼파라미터로 조절해야하는 요소입니다.
3. Word2Vec의 장점
1) 의미적, 문법적 관계 포착
- Word2Vec으로 학습된 단어 벡터는 단순히 단어의 존재 여부를 넘어, 단어 간의 복잡한 관계를 수치적으로 표현할 수 있습니다.
- 예를 들어, "킹 - 남자 + 여자 ≈ 퀸"과 같은 흥미로운 관계를 벡터 연산을 통해 발견할 수 있습니다.
2) 낮은 차원의 밀집 벡터
- 원-핫 벡터와 달리, 단어 임베딩은 보통 100~300차원과 같은 낮은 차원의 밀집 벡터로 구성되어 효율적입니다.
3) 다양한 NLP 태스크에 활용
- 단어 임베딩은 자연어 처리의 다양한 하위 태스크(예: 텍스트 분류, 감성 분석, 기계 번역 등)의 입력 데이터로 사용되어 성능을 크게 향상시켰습니다.

AI 공부합니다